 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The impact of online machine-learning methods on long-term investment decisions and generator utilization in electricity markets
Mar 07, 2021
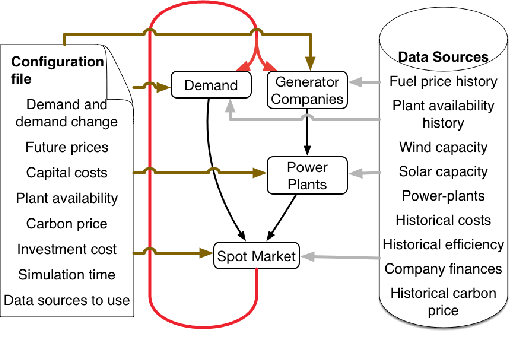
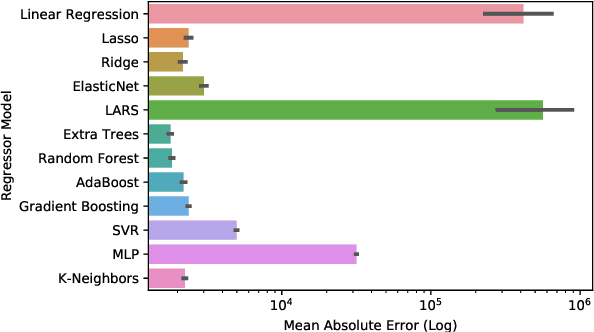
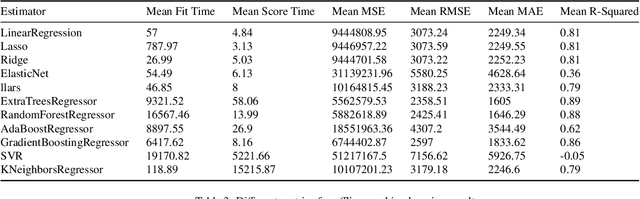
Electricity supply must be matched with demand at all times. This helps reduce the chances of issues such as load frequency control and the chances of electricity blackouts. To gain a better understanding of the load that is likely to be required over the next 24h, estimations under uncertainty are needed. This is especially difficult in a decentralized electricity market with many micro-producers which are not under central control. In this paper, we investigate the impact of eleven offline learning and five online learning algorithms to predict the electricity demand profile over the next 24h. We achieve this through integration within the long-term agent-based model, ElecSim. Through the prediction of electricity demand profile over the next 24h, we can simulate the predictions made for a day-ahead market. Once we have made these predictions, we sample from the residual distributions and perturb the electricity market demand using the simulation, ElecSim. This enables us to understand the impact of errors on the long-term dynamics of a decentralized electricity market. We show we can reduce the mean absolute error by 30% using an online algorithm when compared to the best offline algorithm, whilst reducing the required tendered national grid reserve required. This reduction in national grid reserves leads to savings in costs and emissions. We also show that large errors in prediction accuracy have a disproportionate error on investments made over a 17-year time frame, as well as electricity mix.
