 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEverything Is All It Takes: A Multipronged Strategy for Zero-Shot Cross-Lingual Information Extraction
Sep 14, 2021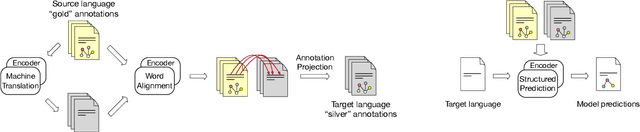

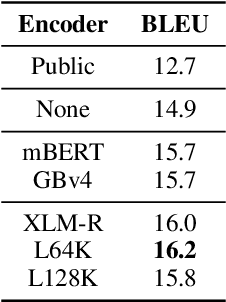
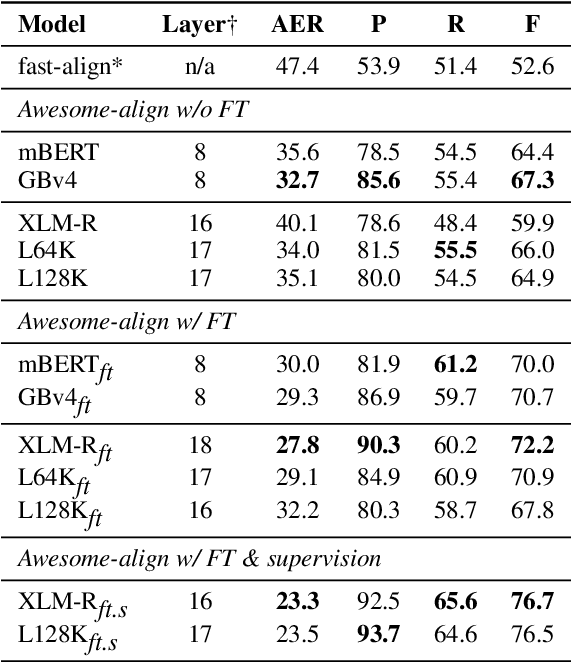
Zero-shot cross-lingual information extraction (IE) describes the construction of an IE model for some target language, given existing annotations exclusively in some other language, typically English. While the advance of pretrained multilingual encoders suggests an easy optimism of "train on English, run on any language", we find through a thorough exploration and extension of techniques that a combination of approaches, both new and old, leads to better performance than any one cross-lingual strategy in particular. We explore techniques including data projection and self-training, and how different pretrained encoders impact them. We use English-to-Arabic IE as our initial example, demonstrating strong performance in this setting for event extraction, named entity recognition, part-of-speech tagging, and dependency parsing. We then apply data projection and self-training to three tasks across eight target languages. Because no single set of techniques performs the best across all tasks, we encourage practitioners to explore various configurations of the techniques described in this work when seeking to improve on zero-shot training.
