 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributionally Robust Post-hoc Classifiers under Prior Shifts
Sep 16, 2023The generalization ability of machine learning models degrades significantly when the test distribution shifts away from the training distribution. We investigate the problem of training models that are robust to shifts caused by changes in the distribution of class-priors or group-priors. The presence of skewed training priors can often lead to the models overfitting to spurious features. Unlike existing methods, which optimize for either the worst or the average performance over classes or groups, our work is motivated by the need for finer control over the robustness properties of the model. We present an extremely lightweight post-hoc approach that performs scaling adjustments to predictions from a pre-trained model, with the goal of minimizing a distributionally robust loss around a chosen target distribution. These adjustments are computed by solving a constrained optimization problem on a validation set and applied to the model during test time. Our constrained optimization objective is inspired by a natural notion of robustness to controlled distribution shifts. Our method comes with provable guarantees and empirically makes a strong case for distributional robust post-hoc classifiers. An empirical implementation is available at https://github.com/weijiaheng/Drops.
Towards Last-layer Retraining for Group Robustness with Fewer Annotations
Sep 15, 2023Empirical risk minimization (ERM) of neural networks is prone to over-reliance on spurious correlations and poor generalization on minority groups. The recent deep feature reweighting (DFR) technique achieves state-of-the-art group robustness via simple last-layer retraining, but it requires held-out group and class annotations to construct a group-balanced reweighting dataset. In this work, we examine this impractical requirement and find that last-layer retraining can be surprisingly effective with no group annotations (other than for model selection) and only a handful of class annotations. We first show that last-layer retraining can greatly improve worst-group accuracy even when the reweighting dataset has only a small proportion of worst-group data. This implies a "free lunch" where holding out a subset of training data to retrain the last layer can substantially outperform ERM on the entire dataset with no additional data or annotations. To further improve group robustness, we introduce a lightweight method called selective last-layer finetuning (SELF), which constructs the reweighting dataset using misclassifications or disagreements. Our empirical and theoretical results present the first evidence that model disagreement upsamples worst-group data, enabling SELF to nearly match DFR on four well-established benchmarks across vision and language tasks with no group annotations and less than 3% of the held-out class annotations. Our code is available at https://github.com/tmlabonte/last-layer-retraining.
Learnable Digital Twin for Efficient Wireless Network Evaluation
Jun 11, 2023Network digital twins (NDTs) facilitate the estimation of key performance indicators (KPIs) before physically implementing a network, thereby enabling efficient optimization of the network configuration. In this paper, we propose a learning-based NDT for network simulators. The proposed method offers a holistic representation of information flow in a wireless network by integrating node, edge, and path embeddings. Through this approach, the model is trained to map the network configuration to KPIs in a single forward pass. Hence, it offers a more efficient alternative to traditional simulation-based methods, thus allowing for rapid experimentation and optimization. Our proposed method has been extensively tested through comprehensive experimentation in various scenarios, including wired and wireless networks. Results show that it outperforms baseline learning models in terms of accuracy and robustness. Moreover, our approach achieves comparable performance to simulators but with significantly higher computational efficiency.
Understanding the Effectiveness of Early Weight Averaging for Training Large Language Models
Jun 05, 2023Training LLMs is expensive, and recent evidence indicates training all the way to convergence is inefficient. In this paper, we investigate the ability of a simple idea, checkpoint averaging along the trajectory of a training run to improve the quality of models before they have converged. This approach incurs no extra cost during training or inference. Specifically, we analyze the training trajectories of Pythia LLMs with 1 to 12 billion parameters and demonstrate that, particularly during the early to mid stages of training, this idea accelerates convergence and improves both test and zero-shot generalization. Loss spikes are a well recognized problem in LLM training; in our analysis we encountered two instances of this in the underlying trajectories, and both instances were mitigated by our averaging. For a 6.9B parameter LLM, for example, our early weight averaging recipe can save upto 4200 hours of GPU time, which corresponds to significant savings in cloud compute costs.
UAVSNet: An Encoder-Decoder Architecture based UAV Image Segmentation Network
Feb 25, 2023Due to an increased application of Unmanned Aerial Vehicle (UAV) devices like drones, segmentation of aerial images for urban scene understanding has brought a new research opportunity. Aerial images own so much variability in scale, object appearance, and complex background. The task of semantic segmentation when capturing the underlying features in a global and local context for the UAV images becomes challenging. In this work, we proposed a UAV Segmentation Network (UAVSNet) for precise semantic segmentation of urban aerial scenes. It is a transformer-based encoder-decoder framework that uses multi-scale feature representations. The UAVSNet exploits the advantage of a self-attention-based transformer framework and convolution mechanisms in capturing the global and local context details. This helps the network precisely capture the inherent feature of the aerial images and generate overall semantically rich feature representation. The proposed Overlap Token Embedding (OTE) module generates multi-scale features. A decoder network is proposed, which further processes these features using a multi-scale feature fusion policy to enhance the feature representation ability of the network. We show the effectiveness of the proposed network on UAVid and Urban drone datasets by achieving mIoU of 64.35% and 74.64%, respectively.