About Graph Degeneracy, Representation Learning and Scalability
Sep 04, 2020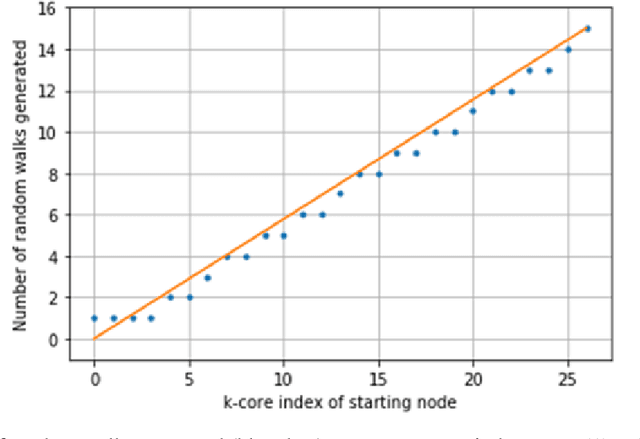

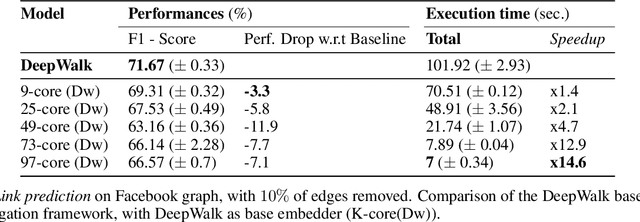
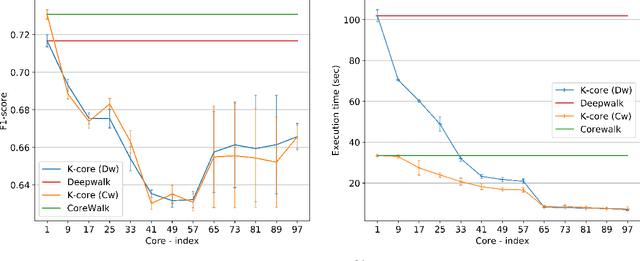
Graphs or networks are a very convenient way to represent data with lots of interaction. Recently, Machine Learning on Graph data has gained a lot of traction. In particular, vertex classification and missing edge detection have very interesting applications, ranging from drug discovery to recommender systems. To achieve such tasks, tremendous work has been accomplished to learn embedding of nodes and edges into finite-dimension vector spaces. This task is called Graph Representation Learning. However, Graph Representation Learning techniques often display prohibitive time and memory complexities, preventing their use in real-time with business size graphs. In this paper, we address this issue by leveraging a degeneracy property of Graphs - the K-Core Decomposition. We present two techniques taking advantage of this decomposition to reduce the time and memory consumption of walk-based Graph Representation Learning algorithms. We evaluate the performances, expressed in terms of quality of embedding and computational resources, of the proposed techniques on several academic datasets. Our code is available at https://github.com/SBrandeis/kcore-embedding
Non-Linear Phase-Shifting of Haar Wavelets for Run-Time All-Frequency Lighting
May 20, 2017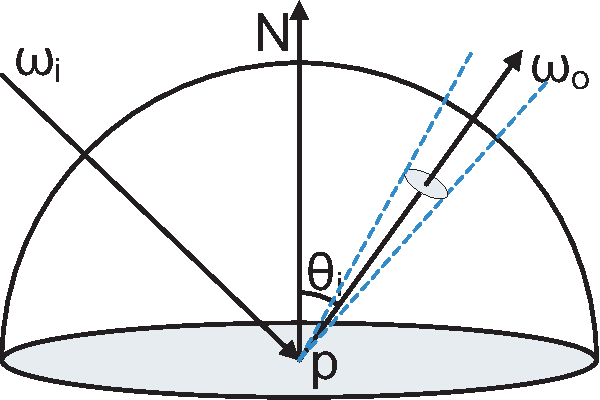

This paper focuses on real-time all-frequency image-based rendering using an innovative solution for run-time computation of light transport. The approach is based on new results derived for non-linear phase shifting in the Haar wavelet domain. Although image-based methods for real-time rendering of dynamic glossy objects have been proposed, they do not truly scale to all possible frequencies and high sampling rates without trading storage, glossiness, or computational time, while varying both lighting and viewpoint. This is due to the fact that current approaches are limited to precomputed radiance transfer (PRT), which is prohibitively expensive in terms of memory requirements and real-time rendering when both varying light and viewpoint changes are required together with high sampling rates for high frequency lighting of glossy material. On the other hand, current methods cannot handle object rotation, which is one of the paramount issues for all PRT methods using wavelets. This latter problem arises because the precomputed data are defined in a global coordinate system and encoded in the wavelet domain, while the object is rotated in a local coordinate system. At the root of all the above problems is the lack of efficient run-time solution to the nontrivial problem of rotating wavelets (a non-linear phase-shift), which we solve in this paper.
