 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Attentional networks for music generation
Feb 06, 2020
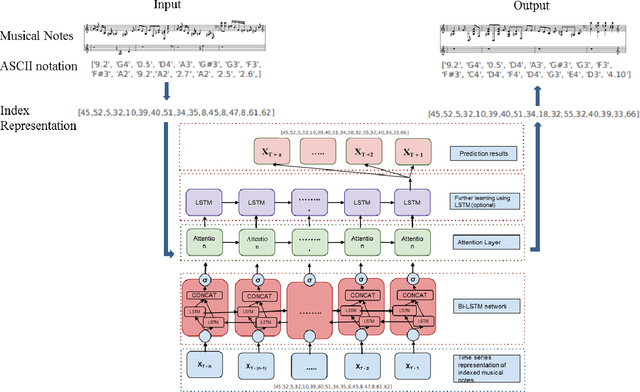
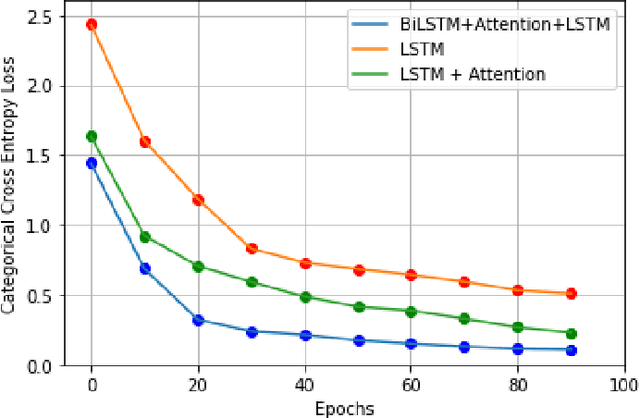
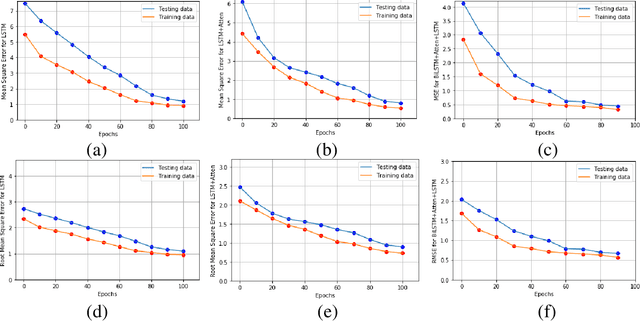
Realistic music generation has always remained as a challenging problem as it may lack structure or rationality. In this work, we propose a deep learning based music generation method in order to produce old style music particularly JAZZ with rehashed melodic structures utilizing a Bi-directional Long Short Term Memory (Bi-LSTM) Neural Network with Attention. Owing to the success in modelling long-term temporal dependencies in sequential data and its success in case of videos, Bi-LSTMs with attention serve as the natural choice and early utilization in music generation. We validate in our experiments that Bi-LSTMs with attention are able to preserve the richness and technical nuances of the music performed.
Research on AI Composition Recognition Based on Music Rules
Oct 15, 2020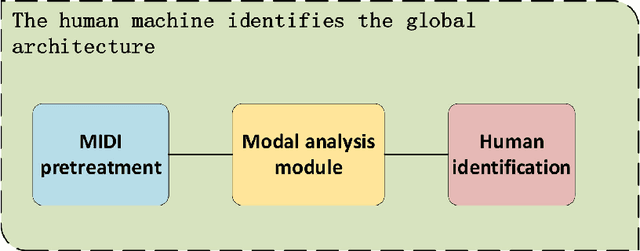
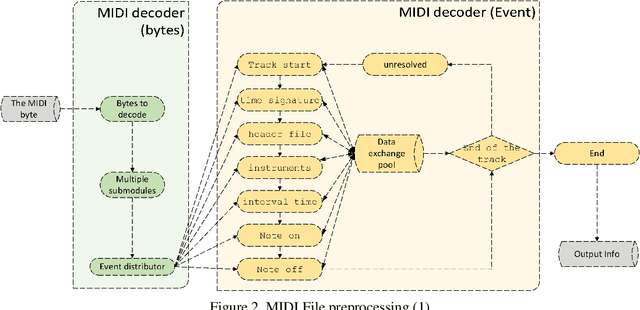
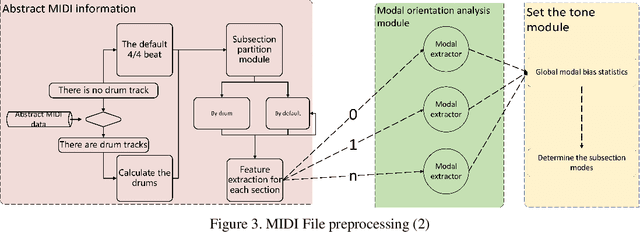
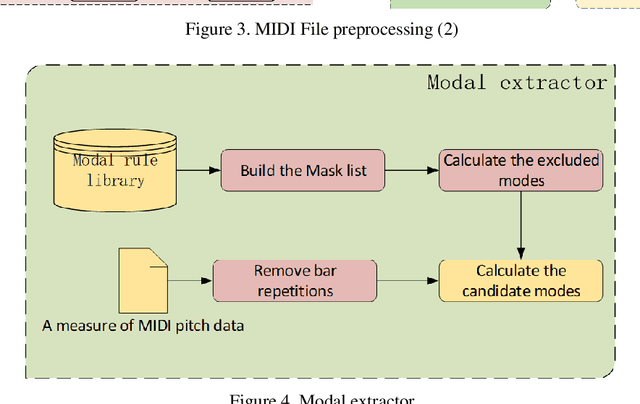
The development of artificial intelligent composition has resulted in the increasing popularity of machine-generated pieces, with frequent copyright disputes consequently emerging. There is an insufficient amount of research on the judgement of artificial and machine-generated works; the creation of a method to identify and distinguish these works is of particular importance. Starting from the essence of the music, the article constructs a music-rule-identifying algorithm through extracting modes, which will identify the stability of the mode of machine-generated music, to judge whether it is artificial