Rewarded meta-pruning: Meta Learning with Rewards for Channel Pruning
Jan 26, 2023Convolutional Neural Networks (CNNs) have a large number of parameters and take significantly large hardware resources to compute, so edge devices struggle to run high-level networks. This paper proposes a novel method to reduce the parameters and FLOPs for computational efficiency in deep learning models. We introduce accuracy and efficiency coefficients to control the trade-off between the accuracy of the network and its computing efficiency. The proposed Rewarded meta-pruning algorithm trains a network to generate weights for a pruned model chosen based on the approximate parameters of the final model by controlling the interactions using a reward function. The reward function allows more control over the metrics of the final pruned model. Extensive experiments demonstrate superior performances of the proposed method over the state-of-the-art methods in pruning ResNet-50, MobileNetV1, and MobileNetV2 networks.
Score-based Causal Representation Learning with Interventions
Jan 19, 2023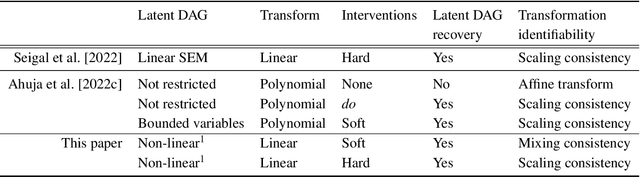
This paper studies causal representation learning problem when the latent causal variables are observed indirectly through an unknown linear transformation. The objectives are: (i) recovering the unknown linear transformation (up to scaling and ordering), and (ii) determining the directed acyclic graph (DAG) underlying the latent variables. Since identifiable representation learning is impossible based on only observational data, this paper uses both observational and interventional data. The interventional data is generated under distinct single-node randomized hard and soft interventions. These interventions are assumed to cover all nodes in the latent space. It is established that the latent DAG structure can be recovered under soft randomized interventions via the following two steps. First, a set of transformation candidates is formed by including all inverting transformations corresponding to which the \emph{score} function of the transformed variables has the minimal number of coordinates that change between an interventional and the observational environment summed over all pairs. Subsequently, this set is distilled using a simple constraint to recover the latent DAG structure. For the special case of hard randomized interventions, with an additional hypothesis testing step, one can also uniquely recover the linear transformation, up to scaling and a valid causal ordering. These results generalize the recent results that either assume deterministic hard interventions or linear causal relationships in the latent space.
Trial-Based Dominance Enables Non-Parametric Tests to Compare both the Speed and Accuracy of Stochastic Optimizers
Dec 19, 2022Non-parametric tests can determine the better of two stochastic optimization algorithms when benchmarking results are ordinal, like the final fitness values of multiple trials. For many benchmarks, however, a trial can also terminate once it reaches a pre-specified target value. When only some trials reach the target value, two variables characterize a trial's outcome: the time it takes to reach the target value (or not) and its final fitness value. This paper describes a simple way to impose linear order on this two-variable trial data set so that traditional non-parametric methods can determine the better algorithm when neither dominates. We illustrate the method with the Mann-Whitney U-test. A simulation demonstrates that U-scores are much more effective than dominance when tasked with identifying the better of two algorithms. We test U-scores by having them determine the winners of the CEC 2022 Special Session and Competition on Real-Parameter Numerical Optimization.
To Aggregate or Not? Learning with Separate Noisy Labels
Jun 14, 2022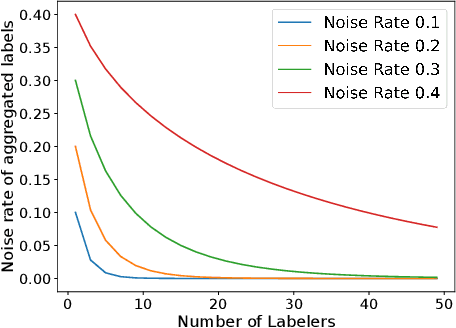
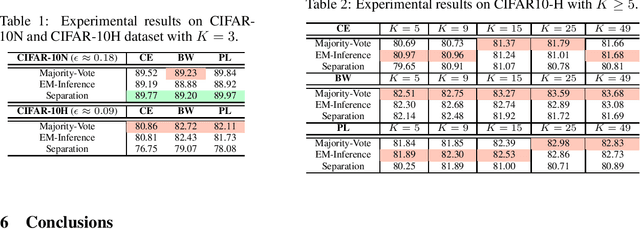
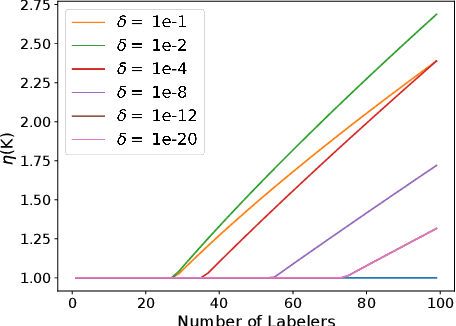
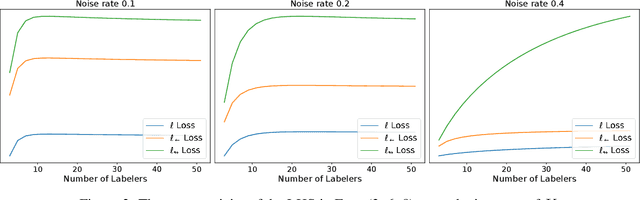
The rawly collected training data often comes with separate noisy labels collected from multiple imperfect annotators (e.g., via crowdsourcing). Typically one would first aggregate the separate noisy labels into one and apply standard training methods. The literature has also studied extensively on effective aggregation approaches. This paper revisits this choice and aims to provide an answer to the question of whether one should aggregate separate noisy labels into single ones or use them separately as given. We theoretically analyze the performance of both approaches under the empirical risk minimization framework for a number of popular loss functions, including the ones designed specifically for the problem of learning with noisy labels. Our theorems conclude that label separation is preferred over label aggregation when the noise rates are high, or the number of labelers/annotations is insufficient. Extensive empirical results validate our conclusion.
