 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Intelligence
May 03, 2021
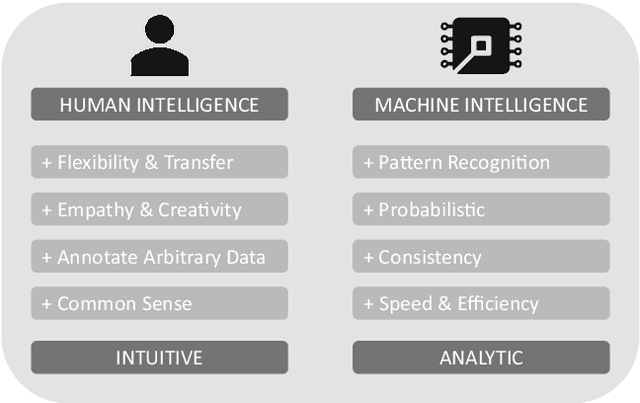
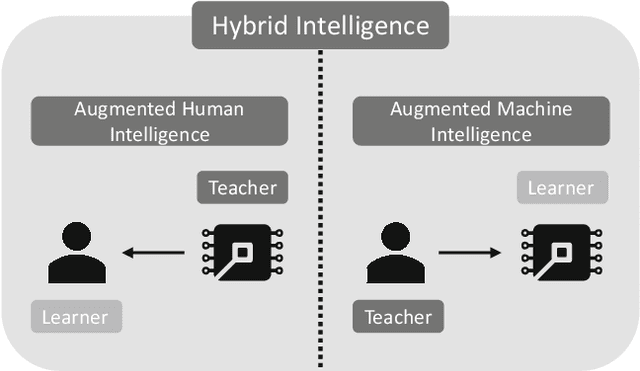
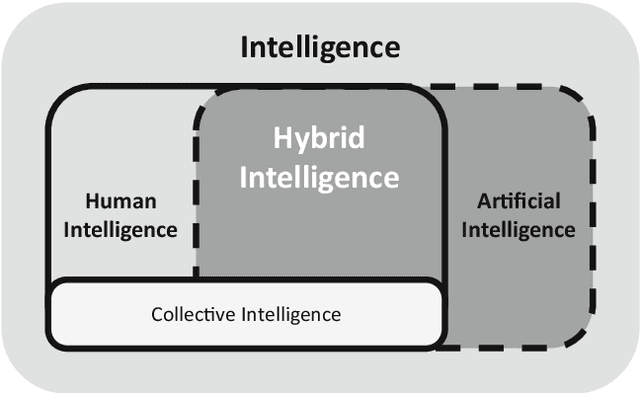
Research has a long history of discussing what is superior in predicting certain outcomes: statistical methods or the human brain. This debate has repeatedly been sparked off by the remarkable technological advances in the field of artificial intelligence (AI), such as solving tasks like object and speech recognition, achieving significant improvements in accuracy through deep-learning algorithms (Goodfellow et al. 2016), or combining various methods of computational intelligence, such as fuzzy logic, genetic algorithms, and case-based reasoning (Medsker 2012). One of the implicit promises that underlie these advancements is that machines will 1 day be capable of performing complex tasks or may even supersede humans in performing these tasks. This triggers new heated debates of when machines will ultimately replace humans (McAfee and Brynjolfsson 2017). While previous research has proved that AI performs well in some clearly defined tasks such as playing chess, playing Go or identifying objects on images, it is doubted that the development of an artificial general intelligence (AGI) which is able to solve multiple tasks at the same time can be achieved in the near future (e.g., Russell and Norvig 2016). Moreover, the use of AI to solve complex business problems in organizational contexts occurs scarcely, and applications for AI that solve complex problems remain mainly in laboratory settings instead of being implemented in practice. Since the road to AGI is still a long one, we argue that the most likely paradigm for the division of labor between humans and machines in the next decades is Hybrid Intelligence. This concept aims at using the complementary strengths of human intelligence and AI, so that they can perform better than each of the two could separately (e.g., Kamar 2016).
