 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Comparing CTC and LFMMI for out-of-domain adaptation of wav2vec 2.0 acoustic model
Apr 06, 2021
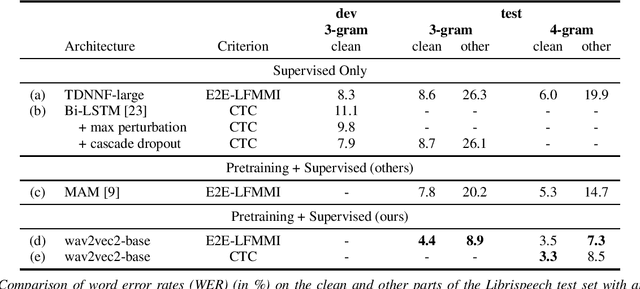
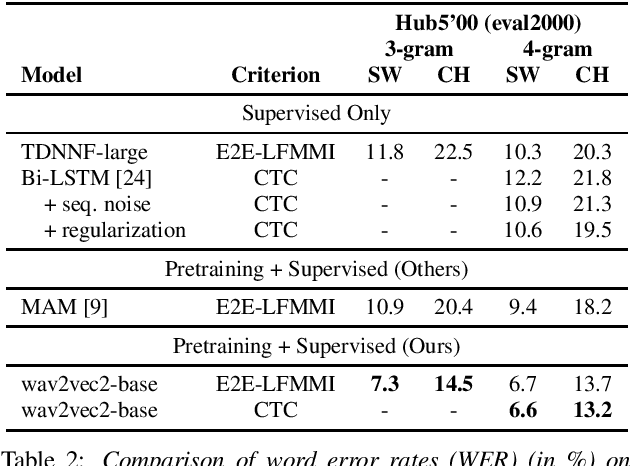
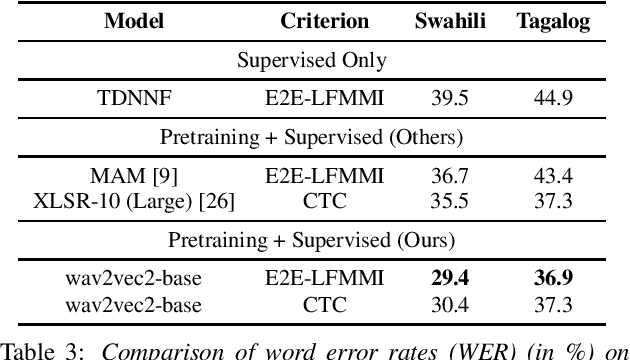
In this work, we investigate if the wav2vec 2.0 self-supervised pretraining helps mitigate the overfitting issues with connectionist temporal classification (CTC) training to reduce its performance gap with flat-start lattice-free MMI (E2E-LFMMI) for automatic speech recognition with limited training data. Towards that objective, we use the pretrained wav2vec 2.0 BASE model and fine-tune it on three different datasets including out-of-domain (Switchboard) and cross-lingual (Babel) scenarios. Our results show that for supervised adaptation of the wav2vec 2.0 model, both E2E-LFMMI and CTC achieve similar results; significantly outperforming the baselines trained only with supervised data. Fine-tuning the wav2vec 2.0 model with E2E-LFMMI and CTC we obtain the following relative WER improvements over the supervised baseline trained with E2E-LFMMI. We get relative improvements of 40% and 44% on the clean-set and 64% and 58% on the test set of Librispeech (100h) respectively. On Switchboard (300h) we obtain relative improvements of 33% and 35% respectively. Finally, for Babel languages, we obtain relative improvements of 26% and 23% on Swahili (38h) and 18% and 17% on Tagalog (84h) respectively.
