 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing the Evidence, Missing the Answer: Tool-Guided Vision-Language Models on Visual Illusions
Mar 31, 2026Vision-language models (VLMs) exhibit a systematic bias when confronted with classic optical illusions: they overwhelmingly predict the illusion as "real" regardless of whether the image has been counterfactually modified. We present a tool-guided inference framework for the DataCV 2026 Challenge (Tasks I and II) that addresses this failure mode without any model training. An off-the-shelf vision-language model is given access to a small set of generic image manipulation tools: line drawing, region cropping, side-by-side comparison, and channel isolation, together with an illusion-type-routing system prompt that prescribes which tools to invoke for each perceptual question category. Critically, every tool call produces a new, immutable image resource appended to a persistent registry, so the model can reference and compose any prior annotated view throughout its reasoning chain. Rather than hard-coding illusion-specific modules, this generic-tool-plus-routing design yields strong cross-structural generalization: performance remained consistent from the validation set to a test set containing structurally unfamiliar illusion variants (e.g., Mach Bands rotated from vertical to horizontal stacking). We further report three empirical observations that we believe warrant additional investigation: (i) a strong positive-detection bias likely rooted in imbalanced illusion training data, (ii) a striking dissociation between pixel-accurate spatial reasoning and logical inference over self-generated annotations, and (iii) pronounced sensitivity to image compression artifacts that compounds false positives.
Story2Proposal: A Scaffold for Structured Scientific Paper Writing
Mar 28, 2026Generating scientific manuscripts requires maintaining alignment between narrative reasoning, experimental evidence, and visual artifacts across the document lifecycle. Existing language-model generation pipelines rely on unconstrained text synthesis with validation applied only after generation, often producing structural drift, missing figures or tables, and cross-section inconsistencies. We introduce Story2Proposal, a contract-governed multi-agent framework that converts a research story into a structured manuscript through coordinated agents operating under a persistent shared visual contract. The system organizes architect, writer, refiner, and renderer agents around a contract state that tracks section structure and registered visual elements, while evaluation agents supply feedback in a generate evaluate adapt loop that updates the contract during generation. Experiments on tasks derived from the Jericho research corpus show that Story2Proposal achieved an expert evaluation score of 6.145 versus 3.963 for DirectChat (+2.182) across GPT, Claude, Gemini, and Qwen backbones. Compared with the structured generation baseline Fars, Story2Proposal obtained an average score of 5.705 versus 5.197, indicating improved structural consistency and visual alignment.
Verifiable Error Bounds for Physics-Informed Neural KKL Observers
Mar 20, 2026This paper proposes a computable state-estimation error bound for learning-based Kazantzis--Kravaris/Luenberger (KKL) observers. Recent work learns the KKL transformation map with a physics-informed neural network (PINN) and a corresponding left-inverse map with a conventional neural network. However, no computable state-estimation error bounds are currently available for this approach. We derive a state-estimation error bound that depends only on quantities that can be certified over a prescribed region using neural network verification. We further extend the result to bounded additive measurement noise and demonstrate the guarantees on nonlinear benchmark systems.
Using Language Models to Detect Alarming Student Responses
May 12, 2023



This article details the advances made to a system that uses artificial intelligence to identify alarming student responses. This system is built into our assessment platform to assess whether a student's response indicates they are a threat to themselves or others. Such responses may include details concerning threats of violence, severe depression, suicide risks, and descriptions of abuse. Driven by advances in natural language processing, the latest model is a fine-tuned language model trained on a large corpus consisting of student responses and supplementary texts. We demonstrate that the use of a language model delivers a substantial improvement in accuracy over the previous iterations of this system.
