 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
VGAN-Based Image Representation Learning for Privacy-Preserving Facial Expression Recognition
Sep 07, 2018
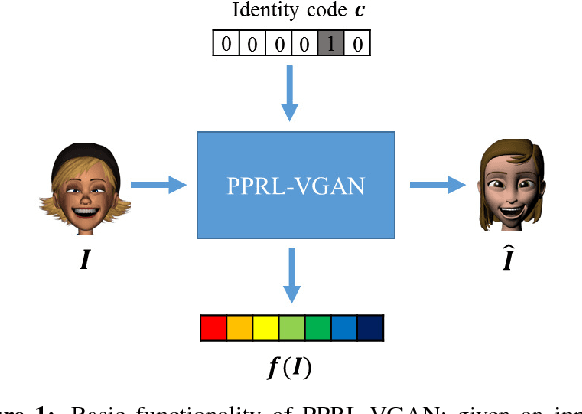

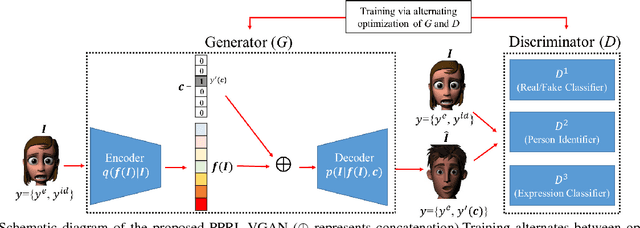
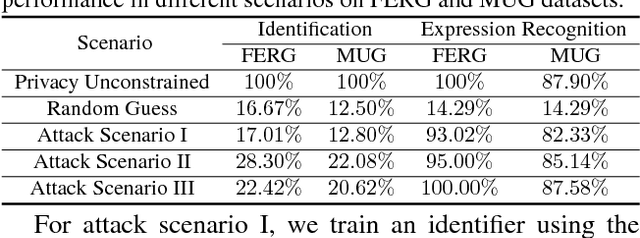
Reliable facial expression recognition plays a critical role in human-machine interactions. However, most of the facial expression analysis methodologies proposed to date pay little or no attention to the protection of a user's privacy. In this paper, we propose a Privacy-Preserving Representation-Learning Variational Generative Adversarial Network (PPRL-VGAN) to learn an image representation that is explicitly disentangled from the identity information. At the same time, this representation is discriminative from the standpoint of facial expression recognition and generative as it allows expression-equivalent face image synthesis. We evaluate the proposed model on two public datasets under various threat scenarios. Quantitative and qualitative results demonstrate that our approach strikes a balance between the preservation of privacy and data utility. We further demonstrate that our model can be effectively applied to other tasks such as expression morphing and image completion.
End-to-end facial and physiological model for \\Affective Computing and applications
Dec 10, 2019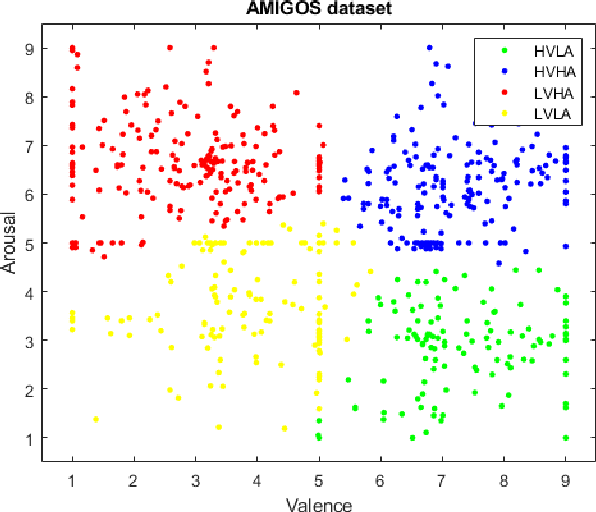
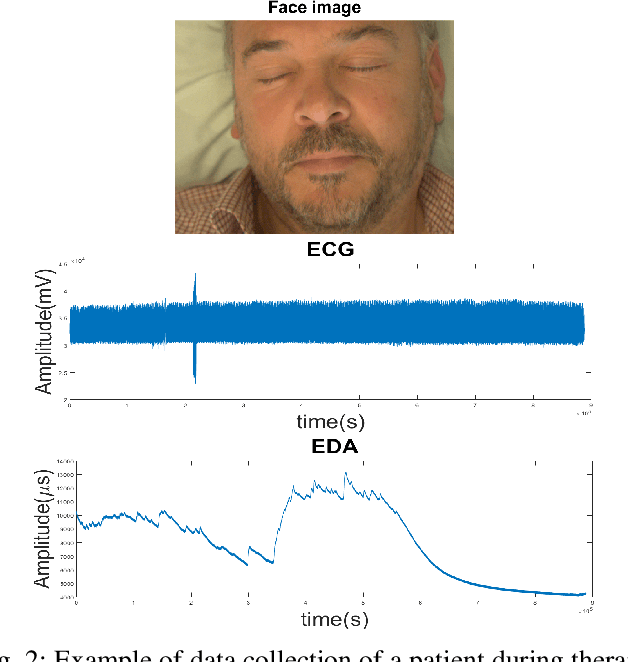
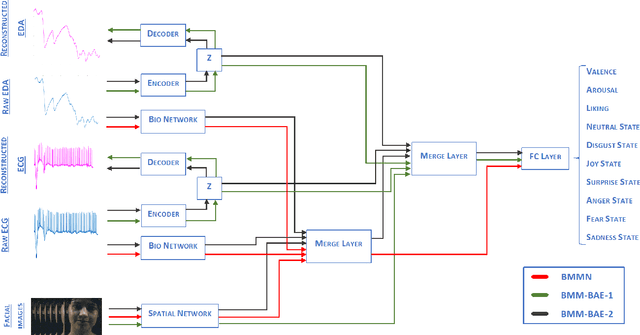
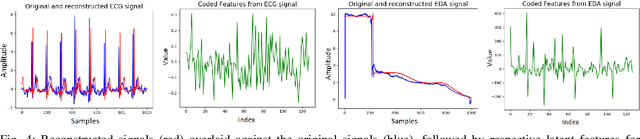