Optimal Transport-based Adaptation in Dysarthric Speech Tasks
Apr 06, 2021
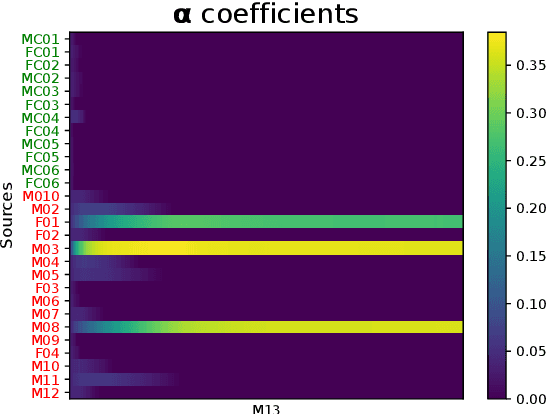
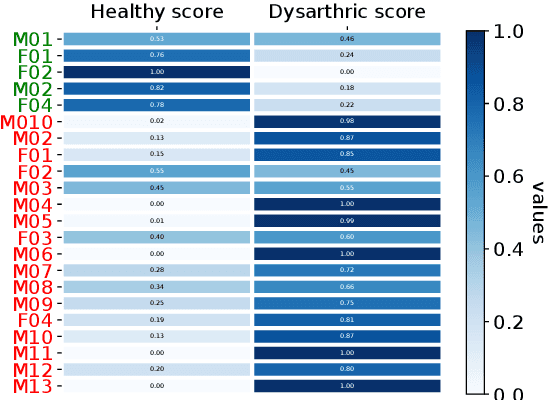
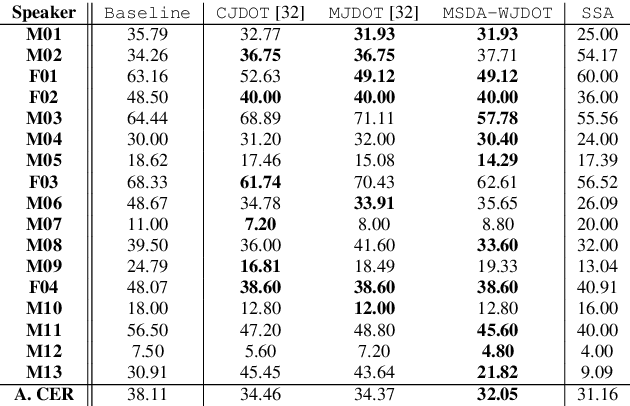
In many real-world applications, the mismatch between distributions of training data (source) and test data (target) significantly degrades the performance of machine learning algorithms. In speech data, causes of this mismatch include different acoustic environments or speaker characteristics. In this paper, we address this issue in the challenging context of dysarthric speech, by multi-source domain/speaker adaptation (MSDA/MSSA). Specifically, we propose the use of an optimal-transport based approach, called MSDA via Weighted Joint Optimal Transport (MSDA-WDJOT). We confront the mismatch problem in dysarthria detection for which the proposed approach outperforms both the Baseline and the state-of-the-art MSDA models, improving the detection accuracy of 0.9% over the best competitor method. We then employ MSDA-WJDOT for dysarthric speaker adaptation in command speech recognition. This provides a Command Error Rate relative reduction of 16% and 7% over the baseline and the best competitor model, respectively. Interestingly, MSDA-WJDOT provides a similarity score between the source and the target, i.e. between speakers in this case. We leverage this similarity measure to define a Dysarthric and Healthy score of the target speaker and diagnose the dysarthria with an accuracy of 95%.
Software Engineering for AI-Based Systems: A Survey
May 05, 2021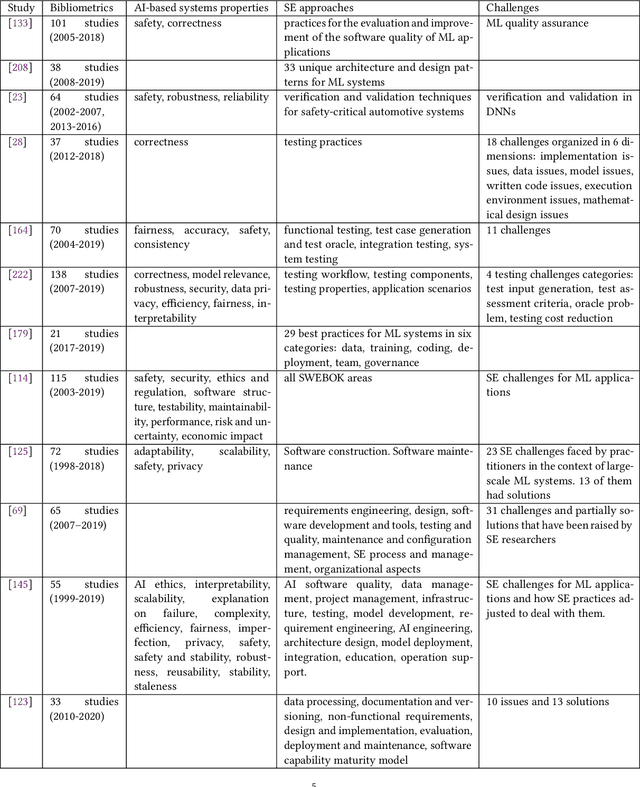
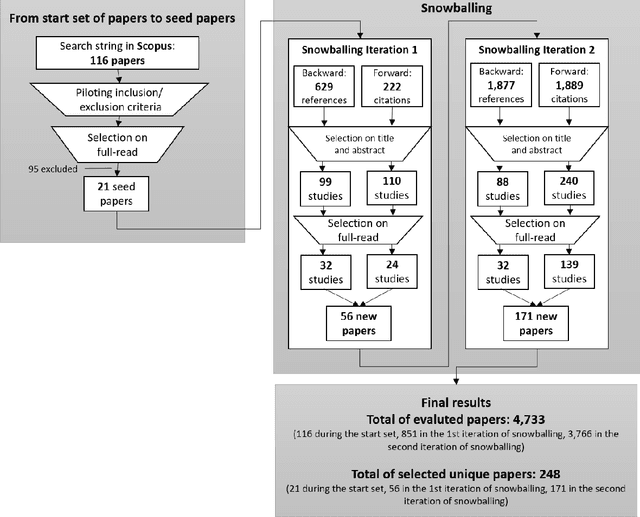

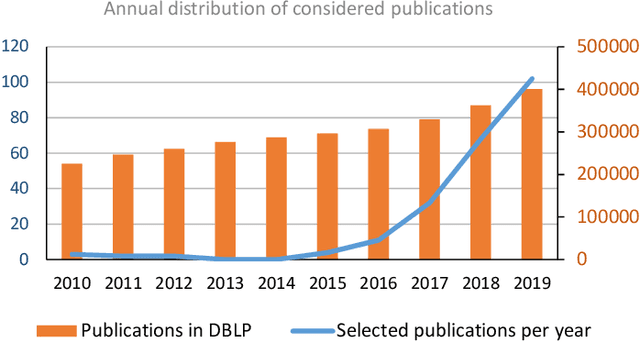
AI-based systems are software systems with functionalities enabled by at least one AI component (e.g., for image- and speech-recognition, and autonomous driving). AI-based systems are becoming pervasive in society due to advances in AI. However, there is limited synthesized knowledge on Software Engineering (SE) approaches for building, operating, and maintaining AI-based systems. To collect and analyze state-of-the-art knowledge about SE for AI-based systems, we conducted a systematic mapping study. We considered 248 studies published between January 2010 and March 2020. SE for AI-based systems is an emerging research area, where more than 2/3 of the studies have been published since 2018. The most