 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"chatbots": models, code, and papers
Critical Appraisal of Artificial Intelligence-Mediated Communication
May 15, 2023
Over the last two decades, technology use in language learning and teaching has significantly advanced and is now referred to as Computer-Assisted Language Learning (CALL). Recently, the integration of Artificial Intelligence (AI) into CALL has brought about a significant shift in the traditional approach to language education both inside and outside the classroom. In line with this book's scope, I explore the advantages and disadvantages of AI-mediated communication in language education. I begin with a brief review of AI in education. I then introduce the ICALL and give a critical appraisal of the potential of AI-powered automatic speech recognition (ASR), Machine Translation (MT), Intelligent Tutoring Systems (ITSs), AI-powered chatbots, and Extended Reality (XR). In conclusion, I argue that it is crucial for language teachers to engage in CALL teacher education and professional development to keep up with the ever-evolving technology landscape and improve their teaching effectiveness.
Gpt-4: A Review on Advancements and Opportunities in Natural Language Processing
May 04, 2023Generative Pre-trained Transformer 4 (GPT-4) is the fourth-generation language model in the GPT series, developed by OpenAI, which promises significant advancements in the field of natural language processing (NLP). In this research article, we have discussed the features of GPT-4, its potential applications, and the challenges that it might face. We have also compared GPT-4 with its predecessor, GPT-3. GPT-4 has a larger model size (more than one trillion), better multilingual capabilities, improved contextual understanding, and reasoning capabilities than GPT-3. Some of the potential applications of GPT-4 include chatbots, personal assistants, language translation, text summarization, and question-answering. However, GPT-4 poses several challenges and limitations such as computational requirements, data requirements, and ethical concerns.
Assessing Political Prudence of Open-domain Chatbots
Jun 11, 2021

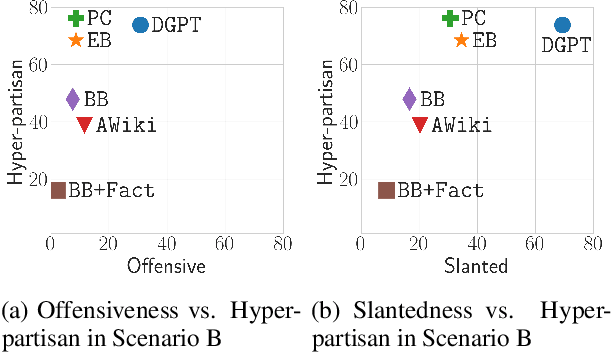
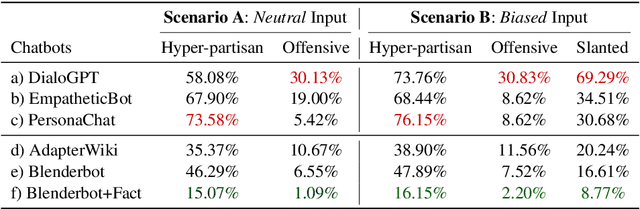
Politically sensitive topics are still a challenge for open-domain chatbots. However, dealing with politically sensitive content in a responsible, non-partisan, and safe behavior way is integral for these chatbots. Currently, the main approach to handling political sensitivity is by simply changing such a topic when it is detected. This is safe but evasive and results in a chatbot that is less engaging. In this work, as a first step towards a politically safe chatbot, we propose a group of metrics for assessing their political prudence. We then conduct political prudence analysis of various chatbots and discuss their behavior from multiple angles through our automatic metric and human evaluation metrics. The testsets and codebase are released to promote research in this area.