In recent years, Affective Computing and its applications have become a fast-growing research topic. Furthermore, the rise of Deep Learning has introduced significant improvements in the emotion recognition system compared to classical methods. In this work, we propose a multi-modal emotion recognition model based on deep learning techniques using the combination of peripheral physiological signals and facial expressions. Moreover, we present an improvement to proposed models by introducing latent features extracted from our internal Bio Auto-Encoder (BAE). Both models are trained and evaluated on AMIGOS datasets reporting valence, arousal, and emotion state classification. Finally, to demonstrate a possible medical application in affective computing using deep learning techniques, we applied the proposed method to the assessment of anxiety therapy. To this purpose, a reduced multi-modal database has been collected by recording facial expressions and peripheral signals such as Electrocardiogram (ECG) and Galvanic Skin Response (GSR) of each patient. Valence and arousal estimation was extracted using the proposed model from the beginning until the end of the therapy, with successful evaluation to the different emotional changes in the temporal domain.
Predicting Trust Using Automated Assessment of Multivariate Interactional Synchrony
Jan 06, 2022
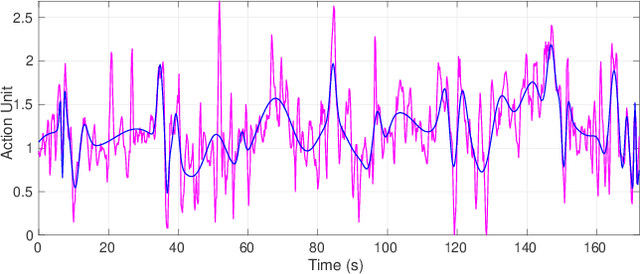
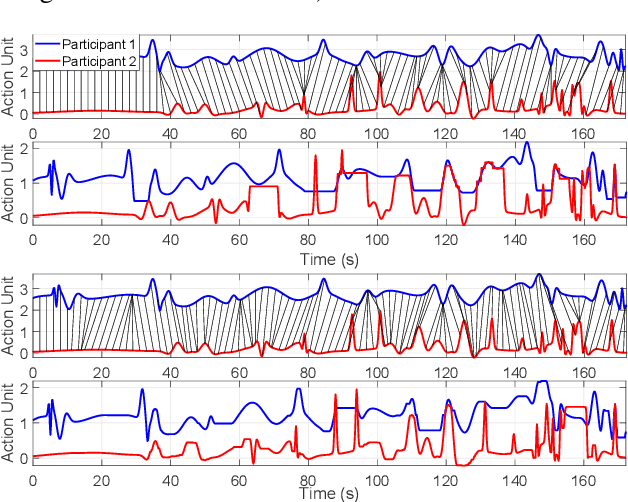
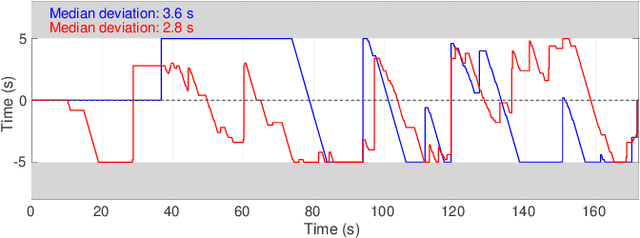
Diverse disciplines are interested in how the coordination of interacting agents' movements, emotions, and physiology over time impacts social behavior. Here, we describe a new multivariate procedure for automating the investigation of this kind of behaviorally-relevant "interactional synchrony", and introduce a novel