 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudShield: Real-time Anomaly Detection in the Cloud
Aug 25, 2021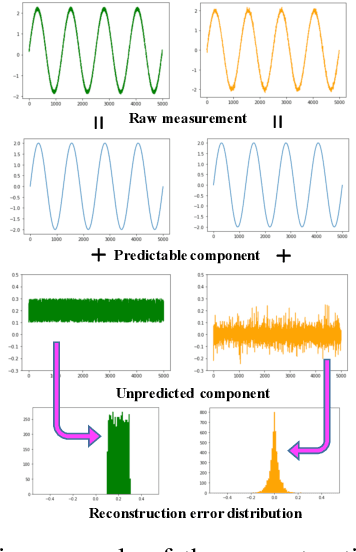
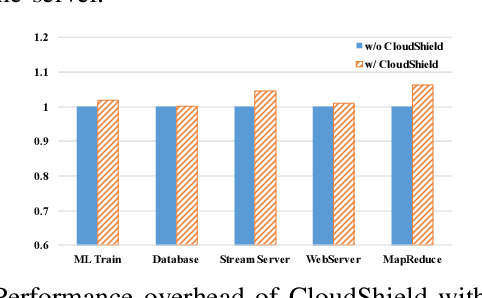
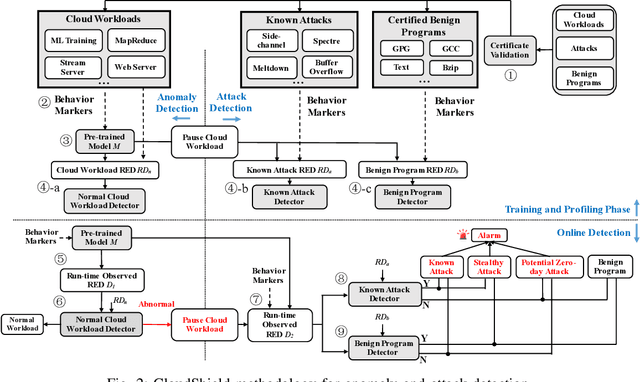
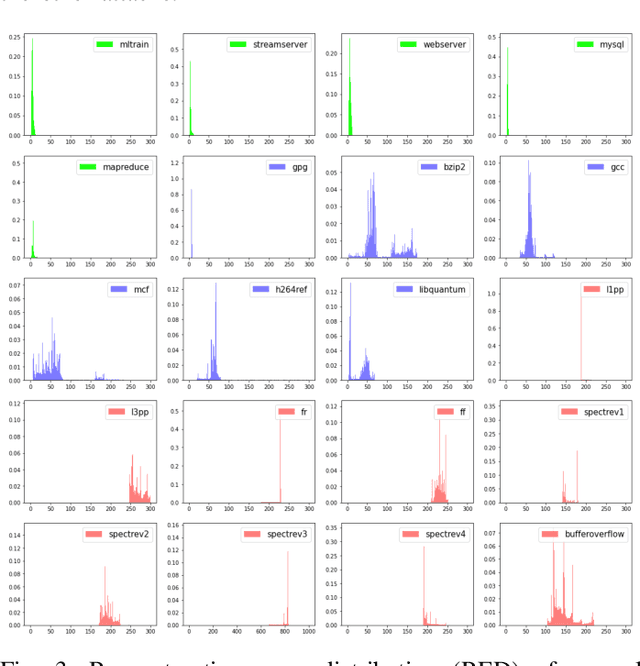
In cloud computing, it is desirable if suspicious activities can be detected by automatic anomaly detection systems. Although anomaly detection has been investigated in the past, it remains unsolved in cloud computing. Challenges are: characterizing the normal behavior of a cloud server, distinguishing between benign and malicious anomalies (attacks), and preventing alert fatigue due to false alarms. We propose CloudShield, a practical and generalizable real-time anomaly and attack detection system for cloud computing. Cloudshield uses a general, pretrained deep learning model with different cloud workloads, to predict the normal behavior and provide real-time and continuous detection by examining the model reconstruction error distributions. Once an anomaly is detected, to reduce alert fatigue, CloudShield automatically distinguishes between benign programs, known attacks, and zero-day attacks, by examining the prediction error distributions. We evaluate the proposed CloudShield on representative cloud benchmarks. Our evaluation shows that CloudShield, using model pretraining, can apply to a wide scope of cloud workloads. Especially, we observe that CloudShield can detect the recently proposed speculative execution attacks, e.g., Spectre and Meltdown attacks, in milliseconds. Furthermore, we show that CloudShield accurately differentiates and prioritizes known attacks, and potential zero-day attacks, from benign programs. Thus, it significantly reduces false alarms by up to 99.0%.