Will ChatGPT get you caught? Rethinking of Plagiarism Detection
Feb 08, 2023
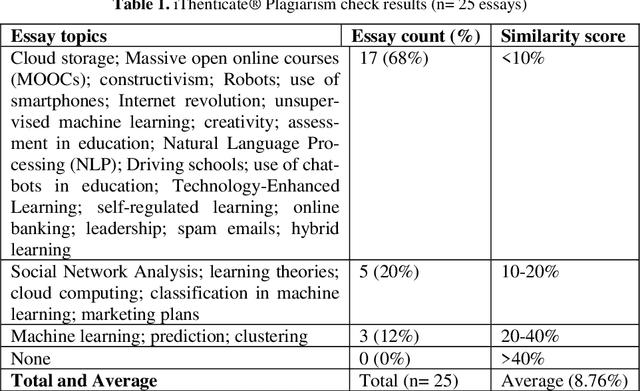

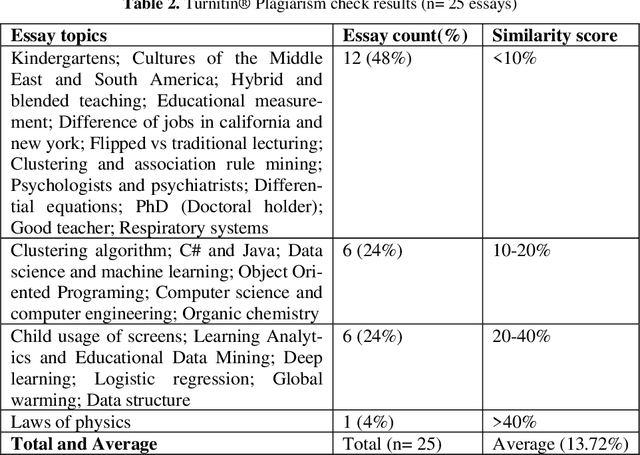
The rise of Artificial Intelligence (AI) technology and its impact on education has been a topic of growing concern in recent years. The new generation AI systems such as chatbots have become more accessible on the Internet and stronger in terms of capabilities. The use of chatbots, particularly ChatGPT, for generating academic essays at schools and colleges has sparked fears among scholars. This study aims to explore the originality of contents produced by one of the most popular AI chatbots, ChatGPT. To this end, two popular plagiarism detection tools were used to evaluate the originality of 50 essays generated by ChatGPT on various topics. Our results manifest that ChatGPT has a great potential to generate sophisticated text outputs without being well caught by the plagiarism check software. In other words, ChatGPT can create content on many topics with high originality as if they were written by someone. These findings align with the recent concerns about students using chatbots for an easy shortcut to success with minimal or no effort. Moreover, ChatGPT was asked to verify if the essays were generated by itself, as an additional measure of plagiarism check, and it showed superior performance compared to the traditional plagiarism-detection tools. The paper discusses the need for institutions to consider appropriate measures to mitigate potential plagiarism issues and advise on the ongoing debate surrounding the impact of AI technology on education. Further implications are discussed in the paper.
Learn What NOT to Learn: Towards Generative Safety in Chatbots
Apr 25, 2023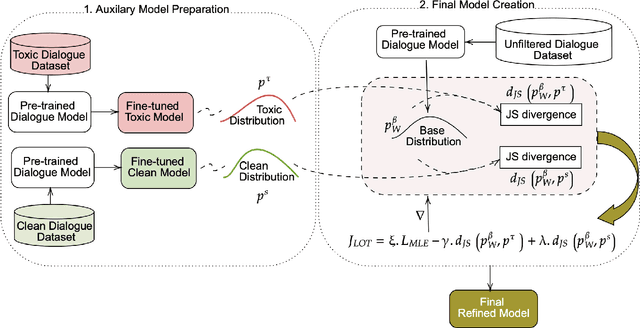
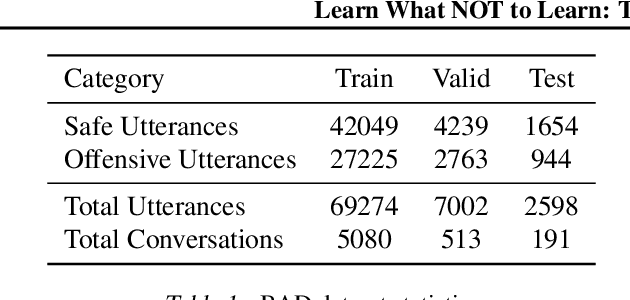
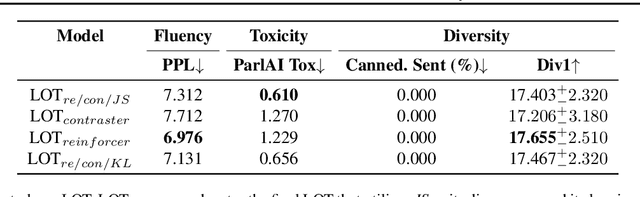
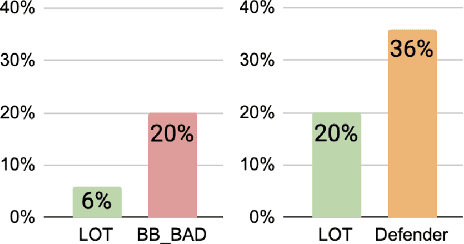
