 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Residual acoustic echo suppression based on efficient multi-task convolutional neural network
Sep 29, 2020




Acoustic echo degrades the user experience in voice communication systems thus needs to be suppressed completely. We propose a real-time residual acoustic echo suppression (RAES) method using an efficient convolutional neural network. The double talk detector is used as an auxiliary task to improve the performance of RAES in the context of multi-task learning. The training criterion is based on a novel loss function, which we call as the suppression loss, to balance the suppression of residual echo and the distortion of near-end signals. The experimental results show that the proposed method can efficiently suppress the residual echo under different circumstances.
Tick: a Python library for statistical learning, with a particular emphasis on time-dependent modelling
Mar 15, 2018

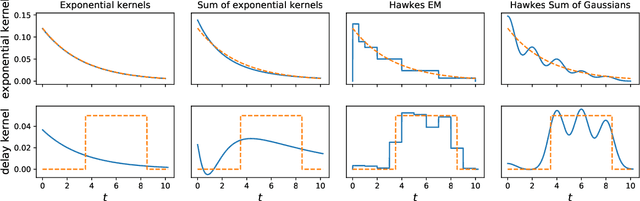
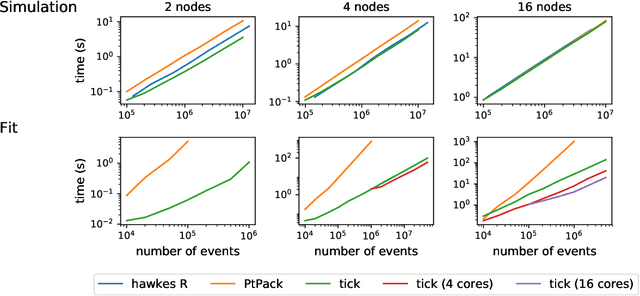
Tick is a statistical learning library for Python~3, with a particular emphasis on time-dependent models, such as point processes, and tools for generalized linear models and survival analysis. The core of the library is an optimization module providing model computational classes, solvers and proximal operators for regularization. tick relies on a C++ implementation and state-of-the-art optimization algorithms to provide very fast computations in a single node multi-core setting. Source code and documentation can be downloaded from https://github.com/X-DataInitiative/tick
$C^3DRec$: Cloud-Client Cooperative Deep Learning for Temporal Recommendation in the Post-GDPR Era
Jan 13, 2021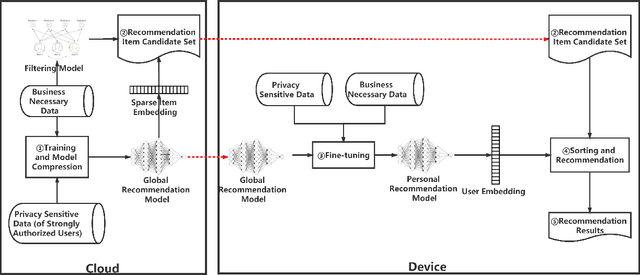

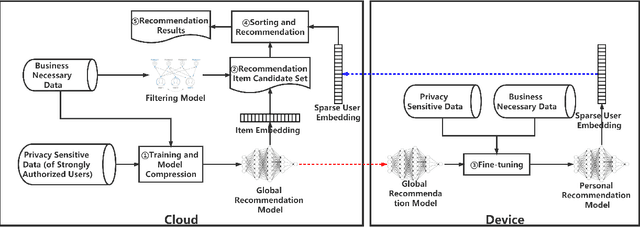
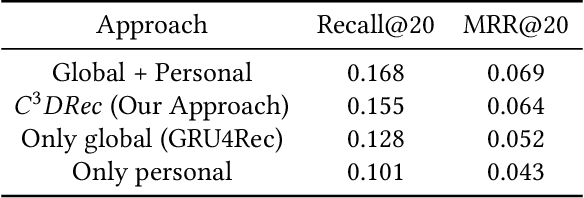
Mobile devices enable users to retrieve information at any time and any place. Considering the occasional requirements and fragmentation usage pattern of mobile users, temporal recommendation techniques are proposed to improve the efficiency of information retrieval on mobile devices by means of accurately recommending items via learning temporal interests with short-term user interaction behaviors. However, the enforcement of privacy-preserving laws and regulations, such as GDPR, may overshadow the successful practice of temporal recommendation. The reason is that state-of-the-art recommendation systems require to gather and process the user data in centralized servers but the interaction behaviors data used for temporal recommendation are usually non-transactional data that are not allowed to gather without the explicit permission of users according to GDPR. As a result, if users do not permit services to gather their interaction behaviors data, the temporal recommendation fails to work. To realize the temporal recommendation in the post-GDPR era, this paper proposes $C^3DRec$, a cloud-client cooperative deep learning framework of mining interaction behaviors for recommendation while preserving user privacy. $C^3DRec$ constructs a global recommendation model on centralized servers using data collected before GDPR and fine-tunes the model directly on individual local devices using data collected after GDPR. We design two modes to accomplish the recommendation, i.e. pull mode where candidate items are pulled down onto the devices and fed into the local model to get recommended items, and push mode where the output of the local model is pushed onto the server and combined with candidate items to get recommended ones. Evaluation results show that $C^3DRec$ achieves comparable recommendation accuracy to the centralized approaches, with minimal privacy concern.