Joint Universal Syntactic and Semantic Parsing
Apr 12, 2021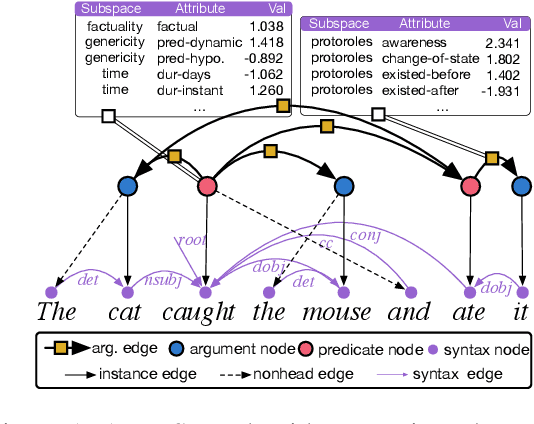
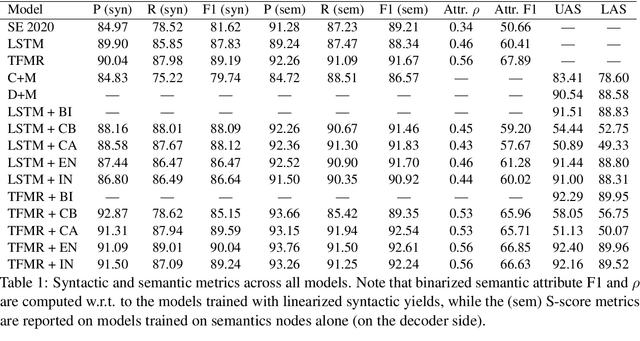
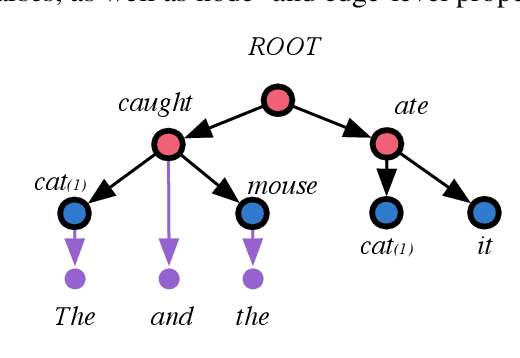
While numerous attempts have been made to jointly parse syntax and semantics, high performance in one domain typically comes at the price of performance in the other. This trade-off contradicts the large body of research focusing on the rich interactions at the syntax-semantics interface. We explore multiple model architectures which allow us to exploit the rich syntactic and semantic annotations contained in the Universal Decompositional Semantics (UDS) dataset, jointly parsing Universal Dependencies and UDS to obtain state-of-the-art results in both formalisms. We analyze the behaviour of a joint model of syntax and semantics, finding