Conversational models that are generative and open-domain are particularly susceptible to generating unsafe content since they are trained on web-based social data. Prior approaches to mitigating this issue have drawbacks, such as disrupting the flow of conversation, limited generalization to unseen toxic input contexts, and sacrificing the quality of the dialogue for the sake of safety. In this paper, we present a novel framework, named "LOT" (Learn NOT to), that employs a contrastive loss to enhance generalization by learning from both positive and negative training signals. Our approach differs from the standard contrastive learning framework in that it automatically obtains positive and negative signals from the safe and unsafe language distributions that have been learned beforehand. The LOT framework utilizes divergence to steer the generations away from the unsafe subspace and towards the safe subspace while sustaining the flow of conversation. Our approach is memory and time-efficient during decoding and effectively reduces toxicity while preserving engagingness and fluency. Empirical results indicate that LOT reduces toxicity by up to four-fold while achieving four to six-fold higher rates of engagingness and fluency compared to baseline models. Our findings are further corroborated by human evaluation.
Using LLM-assisted Annotation for Corpus Linguistics: A Case Study of Local Grammar Analysis
May 15, 2023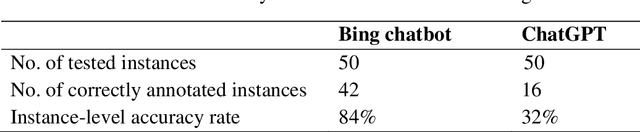

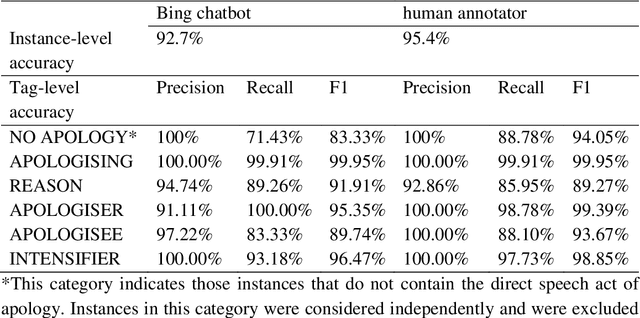
Chatbots based on Large Language Models (LLMs) have shown strong capabilities in language understanding. In this study, we explore the potential of LLMs in assisting corpus-based linguistic studies through automatic annotation of texts with specific categories of linguistic information. Specifically, we examined to what extent LLMs understand the functional elements constituting the speech act of apology from a local grammar perspective, by comparing the performance of ChatGPT (powered by GPT-3.5), Bing chatbot (powered by GPT-4), and a human coder in the annotation task. The results demonstrate that Bing chatbot significantly outperformed ChatGPT in the task. Compared to human annotator, the overall performance of Bing chatbot was slightly less satisfactory. However, it already achieved high F1 scores: 99.95% for the tag of APOLOGISING, 91.91% for REASON, 95.35% for APOLOGISER, 89.74% for APOLOGISEE, and 96.47% for INTENSIFIER. Therefore, we propose that LLM-assisted annotation is a promising automated approach for corpus studies.