Cluster-based Input Weight Initialization for Echo State Networks
Mar 08, 2021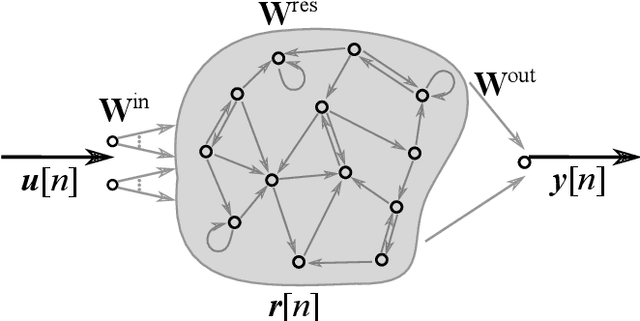
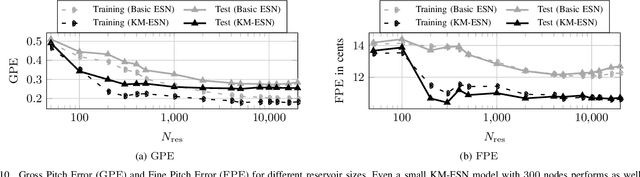
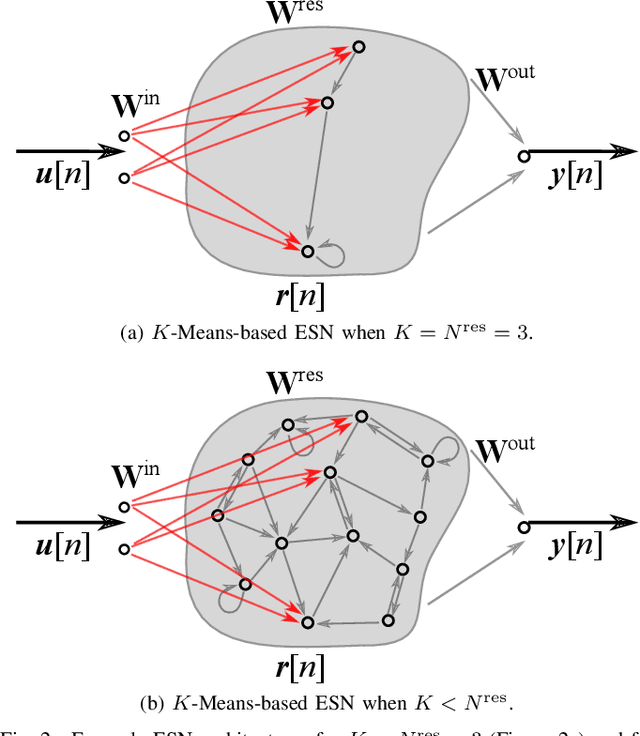
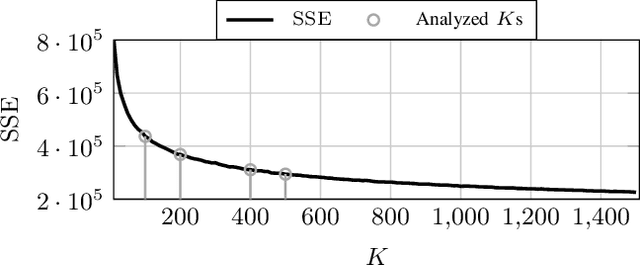
Echo State Networks (ESNs) are a special type of recurrent neural networks (RNNs), in which the input and recurrent connections are traditionally generated randomly, and only the output weights are trained. Despite the recent success of ESNs in various tasks of audio, image and radar recognition, we postulate that a purely random initialization is not the ideal way of initializing ESNs. The aim of this work is to propose an unsupervised initialization of the input connections using the K-Means algorithm on the training data. We show that this initialization performs equivalently or superior than a randomly initialized ESN whilst needing significantly less reservoir neurons (2000 vs. 4000 for spoken digit recognition, and 300 vs. 8000 neurons for f0 extraction) and thus reducing the amount of training time. Furthermore, we discuss that this approach provides the opportunity to estimate the suitable size of the reservoir based on the prior knowledge about the data.
