 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Baseline Methods for IDD-based SSD External Memory Search
Jun 01, 2026Many difficult search problems cannot be solved by algorithms such as A* using only RAM. Search algorithms which use external memory such as SSDs and HDDs with much higher capacity than RAM have been proposed in previous work, but previous work has focused on delayed duplicate detection approaches, as well as complex immediate duplicate detection (IDD) methods, and relatively simple methods for IDD have not been systematically studied. In addition, the effect of OS-level mechanisms for managing and speeding up accesses to external memory, such as page caches, has not been studied. This paper addresses these gaps in the literature by evaluating and analyzing the performance of simple baseline approaches for IDD-based A*.
Is Selection All You Need in Differential Evolution?
Jun 17, 2025Differential Evolution (DE) is a widely used evolutionary algorithm for black-box optimization problems. However, in modern DE implementations, a major challenge lies in the limited population diversity caused by the fixed population size enforced by the generational replacement. Population size is a critical control parameter that significantly affects DE performance. Larger populations inherently contain a more diverse set of individuals, thereby facilitating broader exploration of the search space. Conversely, when the maximum evaluation budgets is constrained, smaller populations focusing on a limited number of promising candidates may be more suitable. Many state-of-the-art DE variants incorporate an archive mechanism, in which a subset of discarded individuals is preserved in an archive during generation replacement and reused in mutation operations. However, maintaining what is essentially a secondary population via an archive introduces additional design considerations, such as policies for insertion, deletion, and appropriate sizing. To address these limitations, we propose a novel DE framework called Unbounded Differential Evolution (UDE), which adds all generated candidates to the population without discarding any individual based on fitness. Unlike conventional DE, which removes inferior individuals during generational replacement, UDE eliminates replacement altogether, along with the associated complexities of archive management and dynamic population sizing. UDE represents a fundamentally new approach to DE, relying solely on selection mechanisms and enabling a more straightforward yet powerful search algorithm.
Parallel Greedy Best-First Search with a Bound on the Number of Expansions Relative to Sequential Search
Dec 16, 2024Parallelization of non-admissible search algorithms such as GBFS poses a challenge because straightforward parallelization can result in search behavior which significantly deviates from sequential search. Previous work proposed PUHF, a parallel search algorithm which is constrained to only expand states that can be expanded by some tie-breaking strategy for GBFS. We show that despite this constraint, the number of states expanded by PUHF is not bounded by a constant multiple of the number of states expanded by sequential GBFS with the worst-case tie-breaking strategy. We propose and experimentally evaluate One Bench At a Time (OBAT), a parallel greedy search which guarantees that the number of states expanded is within a constant factor of the number of states expanded by sequential GBFS with some tie-breaking policy.
Separate Generation and Evaluation for Parallel Greedy Best-First Search
Aug 11, 2024



Parallelization of Greedy Best First Search (GBFS) has been difficult because straightforward parallelization can result in search behavior which differs significantly from sequential GBFS, exploring states which would not be explored by sequential GBFS with any tie-breaking strategy. Recent work has proposed a class of parallel GBFS algorithms which constrains search to exploration of the Bench Transition System (BTS), which is the set of states that can be expanded by GBFS under some tie-breaking policy. However, enforcing this constraint is costly, as such BTS-constrained algorithms are forced to spend much of the time waiting so that only states which are guaranteed to be in the BTS are expanded. We propose an improvement to parallel search which decouples state generation and state evaluation and significantly improves state evaluation rate, resulting in better search performance.
On the Transit Obfuscation Problem
Feb 13, 2024



Concealing an intermediate point on a route or visible from a route is an important goal in some transportation and surveillance scenarios. This paper studies the Transit Obfuscation Problem, the problem of traveling from some start location to an end location while "covering" a specific transit point that needs to be concealed from adversaries. We propose the notion of transit anonymity, a quantitative guarantee of the anonymity of a specific transit point, even with a powerful adversary with full knowledge of the path planning algorithm. We propose and evaluate planning/search algorithms that satisfy this anonymity criterion.
