 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Is All You Need for MI Attacks
Nov 26, 2023
In this evolving era of machine learning security, membership inference attacks have emerged as a potent threat to the confidentiality of sensitive data. In this attack, adversaries aim to determine whether a particular point was used during the training of a target model. This paper proposes a new method to gauge a data point's membership in a model's training set. Instead of correlating loss with membership, as is traditionally done, we have leveraged the fact that training examples generally exhibit higher confidence values when classified into their actual class. During training, the model is essentially being 'fit' to the training data and might face particular difficulties in generalization to unseen data. This asymmetry leads to the model achieving higher confidence on the training data as it exploits the specific patterns and noise present in the training data. Our proposed approach leverages the confidence values generated by the machine learning model. These confidence values provide a probabilistic measure of the model's certainty in its predictions and can further be used to infer the membership of a given data point. Additionally, we also introduce another variant of our method that allows us to carry out this attack without knowing the ground truth(true class) of a given data point, thus offering an edge over existing label-dependent attack methods.
Playing in the Dark: No-regret Learning with Adversarial Constraints
Oct 29, 2023

We study a generalization of the classic Online Convex Optimization (OCO) framework by considering additional long-term adversarial constraints. Specifically, after an online policy decides its action on a round, in addition to a convex cost function, the adversary also reveals a set of $k$ convex constraints. The cost and the constraint functions could change arbitrarily with time, and no information about the future functions is assumed to be available. In this paper, we propose a meta-policy that simultaneously achieves a sublinear cumulative constraint violation and a sublinear regret. This is achieved via a black box reduction of the constrained problem to the standard OCO problem for a recursively constructed sequence of surrogate cost functions. We show that optimal performance bounds can be achieved by solving the surrogate problem using any adaptive OCO policy enjoying a standard data-dependent regret bound. A new Lyapunov-based proof technique is presented that reveals a connection between regret and certain sequential inequalities through a novel decomposition result. We conclude the paper by highlighting applications to online multi-task learning and network control problems.
$α$-Fair Contextual Bandits
Oct 22, 2023



Contextual bandit algorithms are at the core of many applications, including recommender systems, clinical trials, and optimal portfolio selection. One of the most popular problems studied in the contextual bandit literature is to maximize the sum of the rewards in each round by ensuring a sublinear regret against the best-fixed context-dependent policy. However, in many applications, the cumulative reward is not the right objective - the bandit algorithm must be fair in order to avoid the echo-chamber effect and comply with the regulatory requirements. In this paper, we consider the $\alpha$-Fair Contextual Bandits problem, where the objective is to maximize the global $\alpha$-fair utility function - a non-decreasing concave function of the cumulative rewards in the adversarial setting. The problem is challenging due to the non-separability of the objective across rounds. We design an efficient algorithm that guarantees an approximately sublinear regret in the full-information and bandit feedback settings.
BanditQ -- No-Regret Learning with Guaranteed Per-User Rewards in Adversarial Environments
Apr 11, 2023Classic online prediction algorithms, such as Hedge, are inherently unfair by design, as they try to play the most rewarding arm as many times as possible while ignoring the sub-optimal arms to achieve sublinear regret. In this paper, we consider a fair online prediction problem in the adversarial setting with hard lower bounds on the rate of accrual of rewards for all arms. By combining elementary queueing theory with online learning, we propose a new online prediction policy, called BanditQ, that achieves the target rate constraints while achieving a regret of $O(T^{3/4})$ in the full-information setting. The design and analysis of BanditQ involve a novel use of the potential function method and are of independent interest.
