 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
League of Legends: Real-Time Result Prediction
Sep 02, 2023
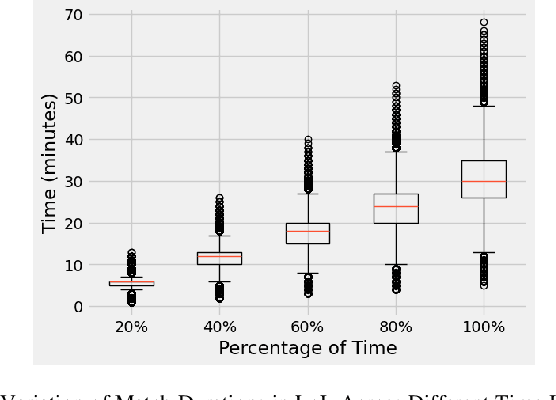
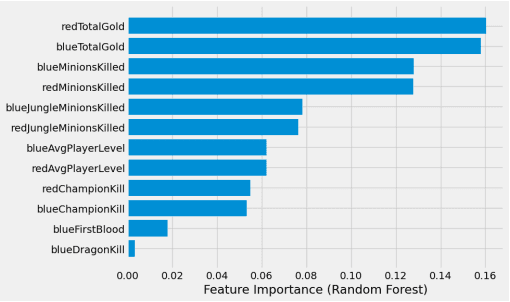
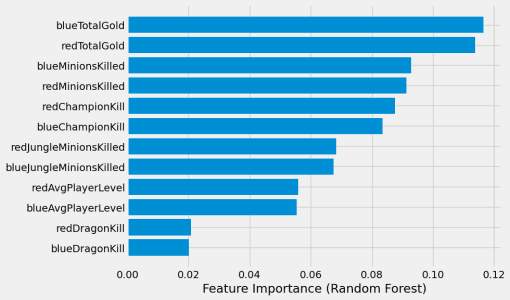
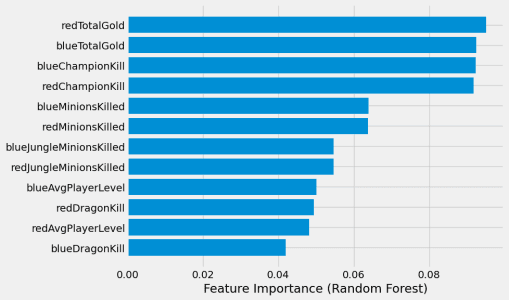
This paper presents a study on the prediction of outcomes in matches of the electronic game League of Legends (LoL) using machine learning techniques. With the aim of exploring the ability to predict real-time results, considering different variables and stages of the match, we highlight the use of unpublished data as a fundamental part of this process. With the increasing popularity of LoL and the emergence of tournaments, betting related to the game has also emerged, making the investigation in this area even more relevant. A variety of models were evaluated and the results were encouraging. A model based on LightGBM showed the best performance, achieving an average accuracy of 81.62\% in intermediate stages of the match when the percentage of elapsed time was between 60\% and 80\%. On the other hand, the Logistic Regression and Gradient Boosting models proved to be more effective in early stages of the game, with promising results. This study contributes to the field of machine learning applied to electronic games, providing valuable insights into real-time prediction in League of Legends. The results obtained may be relevant for both players seeking to improve their strategies and the betting industry related to the game.