Plausibility-Based Heuristics for Latent Space Classical Planning
Jun 20, 2023Recent work on LatPlan has shown that it is possible to learn models for domain-independent classical planners from unlabeled image data. Although PDDL models acquired by LatPlan can be solved using standard PDDL planners, the resulting latent-space plan may be invalid with respect to the underlying, ground-truth domain (e.g., the latent-space plan may include hallucinatory/invalid states). We propose Plausibility-Based Heuristics, which are domain-independent plausibility metrics which can be computed for each state evaluated during search and uses as a heuristic function for best-first search. We show that PBH significantly increases the number of valid found plans on image-based tile puzzle and Towers of Hanoi domains.
Learning Search-Space Specific Heuristics Using Neural Networks
Jun 06, 2023We propose and evaluate a system which learns a neuralnetwork heuristic function for forward search-based, satisficing classical planning. Our system learns distance-to-goal estimators from scratch, given a single PDDL training instance. Training data is generated by backward regression search or by backward search from given or guessed goal states. In domains such as the 24-puzzle where all instances share the same search space, such heuristics can also be reused across all instances in the domain. We show that this relatively simple system can perform surprisingly well, sometimes competitive with well-known domain-independent heuristics.
Classical Planning in Deep Latent Space
Jun 30, 2021

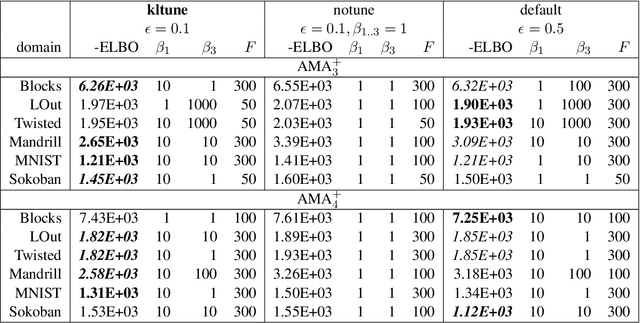
