 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025



Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
RESTRAIN: Reinforcement Learning-Based Secure Framework for Trigger-Action IoT Environment
Mar 12, 2025Internet of Things (IoT) platforms with trigger-action capability allow event conditions to trigger actions in IoT devices autonomously by creating a chain of interactions. Adversaries exploit this chain of interactions to maliciously inject fake event conditions into IoT hubs, triggering unauthorized actions on target IoT devices to implement remote injection attacks. Existing defense mechanisms focus mainly on the verification of event transactions using physical event fingerprints to enforce the security policies to block unsafe event transactions. These approaches are designed to provide offline defense against injection attacks. The state-of-the-art online defense mechanisms offer real-time defense, but extensive reliability on the inference of attack impacts on the IoT network limits the generalization capability of these approaches. In this paper, we propose a platform-independent multi-agent online defense system, namely RESTRAIN, to counter remote injection attacks at runtime. RESTRAIN allows the defense agent to profile attack actions at runtime and leverages reinforcement learning to optimize a defense policy that complies with the security requirements of the IoT network. The experimental results show that the defense agent effectively takes real-time defense actions against complex and dynamic remote injection attacks and maximizes the security gain with minimal computational overhead.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.
How DREAMS are made: Emulating Satellite Galaxy and Subhalo Populations with Diffusion Models and Point Clouds
Sep 04, 2024



The connection between galaxies and their host dark matter (DM) halos is critical to our understanding of cosmology, galaxy formation, and DM physics. To maximize the return of upcoming cosmological surveys, we need an accurate way to model this complex relationship. Many techniques have been developed to model this connection, from Halo Occupation Distribution (HOD) to empirical and semi-analytic models to hydrodynamic. Hydrodynamic simulations can incorporate more detailed astrophysical processes but are computationally expensive; HODs, on the other hand, are computationally cheap but have limited accuracy. In this work, we present NeHOD, a generative framework based on variational diffusion model and Transformer, for painting galaxies/subhalos on top of DM with an accuracy of hydrodynamic simulations but at a computational cost similar to HOD. By modeling galaxies/subhalos as point clouds, instead of binning or voxelization, we can resolve small spatial scales down to the resolution of the simulations. For each halo, NeHOD predicts the positions, velocities, masses, and concentrations of its central and satellite galaxies. We train NeHOD on the TNG-Warm DM suite of the DREAMS project, which consists of 1024 high-resolution zoom-in hydrodynamic simulations of Milky Way-mass halos with varying warm DM mass and astrophysical parameters. We show that our model captures the complex relationships between subhalo properties as a function of the simulation parameters, including the mass functions, stellar-halo mass relations, concentration-mass relations, and spatial clustering. Our method can be used for a large variety of downstream applications, from galaxy clustering to strong lensing studies.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024



Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
MIA-BAD: An Approach for Enhancing Membership Inference Attack and its Mitigation with Federated Learning
Nov 28, 2023The membership inference attack (MIA) is a popular paradigm for compromising the privacy of a machine learning (ML) model. MIA exploits the natural inclination of ML models to overfit upon the training data. MIAs are trained to distinguish between training and testing prediction confidence to infer membership information. Federated Learning (FL) is a privacy-preserving ML paradigm that enables multiple clients to train a unified model without disclosing their private data. In this paper, we propose an enhanced Membership Inference Attack with the Batch-wise generated Attack Dataset (MIA-BAD), a modification to the MIA approach. We investigate that the MIA is more accurate when the attack dataset is generated batch-wise. This quantitatively decreases the attack dataset while qualitatively improving it. We show how training an ML model through FL, has some distinct advantages and investigate how the threat introduced with the proposed MIA-BAD approach can be mitigated with FL approaches. Finally, we demonstrate the qualitative effects of the proposed MIA-BAD methodology by conducting extensive experiments with various target datasets, variable numbers of federated clients, and training batch sizes.
Seven open problems in applied combinatorics
Mar 20, 2023



We present and discuss seven different open problems in applied combinatorics. The application areas relevant to this compilation include quantum computing, algorithmic differentiation, topological data analysis, iterative methods, hypergraph cut algorithms, and power systems.
