 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Random Projections of Mel-Spectrograms as Low-Level Features for Automatic Music Genre Classification
Nov 12, 2019
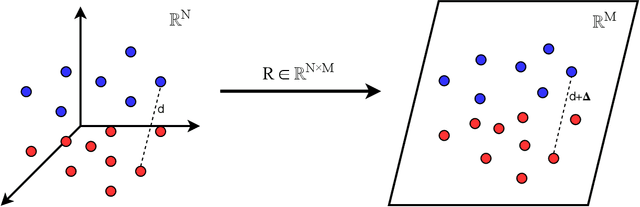
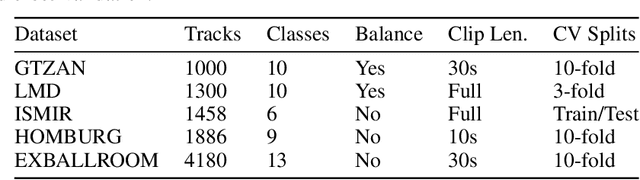
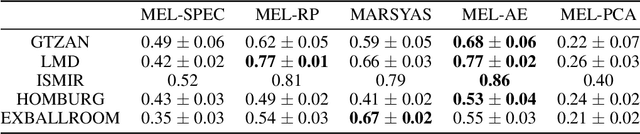
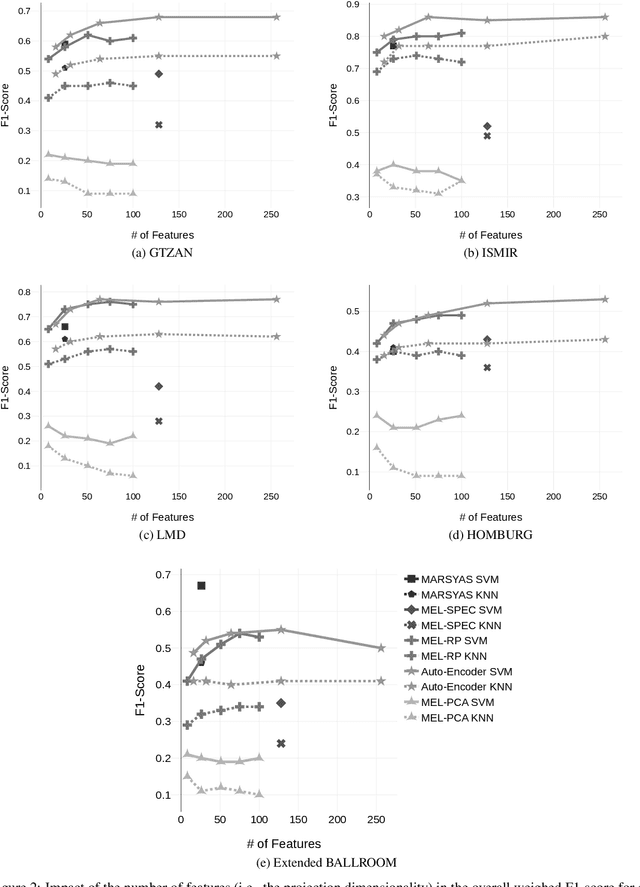
In this work, we analyse the random projections of Mel-spectrograms as low-level features for music genre classification. This approach was compared to handcrafted features, features learned using an auto-encoder and features obtained from a transfer learning setting. Tests in five different well-known, publicly available datasets show that random projections leads to results comparable to learned features and outperforms features obtained via transfer learning in a shallow learning scenario. Random projections do not require using extensive specialist knowledge and, simultaneously, requires less computational power for training than other projection-based low-level features. Therefore, they can be are a viable choice for usage in shallow learning content-based music genre classification.
