 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
One-dimensional Deep Image Prior for Time Series Inverse Problems
Apr 18, 2019
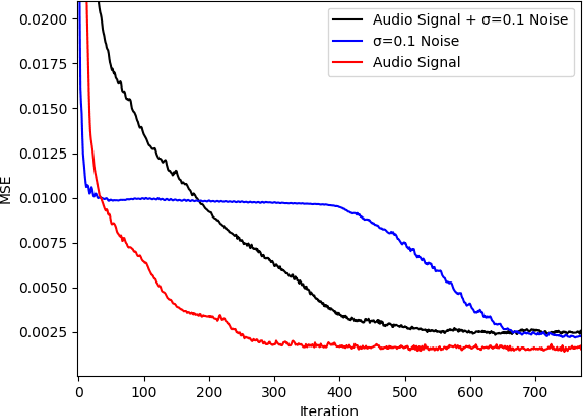
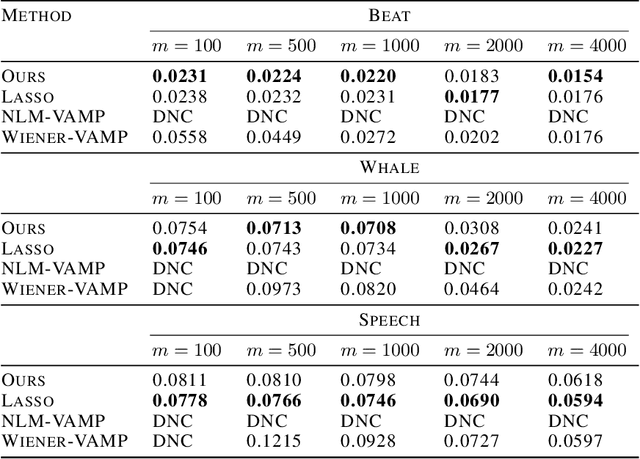
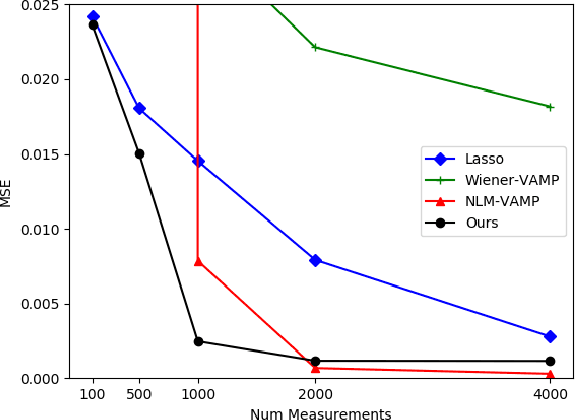

We extend the Deep Image Prior (DIP) framework to one-dimensional signals. DIP is using a randomly initialized convolutional neural network (CNN) to solve linear inverse problems by optimizing over weights to fit the observed measurements. Our main finding is that properly tuned one-dimensional convolutional architectures provide an excellent Deep Image Prior for various types of temporal signals including audio, biological signals, and sensor measurements. We show that our network can be used in a variety of recovery tasks including missing value imputation, blind denoising, and compressed sensing from random Gaussian projections. The key challenge is how to avoid overfitting by carefully tuning early stopping, total variation, and weight decay regularization. Our method requires up to 4 times fewer measurements than Lasso and outperforms NLM-VAMP for random Gaussian measurements on audio signals, has similar imputation performance to a Kalman state-space model on a variety of data, and outperforms wavelet filtering in removing additive noise from air-quality sensor readings.
