 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Differential Generative Adversarial Networks: Synthesizing Non-linear Facial Variations with Limited Number of Training Data
Dec 29, 2017
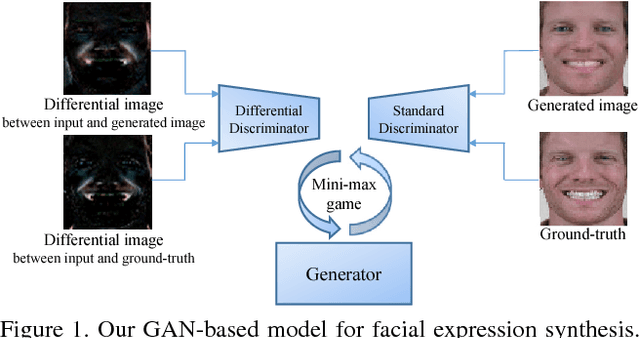
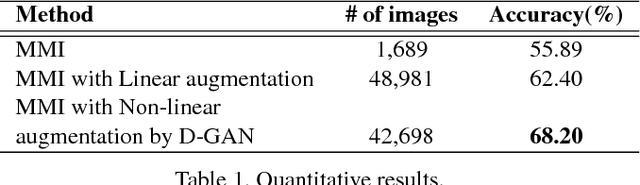
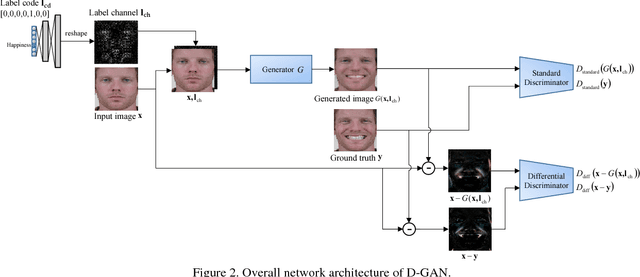

In face-related applications with a public available dataset, synthesizing non-linear facial variations (e.g., facial expression, head-pose, illumination, etc.) through a generative model is helpful in addressing the lack of training data. In reality, however, there is insufficient data to even train the generative model for face synthesis. In this paper, we propose Differential Generative Adversarial Networks (D-GAN) that can perform photo-realistic face synthesis even when training data is small. Two discriminators are devised to ensure the generator to approximate a face manifold, which can express face changes as it wants. Experimental results demonstrate that the proposed method is robust to the amount of training data and synthesized images are useful to improve the performance of a face expression classifier.
Responsible AI: Gender bias assessment in emotion recognition
Mar 21, 2021
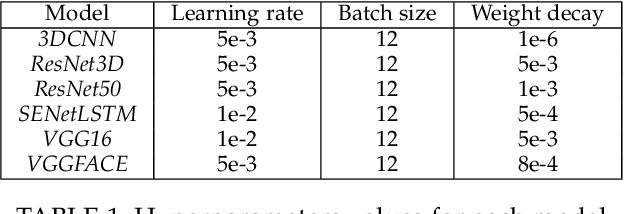

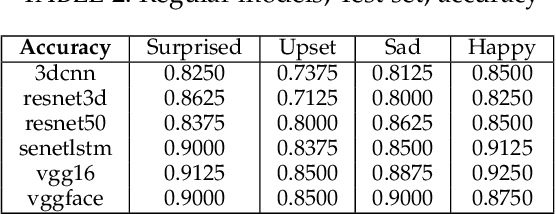
Rapid development of artificial intelligence (AI) systems amplify many concerns in society. These AI algorithms inherit different biases from humans due to mysterious operational flow and because of that it is becoming adverse in usage. As a result, researchers have started to address the issue by investigating deeper in the direction towards Responsible and Explainable AI. Among variety of applications of AI, facial expression recognition might not be the most important one, yet is considered as a valuable part of human-AI interaction. Evolution of facial expression recognition from the feature based methods to deep learning drastically improve quality of such algorithms. This research work aims to study a gender bias in deep learning methods for facial expression recognition by investigating six distinct neural networks, training them, and further analysed on the presence of bias, according to the three definition of fairness. The main outcomes show which models are gender biased, which are not and how gender of subject affects its emotion recognition. More biased neural networks show bigger accuracy gap in emotion recognition between male and female test sets. Furthermore, this trend keeps for true positive and false positive rates. In addition, due to the nature of the research, we can observe which types of emotions are better classified for men and which for women. Since the topic of biases in facial expression recognition is not well studied, a spectrum of continuation of this research is truly extensive, and may comprise detail analysis of state-of-the-art methods, as well as targeting other biases.