Musical Instrument Recognition by XGBoost Combining Feature Fusion
Jun 02, 2022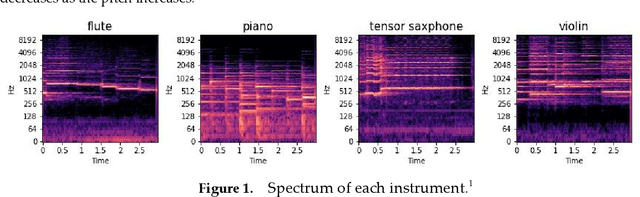

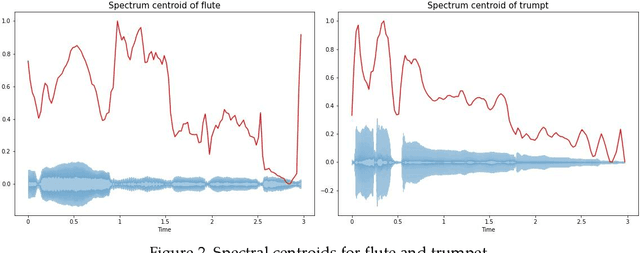
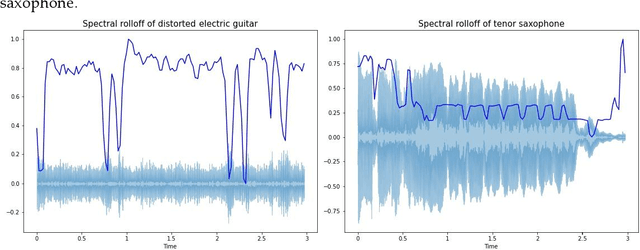
Musical instrument classification is one of the focuses of Music Information Retrieval (MIR). In order to solve the problem of poor performance of current musical instrument classification models, we propose a musical instrument classification algorithm based on multi-channel feature fusion and XGBoost. Based on audio feature extraction and fusion of the dataset, the features are input into the XGBoost model for training; secondly, we verified the superior performance of the algorithm in the musical instrument classification task by com-paring different feature combinations and several classical machine learning models such as Naive Bayes. The algorithm achieves an accuracy of 97.65% on the Medley-solos-DB dataset, outperforming existing models. The experiments provide a reference for feature selection in feature engineering for musical instrument classification.
MM-ALT: A Multimodal Automatic Lyric Transcription System
Jul 13, 2022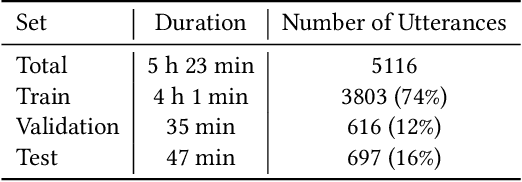
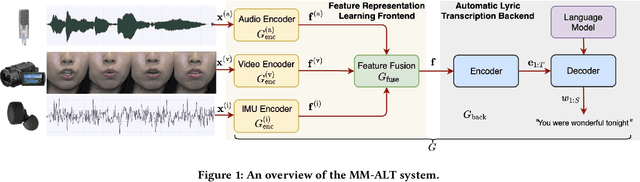
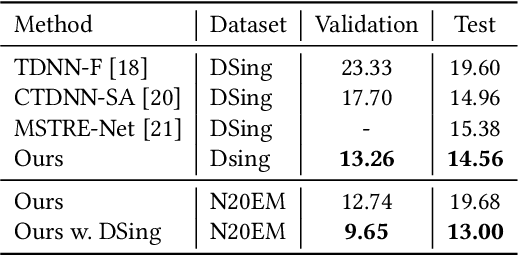
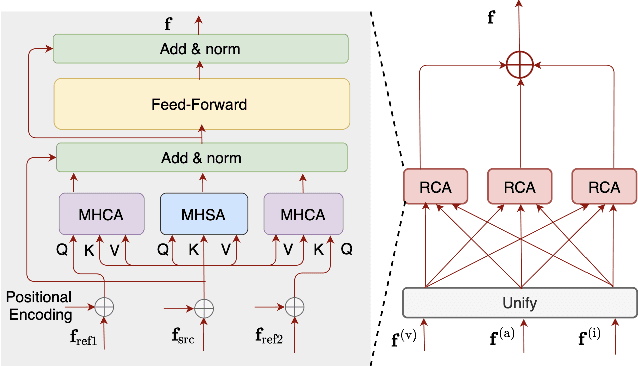
Automatic lyric transcription (ALT) is a nascent field of study attracting increasing interest from both the speech and music information retrieval communities, given its significant application potential. However, ALT with audio data alone is a notoriously difficult task due to instrumental accompaniment and musical constraints resulting in degradation of both the phonetic cues and the intelligibility of sung lyrics. To tackle this challenge, we propose the MultiModal Automatic Lyric Transcription system (MM-ALT), together with a new dataset, N20EM, which consists of audio recordings, videos of lip movements, and inertial measurement unit (IMU) data of an earbud worn by the performing singer. We first adapt the wav2vec 2.0 framework from automatic speech recognition (ASR) to the ALT task. We then propose a video-based ALT method and an IMU-based voice activity detection (VAD) method. In addition, we put forward the Residual Cross Attention (RCA) mechanism to fuse data from the three modalities (i.e., audio, video, and IMU). Experiments show the effectiveness of our proposed MM-ALT system, especially in terms of noise robustness.