Sentiment Analysis in Digital Spaces: An Overview of Reviews
Oct 30, 2023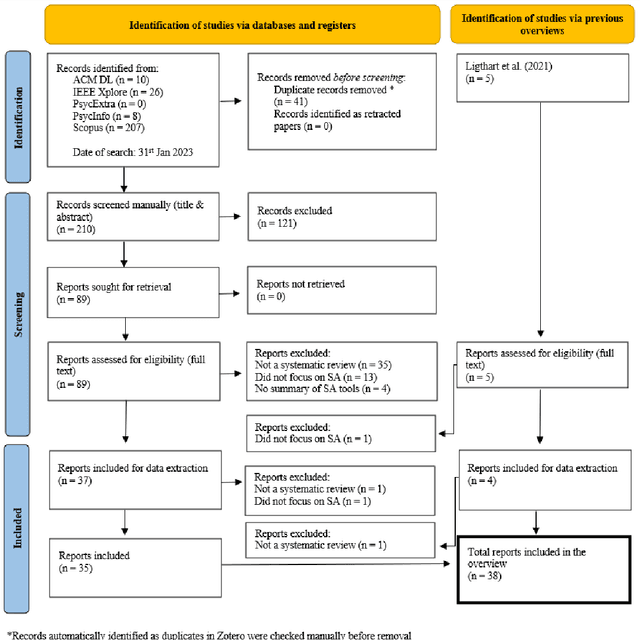


Sentiment analysis (SA) is commonly applied to digital textual data, revealing insight into opinions and feelings. Many systematic reviews have summarized existing work, but often overlook discussions of validity and scientific practices. Here, we present an overview of reviews, synthesizing 38 systematic reviews, containing 2,275 primary studies. We devise a bespoke quality assessment framework designed to assess the rigor and quality of systematic review methodologies and reporting standards. Our findings show diverse applications and methods, limited reporting rigor, and challenges over time. We discuss how future research and practitioners can address these issues and highlight their importance across numerous applications.
Bayesian Simulation-based Inference for Cosmological Initial Conditions
Oct 30, 2023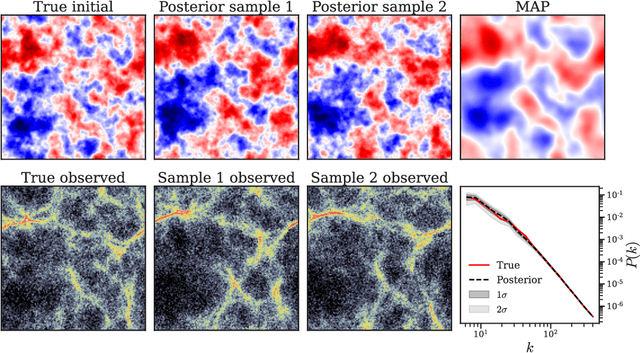
Reconstructing astrophysical and cosmological fields from observations is challenging. It requires accounting for non-linear transformations, mixing of spatial structure, and noise. In contrast, forward simulators that map fields to observations are readily available for many applications. We present a versatile Bayesian field reconstruction algorithm rooted in simulation-based inference and enhanced by autoregressive modeling. The proposed technique is applicable to generic (non-differentiable) forward simulators and allows sampling from the posterior for the underlying field. We show first promising results on a proof-of-concept application: the recovery of cosmological initial conditions from late-time density fields.
A Systematic Comparison of Syllogistic Reasoning in Humans and Language Models
Nov 01, 2023A central component of rational behavior is logical inference: the process of determining which conclusions follow from a set of premises. Psychologists have documented several ways in which humans' inferences deviate from the rules of logic. Do language models, which are trained on text generated by humans, replicate these biases, or are they able to overcome them? Focusing on the case of syllogisms -- inferences from two simple premises, which have been studied extensively in psychology -- we show that larger models are more logical than smaller ones, and also more logical than humans. At the same time, even the largest models make systematic errors, some of which mirror human reasoning biases such as ordering effects and logical fallacies. Overall, we find that language models mimic the human biases included in their training data, but are able to overcome them in some cases.
