 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Topic Modeling": models, code, and papers
Neural Contrastive Clustering: Fully Unsupervised Bias Reduction for Sentiment Classification
Apr 22, 2022
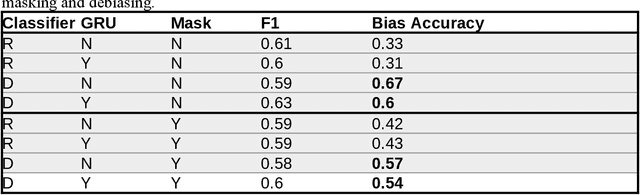
Background: Neural networks produce biased classification results due to correlation bias (they learn correlations between their inputs and outputs to classify samples, even when those correlations do not represent cause-and-effect relationships). Objective: This study introduces a fully unsupervised method of mitigating correlation bias, demonstrated with sentiment classification on COVID-19 social media data. Methods: Correlation bias in sentiment classification often arises in conversations about controversial topics. Therefore, this study uses adversarial learning to contrast clusters based on sentiment classification labels, with clusters produced by unsupervised topic modeling. This discourages the neural network from learning topic-related features that produce biased classification results. Results: Compared to a baseline classifier, neural contrastive clustering approximately doubles accuracy on bias-prone sentences for human-labeled COVID-19 social media data, without adversely affecting the classifier's overall F1 score. Despite being a fully unsupervised approach, neural contrastive clustering achieves a larger improvement in accuracy on bias-prone sentences than a supervised masking approach. Conclusions: Neural contrastive clustering reduces correlation bias in sentiment text classification. Further research is needed to explore generalizing this technique to other neural network architectures and application domains.
Hate speech, Censorship, and Freedom of Speech: The Changing Policies of Reddit
Mar 18, 2022



This paper examines the shift in focus on content policies and user attitudes on the social media platform Reddit. We do this by focusing on comments from general Reddit users from five posts made by admins (moderators) on updates to Reddit Content Policy. All five concern the nature of what kind of content is allowed to be posted on Reddit, and which measures will be taken against content that violates these policies. We use topic modeling to probe how the general discourse for Redditors has changed around limitations on content, and later, limitations on hate speech, or speech that incites violence against a particular group. We show that there is a clear shift in both the contents and the user attitudes that can be linked to contemporary societal upheaval as well as newly passed laws and regulations, and contribute to the wider discussion on hate speech moderation.