3D Lip Event Detection via Interframe Motion Divergence at Multiple Temporal Resolutions
Nov 18, 2021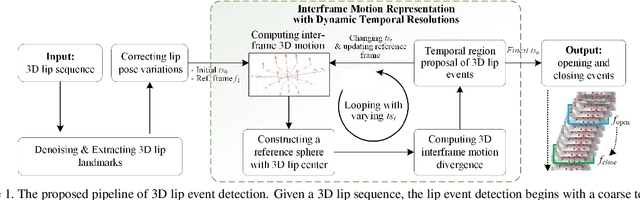
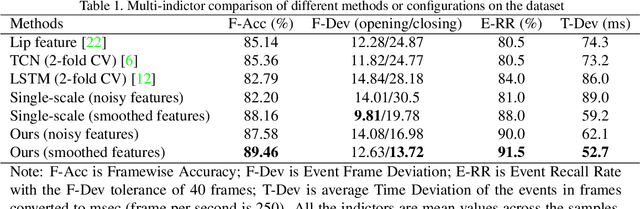
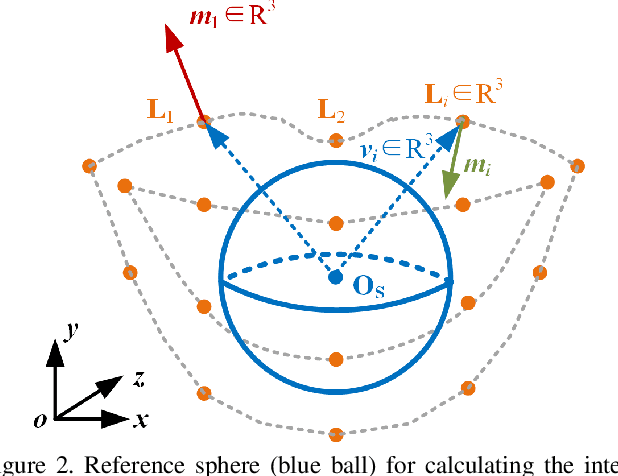
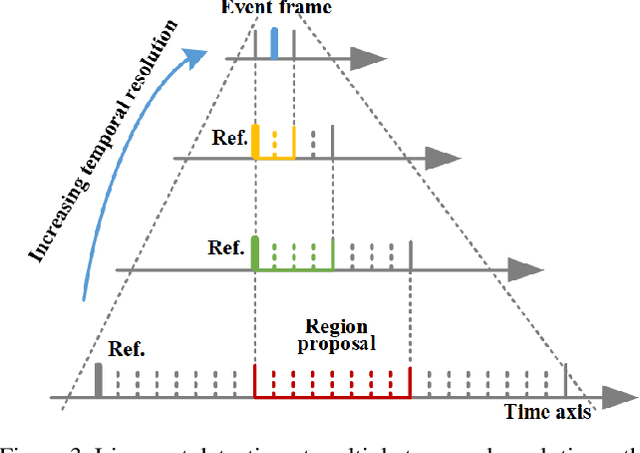
The lip is a dominant dynamic facial unit when a person is speaking. Detecting lip events is beneficial to speech analysis and support for the hearing impaired. This paper proposes a 3D lip event detection pipeline that automatically determines the lip events from a 3D speaking lip sequence. We define a motion divergence measure using 3D lip landmarks to quantify the interframe dynamics of a 3D speaking lip. Then, we cast the interframe motion detection in a multi-temporal-resolution framework that allows the detection to be applicable to different speaking speeds. The experiments on the S3DFM Dataset investigate the overall 3D lip dynamics based on the proposed motion divergence. The proposed 3D pipeline is able to detect opening and closing lip events across 100 sequences, achieving a state-of-the-art performance.
