 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis
Oct 27, 2023
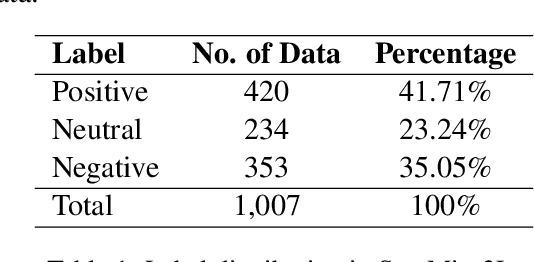

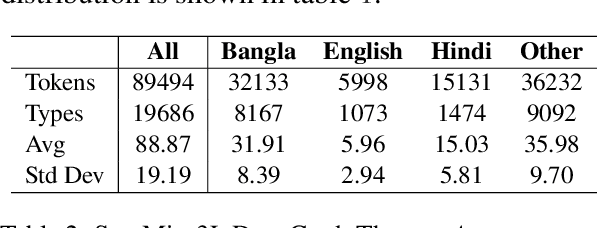
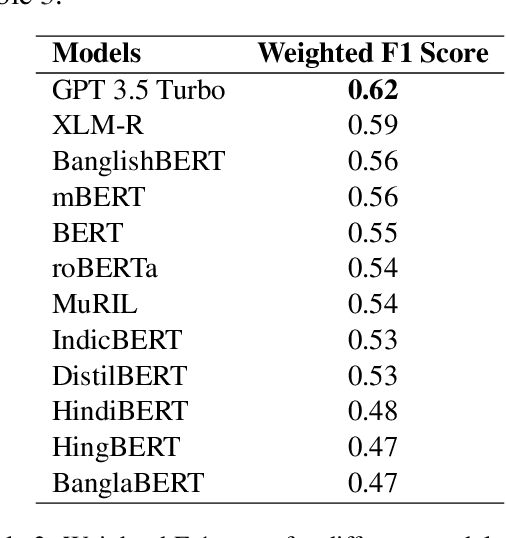
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several datasets have been build with the goal of training computational models for code-mixing. Although it is very common to observe code-mixing with multiple languages, most datasets available contain code-mixed between only two languages. In this paper, we introduce SentMix-3L, a novel dataset for sentiment analysis containing code-mixed data between three languages Bangla, English, and Hindi. We carry out a comprehensive evaluation using SentMix-3L. We show that zero-shot prompting with GPT-3.5 outperforms all transformer-based models on SentMix-3L.
OffMix-3L: A Novel Code-Mixed Dataset in Bangla-English-Hindi for Offensive Language Identification
Oct 27, 2023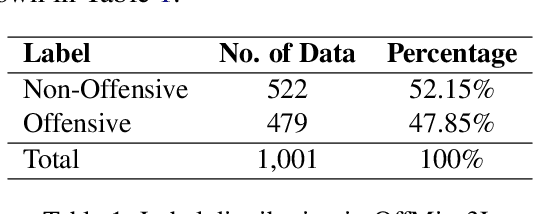

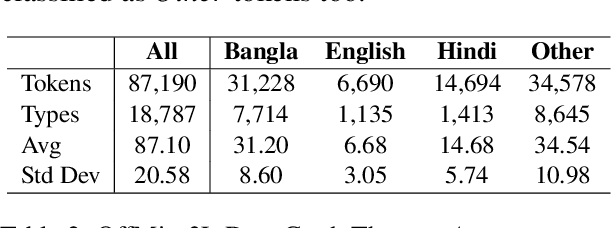
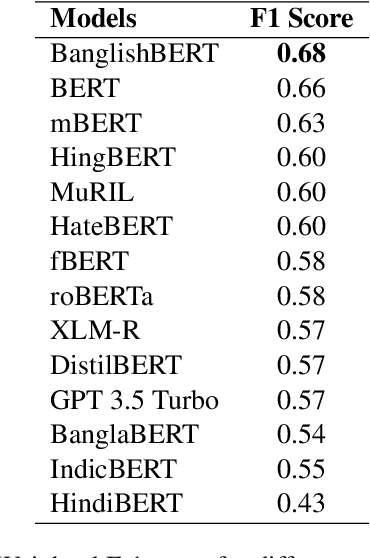
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several works have been conducted on building datasets and performing downstream NLP tasks on code-mixed data. Although it is not uncommon to observe code-mixing of three or more languages, most available datasets in this domain contain code-mixed data from only two languages. In this paper, we introduce OffMix-3L, a novel offensive language identification dataset containing code-mixed data from three different languages. We experiment with several models on this dataset and observe that BanglishBERT outperforms other transformer-based models and GPT-3.5.