patterns supported by linguistic theory at the syntax-semantics interface. We then investigate to what degree joint modeling generalizes to a multilingual setting, where we find similar trends across 8 languages.
Decomposing and Recomposing Event Structure
Mar 18, 2021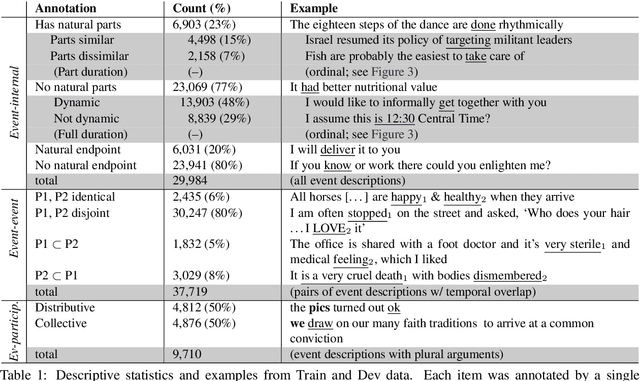
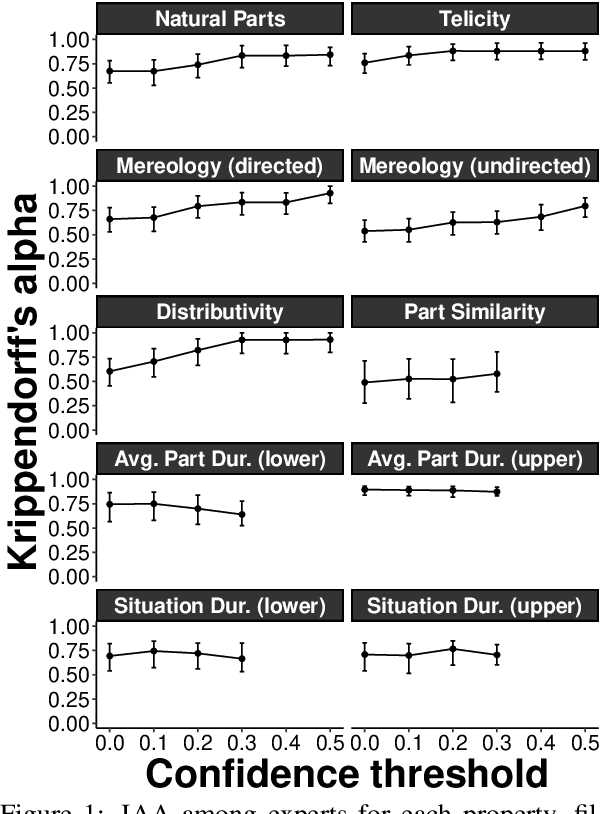
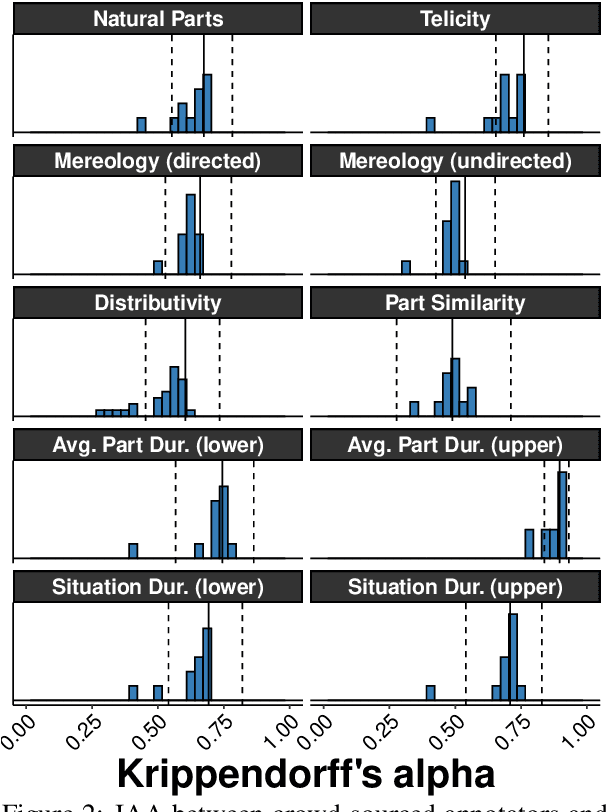
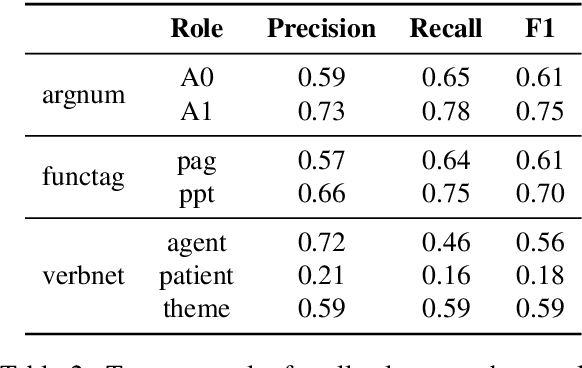
We present an event structure ontology empirically derived from inferential properties annotated on sentence- and document-level semantic graphs. We induce this ontology jointly with semantic role, entity type, and event-event relation ontologies using a document-level generative model, identifying sets of types that align closely with previous theoretically-motivated taxonomies.
