 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Post-training of LLMs for Code Generation With Offline Reinforcement Learning
May 27, 2026Post-training using online reinforcement learning (RL) is an important training step for LLMs, including code-generating models. However, online RL for code generation involves LLM inference and verification of the generated output, which can take considerable time and resources. In this paper, we explore the application of offline RL to code-generating models by leveraging existing code datasets. Our experiments demonstrate that offline RL is an effective training strategy for improving LLM performance. We show that offline RL can be especially beneficial for small LLMs and challenging coding problems.
Domain-Adaptable Reinforcement Learning for Code Generation with Dense Rewards
May 20, 2026Large language models show strong potential for automated code generation, but lack guarantees for correctness, quality, safety, and domain-specific constraints. For instance in robotics, where code generation is increasingly being used for planning and executing actions, awareness of the environment and physical constraints is critical. To facilitate the adaption of code-generating LLMs to diverse requirements, including domain-specific ones, we present a reinforcement learning framework that fine-tunes pre-trained LLMs using proximal policy optimization. Our customizable execution-aware reward formula captures and optimizes syntax, functional correctness, code style, security, and simulator executability. A token-level reward mapping mechanism enables effective credit assignment from execution outcomes to generated tokens. The framework is evaluated on general-purpose code generation (MBPP/MBPP+) and robotic program synthesis (RoboEval). The results show substantial improvements in functional correctness and simulator executability, including an absolute pass@1 increase of 19% on MBPP and a reduction in execution failures by 51% on RoboEval. These findings demonstrate that structured reinforcement learning can effectively align language models to correct program generation and domain-specific requirements.
Towards Understanding What State Space Models Learn About Code
Feb 06, 2026State Space Models (SSMs) have emerged as an efficient alternative to the transformer architecture. Recent studies show that SSMs can match or surpass Transformers on code understanding tasks, such as code retrieval, when trained under similar conditions. However, their internal mechanisms remain a black box. We present the first systematic analysis of what SSM-based code models actually learn and perform the first comparative analysis of SSM and Transformer-based code models. Our analysis reveals that SSMs outperform Transformers at capturing code syntax and semantics in pretraining but forgets certain syntactic and semantic relations during fine-tuning on task, especially when the task emphasizes short-range dependencies. To diagnose this, we introduce SSM-Interpret, a frequency-domain framework that exposes a spectral shift toward short-range dependencies during fine-tuning. Guided by these findings, we propose architectural modifications that significantly improve the performance of SSM-based code model, validating that our analysis directly enables better models.
Analysis of Long Range Dependency Understanding in State Space Models
Jan 19, 2026Although state-space models (SSMs) have demonstrated strong performance on long-sequence benchmarks, most research has emphasized predictive accuracy rather than interpretability. In this work, we present the first systematic kernel interpretability study of the diagonalized state-space model (S4D) trained on a real-world task (vulnerability detection in source code). Through time and frequency domain analysis of the S4D kernel, we show that the long-range modeling capability of S4D varies significantly under different model architectures, affecting model performance. For instance, we show that the depending on the architecture, S4D kernel can behave as low-pass, band-pass or high-pass filter. The insights from our analysis can guide future work in designing better S4D-based models.
BiGSCoder: State Space Model for Code Understanding
May 02, 2025We present BiGSCoder, a novel encoder-only bidirectional state-space model (SSM) featuring a gated architecture, pre-trained for code understanding on a code dataset using masked language modeling. Our work aims to systematically evaluate SSMs' capabilities in coding tasks compared to traditional transformer architectures; BiGSCoder is built for this purpose. Through comprehensive experiments across diverse pre-training configurations and code understanding benchmarks, we demonstrate that BiGSCoder outperforms transformer-based models, despite utilizing simpler pre-training strategies and much less training data. Our results indicate that BiGSCoder can serve as a more sample-efficient alternative to conventional transformer models. Furthermore, our study shows that SSMs perform better without positional embeddings and can effectively extrapolate to longer sequences during fine-tuning.
Integrating Symbolic Execution into the Fine-Tuning of Code-Generating LLMs
Apr 21, 2025



Code-generating Large Language Models (LLMs) have become essential tools in modern software development, enhancing productivity and accelerating development. This paper aims to investigate the fine-tuning of code-generating LLMs using Reinforcement Learning and Direct Preference Optimization, further improving their performance. To achieve this, we enhance the training data for the reward model with the help of symbolic execution techniques, ensuring more comprehensive and objective data. With symbolic execution, we create a custom dataset that better captures the nuances in code evaluation. Our reward models, fine-tuned on this dataset, demonstrate significant improvements over the baseline, CodeRL, in estimating the quality of generated code. Our code-generating LLMs, trained with the help of reward model feedback, achieve similar results compared to the CodeRL benchmark.