Sparse Coding of Shape Trajectories for Facial Expression and Action Recognition
Aug 08, 2019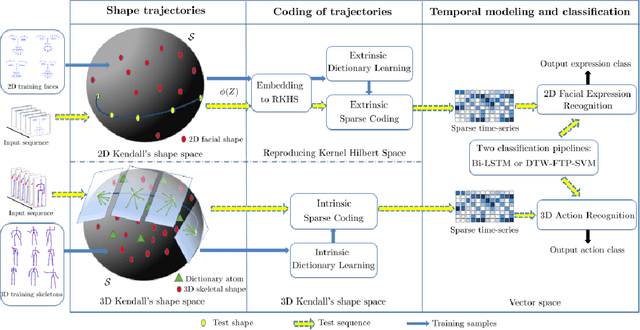
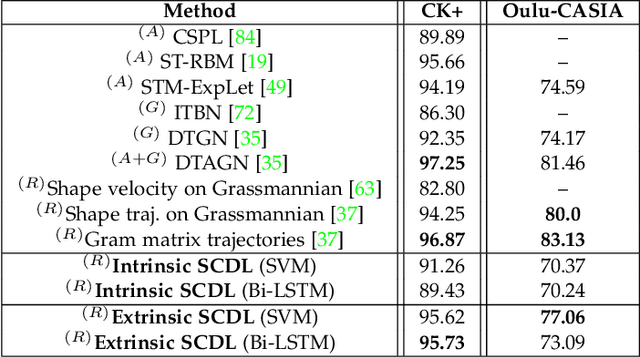
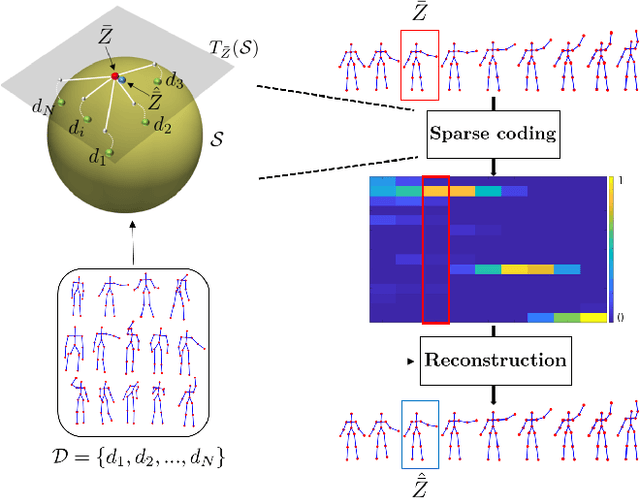
The detection and tracking of human landmarks in video streams has gained in reliability partly due to the availability of affordable RGB-D sensors. The analysis of such time-varying geometric data is playing an important role in the automatic human behavior understanding. However, suitable shape representations as well as their temporal evolution, termed trajectories, often lie to nonlinear manifolds. This puts an additional constraint (i.e., nonlinearity) in using conventional Machine Learning techniques. As a solution, this paper accommodates the well-known Sparse Coding and Dictionary Learning approach to study time-varying shapes on the Kendall shape spaces of 2D and 3D landmarks. We illustrate effective coding of 3D skeletal sequences for action recognition and 2D facial landmark sequences for macro- and micro-expression recognition. To overcome the inherent nonlinearity of the shape spaces, intrinsic and extrinsic solutions were explored. As main results, shape trajectories give rise to more discriminative time-series with suitable computational properties, including sparsity and vector space structure. Extensive experiments conducted on commonly-used datasets demonstrate the competitiveness of the proposed approaches with respect to state-of-the-art.