intelligent. The evaluation datasets used are provided by the Conference on Sound and Music Technology(CSMT). Experimental results demonstrate the algorithm to have a successful distinguishing ability between datasets with different source distributions. The algorithm will also provide some technological reference to the benign development of the music copyright and artificial intelligent music.
Modeling the Music Genre Perception across Language-Bound Cultures
Oct 13, 2020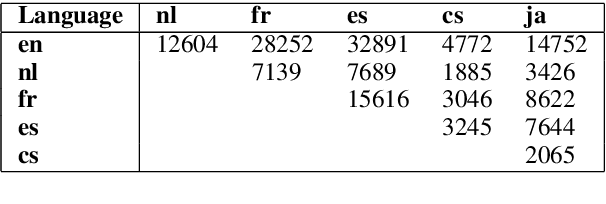
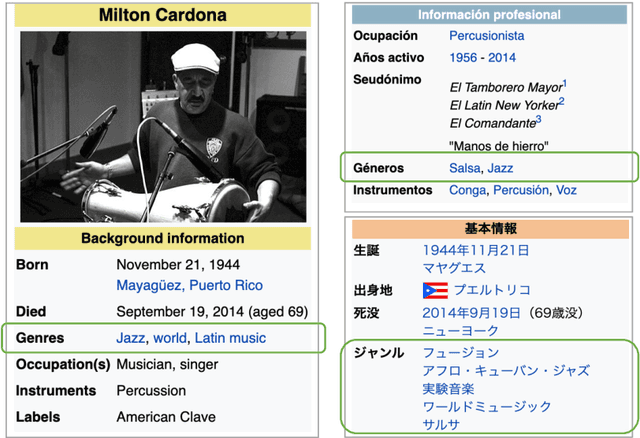
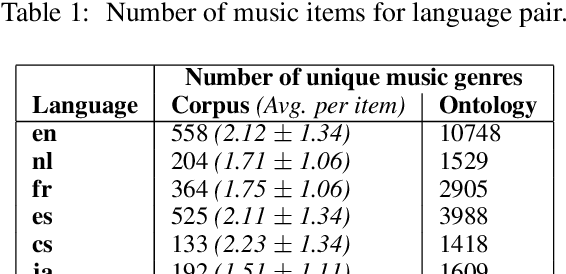
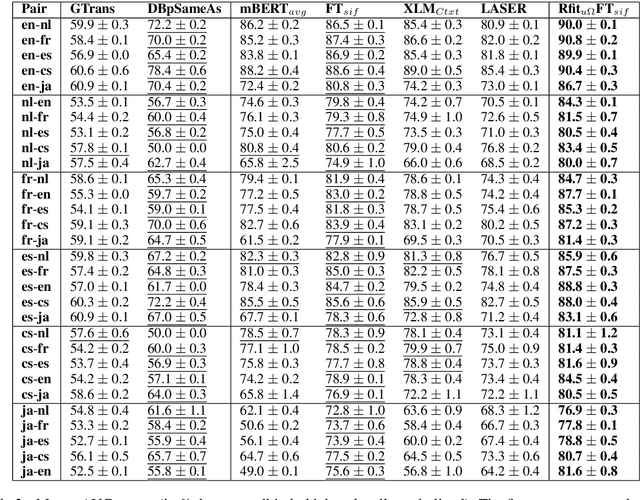
The music genre perception expressed through human annotations of artists or albums varies significantly across language-bound cultures. These variations cannot be modeled as mere translations since we also need to account for cultural differences in the music genre perception. In this work, we study the feasibility of obtaining relevant cross-lingual, culture-specific music genre annotations based only on language-specific semantic representations, namely distributed concept embeddings and ontologies. Our study, focused on six languages, shows that unsupervised cross-lingual music genre annotation is feasible with high accuracy, especially when combining both types of representations. This approach of studying music genres is the most extensive to date and has many implications in musicology and music information retrieval. Besides, we introduce a new, domain-dependent cross-lingual corpus to benchmark state of the art multilingual pre-trained embedding models.
Use Cases for Time-Frequency Image Representations and Deep Learning Techniques for Improved Signal Classification
Feb 22, 2023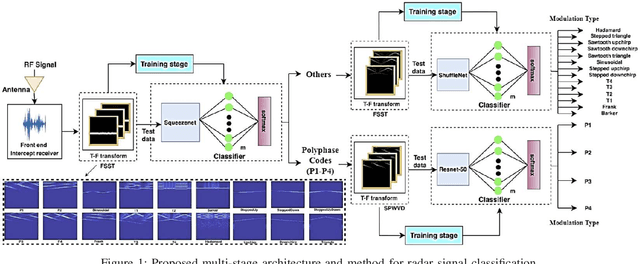