SuperDeConFuse: A Supervised Deep Convolutional Transform based Fusion Framework for Financial Trading Systems
Nov 09, 2020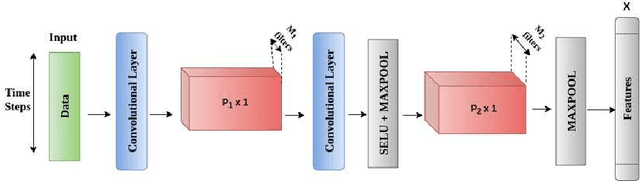
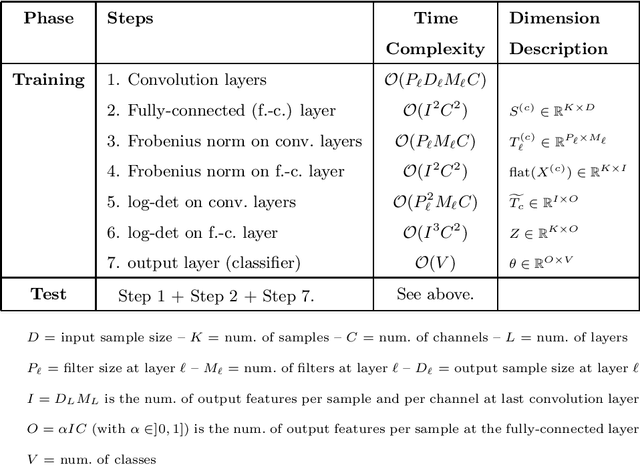
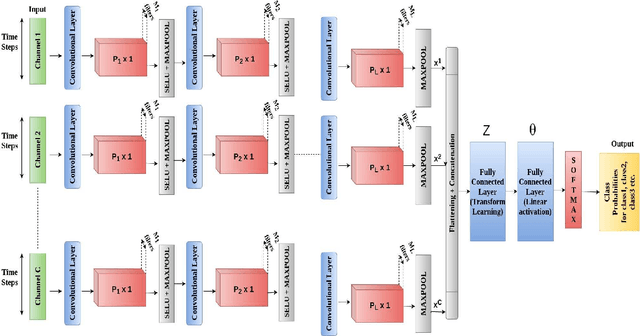
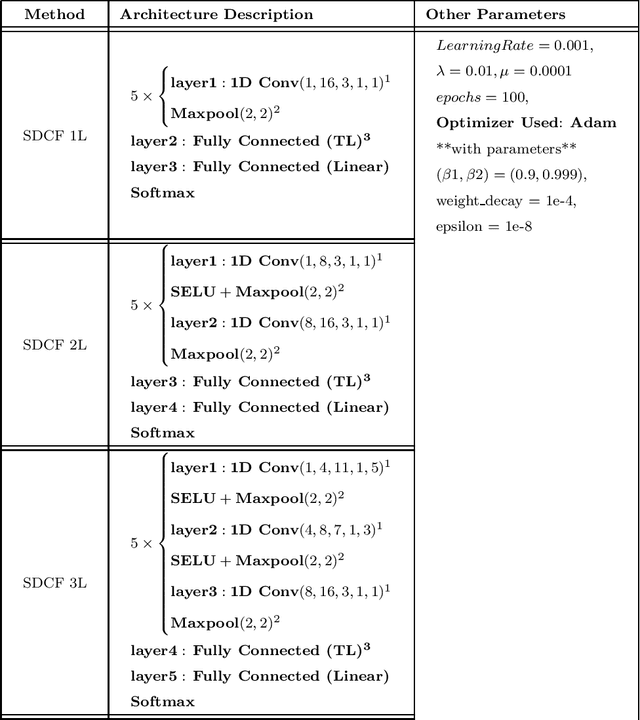
This work proposes a supervised multi-channel time-series learning framework for financial stock trading. Although many deep learning models have recently been proposed in this domain, most of them treat the stock trading time-series data as 2-D image data, whereas its true nature is 1-D time-series data. Since the stock trading systems are multi-channel data, many existing techniques treating them as 1-D time-series data are not suggestive of any technique to effectively fusion the information carried by the multiple channels. To contribute towards both of these shortcomings, we propose an end-to-end supervised learning framework inspired by the previously established (unsupervised) convolution transform learning framework. Our approach consists of processing the data channels through separate 1-D convolution layers, then fusing the outputs with a series of fully-connected layers, and finally applying a softmax classification layer. The peculiarity of our framework - SuperDeConFuse (SDCF), is that we remove the nonlinear activation located between the multi-channel convolution layers and the fully-connected layers, as well as the one located between the latter and the output layer. We compensate for this removal by introducing a suitable regularization on the aforementioned layer outputs and filters during the training phase. Specifically, we apply a logarithm determinant regularization on the layer filters to break symmetry and force diversity in the learnt transforms, whereas we enforce the non-negativity constraint on the layer outputs to mitigate the issue of dead neurons. This results in the effective learning of a richer set of features and filters with respect to a standard convolutional neural network. Numerical experiments confirm that the proposed model yields considerably better results than state-of-the-art deep learning techniques for real-world problem of stock trading.