* 14 pages, 5 figures
MorphGAN: One-Shot Face Synthesis GAN for Detecting Recognition Bias
Dec 10, 2020
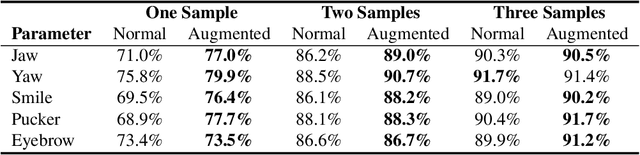
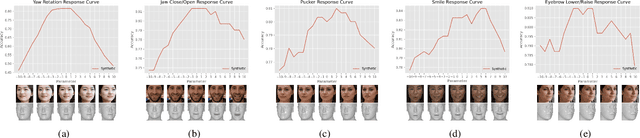

To detect bias in face recognition networks, it can be useful to probe a network under test using samples in which only specific attributes vary in some controlled way. However, capturing a sufficiently large dataset with specific control over the attributes of interest is difficult. In this work, we describe a simulator that applies specific head pose and facial expression adjustments to images of previously unseen people. The simulator first fits a 3D morphable model to a provided image, applies the desired head pose and facial expression controls, then renders the model into an image. Next, a conditional Generative Adversarial Network (GAN) conditioned on the original image and the rendered morphable model is used to produce the image of the original person with the new facial expression and head pose. We call this conditional GAN -- MorphGAN. Images generated using MorphGAN conserve the identity of the person in the original image, and the provided control over head pose and facial expression allows test sets to be created to identify robustness issues of a facial recognition deep network with respect to pose and expression. Images generated by MorphGAN can also serve as data augmentation when training data are scarce. We show that by augmenting small datasets of faces with new poses and expressions improves the recognition performance by up to 9% depending on the augmentation and data scarcity.
Coherence Constraints in Facial Expression Recognition
Oct 17, 2018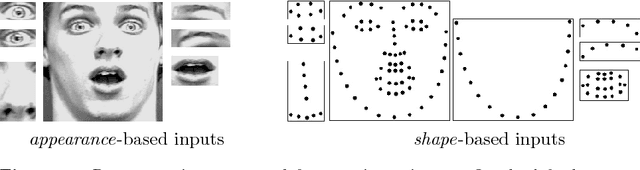
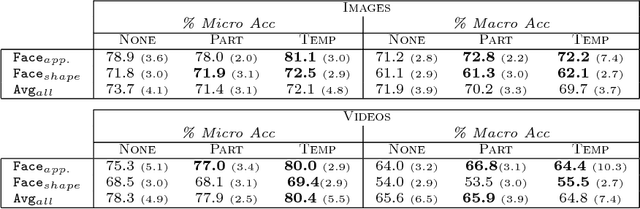
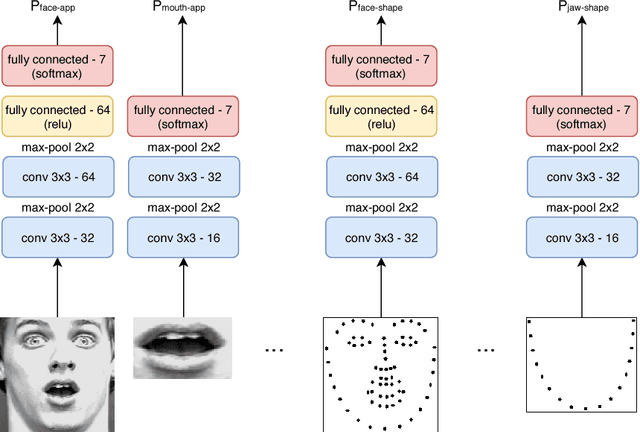
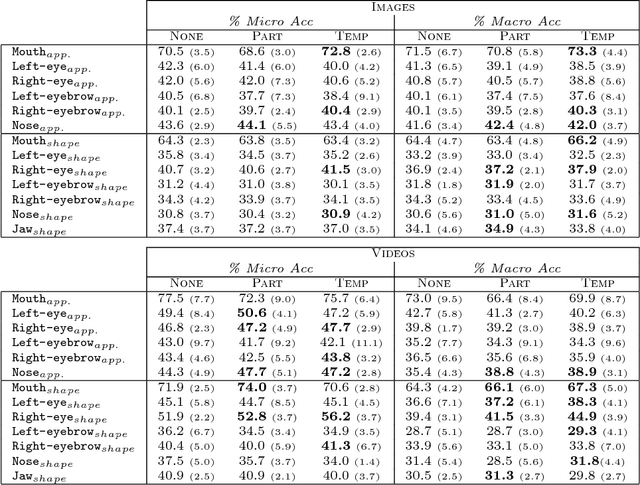