How Many Annotators Do We Need? -- A Study on the Influence of Inter-Observer Variability on the Reliability of Automatic Mitotic Figure Assessment
Jan 08, 2021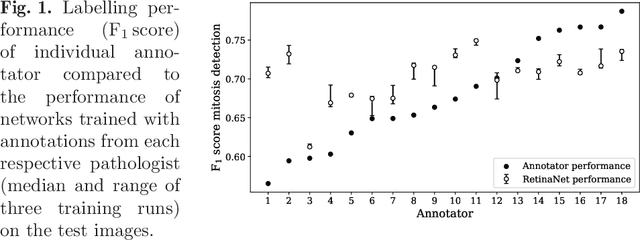
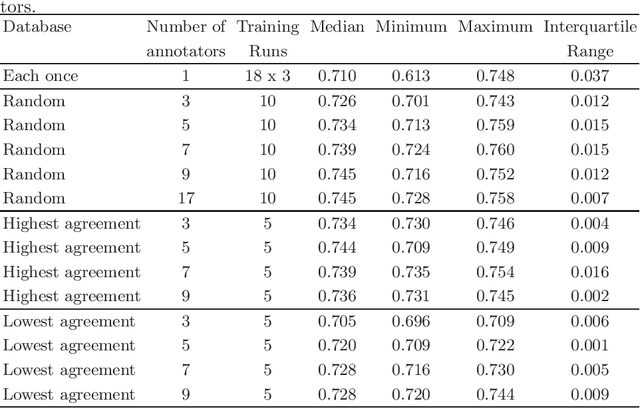
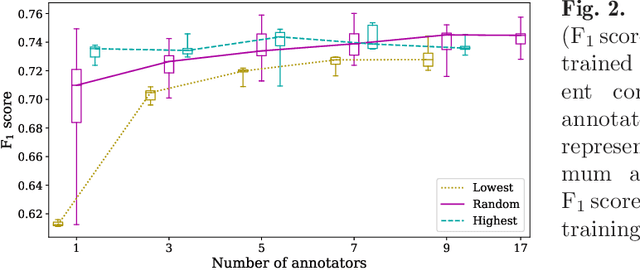
Density of mitotic figures in histologic sections is a prognostically relevant characteristic for many tumours. Due to high inter-pathologist variability, deep learning-based algorithms are a promising solution to improve tumour prognostication. Pathologists are the gold standard for database development, however, labelling errors may hamper development of accurate algorithms. In the present work we evaluated the benefit of multi-expert consensus (n = 3, 5, 7, 9, 11) on algorithmic performance. While training with individual databases resulted in highly variable F$_1$ scores, performance was notably increased and more consistent when using the consensus of three annotators. Adding more annotators only resulted in minor improvements. We conclude that databases by few pathologists and high label accuracy may be the best compromise between high algorithmic performance and time investment.