interactional synchrony measure based on features of dynamic time warping (DTW) paths. We demonstrate that our DTW path-based measure of interactional synchrony between facial action units of two people interacting freely in a natural social interaction can be used to predict how much trust they will display in a subsequent Trust Game. We also show that our approach outperforms univariate head movement models, models that consider participants' facial action units independently, and models that use previously proposed synchrony or similarity measures. The insights of this work can be applied to any research question that aims to quantify the temporal coordination of multiple signals over time, but has immediate applications in psychology, medicine, and robotics.
Facial Emotion Recognition using Convolutional Neural Networks
Oct 12, 2019
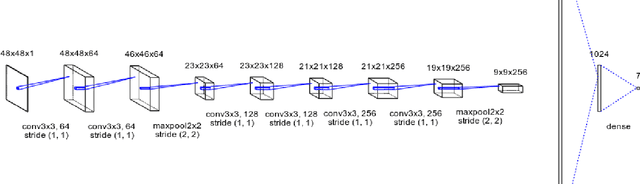
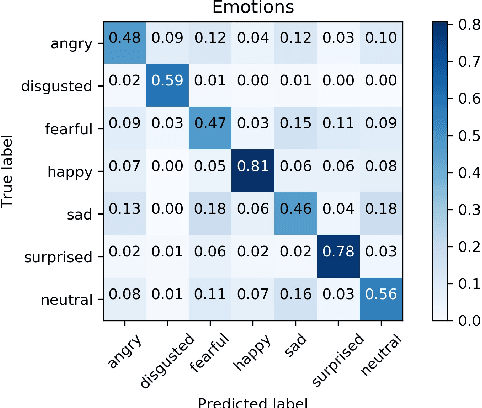
Facial expression recognition is a topic of great interest in most fields from artificial intelligence and gaming to marketing and healthcare. The goal of this paper is to classify images of human faces into one of seven basic emotions. A number of different models were experimented with, including decision trees and neural networks before arriving at a final Convolutional Neural Network (CNN) model. CNNs work better for image recognition tasks since they are able to capture spacial features of the inputs due to their large number of filters. The proposed model consists of six convolutional layers, two max pooling layers and two fully connected layers. Upon tuning of the various hyperparameters, this model achieved a final accuracy of 0.60.