Real-Time Visual Place Recognition for Personal Localization on a Mobile Device
Apr 27, 2017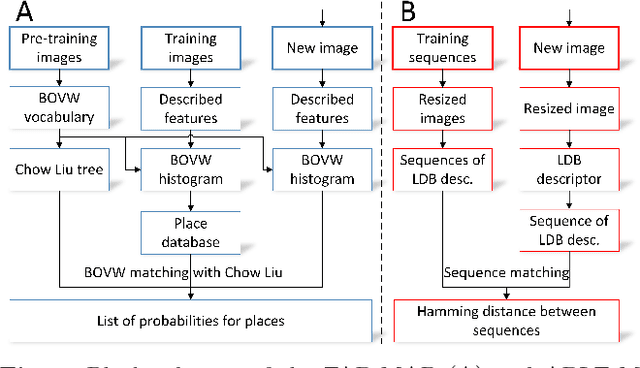
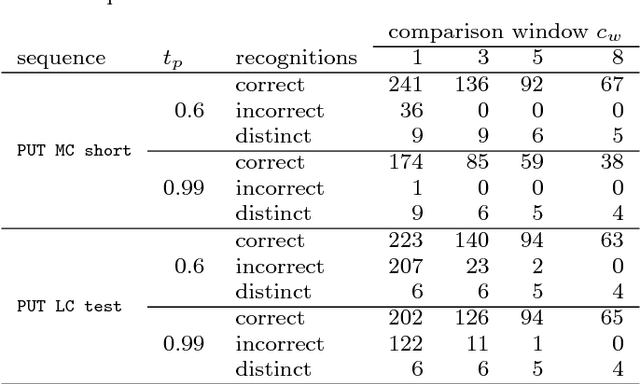
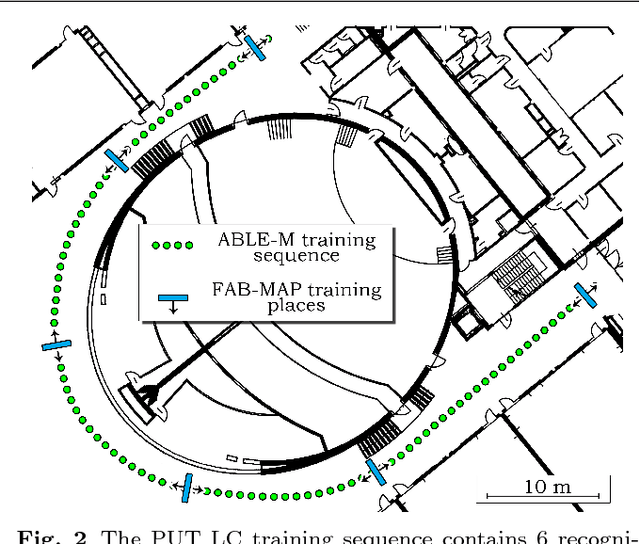
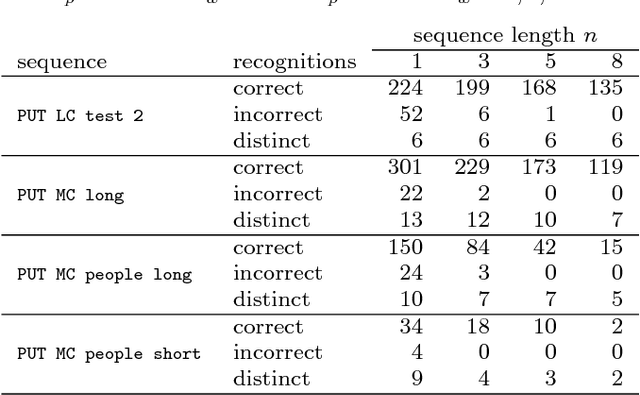
The paper presents an approach to indoor personal localization on a mobile device based on visual place recognition. We implemented on a smartphone two state-of-the-art algorithms that are representative to two different approaches to visual place recognition: FAB-MAP that recognizes places using individual images, and ABLE-M that utilizes sequences of images. These algorithms are evaluated in environments of different structure, focusing on problems commonly encountered when a mobile device camera is used. The conclusions drawn from this evaluation are guidelines to design the FastABLE system, which is based on the ABLE-M algorithm, but introduces major modifications to the concept of image matching. The improvements radically cut down the processing time and improve scalability, making it possible to localize the user in long image sequences with the limited computing power of a mobile device. The resulting place recognition system compares favorably to both the ABLE-M and the FAB-MAP solutions in the context of real-time personal localization.