A Deep and Autoregressive Approach for Topic Modeling of Multimodal Data
Dec 31, 2015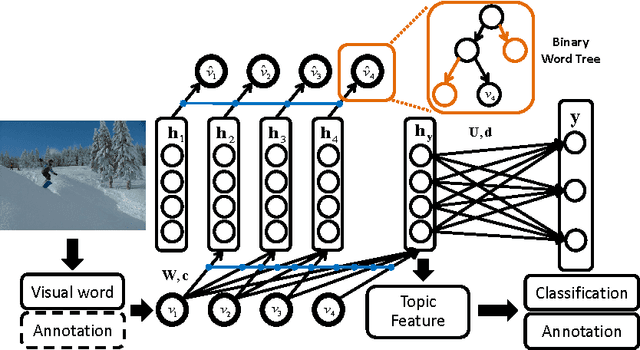
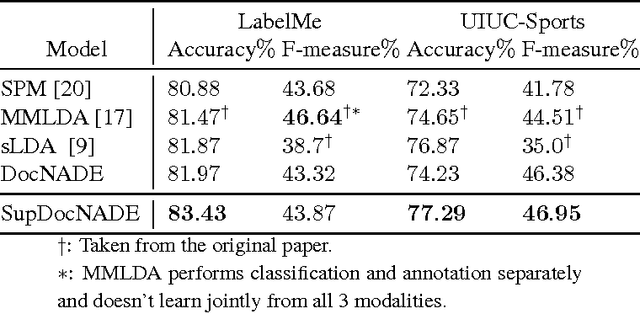
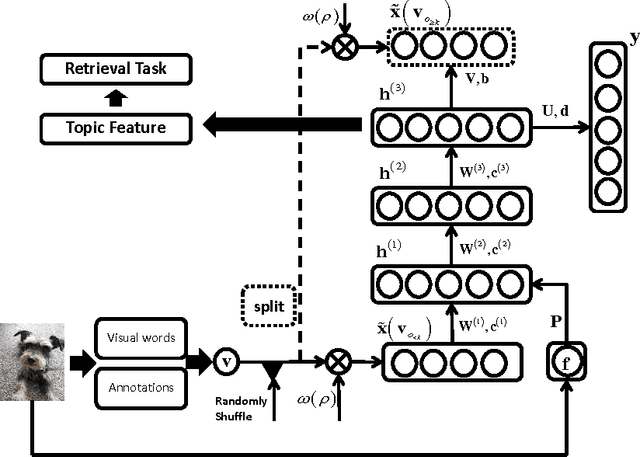

Topic modeling based on latent Dirichlet allocation (LDA) has been a framework of choice to deal with multimodal data, such as in image annotation tasks. Another popular approach to model the multimodal data is through deep neural networks, such as the deep Boltzmann machine (DBM). Recently, a new type of topic model called the Document Neural Autoregressive Distribution Estimator (DocNADE) was proposed and demonstrated state-of-the-art performance for text document modeling. In this work, we show how to successfully apply and extend this model to multimodal data, such as simultaneous image classification and annotation. First, we propose SupDocNADE, a supervised extension of DocNADE, that increases the discriminative power of the learned hidden topic features and show how to employ it to learn a joint representation from image visual words, annotation words and class label information. We test our model on the LabelMe and UIUC-Sports data sets and show that it compares favorably to other topic models. Second, we propose a deep extension of our model and provide an efficient way of training the deep model. Experimental results show that our deep model outperforms its shallow version and reaches state-of-the-art performance on the Multimedia Information Retrieval (MIR) Flickr data set.
Topic Modeling with Contextualized Word Representation Clusters
Oct 23, 2020
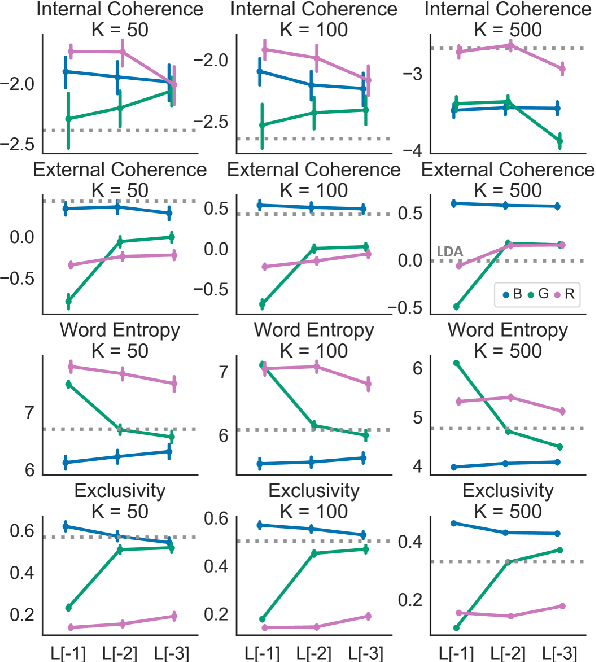
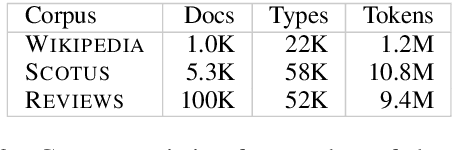
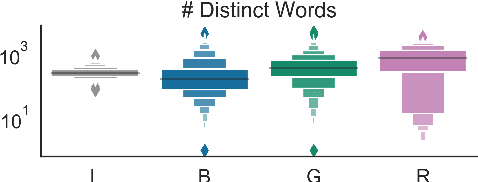
Clustering token-level contextualized word representations produces output that shares many similarities with topic models for English text collections. Unlike clusterings of vocabulary-level word embeddings, the resulting models more naturally capture polysemy and can be used as a way of organizing documents. We evaluate token clusterings trained from several different output layers of popular contextualized language models. We find that BERT and GPT-2 produce high quality clusterings, but RoBERTa does not. These cluster models are simple, reliable, and can perform as well as, if not better than, LDA topic models, maintaining high topic quality even when the number of topics is large relative to the size of the local collection.