Current domain-independent, classical planners require symbolic models of the problem domain and instance as input, resulting in a knowledge acquisition bottleneck. Meanwhile, although deep learning has achieved significant success in many fields, the knowledge is encoded in a subsymbolic representation which is incompatible with symbolic systems such as planners. We propose Latplan, an unsupervised architecture combining deep learning and classical planning. Given only an unlabeled set of image pairs showing a subset of transitions allowed in the environment (training inputs), Latplan learns a complete propositional PDDL action model of the environment. Later, when a pair of images representing the initial and the goal states (planning inputs) is given, Latplan finds a plan to the goal state in a symbolic latent space and returns a visualized plan execution. We evaluate Latplan using image-based versions of 6 planning domains: 8-puzzle, 15-Puzzle, Blocksworld, Sokoban and Two variations of LightsOut.
TPAM: A Simulation-Based Model for Quantitatively Analyzing Parameter Adaptation Methods
Oct 05, 2020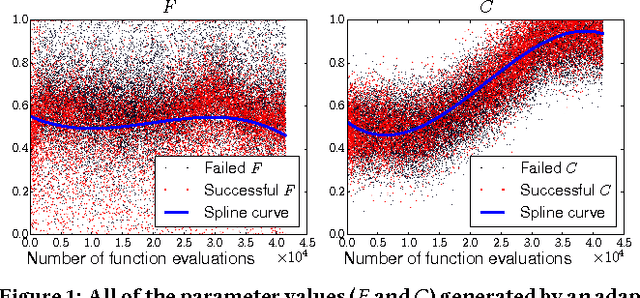
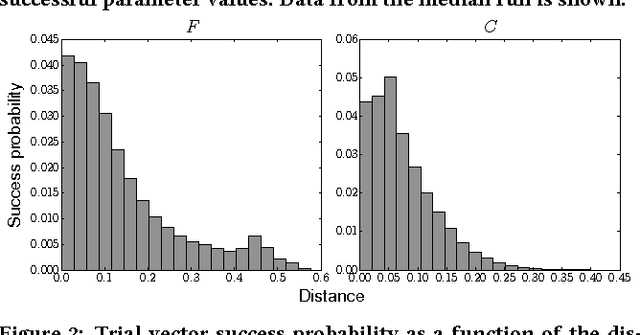
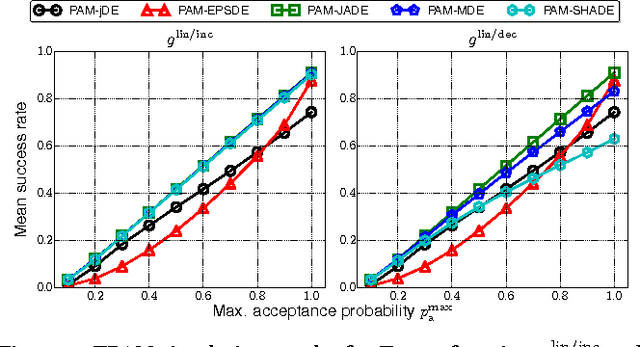
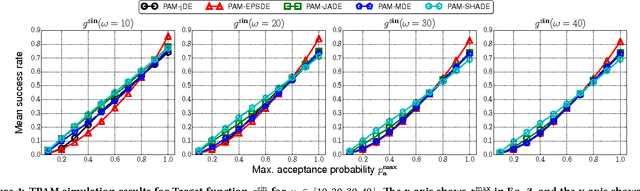
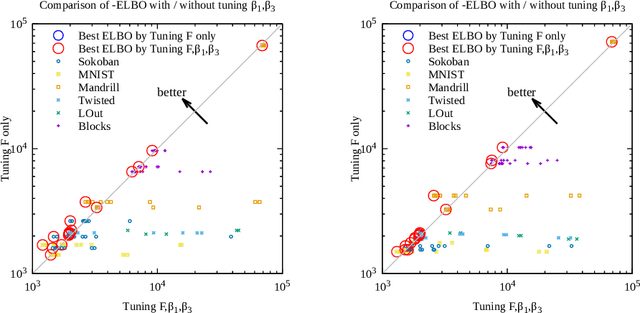
While a large number of adaptive Differential Evolution (DE) algorithms have been proposed, their Parameter Adaptation Methods (PAMs) are not well understood. We propose a Target function-based PAM simulation (TPAM) framework for evaluating the tracking performance of PAMs. The proposed TPAM simulation framework measures the ability of PAMs to track predefined target parameters, thus enabling quantitative analysis of the adaptive behavior of PAMs. We evaluate the tracking performance of PAMs of widely