Generalization Bounds for Label Noise Stochastic Gradient Descent
Nov 01, 2023We develop generalization error bounds for stochastic gradient descent (SGD) with label noise in non-convex settings under uniform dissipativity and smoothness conditions. Under a suitable choice of semimetric, we establish a contraction in Wasserstein distance of the label noise stochastic gradient flow that depends polynomially on the parameter dimension $d$. Using the framework of algorithmic stability, we derive time-independent generalisation error bounds for the discretized algorithm with a constant learning rate. The error bound we achieve scales polynomially with $d$ and with the rate of $n^{-2/3}$, where $n$ is the sample size. This rate is better than the best-known rate of $n^{-1/2}$ established for stochastic gradient Langevin dynamics (SGLD) -- which employs parameter-independent Gaussian noise -- under similar conditions. Our analysis offers quantitative insights into the effect of label noise.
Time Series Analysis of Urban Liveability
Sep 01, 2023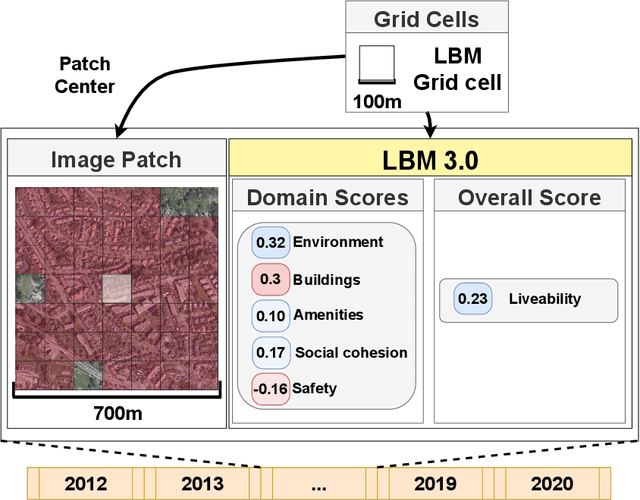
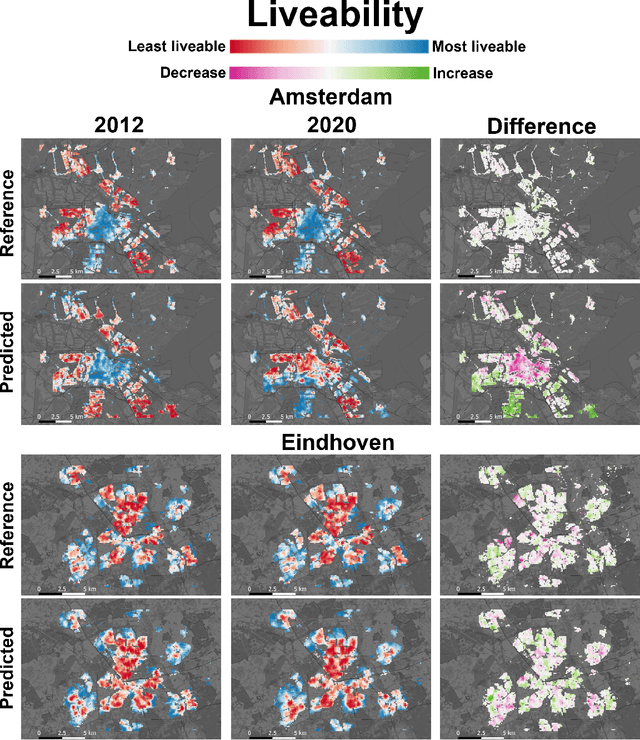
In this paper we explore deep learning models to monitor longitudinal liveability changes in Dutch cities at the neighbourhood level. Our liveability reference data is defined by a country-wise yearly survey based on a set of indicators combined into a liveability score, the Leefbaarometer. We pair this reference data with yearly-available high-resolution aerial images, which creates yearly timesteps at which liveability can be monitored. We deploy a convolutional neural network trained on an aerial image from 2016 and the Leefbaarometer score to predict liveability at new timesteps 2012 and 2020. The results in a city used for training (Amsterdam) and one never seen during training (Eindhoven) show some trends which are difficult to interpret, especially in light of the differences in image acquisitions at the different time steps. This demonstrates the complexity of liveability monitoring across time periods and the necessity for more sophisticated methods compensating for changes unrelated to liveability dynamics.
