 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemeSequencer: Sparse Matching for Embedding Image Macros
Feb 14, 2018
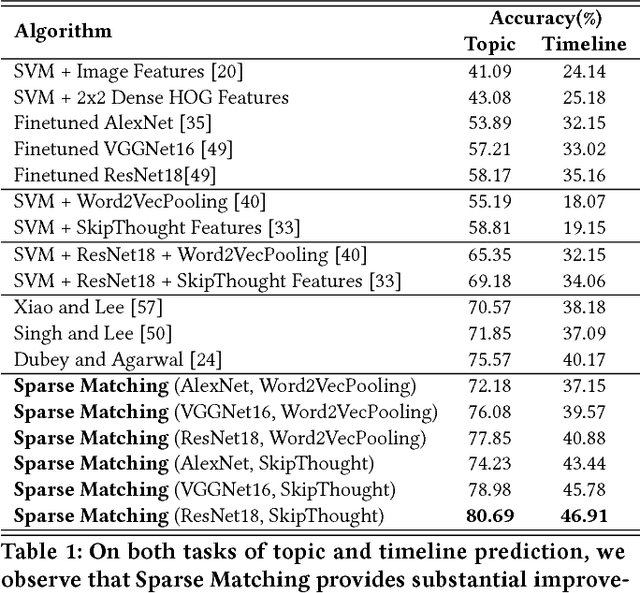

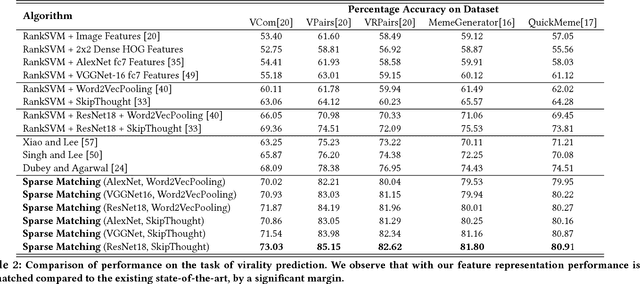
The analysis of the creation, mutation, and propagation of social media content on the Internet is an essential problem in computational social science, affecting areas ranging from marketing to political mobilization. A first step towards understanding the evolution of images online is the analysis of rapidly modifying and propagating memetic imagery or `memes'. However, a pitfall in proceeding with such an investigation is the current incapability to produce a robust semantic space for such imagery, capable of understanding differences in Image Macros. In this study, we provide a first step in the systematic study of image evolution on the Internet, by proposing an algorithm based on sparse representations and deep learning to decouple various types of content in such images and produce a rich semantic embedding. We demonstrate the benefits of our approach on a variety of tasks pertaining to memes and Image Macros, such as image clustering, image retrieval, topic prediction and virality prediction, surpassing the existing methods on each. In addition to its utility on quantitative tasks, our method opens up the possibility of obtaining the first large-scale understanding of the evolution and propagation of memetic imagery.
Learning Neural Network Classifiers with Low Model Complexity
Jan 02, 2018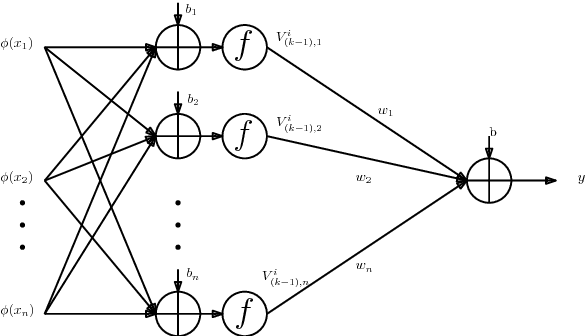


Modern neural network architectures for large-scale learning tasks have substantially higher model complexities, which makes understanding, visualizing and training these architectures difficult. Recent contributions to deep learning techniques have focused on architectural modifications to improve parameter efficiency and performance. In this paper, we derive a continuous and differentiable error functional for a neural network that minimizes its empirical error as well as a measure of the model complexity. The latter measure is obtained by deriving a differentiable upper bound on the Vapnik-Chervonenkis (VC) dimension of the classifier layer of a class of deep networks. Using standard backpropagation, we realize a training rule that tries to minimize the error on training samples, while improving generalization by keeping the model complexity low. We demonstrate the effectiveness of our formulation (the Low Complexity Neural Network - LCNN) across several deep learning algorithms, and a variety of large benchmark datasets. We show that hidden layer neurons in the resultant networks learn features that are crisp, and in the case of image datasets, quantitatively sharper. Our proposed approach yields benefits across a wide range of architectures, in comparison to and in conjunction with methods such as Dropout and Batch Normalization, and our results strongly suggest that deep learning techniques can benefit from model complexity control methods such as the LCNN learning rule.