studied properties of AI-based systems are dependability and safety. We identified multiple SE approaches for AI-based systems, which we classified according to the SWEBOK areas. Studies related to software testing and software quality are very prevalent, while areas like software maintenance seem neglected. Data-related issues are the most recurrent challenges. Our results are valuable for: researchers, to quickly understand the state of the art and learn which topics need more research; practitioners, to learn about the approaches and challenges that SE entails for AI-based systems; and, educators, to bridge the gap among SE and AI in their curricula.
Multi-Scale Temporal Convolution Network for Classroom Voice Detection
May 31, 2021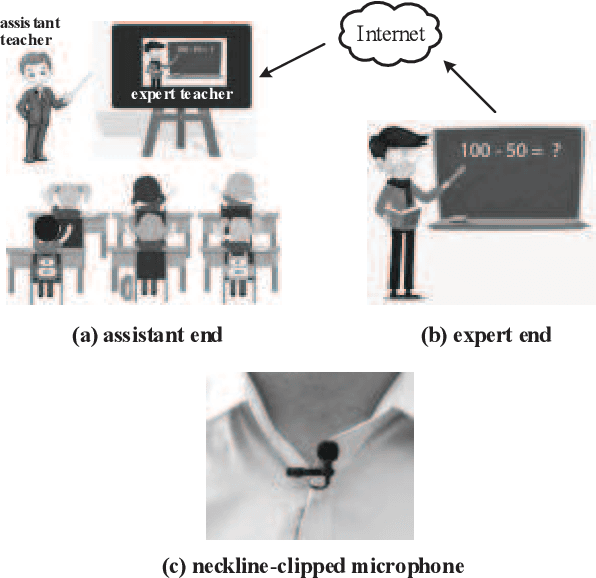
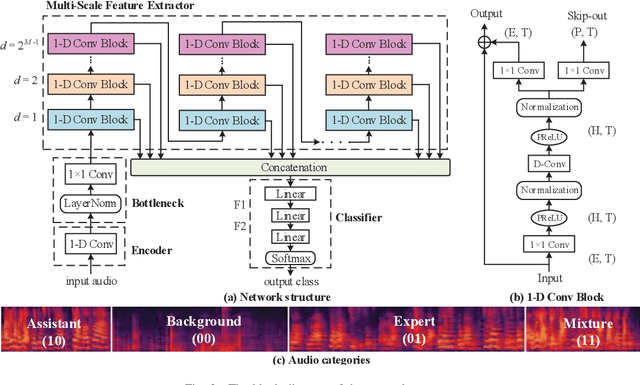
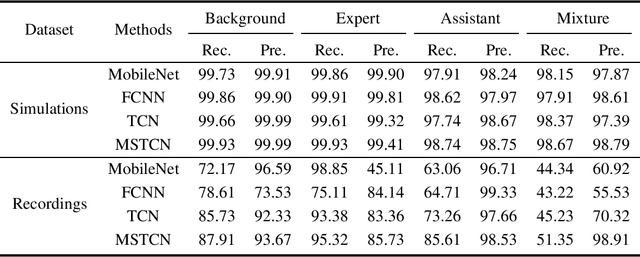
Teaching with the cooperation of expert teacher and assistant teacher, which is the so-called "double-teachers classroom", i.e., the course is giving by the expert online and presented through projection screen at the classroom, and the teacher at the classroom performs as an assistant for guiding the students in learning, is becoming more prevalent in today's teaching method for K-12 education. For monitoring the teaching quality, a microphone clipped on the assistant's neckline is always used for voice recording, then fed to the downstream tasks of automatic speech recognition (ASR) and neural language processing (NLP). However, besides its voice, there would be some other interfering voices, including the expert's one and the student's one. Here, we propose to extract the assistant' voices from the perspective of sound event detection, i.e., the voices are classified into four categories, namely the expert, the teacher, the mixture of them, and the background. To make frame-level identification, which is important for grabbing sensitive words for the downstream tasks, a multi-scale temporal convolution neural network is constructed with stacked dilated convolutions for considering both local and global properties. These features are concatenated and fed to a classification network constructed by three linear layers. The framework is evaluated on simulated data and real-world recordings, giving considerable performance in terms of precision and recall, compared with some classical classification methods.