Gradual Fine-Tuning for Low-Resource Domain Adaptation
Mar 03, 2021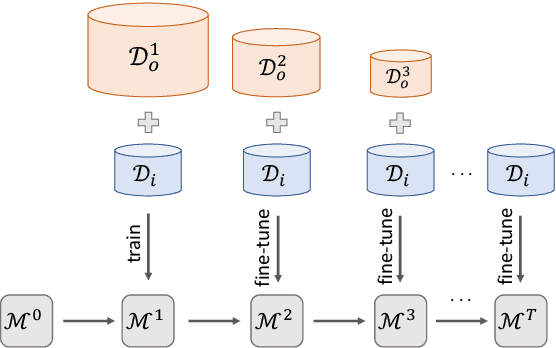
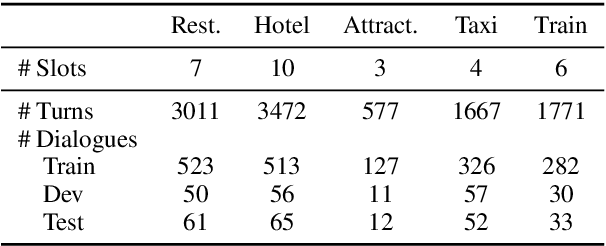
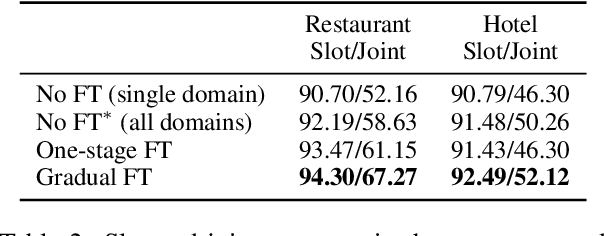
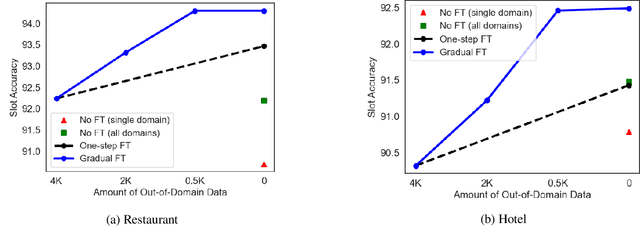
Fine-tuning is known to improve NLP models by adapting an initial model trained on more plentiful but less domain-salient examples to data in a target domain. Such domain adaptation is typically done using one stage of fine-tuning. We demonstrate that gradually fine-tuning in a multi-stage process can yield substantial further gains and can be applied without modifying the model or learning objective.
LOME: Large Ontology Multilingual Extraction
Jan 28, 2021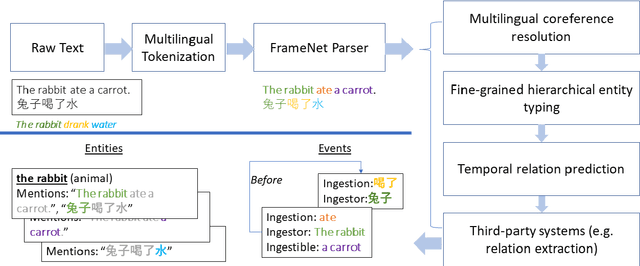
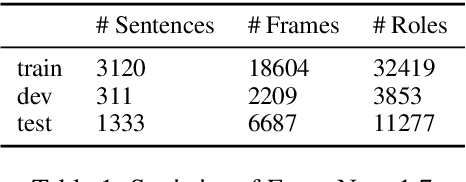
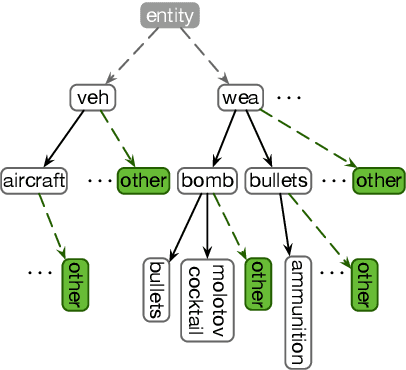
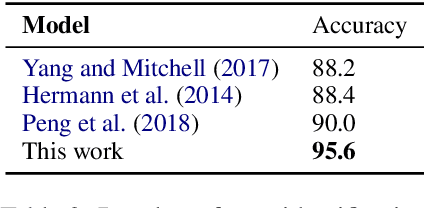
We present LOME, a system for performing multilingual information extraction. Given a text document as input, our core system identifies spans of textual entity and event mentions with a FrameNet (Baker et al., 1998) parser. It subsequently performs coreference resolution, fine-grained entity typing, and temporal relation prediction between events. By doing so, the system constructs an event and entity focused knowledge graph. We can further apply third-party modules for other types of annotation, like relation extraction. Our (multilingual) first-party modules either outperform or are competitive with the (monolingual) state-of-the-art. We achieve this through the use of multilingual encoders like XLM-R (Conneau et al., 2020) and leveraging multilingual training data. LOME is available as a Docker container on Docker Hub. In addition, a lightweight version of the system is accessible as a web demo.