Multi-Modal Subjective Context Modelling and Recognition
Nov 19, 2020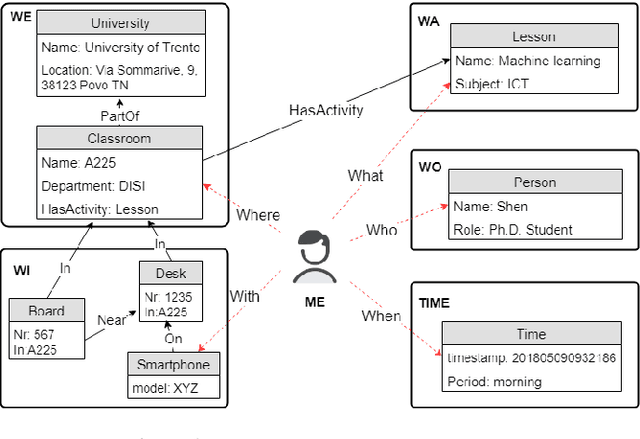

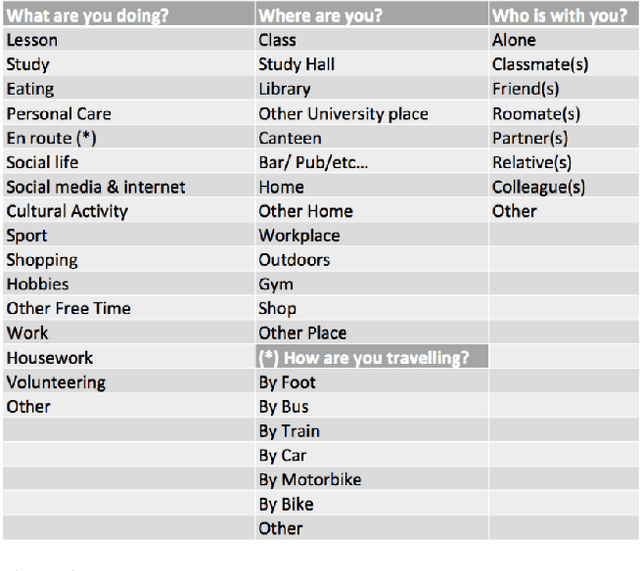
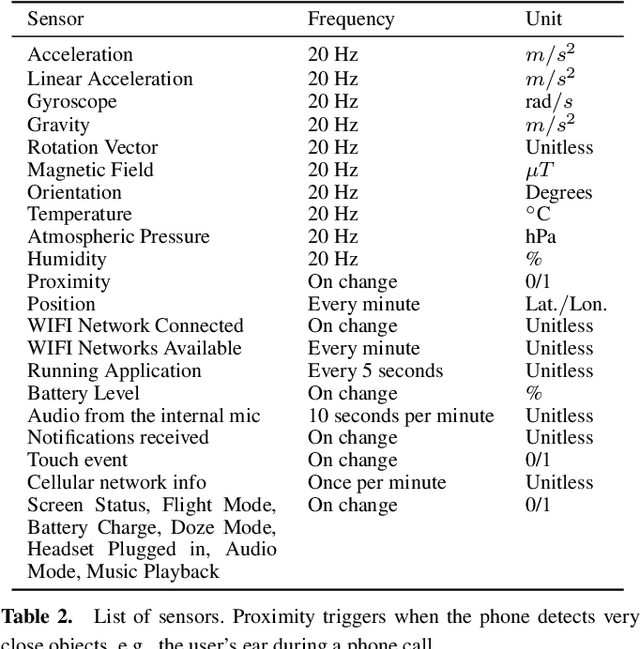
Applications like personal assistants need to be aware ofthe user's context, e.g., where they are, what they are doing, and with whom. Context information is usually inferred from sensor data, like GPS sensors and accelerometers on the user's smartphone. This prediction task is known as context recognition. A well-defined context model is fundamental for successful recognition. Existing models, however, have two major limitations. First, they focus on few aspects, like location or activity, meaning that recognition methods based onthem can only compute and leverage few inter-aspect correlations. Second, existing models typically assume that context is objective, whereas in most applications context is best viewed from the user's perspective. Neglecting these factors limits the usefulness of the context model and hinders recognition. We present a novel ontological context model that captures five dimensions, namely time, location, activity, social relations and object. Moreover, our model defines three levels of description(objective context, machine context and subjective context) that naturally support subjective annotations and reasoning.An initial context recognition experiment on real-world data hints at the promise of our model.