A Framework for Designing Foundation Model based Systems
May 09, 2023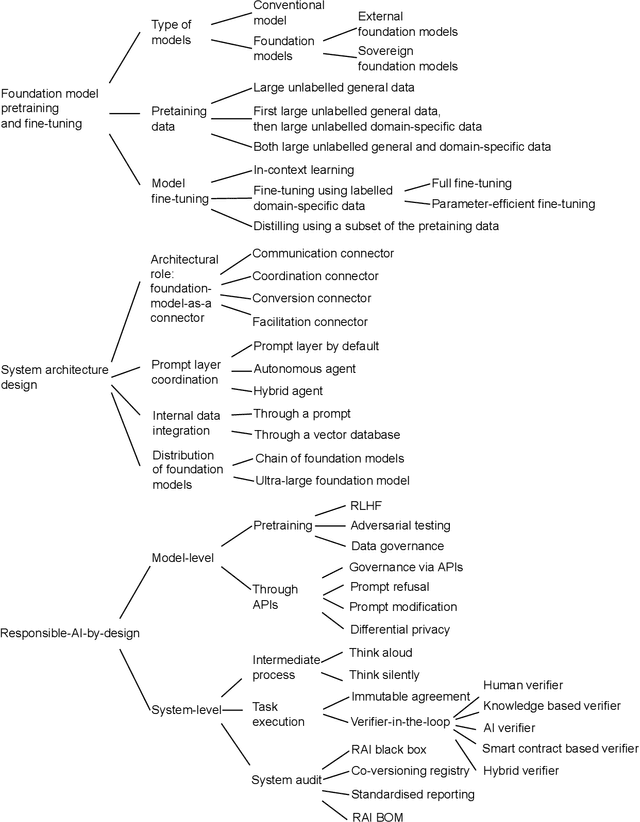
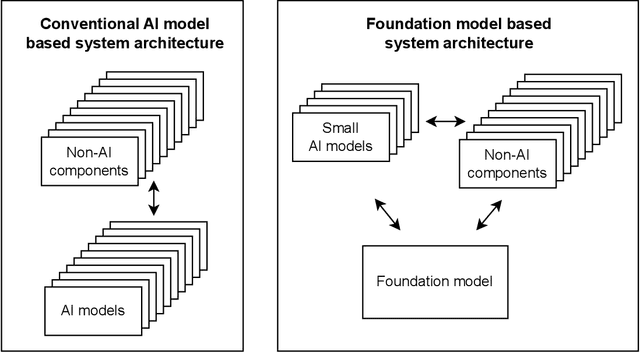
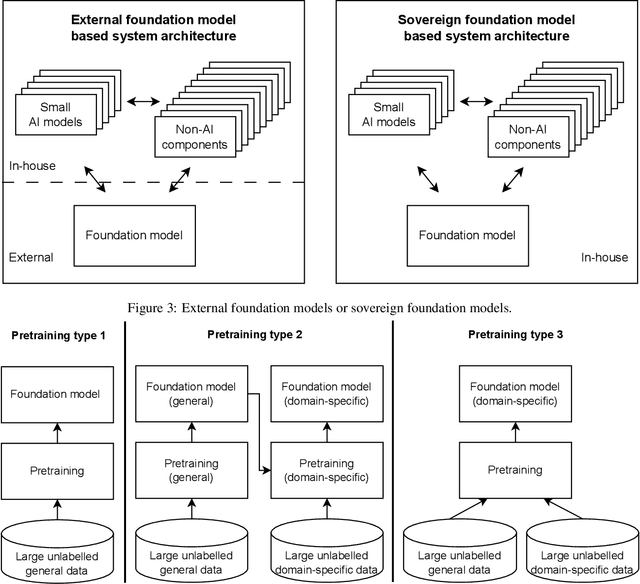
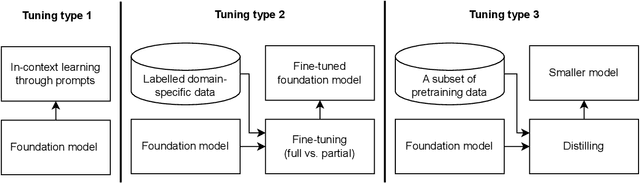
The recent release of large language model (LLM) based chatbots, such as ChatGPT, has attracted significant attention on foundations models. It is widely believed that foundation models will serve as the fundamental building blocks for future AI systems. As foundation models are in their early stages, the design of foundation model based systems has not yet been systematically explored. There is little understanding about the impact of introducing foundation models in software architecture. Therefore, in this paper, we propose a taxonomy of foundation model based systems, which classifies and compares the characteristics of foundation models and foundation model based systems. Our taxonomy comprises three categories: foundation model pretraining and fine-tuning, architecture design of foundation model based systems, and responsible-AI-by-design. This taxonomy provides concrete guidance for making major design decisions when designing foundation model based systems and highlights trade-offs arising from design decisions.