Smartphone Impostor Detection with Behavioral Data Privacy and Minimalist Hardware Support
Mar 17, 2021
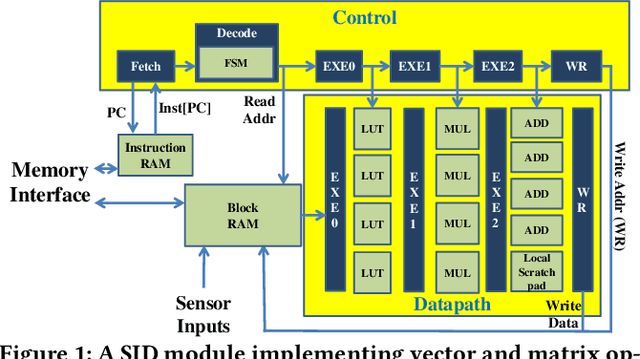
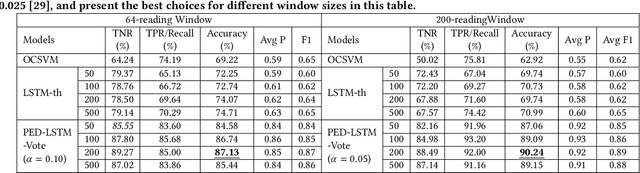
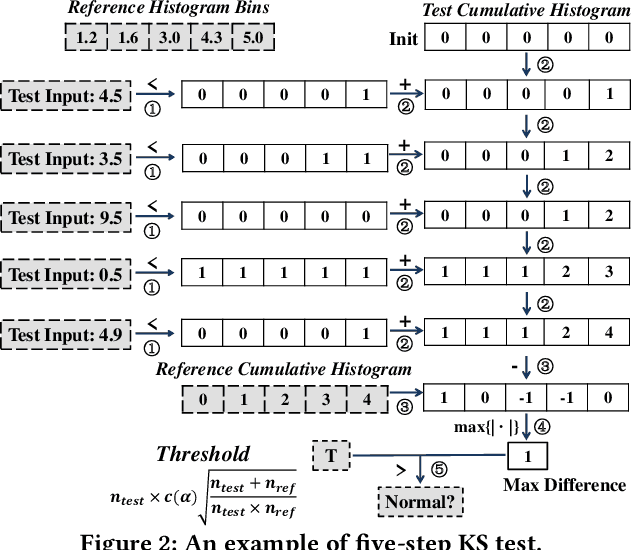
Impostors are attackers who take over a smartphone and gain access to the legitimate user's confidential and private information. This paper proposes a defense-in-depth mechanism to detect impostors quickly with simple Deep Learning algorithms, which can achieve better detection accuracy than the best prior work which used Machine Learning algorithms requiring computation of multiple features. Different from previous work, we then consider protecting the privacy of a user's behavioral (sensor) data by not exposing it outside the smartphone. For this scenario, we propose a Recurrent Neural Network (RNN) based Deep Learning algorithm that uses only the legitimate user's sensor data to learn his/her normal behavior. We propose to use Prediction Error Distribution (PED) to enhance the detection accuracy. We also show how a minimalist hardware module, dubbed SID for Smartphone Impostor Detector, can be designed and integrated into smartphones for self-contained impostor detection. Experimental results show that SID can support real-time impostor detection, at a very low hardware cost and energy consumption, compared to other RNN accelerators.