Multinomial Sampling for Hierarchical Change-Point Detection
Jul 24, 2020

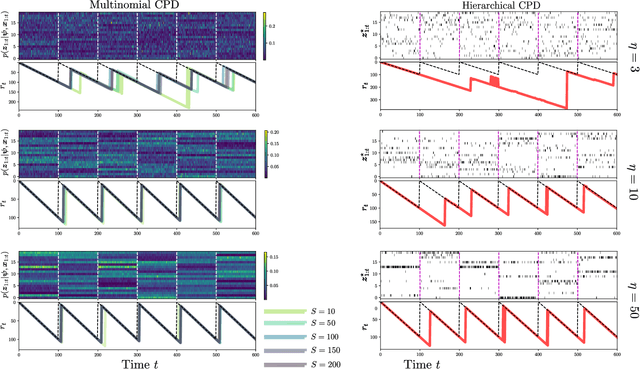
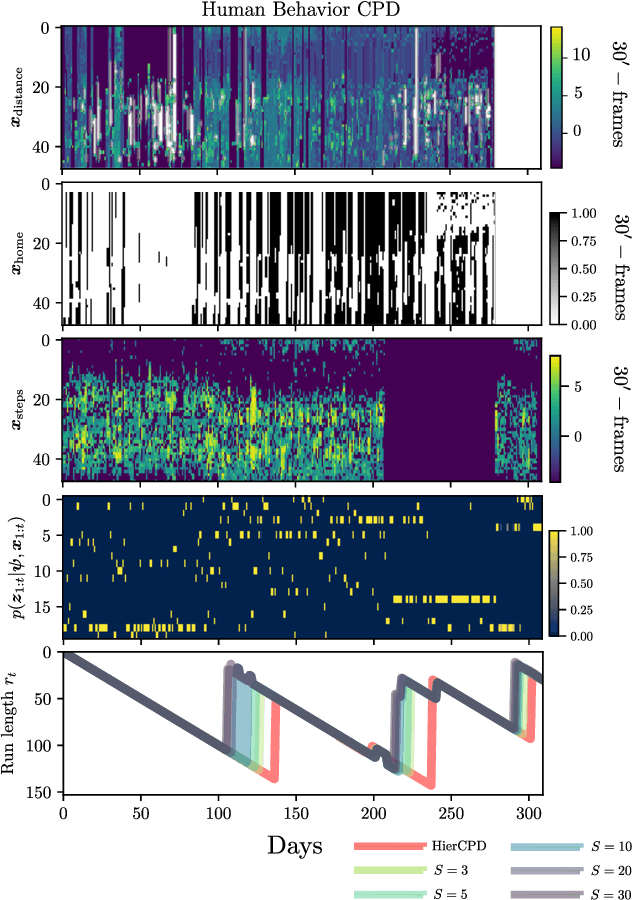
Bayesian change-point detection, together with latent variable models, allows to perform segmentation over high-dimensional time-series. We assume that change-points lie on a lower-dimensional manifold where we aim to infer subsets of discrete latent variables. For this model, full inference is computationally unfeasible and pseudo-observations based on point-estimates are used instead. However, if estimation is not certain enough, change-point detection gets affected. To circumvent this problem, we propose a multinomial sampling methodology that improves the detection rate and reduces the delay while keeping complexity stable and inference analytically tractable. Our experiments show results that outperform the baseline method and we also provide an example oriented to a human behavior study.
ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM
Jul 23, 2020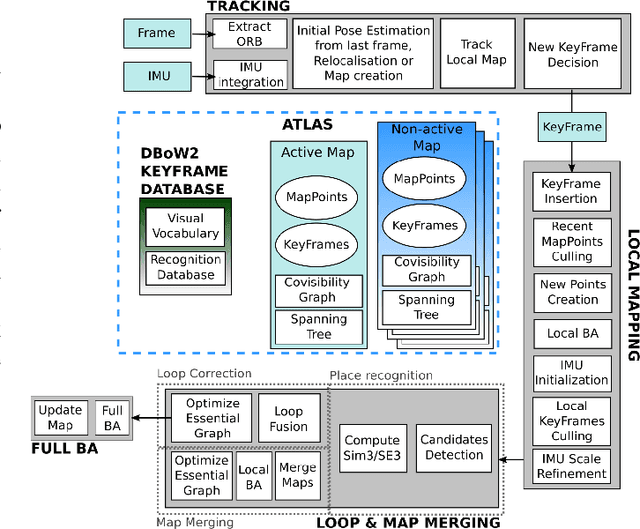
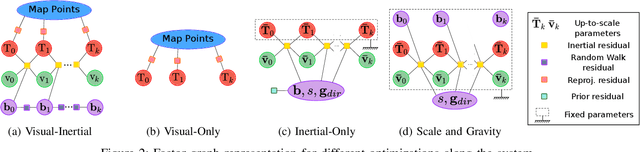
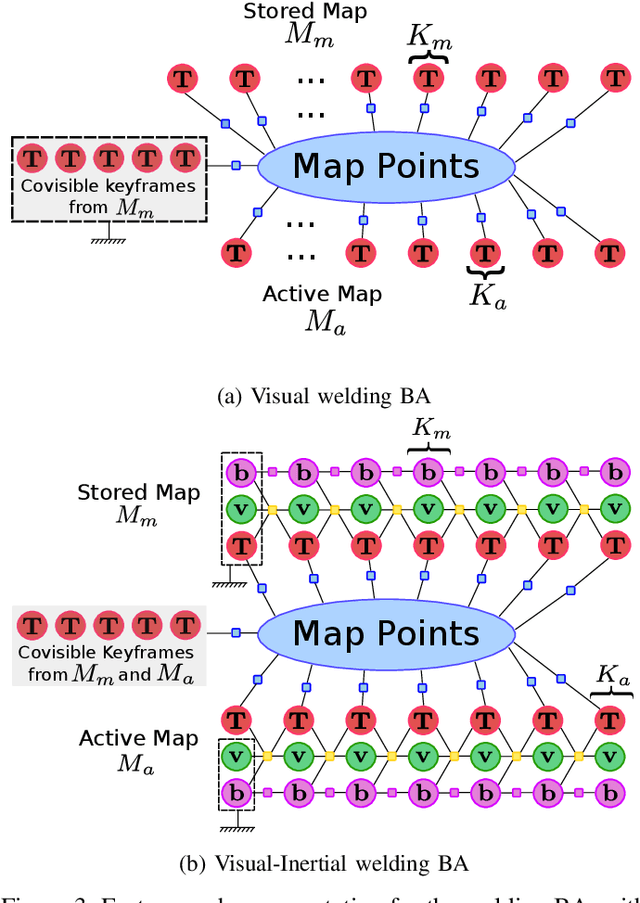
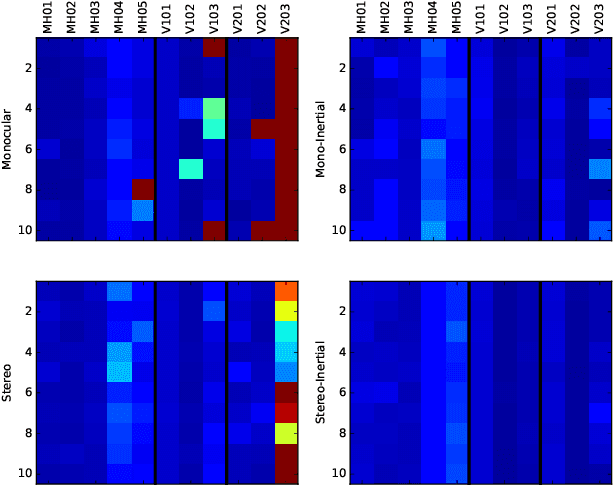
This paper presents ORB-SLAM3, the first system able to perform visual, visual-inertial and multi-map SLAM with monocular, stereo and RGB-D cameras, using pin-hole and fisheye lens models. The first main novelty is a feature-based tightly-integrated visual-inertial SLAM system that fully relies on Maximum-a-Posteriori (MAP) estimation, even during the IMU initialization phase. The result is a system that operates robustly in real-time, in small and large, indoor and outdoor environments, and is 2 to 5 times more accurate than previous approaches. The second main novelty is a multiple map system that relies on a new place recognition method with improved recall. Thanks to it, ORB-SLAM3 is able to survive to long periods of poor visual information: when it gets lost, it starts a new map that will be seamlessly merged with previous maps when revisiting mapped areas. Compared with visual odometry systems that only use information from the last few seconds, ORB-SLAM3 is the first system able to reuse in all the algorithm stages all previous information. This allows to include in bundle adjustment co-visible keyframes, that provide high parallax observations boosting accuracy, even if they are widely separated in time or if they come from a previous mapping session. Our experiments show that, in all sensor configurations, ORB-SLAM3 is as robust as the best systems available in the literature, and significantly more accurate. Notably, our stereo-inertial SLAM achieves an average accuracy of 3.6 cm on the EuRoC drone and 9 mm under quick hand-held motions in the room of TUM-VI dataset, a setting representative of AR/VR scenarios. For the benefit of the community we make public the source code.