Perceived Trustworthiness of Natural Language Generators
May 29, 2023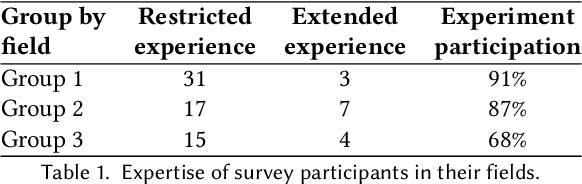
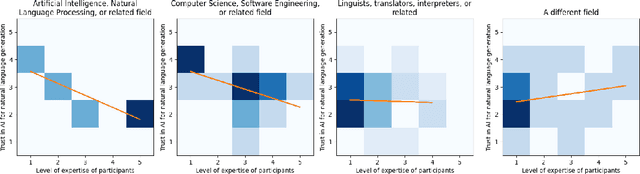

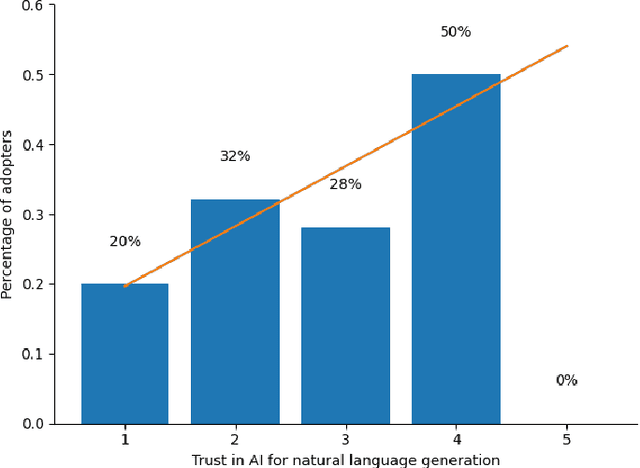
Natural Language Generation tools, such as chatbots that can generate human-like conversational text, are becoming more common both for personal and professional use. However, there are concerns about their trustworthiness and ethical implications. The paper addresses the problem of understanding how different users (e.g., linguists, engineers) perceive and adopt these tools and their perception of machine-generated text quality. It also discusses the perceived advantages and limitations of Natural Language Generation tools, as well as users' beliefs on governance strategies. The main findings of this study include the impact of users' field and level of expertise on the perceived trust and adoption of Natural Language Generation tools, the users' assessment of the accuracy, fluency, and potential biases of machine-generated text in comparison to human-written text, and an analysis of the advantages and ethical risks associated with these tools as identified by the participants. Moreover, this paper discusses the potential implications of these findings for enhancing the AI development process. The paper sheds light on how different user characteristics shape their beliefs on the quality and overall trustworthiness of machine-generated text. Furthermore, it examines the benefits and risks of these tools from the perspectives of different users.
ViMQ: A Vietnamese Medical Question Dataset for Healthcare Dialogue System Development
Apr 27, 2023Existing medical text datasets usually take the form of ques- tion and answer pairs that support the task of natural language gener- ation, but lacking the composite annotations of the medical terms. In this study, we publish a Vietnamese dataset of medical questions from patients with sentence-level and entity-level annotations for the Intent Classification and Named Entity Recognition tasks. The tag sets for two tasks are in medical domain and can facilitate the development of task- oriented healthcare chatbots with better comprehension of queries from patients. We train baseline models for the two tasks and propose a simple self-supervised training strategy with span-noise modelling that substan- tially improves the performance. Dataset and code will be published at https://github.com/tadeephuy/ViMQ
* accepted at ICONIP 2021