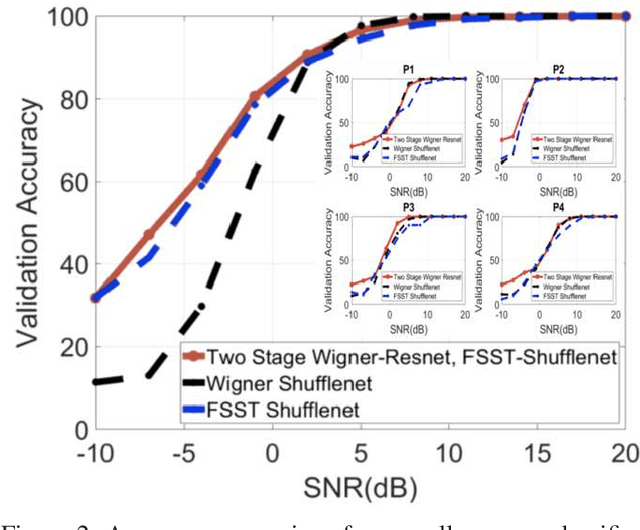
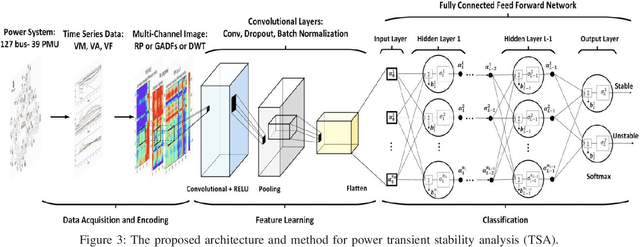
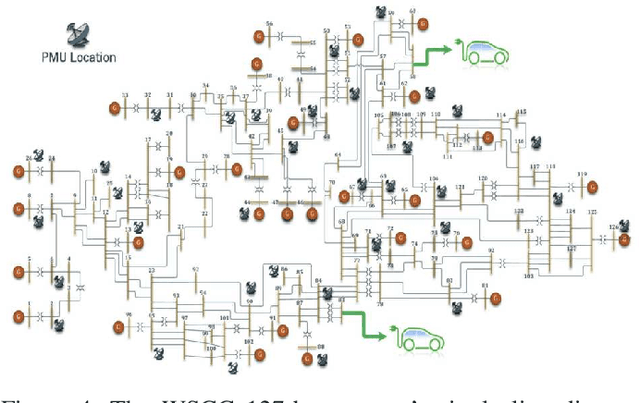
Time-frequency images (TFIs) provide a joint time-frequency representation of a signal and have become an effective tool for analyzing, characterizing, and processing non-stationary signals. Deep learning (DL) techniques have become versatile for signal classification, enabling the automatic extraction of relevant features from raw data. In this paper, we present two use cases on the time-frequency transformation and deep learning techniques for signal classification, where signals are first pre-processed and transformed into TFIs, and their features are then extracted through deep learning neural networks and classification algorithms. The specific methods and algorithms used may vary depending on the particular application, therefore different methods for creating TFIs; the Short-Time Fourier Transform (STFT), Fourier-based Synchrosqueezing Transform (FSST), Wigner Ville distribution (WVD), Smoothed Pseudo-Wigner distribution (SPWD), Choi-Williams distribution (CWD), and Continuous Wavelet Transform (CWT) are investigated. The performance of various deep learning, and convolutional neural network (CNN) models such as ResNet-50, ShuffleNet, and Squeezenet are evaluated for their accuracy of classification in different applications and the results are compared with the results of the conventional machine learning and ensemble methods such as Multilayer Perceptrons (MLP), Support Vector Machine (SVM), Random Forest (RF), Decision Tree (DT), and XGboost. The results of this research demonstrate that significant improvements in signal classification accuracy can be achieved by leveraging the combined power of TFIs, and deep learning models. These advances have found practical applications in a wide range of fields, including radar signal classification, stability analysis of power systems, speech and music recognition, and biomedical signal characterization.