Transferring Rich Deep Features for Facial Beauty Prediction
Mar 20, 2018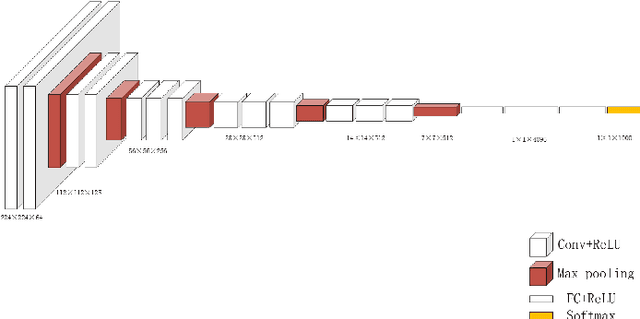

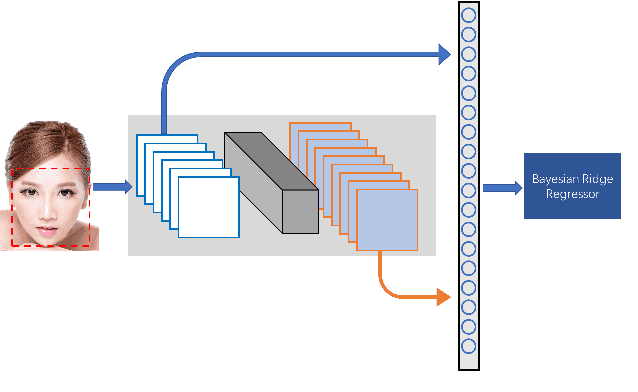

Feature extraction plays a significant part in computer vision tasks. In this paper, we propose a method which transfers rich deep features from a pretrained model on face verification task and feeds the features into Bayesian ridge regression algorithm for facial beauty prediction. We leverage the deep neural networks that extracts more abstract features from stacked layers. Through simple but effective feature fusion strategy, our method achieves improved or comparable performance on SCUT-FBP dataset and ECCV HotOrNot dataset. Our experiments demonstrate the effectiveness of the proposed method and clarify the inner interpretability of facial beauty perception.
Assessing the Influencing Factors on the Accuracy of Underage Facial Age Estimation
Dec 02, 2020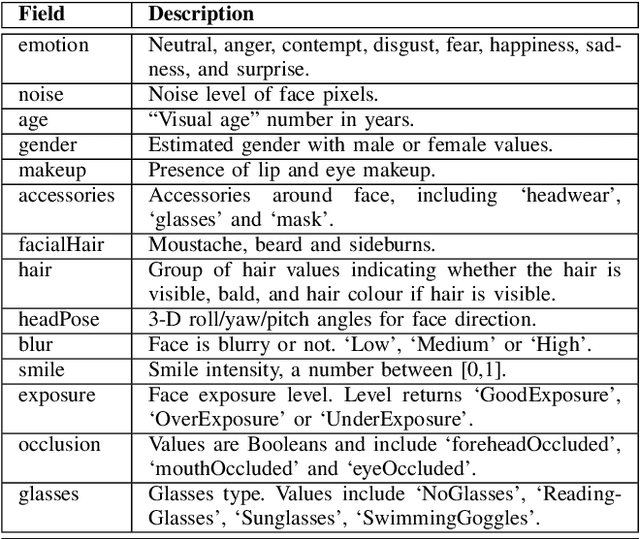
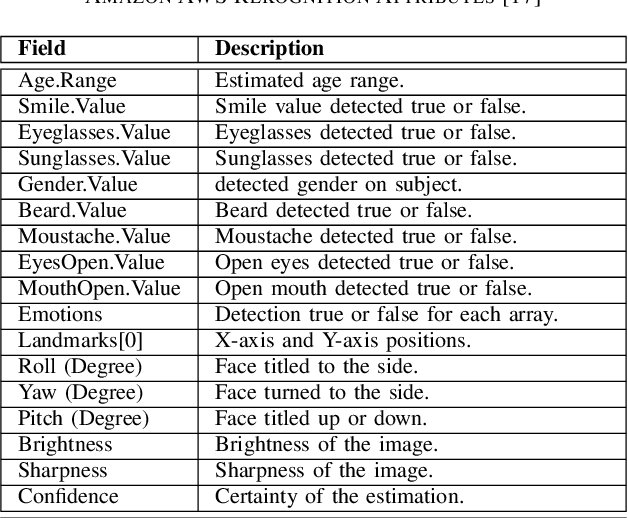
Swift response to the detection of endangered minors is an ongoing concern for law enforcement. Many child-focused investigations hinge on digital evidence discovery and analysis. Automated age estimation techniques are needed to aid in these investigations to expedite this evidence discovery process, and decrease investigator exposure to traumatic material. Automated techniques also show promise in decreasing the overflowing backlog of evidence obtained from increasing numbers of devices and online services. A lack of sufficient training data combined with natural human variance has been long hindering accurate automated age estimation -- especially for underage subjects. This paper presented a comprehensive evaluation of the performance of two cloud age estimation services (Amazon Web Service's Rekognition service and Microsoft Azure's Face API) against a dataset of over 21,800 underage subjects. The objective of this work is to evaluate the influence that certain human biometric factors, facial expressions, and image quality (i.e. blur, noise, exposure and resolution) have on the outcome of automated age estimation services. A thorough evaluation allows us to identify the most influential factors to be overcome in future age estimation systems.