* Accepted at JURSE 2023
Jorge: Approximate Preconditioning for GPU-efficient Second-order Optimization
Oct 27, 2023Despite their better convergence properties compared to first-order optimizers, second-order optimizers for deep learning have been less popular due to their significant computational costs. The primary efficiency bottleneck in such optimizers is matrix inverse calculations in the preconditioning step, which are expensive to compute on GPUs. In this paper, we introduce Jorge, a second-order optimizer that promises the best of both worlds -- rapid convergence benefits of second-order methods, and high computational efficiency typical of first-order methods. We address the primary computational bottleneck of computing matrix inverses by completely eliminating them using an approximation of the preconditioner computation. This makes Jorge extremely efficient on GPUs in terms of wall-clock time. Further, we describe an approach to determine Jorge's hyperparameters directly from a well-tuned SGD baseline, thereby significantly minimizing tuning efforts. Our empirical evaluations demonstrate the distinct advantages of using Jorge, outperforming state-of-the-art optimizers such as SGD, AdamW, and Shampoo across multiple deep learning models, both in terms of sample efficiency and wall-clock time.
ArcheType: A Novel Framework for Open-Source Column Type Annotation using Large Language Models
Oct 27, 2023Existing deep-learning approaches to semantic column type annotation (CTA) have important shortcomings: they rely on semantic types which are fixed at training time; require a large number of training samples per type and incur large run-time inference costs; and their performance can degrade when evaluated on novel datasets, even when types remain constant. Large language models have exhibited strong zero-shot classification performance on a wide range of tasks and in this paper we explore their use for CTA. We introduce ArcheType, a simple, practical method for context sampling, prompt serialization, model querying, and label remapping, which enables large language models to solve column type annotation problems in a fully zero-shot manner. We ablate each component of our method separately, and establish that improvements to context sampling and label remapping provide the most consistent gains. ArcheType establishes new state-of-the-art performance on both zero-shot and fine-tuned CTA, including three new domain-specific benchmarks, which we release, along with the code to reproduce our results at https://github.com/penfever/ArcheType.
Burgers' pinns with implicit euler transfer learning
Oct 23, 2023The Burgers equation is a well-established test case in the computational modeling of several phenomena such as fluid dynamics, gas dynamics, shock theory, cosmology, and others. In this work, we present the application of Physics-Informed Neural Networks (PINNs) with an implicit Euler transfer learning approach to solve the Burgers equation. The proposed approach consists in seeking a time-discrete solution by a sequence of Artificial Neural Networks (ANNs). At each time step, the previous ANN transfers its knowledge to the next network model, which learns the current time solution by minimizing a loss function based on the implicit Euler approximation of the Burgers equation. The approach is tested for two benchmark problems: the first with an exact solution and the other with an alternative analytical solution. In comparison to the usual PINN models, the proposed approach has the advantage of requiring smaller neural network architectures with similar accurate results and potentially decreasing computational costs.
A self-adaptive genetic algorithm for the flying sidekick travelling salesman problem
Oct 23, 2023This paper presents a novel approach to solving the Flying Sidekick Travelling Salesman Problem (FSTSP) using a state-of-the-art self-adaptive genetic algorithm. The Flying Sidekick Travelling Salesman Problem is a combinatorial optimisation problem that extends the Travelling Salesman Problem (TSP) by introducing the use of drones. In FSTSP, the objective is to minimise the total time to visit all locations while strategically deploying a drone to serve hard-to-reach customer locations. Also, to the best of my knowledge, this is the first time a self-adaptive genetic algorithm (GA) has been used to solve the FSTSP problem. Experimental results on smaller-sized problem instances demonstrate that this algorithm can find a higher quantity of optimal solutions and a lower percentage gap to the optimal solution compared to rival algorithms. Moreover, on larger-sized problem instances, this algorithm outperforms all rival algorithms on each problem size while maintaining a reasonably low computation time.