 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink before you speak: Training Language Models With Pause Tokens
Oct 03, 2023



Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $\textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $\textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18\%$ EM score on the QA task of SQuAD, $8\%$ on CommonSenseQA and $1\%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
The importance of feature preprocessing for differentially private linear optimization
Jul 19, 2023

Training machine learning models with differential privacy (DP) has received increasing interest in recent years. One of the most popular algorithms for training differentially private models is differentially private stochastic gradient descent (DPSGD) and its variants, where at each step gradients are clipped and combined with some noise. Given the increasing usage of DPSGD, we ask the question: is DPSGD alone sufficient to find a good minimizer for every dataset under privacy constraints? As a first step towards answering this question, we show that even for the simple case of linear classification, unlike non-private optimization, (private) feature preprocessing is vital for differentially private optimization. In detail, we first show theoretically that there exists an example where without feature preprocessing, DPSGD incurs a privacy error proportional to the maximum norm of features over all samples. We then propose an algorithm called DPSGD-F, which combines DPSGD with feature preprocessing and prove that for classification tasks, it incurs a privacy error proportional to the diameter of the features $\max_{x, x' \in D} \|x - x'\|_2$. We then demonstrate the practicality of our algorithm on image classification benchmarks.
When Does Confidence-Based Cascade Deferral Suffice?
Jul 06, 2023



Cascades are a classical strategy to enable inference cost to vary adaptively across samples, wherein a sequence of classifiers are invoked in turn. A deferral rule determines whether to invoke the next classifier in the sequence, or to terminate prediction. One simple deferral rule employs the confidence of the current classifier, e.g., based on the maximum predicted softmax probability. Despite being oblivious to the structure of the cascade -- e.g., not modelling the errors of downstream models -- such confidence-based deferral often works remarkably well in practice. In this paper, we seek to better understand the conditions under which confidence-based deferral may fail, and when alternate deferral strategies can perform better. We first present a theoretical characterisation of the optimal deferral rule, which precisely characterises settings under which confidence-based deferral may suffer. We then study post-hoc deferral mechanisms, and demonstrate they can significantly improve upon confidence-based deferral in settings where (i) downstream models are specialists that only work well on a subset of inputs, (ii) samples are subject to label noise, and (iii) there is distribution shift between the train and test set.
ResMem: Learn what you can and memorize the rest
Feb 03, 2023



The impressive generalization performance of modern neural networks is attributed in part to their ability to implicitly memorize complex training patterns. Inspired by this, we explore a novel mechanism to improve model generalization via explicit memorization. Specifically, we propose the residual-memorization (ResMem) algorithm, a new method that augments an existing prediction model (e.g. a neural network) by fitting the model's residuals with a $k$-nearest neighbor based regressor. The final prediction is then the sum of the original model and the fitted residual regressor. By construction, ResMem can explicitly memorize the training labels. Empirically, we show that ResMem consistently improves the test set generalization of the original prediction model across various standard vision and natural language processing benchmarks. Theoretically, we formulate a stylized linear regression problem and rigorously show that ResMem results in a more favorable test risk over the base predictor.
Learning to reject meets OOD detection: Are all abstentions created equal?
Jan 31, 2023Learning to reject (L2R) and out-of-distribution (OOD) detection are two classical problems, each of which involve detecting certain abnormal samples: in L2R, the goal is to detect "hard" samples on which to abstain, while in OOD detection, the goal is to detect "outlier" samples not drawn from the training distribution. Intriguingly, despite being developed in parallel literatures, both problems share a simple baseline: the maximum softmax probability (MSP) score. However, there is limited understanding of precisely how these problems relate. In this paper, we formally relate these problems, and show how they may be jointly solved. We first show that while MSP is theoretically optimal for L2R, it can be theoretically sub-optimal for OOD detection in some important practical settings. We then characterize the Bayes-optimal classifier for a unified formulation that generalizes both L2R and OOD detection. Based on this, we design a plug-in approach for learning to abstain on both inlier and OOD samples, while constraining the total abstention budget. Experiments on benchmark OOD datasets demonstrate that our approach yields competitive classification and OOD detection performance compared to baselines from both literatures.
On student-teacher deviations in distillation: does it pay to disobey?
Jan 30, 2023



Knowledge distillation has been widely-used to improve the performance of a "student" network by hoping to mimic soft probabilities of a "teacher" network. Yet, for self-distillation to work, the student must somehow deviate from the teacher (Stanton et al., 2021). But what is the nature of these deviations, and how do they relate to gains in generalization? We investigate these questions through a series of experiments across image and language classification datasets. First, we observe that distillation consistently deviates in a characteristic way: on points where the teacher has low confidence, the student achieves even lower confidence than the teacher. Secondly, we find that deviations in the initial dynamics of training are not crucial -- simply switching to distillation loss in the middle of training can recover much of its gains. We then provide two parallel theoretical perspectives to understand the role of student-teacher deviations in our experiments, one casting distillation as a regularizer in eigenspace, and another as a gradient denoiser. Our analysis bridges several gaps between existing theory and practice by (a) focusing on gradient-descent training, (b) by avoiding label noise assumptions, and (c) by unifying several disjoint empirical and theoretical findings.
Supervision Complexity and its Role in Knowledge Distillation
Jan 28, 2023Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student's margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval
Jan 27, 2023