Neural Font Rendering
Nov 29, 2022
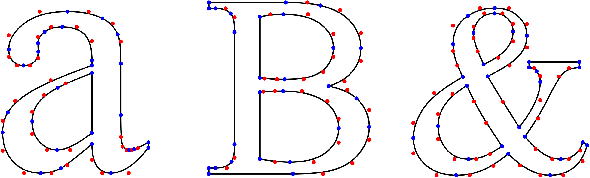

Recent advances in deep learning techniques and applications have revolutionized artistic creation and manipulation in many domains (text, images, music); however, fonts have not yet been integrated with deep learning architectures in a manner that supports their multi-scale nature. In this work we aim to bridge this gap, proposing a network architecture capable of rasterizing glyphs in multiple sizes, potentially paving the way for easy and accessible creation and manipulation of fonts.
Nonnegative Tucker Decomposition with Beta-divergence for Music Structure Analysis of audio signals
Oct 27, 2021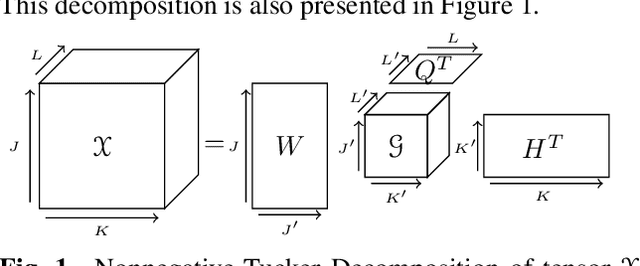
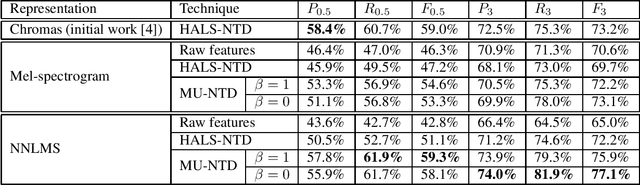

Nonnegative Tucker Decomposition (NTD), a tensor decomposition model, has received increased interest in the recent years because of its ability to blindly extract meaningful patterns in tensor data. Nevertheless, existing algorithms to compute NTD are mostly designed for the Euclidean loss. On the other hand, NTD has recently proven to be a powerful tool in Music Information Retrieval. This work proposes a Multiplicative Updates algorithm to compute NTD with the beta-divergence loss, often considered a better loss for audio processing. We notably show how to implement efficiently the multiplicative rules using tensor algebra, a naive approach being intractable. Finally, we show on a Music Structure Analysis task that unsupervised NTD fitted with beta-divergence loss outperforms earlier results obtained with the Euclidean loss.