Multi-task Learning Approach for Automatic Modulation and Wireless Signal Classification
Feb 20, 2021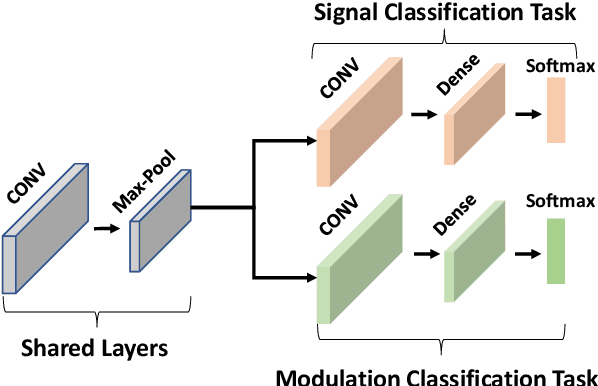
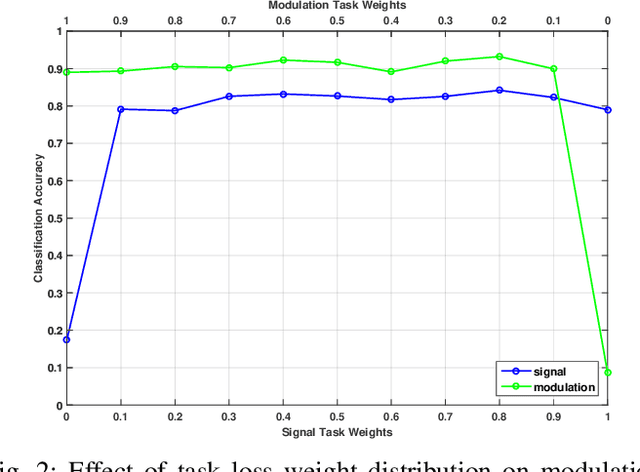
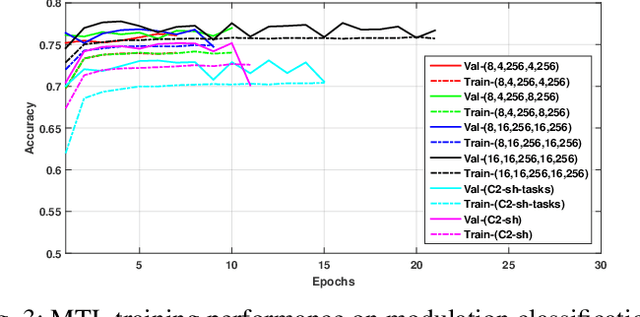
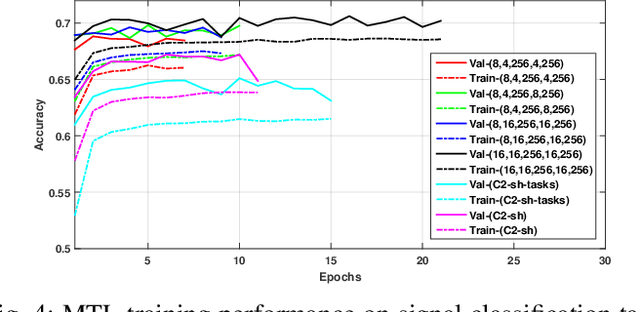
Wireless signal recognition is becoming increasingly more significant for spectrum monitoring, spectrum management, and secure communications. Consequently, it will become a key enabler with the emerging fifth-generation (5G) and beyond 5G communications, Internet of Things networks, among others. State-of-the-art studies in wireless signal recognition have only focused on a single task which in many cases is insufficient information for a system to act on. In this work, for the first time in the wireless communication domain, we exploit the potential of deep neural networks in conjunction with multi-task learning (MTL) framework to simultaneously learn modulation and signal classification tasks. The proposed MTL architecture benefits from the mutual relation between the two tasks in improving the classification accuracy as well as the learning efficiency with a lightweight neural network model. Additionally, we consider the problem of heterogeneous wireless signals such as radar and communication signals in the electromagnetic spectrum. Accordingly, we have shown how the proposed MTL model outperforms several state-of-the-art single-task learning classifiers while maintaining a lighter architecture and performing two signal characterization tasks simultaneously. Finally, we also release the only known open heterogeneous wireless signals dataset that comprises of radar and communication signals with multiple labels.