Large neural models (such as Transformers) achieve state-of-the-art performance for information retrieval (IR). In this paper, we aim to improve distillation methods that pave the way for the deployment of such models in practice. The proposed distillation approach supports both retrieval and re-ranking stages and crucially leverages the relative geometry among queries and documents learned by the large teacher model. It goes beyond existing distillation methods in the IR literature, which simply rely on the teacher's scalar scores over the training data, on two fronts: providing stronger signals about local geometry via embedding matching and attaining better coverage of data manifold globally via query generation. Embedding matching provides a stronger signal to align the representations of the teacher and student models. At the same time, query generation explores the data manifold to reduce the discrepancies between the student and teacher where training data is sparse. Our distillation approach is theoretically justified and applies to both dual encoder (DE) and cross-encoder (CE) models. Furthermore, for distilling a CE model to a DE model via embedding matching, we propose a novel dual pooling-based scorer for the CE model that facilitates a distillation-friendly embedding geometry, especially for DE student models.
When does mixup promote local linearity in learned representations?
Oct 28, 2022



Mixup is a regularization technique that artificially produces new samples using convex combinations of original training points. This simple technique has shown strong empirical performance, and has been heavily used as part of semi-supervised learning techniques such as mixmatch~\citep{berthelot2019mixmatch} and interpolation consistent training (ICT)~\citep{verma2019interpolation}. In this paper, we look at Mixup through a \emph{representation learning} lens in a semi-supervised learning setup. In particular, we study the role of Mixup in promoting linearity in the learned network representations. Towards this, we study two questions: (1) how does the Mixup loss that enforces linearity in the \emph{last} network layer propagate the linearity to the \emph{earlier} layers?; and (2) how does the enforcement of stronger Mixup loss on more than two data points affect the convergence of training? We empirically investigate these properties of Mixup on vision datasets such as CIFAR-10, CIFAR-100 and SVHN. Our results show that supervised Mixup training does not make \emph{all} the network layers linear; in fact the \emph{intermediate layers} become more non-linear during Mixup training compared to a network that is trained \emph{without} Mixup. However, when Mixup is used as an unsupervised loss, we observe that all the network layers become more linear resulting in faster training convergence.
Robust Distillation for Worst-class Performance
Jun 13, 2022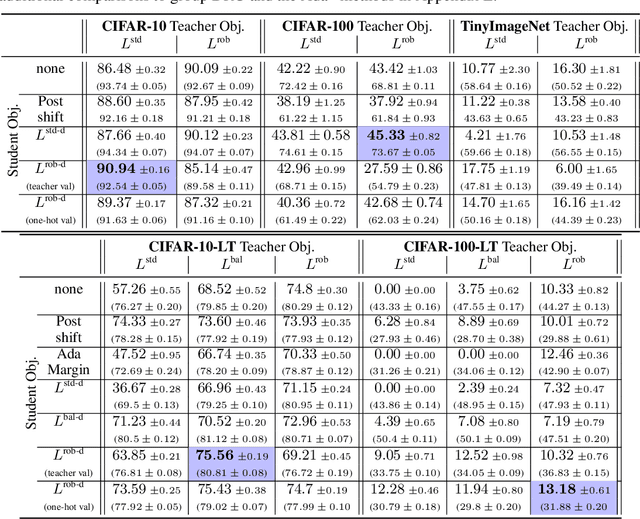
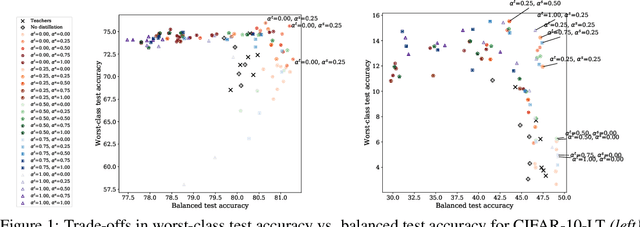
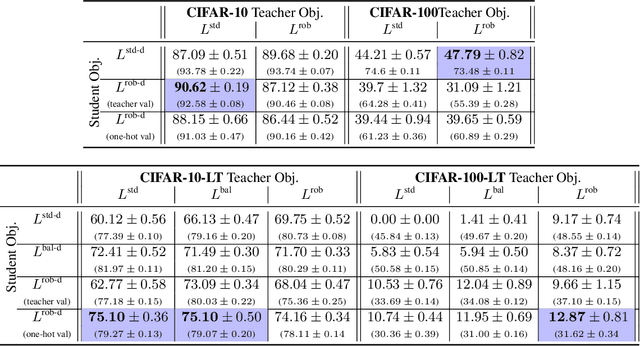
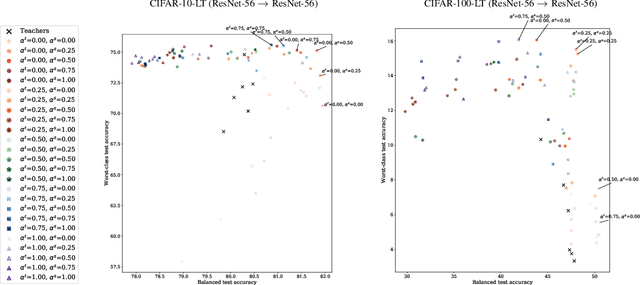
Knowledge distillation has proven to be an effective technique in improving the performance a student model using predictions from a teacher model. However, recent work has shown that gains in average efficiency are not uniform across subgroups in the data, and in particular can often come at the cost of accuracy on rare subgroups and classes. To preserve strong performance across classes that may follow a long-tailed distribution, we develop distillation techniques that are tailored to improve the student's worst-class performance. Specifically, we introduce robust optimization objectives in different combinations for the teacher and student, and further allow for training with any tradeoff between the overall accuracy and the robust worst-class objective. We show empirically that our robust distillation techniques not only achieve better worst-class performance, but also lead to Pareto improvement in the tradeoff between overall performance and worst-class performance compared to other baseline methods. Theoretically, we provide insights into what makes a good teacher when the goal is to train a robust student.