Compressive Representations of Weather Scenes for Strategic Air Traffic Flow Management
Jul 02, 2021
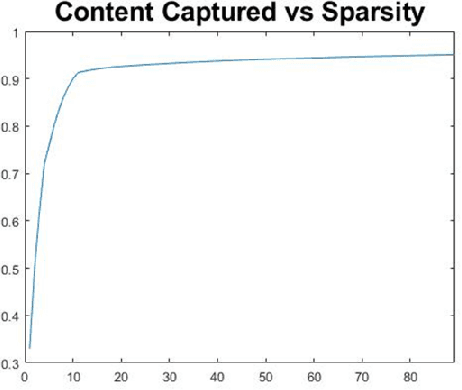
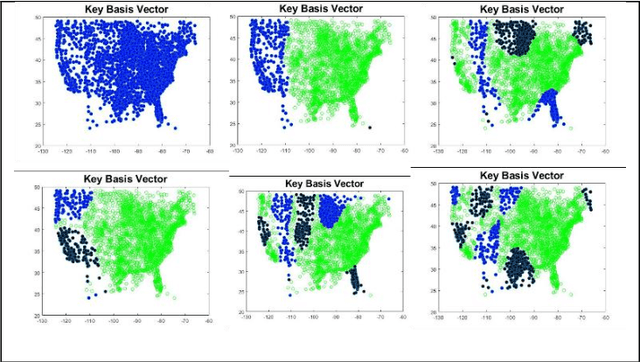
Terse representation of high-dimensional weather scene data is explored, in support of strategic air traffic flow management objectives. Specifically, we consider whether aviation-relevant weather scenes are compressible, in the sense that each scene admits a possibly-different sparse representation in a basis of interest. Here, compression of weather scenes extracted from METAR data (including temperature, flight categories, and visibility profiles for the contiguous United States) is examined, for the graph-spectral basis. The scenes are found to be compressible, with 75-95% of the scene content captured using 0.5-4% of the basis vectors. Further, the dominant basis vectors for each scene are seen to identify time-varying spatial characteristics of the weather, and reconstruction from the compressed representation is demonstrated. Finally, potential uses of the compressive representations in strategic TFM design are briefly scoped.
Compressibility of Network Opinion and Spread States in the Laplacian-Eigenvector Basis
Mar 28, 2021
