 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Streaming End-to-End Framework For Spoken Language Understanding
May 20, 2021
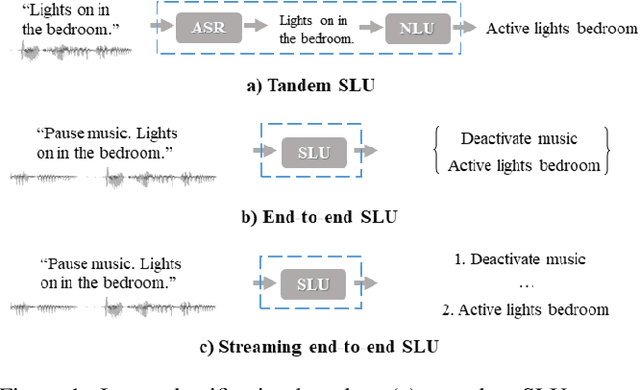
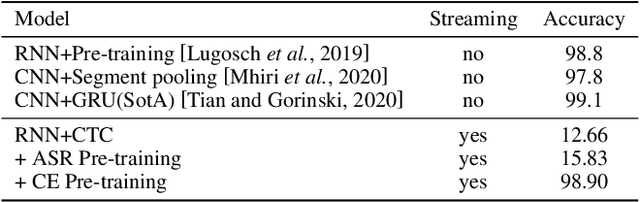
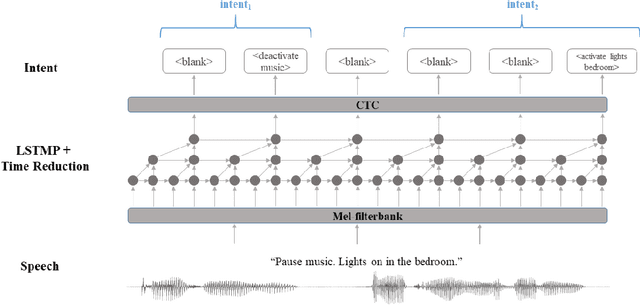

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.
Speak or Chat with Me: End-to-End Spoken Language Understanding System with Flexible Inputs
Apr 07, 2021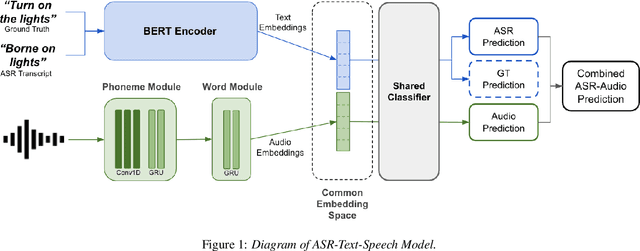
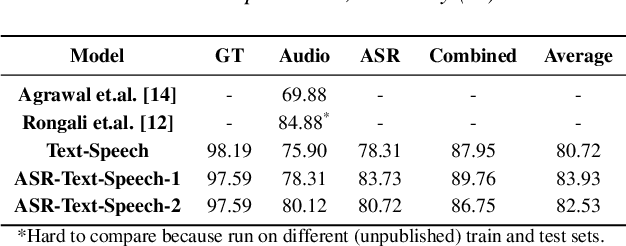
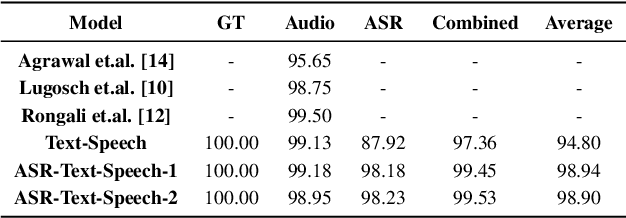
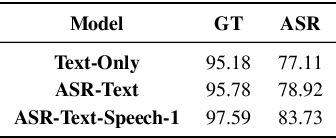
A major focus of recent research in spoken language understanding (SLU) has been on the end-to-end approach where a single model can predict intents directly from speech inputs without intermediate transcripts. However, this approach presents some challenges. First, since speech can be considered as personally identifiable information, in some cases only automatic speech recognition (ASR) transcripts are accessible. Second, intent-labeled speech data is scarce. To address the first challenge, we propose a novel system that can predict intents from flexible types of inputs: speech, ASR transcripts, or both. We demonstrate strong performance for either modality separately, and when both speech and ASR transcripts are available, through system combination, we achieve better results than using a single input modality. To address the second challenge, we leverage a semantically robust pre-trained BERT model and adopt a cross-modal system that co-trains text embeddings and acoustic embeddings in a shared latent space. We further enhance this system by utilizing an acoustic module pre-trained on LibriSpeech and domain-adapting the text module on our target datasets. Our experiments show significant advantages for these pre-training and fine-tuning strategies, resulting in a system that achieves competitive intent-classification performance on Snips SLU and Fluent Speech Commands datasets.