Natural Language Inference with Mixed Effects
Oct 20, 2020
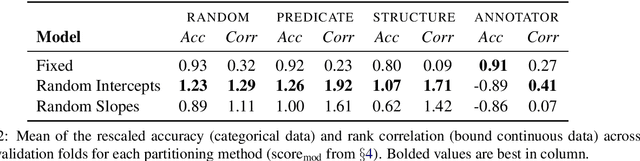
There is growing evidence that the prevalence of disagreement in the raw annotations used to construct natural language inference datasets makes the common practice of aggregating those annotations to a single label problematic. We propose a generic method that allows one to skip the aggregation step and train on the raw annotations directly without subjecting the model to unwanted noise that can arise from annotator response biases. We demonstrate that this method, which generalizes the notion of a \textit{mixed effects model} by incorporating \textit{annotator random effects} into any existing neural model, improves performance over models that do not incorporate such effects.
Montague Grammar Induction
Oct 15, 2020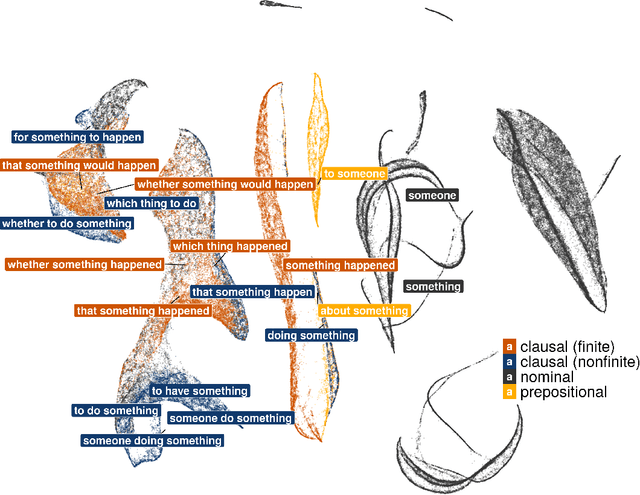
We propose a computational modeling framework for inducing combinatory categorial grammars from arbitrary behavioral data. This framework provides the analyst fine-grained control over the assumptions that the induced grammar should conform to: (i) what the primitive types are; (ii) how complex types are constructed; (iii) what set of combinators can be used to combine types; and (iv) whether (and to what) the types of some lexical items should be fixed. In a proof-of-concept experiment, we deploy our framework for use in distributional analysis. We focus on the relationship between s(emantic)-selection and c(ategory)-selection, using as input a lexicon-scale acceptability judgment dataset focused on English verbs' syntactic distribution (the MegaAcceptability dataset) and enforcing standard assumptions from the semantics literature on the induced grammar.