Instrument-Independent Dastgah Recognition of Iranian Classical Music Using AzarNet
Jan 09, 2019
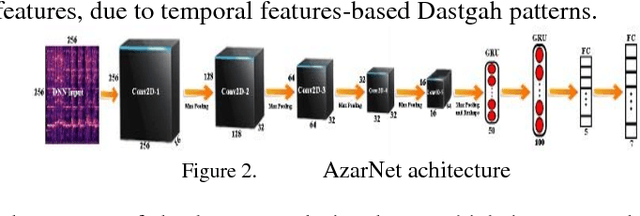
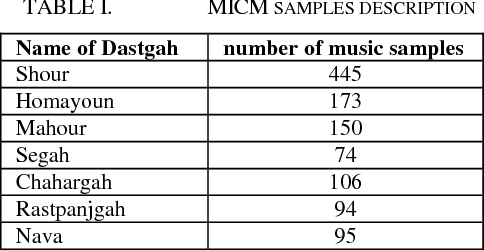
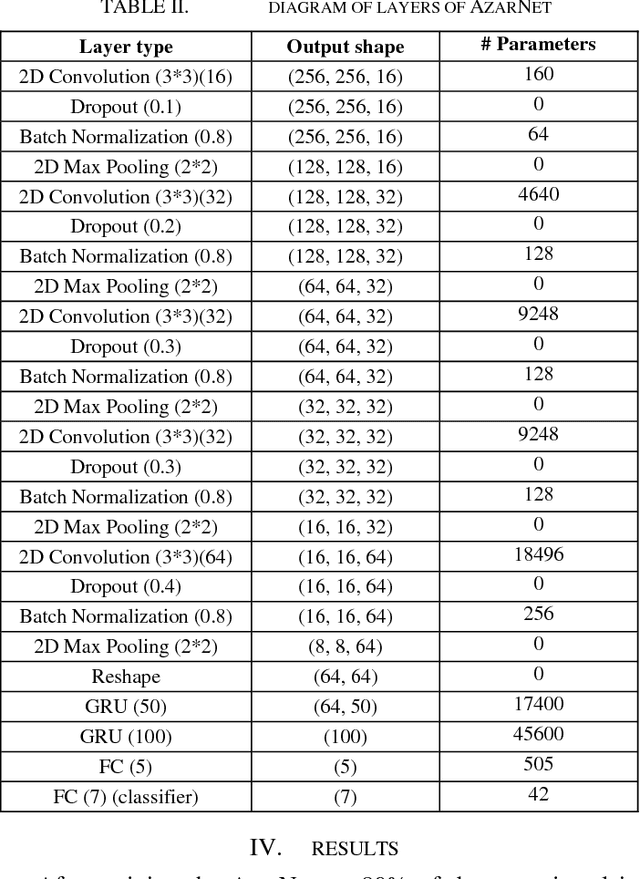
In this paper, AzarNet, a deep neural network (DNN), is proposed to recognizing seven different Dastgahs of Iranian classical music in Maryam Iranian classical music (MICM) dataset. Over the last years, there has been remarkable interest in employing feature learning and DNNs which lead to decreasing the required engineering effort. DNNs have shown better performance in many classification tasks such as audio signal classification compares to shallow processing architectures. Despite image data, audio data need some preprocessing steps to extract spectra and temporal features. Some transformations like Short-Time Fourier Transform (STFT) have been used in the state of art researches to transform audio signals from time-domain to time-frequency domain to extract both temporal and spectra features. In this research, the STFT output results which are extracted features are given to AzarNet for learning and classification processes. It is worth noting that, the mentioned dataset contains music tracks composed with two instruments (violin and straw). The overall f1 score of AzarNet on test set, for average of all seven classes was 86.21% which is the best result ever reported in Dastgah classification according to our best knowledge.