Smartphone Impostor Detection with Behavioral Data Privacy and Minimalist Hardware Support
Mar 17, 2021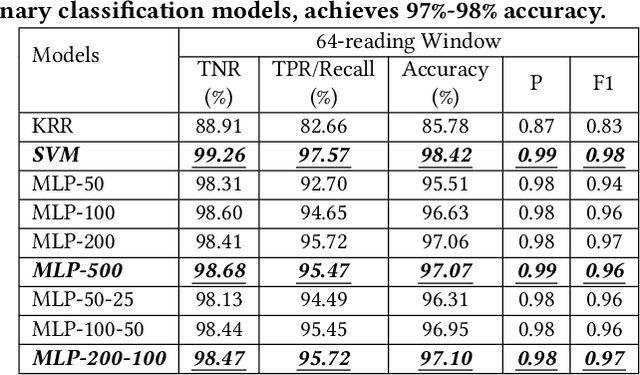
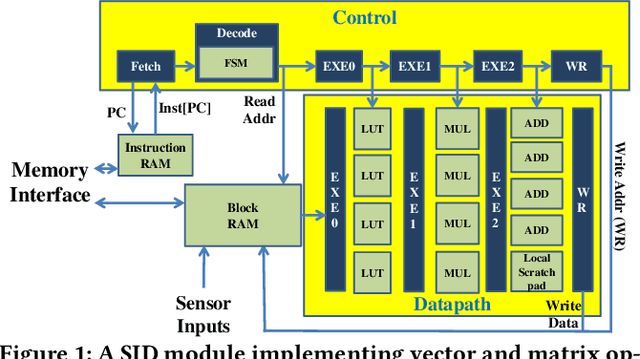
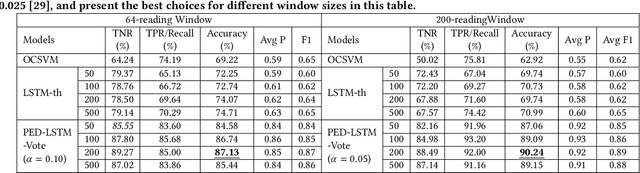
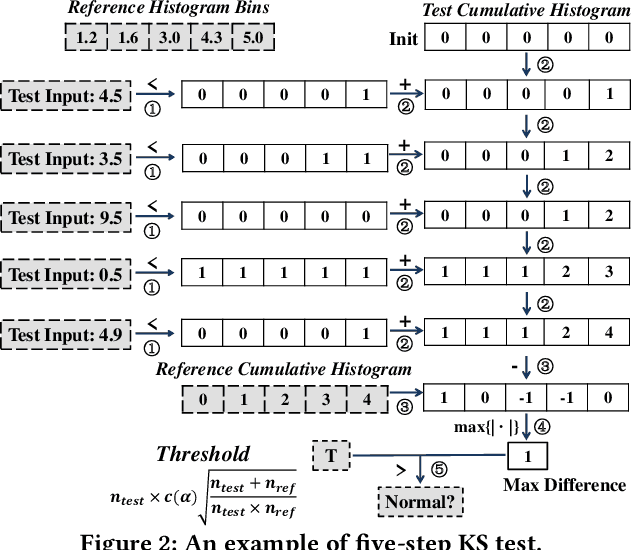
Impostors are attackers who take over a smartphone and gain access to the legitimate user's confidential and private information. This paper proposes a defense-in-depth mechanism to detect impostors quickly with simple Deep Learning algorithms, which can achieve better detection accuracy than the best prior work which used Machine Learning algorithms requiring computation of multiple features. Different from previous work, we then consider protecting the privacy of a user's behavioral (sensor) data by not exposing it outside the smartphone. For this scenario, we propose a Recurrent Neural Network (RNN) based Deep Learning algorithm that uses only the legitimate user's sensor data to learn his/her normal behavior. We propose to use Prediction Error Distribution (PED) to enhance the detection accuracy. We also show how a minimalist hardware module, dubbed SID for Smartphone Impostor Detector, can be designed and integrated into smartphones for self-contained impostor detection. Experimental results show that SID can support real-time impostor detection, at a very low hardware cost and energy consumption, compared to other RNN accelerators.