Advancing the study of Large-Scale Learning in Overlapped Speech Detection
Aug 28, 2023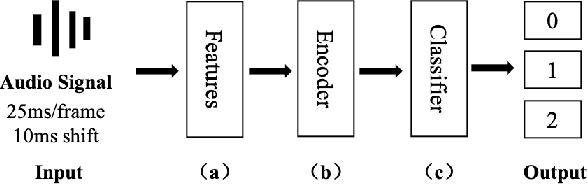
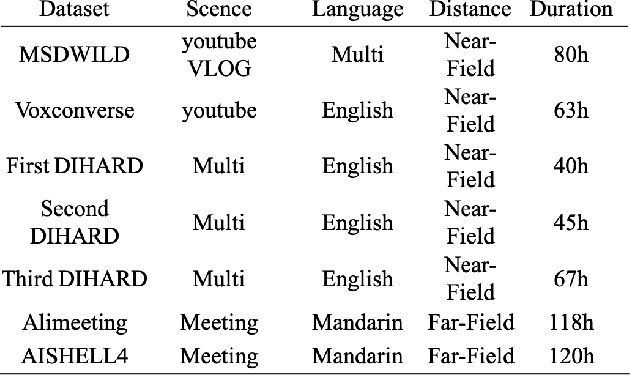
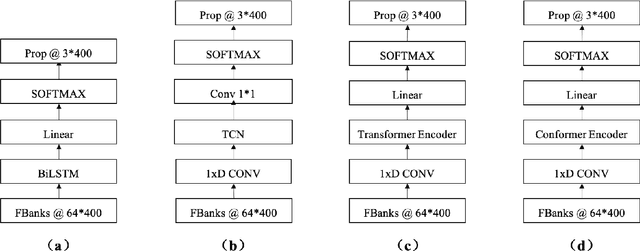
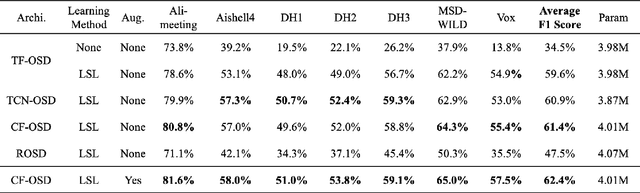
Overlapped Speech Detection (OSD) is an important part of speech applications involving analysis of multi-party conversations. However, most of the existing OSD systems are trained and evaluated on specific dataset, which limits the application scenarios of these systems. To solve this problem, we conduct a study of large-scale learning (LSL) in OSD tasks and propose a general 16K single-channel OSD system. In our study, 522 hours of labeled audio in different languages and styles are collected and used as the large-scale dataset. Rigorous comparative experiments are designed and used to evaluate the effectiveness of LSL in OSD tasks and select the appropriate model of general OSD system. The results show that LSL can significantly improve the performance and robustness of OSD models, and the OSD model based on Conformer (CF-OSD) with LSL is currently the best 16K single-channel OSD system. Moreover, the CF-OSD with LSL establishes a state-of-the-art performance with an F1-score of 81.6% and 53.8% on Alimeeting test set and DIHARD II evaluation set, respectively.