The Chamber Ensemble Generator: Limitless High-Quality MIR Data via Generative Modeling
Sep 28, 2022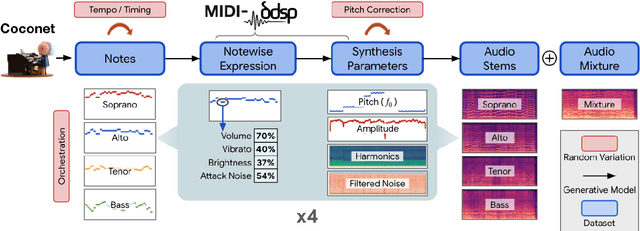
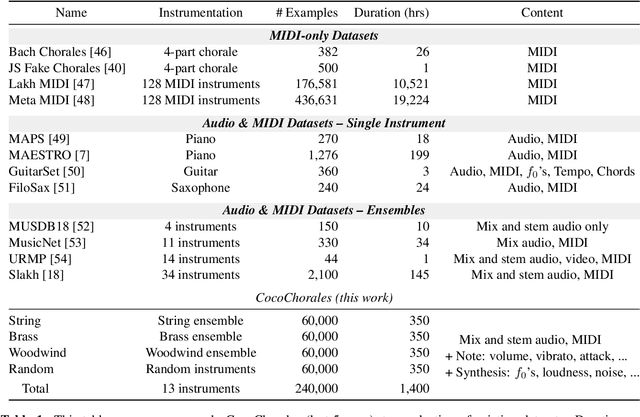
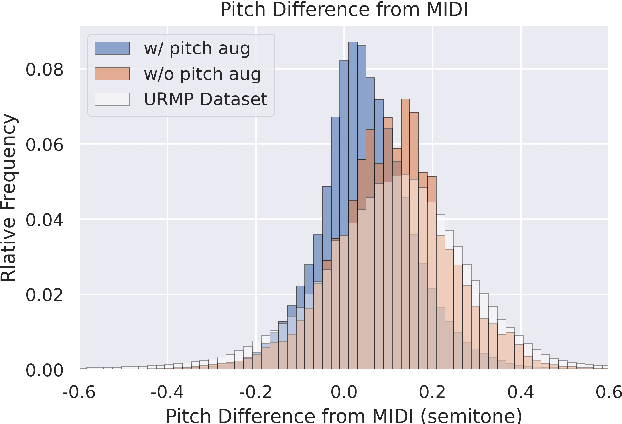
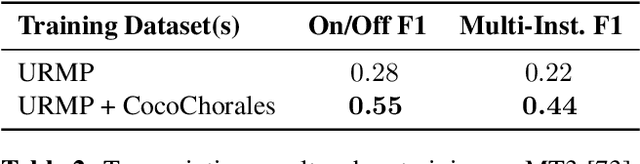
Data is the lifeblood of modern machine learning systems, including for those in Music Information Retrieval (MIR). However, MIR has long been mired by small datasets and unreliable labels. In this work, we propose to break this bottleneck using generative modeling. By pipelining a generative model of notes (Coconet trained on Bach Chorales) with a structured synthesis model of chamber ensembles (MIDI-DDSP trained on URMP), we demonstrate a system capable of producing unlimited amounts of realistic chorale music with rich annotations including mixes, stems, MIDI, note-level performance attributes (staccato, vibrato, etc.), and even fine-grained synthesis parameters (pitch, amplitude, etc.). We call this system the Chamber Ensemble Generator (CEG), and use it to generate a large dataset of chorales from four different chamber ensembles (CocoChorales). We demonstrate that data generated using our approach improves state-of-the-art models for music transcription and source separation, and we release both the system and the dataset as an open-source foundation for future work in the MIR community.