Adaptive County Level COVID-19 Forecast Models: Analysis and Improvement
Jun 16, 2020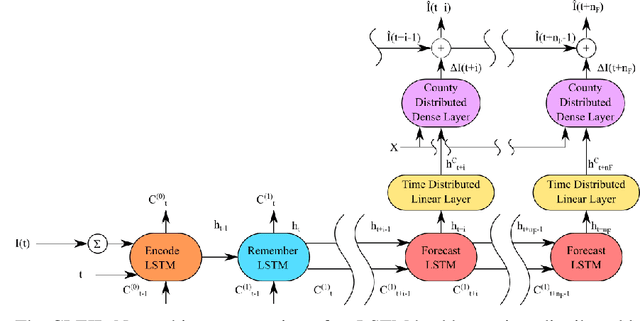
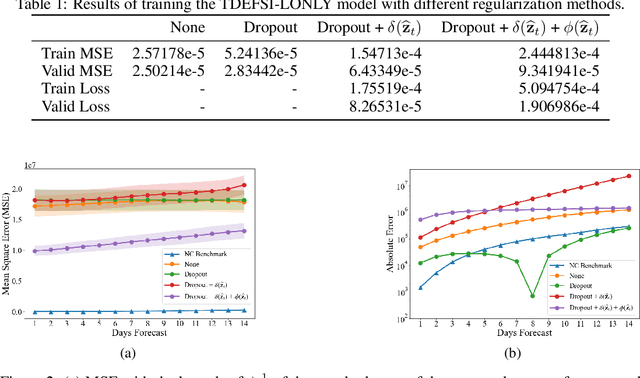
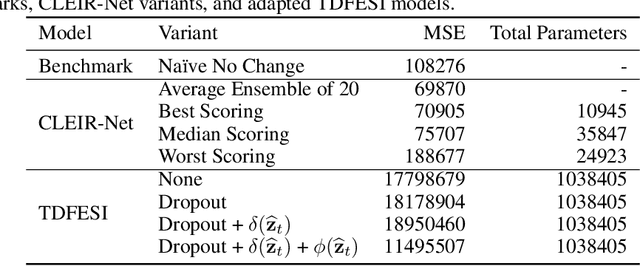
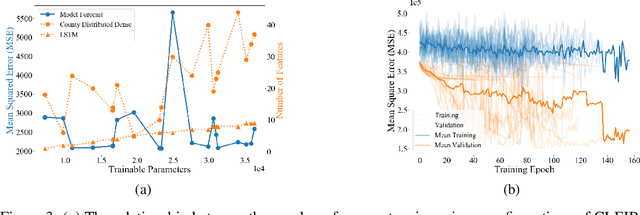
Accurately forecasting county level COVID-19 confirmed cases is crucial to optimizing medical resources. Forecasting emerging outbreaks pose a particular challenge because many existing forecasting techniques learn from historical seasons trends. Recurrent neural networks (RNNs) with LSTM-based cells are a logical choice of model due to their ability to learn temporal dynamics. In this paper, we adapt the state and county level influenza model, TDEFSI-LONLY, proposed in Wang et a. [l2020] to national and county level COVID-19 data. We show that this model poorly forecasts the current pandemic. We analyze the two week ahead forecasting capabilities of the TDEFSI-LONLY model with combinations of regularization techniques. Effective training of the TDEFSI-LONLY model requires data augmentation, to overcome this challenge we utilize an SEIR model and present an inter-county mixing extension to this model to simulate sufficient training data. Further, we propose an alternate forecast model, {\it County Level Epidemiological Inference Recurrent Network} (\alg{}) that trains an LSTM backbone on national confirmed cases to learn a low dimensional time pattern and utilizes a time distributed dense layer to learn individual county confirmed case changes each day for a two weeks forecast. We show that the best, worst, and median state forecasts made using CLEIR-Net model are respectively New York, South Carolina, and Montana.