Rethinking Automatic Evaluation in Sentence Simplification
Apr 16, 2021
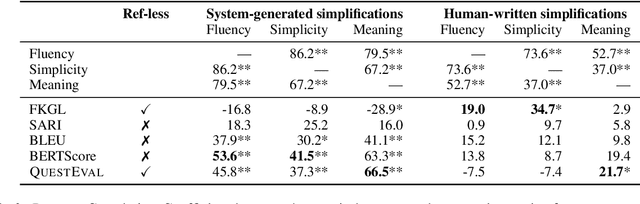
Automatic evaluation remains an open research question in Natural Language Generation. In the context of Sentence Simplification, this is particularly challenging: the task requires by nature to replace complex words with simpler ones that shares the same meaning. This limits the effectiveness of n-gram based metrics like BLEU. Going hand in hand with the recent advances in NLG, new metrics have been proposed, such as BERTScore for Machine Translation. In summarization, the QuestEval metric proposes to automatically compare two texts by questioning them. In this paper, we first propose a simple modification of QuestEval allowing it to tackle Sentence Simplification. We then extensively evaluate the correlations w.r.t. human judgement for several metrics including the recent BERTScore and QuestEval, and show that the latter obtain state-of-the-art correlations, outperforming standard metrics like BLEU and SARI. More importantly, we also show that a large part of the correlations are actually spurious for all the metrics. To investigate this phenomenon further, we release a new corpus of evaluated simplifications, this time not generated by systems but instead, written by humans. This allows us to remove the spurious correlations and draw very different conclusions from the original ones, resulting in a better understanding of these metrics. In particular, we raise concerns about very low correlations for most of traditional metrics. Our results show that the only significant measure of the Meaning Preservation is our adaptation of QuestEval.
Linear-time Detection of Non-linear Changes in Massively High Dimensional Time Series
Oct 28, 2015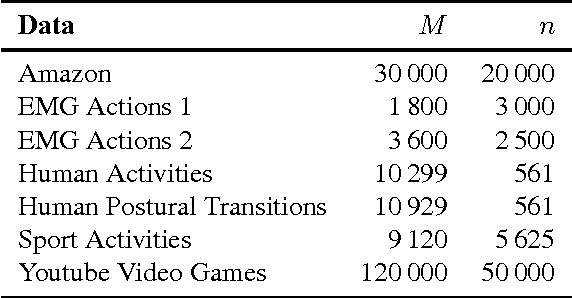
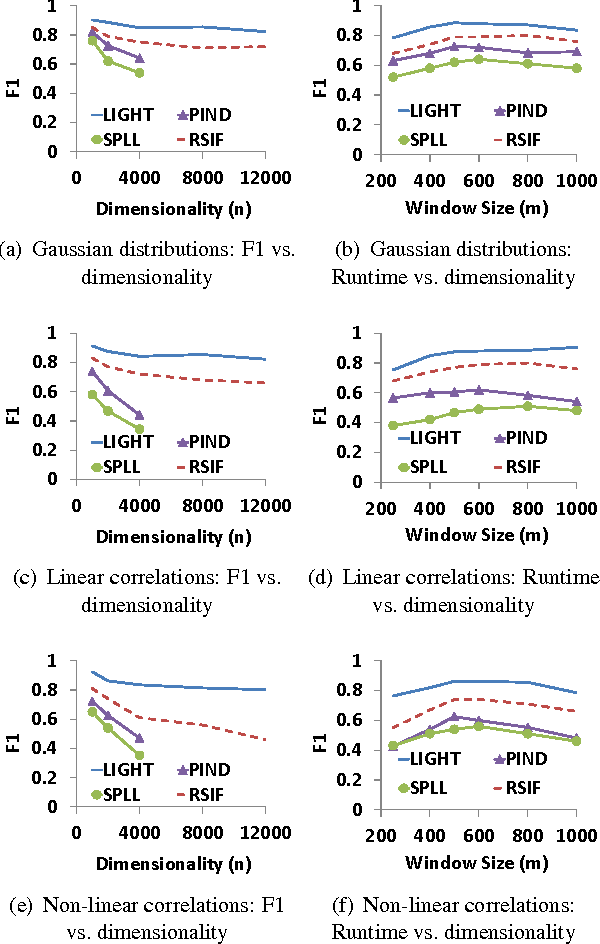
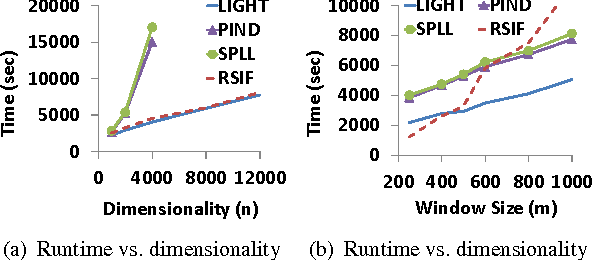
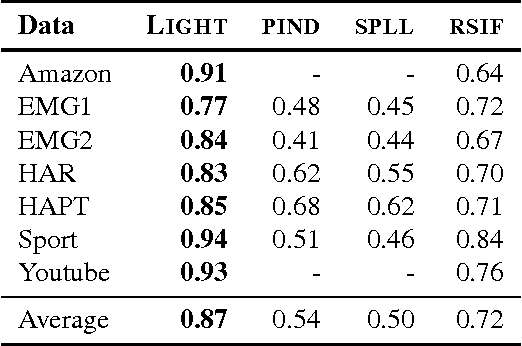
Change detection in multivariate time series has applications in many domains, including health care and network monitoring. A common approach to detect changes is to compare the divergence between the distributions of a reference window and a test window. When the number of dimensions is very large, however, the naive approach has both quality and efficiency issues: to ensure robustness the window size needs to be large, which