MS-SincResNet: Joint learning of 1D and 2D kernels using multi-scale SincNet and ResNet for music genre classification
Sep 18, 2021
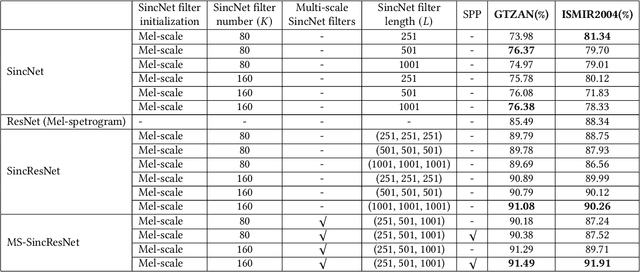
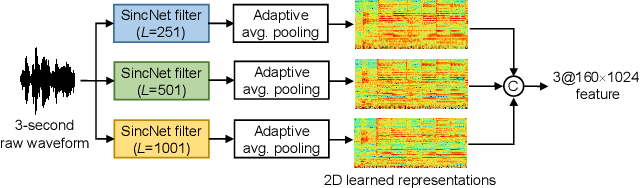
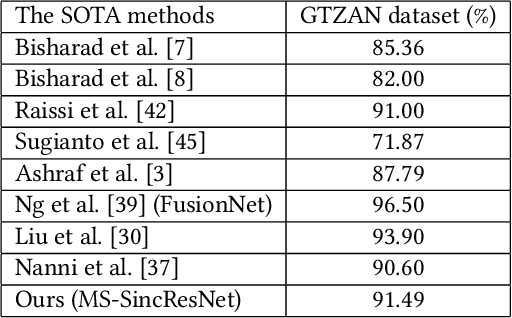
In this study, we proposed a new end-to-end convolutional neural network, called MS-SincResNet, for music genre classification. MS-SincResNet appends 1D multi-scale SincNet (MS-SincNet) to 2D ResNet as the first convolutional layer in an attempt to jointly learn 1D kernels and 2D kernels during the training stage. First, an input music signal is divided into a number of fixed-duration (3 seconds in this study) music clips, and the raw waveform of each music clip is fed into 1D MS-SincNet filter learning module to obtain three-channel 2D representations. The learned representations carry rich timbral, harmonic, and percussive characteristics comparing with spectrograms, harmonic spectrograms, percussive spectrograms and Mel-spectrograms. ResNet is then used to extract discriminative embeddings from these 2D representations. The spatial pyramid pooling (SPP) module is further used to enhance the feature discriminability, in terms of both time and frequency aspects, to obtain the classification label of each music clip. Finally, the voting strategy is applied to summarize the classification results from all 3-second music clips. In our experimental results, we demonstrate that the proposed MS-SincResNet outperforms the baseline SincNet and many well-known hand-crafted features. Considering individual 2D representation, MS-SincResNet also yields competitive results with the state-of-the-art methods on the GTZAN dataset and the ISMIR2004 dataset. The code is available at https://github.com/PeiChunChang/MS-SincResNet
Upsampling layers for music source separation
Nov 23, 2021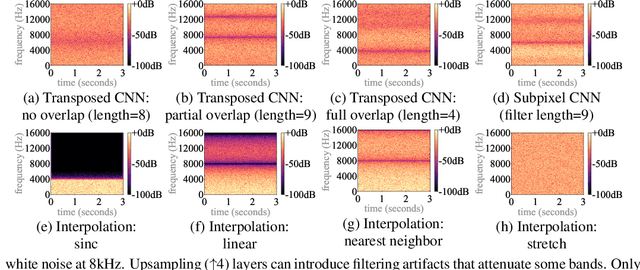
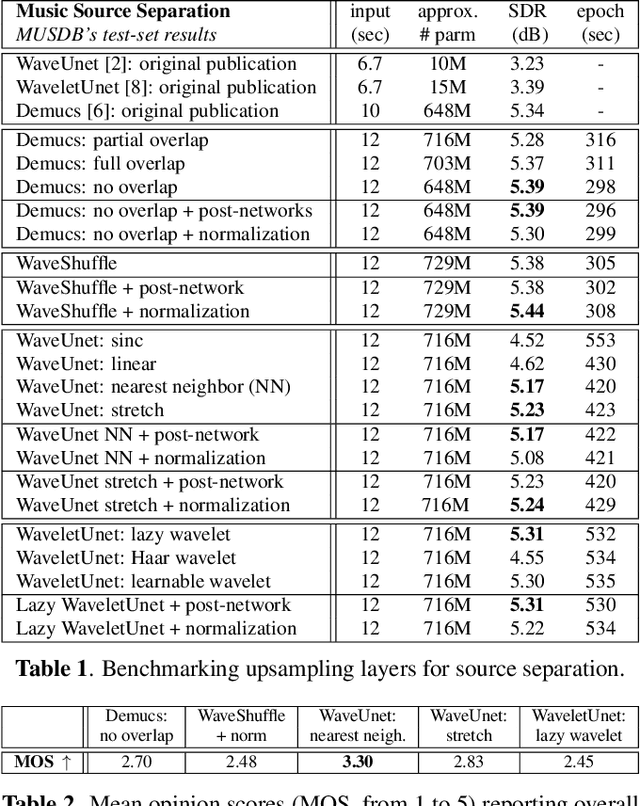

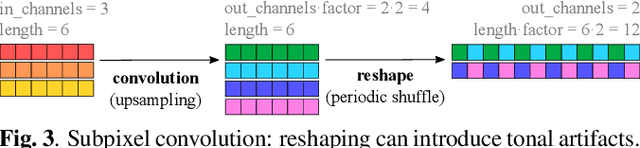
