 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music generation": models, code, and papers
Melody Structure Transfer Network: Generating Music with Separable Self-Attention
Jul 21, 2021
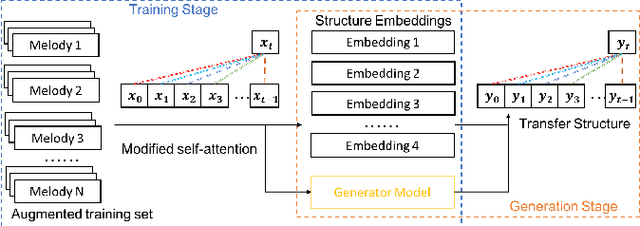
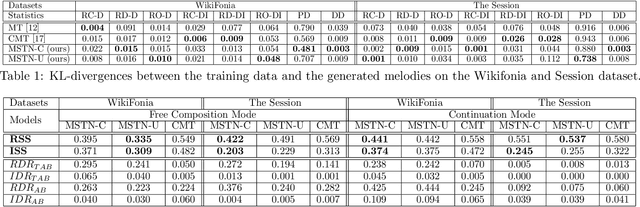
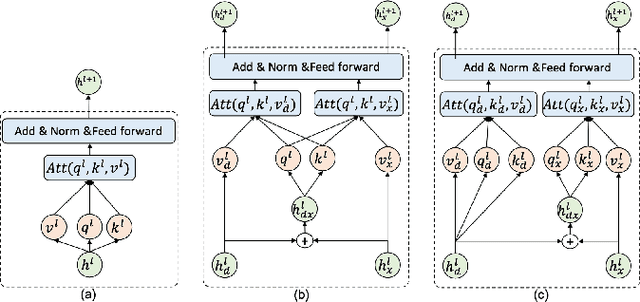
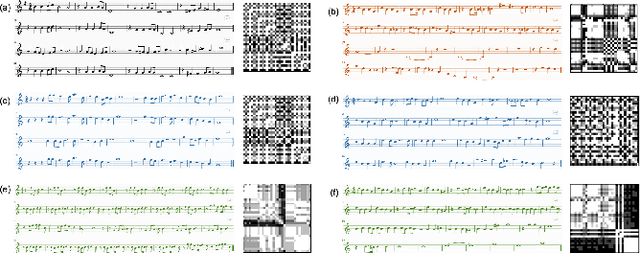
Symbolic music generation has attracted increasing attention, while most methods focus on generating short piece (mostly less than 8 bars, and up to 32 bars). Generating long music calls for effective expression of the coherent music structure. Despite their success on long sequences, self-attention architectures still have challenge in dealing with long-term music as it requires additional care on the subtle music structure. In this paper, we propose to transfer the structure of training samples for new music generation, and develop a novel separable self-attention based model which enable the learning and transferring of the structure embedding. We show that our transfer model can generate music sequences (up to 100 bars) with interpretable structures, which bears similar structures and composition techniques with the template music from training set. Extensive experiments show its ability of generating music with target structure and well diversity. The generated 3,000 sets of music is uploaded as supplemental material.
Evaluation of Latent Space Disentanglement in the Presence of Interdependent Attributes
Oct 11, 2021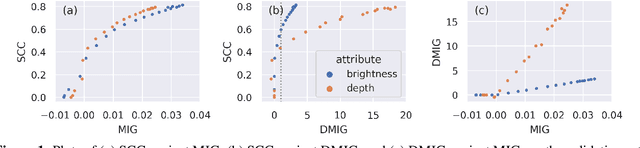
Controllable music generation with deep generative models has become increasingly reliant on disentanglement learning techniques. However, current disentanglement metrics, such as mutual information gap (MIG), are often inadequate and misleading when used for evaluating latent representations in the presence of interdependent semantic attributes often encountered in real-world music datasets. In this work, we propose a dependency-aware information metric as a drop-in replacement for MIG that accounts for the inherent relationship between semantic attributes.