Do as I mean, not as I say: Sequence Loss Training for Spoken Language Understanding
Feb 12, 2021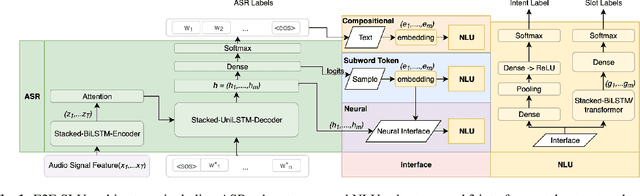
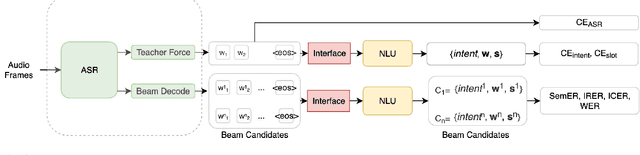
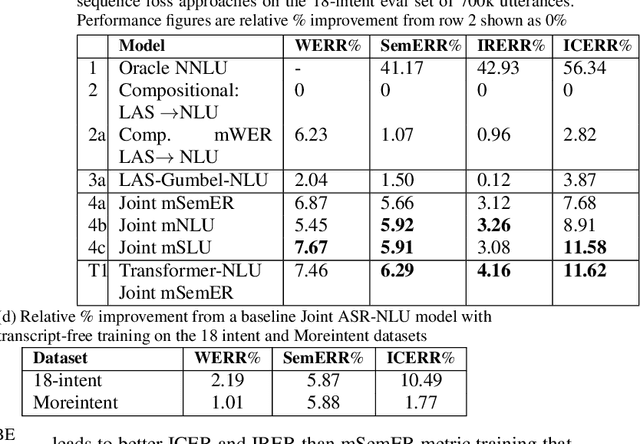
Spoken language understanding (SLU) systems extract transcriptions, as well as semantics of intent or named entities from speech, and are essential components of voice activated systems. SLU models, which either directly extract semantics from audio or are composed of pipelined automatic speech recognition (ASR) and natural language understanding (NLU) models, are typically trained via differentiable cross-entropy losses, even when the relevant performance metrics of interest are word or semantic error rates. In this work, we propose non-differentiable sequence losses based on SLU metrics as a proxy for semantic error and use the REINFORCE trick to train ASR and SLU models with this loss. We show that custom sequence loss training is the state-of-the-art on open SLU datasets and leads to 6% relative improvement in both ASR and NLU performance metrics on large proprietary datasets. We also demonstrate how the semantic sequence loss training paradigm can be used to update ASR and SLU models without transcripts, using semantic feedback alone.