Supervised Dictionary Learning with Auxiliary Covariates
Jun 14, 2022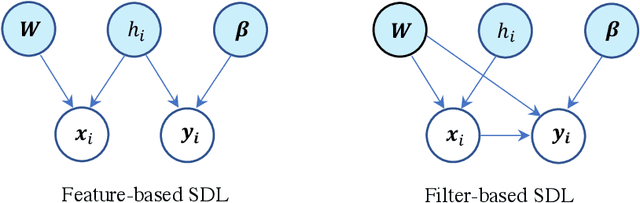

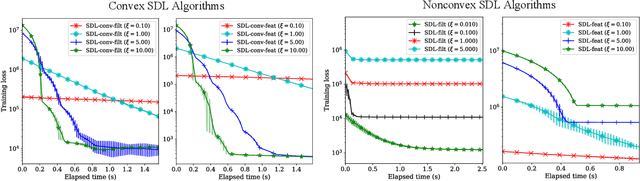
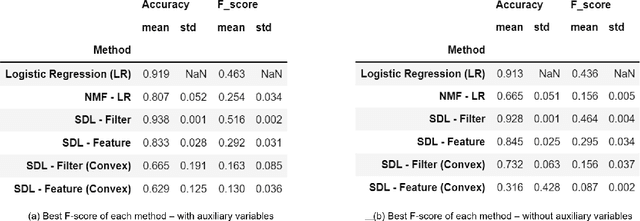
Supervised dictionary learning (SDL) is a classical machine learning method that simultaneously seeks feature extraction and classification tasks, which are not necessarily a priori aligned objectives. The goal of SDL is to learn a class-discriminative dictionary, which is a set of latent feature vectors that can well-explain both the features as well as labels of observed data. In this paper, we provide a systematic study of SDL, including the theory, algorithm, and applications of SDL. First, we provide a novel framework that `lifts' SDL as a convex problem in a combined factor space and propose a low-rank projected gradient descent algorithm that converges exponentially to the global minimizer of the objective. We also formulate generative models of SDL and provide global estimation guarantees of the true parameters depending on the hyperparameter regime. Second, viewed as a nonconvex constrained optimization problem, we provided an efficient block coordinate descent algorithm for SDL that is guaranteed to find an $\varepsilon$-stationary point of the objective in $O(\varepsilon^{-1}(\log \varepsilon^{-1})^{2})$ iterations. For the corresponding generative model, we establish a novel non-asymptotic local consistency result for constrained and regularized maximum likelihood estimation problems, which may be of independent interest. Third, we apply SDL for imbalanced document classification by supervised topic modeling and also for pneumonia detection from chest X-ray images. We also provide simulation studies to demonstrate that SDL becomes more effective when there is a discrepancy between the best reconstructive and the best discriminative dictionaries.