Frequency, Acceptability, and Selection: A case study of clause-embedding
Apr 08, 2020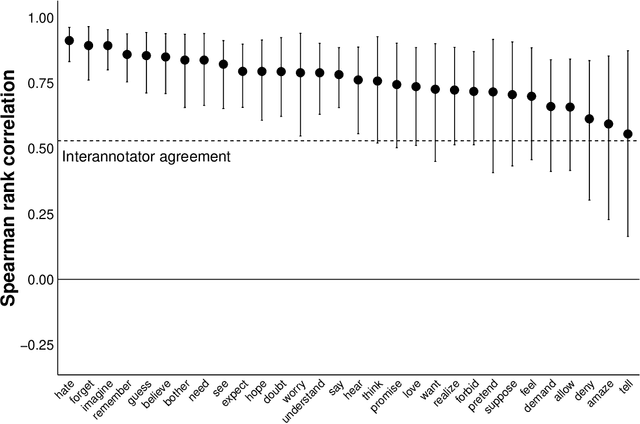
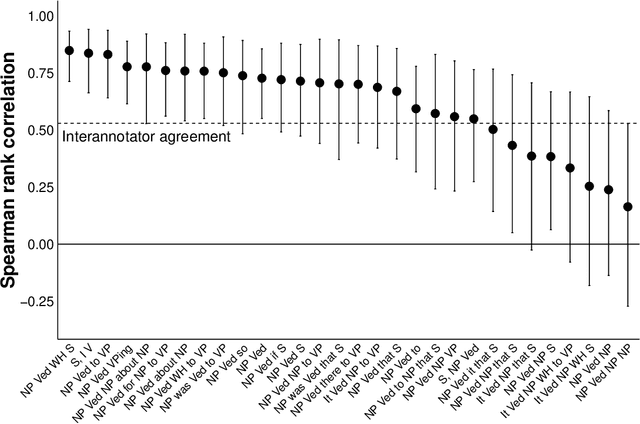


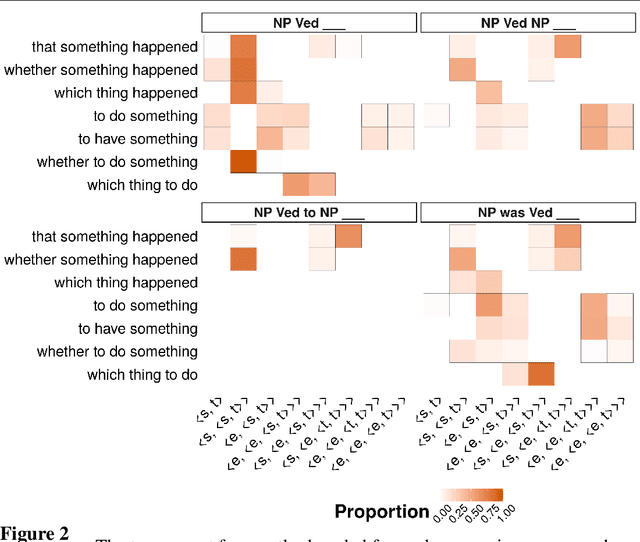
We investigate the relationship between the frequency with which verbs are found in particular subcategorization frames and the acceptability of those verbs in those frames, focusing in particular on subordinate clause-taking verbs, such as "think", "want", and "tell". We show that verbs' subcategorization frame frequency distributions are poor predictors of their acceptability in those frames---explaining, at best, less than 1/3 of the total information about acceptability across the lexicon---and, further, that common matrix factorization techniques used to model the acquisition of verbs' acceptability in subcategorization frames fare only marginally better. All data and code are available at http://megaattitude.io.