Fully Learnable Front-End for Multi-Channel Acoustic Modeling using Semi-Supervised Learning
Feb 01, 2020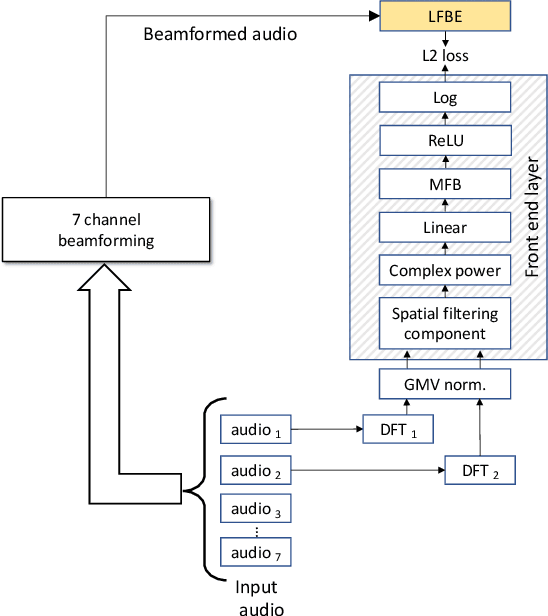
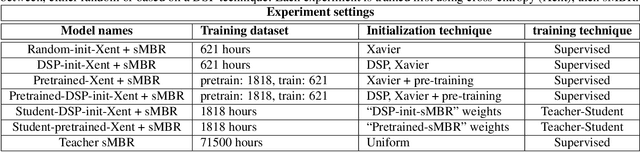
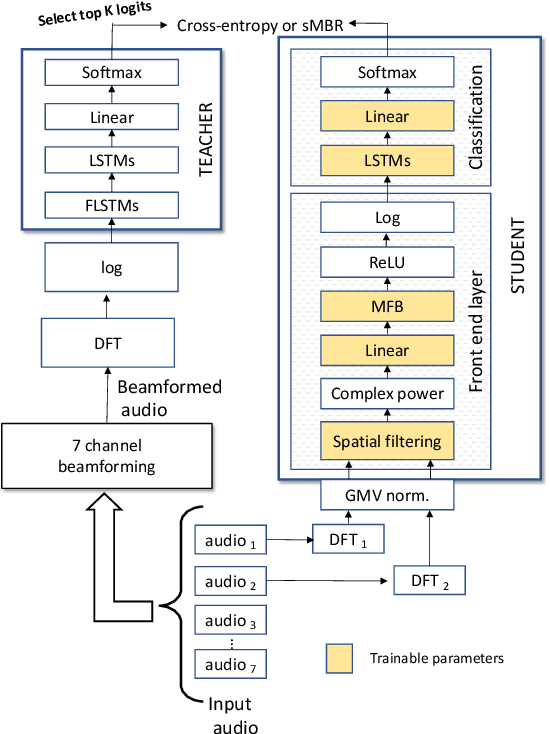

In this work, we investigated the teacher-student training paradigm to train a fully learnable multi-channel acoustic model for far-field automatic speech recognition (ASR). Using a large offline teacher model trained on beamformed audio, we trained a simpler multi-channel student acoustic model used in the speech recognition system. For the student, both multi-channel feature extraction layers and the higher classification layers were jointly trained using the logits from the teacher model. In our experiments, compared to a baseline model trained on about 600 hours of transcribed data, a relative word-error rate (WER) reduction of about 27.3% was achieved when using an additional 1800 hours of untranscribed data. We also investigated the benefit of pre-training the multi-channel front end to output the beamformed log-mel filter bank energies (LFBE) using L2 loss. We find that pre-training improves the word error rate by 10.7% when compared to a multi-channel model directly initialized with a beamformer and mel-filter bank coefficients for the front end. Finally, combining pre-training and teacher-student training produces a WER reduction of 31% compared to our baseline.