* To appear in Proc. of IEEE International Conference on Communications (ICC) 2021. Open data set also included in the reference
Memformer: The Memory-Augmented Transformer
Oct 14, 2020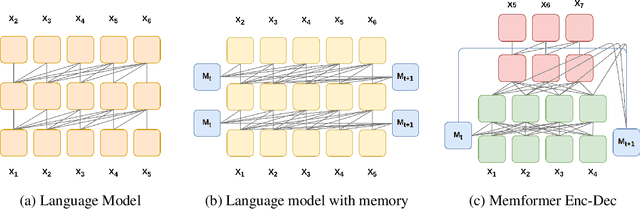
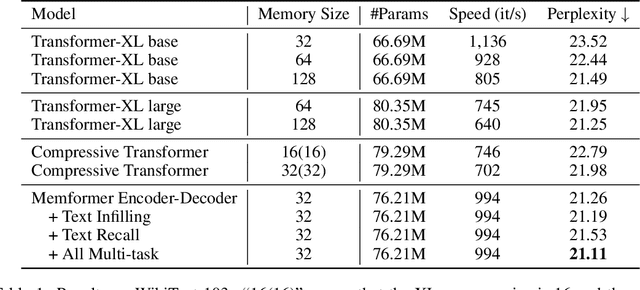
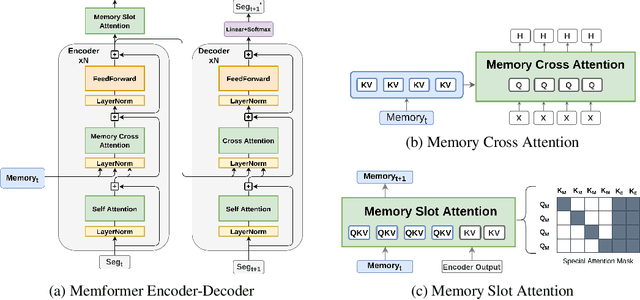

Transformer models have obtained remarkable accomplishments in various NLP tasks. However, these models have efficiency issues on long sequences, as the complexity of their self-attention module scales quadratically with the sequence length. To remedy the limitation, we present Memformer, a novel language model that utilizes a single unified memory to encode and retrieve past information. It includes a new optimization scheme, Memory Replay Back-Propagation, which promotes long-range back-propagation through time with a significantly reduced memory requirement. Memformer achieves $\mathcal{O}(n)$ time complexity and $\mathcal{O}(1)$ space complexity in processing long sequences, meaning that the model can handle an infinite length sequence during inference. Our model is also compatible with other self-supervised tasks to further improve the performance on language modeling. Experimental results show that Memformer outperforms the previous long-range sequence models on WikiText-103, including Transformer-XL and compressive Transformer.
Constrained optimization under uncertainty for decision-making problems: Application to Real-Time Strategy games
Jan 07, 2019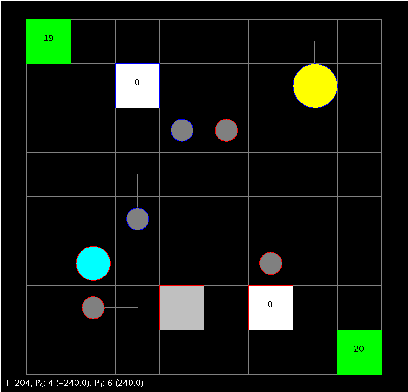
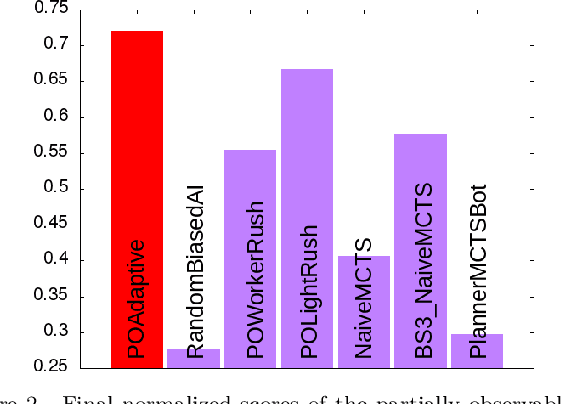
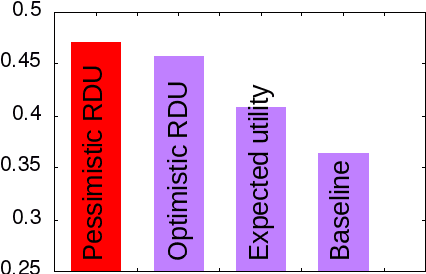
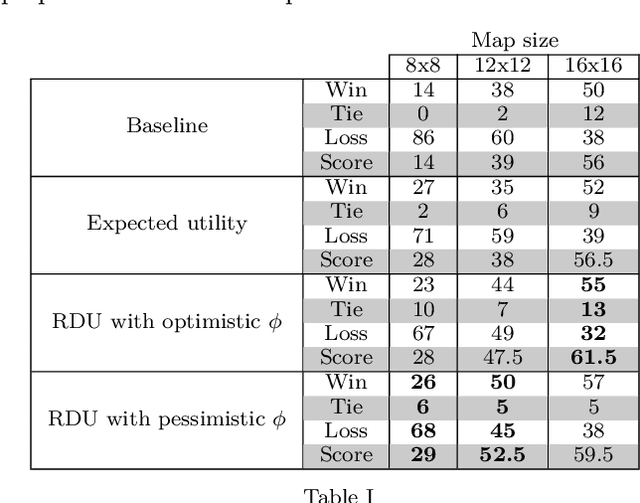
Decision-making problems can be modeled as combinatorial optimization problems with Constraint Programming formalisms such as Constrained Optimization Problems. However, few Constraint Programming formalisms can deal with both optimization and uncertainty at the same time, and none of them are convenient to model problems we tackle in this paper. Here, we propose a way to deal with combinatorial optimization problems under uncertainty within the