UniNet: Scalable Network Representation Learning with Metropolis-Hastings Sampling
Oct 10, 2020
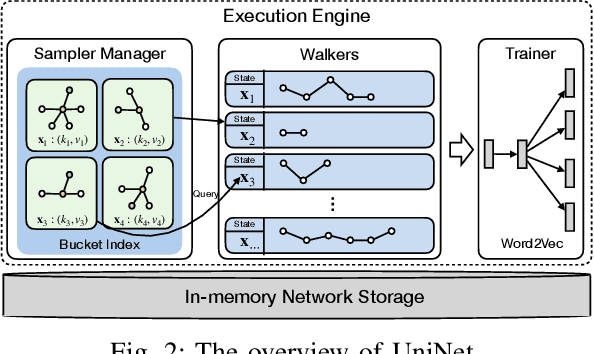

Network representation learning (NRL) technique has been successfully adopted in various data mining and machine learning applications. Random walk based NRL is one popular paradigm, which uses a set of random walks to capture the network structural information, and then employs word2vec models to learn the low-dimensional representations. However, until now there is lack of a framework, which unifies existing random walk based NRL models and supports to efficiently learn from large networks. The main obstacle comes from the diverse random walk models and the inefficient sampling method for the random walk generation. In this paper, we first introduce a new and efficient edge sampler based on Metropolis-Hastings sampling technique, and theoretically show the convergence property of the edge sampler to arbitrary discrete probability distributions. Then we propose a random walk model abstraction, in which users can easily define different transition probability by specifying dynamic edge weights and random walk states. The abstraction is efficiently supported by our edge sampler, since our sampler can draw samples from unnormalized probability distribution in constant time complexity. Finally, with the new edge sampler and random walk model abstraction, we carefully implement a scalable NRL framework called UniNet. We conduct comprehensive experiments with five random walk based NRL models over eleven real-world datasets, and the results clearly demonstrate the efficiency of UniNet over billion-edge networks.
Unsupervised Abnormality Detection Using Heterogeneous Autonomous Systems
Jun 05, 2020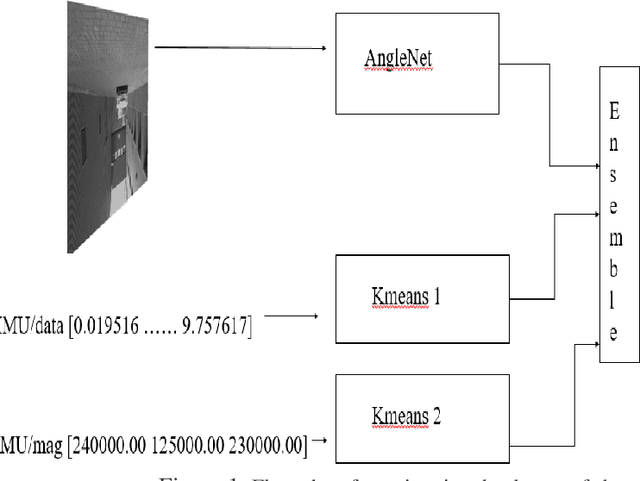


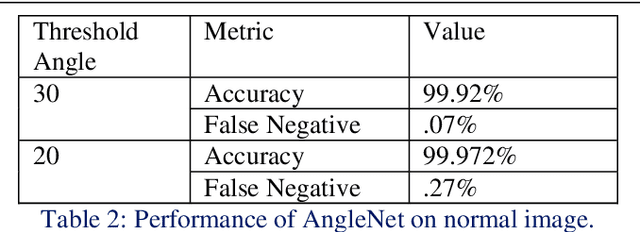
Anomaly detection in a surveillance scenario is an emerging and challenging field of research. For autonomous vehicles like drones or cars, it is immensely important to distinguish between normal and abnormal states in real-time to avoid/detect potential threats. But the nature and degree of abnormality may vary depending upon the actual environment and adversary. As a result, it is impractical to model all cases a priori and use supervised methods to classify. Also, an autonomous vehicle provides various data types like images and other analog or digital sensor data. In this paper, a heterogeneous system is proposed which estimates the degree of abnormality of an environment using drone-feed, analyzing real-time image and IMU sensor data in an unsupervised manner. Here, we have demonstrated AngleNet (a novel CNN architecture) to estimate the angle between a normal image and another image under consideration, which provides us with a measure of anomaly. Moreover, the IMU data are used in clustering models to predict abnormality. Finally, the results from these two algorithms are ensembled to estimate the final abnormality. The proposed method performs satisfactorily on the IEEE SP Cup-2020 dataset with an accuracy of 99.92%. Additionally, we have also tested this approach on an in-house dataset to validate its robustness.