VerIDeep: Verifying Integrity of Deep Neural Networks through Sensitive-Sample Fingerprinting
Aug 20, 2018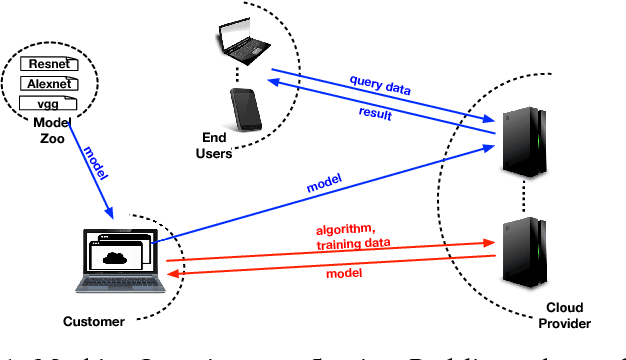
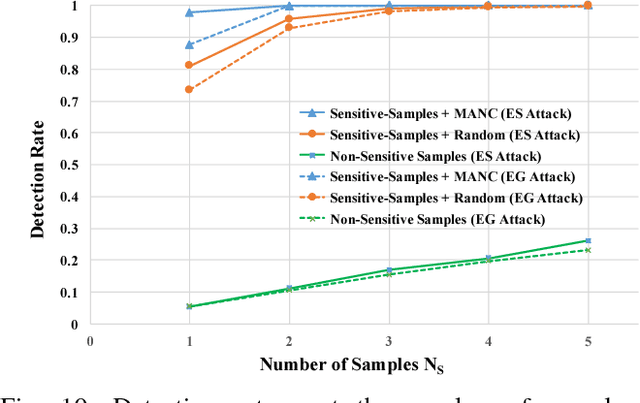

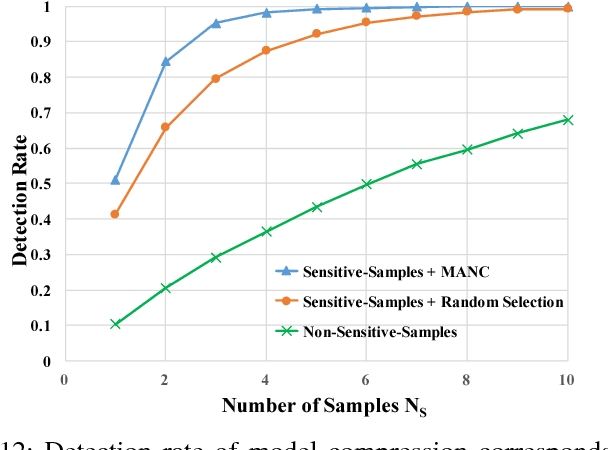
Deep learning has become popular, and numerous cloud-based services are provided to help customers develop and deploy deep learning applications. Meanwhile, various attack techniques have also been discovered to stealthily compromise the model's integrity. When a cloud customer deploys a deep learning model in the cloud and serves it to end-users, it is important for him to be able to verify that the deployed model has not been tampered with, and the model's integrity is protected. We propose a new low-cost and self-served methodology for customers to verify that the model deployed in the cloud is intact, while having only black-box access (e.g., via APIs) to the deployed model. Customers can detect arbitrary changes to their deep learning models. Specifically, we define \texttt{Sensitive-Sample} fingerprints, which are a small set of transformed inputs that make the model outputs sensitive to the model's parameters. Even small weight changes can be clearly reflected in the model outputs, and observed by the customer. Our experiments on different types of model integrity attacks show that we can detect model integrity breaches with high accuracy ($>$99\%) and low overhead ($<$10 black-box model accesses).
Privacy-preserving Machine Learning through Data Obfuscation
Jul 13, 2018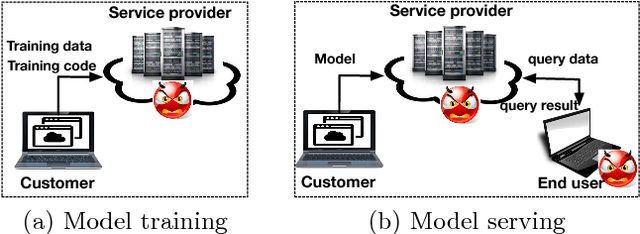
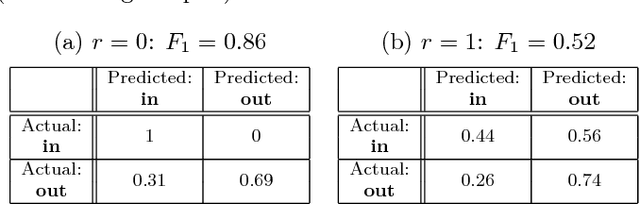

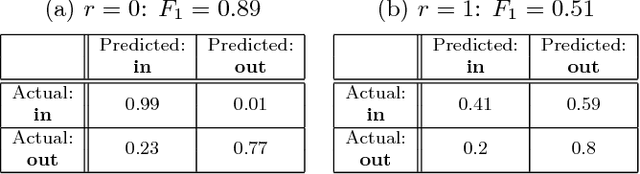
As machine learning becomes a practice and commodity, numerous cloud-based services and frameworks are provided to help customers develop and deploy machine learning applications. While it is prevalent to outsource model training and serving tasks in the cloud, it is important to protect the privacy of sensitive samples in the training dataset and prevent information leakage to untrusted third parties. Past work have shown that a malicious machine learning service provider or end user can easily extract critical information about the training samples, from the model parameters or even just model outputs. In this paper, we propose a novel and generic methodology to preserve the privacy of training data in machine learning applications. Specifically we introduce an obfuscate function and apply it to the training data before feeding them to the model training task. This function adds random noise to existing samples, or augments the dataset with new samples. By doing so sensitive information about the properties of individual samples, or statistical properties of a group of samples, is hidden. Meanwhile the model trained from the obfuscated dataset can still achieve high accuracy. With this approach, the customers can safely disclose the data or models to third-party providers or end users without the need to worry about data privacy. Our experiments show that this approach can effective defeat four existing types of machine learning privacy attacks at negligible accuracy cost.