classical Constrained Optimization Problems formalism by injecting the Rank Dependent Utility from decision theory. We also propose a proof of concept of our method to show it is implementable and can solve concrete decision-making problems using a regular constraint solver, and propose a bot that won the partially observable track of the 2018 {\mu}RTS AI competition. Our result shows it is possible to handle uncertainty with regular Constraint Programming solvers, without having to define a new formalism neither to develop dedicated solvers. This brings new perspective to tackle uncertainty in Constraint Programming.
Reviving Iterative Training with Mask Guidance for Interactive Segmentation
Feb 12, 2021
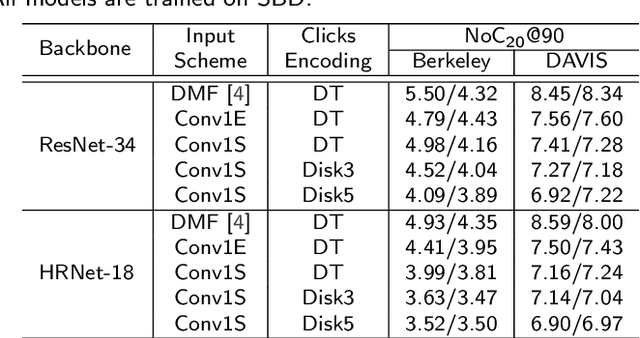

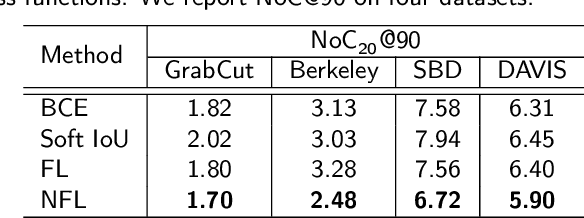
Recent works on click-based interactive segmentation have demonstrated state-of-the-art results by using various inference-time optimization schemes. These methods are considerably more computationally expensive compared to feedforward approaches, as they require performing backward passes through a network during inference and are hard to deploy on mobile frameworks that usually support only forward passes. In this paper, we extensively evaluate various design choices for interactive segmentation and discover that new state-of-the-art results can be obtained without any additional optimization schemes. Thus, we propose a simple feedforward model for click-based interactive segmentation that employs the segmentation masks from previous steps. It allows not only to segment an entirely new object, but also to start with an external mask and correct it. When analyzing the performance of models trained on different datasets, we observe that the choice of a training dataset greatly impacts the quality of interactive segmentation. We find that the models trained on a combination of COCO and LVIS with diverse and high-quality annotations show performance superior to all existing models. The code and trained models are available at https://github.com/saic-vul/ritm_interactive_segmentation.