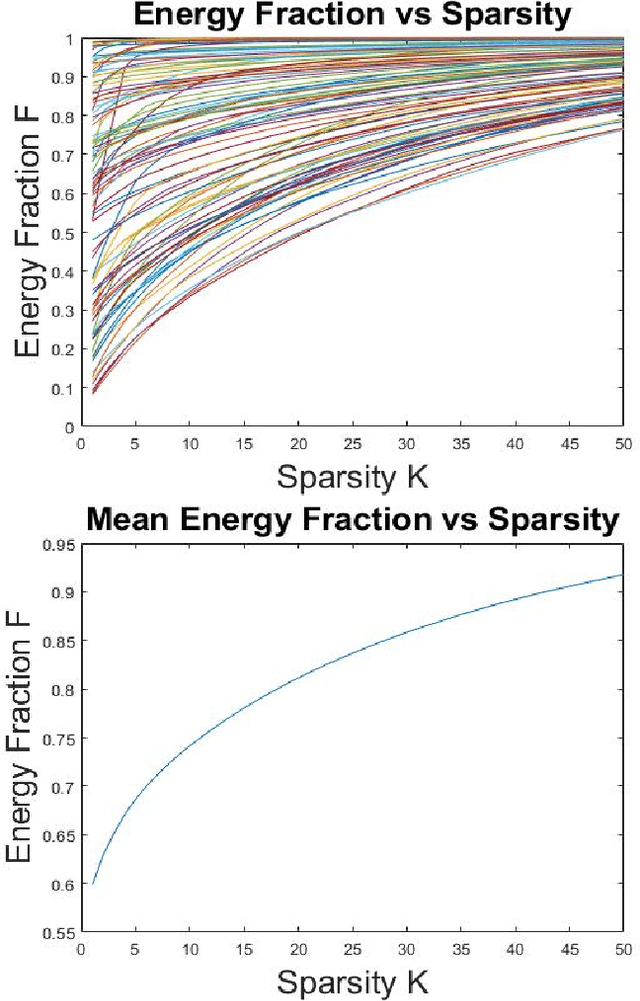
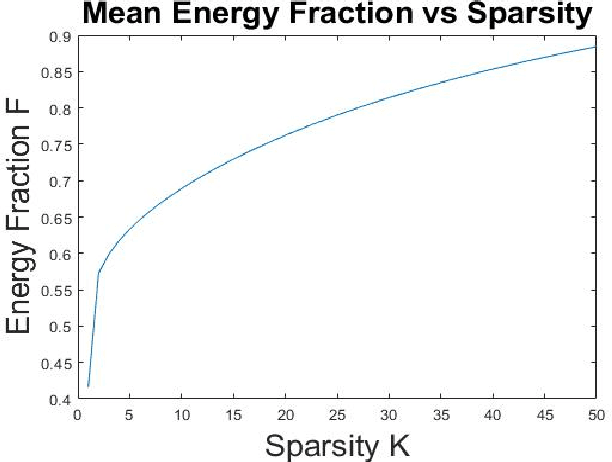
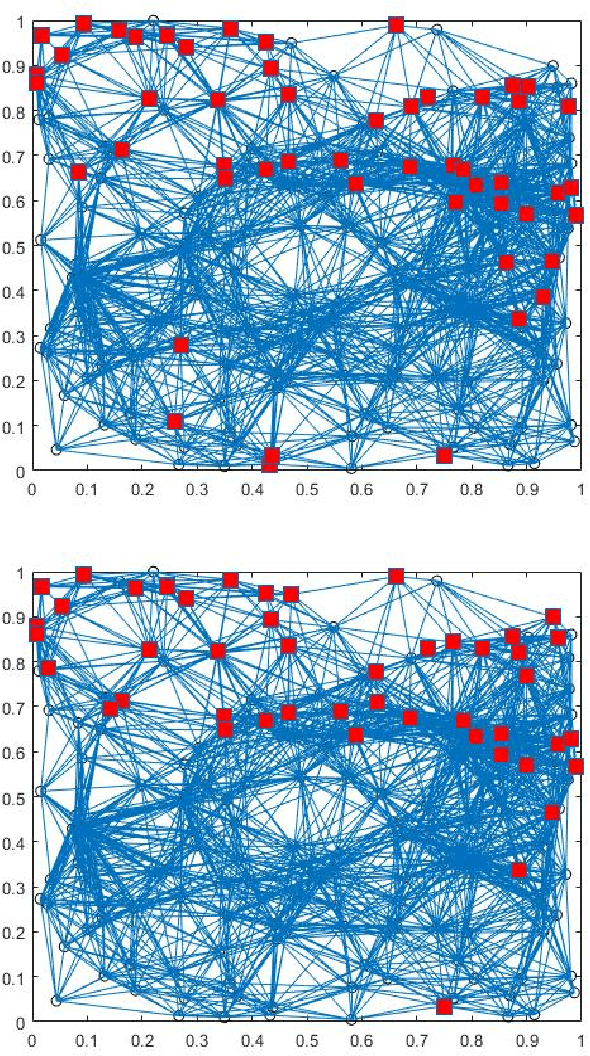
Opinion-evolution and spread processes on networks (e.g., infectious disease spread, opinion formation in social networks) are not only high dimensional but also volatile and multiscale in nature. In this study, we explore whether snapshot data from these processes can admit terse representations. Specifically, using three case studies, we explore whether the data are compressible in the Laplacian-eigenvector basis, in the sense that each snapshot can be approximated well using a (possibly different) small set of basis vectors. The first case study is concerned with a linear consensus model that is subject to a stochastic input at an unknown location; both empirical and formal analyses are used to characterize compressibility. Second, compressibility of state snapshots for a stochastic voter model is assessed via an empirical study. Finally, compressibility is studied for state-level daily COVID-19 positivity-rate data. The three case studies indicate that state snapshots from opinion-evolution and spread processes allow terse representations, which nevertheless capture their rich propagative dynamics.