Content-Aware Speaker Embeddings for Speaker Diarisation
Feb 12, 2021
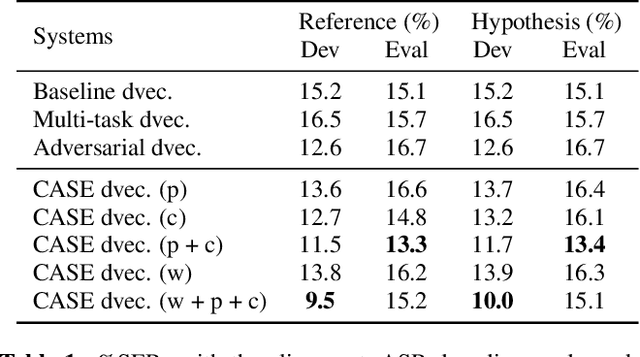
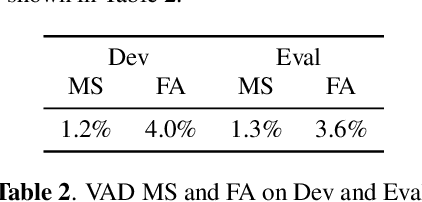
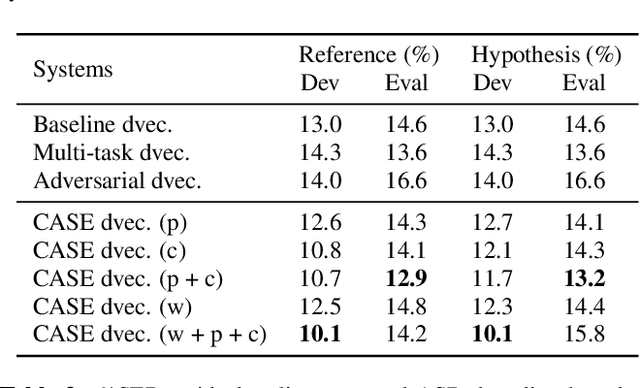
Recent speaker diarisation systems often convert variable length speech segments into fixed-length vector representations for speaker clustering, which are known as speaker embeddings. In this paper, the content-aware speaker embeddings (CASE) approach is proposed, which extends the input of the speaker classifier to include not only acoustic features but also their corresponding speech content, via phone, character, and word embeddings. Compared to alternative methods that leverage similar information, such as multitask or adversarial training, CASE factorises automatic speech recognition (ASR) from speaker recognition to focus on modelling speaker characteristics and correlations with the corresponding content units to derive more expressive representations. CASE is evaluated for speaker re-clustering with a realistic speaker diarisation setup using the AMI meeting transcription dataset, where the content information is obtained by performing ASR based on an automatic segmentation. Experimental results showed that CASE achieved a 17.8% relative speaker error rate reduction over conventional methods.
Tokenwise Contrastive Pretraining for Finer Speech-to-BERT Alignment in End-to-End Speech-to-Intent Systems
Apr 11, 2022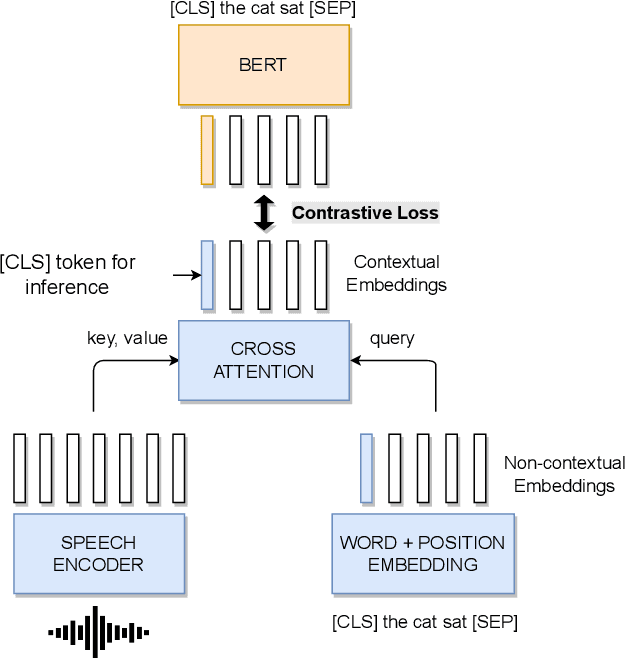
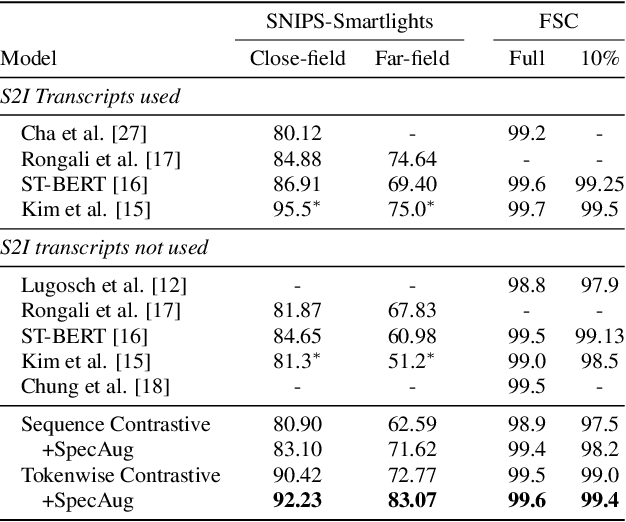
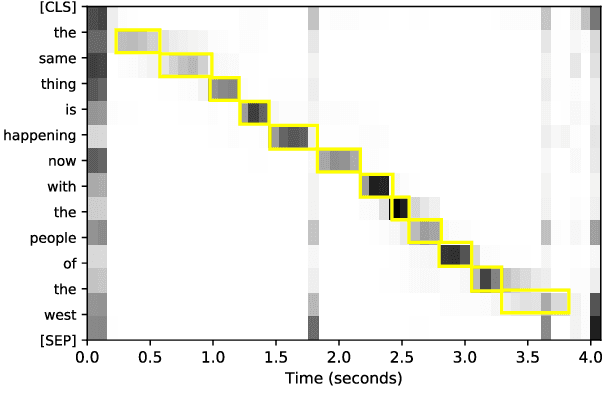
Recent advances in End-to-End (E2E) Spoken Language Understanding (SLU) have been primarily due to effective pretraining of speech representations. One such pretraining paradigm is the distillation of semantic knowledge from state-of-the-art text-based models like BERT to speech encoder neural networks. This work is a step towards doing the same in a much more efficient and fine-grained manner where we align speech embeddings and BERT embeddings on a token-by-token basis. We introduce a simple yet novel technique that