Sequential Changepoint Detection in Neural Networks with Checkpoints
Oct 06, 2020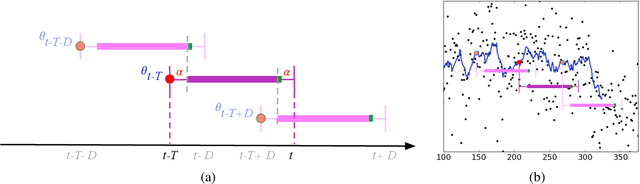
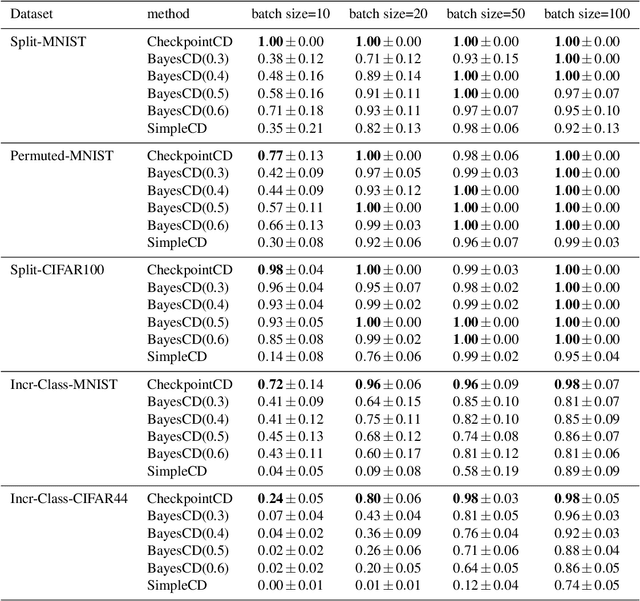
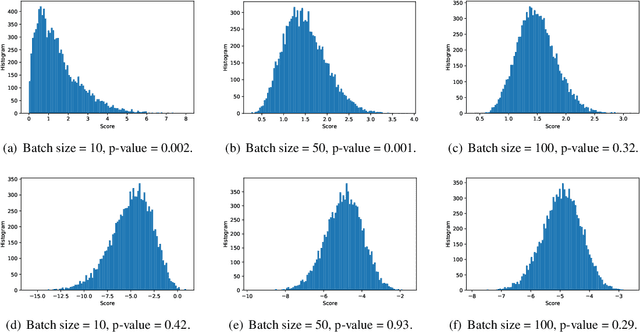
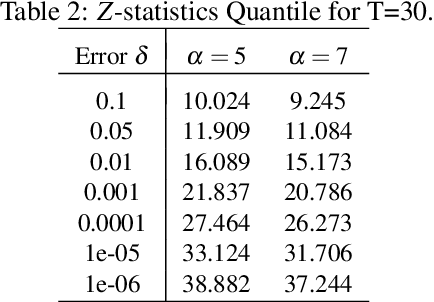
We introduce a framework for online changepoint detection and simultaneous model learning which is applicable to highly parametrized models, such as deep neural networks. It is based on detecting changepoints across time by sequentially performing generalized likelihood ratio tests that require only evaluations of simple prediction score functions. This procedure makes use of checkpoints, consisting of early versions of the actual model parameters, that allow to detect distributional changes by performing predictions on future data. We define an algorithm that bounds the Type I error in the sequential testing procedure. We demonstrate the efficiency of our method in challenging continual learning applications with unknown task changepoints, and show improved performance compared to online Bayesian changepoint detection.
