 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActual Causality and Responsibility Attribution in Decentralized Partially Observable Markov Decision Processes
Apr 01, 2022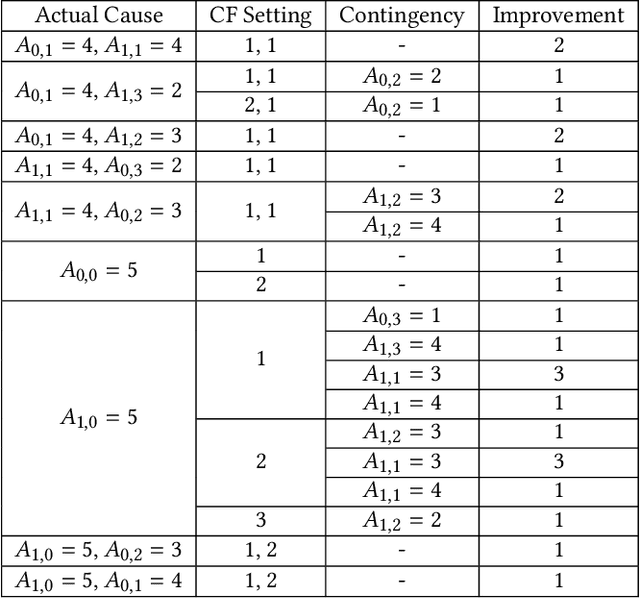
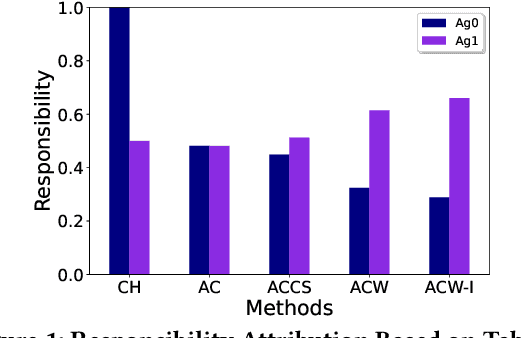
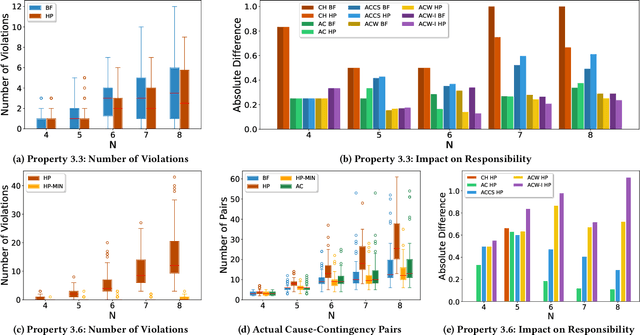
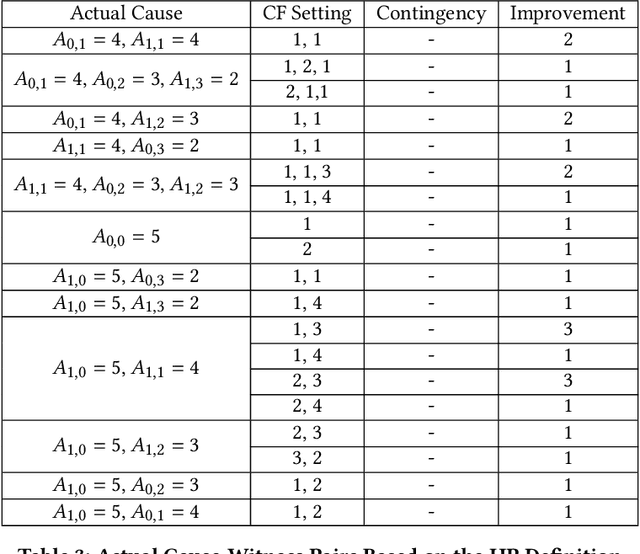
Actual causality and a closely related concept of responsibility attribution are central to accountable decision making. Actual causality focuses on specific outcomes and aims to identify decisions (actions) that were critical in realizing an outcome of interest. Responsibility attribution is complementary and aims to identify the extent to which decision makers (agents) are responsible for this outcome. In this paper, we study these concepts under a widely used framework for multi-agent sequential decision making under uncertainty: decentralized partially observable Markov decision processes (Dec-POMDPs). Following recent works in RL that show correspondence between POMDPs and Structural Causal Models (SCMs), we first establish a connection between Dec-POMDPs and SCMs. This connection enables us to utilize a language for describing actual causality from prior work and study existing definitions of actual causality in Dec-POMDPs. Given that some of the well-known definitions may lead to counter-intuitive actual causes, we introduce a novel definition that more explicitly accounts for causal dependencies between agents' actions. We then turn to responsibility attribution based on actual causality, where we argue that in ascribing responsibility to an agent it is important to consider both the number of actual causes in which the agent participates, as well as its ability to manipulate its own degree of responsibility. Motivated by these arguments we introduce a family of responsibility attribution methods that extends prior work, while accounting for the aforementioned considerations. Finally, through a simulation-based experiment, we compare different definitions of actual causality and responsibility attribution methods. The empirical results demonstrate the qualitative difference between the considered definitions of actual causality and their impact on attributed responsibility.