Transductive Parsing for Universal Decompositional Semantics
Oct 23, 2019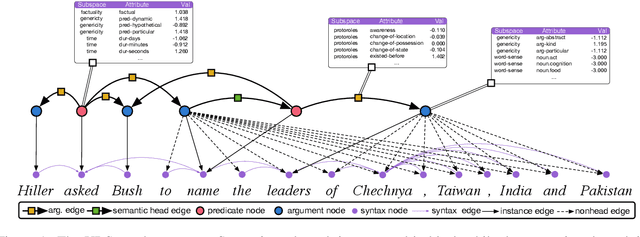
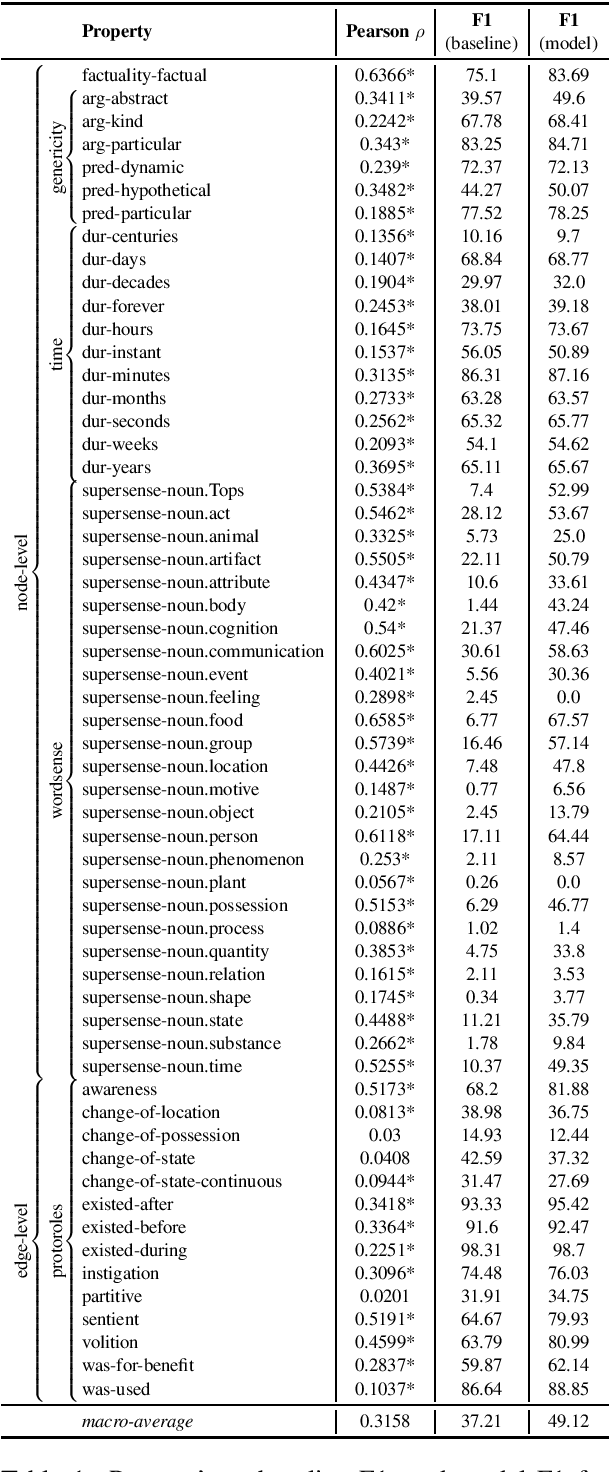
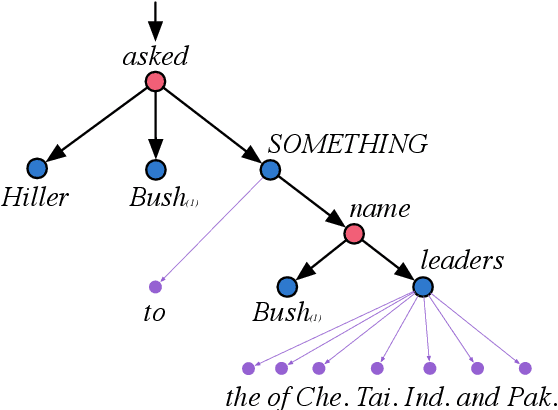

We introduce a transductive model for parsing into Universal Decompositional Semantics (UDS) representations, which jointly learns to map natural language utterances into UDS graph structures and annotate the graph with decompositional semantic attribute scores. We also introduce a strong pipeline model for parsing UDS graph structure, and show that our parser can perform comparably while additionally performing attribute prediction.