Recognizing facial expressions from static images or video sequences is a widely studied but still challenging problem. The recent progresses obtained by deep neural architectures, or by ensembles of heterogeneous models, have shown that integrating multiple input representations leads to state-of-the-art results. In particular, the appearance and the shape of the input face, or the representations of some face parts, are commonly used to boost the quality of the recognizer. This paper investigates the application of Convolutional Neural Networks (CNNs) with the aim of building a versatile recognizer of expressions in static images that can be further applied to video sequences. We first study the importance of different face parts in the recognition task, focussing on appearance and shape-related features. Then we cast the learning problem in the Semi-Supervised setting, exploiting video data, where only a few frames are supervised. The unsupervised portion of the training data is used to enforce three types of coherence, namely temporal coherence, coherence among the predictions on the face parts and coherence between appearance and shape-based representation. Our experimental analysis shows that coherence constraints can improve the quality of the expression recognizer, thus offering a suitable basis to profitably exploit unsupervised video sequences. Finally we present some examples with occlusions where the shape-based predictor performs better than the appearance one.
Facial Surface Analysis using Iso-Geodesic Curves in Three Dimensional Face Recognition System
Aug 31, 2016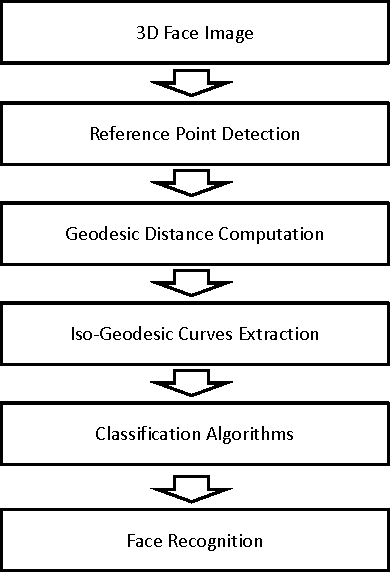
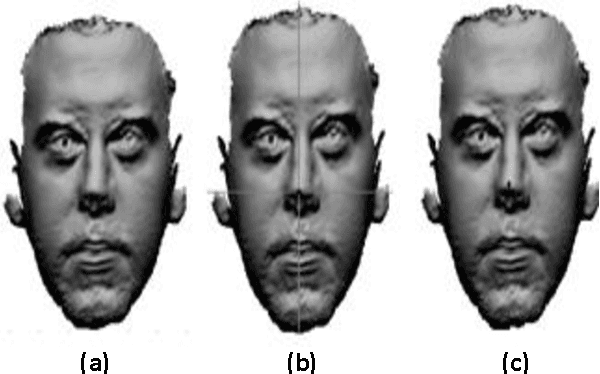


In this paper, we present an automatic 3D face recognition system. This system is based on the representation of human faces surfaces as collections of Iso-Geodesic Curves (IGC) using 3D Fast Marching algorithm. To compare two facial surfaces, we compute a geodesic distance between a pair of facial curves using a Riemannian geometry. In the classifying step, we use: Neural Networks (NN), K-Nearest Neighbor (KNN) and Support Vector Machines (SVM). To test this method and evaluate its performance, a simulation series of experiments were performed on 3D Shape REtrieval Contest 2008 database (SHREC2008).