Multi-Source Contrastive Learning from Musical Audio
Feb 14, 2023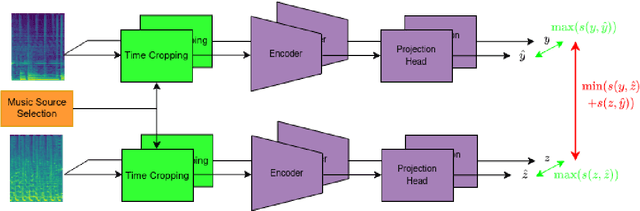
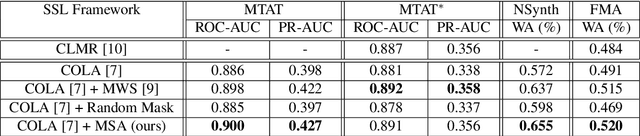
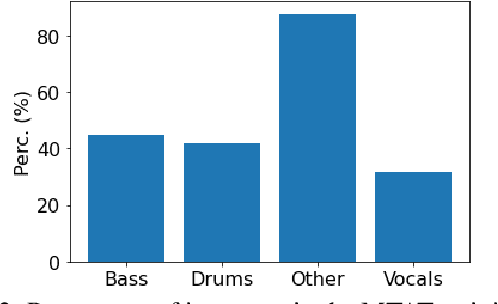
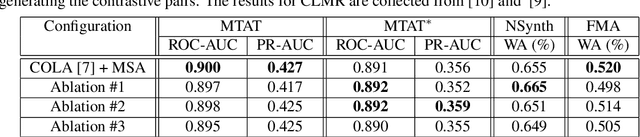
Contrastive learning constitutes an emerging branch of self-supervised learning that leverages large amounts of unlabeled data, by learning a latent space, where pairs of different views of the same sample are associated. In this paper, we propose musical source association as a pair generation strategy in the context of contrastive music representation learning. To this end, we modify COLA, a widely used contrastive learning audio framework, to learn to associate a song excerpt with a stochastically selected and automatically extracted vocal or instrumental source. We further introduce a novel modification to the contrastive loss to incorporate information about the existence or absence of specific sources. Our experimental evaluation in three different downstream tasks (music auto-tagging, instrument classification and music genre classification) using the publicly available Magna-Tag-A-Tune (MTAT) as a source dataset yields competitive results to existing literature methods, as well as faster network convergence. The results also show that this pre-training method can be steered towards specific features, according to the selected musical source, while also being dependent on the quality of the separated sources.
Music Generation with Temporal Structure Augmentation
Apr 21, 2020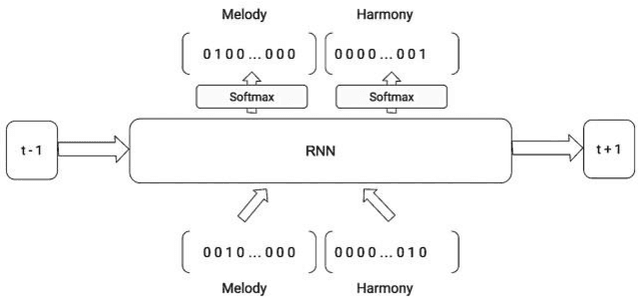
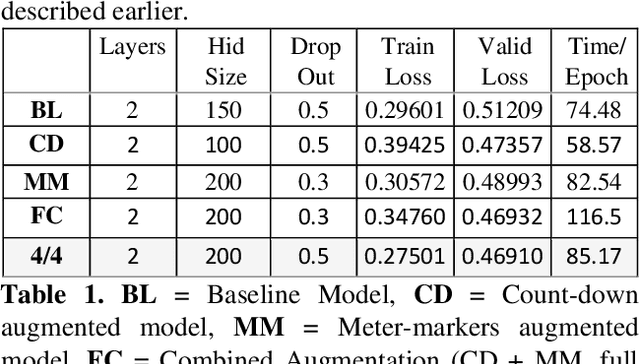
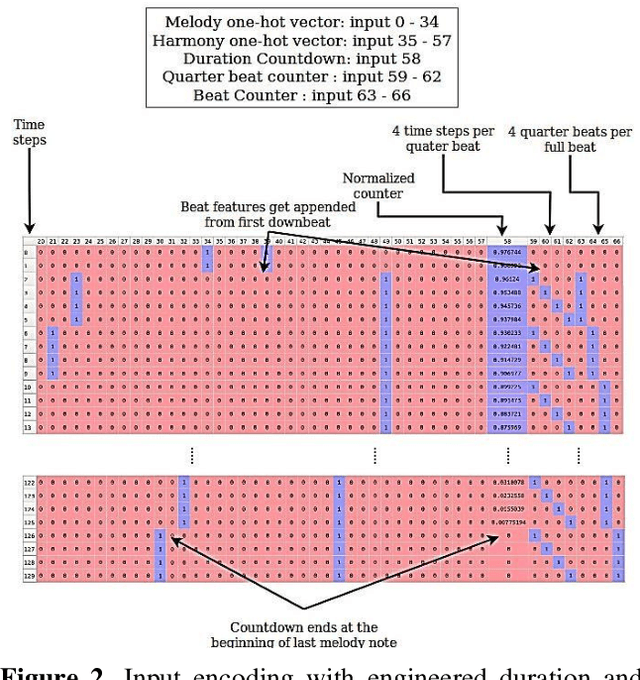
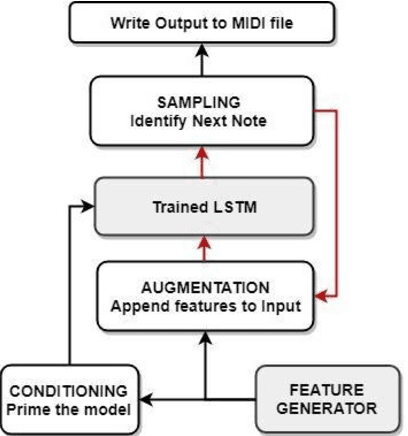