Differential Replication in Machine Learning
Jul 15, 2020
When deployed in the wild, machine learning models are usually confronted with data and requirements that constantly vary, either because of changes in the generating distribution or because external constraints change the environment where the model operates. To survive in such an ecosystem, machine learning models need to adapt to new conditions by evolving over time. The idea of model adaptability has been studied from different perspectives. In this paper, we propose a solution based on reusing the knowledge acquired by the already deployed machine learning models and leveraging it to train future generations. This is the idea behind differential replication of machine learning models.
Data-driven Flood Emulation: Speeding up Urban Flood Predictions by Deep Convolutional Neural Networks
May 13, 2020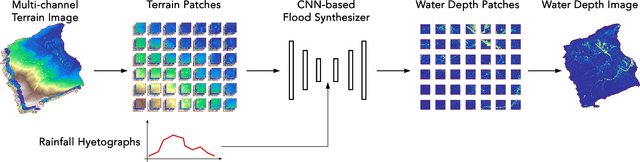
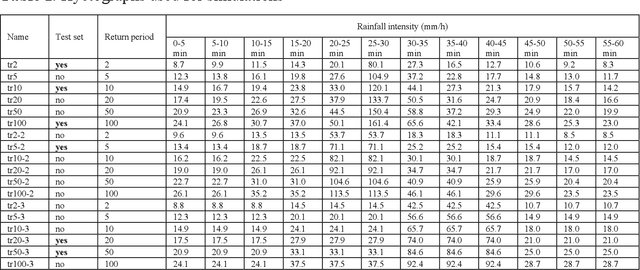
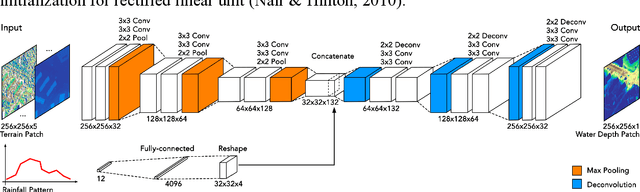
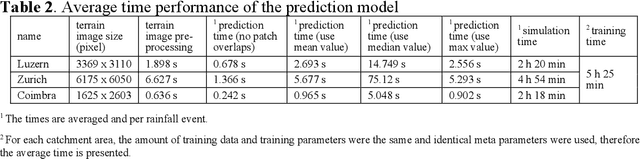
Computational complexity has been the bottleneck of applying physically-based simulations on large urban areas with high spatial resolution for efficient and systematic flooding analyses and risk assessments. To address this issue of long computational time, this paper proposes that the prediction of maximum water depth rasters can be considered as an image-to-image translation problem where the results are generated from input elevation rasters using the information learned from data rather than by conducting simulations, which can significantly accelerate the prediction process. The proposed approach was implemented by a deep convolutional neural network trained on flood simulation data of 18 designed hyetographs on three selected catchments. Multiple tests with both designed and real rainfall events were performed and the results show that the flood predictions by neural network uses only 0.5 % of time comparing with physically-based approaches, with promising accuracy and ability of generalizations. The proposed neural network can also potentially be applied to different but relevant problems including flood predictions for urban layout planning.