WarpedGANSpace: Finding non-linear RBF paths in GAN latent space
Sep 27, 2021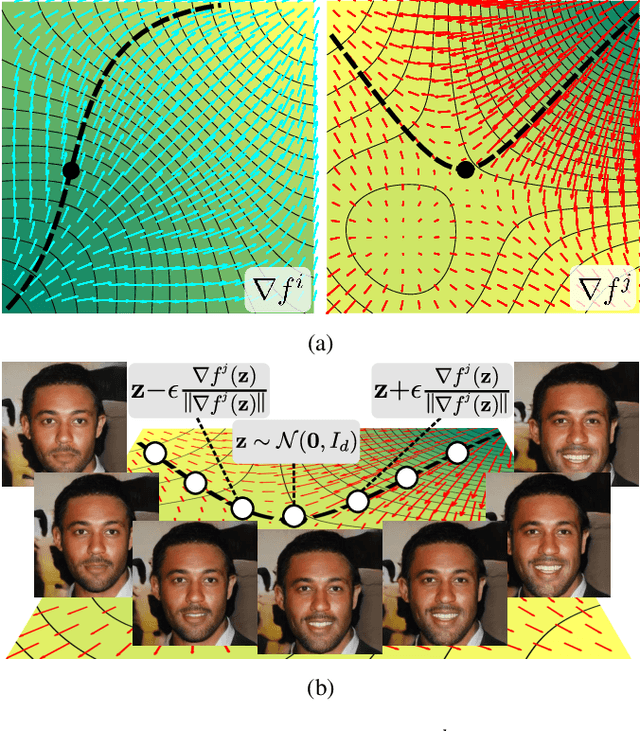
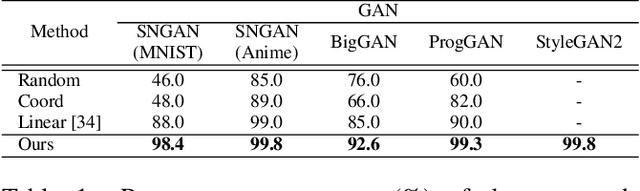
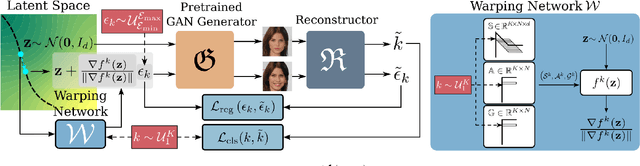
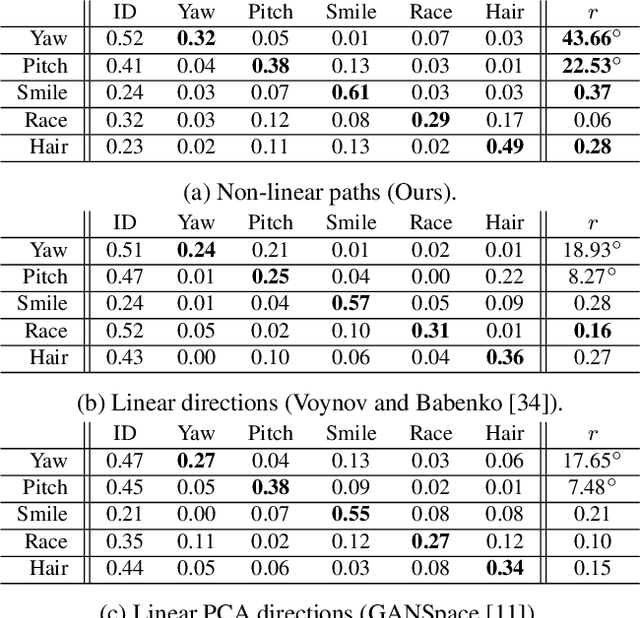
This work addresses the problem of discovering, in an unsupervised manner, interpretable paths in the latent space of pretrained GANs, so as to provide an intuitive and easy way of controlling the underlying generative factors. In doing so, it addresses some of the limitations of the state-of-the-art works, namely, a) that they discover directions that are independent of the latent code, i.e., paths that are linear, and b) that their evaluation relies either on visual inspection or on laborious human labeling. More specifically, we propose to learn non-linear warpings on the latent space, each one parametrized by a set of RBF-based latent space warping functions, and where each warping gives rise to a family of non-linear paths via the gradient of the function. Building on the work of Voynov and Babenko, that discovers linear paths, we optimize the trainable parameters of the set of RBFs, so as that images that are generated by codes along different paths, are easily distinguishable by a discriminator network. This leads to easily distinguishable image transformations, such as pose and facial expressions in facial images. We show that linear paths can be derived as a special case of our method, and show experimentally that non-linear paths in the latent space lead to steeper, more disentangled and interpretable changes in the image space than in state-of-the art methods, both qualitatively and quantitatively. We make the code and the pretrained models publicly available at: https://github.com/chi0tzp/WarpedGANSpace.