Securing Voice Biometrics: One-Shot Learning Approach for Audio Deepfake Detection
Oct 05, 2023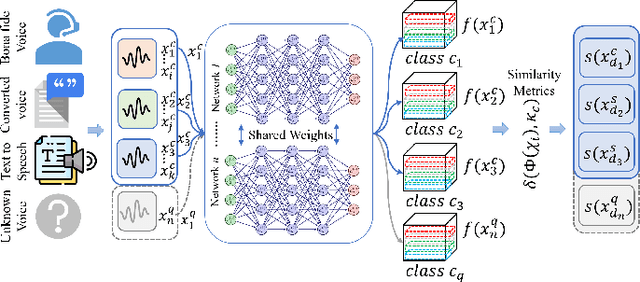
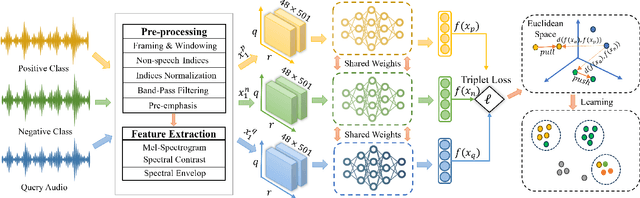
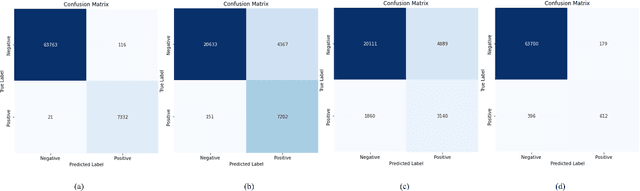
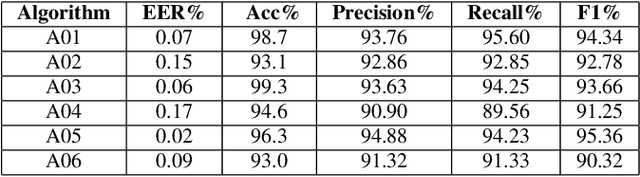
The Automatic Speaker Verification (ASV) system is vulnerable to fraudulent activities using audio deepfakes, also known as logical-access voice spoofing attacks. These deepfakes pose a concerning threat to voice biometrics due to recent advancements in generative AI and speech synthesis technologies. While several deep learning models for speech synthesis detection have been developed, most of them show poor generalizability, especially when the attacks have different statistical distributions from the ones seen. Therefore, this paper presents Quick-SpoofNet, an approach for detecting both seen and unseen synthetic attacks in the ASV system using one-shot learning and metric learning techniques. By using the effective spectral feature set, the proposed method extracts compact and representative temporal embeddings from the voice samples and utilizes metric learning and triplet loss to assess the similarity index and distinguish different embeddings. The system effectively clusters similar speech embeddings, classifying bona fide speeches as the target class and identifying other clusters as spoofing attacks. The proposed system is evaluated using the ASVspoof 2019 logical access (LA) dataset and tested against unseen deepfake attacks from the ASVspoof 2021 dataset. Additionally, its generalization ability towards unseen bona fide speech is assessed using speech data from the VSDC dataset.
Challenges and Insights: Exploring 3D Spatial Features and Complex Networks on the MISP Dataset
Oct 05, 2023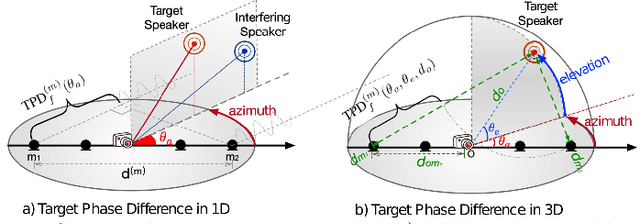


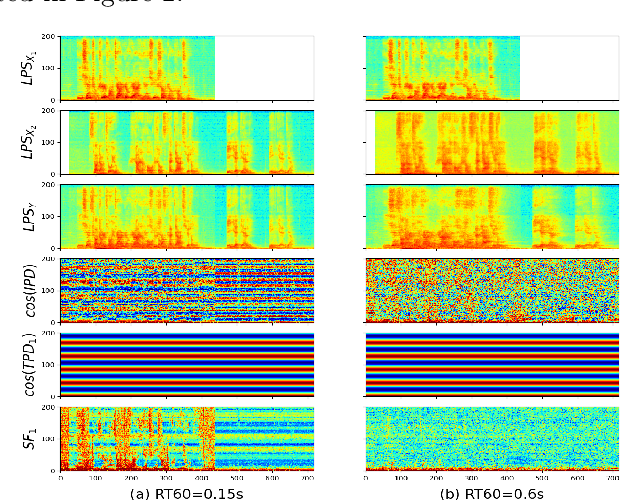
Multi-channel multi-talker speech recognition presents formidable challenges in the realm of speech processing, marked by issues such as background noise, reverberation, and overlapping speech. Overcoming these complexities requires leveraging contextual cues to separate target speech from a cacophonous mix, enabling accurate recognition. Among these cues, the 3D spatial feature has emerged as a cutting-edge solution, particularly when equipped with spatial information about the target speaker. Its exceptional ability to discern the target speaker within mixed audio, often rendering intermediate processing redundant, paves the way for the direct training of "All-in-one" ASR models. These models have demonstrated commendable performance on both simulated and real-world data. In this paper, we extend this approach to the MISP dataset to further validate its efficacy. We delve into the challenges encountered and insights gained when applying 3D spatial features to MISP, while also exploring preliminary experiments involving the replacement of these features with more complex input and models.