MuseGAN: Multi-track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment
Nov 24, 2017
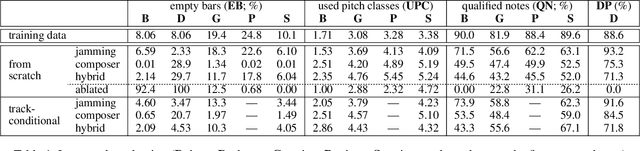
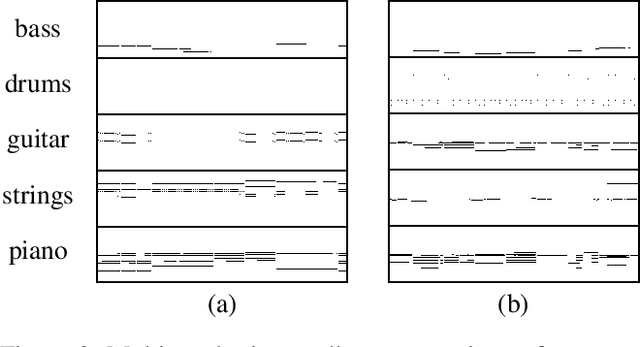
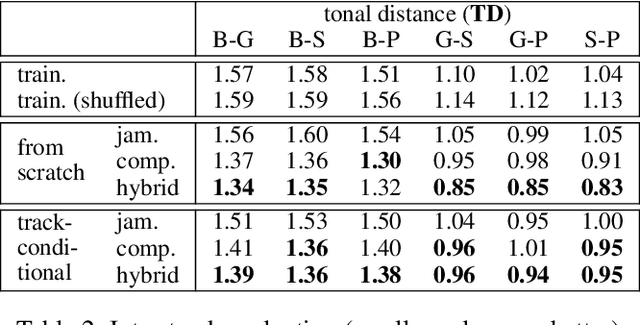
Generating music has a few notable differences from generating images and videos. First, music is an art of time, necessitating a temporal model. Second, music is usually composed of multiple instruments/tracks with their own temporal dynamics, but collectively they unfold over time interdependently. Lastly, musical notes are often grouped into chords, arpeggios or melodies in polyphonic music, and thereby introducing a chronological ordering of notes is not naturally suitable. In this paper, we propose three models for symbolic multi-track music generation under the framework of generative adversarial networks (GANs). The three models, which differ in the underlying assumptions and accordingly the network architectures, are referred to as the jamming model, the composer model and the hybrid model. We trained the proposed models on a dataset of over one hundred thousand bars of rock music and applied them to generate piano-rolls of five tracks: bass, drums, guitar, piano and strings. A few intra-track and inter-track objective metrics are also proposed to evaluate the generative results, in addition to a subjective user study. We show that our models can generate coherent music of four bars right from scratch (i.e. without human inputs). We also extend our models to human-AI cooperative music generation: given a specific track composed by human, we can generate four additional tracks to accompany it. All code, the dataset and the rendered audio samples are available at https://salu133445.github.io/musegan/ .