Modeling Image Virality with Pairwise Spatial Transformer Networks
Sep 22, 2017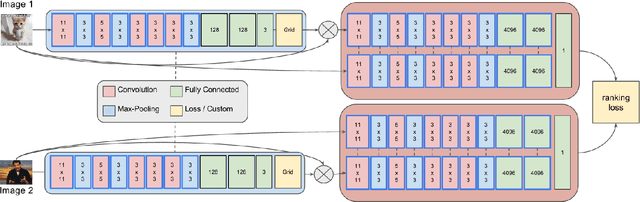
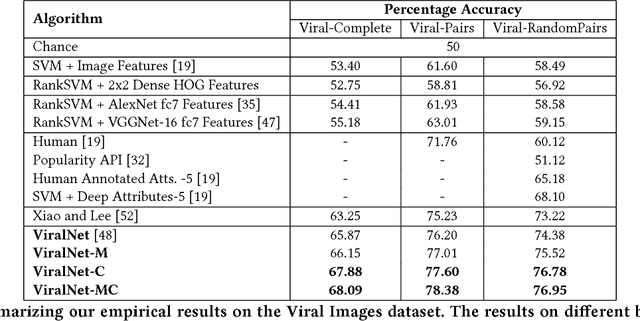
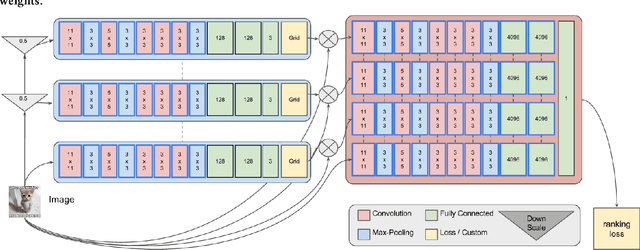
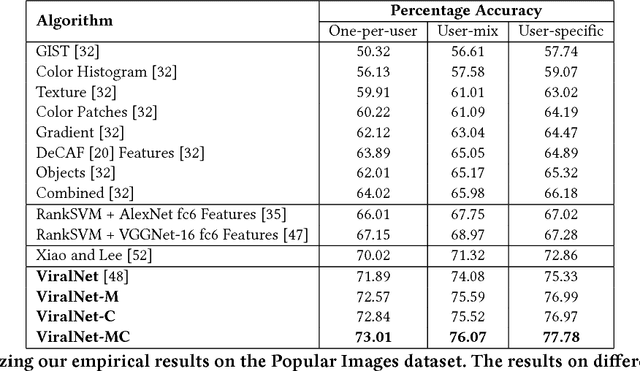
The study of virality and information diffusion online is a topic gaining traction rapidly in the computational social sciences. Computer vision and social network analysis research have also focused on understanding the impact of content and information diffusion in making content viral, with prior approaches not performing significantly well as other traditional classification tasks. In this paper, we present a novel pairwise reformulation of the virality prediction problem as an attribute prediction task and develop a novel algorithm to model image virality on online media using a pairwise neural network. Our model provides significant insights into the features that are responsible for promoting virality and surpasses the existing state-of-the-art by a 12% average improvement in prediction. We also investigate the effect of external category supervision on relative attribute prediction and observe an increase in prediction accuracy for the same across several attribute learning datasets.
Examining Representational Similarity in ConvNets and the Primate Visual Cortex
Sep 12, 2016
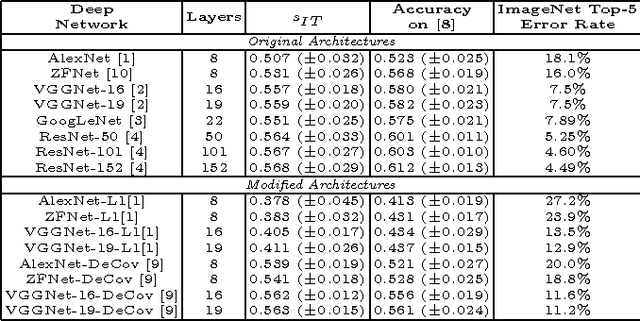
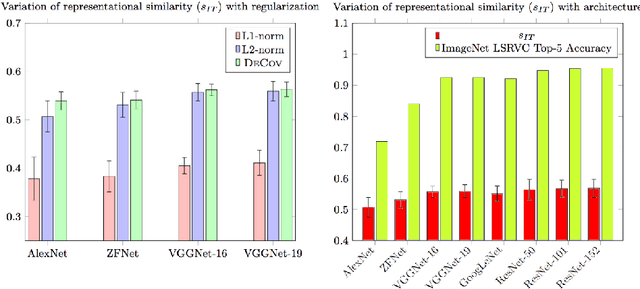
We compare several ConvNets with different depth and regularization techniques with multi-unit macaque IT cortex recordings and assess the impact of the same on representational similarity with the primate visual cortex. We find that with increasing depth and validation performance, ConvNet features are closer to cortical IT representations.