In this paper we introduce a novel feature augmentation approach for generating structured musical compositions comprising melodies and harmonies. The proposed method augments a connectionist generation model with count-down to song conclusion and meter markers as extra input features to study whether neural networks can learn to produce more aesthetically pleasing and structured musical output as a consequence of augmenting the input data with structural features. An RNN architecture with LSTM cells is trained on the Nottingham folk music dataset in a supervised sequence learning setup, following a Music Language Modelling approach, and then applied to generation of harmonies and melodies. Our experiments show an improved prediction performance for both types of annotation. The generated music was also subjectively evaluated using an on-line Turing style listening test which confirms a substantial improvement in the aesthetic quality and in the perceived structure of the music generated using the temporal structure.
MIDI-Sandwich: Multi-model Multi-task Hierarchical Conditional VAE-GAN networks for Symbolic Single-track Music Generation
Jul 04, 2019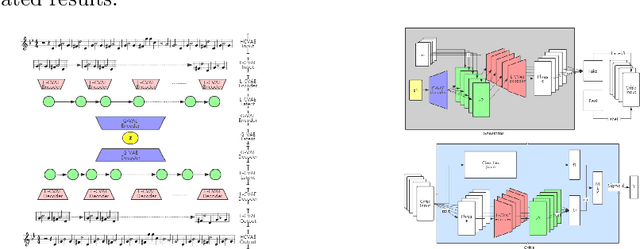
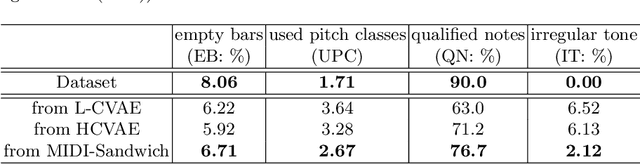
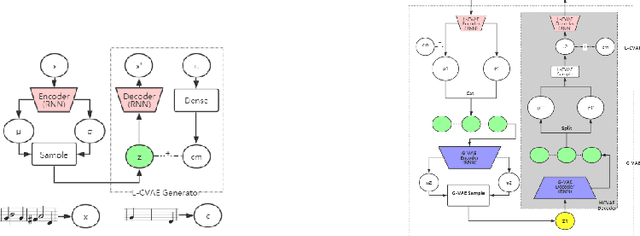
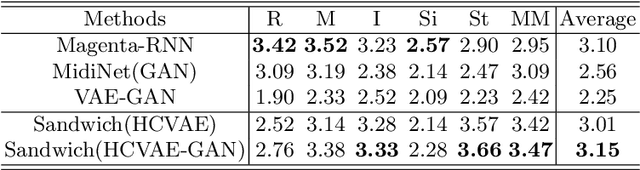
Most existing neural network models for music generation explore how to generate music bars, then directly splice the music bars into a song. However, these methods do not explore the relationship between the bars, and the connected song as a whole has no musical form structure and sense of musical direction. To address this issue, we propose a Multi-model Multi-task Hierarchical Conditional VAE-GAN (Variational Autoencoder-Generative adversarial networks) networks, named MIDI-Sandwich, which combines musical knowledge, such as musical form, tonic, and melodic motion. The MIDI-Sandwich has two submodels: Hierarchical Conditional Variational Autoencoder (HCVAE) and Hierarchical Conditional Generative Adversarial Network (HCGAN). The HCVAE uses hierarchical structure. The underlying layer of HCVAE uses Local Conditional Variational Autoencoder (L-CVAE) to generate a music bar which is pre-specified