A Weakly-Supervised Iterative Graph-Based Approach to Retrieve COVID-19 Misinformation Topics
May 19, 2022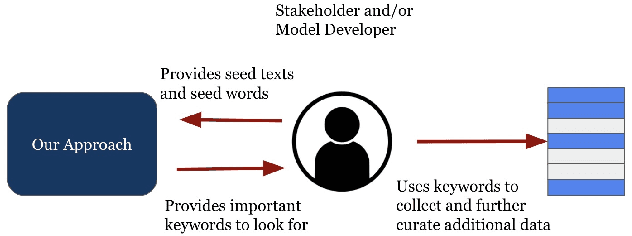
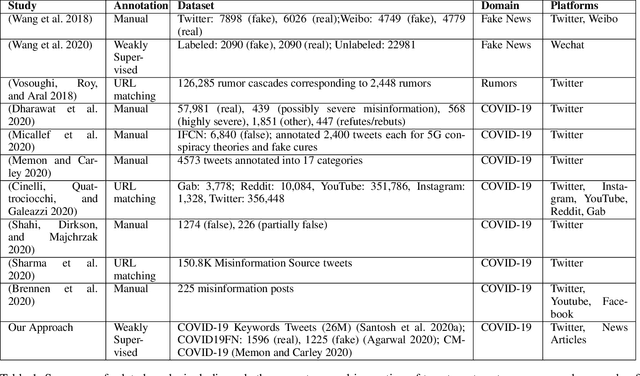
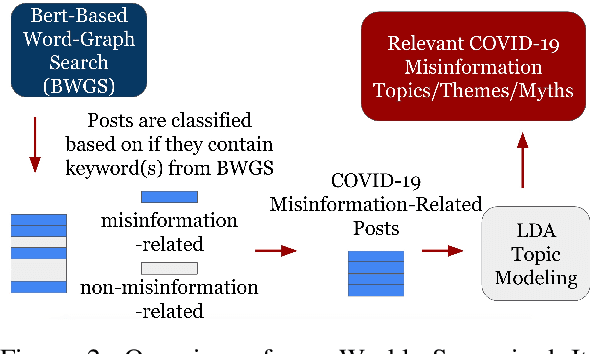
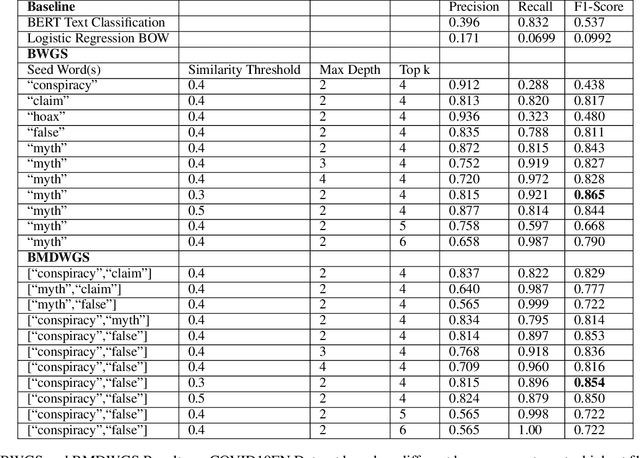
The COVID-19 pandemic has been accompanied by an `infodemic' -- of accurate and inaccurate health information across social media. Detecting misinformation amidst dynamically changing information landscape is challenging; identifying relevant keywords and posts is arduous due to the large amount of human effort required to inspect the content and sources of posts. We aim to reduce the resource cost of this process by introducing a weakly-supervised iterative graph-based approach to detect keywords, topics, and themes related to misinformation, with a focus on COVID-19. Our approach can successfully detect specific topics from general misinformation-related seed words in a few seed texts. Our approach utilizes the BERT-based Word Graph Search (BWGS) algorithm that builds on context-based neural network embeddings for retrieving misinformation-related posts. We utilize Latent Dirichlet Allocation (LDA) topic modeling for obtaining misinformation-related themes from the texts returned by BWGS. Furthermore, we propose the BERT-based Multi-directional Word Graph Search (BMDWGS) algorithm that utilizes greater starting context information for misinformation extraction. In addition to a qualitative analysis of our approach, our quantitative analyses show that BWGS and BMDWGS are effective in extracting misinformation-related content compared to common baselines in low data resource settings. Extracting such content is useful for uncovering prevalent misconceptions and concerns and for facilitating precision public health messaging campaigns to improve health behaviors.