No-regret Algorithms for Fair Resource Allocation
Mar 11, 2023



We consider a fair resource allocation problem in the no-regret setting against an unrestricted adversary. The objective is to allocate resources equitably among several agents in an online fashion so that the difference of the aggregate $\alpha$-fair utilities of the agents between an optimal static clairvoyant allocation and that of the online policy grows sub-linearly with time. The problem is challenging due to the non-additive nature of the $\alpha$-fairness function. Previously, it was shown that no online policy can exist for this problem with a sublinear standard regret. In this paper, we propose an efficient online resource allocation policy, called Online Proportional Fair (OPF), that achieves $c_\alpha$-approximate sublinear regret with the approximation factor $c_\alpha=(1-\alpha)^{-(1-\alpha)}\leq 1.445,$ for $0\leq \alpha < 1$. The upper bound to the $c_\alpha$-regret for this problem exhibits a surprising phase transition phenomenon. The regret bound changes from a power-law to a constant at the critical exponent $\alpha=\frac{1}{2}.$ As a corollary, our result also resolves an open problem raised by Even-Dar et al. [2009] on designing an efficient no-regret policy for the online job scheduling problem in certain parameter regimes. The proof of our results introduces new algorithmic and analytical techniques, including greedy estimation of the future gradients for non-additive global reward functions and bootstrapping adaptive regret bounds, which may be of independent interest.
Online Subset Selection using $α$-Core with no Augmented Regret
Sep 29, 2022
We consider the problem of sequential sparse subset selections in an online learning setup. Assume that the set $[N]$ consists of $N$ distinct elements. On the $t^{\text{th}}$ round, a monotone reward function $f_t: 2^{[N]} \to \mathbb{R}_+,$ which assigns a non-negative reward to each subset of $[N],$ is revealed to a learner. The learner selects (perhaps randomly) a subset $S_t \subseteq [N]$ of $k$ elements before the reward function $f_t$ for that round is revealed $(k \leq N)$. As a consequence of its choice, the learner receives a reward of $f_t(S_t)$ on the $t^{\text{th}}$ round. The learner's goal is to design an online subset selection policy to maximize its expected cumulative reward accrued over a given time horizon. In this connection, we propose an online learning policy called SCore (Subset Selection with Core) that solves the problem for a large class of reward functions. The proposed SCore policy is based on a new concept of $\alpha$-Core, which is a generalization of the notion of Core from the cooperative game theory literature. We establish a learning guarantee for the SCore policy in terms of a new performance metric called $\alpha$-augmented regret. In this new metric, the power of the offline benchmark is suitably augmented compared to the online policy. We give several illustrative examples to show that a broad class of reward functions, including submodular, can be efficiently learned with the SCore policy. We also outline how the SCore policy can be used under a semi-bandit feedback model and conclude the paper with a number of open problems.
Optimistic No-regret Algorithms for Discrete Caching
Aug 15, 2022
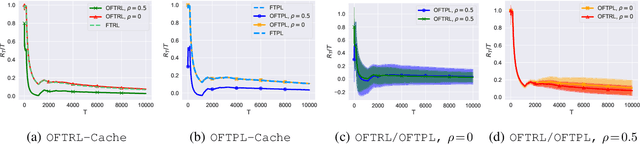

We take a systematic look at the problem of storing whole files in a cache with limited capacity in the context of optimistic learning, where the caching policy has access to a prediction oracle (provided by, e.g., a Neural Network). The successive file requests are assumed to be generated by an adversary, and no assumption is made on the accuracy of the oracle. In this setting, we provide a universal lower bound for prediction-assisted online caching and proceed to design a suite of policies with a range of performance-complexity trade-offs. All proposed policies offer sublinear regret bounds commensurate with the accuracy of the oracle. Our results substantially improve upon all recently-proposed online caching policies, which, being unable to exploit the oracle predictions, offer only $O(\sqrt{T})$ regret. In this pursuit, we design, to the best of our knowledge, the first comprehensive optimistic Follow-the-Perturbed leader policy, which generalizes beyond the caching problem. We also study the problem of caching files with different sizes and the bipartite network caching problem. Finally, we evaluate the efficacy of the proposed policies through extensive numerical experiments using real-world traces.