Admissible Policy Teaching through Reward Design
Jan 06, 2022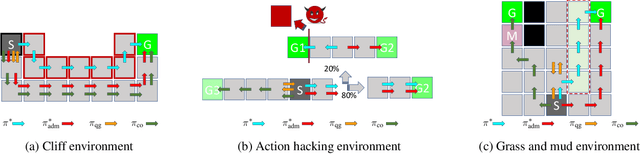
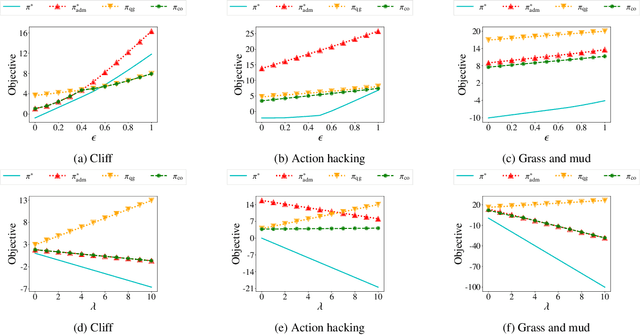
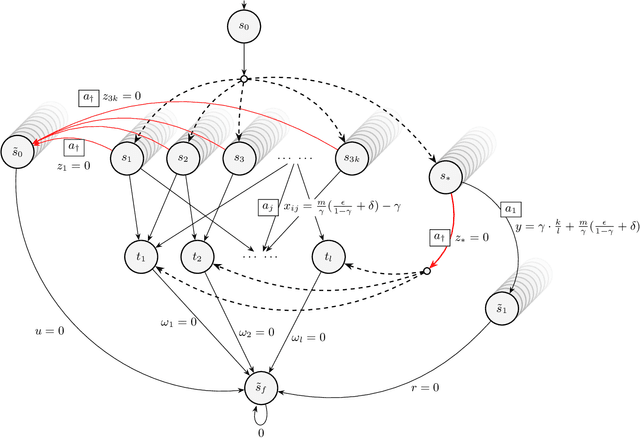
We study reward design strategies for incentivizing a reinforcement learning agent to adopt a policy from a set of admissible policies. The goal of the reward designer is to modify the underlying reward function cost-efficiently while ensuring that any approximately optimal deterministic policy under the new reward function is admissible and performs well under the original reward function. This problem can be viewed as a dual to the problem of optimal reward poisoning attacks: instead of forcing an agent to adopt a specific policy, the reward designer incentivizes an agent to avoid taking actions that are inadmissible in certain states. Perhaps surprisingly, and in contrast to the problem of optimal reward poisoning attacks, we first show that the reward design problem for admissible policy teaching is computationally challenging, and it is NP-hard to find an approximately optimal reward modification. We then proceed by formulating a surrogate problem whose optimal solution approximates the optimal solution to the reward design problem in our setting, but is more amenable to optimization techniques and analysis. For this surrogate problem, we present characterization results that provide bounds on the value of the optimal solution. Finally, we design a local search algorithm to solve the surrogate problem and showcase its utility using simulation-based experiments.