The Universal Decompositional Semantics Dataset and Decomp Toolkit
Sep 30, 2019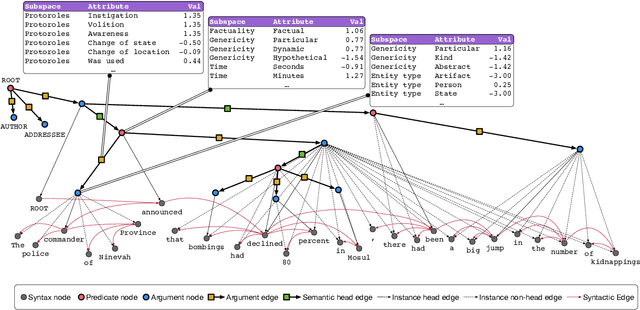
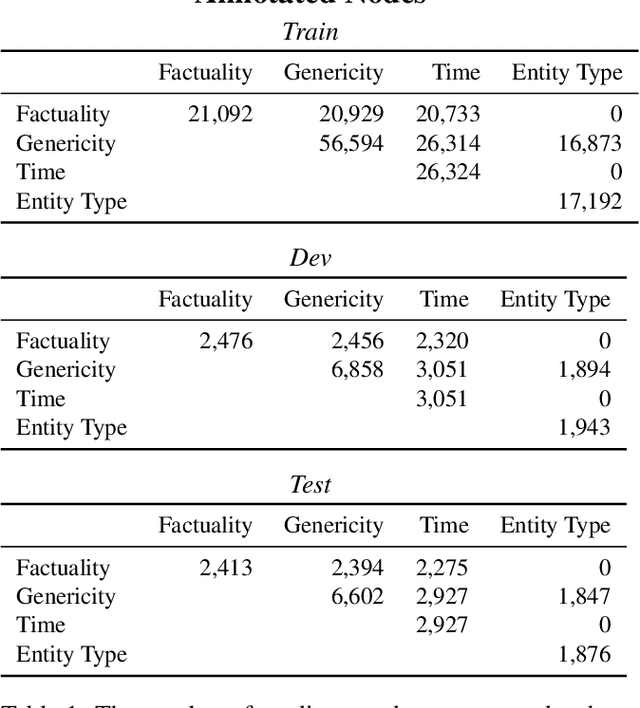
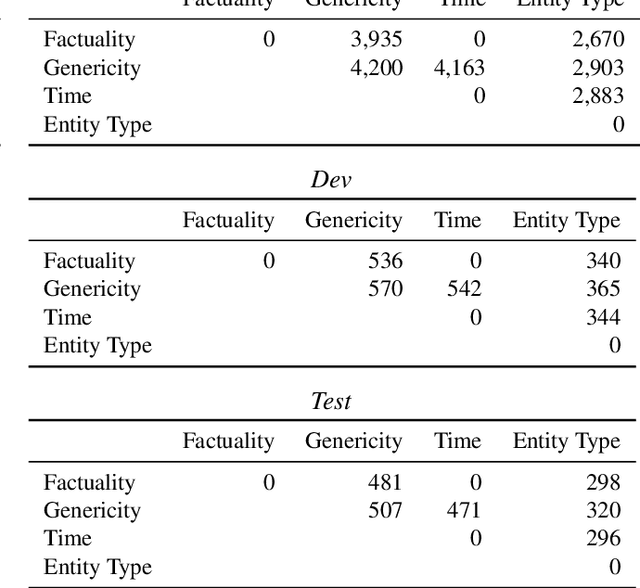

We present the Universal Decompositional Semantics (UDS) dataset (v1.0), which is bundled with the Decomp toolkit (v0.1). UDS1.0 unifies five high-quality, decompositional semantics-aligned annotation sets within a single semantic graph specification---with graph structures defined by the predicative patterns produced by the PredPatt tool and real-valued node and edge attributes constructed using sophisticated normalization procedures. The Decomp toolkit provides a suite of Python 3 tools for querying UDS graphs using SPARQL. Both UDS1.0 and Decomp0.1 are publicly available at http://decomp.io.