A Critical Study of What Code-LLMs Learn
Jun 17, 2024Large Language Models trained on code corpora (code-LLMs) have demonstrated impressive performance in various coding assistance tasks. However, despite their increased size and training dataset, code-LLMs still have limitations such as suggesting codes with syntactic errors, variable misuse etc. Some studies argue that code-LLMs perform well on coding tasks because they use self-attention and hidden representations to encode relations among input tokens. However, previous works have not studied what code properties are not encoded by code-LLMs. In this paper, we conduct a fine-grained analysis of attention maps and hidden representations of code-LLMs. Our study indicates that code-LLMs only encode relations among specific subsets of input tokens. Specifically, by categorizing input tokens into syntactic tokens and identifiers, we found that models encode relations among syntactic tokens and among identifiers, but they fail to encode relations between syntactic tokens and identifiers. We also found that fine-tuned models encode these relations poorly compared to their pre-trained counterparts. Additionally, larger models with billions of parameters encode significantly less information about code than models with only a few hundred million parameters.
Hybrid ACO-CI Algorithm for Beam Design problems
Mar 29, 2023A range of complicated real-world problems have inspired the development of several optimization methods. Here, a novel hybrid version of the Ant colony optimization (ACO) method is developed using the sample space reduction technique of the Cohort Intelligence (CI) Algorithm. The algorithm is developed, and accuracy is tested by solving 35 standard benchmark test functions. Furthermore, the constrained version of the algorithm is used to solve two mechanical design problems involving stepped cantilever beams and I-section beams. The effectiveness of the proposed technique of solution is evaluated relative to contemporary algorithmic approaches that are already in use. The results show that our proposed hybrid ACO-CI algorithm will take lesser number of iterations to produce the desired output which means lesser computational time. For the minimization of weight of stepped cantilever beam and deflection in I-section beam a proposed hybrid ACO-CI algorithm yielded best results when compared to other existing algorithms. The proposed work could be investigate for variegated real world applications encompassing domains of engineering, combinatorial and health care problems.
Impact of Mobility on Downlink Cell-Free Massive MIMO Systems