Unsupervised Features for Facial Expression Intensity Estimation over Time
May 03, 2018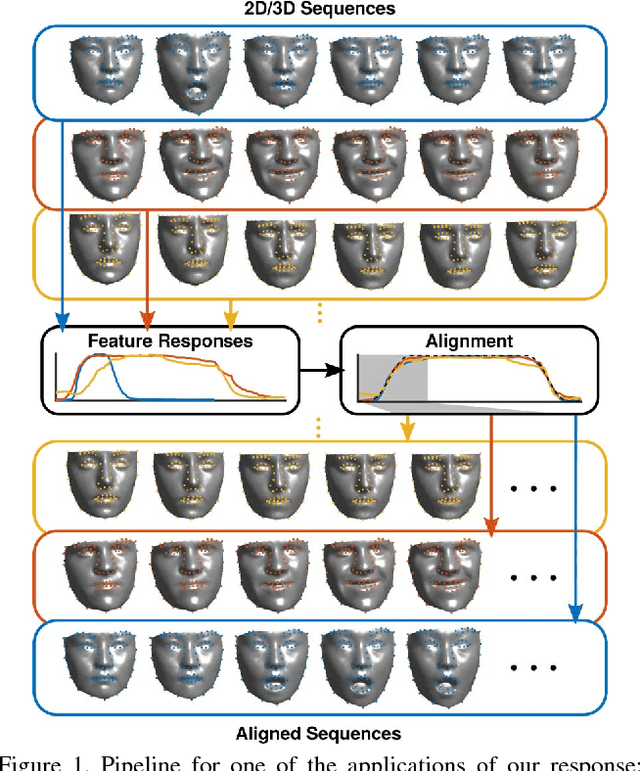
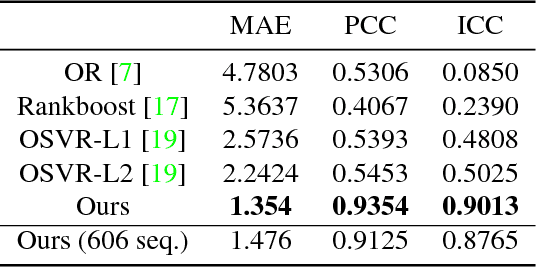
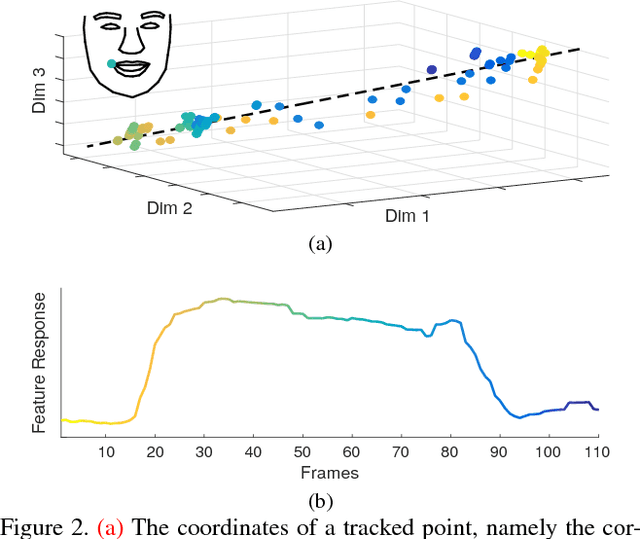
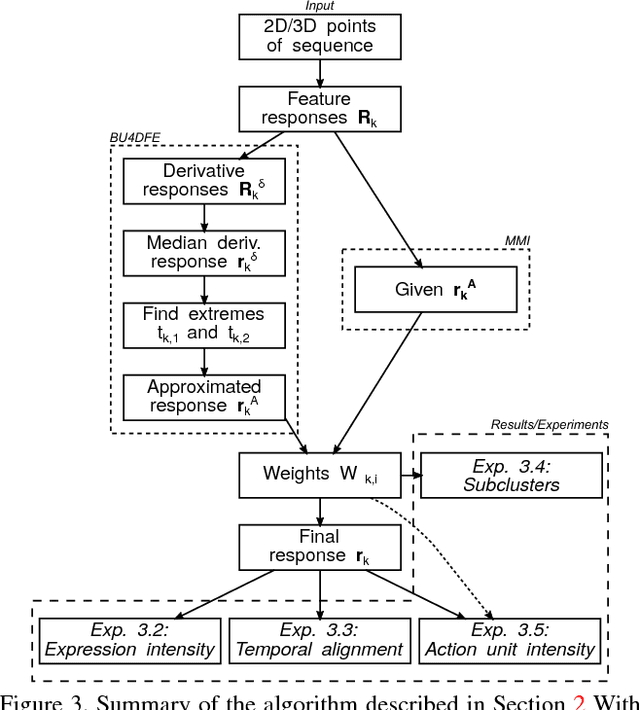
The diversity of facial shapes and motions among persons is one of the greatest challenges for automatic analysis of facial expressions. In this paper, we propose a feature describing expression intensity over time, while being invariant to person and the type of performed expression. Our feature is a weighted combination of the dynamics of multiple points adapted to the overall expression trajectory. We evaluate our method on several tasks all related to temporal analysis of facial expression. The proposed feature is compared to a state-of-the-art method for expression intensity estimation, which it outperforms. We use our proposed feature to temporally align multiple sequences of recorded 3D facial expressions. Furthermore, we show how our feature can be used to reveal person-specific differences in performances of facial expressions. Additionally, we apply our feature to identify the local changes in face video sequences based on action unit labels. For all the experiments our feature proves to be robust against noise and outliers, making it applicable to a variety of applications for analysis of facial movements.