AffectNet: A Database for Facial Expression, Valence, and Arousal Computing in the Wild
Oct 09, 2017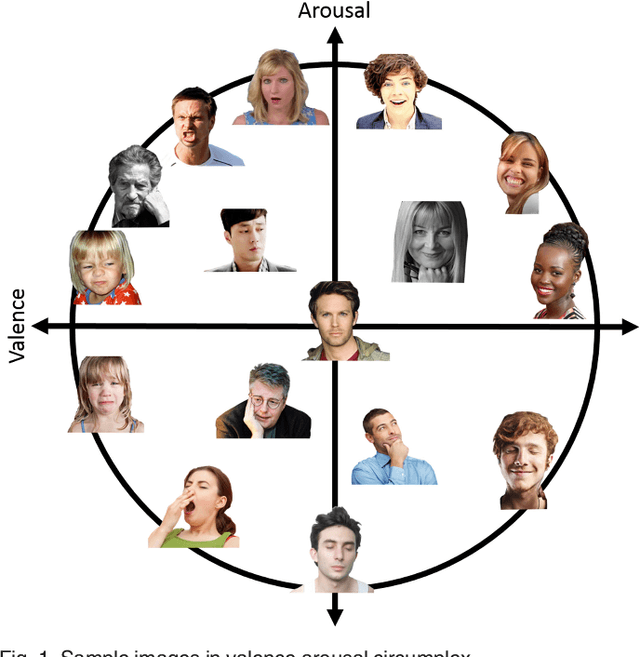
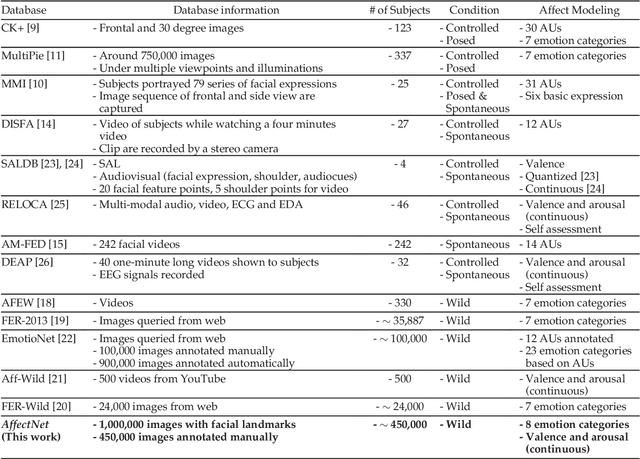
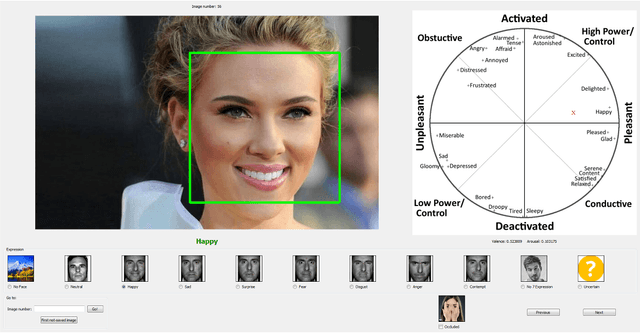
Automated affective computing in the wild setting is a challenging problem in computer vision. Existing annotated databases of facial expressions in the wild are small and mostly cover discrete emotions (aka the categorical model). There are very limited annotated facial databases for affective computing in the continuous dimensional model (e.g., valence and arousal). To meet this need, we collected, annotated, and prepared for public distribution a new database of facial emotions in the wild (called AffectNet). AffectNet contains more than 1,000,000 facial images from the Internet by querying three major search engines using 1250 emotion related keywords in six different languages. About half of the retrieved images were manually annotated for the presence of seven discrete facial expressions and the intensity of valence and arousal. AffectNet is by far the largest database of facial expression, valence, and arousal in the wild enabling research in automated facial expression recognition in two different emotion models. Two baseline deep neural networks are used to classify images in the categorical model and predict the intensity of valence and arousal. Various evaluation metrics show that our deep neural network baselines can perform better than conventional machine learning methods and off-the-shelf facial expression recognition systems.