A Weakly-Supervised Iterative Graph-Based Approach to Retrieve COVID-19 Misinformation Topics
May 19, 2022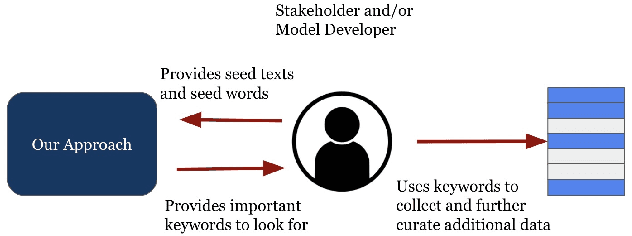
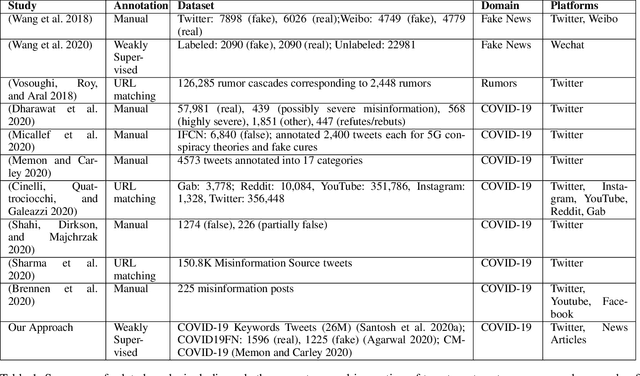
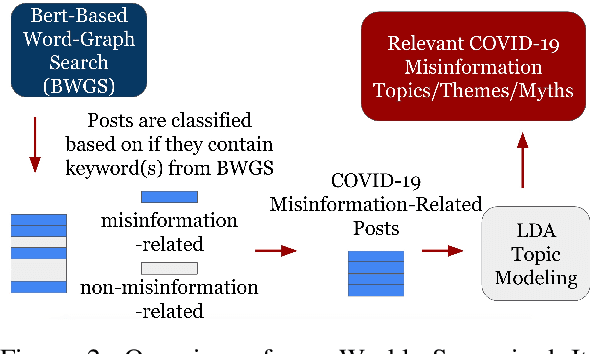
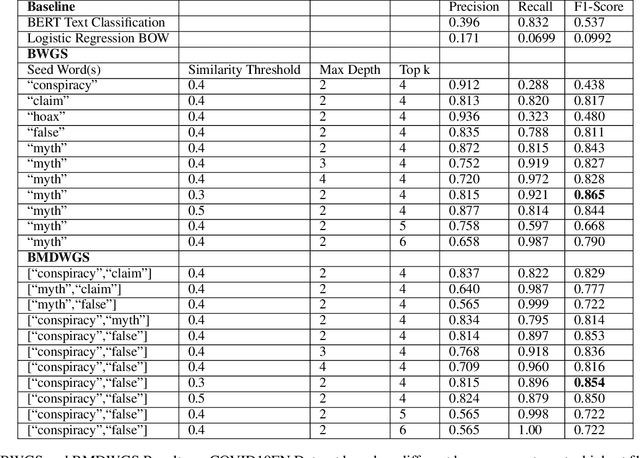
The COVID-19 pandemic has been accompanied by an `infodemic' -- of accurate and inaccurate health information across social media. Detecting misinformation amidst dynamically changing information landscape is challenging; identifying relevant keywords and posts is arduous due to the large amount of human effort required to inspect the content and sources of posts. We aim to reduce the resource cost of this process by introducing a weakly-supervised iterative graph-based approach to detect keywords, topics, and themes related to misinformation, with a focus on COVID-19. Our approach can successfully detect specific topics from general misinformation-related seed words in a few seed texts. Our approach utilizes the BERT-based Word Graph Search (BWGS) algorithm that builds on context-based neural network embeddings for retrieving misinformation-related posts. We utilize Latent Dirichlet Allocation (LDA) topic modeling for obtaining misinformation-related themes from the texts returned by BWGS. Furthermore, we propose the BERT-based Multi-directional Word Graph Search (BMDWGS) algorithm that utilizes greater starting context information for misinformation extraction. In addition to a qualitative analysis of our approach, our quantitative analyses show that BWGS and BMDWGS are effective in extracting misinformation-related content compared to common baselines in low data resource settings. Extracting such content is useful for uncovering prevalent misconceptions and concerns and for facilitating precision public health messaging campaigns to improve health behaviors.
