 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Adaptable Reinforcement Learning for Code Generation with Dense Rewards
May 20, 2026Large language models show strong potential for automated code generation, but lack guarantees for correctness, quality, safety, and domain-specific constraints. For instance in robotics, where code generation is increasingly being used for planning and executing actions, awareness of the environment and physical constraints is critical. To facilitate the adaption of code-generating LLMs to diverse requirements, including domain-specific ones, we present a reinforcement learning framework that fine-tunes pre-trained LLMs using proximal policy optimization. Our customizable execution-aware reward formula captures and optimizes syntax, functional correctness, code style, security, and simulator executability. A token-level reward mapping mechanism enables effective credit assignment from execution outcomes to generated tokens. The framework is evaluated on general-purpose code generation (MBPP/MBPP+) and robotic program synthesis (RoboEval). The results show substantial improvements in functional correctness and simulator executability, including an absolute pass@1 increase of 19% on MBPP and a reduction in execution failures by 51% on RoboEval. These findings demonstrate that structured reinforcement learning can effectively align language models to correct program generation and domain-specific requirements.
StyleMC: Multi-Channel Based Fast Text-Guided Image Generation and Manipulation
Dec 15, 2021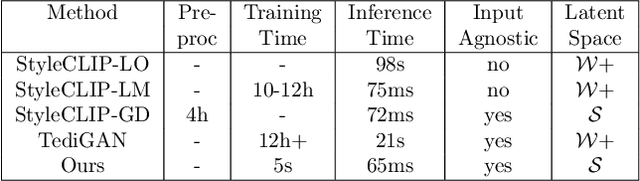
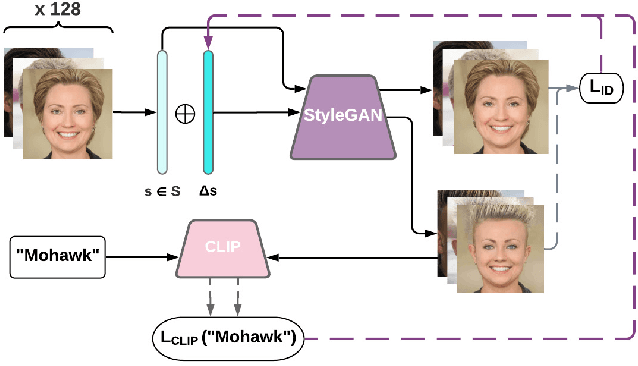


Discovering meaningful directions in the latent space of GANs to manipulate semantic attributes typically requires large amounts of labeled data. Recent work aims to overcome this limitation by leveraging the power of Contrastive Language-Image Pre-training (CLIP), a joint text-image model. While promising, these methods require several hours of preprocessing or training to achieve the desired manipulations. In this paper, we present StyleMC, a fast and efficient method for text-driven image generation and manipulation. StyleMC uses a CLIP-based loss and an identity loss to manipulate images via a single text prompt without significantly affecting other attributes. Unlike prior work, StyleMC requires only a few seconds of training per text prompt to find stable global directions, does not require prompt engineering and can be used with any pre-trained StyleGAN2 model. We demonstrate the effectiveness of our method and compare it to state-of-the-art methods. Our code can be found at http://catlab-team.github.io/stylemc.