not only leads to missed alarms but also increases runtime. To this end, we propose LIGHT, a linear-time algorithm for robustly detecting non-linear changes in massively high dimensional time series. Importantly, LIGHT provides high flexibility in choosing the window size, allowing the domain expert to fit the level of details required. To do such, we 1) perform scalable PCA to reduce dimensionality, 2) perform scalable factorization of the joint distribution, and 3) scalably compute divergences between these lower dimensional distributions. Extensive empirical evaluation on both synthetic and real-world data show that LIGHT outperforms state of the art with up to 100% improvement in both quality and efficiency.
Deeper and Wider Siamese Networks for Real-Time Visual Tracking
Jan 08, 2019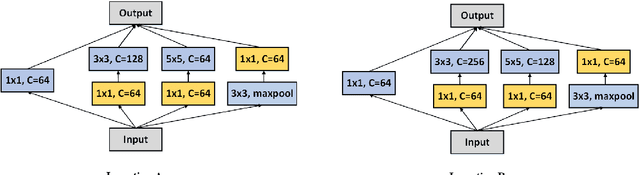

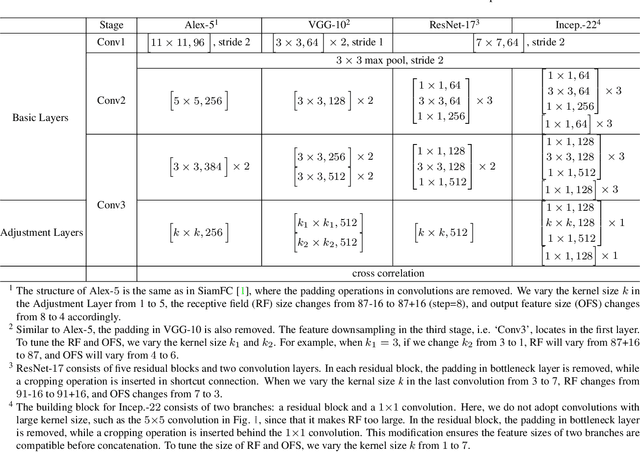
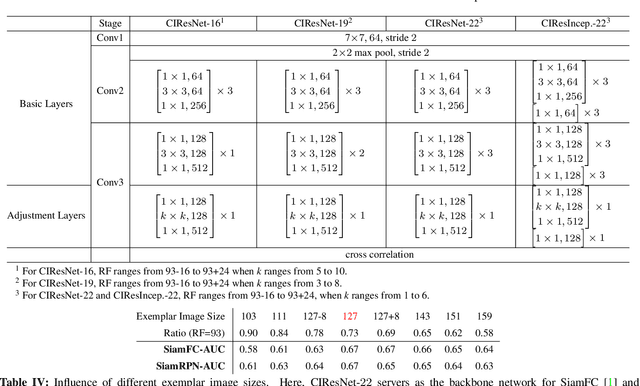
Siamese networks have drawn great attention in visual tracking because of their balanced accuracy and speed. However, the backbone networks used in Siamese trackers are relatively shallow, such as AlexNet [18], which does not fully take advantage of the capability of modern deep neural networks. In this paper, we investigate how to leverage deeper and wider convolutional neural networks to enhance tracking robustness and accuracy. We observe that direct replacement of backbones with existing powerful architectures, such as ResNet [14] and Inception [33], does not bring improvements. The main reasons are that 1)large increases in the receptive field of neurons lead to reduced feature discriminability and localization precision; and 2) the network padding for convolutions induces a positional bias in learning. To address these issues, we propose new residual modules to eliminate the negative impact of padding, and further design new architectures using these modules with controlled receptive field size and network stride. The designed architectures are lightweight and guarantee real-time tracking speed when applied to SiamFC [2] and SiamRPN [20]. Experiments show that solely due to the proposed network architectures, our SiamFC+ and SiamRPN+ obtain up to 9.8%/5.7% (AUC), 23.3%/8.8% (EAO) and 24.4%/25.0% (EAO) relative improvements over the original versions [2, 20] on the OTB-15, VOT-16 and VOT-17 datasets, respectively.