A Query-Driven Topic Model
Jun 22, 2021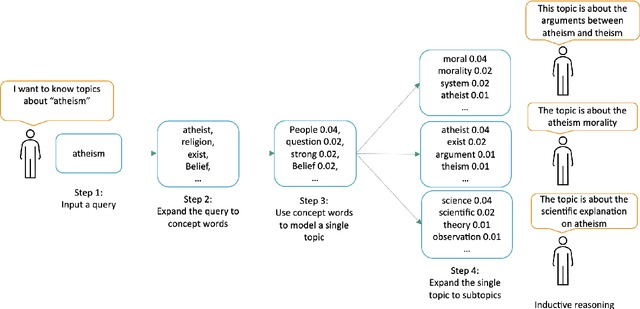
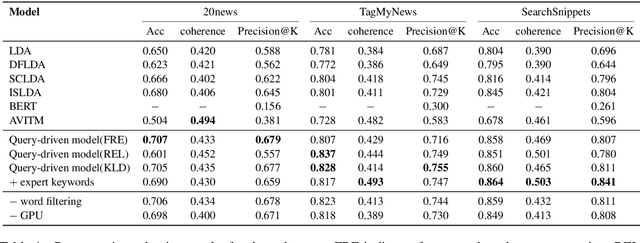
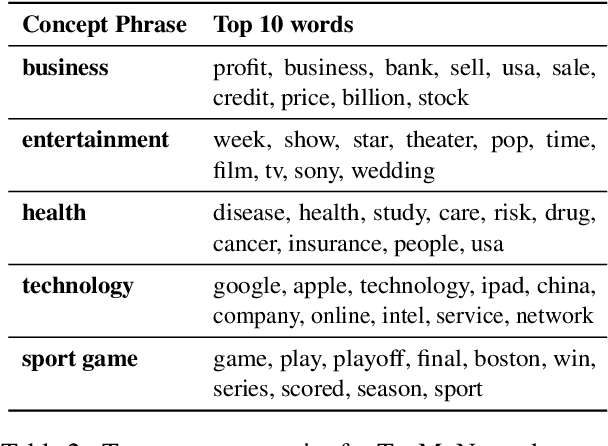

Topic modeling is an unsupervised method for revealing the hidden semantic structure of a corpus. It has been increasingly widely adopted as a tool in the social sciences, including political science, digital humanities and sociological research in general. One desirable property of topic models is to allow users to find topics describing a specific aspect of the corpus. A possible solution is to incorporate domain-specific knowledge into topic modeling, but this requires a specification from domain experts. We propose a novel query-driven topic model that allows users to specify a simple query in words or phrases and return query-related topics, thus avoiding tedious work from domain experts. Our proposed approach is particularly attractive when the user-specified query has a low occurrence in a text corpus, making it difficult for traditional topic models built on word cooccurrence patterns to identify relevant topics. Experimental results demonstrate the effectiveness of our model in comparison with both classical topic models and neural topic models.
Trend and Thoughts: Understanding Climate Change Concern using Machine Learning and Social Media Data
Nov 06, 2021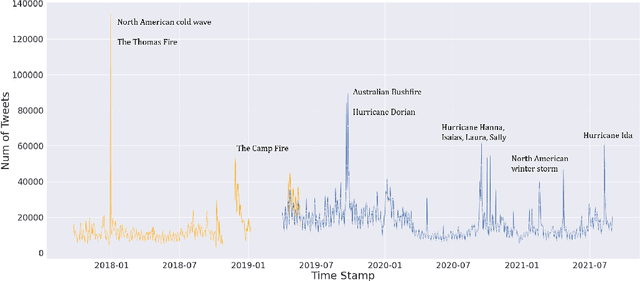
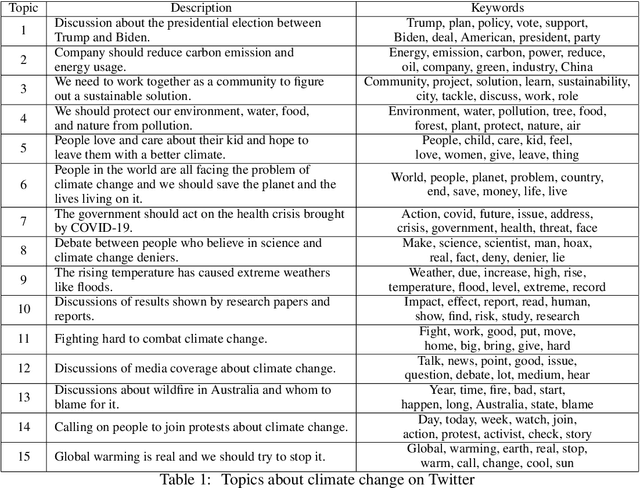
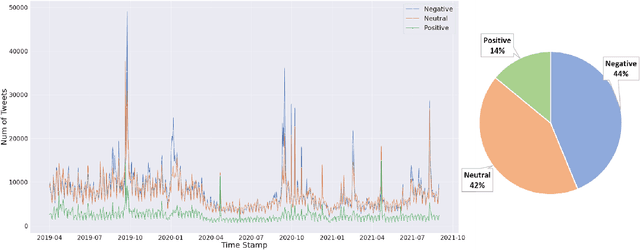
Nowadays social media platforms such as Twitter provide a great opportunity to understand public opinion of climate change compared to traditional survey methods. In this paper, we constructed a massive climate change Twitter dataset and conducted comprehensive analysis using machine learning. By conducting topic modeling and natural language processing, we show the relationship between the number of tweets about climate change and major climate events; the common topics people discuss climate change; and the trend of sentiment. Our dataset was published on Kaggle (\url{https://www.kaggle.com/leonshangguan/climate-change-tweets-ids-until-aug-2021}) and can be used in further research.