Task-Agnostic Low-Rank Adapters for Unseen English Dialects
Nov 02, 2023Large Language Models (LLMs) are trained on corpora disproportionally weighted in favor of Standard American English. As a result, speakers of other dialects experience significantly more failures when interacting with these technologies. In practice, these speakers often accommodate their speech to be better understood. Our work shares the belief that language technologies should be designed to accommodate the diversity in English dialects and not the other way around. However, prior works on dialect struggle with generalizing to evolving and emerging dialects in a scalable manner. To fill this gap, our method, HyperLoRA, leverages expert linguistic knowledge to enable resource-efficient adaptation via hypernetworks. By disentangling dialect-specific and cross-dialectal information, HyperLoRA improves generalization to unseen dialects in a task-agnostic fashion. Not only is HyperLoRA more scalable in the number of parameters, but it also achieves the best or most competitive performance across 5 dialects in a zero-shot setting. In this way, our approach facilitates access to language technology for billions of English dialect speakers who are traditionally underrepresented.
Training dynamic models using early exits for automatic speech recognition on resource-constrained devices
Sep 18, 2023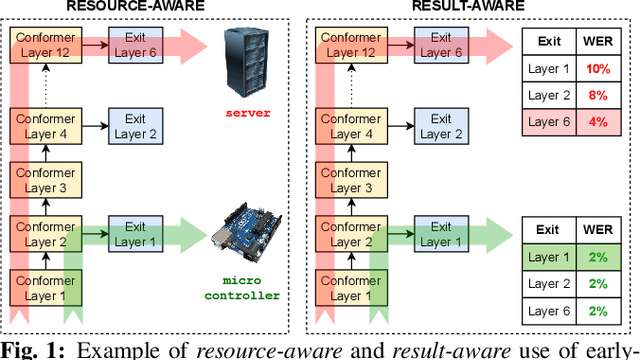
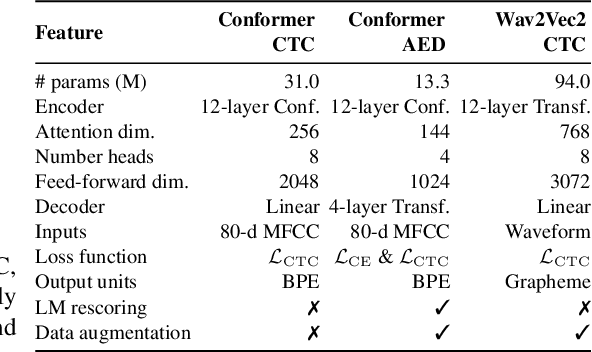
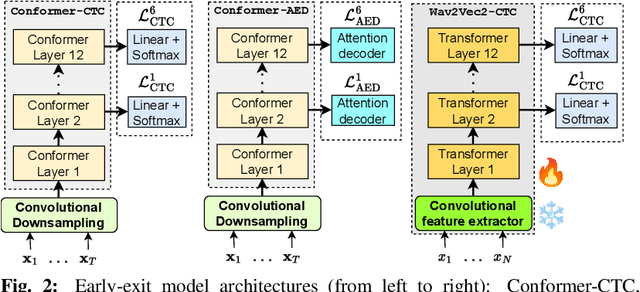
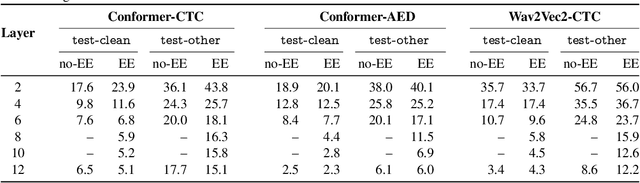
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.