Teaching an Active Learner with Contrastive Examples
Oct 29, 2021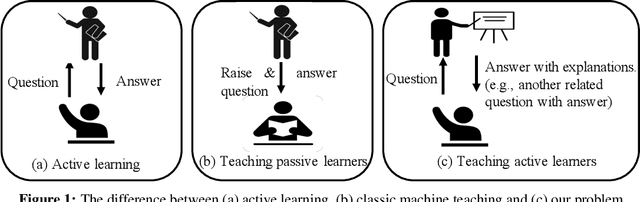
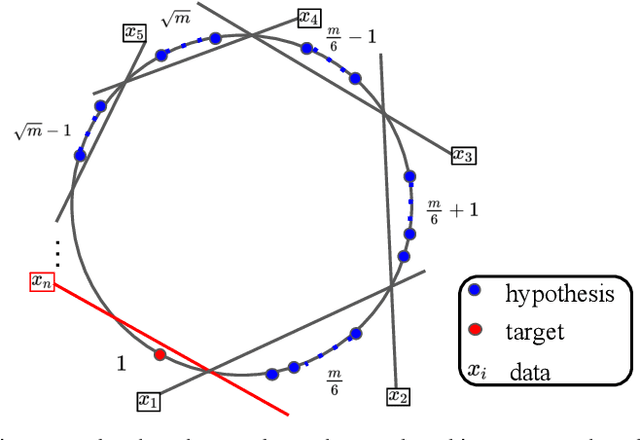
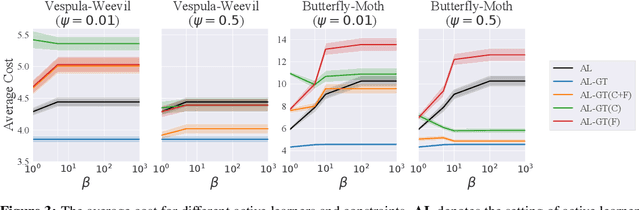
We study the problem of active learning with the added twist that the learner is assisted by a helpful teacher. We consider the following natural interaction protocol: At each round, the learner proposes a query asking for the label of an instance $x^q$, the teacher provides the requested label $\{x^q, y^q\}$ along with explanatory information to guide the learning process. In this paper, we view this information in the form of an additional contrastive example ($\{x^c, y^c\}$) where $x^c$ is picked from a set constrained by $x^q$ (e.g., dissimilar instances with the same label). Our focus is to design a teaching algorithm that can provide an informative sequence of contrastive examples to the learner to speed up the learning process. We show that this leads to a challenging sequence optimization problem where the algorithm's choices at a given round depend on the history of interactions. We investigate an efficient teaching algorithm that adaptively picks these contrastive examples. We derive strong performance guarantees for our algorithm based on two problem-dependent parameters and further show that for specific types of active learners (e.g., a generalized binary search learner), the proposed teaching algorithm exhibits strong approximation guarantees. Finally, we illustrate our bounds and demonstrate the effectiveness of our teaching framework via two numerical case studies.
Fairness Degrading Adversarial Attacks Against Clustering Algorithms
Oct 22, 2021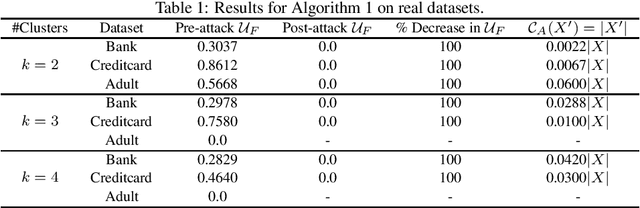
Clustering algorithms are ubiquitous in modern data science pipelines, and are utilized in numerous fields ranging from biology to facility location. Due to their widespread use, especially in societal resource allocation problems, recent research has aimed at making clustering algorithms fair, with great success. Furthermore, it has also been shown that clustering algorithms, much like other machine learning algorithms, are susceptible to adversarial attacks where a malicious entity seeks to subvert the performance of the learning algorithm. However, despite these known vulnerabilities, there has been no research undertaken that investigates fairness degrading adversarial attacks for clustering. We seek to bridge this gap by formulating a generalized attack optimization problem aimed at worsening the group-level fairness of centroid-based clustering algorithms. As a first step, we propose a fairness degrading attack algorithm for k-median clustering that operates under a whitebox threat model -- where the clustering algorithm, fairness notion, and the input dataset are known to the adversary. We provide empirical results as well as theoretical analysis for our simple attack algorithm, and find that the addition of the generated adversarial samples can lead to significantly lower fairness values. In this manner, we aim to motivate fairness degrading adversarial attacks as a direction for future research in fair clustering.