RussianSuperGLUE: A Russian Language Understanding Evaluation Benchmark
Nov 02, 2020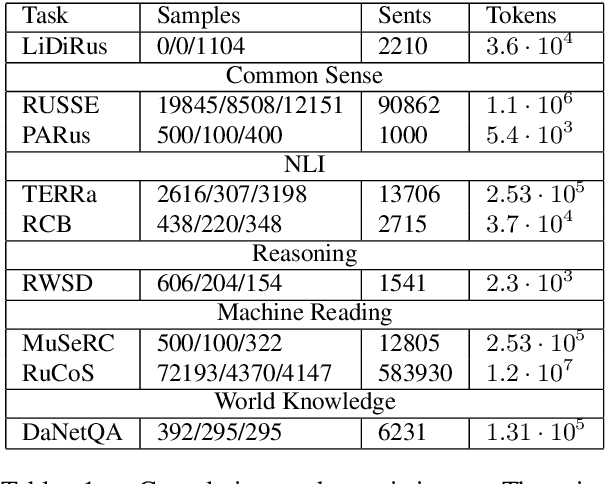

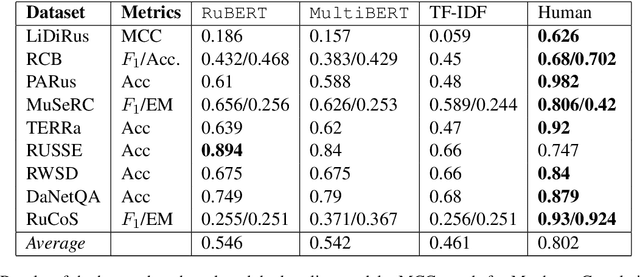

In this paper, we introduce an advanced Russian general language understanding evaluation benchmark -- RussianGLUE. Recent advances in the field of universal language models and transformers require the development of a methodology for their broad diagnostics and testing for general intellectual skills - detection of natural language inference, commonsense reasoning, ability to perform simple logical operations regardless of text subject or lexicon. For the first time, a benchmark of nine tasks, collected and organized analogically to the SuperGLUE methodology, was developed from scratch for the Russian language. We provide baselines, human level evaluation, an open-source framework for evaluating models (https://github.com/RussianNLP/RussianSuperGLUE), and an overall leaderboard of transformer models for the Russian language. Besides, we present the first results of comparing multilingual models in the adapted diagnostic test set and offer the first steps to further expanding or assessing state-of-the-art models independently of language.