CoVoST 2: A Massively Multilingual Speech-to-Text Translation Corpus
Jul 20, 2020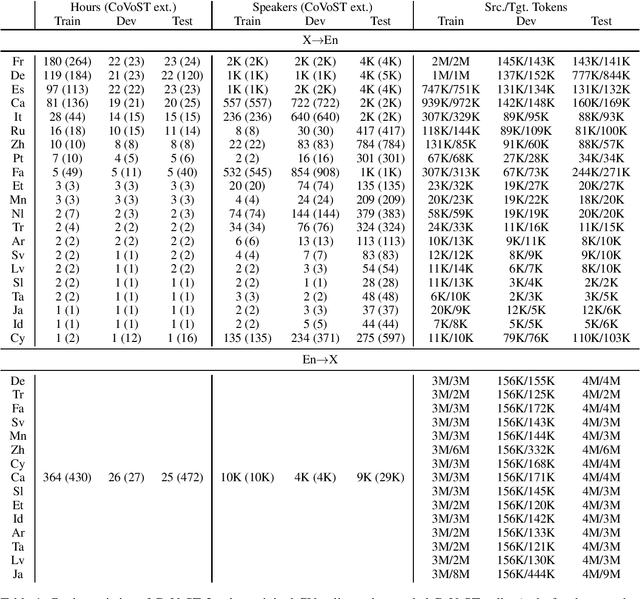
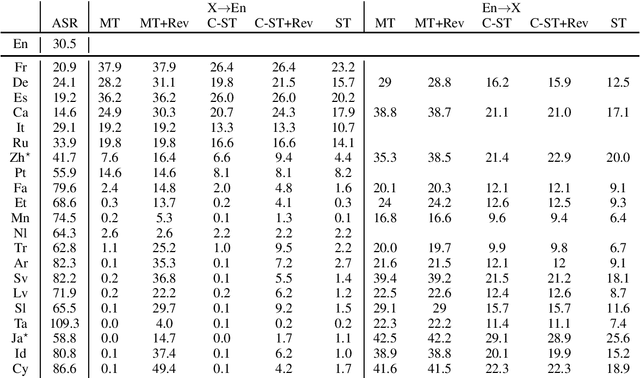
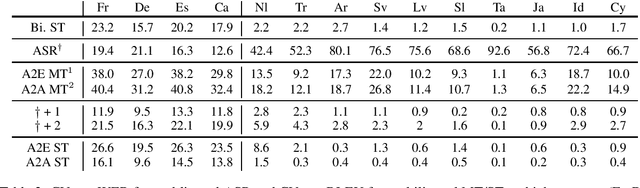
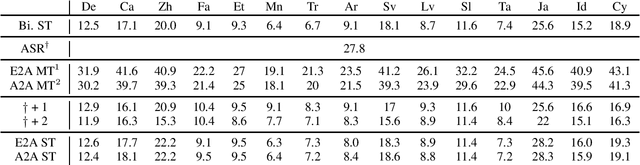
Speech translation has recently become an increasingly popular topic of research, partly due to the development of benchmark datasets. Nevertheless, current datasets cover a limited number of languages. With the aim to foster research in massive multilingual speech translation and speech translation for low resource language pairs, we release CoVoST 2, a large-scale multilingual speech translation corpus covering translations from 21 languages into English and from English into 15 languages. This represents the largest open dataset available to date from total volume and language coverage perspective. Data sanity checks provide evidence about the quality of the data, which is released under CC0 license. We also provide extensive speech recognition, bilingual and multilingual machine translation and speech translation baselines.
Zero-shot Speech Translation
Jul 13, 2021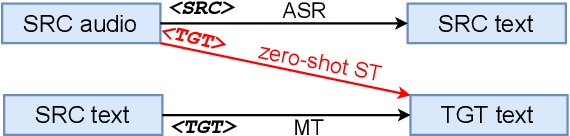
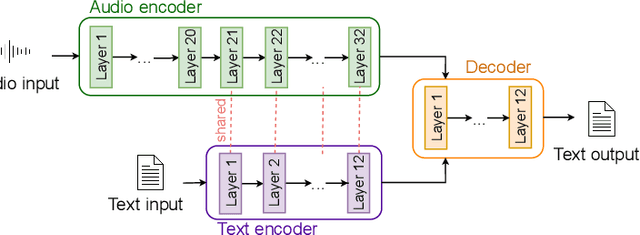

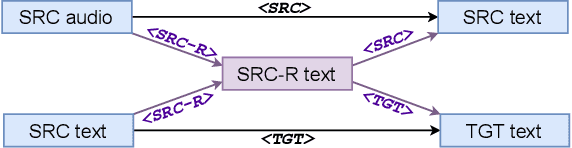
Speech Translation (ST) is the task of translating speech in one language into text in another language. Traditional cascaded approaches for ST, using Automatic Speech Recognition (ASR) and Machine Translation (MT) systems, are prone to error propagation. End-to-end approaches use only one system to avoid propagating error, yet are difficult to employ due to data scarcity. We explore zero-shot translation, which enables translating a pair of languages that is unseen during training, thus avoid the use of end-to-end ST data. Zero-shot translation has been shown to work for multilingual machine translation, yet has not been studied for speech translation. We attempt to build zero-shot ST models that are trained only on ASR and MT tasks but can do ST task during inference. The challenge is that the representation of text and audio is significantly different, thus the models learn ASR and MT tasks in different ways, making it non-trivial to perform zero-shot. These models tend to output the wrong language when performing zero-shot ST. We tackle the issues by including additional training data and an auxiliary loss function that minimizes the text-audio difference. Our experiment results and analysis show that the methods are promising for zero-shot ST. Moreover, our methods are particularly useful in the few-shot settings where a limited amount of ST data is available, with improvements of up to +11.8 BLEU points compared to direct end-to-end ST models and +3.9 BLEU points compared to ST models fine-tuned from pre-trained ASR model.