used five adaptive DEs (jDE, EPSDE, JADE, MDE, and SHADE) on the proposed TPAM, and show that TPAM can provide important insights on PAMs, e.g., why the PAM of SHADE performs better than that of JADE, and under what conditions the PAM of EPSDE fails at parameter adaptation.
Reviewing and Benchmarking Parameter Control Methods in Differential Evolution
Oct 02, 2020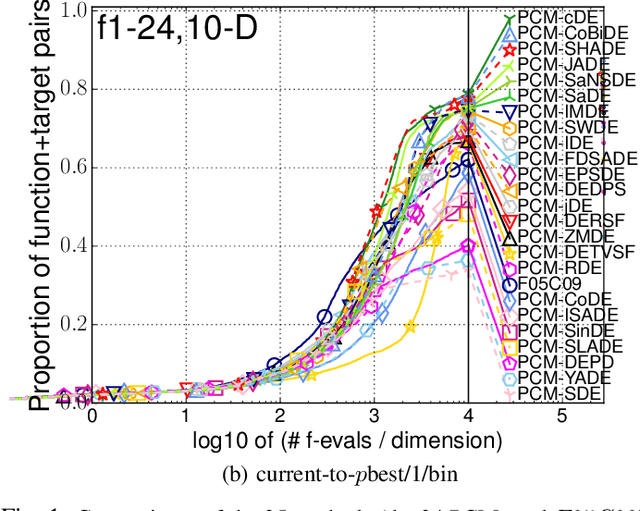
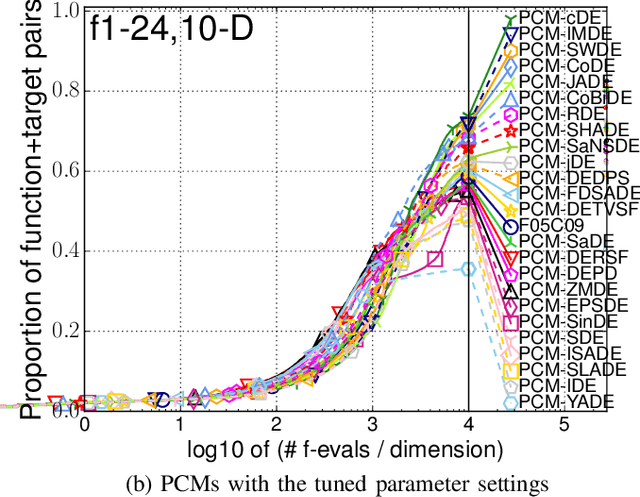
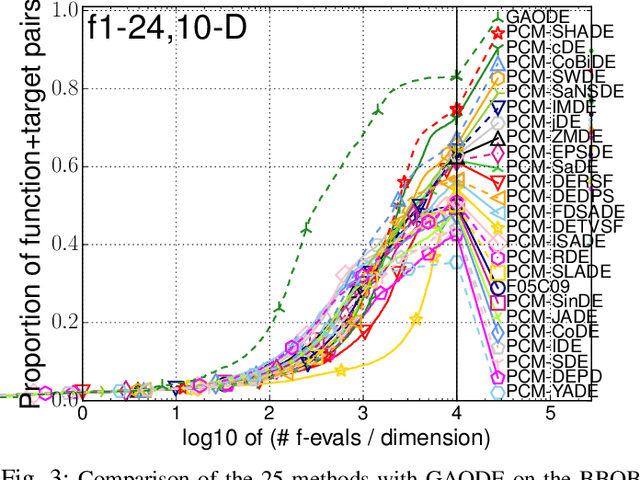
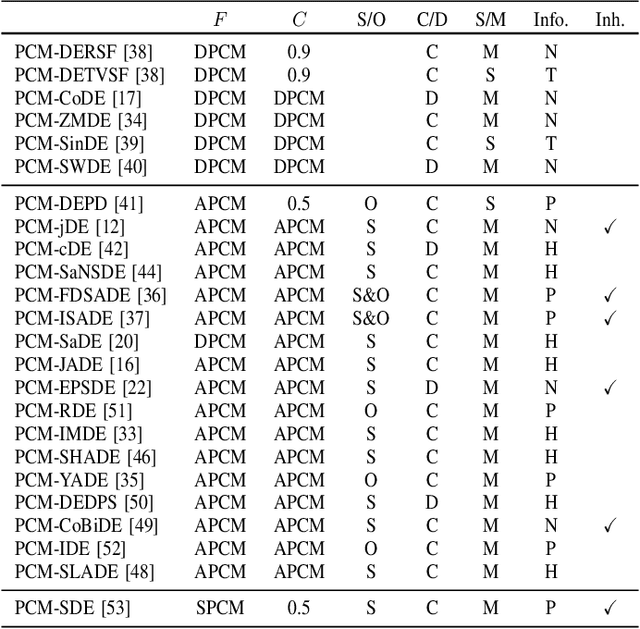
Many Differential Evolution (DE) algorithms with various parameter control methods (PCMs) have been proposed. However, previous studies usually considered PCMs to be an integral component of a complex DE algorithm. Thus the characteristics and performance of each method are poorly understood. We present an in-depth review of 24 PCMs for the scale factor and crossover rate in DE and a large scale benchmarking study. We carefully extract the 24 PCMs from their original, complex algorithms and describe them according to a systematic manner. Our review facilitates the understanding of similarities and differences between existing, representative PCMs. The performance of DEs with the 24 PCMs and 16 variation operators is investigated on 24 black-box benchmark functions. Our benchmarking results reveal which methods exhibit high performance when embedded in a standardized framework under 16 different conditions, independent from their original, complex algorithms. We also investigate how much room there is for further improvement of PCMs by comparing the 24 methods with an oracle-based model, which can be considered to be a conservative lower bound on the performance of an optimal method.