Focusing Knowledge-based Graph Argument Mining via Topic Modeling
Feb 03, 2021
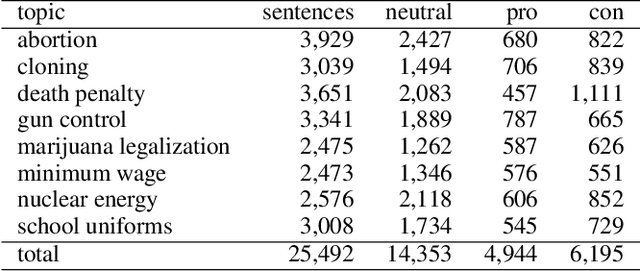
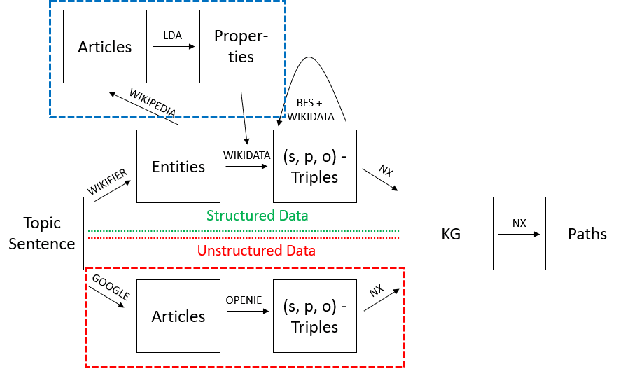

Decision-making usually takes five steps: identifying the problem, collecting data, extracting evidence, identifying pro and con arguments, and making decisions. Focusing on extracting evidence, this paper presents a hybrid model that combines latent Dirichlet allocation and word embeddings to obtain external knowledge from structured and unstructured data. We study the task of sentence-level argument mining, as arguments mostly require some degree of world knowledge to be identified and understood. Given a topic and a sentence, the goal is to classify whether a sentence represents an argument in regard to the topic. We use a topic model to extract topic- and sentence-specific evidence from the structured knowledge base Wikidata, building a graph based on the cosine similarity between the entity word vectors of Wikidata and the vector of the given sentence. Also, we build a second graph based on topic-specific articles found via Google to tackle the general incompleteness of structured knowledge bases. Combining these graphs, we obtain a graph-based model which, as our evaluation shows, successfully capitalizes on both structured and unstructured data.
Query-Driven Topic Model
May 28, 2021Topic modeling is an unsupervised method for revealing the hidden semantic structure of a corpus. It has been increasingly widely adopted as a tool in the social sciences, including political science, digital humanities and sociological research in general. One desirable property of topic models is to allow users to find topics describing a specific aspect of the corpus. A possible solution is to incorporate domain-specific knowledge into topic modeling, but this requires a specification from domain experts. We propose a novel query-driven topic model that allows users to specify a simple query in words or phrases and return query-related topics, thus avoiding tedious work from domain experts. Our proposed approach is particularly attractive when the user-specified query has a low occurrence in a text corpus, making it difficult for traditional topic models built on word cooccurrence patterns to identify relevant topics. Experimental results demonstrate the effectiveness of our model in comparison with both classical topic models and neural topic models.