Thinking Deeply with Recurrence: Generalizing from Easy to Hard Sequential Reasoning Problems
Mar 17, 2021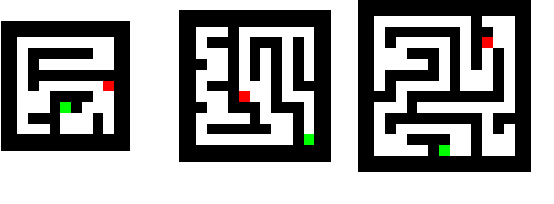
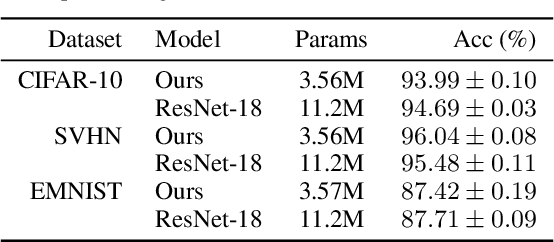
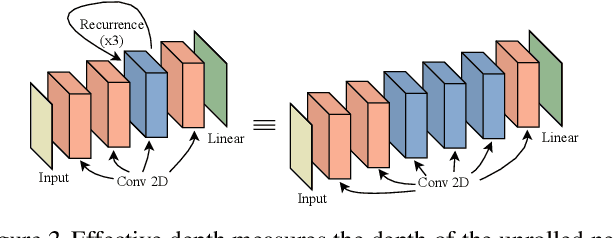

Deep neural networks are powerful machines for visual pattern recognition, but reasoning tasks that are easy for humans may still be difficult for neural models. Humans can extrapolate simple reasoning strategies to solve difficult problems using long sequences of abstract manipulations, i.e., harder problems are solved by thinking for longer. In contrast, the sequential computing budget of feed-forward networks is limited by their depth, and networks trained on simple problems have no way of extending their reasoning capabilities without retraining. In this work, we observe that recurrent networks have the uncanny ability to closely emulate the behavior of non-recurrent deep models, often doing so with far fewer parameters, on both image classification and maze solving tasks. We also explore whether recurrent networks can make the generalization leap from simple problems to hard problems simply by increasing the number of recurrent iterations used at test time. To this end, we show that recurrent networks that are trained to solve simple mazes with few recurrent steps can indeed solve much more complex problems simply by performing additional recurrences during inference.
Quarter Laplacian Filter for Edge Aware Image Processing
Jan 20, 2021
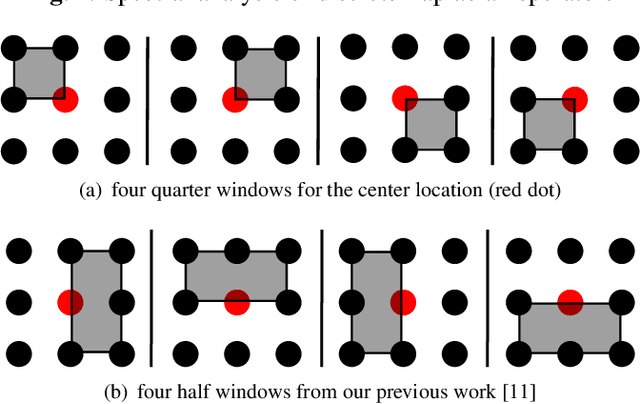

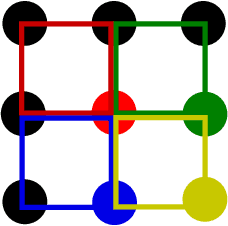
This paper presents a quarter Laplacian filter that can preserve corners and edges during image smoothing. Its support region is $2\times2$, which is smaller than the $3\times3$ support region of Laplacian filter. Thus, it is more local. Moreover, this filter can be implemented via the classical box filter, leading to high performance for real time applications. Finally, we show its edge preserving property in several image processing tasks, including image smoothing, texture enhancement, and low-light image enhancement. The proposed filter can be adopted in a wide range of image processing applications.