Instance exploitation for learning temporary concepts from sparsely labeled drifting data streams
Sep 20, 2020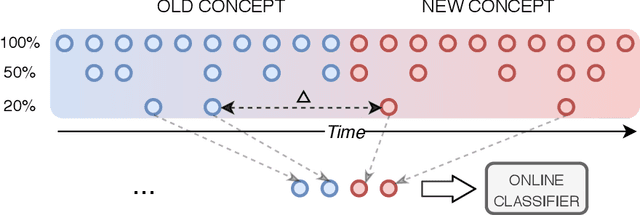
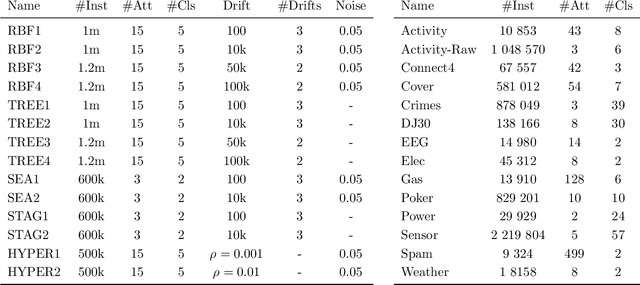
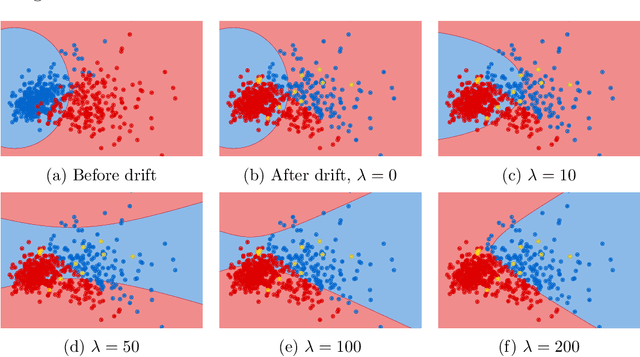

Continual learning from streaming data sources becomes more and more popular due to the increasing number of online tools and systems. Dealing with dynamic and everlasting problems poses new challenges for which traditional batch-based offline algorithms turn out to be insufficient in terms of computational time and predictive performance. One of the most crucial limitations is that we cannot assume having access to a finite and complete data set - we always have to be ready for new data that may complement our model. This poses a critical problem of providing labels for potentially unbounded streams. In the real world, we are forced to deal with very strict budget limitations, therefore, we will most likely face the scarcity of annotated instances, which are essential in supervised learning. In our work, we emphasize this problem and propose a novel instance exploitation technique. We show that when: (i) data is characterized by temporary non-stationary concepts, and (ii) there are very few labels spanned across a long time horizon, it is actually better to risk overfitting and adapt models more aggressively by exploiting the only labeled instances we have, instead of sticking to a standard learning mode and suffering from severe underfitting. We present different strategies and configurations for our methods, as well as an ensemble algorithm that attempts to maintain a sweet spot between risky and normal adaptation. Finally, we conduct a complex in-depth comparative analysis of our methods, using state-of-the-art streaming algorithms relevant to the given problem.
Imaging Time-Series to Improve Classification and Imputation
Jun 01, 2015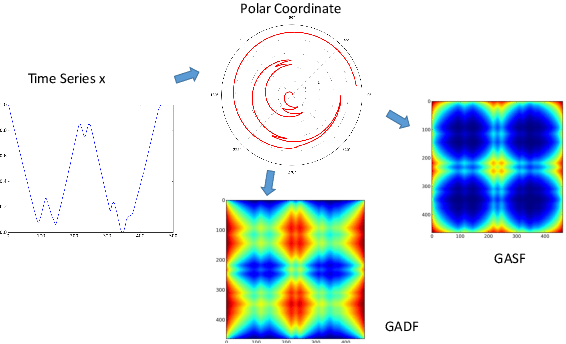
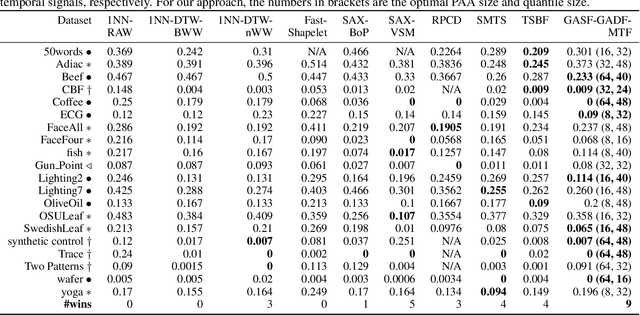
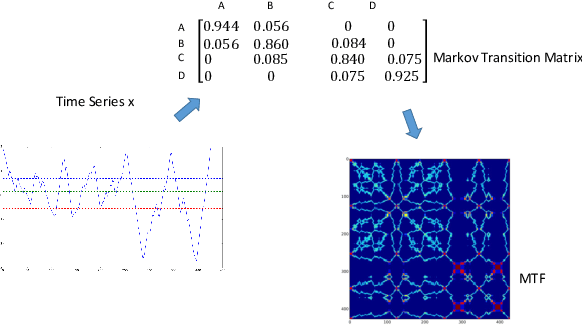
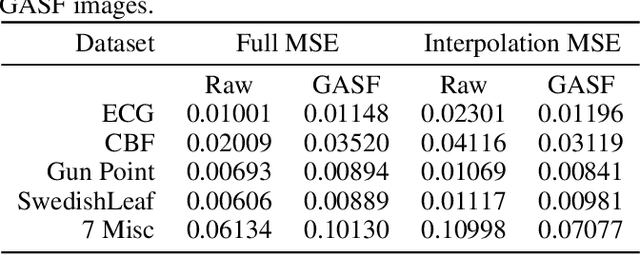
Inspired by recent successes of deep learning in computer vision, we propose a novel framework for encoding time series as different types of images, namely, Gramian Angular Summation/Difference Fields (GASF/GADF) and Markov Transition Fields (MTF). This enables the use of techniques from computer vision for time series classification and imputation. We used Tiled Convolutional Neural Networks (tiled CNNs) on 20 standard datasets to learn high-level features from the individual and compound GASF-GADF-MTF images. Our approaches achieve highly competitive results when compared to nine of the current best time series classification approaches. Inspired by the bijection property of GASF on 0/1 rescaled data, we train Denoised Auto-encoders (DA) on the GASF images of four standard and one synthesized compound dataset. The imputation MSE on test data is reduced by 12.18%-48.02% when compared to using the raw data. An analysis of the features and weights learned via tiled CNNs and DAs explains why the approaches work.