Deep Learning the City : Quantifying Urban Perception At A Global Scale
Sep 12, 2016
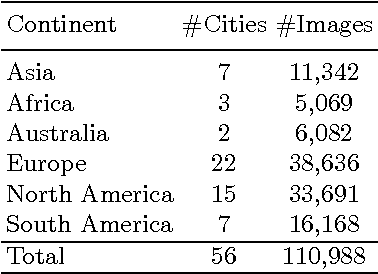
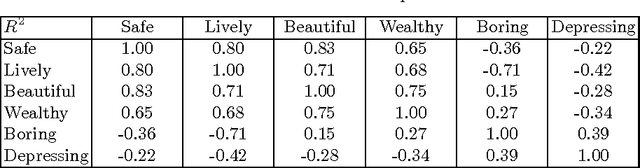
Computer vision methods that quantify the perception of urban environment are increasingly being used to study the relationship between a city's physical appearance and the behavior and health of its residents. Yet, the throughput of current methods is too limited to quantify the perception of cities across the world. To tackle this challenge, we introduce a new crowdsourced dataset containing 110,988 images from 56 cities, and 1,170,000 pairwise comparisons provided by 81,630 online volunteers along six perceptual attributes: safe, lively, boring, wealthy, depressing, and beautiful. Using this data, we train a Siamese-like convolutional neural architecture, which learns from a joint classification and ranking loss, to predict human judgments of pairwise image comparisons. Our results show that crowdsourcing combined with neural networks can produce urban perception data at the global scale.
Coreset-Based Adaptive Tracking
Nov 19, 2015
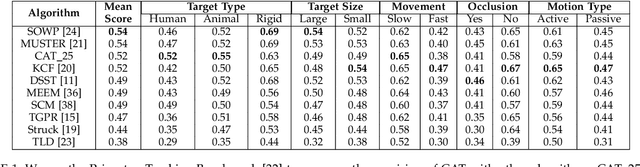
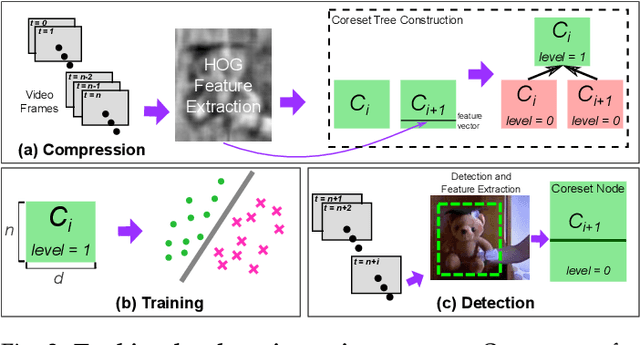
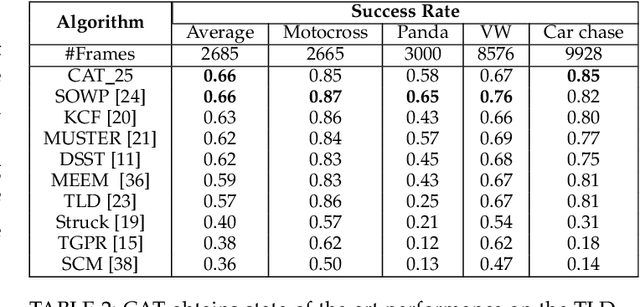
We propose a method for learning from streaming visual data using a compact, constant size representation of all the data that was seen until a given moment. Specifically, we construct a 'coreset' representation of streaming data using a parallelized algorithm, which is an approximation of a set with relation to the squared distances between this set and all other points in its ambient space. We learn an adaptive object appearance model from the coreset tree in constant time and logarithmic space and use it for object tracking by detection. Our method obtains excellent results for object tracking on three standard datasets over more than 100 videos. The ability to summarize data efficiently makes our method ideally suited for tracking in long videos in presence of space and time constraints. We demonstrate this ability by outperforming a variety of algorithms on the TLD dataset with 2685 frames on average. This coreset based learning approach can be applied for both real-time learning of small, varied data and fast learning of big data.