A Novel Self-training Approach for Low-resource Speech Recognition
Aug 10, 2023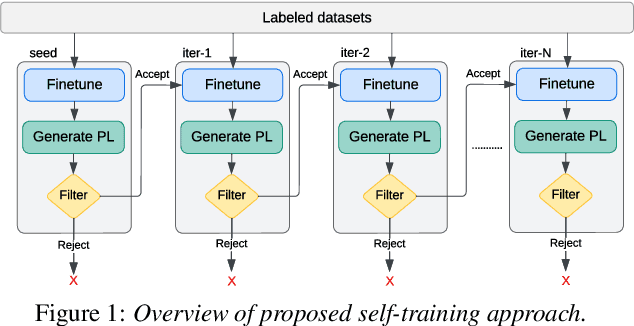
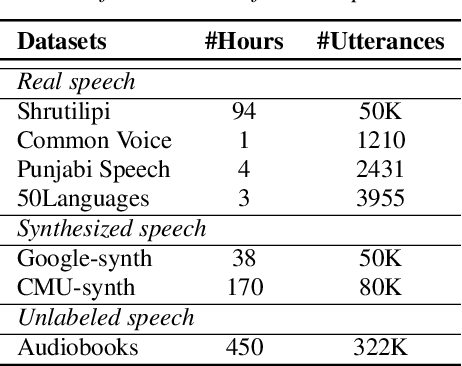

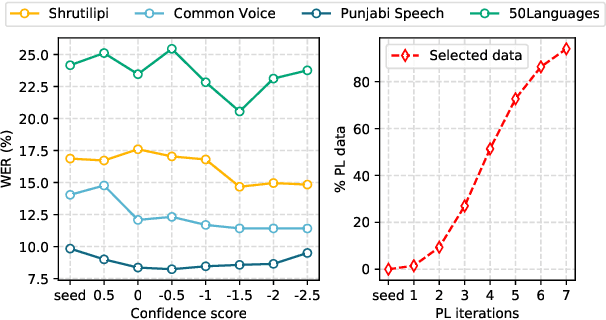
In this paper, we propose a self-training approach for automatic speech recognition (ASR) for low-resource settings. While self-training approaches have been extensively developed and evaluated for high-resource languages such as English, their applications to low-resource languages like Punjabi have been limited, despite the language being spoken by millions globally. The scarcity of annotated data has hindered the development of accurate ASR systems, especially for low-resource languages (e.g., Punjabi and M\=aori languages). To address this issue, we propose an effective self-training approach that generates highly accurate pseudo-labels for unlabeled low-resource speech. Our experimental analysis demonstrates that our approach significantly improves word error rate, achieving a relative improvement of 14.94% compared to a baseline model across four real speech datasets. Further, our proposed approach reports the best results on the Common Voice Punjabi dataset.
Harnessing Pre-Trained Sentence Transformers for Offensive Language Detection in Indian Languages
Oct 03, 2023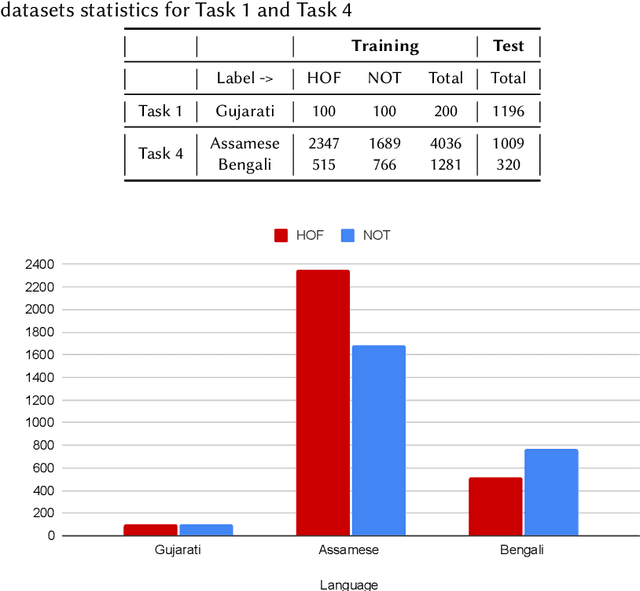
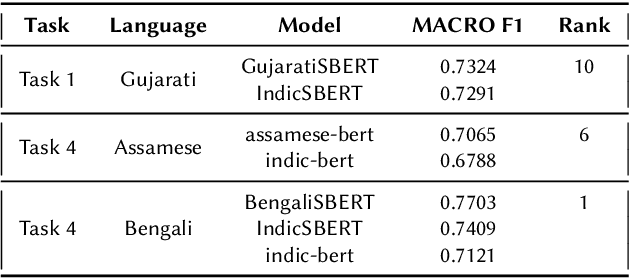
In our increasingly interconnected digital world, social media platforms have emerged as powerful channels for the dissemination of hate speech and offensive content. This work delves into the domain of hate speech detection, placing specific emphasis on three low-resource Indian languages: Bengali, Assamese, and Gujarati. The challenge is framed as a text classification task, aimed at discerning whether a tweet contains offensive or non-offensive content. Leveraging the HASOC 2023 datasets, we fine-tuned pre-trained BERT and SBERT models to evaluate their effectiveness in identifying hate speech. Our findings underscore the superiority of monolingual sentence-BERT models, particularly in the Bengali language, where we achieved the highest ranking. However, the performance in Assamese and Gujarati languages signifies ongoing opportunities for enhancement. Our goal is to foster inclusive online spaces by countering hate speech proliferation.