The MIDI Degradation Toolkit: Symbolic Music Augmentation and Correction
Sep 30, 2020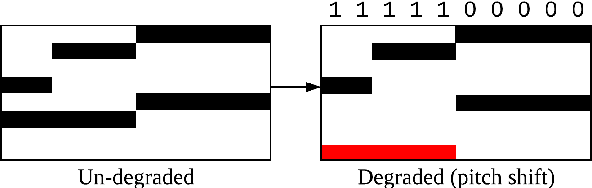
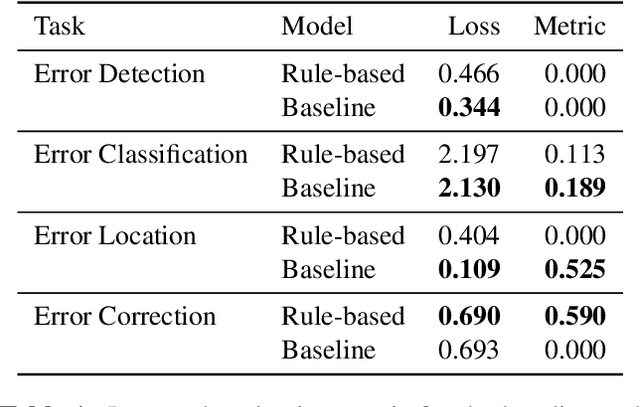
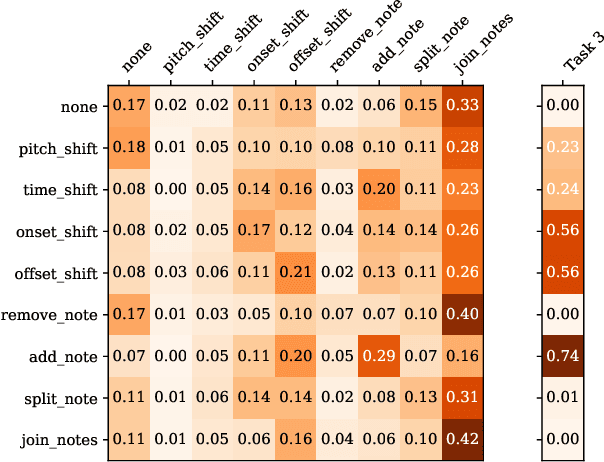
In this paper, we introduce the MIDI Degradation Toolkit (MDTK), containing functions which take as input a musical excerpt (a set of notes with pitch, onset time, and duration), and return a "degraded" version of that excerpt with some error (or errors) introduced. Using the toolkit, we create the Altered and Corrupted MIDI Excerpts dataset version 1.0 (ACME v1.0), and propose four tasks of increasing difficulty to detect, classify, locate, and correct the degradations. We hypothesize that models trained for these tasks can be useful in (for example) improving automatic music transcription performance if applied as a post-processing step. To that end, MDTK includes a script that measures the distribution of different types of errors in a transcription, and creates a degraded dataset with similar properties. MDTK's degradations can also be applied dynamically to a dataset during training (with or without the above script), generating novel degraded excerpts each epoch. MDTK could also be used to test the robustness of any system designed to take MIDI (or similar) data as input (e.g. systems designed for voice separation, metrical alignment, or chord detection) to such transcription errors or otherwise noisy data. The toolkit and dataset are both publicly available online, and we encourage contribution and feedback from the community.
Machine learning as a flaring storm warning machine: Was a warning machine for the September 2017 solar flaring storm possible?