Sep 06, 2022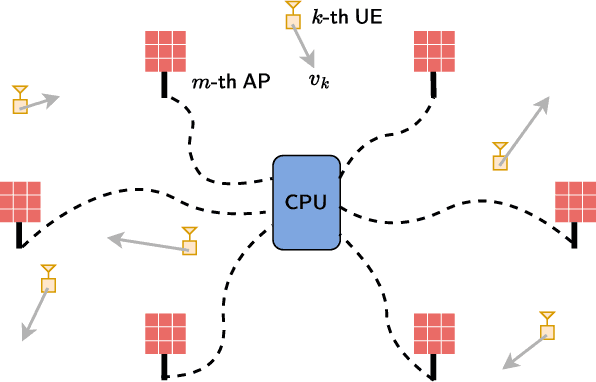

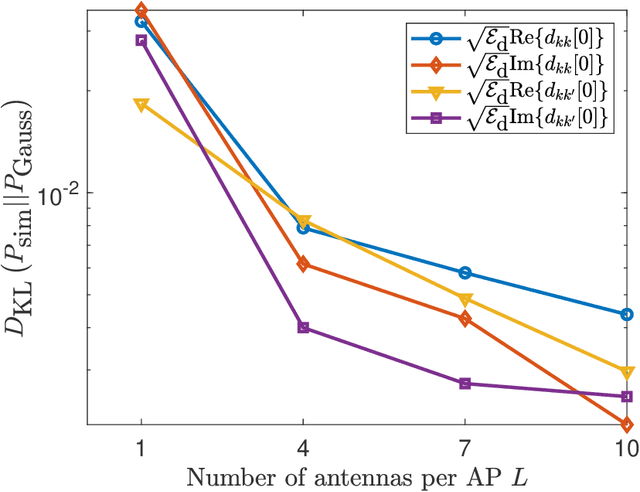
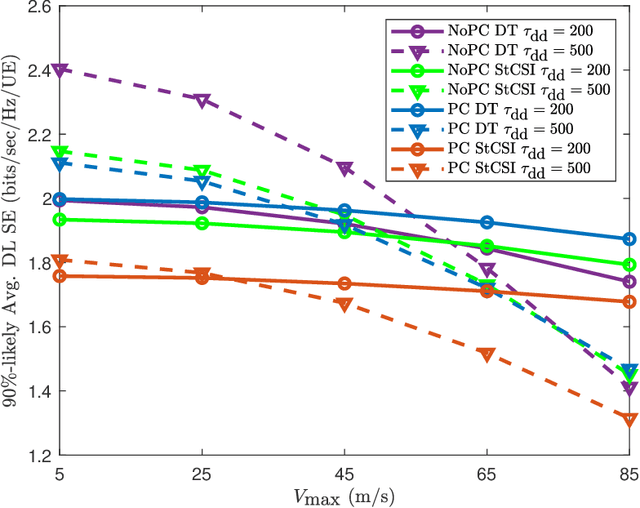
In this paper, we analyze the achievable downlink spectral efficiency of cell-free massive multiple input multiple output (CF-mMIMO) systems, accounting for the effects of channel aging (caused by user mobility) and pilot contamination. We consider two cases, one where user equipments (UEs) rely on downlink pilots beamformed by the access points (APs) to estimate downlink channel, and another where UEs utilize statistical channel state information (CSI) for data decoding. For comparison, we also consider cellular mMIMO and derive its achievable spectral efficiency with channel aging and pilot contamination in the above two cases. Our results show that, in CF-mMIMO, downlink training is preferable over statistical CSI when the length of the data sequence is chosen optimally to maximize the spectral efficiency. In cellular mMIMO, however, either one of the two schemes may be better depending on whether user fairness or sum spectral efficiency is prioritized. Furthermore, the CF-mMIMO system generally outperforms cellular mMIMO even after accounting for the effects of channel aging and pilot contamination. Through numerical results, we illustrate the effect of various system parameters such as the maximum user velocity, uplink/downlink pilot lengths, data duration, network densification, and provide interesting insights into the key differences between cell-free and cellular mMIMO systems.
Quantum compression with classically simulatable circuits
Jul 06, 2022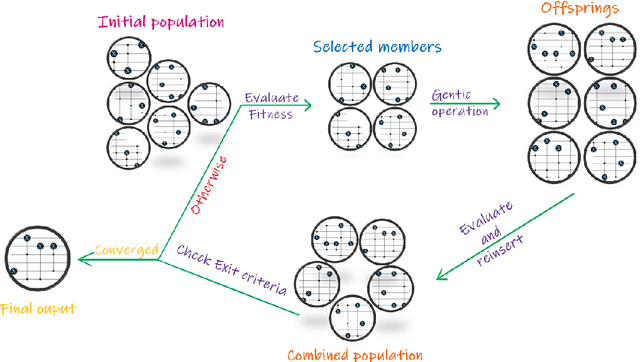
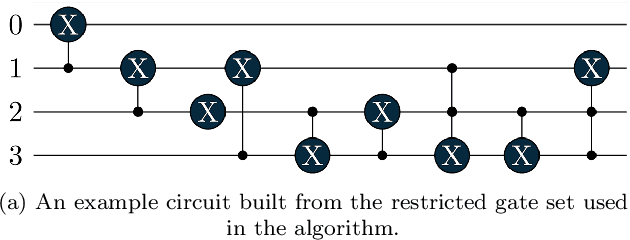
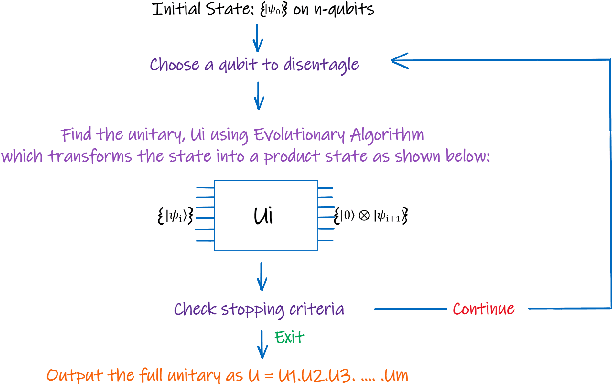
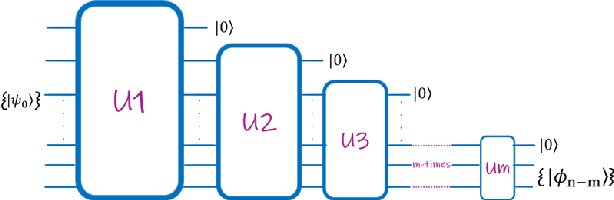
As we continue to find applications where the currently available noisy devices exhibit an advantage over their classical counterparts, the efficient use of quantum resources is highly desirable. The notion of quantum autoencoders was proposed as a way for the compression of quantum information to reduce resource requirements. Here, we present a strategy to design quantum autoencoders using evolutionary algorithms for transforming quantum information into lower-dimensional representations. We successfully demonstrate the initial applications of the algorithm for compressing different families of quantum states. In particular, we point out that using a restricted gate set in the algorithm allows for efficient simulation of the generated circuits. This approach opens the possibility of using classical logic to find low representations of quantum data, using fewer computational resources.