Music Boundary Detection using Convolutional Neural Networks: A comparative analysis of combined input features
Aug 17, 2020
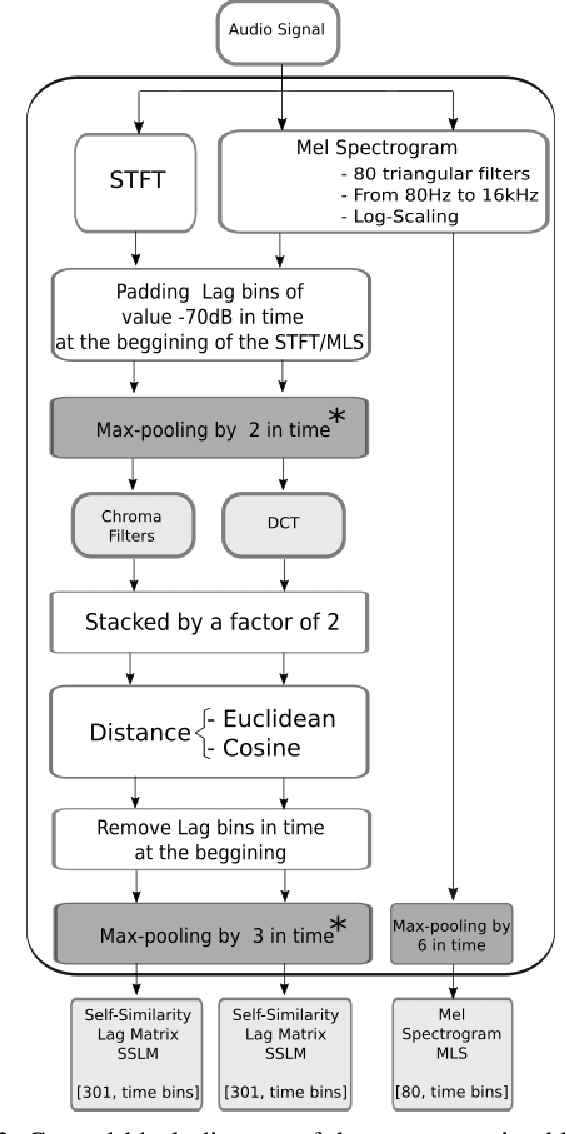
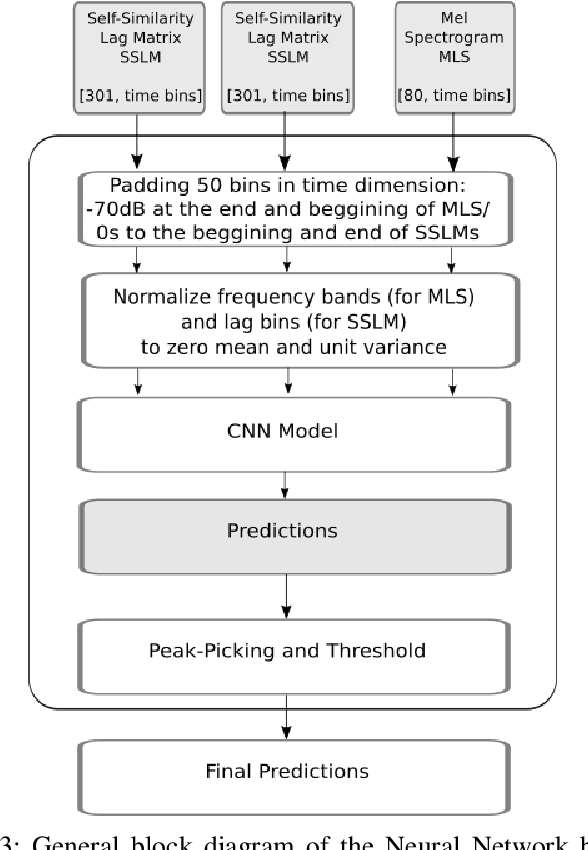
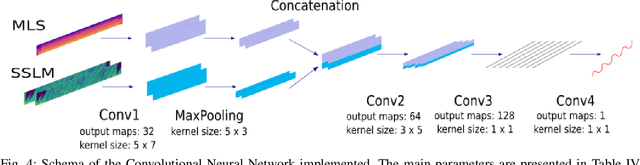
The analysis of the structure of musical pieces is a task that remains a challenge for Artificial Intelligence, especially in the field of Deep Learning. It requires prior identification of structural boundaries of the music pieces. This structural boundary analysis has recently been studied with unsupervised methods and \textit{end-to-end} techniques such as Convolutional Neural Networks (CNN) using Mel-Scaled Log-magnitude Spectograms features (MLS), Self-Similarity Matrices (SSM) or Self-Similarity Lag Matrices (SSLM) as inputs and trained with human annotations. Several studies have been published divided into unsupervised and \textit{end-to-end} methods in which pre-processing is done in different ways, using different distance metrics and audio characteristics, so a generalized pre-processing method to compute model inputs is missing. The objective of this work is to establish a general method of pre-processing these inputs by comparing the inputs calculated from different pooling strategies, distance metrics and audio characteristics, also taking into account the computing time to obtain them. We also establish the most effective combination of inputs to be delivered to the CNN in order to establish the most efficient way to extract the limits of the structure of the music pieces. With an adequate combination of input matrices and pooling strategies we obtain a measurement accuracy $F_1$ of 0.411 that outperforms the current one obtained under the same conditions.
Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals
Jun 22, 2022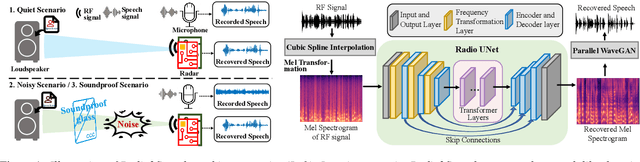
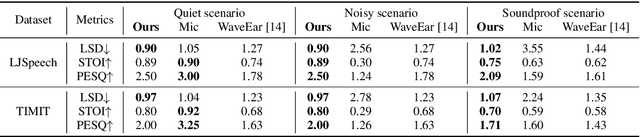

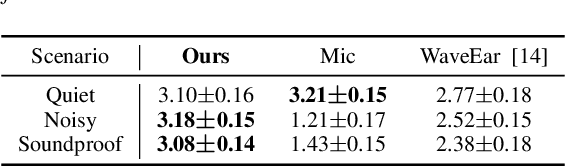
Considering the microphone is easily affected by noise and soundproof materials, the radio frequency (RF) signal is a promising candidate to recover audio as it is immune to noise and can traverse many soundproof objects. In this paper, we introduce Radio2Speech, a system that uses RF signals to recover high quality speech from the loudspeaker. Radio2Speech can recover speech comparable to the quality of the microphone, advancing from recovering only single tone music or incomprehensible speech in existing approaches. We use Radio UNet to accurately recover speech in time-frequency domain from RF signals with limited frequency band. Also, we incorporate the neural vocoder to synthesize the speech waveform from the estimated time-frequency representation without using the contaminated phase. Quantitative and qualitative evaluations show that in quiet, noisy and soundproof scenarios, Radio2Speech achieves state-of-the-art performance and is on par with the microphone that works in quiet scenarios.
Beamforming Feedback-based Model-driven Angle of Departure Estimation Toward Firmware-Agnostic WiFi Sensing
Oct 27, 2021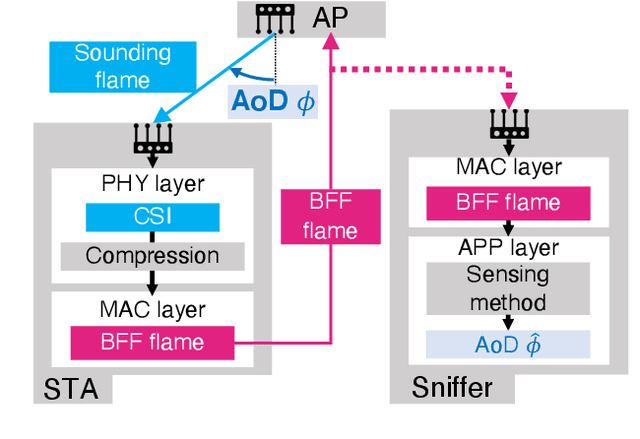
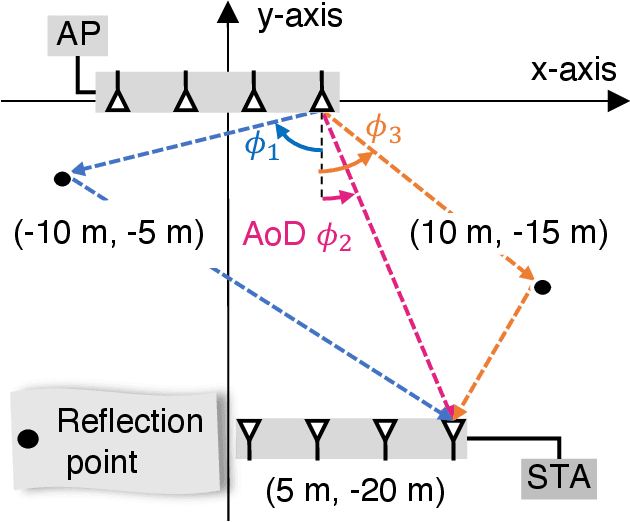
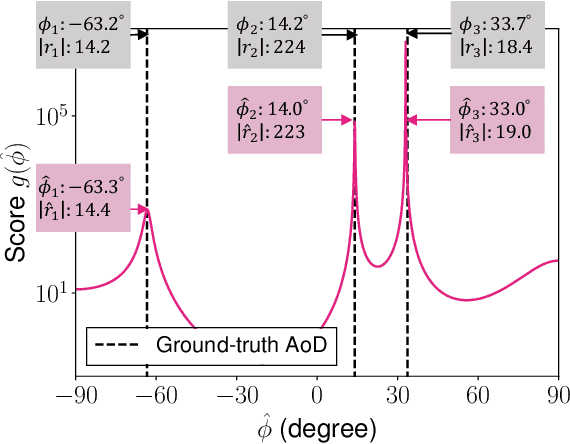
This paper proves that the angle of departure (AoD) estimation using the multiple signal classification (MUSIC) with only WiFi control frames for beamforming feedback (BFF), defined in IEEE 802.11ac/ax, is possible. Although channel state information (CSI) enables model-driven AoD estimation, most BFF-based sensing techniques are data-driven because they only contain the right singular vectors of CSI and subcarrier-averaged stream gain. Specifically, we find that right singular vectors with a subcarrier-averaged stream gain of zero have the same role as the noise subspace vectors in the CSI-based MUSIC algorithm. Numerical evaluations confirm that the proposed BFF-based MUSIC successfully estimates the AoDs and gains for all propagation paths. Meanwhile, this result implies a potential privacy risk; a malicious sniffer can carry out AoD estimation only with unencrypted BFF frames.