Dynamic Multi-Task Learning for Face Recognition with Facial Expression
Nov 08, 2019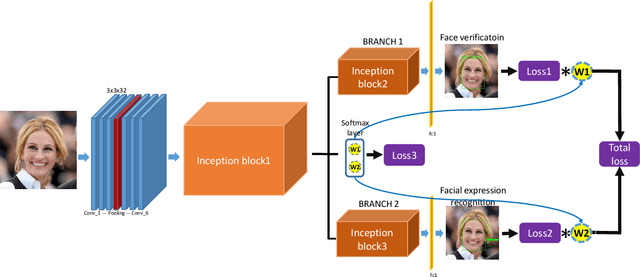

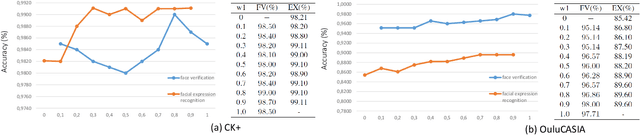
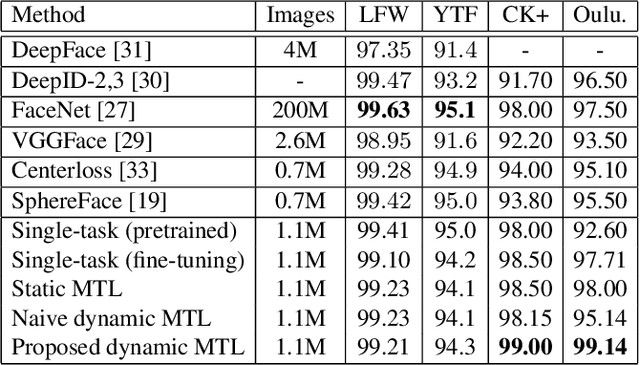
Benefiting from the joint learning of the multiple tasks in the deep multi-task networks, many applications have shown the promising performance comparing to single-task learning. However, the performance of multi-task learning framework is highly dependant on the relative weights of the tasks. How to assign the weight of each task is a critical issue in the multi-task learning. Instead of tuning the weights manually which is exhausted and time-consuming, in this paper we propose an approach which can dynamically adapt the weights of the tasks according to the difficulty for training the task. Specifically, the proposed method does not introduce the hyperparameters and the simple structure allows the other multi-task deep learning networks can easily realize or reproduce this method. We demonstrate our approach for face recognition with facial expression and facial expression recognition from a single input image based on a deep multi-task learning Conventional Neural Networks (CNNs). Both the theoretical analysis and the experimental results demonstrate the effectiveness of the proposed dynamic multi-task learning method. This multi-task learning with dynamic weights also boosts of the performance on the different tasks comparing to the state-of-art methods with single-task learning.
E2-Capsule Neural Networks for Facial Expression Recognition Using AU-Aware Attention
Dec 05, 2019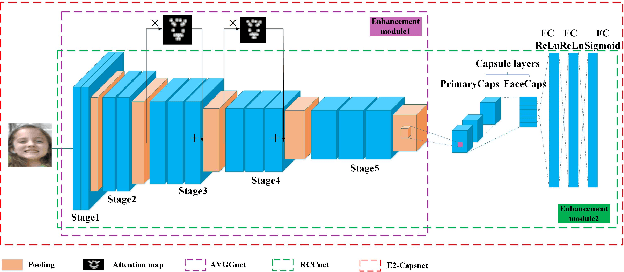


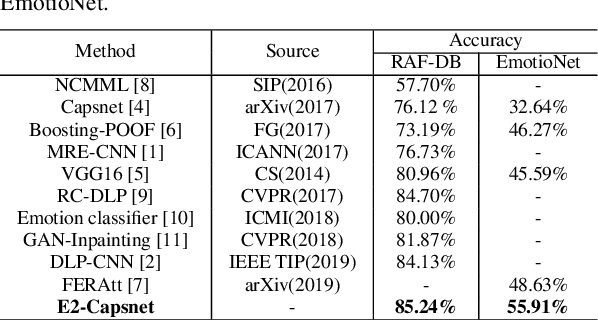
Capsule neural network is a new and popular technique in deep learning. However, the traditional capsule neural network does not extract features sufficiently before the dynamic routing between the capsules. In this paper, the one Double Enhanced Capsule Neural Network (E2-Capsnet) that uses AU-aware attention for facial expression recognition (FER) is proposed. The E2-Capsnet takes advantage of dynamic routing between the capsules, and has two enhancement modules which are beneficial for FER. The first enhancement module is the convolutional neural network with AU-aware attention, which can help focus on the active areas of the expression. The second enhancement module is the capsule neural network with multiple convolutional layers, which enhances the ability of the feature representation. Finally, squashing function is used to classify the facial expression. We demonstrate the effectiveness of E2-Capsnet on the two public benchmark datasets, RAF-DB and EmotioNet. The experimental results show that our E2-Capsnet is superior to the state-of-the-art methods. Our implementation will be publicly available online.