LSTM and GPT-2 Synthetic Speech Transfer Learning for Speaker Recognition to Overcome Data Scarcity
Jul 03, 2020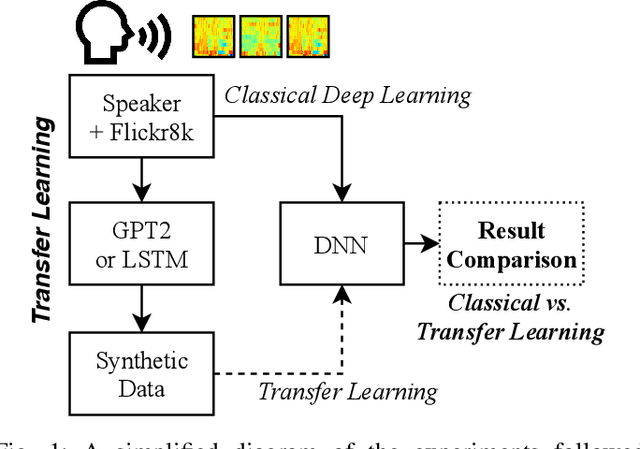
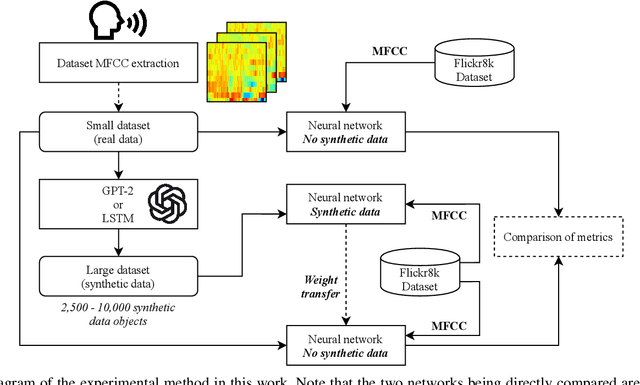
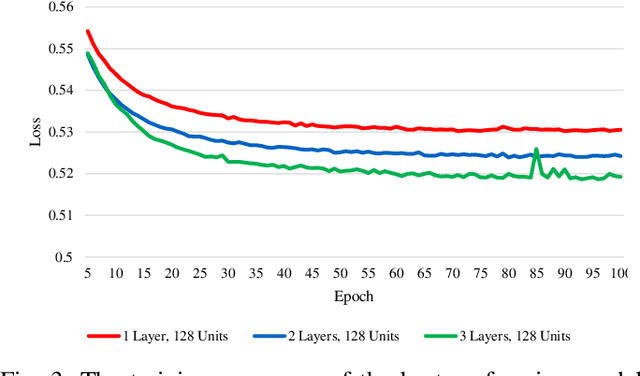
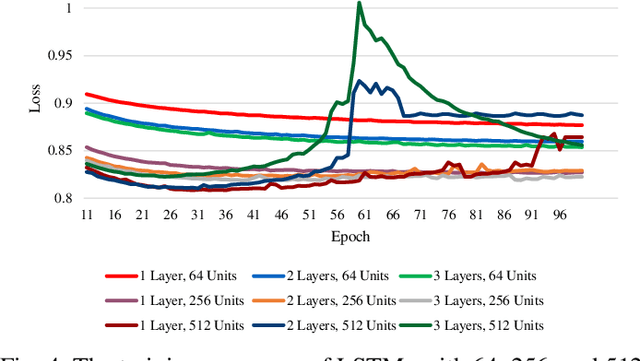
In speech recognition problems, data scarcity often poses an issue due to the willingness of humans to provide large amounts of data for learning and classification. In this work, we take a set of 5 spoken Harvard sentences from 7 subjects and consider their MFCC attributes. Using character level LSTMs (supervised learning) and OpenAI's attention-based GPT-2 models, synthetic MFCCs are generated by learning from the data provided on a per-subject basis. A neural network is trained to classify the data against a large dataset of Flickr8k speakers and is then compared to a transfer learning network performing the same task but with an initial weight distribution dictated by learning from the synthetic data generated by the two models. The best result for all of the 7 subjects were networks that had been exposed to synthetic data, the model pre-trained with LSTM-produced data achieved the best result 3 times and the GPT-2 equivalent 5 times (since one subject had their best result from both models at a draw). Through these results, we argue that speaker classification can be improved by utilising a small amount of user data but with exposure to synthetically-generated MFCCs which then allow the networks to achieve near maximum classification scores.