Reinforcement Learning Under Algorithmic Triage
Sep 23, 2021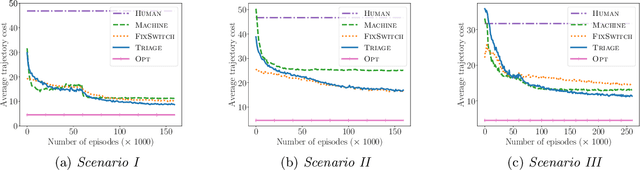
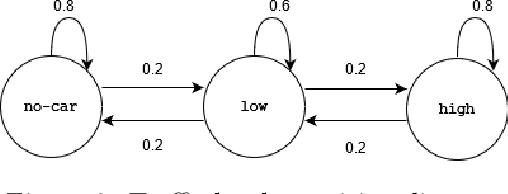
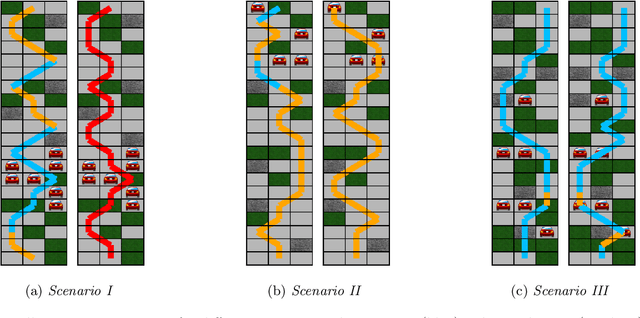
Methods to learn under algorithmic triage have predominantly focused on supervised learning settings where each decision, or prediction, is independent of each other. Under algorithmic triage, a supervised learning model predicts a fraction of the instances and humans predict the remaining ones. In this work, we take a first step towards developing reinforcement learning models that are optimized to operate under algorithmic triage. To this end, we look at the problem through the framework of options and develop a two-stage actor-critic method to learn reinforcement learning models under triage. The first stage performs offline, off-policy training using human data gathered in an environment where the human has operated on their own. The second stage performs on-policy training to account for the impact that switching may have on the human policy, which may be difficult to anticipate from the above human data. Extensive simulation experiments in a synthetic car driving task show that the machine models and the triage policies trained using our two-stage method effectively complement human policies and outperform those provided by several competitive baselines.
On Blame Attribution for Accountable Multi-Agent Sequential Decision Making
Jul 26, 2021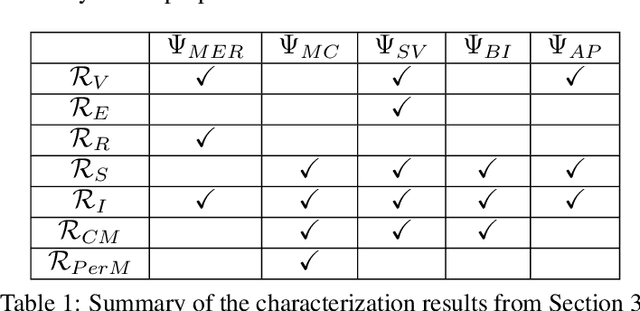
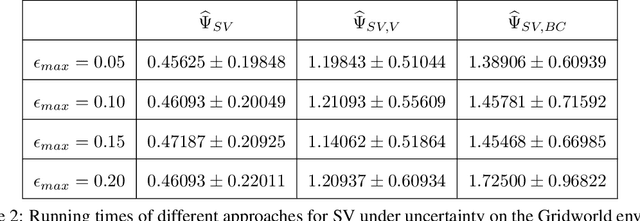
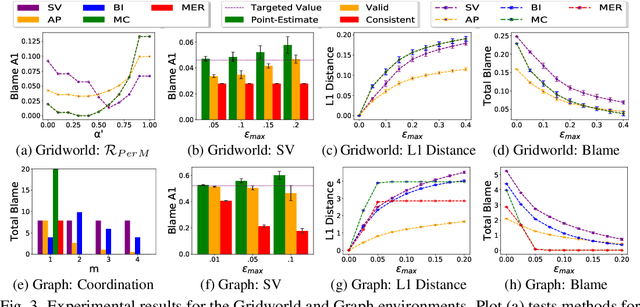
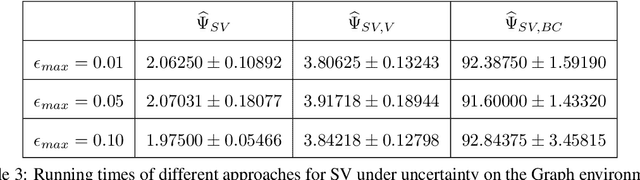
Blame attribution is one of the key aspects of accountable decision making, as it provides means to quantify the responsibility of an agent for a decision making outcome. In this paper, we study blame attribution in the context of cooperative multi-agent sequential decision making. As a particular setting of interest, we focus on cooperative decision making formalized by Multi-Agent Markov Decision Processes (MMDP), and we analyze different blame attribution methods derived from or inspired by existing concepts in cooperative game theory. We formalize desirable properties of blame attribution in the setting of interest, and we analyze the relationship between these properties and the studied blame attribution methods. Interestingly, we show that some of the well known blame attribution methods, such as Shapley