uses a cross-modal attention mechanism to extract token-level contextual embeddings from a speech encoder such that these can be directly compared and aligned with BERT based contextual embeddings. This alignment is performed using a novel tokenwise contrastive loss. Fine-tuning such a pretrained model to perform intent recognition using speech directly yields state-of-the-art performance on two widely used SLU datasets. Our model improves further when fine-tuned with additional regularization using SpecAugment especially when speech is noisy, giving an absolute improvement as high as 8% over previous results.
DeCoAR 2.0: Deep Contextualized Acoustic Representations with Vector Quantization
Dec 11, 2020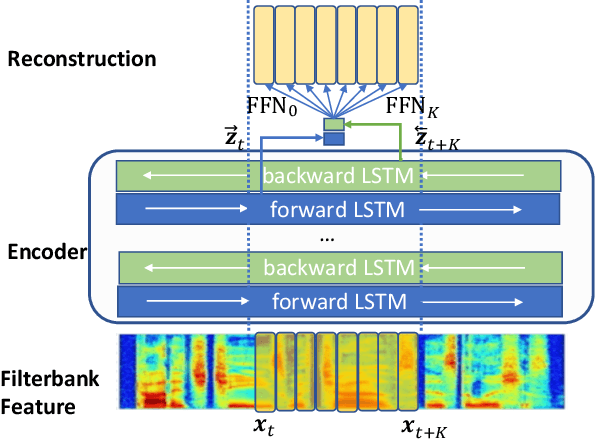

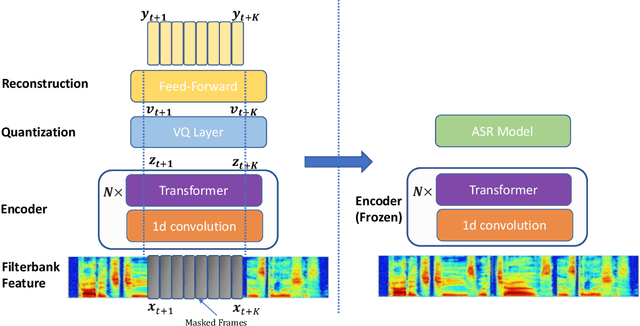
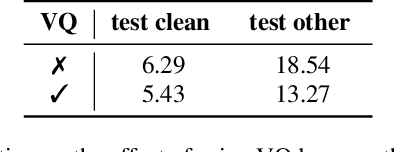
Recent success in speech representation learning enables a new way to leverage unlabeled data to train speech recognition model. In speech representation learning, a large amount of unlabeled data is used in a self-supervised manner to learn a feature representation. Then a smaller amount of labeled data is used to train a downstream ASR system using the new feature representations. Based on our previous work DeCoAR and inspirations from other speech representation learning, we propose DeCoAR 2.0, a Deep Contextualized Acoustic Representation with vector quantization. We introduce several modifications over the DeCoAR: first, we use Transformers in encoding module instead of LSTMs; second, we introduce a vector quantization layer between encoder and reconstruction modules; third, we propose an objective that combines the reconstructive loss with vector quantization diversity loss to train speech representations. Our experiments show consistent improvements over other speech representations in different data-sparse scenarios. Without fine-tuning, a light-weight ASR model trained on 10 hours of LibriSpeech labeled data with DeCoAR 2.0 features outperforms the model trained on the full 960-hour dataset with filterbank features.