Towards Lifelong Learning of End-to-end ASR
Apr 04, 2021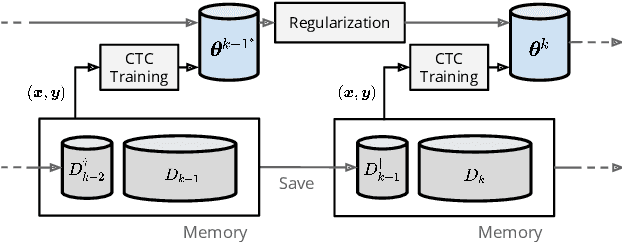

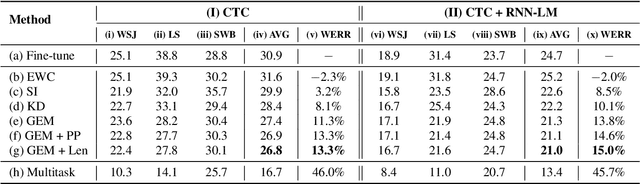
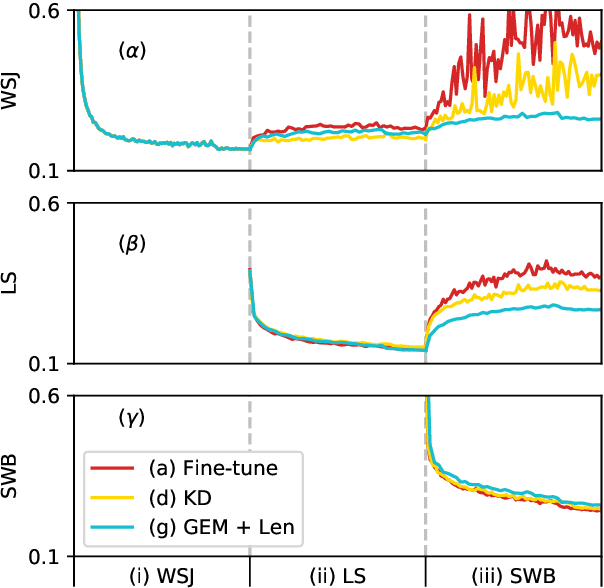
Automatic speech recognition (ASR) technologies today are primarily optimized for given datasets; thus, any changes in the application environment (e.g., acoustic conditions or topic domains) may inevitably degrade the performance. We can collect new data describing the new environment and fine-tune the system, but this naturally leads to higher error rates for the earlier datasets, referred to as catastrophic forgetting. The concept of lifelong learning (LLL) aiming to enable a machine to sequentially learn new tasks from new datasets describing the changing real world without forgetting the previously learned knowledge is thus brought to attention. This paper reports, to our knowledge, the first effort to extensively consider and analyze the use of various approaches of LLL in end-to-end (E2E) ASR, including proposing novel methods in saving data for past domains to mitigate the catastrophic forgetting problem. An overall relative reduction of 28.7% in WER was achieved compared to the fine-tuning baseline when sequentially learning on three very different benchmark corpora. This can be the first step toward the highly desired ASR technologies capable of synchronizing with the continuously changing real world.