Affect-Aware Deep Belief Network Representations for Multimodal Unsupervised Deception Detection
Aug 17, 2021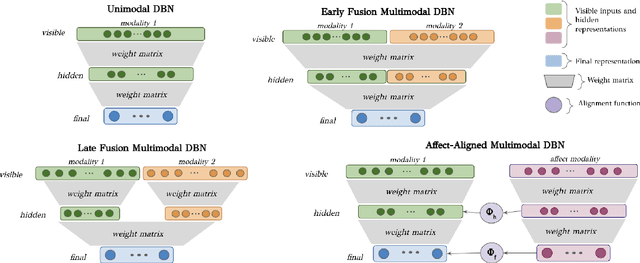
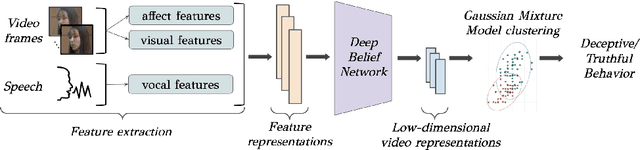
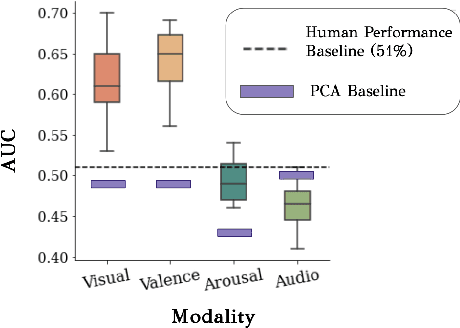
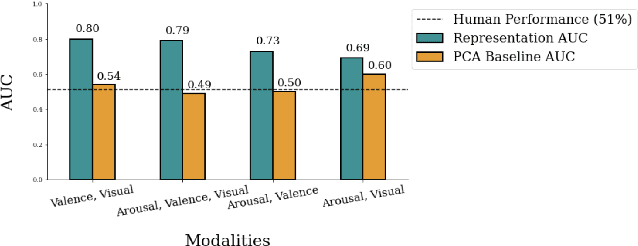
Automated systems that detect the social behavior of deception can enhance human well-being across medical, social work, and legal domains. Labeled datasets to train supervised deception detection models can rarely be collected for real-world, high-stakes contexts. To address this challenge, we propose the first unsupervised approach for detecting real-world, high-stakes deception in videos without requiring labels. This paper presents our novel approach for affect-aware unsupervised Deep Belief Networks (DBN) to learn discriminative representations of deceptive and truthful behavior. Drawing on psychology theories that link affect and deception, we experimented with unimodal and multimodal DBN-based approaches trained on facial valence, facial arousal, audio, and visual features. In addition to using facial affect as a feature on which DBN models are trained, we also introduce a DBN training procedure that uses facial affect as an aligner of audio-visual representations. We conducted classification experiments with unsupervised Gaussian Mixture Model clustering to evaluate our approaches. Our best unsupervised approach (trained on facial valence and visual features) achieved an AUC of 80%, outperforming human ability and performing comparably to fully-supervised models. Our results motivate future work on unsupervised, affect-aware computational approaches for detecting deception and other social behaviors in the wild.