Nanopore Base Calling on the Edge
Nov 09, 2020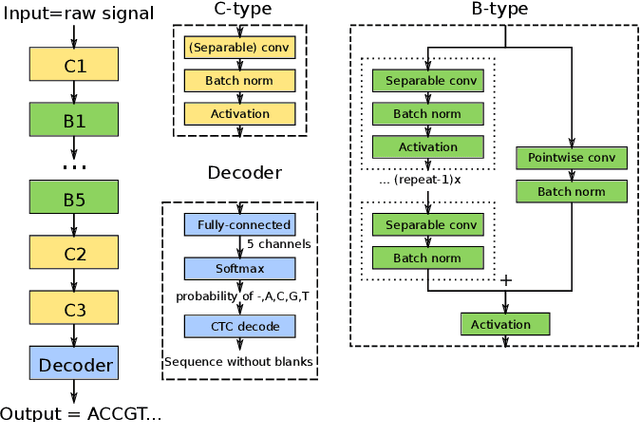

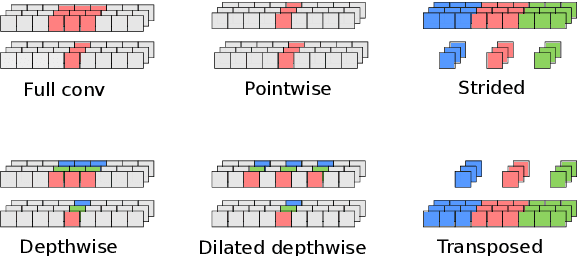
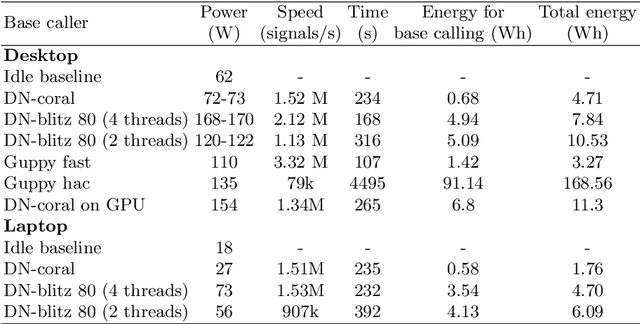
We developed a new base caller DeepNano-coral for nanopore sequencing, which is optimized to run on the Coral Edge Tensor Processing Unit, a small USB-attached hardware accelerator. To achieve this goal, we have designed new versions of two key components used in convolutional neural networks for speech recognition and base calling. In our components, we propose a new way of factorization of a full convolution into smaller operations, which decreases memory access operations, memory access being a bottleneck on this device. DeepNano-coral achieves real-time base calling during sequencing with the accuracy slightly better than the fast mode of the Guppy base caller and is extremely energy efficient, using only 10W of power. Availability: https://github.com/fmfi-compbio/coral-basecaller
Goal-driven text descriptions for images
Aug 28, 2021

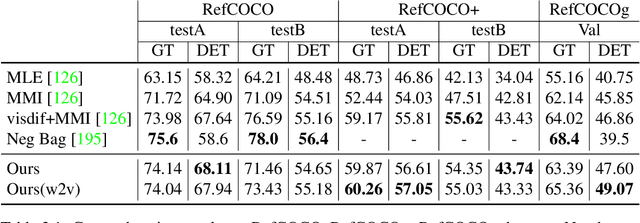
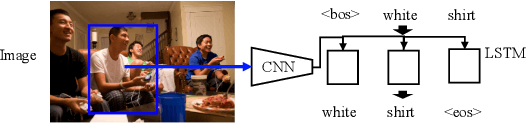
A big part of achieving Artificial General Intelligence(AGI) is to build a machine that can see and listen like humans. Much work has focused on designing models for image classification, video classification, object detection, pose estimation, speech recognition, etc., and has achieved significant progress in recent years thanks to deep learning. However, understanding the world is not enough. An AI agent also needs to know how to talk, especially how to communicate with a human. While perception (vision, for example) is more common across animal species, the use of complicated language is unique to humans and is one of the most important aspects of intelligence. In this thesis, we focus on generating textual output given