 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMelody Structure Transfer Network: Generating Music with Separable Self-Attention
Paper and Code
Jul 21, 2021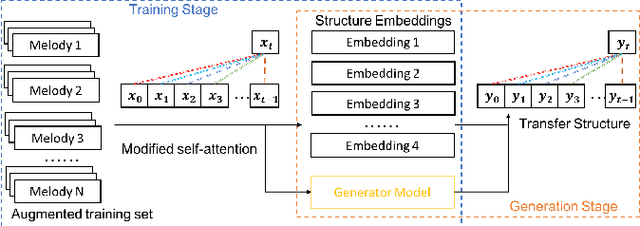
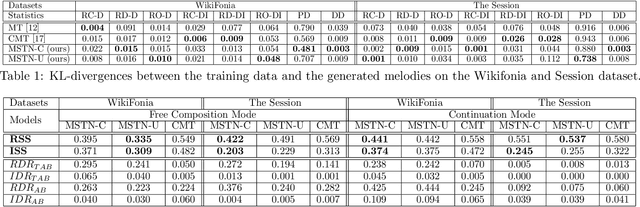
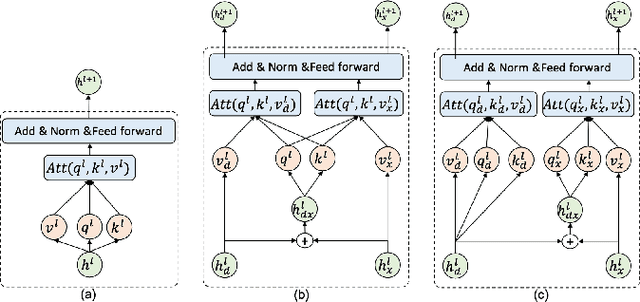
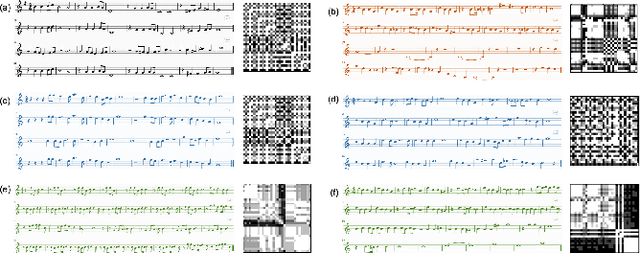
Symbolic music generation has attracted increasing attention, while most methods focus on generating short piece (mostly less than 8 bars, and up to 32 bars). Generating long music calls for effective expression of the coherent music structure. Despite their success on long sequences, self-attention architectures still have challenge in dealing with long-term music as it requires additional care on the subtle music structure. In this paper, we propose to transfer the structure of training samples for new music generation, and develop a novel separable self-attention based model which enable the learning and transferring of the structure embedding. We show that our transfer model can generate music sequences (up to 100 bars) with interpretable structures, which bears similar structures and composition techniques with the template music from training set. Extensive experiments show its ability of generating music with target structure and well diversity. The generated 3,000 sets of music is uploaded as supplemental material.