MONAH: Multi-Modal Narratives for Humans to analyze conversations
Jan 20, 2021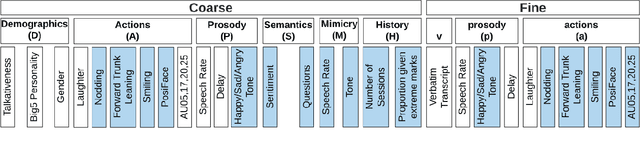
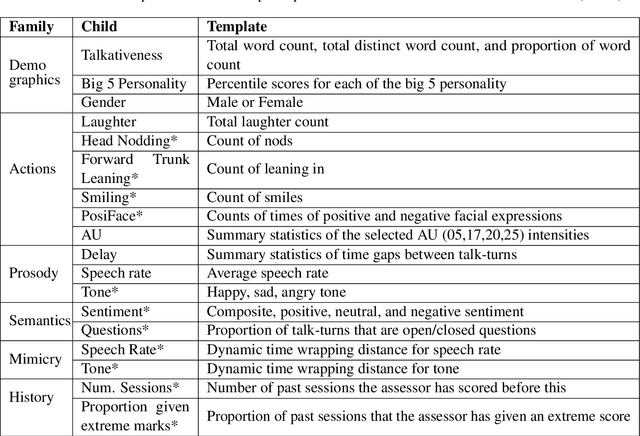
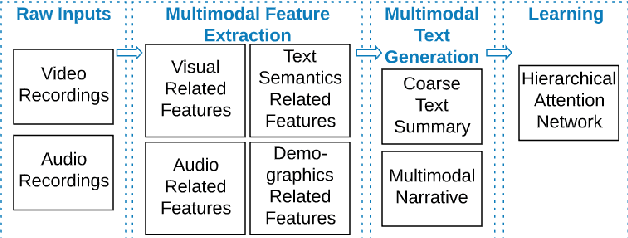
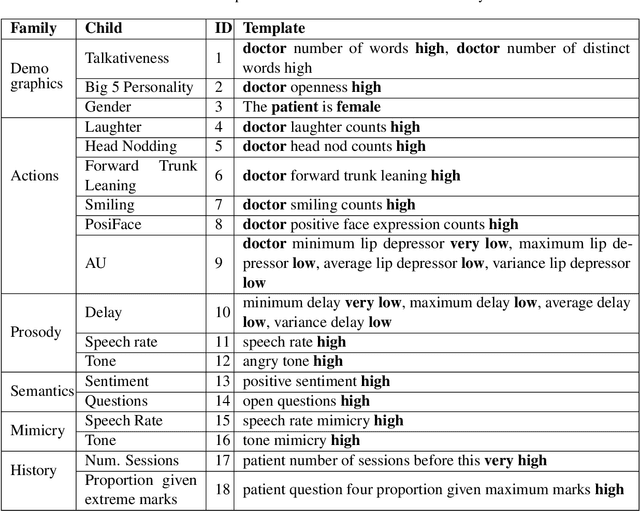
In conversational analyses, humans manually weave multimodal information into the transcripts, which is significantly time-consuming. We introduce a system that automatically expands the verbatim transcripts of video-recorded conversations using multimodal data streams. This system uses a set of preprocessing rules to weave multimodal annotations into the verbatim transcripts and promote interpretability. Our feature engineering contributions are two-fold: firstly, we identify the range of multimodal features relevant to detect rapport-building; secondly, we expand the range of multimodal annotations and show that the expansion leads to statistically significant improvements in detecting rapport-building.