visual input. In Chapter 3, we focus on generating the referring expression, a text description for an object in the image so that a receiver can infer which object is being described. We use a comprehension machine to directly guide the generated referring expressions to be more discriminative. In Chapter 4, we introduce a method that encourages discriminability in image caption generation. We show that more discriminative captioning models generate more descriptive captions. In Chapter 5, we study how training objectives and sampling methods affect the models' ability to generate diverse captions. We find that a popular captioning training strategy will be detrimental to the diversity of generated captions. In Chapter 6, we propose a model that can control the length of generated captions. By changing the desired length, one can influence the style and descriptiveness of the captions. Finally, in Chapter 7, we rank/generate informative image tags according to their information utility. The proposed method better matches what humans think are the most important tags for the images.
Predicting Entity Popularity to Improve Spoken Entity Recognition by Virtual Assistants
May 26, 2020
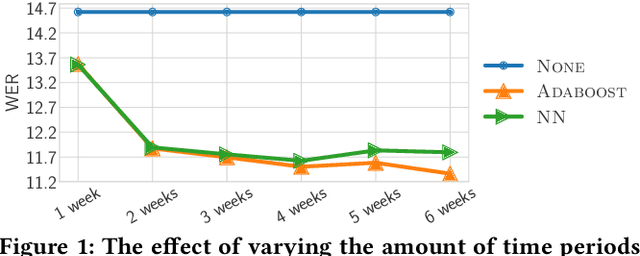
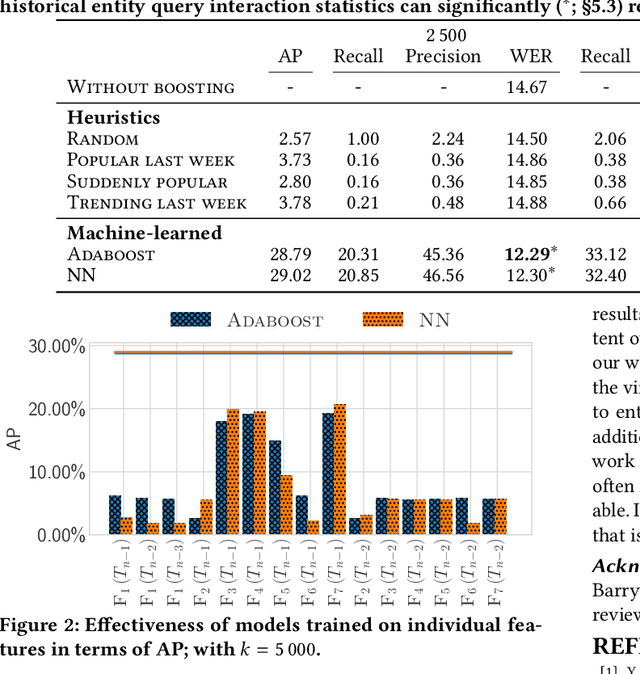
We focus on improving the effectiveness of a Virtual Assistant (VA) in recognizing emerging entities in spoken queries. We introduce a method that uses historical user interactions to forecast which entities will gain in popularity and become trending, and it subsequently integrates the predictions within the Automated Speech Recognition (ASR) component of the VA. Experiments show that our proposed approach results in a 20% relative reduction in errors on emerging entity name utterances without degrading the overall recognition quality of the system.