GridShift: A Faster Mode-seeking Algorithm for Image Segmentation and Object Tracking
Jun 05, 2022
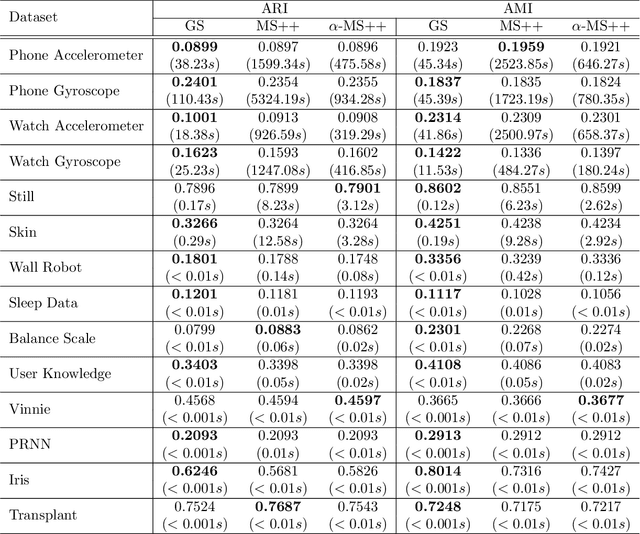
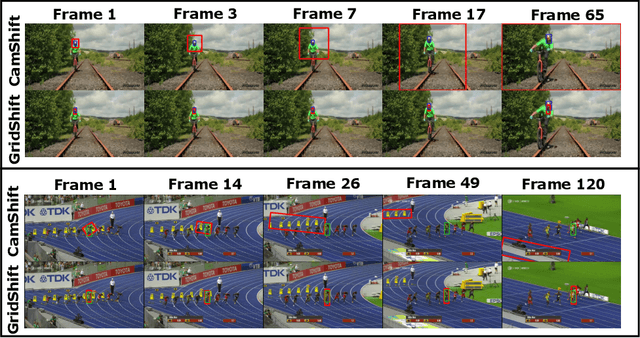
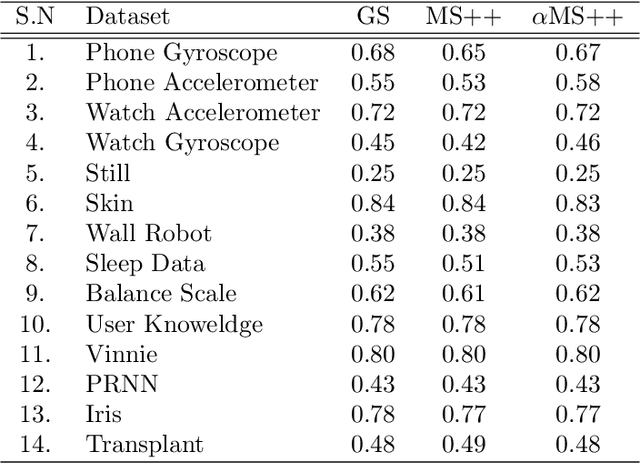
In machine learning and computer vision, mean shift (MS) qualifies as one of the most popular mode-seeking algorithms used for clustering and image segmentation. It iteratively moves each data point to the weighted mean of its neighborhood data points. The computational cost required to find the neighbors of each data point is quadratic to the number of data points. Consequently, the vanilla MS appears to be very slow for large-scale datasets. To address this issue, we propose a mode-seeking algorithm called GridShift, with significant speedup and principally based on MS. To accelerate, GridShift employs a grid-based approach for neighbor search, which is linear in the number of data points. In addition, GridShift moves the active grid cells (grid cells associated with at least one data point) in place of data points towards the higher density, a step that provides more speedup. The runtime of GridShift is linear in the number of active grid cells and exponential in the number of features. Therefore, it is ideal for large-scale low-dimensional applications such as object tracking and image segmentation. Through extensive experiments, we showcase the superior performance of GridShift compared to other MS-based as well as state-of-the-art algorithms in terms of accuracy and runtime on benchmark datasets for image segmentation. Finally, we provide a new object-tracking algorithm based on GridShift and show promising results for object tracking compared to CamShift and meanshift++.