Upsampling artifacts are caused by problematic upsampling layers and due to spectral replicas that emerge while upsampling. Also, depending on the used upsampling layer, such artifacts can either be tonal artifacts (additive high-frequency noise) or filtering artifacts (substractive, attenuating some bands). In this work we investigate the practical implications of having upsampling artifacts in the resulting audio, by studying how different artifacts interact and assessing their impact on the models' performance. To that end, we benchmark a large set of upsampling layers for music source separation: different transposed and subpixel convolution setups, different interpolation upsamplers (including two novel layers based on stretch and sinc interpolation), and different wavelet-based upsamplers (including a novel learnable wavelet layer). Our results show that filtering artifacts, associated with interpolation upsamplers, are perceptually preferrable, even if they tend to achieve worse objective scores.
Use of Variational Inference in Music Emotion Recognition
Jul 09, 2021
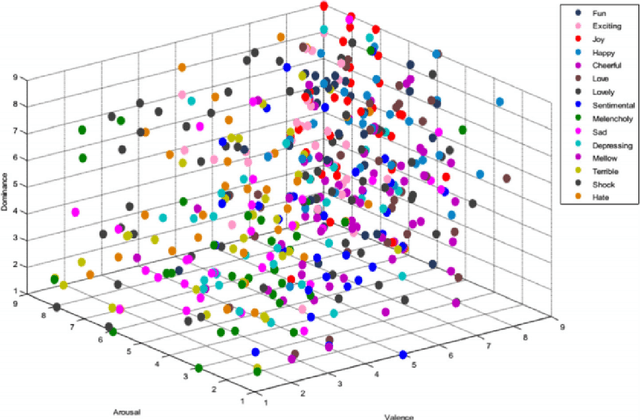
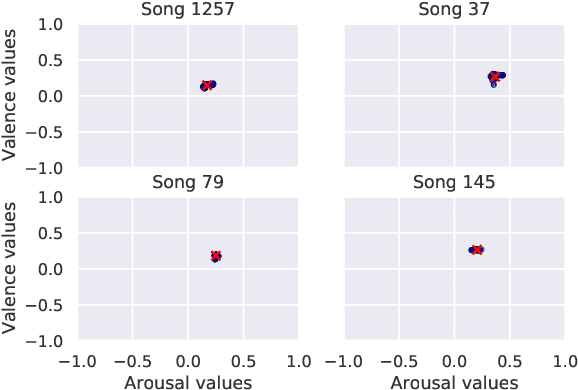
This work was developed aiming to employ Statistical techniques to the field of Music Emotion Recognition, a well-recognized area within the Signal Processing world, but hardly explored from the statistical point of view. Here, we opened several possibilities within the field, applying modern Bayesian Statistics techniques and developing efficient algorithms, focusing on the applicability of the results obtained. Although the motivation for this project was the development of a emotion-based music recommendation system, its main contribution is a highly adaptable multivariate model that can be useful interpreting any database where there is an interest in applying regularization in an efficient manner. Broadly speaking, we will explore what role a sound theoretical statistical analysis can play in the modeling of an algorithm that is able to understand a well-known database and what can be gained with this kind of approach.