Persian phonemes recognition using PPNet
Dec 17, 2018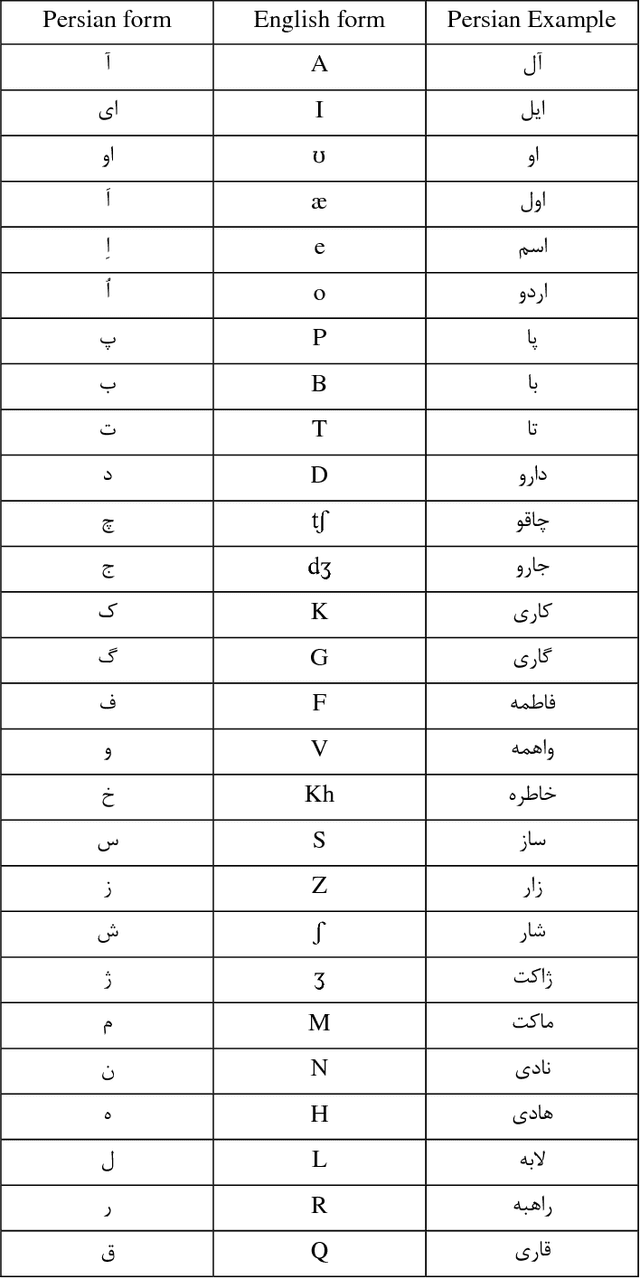
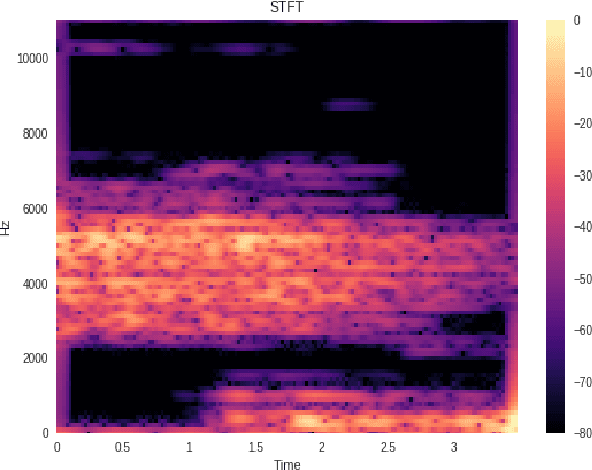
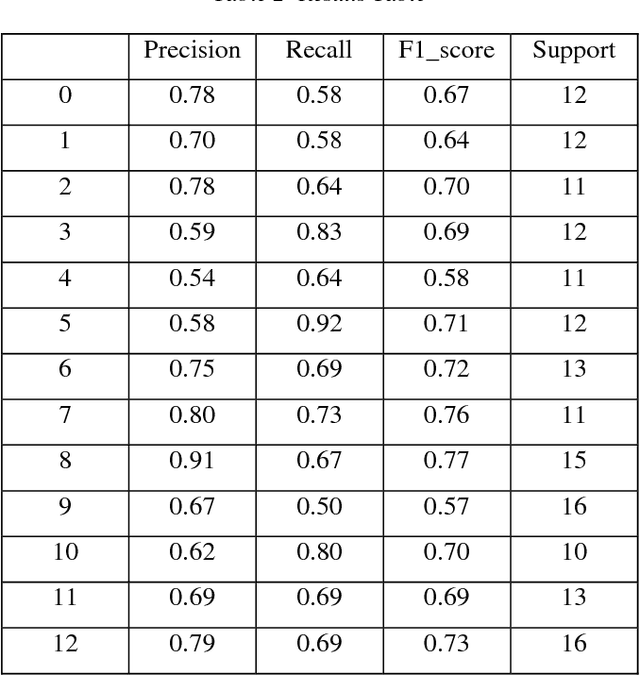
In this paper a new approach for recognition of Persian phonemes on the PCVC speech dataset is proposed. Nowadays deep neural networks are playing main rule in classification tasks. However the best results in speech recognition are not as good as human recognition rate yet. Deep learning techniques are shown their outstanding performance over so many classification tasks like image classification, document classification, etc. Also in some tasks their performance were even better than human. So the reason why ASR (automatic speech recognition) systems are not as good as the human speech recognition system is mostly depend on features of data is fed to deep neural networks. In this research first sound samples are cut for exact extraction of phoneme sounds in 50ms samples. Then phonemes are grouped in 30 groups; Containing 23 consonants, 6 vowels and a silence phoneme. STFT (Short time Fourier transform) is applied on them and Then STFT results are given to PPNet (A new deep convolutional neural network architecture) classifier and a total average of 75.87% accuracy is reached which is the best result ever compared to other algorithms on Separated Persian phonemes (Like in PCVC speech dataset).