value, are not performance-incentivizing, while others, such as Banzhaf index, may over-blame agents. To mitigate these value misalignment and fairness issues, we introduce a novel blame attribution method, unique in the set of properties it satisfies, which trade-offs explanatory power (by under-blaming agents) for the aforementioned properties. We further show how to account for uncertainty about agents' decision making policies, and we experimentally: a) validate the qualitative properties of the studied blame attribution methods, and b) analyze their robustness to uncertainty.
Reinforcement Learning for Education: Opportunities and Challenges
Jul 15, 2021This survey article has grown out of the RL4ED workshop organized by the authors at the Educational Data Mining (EDM) 2021 conference. We organized this workshop as part of a community-building effort to bring together researchers and practitioners interested in the broad areas of reinforcement learning (RL) and education (ED). This article aims to provide an overview of the workshop activities and summarize the main research directions in the area of RL for ED.
Curriculum Design for Teaching via Demonstrations: Theory and Applications
Jun 08, 2021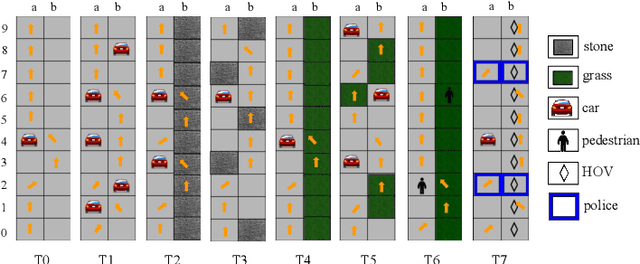

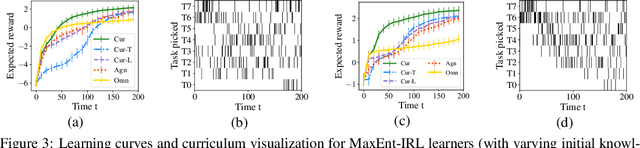
We consider the problem of teaching via demonstrations in sequential decision-making settings. In particular, we study how to design a personalized curriculum over demonstrations to speed up the learner's convergence. We provide a unified curriculum strategy for two popular learner models: Maximum Causal Entropy Inverse Reinforcement Learning (MaxEnt-IRL) and Cross-Entropy Behavioral Cloning (CrossEnt-BC). Our unified strategy induces a ranking over demonstrations based on a notion of difficulty scores computed w.r.t. the teacher's optimal policy and the learner's current policy. Compared to the state of the art, our strategy doesn't require access to the learner's internal dynamics and still enjoys similar convergence guarantees under mild technical conditions. Furthermore, we adapt our curriculum strategy to teach a learner using domain knowledge in the form of task-specific difficulty scores when the teacher's optimal policy is unknown. Experiments on a car driving simulator environment and shortest path problems in a grid-world environment demonstrate the effectiveness of our proposed curriculum strategy.