Causality Guided Disentanglement for Cross-Platform Hate Speech Detection
Aug 03, 2023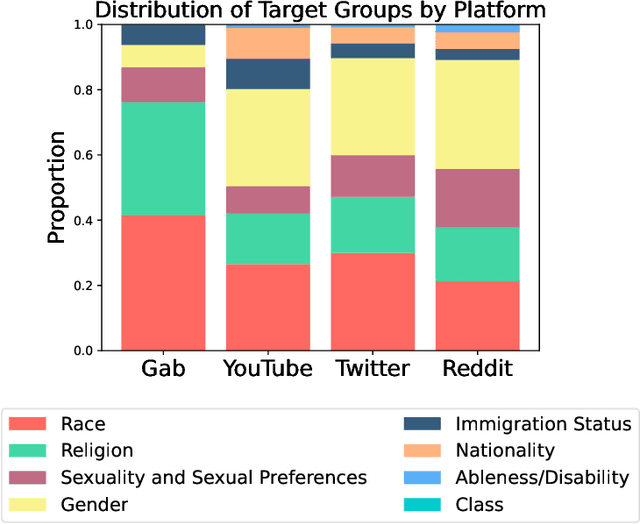
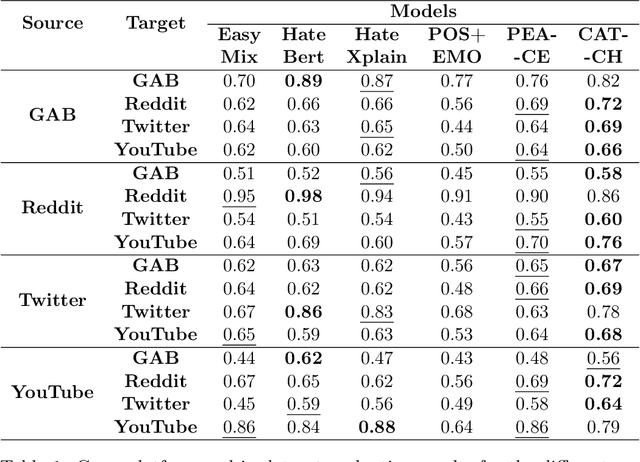
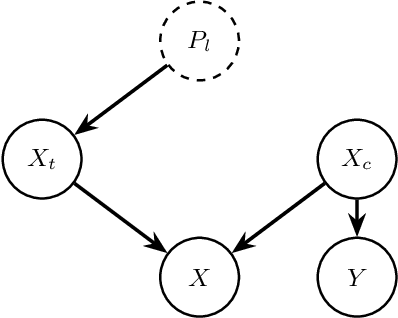
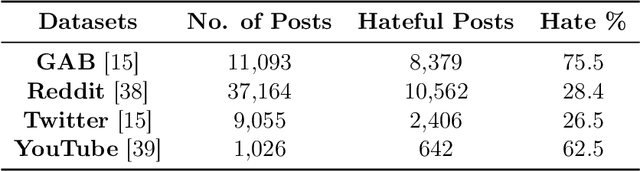
Social media platforms, despite their value in promoting open discourse, are often exploited to spread harmful content. Current deep learning and natural language processing models used for detecting this harmful content overly rely on domain-specific terms affecting their capabilities to adapt to generalizable hate speech detection. This is because they tend to focus too narrowly on particular linguistic signals or the use of certain categories of words. Another significant challenge arises when platforms lack high-quality annotated data for training, leading to a need for cross-platform models that can adapt to different distribution shifts. Our research introduces a cross-platform hate speech detection model capable of being trained on one platform's data and generalizing to multiple unseen platforms. To achieve good generalizability across platforms, one way is to disentangle the input representations into invariant and platform-dependent features. We also argue that learning causal relationships, which remain constant across diverse environments, can significantly aid in understanding invariant representations in hate speech. By disentangling input into platform-dependent features (useful for predicting hate targets) and platform-independent features (used to predict the presence of hate), we learn invariant representations resistant to distribution shifts. These features are then used to predict hate speech across unseen platforms. Our extensive experiments across four platforms highlight our model's enhanced efficacy compared to existing state-of-the-art methods in detecting generalized hate speech.