Universal Caching
May 10, 2022
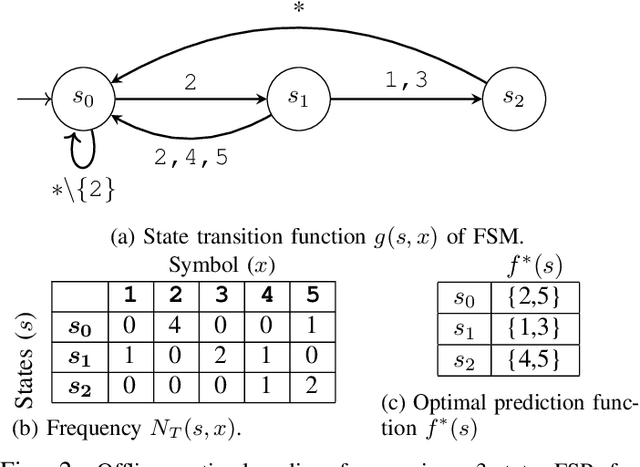
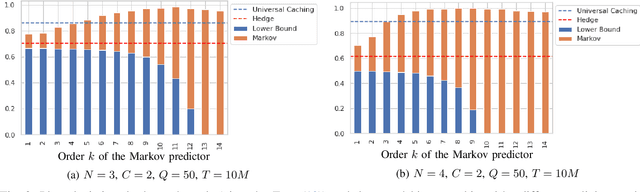
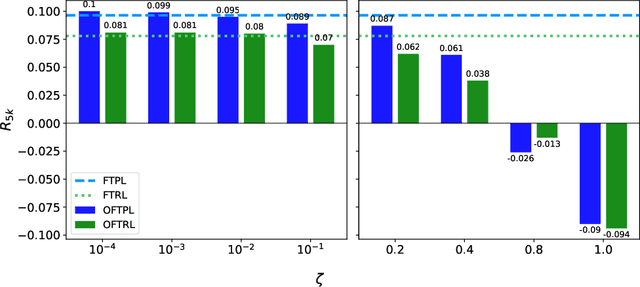
In the learning literature, the performance of an online policy is commonly measured in terms of the static regret metric, which compares the cumulative loss of an online policy to that of an optimal benchmark in hindsight. In the definition of static regret, the benchmark policy remains fixed throughout the time horizon. Naturally, the resulting regret bounds become loose in non-stationary settings where fixed benchmarks often suffer from poor performance. In this paper, we investigate a stronger notion of regret minimization in the context of an online caching problem. In particular, we allow the action of the offline benchmark at any round to be decided by a finite state predictor containing arbitrarily many states. Using ideas from the universal prediction literature in information theory, we propose an efficient online caching policy with an adaptive sub-linear regret bound. To the best of our knowledge, this is the first data-dependent regret bound known for the universal caching problem. We establish this result by combining a recently-proposed online caching policy with an incremental parsing algorithm, e.g., Lempel-Ziv '78. Our methods also yield a simpler learning-theoretic proof of the improved regret bound as opposed to the more involved and problem-specific combinatorial arguments used in the earlier works.