Fair Clustering Using Antidote Data
Jun 01, 2021
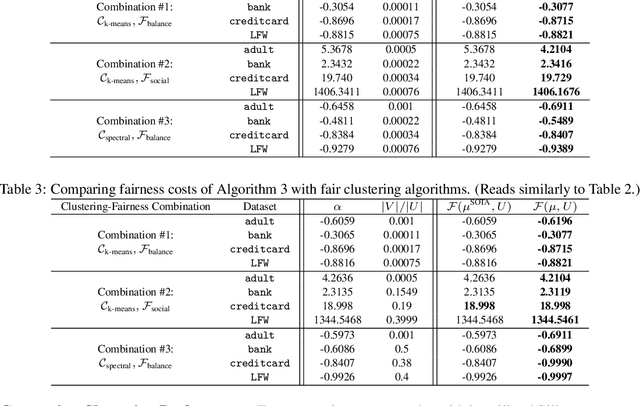
Clustering algorithms are widely utilized for many modern data science applications. This motivates the need to make outputs of clustering algorithms fair. Traditionally, new fair algorithmic variants to clustering algorithms are developed for specific notions of fairness. However, depending on the application context, different definitions of fairness might need to be employed. As a result, new algorithms and analysis need to be proposed for each combination of clustering algorithm and fairness definition. Additionally, each new algorithm would need to be reimplemented for deployment in a real-world system. Hence, we propose an alternate approach to fairness in clustering where we augment the original dataset with a small number of data points, called antidote data. When clustering is undertaken on this new dataset, the output is fair, for the chosen clustering algorithm and fairness definition. We formulate this as a general bi-level optimization problem which can accommodate any center-based clustering algorithms and fairness notions. We then categorize approaches for solving this bi-level optimization for different problem settings. Extensive experiments on different clustering algorithms and fairness notions show that our algorithms can achieve desired levels of fairness on many real-world datasets with a very small percentage of antidote data added. We also find that our algorithms achieve lower fairness costs and competitive clustering performance compared to other state-of-the-art fair clustering algorithms.
Loss-Aversively Fair Classification
May 10, 2021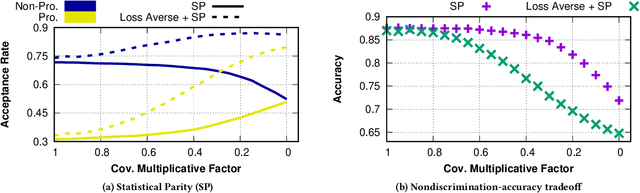
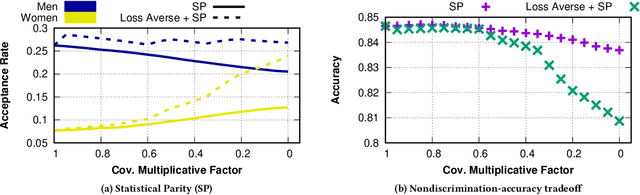
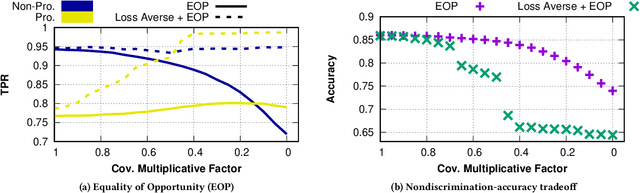
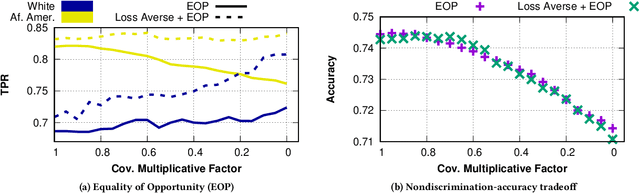
The use of algorithmic (learning-based) decision making in scenarios that affect human lives has motivated a number of recent studies to investigate such decision making systems for potential unfairness, such as discrimination against subjects based on their sensitive features like gender or race. However, when judging the fairness of a newly designed decision making system, these studies have overlooked an important influence on people's perceptions of fairness, which is how the new algorithm changes the status quo, i.e., decisions of the existing decision making system. Motivated by extensive literature in behavioral economics and behavioral psychology (prospect theory), we propose a notion of fair updates that we refer to as loss-averse updates. Loss-averse updates constrain the updates to yield improved (more beneficial) outcomes to subjects compared to the status quo. We propose tractable proxy measures that would allow this notion to be incorporated in the training of a variety of linear and non-linear classifiers. We show how our proxy measures can be combined with existing measures for training nondiscriminatory classifiers. Our evaluation using synthetic and real-world datasets demonstrates that the proposed proxy measures are effective for their desired tasks.
* 8 pages, Accepted at AIES 2019