Generating Music from Literature
Mar 10, 2014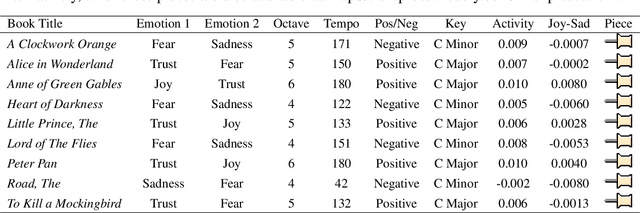
We present a system, TransProse, that automatically generates musical pieces from text. TransProse uses known relations between elements of music such as tempo and scale, and the emotions they evoke. Further, it uses a novel mechanism to determine sequences of notes that capture the emotional activity in the text. The work has applications in information visualization, in creating audio-visual e-books, and in developing music apps.
How Much do Lyrics Matter? Analysing Lyrical Simplicity Preferences for Individuals At Risk of Depression
Sep 15, 2021
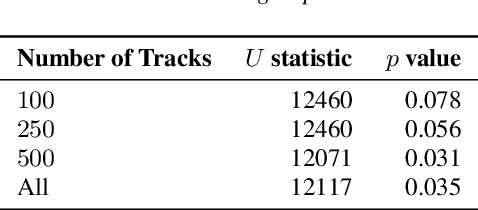
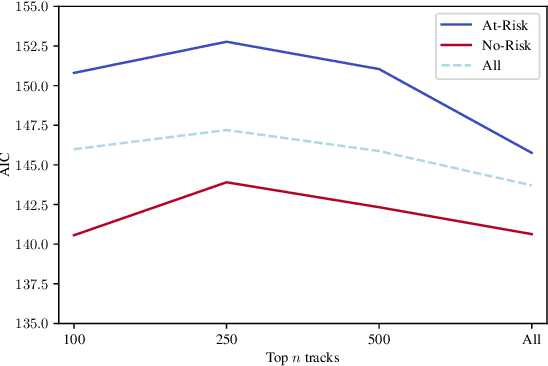
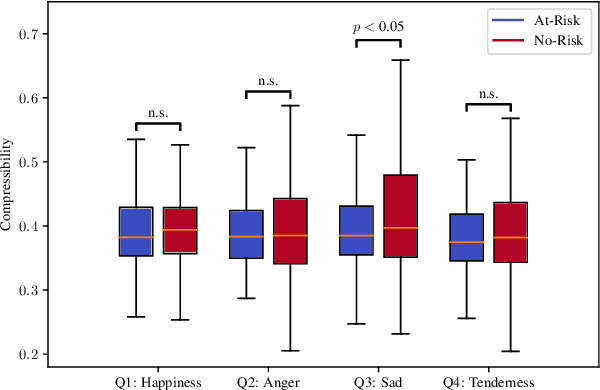
Music affects and in some cases reflects one's emotional state. Key to this influence is lyrics and their meaning in conjunction with the acoustic properties of the track. Recent work has focused on analysing these acoustic properties and showing that individuals prone to depression primarily consume low valence and low energy music. However, no studies yet have explored lyrical content preferences in relation to online music consumption of such individuals. In the current study, we examine lyrical simplicity, measured as the Compressibility and Absolute Information Content of the text, associated with preferences of individuals at risk for depression. Using the six-month listening history of 541 Last.fm users, we compare lyrical simplicity trends for users grouped as being at risk (At-Risk) of depression from those that are not (No-Risk). Our findings reveal that At-Risk individuals prefer songs with greater information content (lower Compressibility) on average, especially for songs characterised as Sad. Furthermore, we found that At-Risk individuals also have greater variability of Absolute Information Content across their listening history. We discuss the results in light of existing socio-psychological lab-based research on music habits associated with depression and their relevance to naturally occurring online music listening behaviour.