Survey on RGB, 3D, Thermal, and Multimodal Approaches for Facial Expression Recognition: History, Trends, and Affect-related Applications
Jun 10, 2016
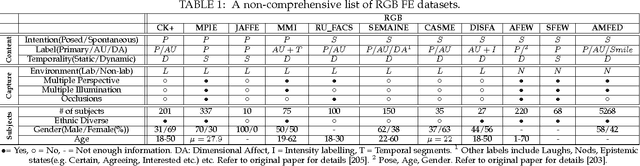

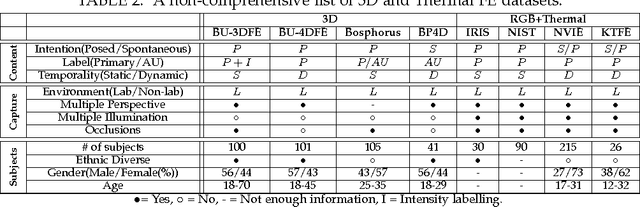
Facial expressions are an important way through which humans interact socially. Building a system capable of automatically recognizing facial expressions from images and video has been an intense field of study in recent years. Interpreting such expressions remains challenging and much research is needed about the way they relate to human affect. This paper presents a general overview of automatic RGB, 3D, thermal and multimodal facial expression analysis. We define a new taxonomy for the field, encompassing all steps from face detection to facial expression recognition, and describe and classify the state of the art methods accordingly. We also present the important datasets and the bench-marking of most influential methods. We conclude with a general discussion about trends, important questions and future lines of research.
A pilot study of the Earable device to measure facial muscle and eye movement tasks among healthy volunteers
Feb 01, 2022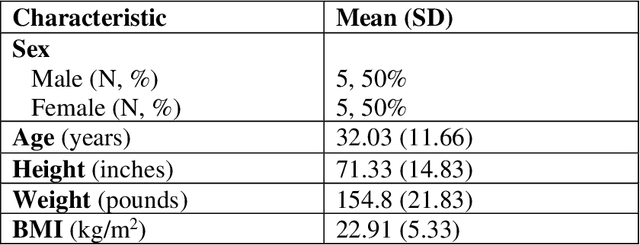
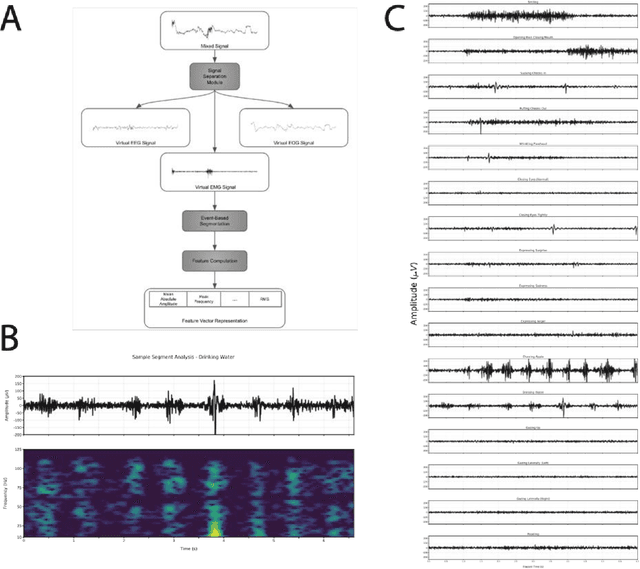
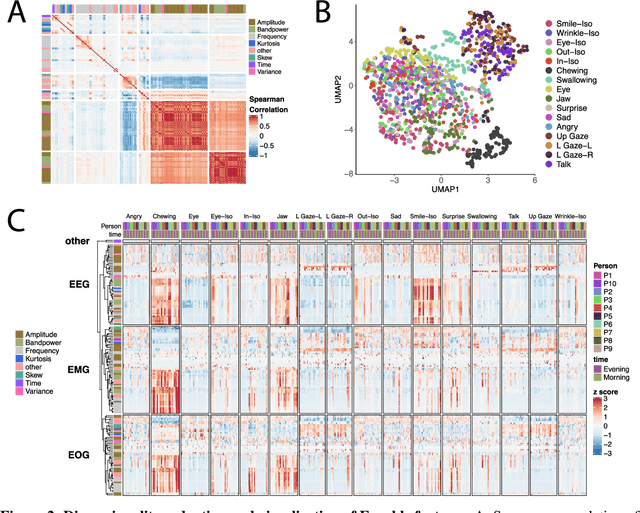
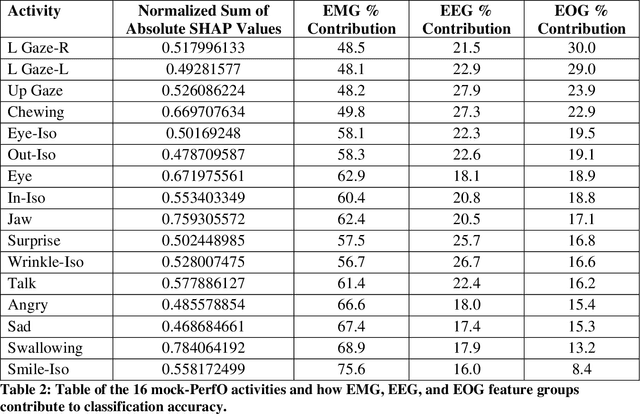
Many neuromuscular disorders impair function of cranial nerve enervated muscles. Clinical assessment of cranial muscle function has several limitations. Clinician rating of symptoms suffers from inter-rater variation, qualitative or semi-quantitative scoring, and limited ability to capture infrequent or fluctuating symptoms. Patient-reported outcomes are limited by recall bias and poor precision. Current tools to measure orofacial and oculomotor function are cumbersome, difficult to implement, and non-portable. Here, we show how Earable, a wearable device, can discriminate certain cranial muscle activities such as chewing, talking, and swallowing. We demonstrate using data from a pilot study of 10 healthy participants how Earable can be used to measure features from EMG, EEG, and EOG waveforms from subjects performing mock Performance Outcome Assessments (mock-PerfOs), utilized widely in clinical research. Our analysis pipeline provides a framework for how to computationally process and statistically rank features from the Earable device. Finally, we demonstrate that Earable data may be used to classify these activities. Our results, conducted in a pilot study of healthy participants, enable a more comprehensive strategy for the design, development, and analysis of wearable sensor data for investigating clinical populations. Additionally, the results from this study support further evaluation of Earable or similar devices as tools to objectively measure cranial muscle activity in the context of a clinical research setting. Future work will be conducted in clinical disease populations, with a focus on detecting disease signatures, as well as monitoring intra-subject treatment responses. Readily available quantitative metrics from wearable sensor devices like Earable support strategies for the development of novel digital endpoints, a hallmark goal of clinical research.