by the First and Last Notes (FLN). The upper layer of HCVAE uses Global Variational Autoencoder(G-VAE) to analyze the latent vector sequence generated by the L-CVAE encoder, to explore the musical relationship between the bars, and to produce the song pieced together by multiple music bars generated by the L-CVAE decoder, which makes the song both have musical structure and sense of direction. At the same time, the HCVAE shares a part of itself with the HCGAN to further improve the performance of the generated music. The MIDI-Sandwich is validated on the Nottingham dataset and is able to generate a single-track melody sequence (17x8 beats), which is superior to the length of most of the generated models (8 to 32 beats). Meanwhile, by referring to the experimental methods of many classical kinds of literature, the quality evaluation of the generated music is performed. The above experiments prove the validity of the model.
MELONS: generating melody with long-term structure using transformers and structure graph
Nov 03, 2021

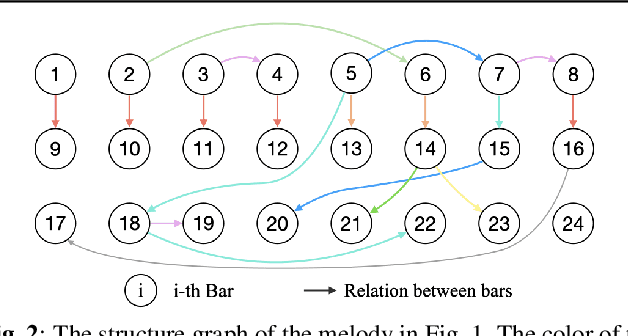
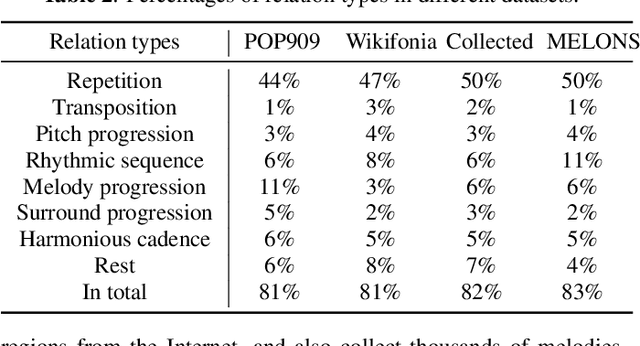
The creation of long melody sequences requires effective expression of coherent musical structure. However, there is no clear representation of musical structure. Recent works on music generation have suggested various approaches to deal with the structural information of music, but generating a full-song melody with clear long-term structure remains a challenge. In this paper, we propose MELONS, a melody generation framework based on a graph representation of music structure which consists of eight types of bar-level relations. MELONS adopts a multi-step generation method with transformer-based networks by factoring melody generation into two sub-problems: structure generation and structure conditional melody generation. Experimental results show that MELONS can produce structured melodies with high quality and rich contents.