How Speech is Recognized to Be Emotional - A Study Based on Information Decomposition
Nov 24, 2021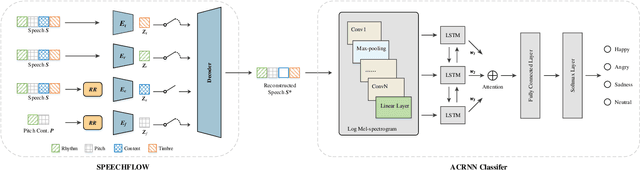
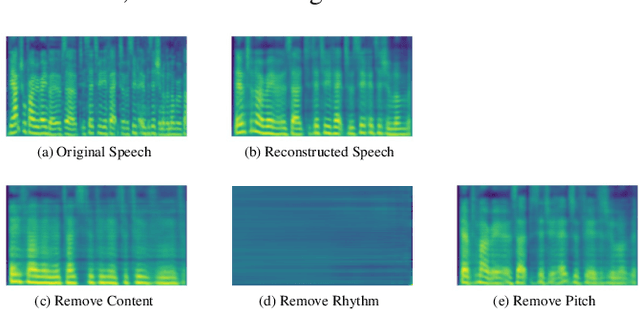
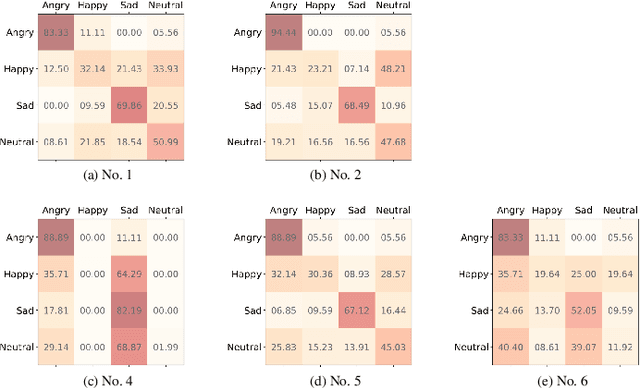
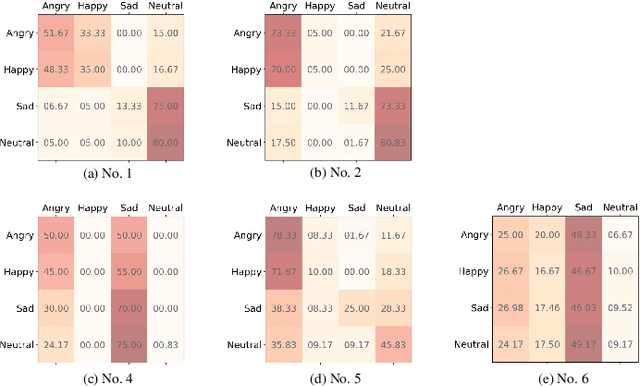
The way that humans encode their emotion into speech signals is complex. For instance, an angry man may increase his pitch and speaking rate, and use impolite words. In this paper, we present a preliminary study on various emotional factors and investigate how each of them impacts modern emotion recognition systems. The key tool of our study is the SpeechFlow model presented recently, by which we are able to decompose speech signals into separate information factors (content, pitch, rhythm). Based on this decomposition, we carefully studied the performance of each information component and their combinations. We conducted the study on three different speech emotion corpora and chose an attention-based convolutional RNN as the emotion classifier. Our results show that rhythm is the most important component for emotional expression. Moreover, the cross-corpus results are very bad (even worse than guess), demonstrating that the present speech emotion recognition model is rather weak. Interestingly, by removing one or several unimportant components, the cross-corpus results can be improved. This demonstrates the potential of the decomposition approach towards a generalizable emotion recognition.