Comparison of Guidance Modes for the AUV "Slocum Glider" in Time-Varying Ocean Flows
Feb 26, 2017
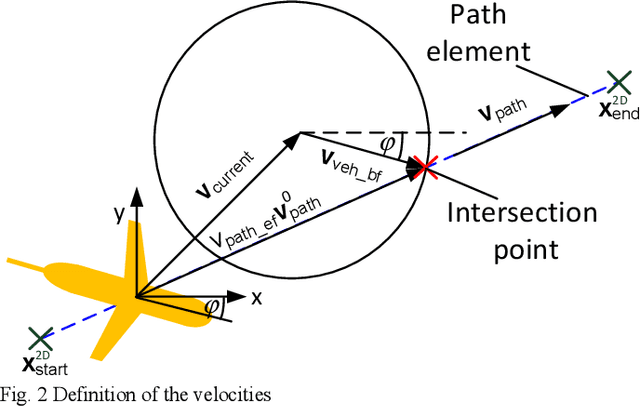
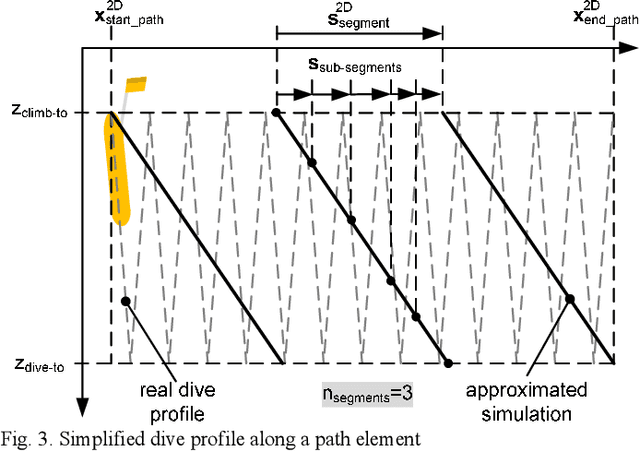
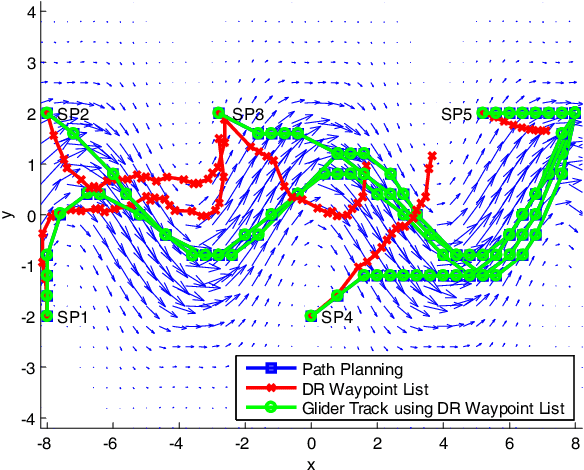
This paper presents possibilities for the reliable guidance of an AUV "Slocum Glider" in time-varying ocean flows. The presented guidance modes consider the restricted information during a real mission about the actual position and ocean current conditions as well as the available control modes of a glider. A faster-than-real-time, full software stack simulator for the Slocum glider will be described in order to test the developed guidance modes under real mission conditions.