Jul 05, 2020
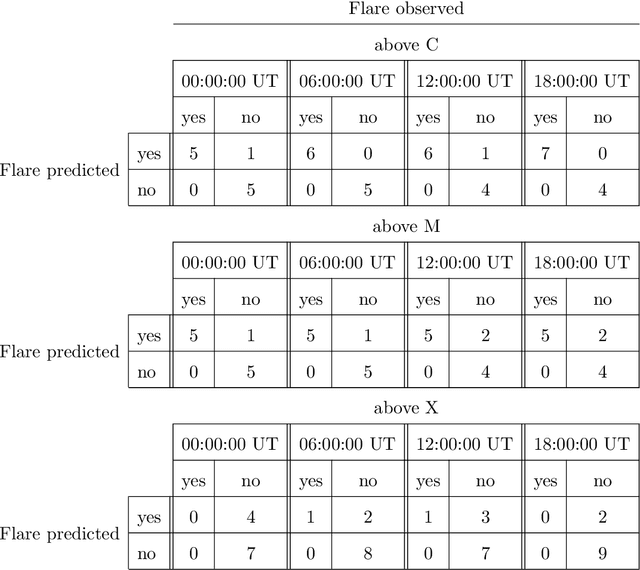
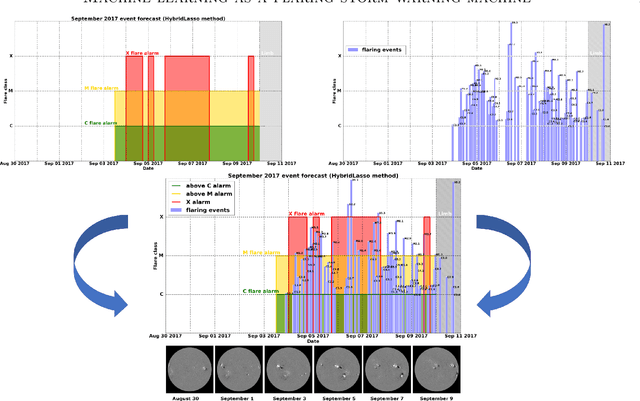
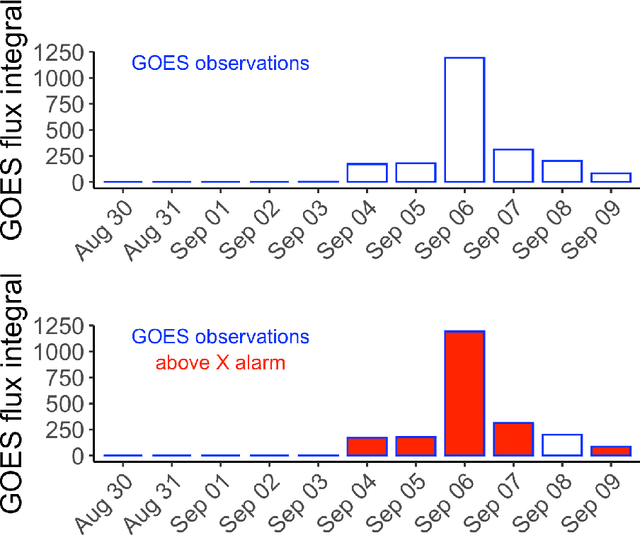
Machine learning is nowadays the methodology of choice for flare forecasting and supervised techniques, in both their traditional and deep versions, are becoming the most frequently used ones for prediction in this area of space weather. Yet, machine learning has not been able so far to realize an operating warning system for flaring storms and the scientific literature of the last decade suggests that its performances in the prediction of intense solar flares are not optimal. The main difficulties related to forecasting solar flaring storms are probably two. First, most methods are conceived to provide probabilistic predictions and not to send binary yes/no indications on the consecutive occurrence of flares along an extended time range. Second, flaring storms are typically characterized by the explosion of high energy events, which are seldom recorded in the databases of space missions; as a consequence, supervised methods are trained on very imbalanced historical sets, which makes them particularly ineffective for the forecasting of intense flares. Yet, in this study we show that supervised machine learning could be utilized in a way to send timely warnings about the most violent and most unexpected flaring event of the last decade, and even to predict with some accuracy the energy budget daily released by magnetic reconnection during the whole time course of the storm. Further, we show that the combination of sparsity-enhancing machine learning and feature ranking could allow the identification of the prominent role that energy played as an Active Region property in the forecasting process.