EmotionBox: a music-element-driven emotional music generation system using Recurrent Neural Network
Dec 16, 2021
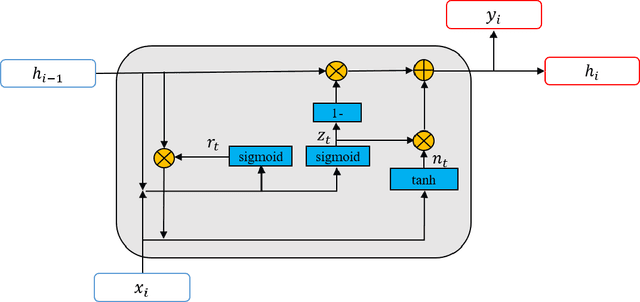
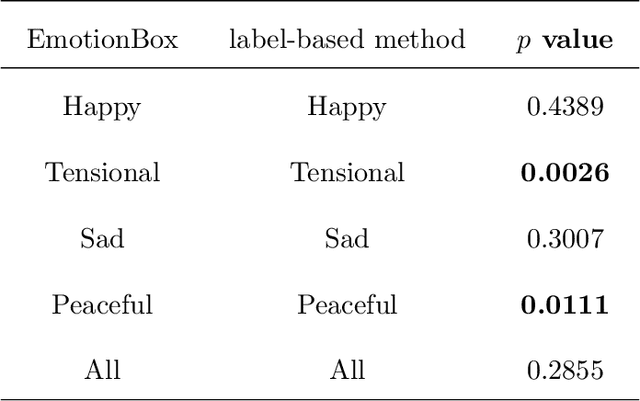
With the development of deep neural networks, automatic music composition has made great progress. Although emotional music can evoke listeners' different emotions and it is important for artistic expression, only few researches have focused on generating emotional music. This paper presents EmotionBox -an music-element-driven emotional music generator that is capable of composing music given a specific emotion, where this model does not require a music dataset labeled with emotions. Instead, pitch histogram and note density are extracted as features that represent mode and tempo respectively to control music emotions. The subjective listening tests show that the Emotionbox has a more competitive and balanced performance in arousing a specified emotion than the emotion-label-based method.
Is Disentanglement enough? On Latent Representations for Controllable Music Generation
Aug 01, 2021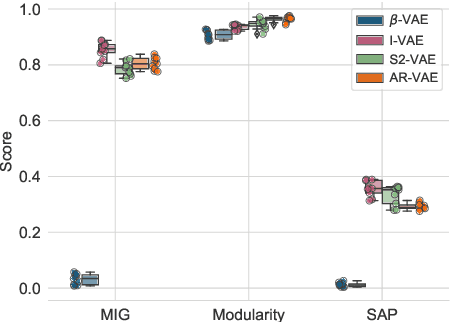
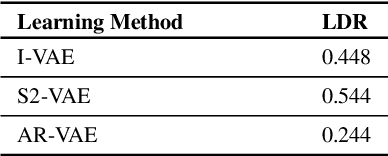
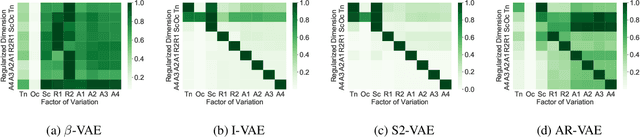
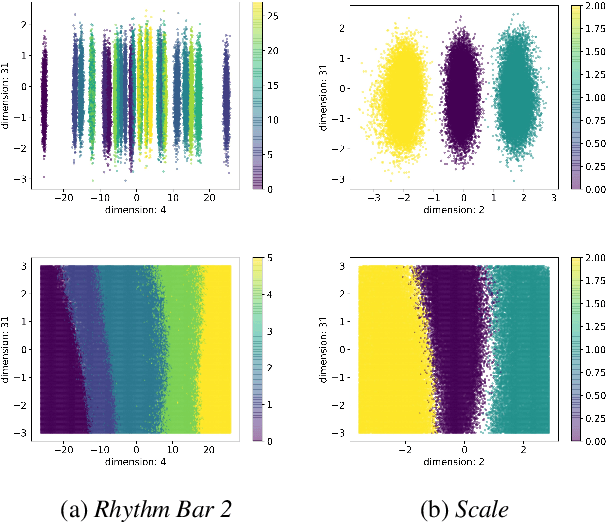
Improving controllability or the ability to manipulate one or more attributes of the generated data has become a topic of interest in the context of deep generative models of music. Recent attempts in this direction have relied on learning disentangled representations from data such that the underlying factors of variation are well separated. In this paper, we focus on the relationship between disentanglement and controllability by conducting a systematic study using different supervised disentanglement learning algorithms based on the Variational Auto-Encoder (VAE) architecture. Our experiments show that a high degree of disentanglement can be achieved by using different forms of supervision to train a strong discriminative encoder. However, in the absence of a strong generative decoder, disentanglement does not necessarily imply controllability. The structure of the latent space with respect to the VAE-decoder plays an important role in boosting the ability of a generative model to manipulate different attributes. To this end, we also propose methods and metrics to help evaluate the quality of a latent space with respect to the afforded degree of controllability.