Tracking Time-Vertex Propagation using Dynamic Graph Wavelets
Jun 21, 2016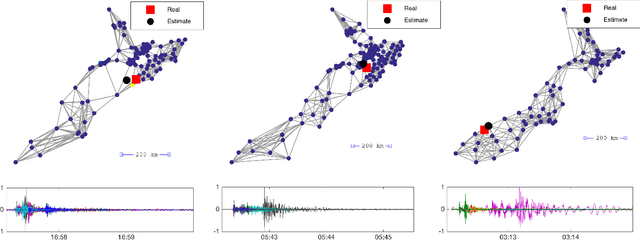
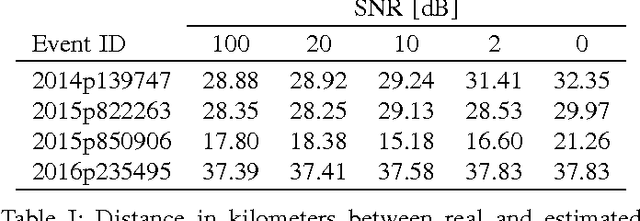
Graph Signal Processing generalizes classical signal processing to signal or data indexed by the vertices of a weighted graph. So far, the research efforts have been focused on static graph signals. However numerous applications involve graph signals evolving in time, such as spreading or propagation of waves on a network. The analysis of this type of data requires a new set of methods that fully takes into account the time and graph dimensions. We propose a novel class of wavelet frames named Dynamic Graph Wavelets, whose time-vertex evolution follows a dynamic process. We demonstrate that this set of functions can be combined with sparsity based approaches such as compressive sensing to reveal information on the dynamic processes occurring on a graph. Experiments on real seismological data show the efficiency of the technique, allowing to estimate the epicenter of earthquake events recorded by a seismic network.