$k\texttt{-experts}$ -- Online Policies and Fundamental Limits
Oct 15, 2021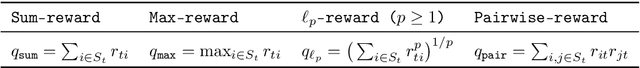
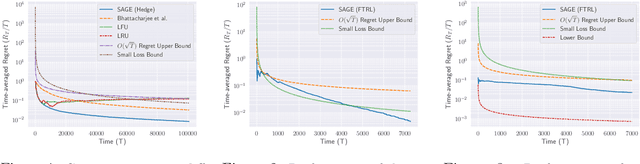

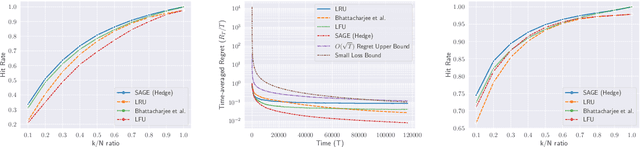
This paper introduces and studies the $k\texttt{-experts}$ problem -- a generalization of the classic Prediction with Expert's Advice (i.e., the $\texttt{Experts}$) problem. Unlike the $\texttt{Experts}$ problem, where the learner chooses exactly one expert, in this problem, the learner selects a subset of $k$ experts from a pool of $N$ experts at each round. The reward obtained by the learner at any round depends on the rewards of the selected experts. The $k\texttt{-experts}$ problem arises in many practical settings, including online ad placements, personalized news recommendations, and paging. Our primary goal is to design an online learning policy having a small regret. In this pursuit, we propose $\texttt{SAGE}$ ($\textbf{Sa}$mpled Hed$\textbf{ge}$) - a framework for designing efficient online learning policies by leveraging statistical sampling techniques. We show that, for many related problems, $\texttt{SAGE}$ improves upon the state-of-the-art bounds for regret and computational complexity. Furthermore, going beyond the notion of regret, we characterize the mistake bounds achievable by online learning policies for a class of stable loss functions. We conclude the paper by establishing a tight regret lower bound for a variant of the $k\texttt{-experts}$ problem and carrying out experiments with standard datasets.
D2C: Diffusion-Denoising Models for Few-shot Conditional Generation
Jun 12, 2021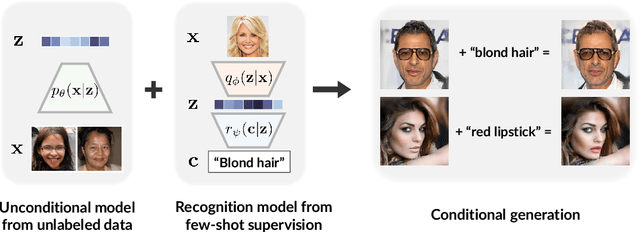
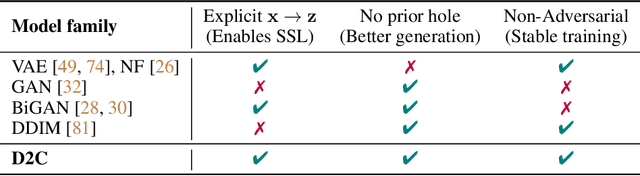
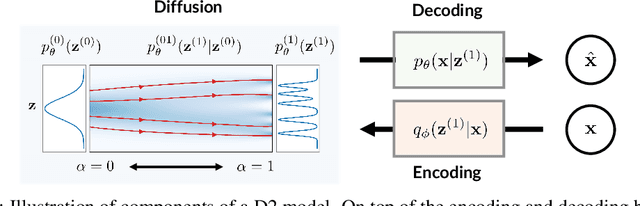
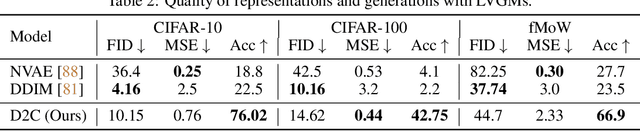
Conditional generative models of high-dimensional images have many applications, but supervision signals from conditions to images can be expensive to acquire. This paper describes Diffusion-Decoding models with Contrastive representations (D2C), a paradigm for training unconditional variational autoencoders (VAEs) for few-shot conditional image generation. D2C uses a learned diffusion-based prior over the latent representations to improve generation and contrastive self-supervised learning to improve representation quality. D2C can adapt to novel generation tasks conditioned on labels or manipulation constraints, by learning from as few as 100 labeled examples. On conditional generation from new labels, D2C achieves superior performance over state-of-the-art VAEs and diffusion models. On conditional image manipulation, D2C generations are two orders of magnitude faster to produce over StyleGAN2 ones and are preferred by 50% - 60% of the human evaluators in a double-blind study.