 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposal and study of statistical features for string similarity computation and classification
May 14, 2026Adaptations of features commonly applied in the field of visual computing, co-occurrence matrix (COM) and run-length matrix (RLM), are proposed for the similarity computation of strings in general (words, phrases, codes and texts). The proposed features are not sensitive to language related information. These are purely statistical and can be used in any context with any language or grammatical structure. Other statistical measures that are commonly employed in the field such as longest common subsequence, maximal consecutive longest common subsequence, mutual information and edit distances are evaluated and compared. In the first synthetic set of experiments, the COM and RLM features outperform the remaining state-of-the-art statistical features. In 3 out of 4 cases, the RLM and COM features were statistically more significant than the second best group based on distances (P-value < 0.001). When it comes to a real text plagiarism dataset, the RLM features obtained the best results.
A systematic comparison of supervised classifiers
Oct 17, 2013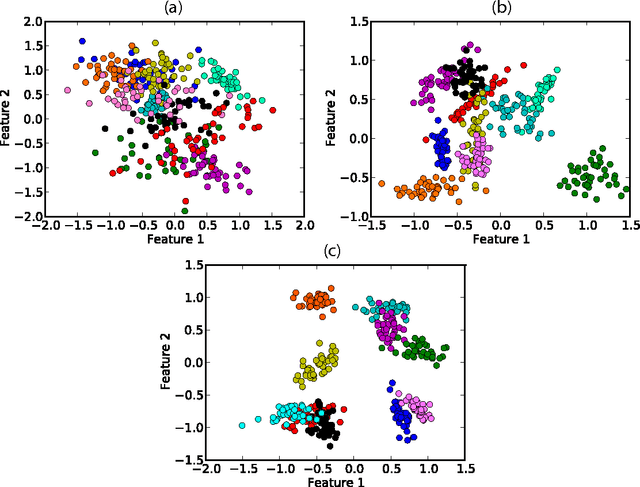

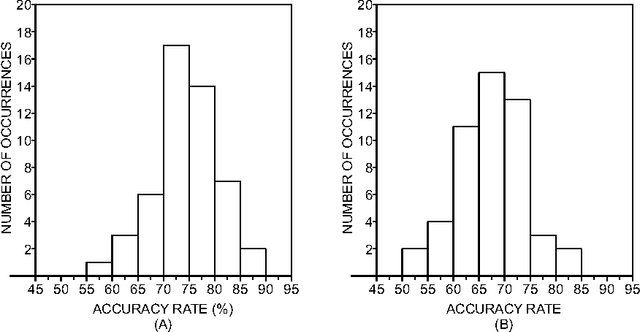
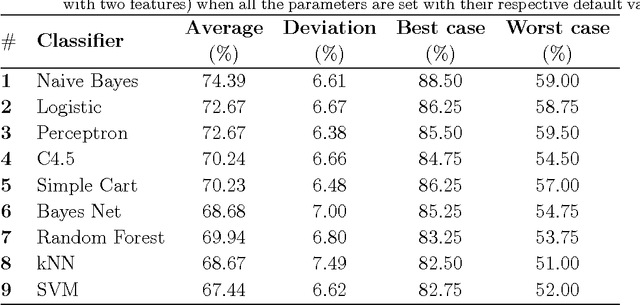
Pattern recognition techniques have been employed in a myriad of industrial, medical, commercial and academic applications. To tackle such a diversity of data, many techniques have been devised. However, despite the long tradition of pattern recognition research, there is no technique that yields the best classification in all scenarios. Therefore, the consideration of as many as possible techniques presents itself as an fundamental practice in applications aiming at high accuracy. Typical works comparing methods either emphasize the performance of a given algorithm in validation tests or systematically compare various algorithms, assuming that the practical use of these methods is done by experts. In many occasions, however, researchers have to deal with their practical classification tasks without an in-depth knowledge about the underlying mechanisms behind parameters. Actually, the adequate choice of classifiers and parameters alike in such practical circumstances constitutes a long-standing problem and is the subject of the current paper. We carried out a study on the performance of nine well-known classifiers implemented by the Weka framework and compared the dependence of the accuracy with their configuration parameter configurations. The analysis of performance with default parameters revealed that the k-nearest neighbors method exceeds by a large margin the other methods when high dimensional datasets are considered. When other configuration of parameters were allowed, we found that it is possible to improve the quality of SVM in more than 20% even if parameters are set randomly. Taken together, the investigation conducted in this paper suggests that, apart from the SVM implementation, Weka's default configuration of parameters provides an performance close the one achieved with the optimal configuration.