 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Truncated Log-concave Sampling with Reflective Hamiltonian Monte Carlo
Feb 25, 2021
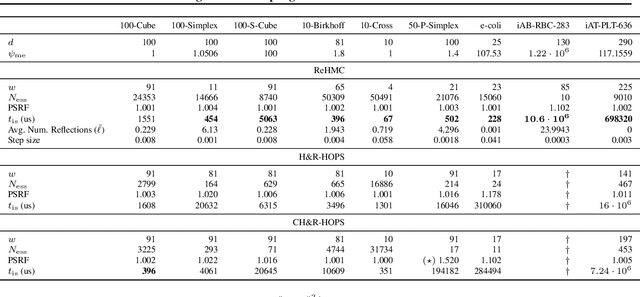
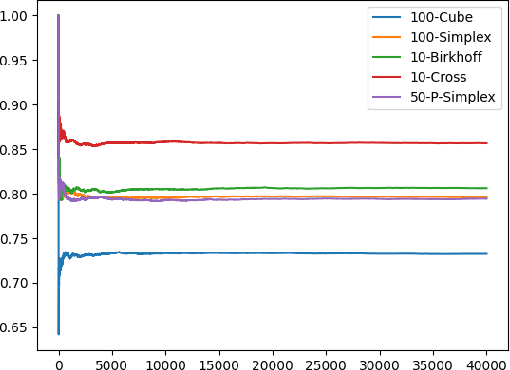
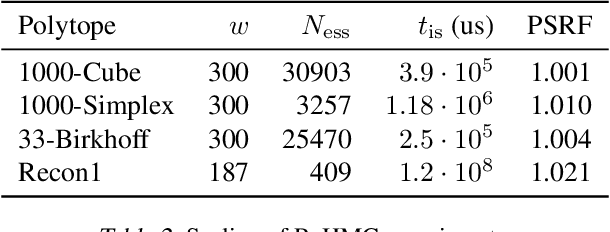
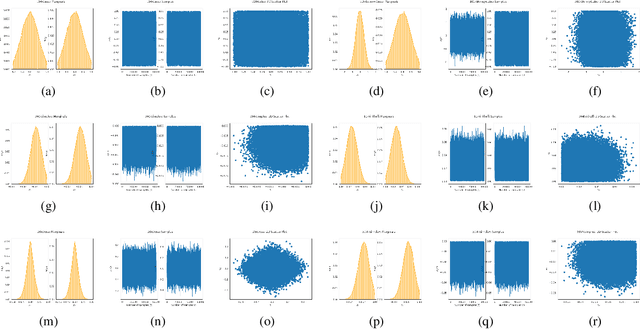
We introduce Reflective Hamiltonian Monte Carlo (ReHMC), an HMC-based algorithm, to sample from a log-concave distribution restricted to a convex polytope. We prove that, starting from a warm start, it mixes in $\widetilde O(\kappa d^2 \ell^2 \log (1 / \varepsilon))$ steps for a well-rounded polytope, ignoring logarithmic factors where $\kappa$ is the condition number of the negative log-density, $d$ is the dimension, $\ell$ is an upper bound on the number of reflections, and $\varepsilon$ is the accuracy parameter. We also developed an open source implementation of ReHMC and we performed an experimental study on various high-dimensional data-sets. Experiments suggest that ReHMC outperfroms Hit-and-Run and Coordinate-Hit-and-Run regarding the time it needs to produce an independent sample.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 20, 2021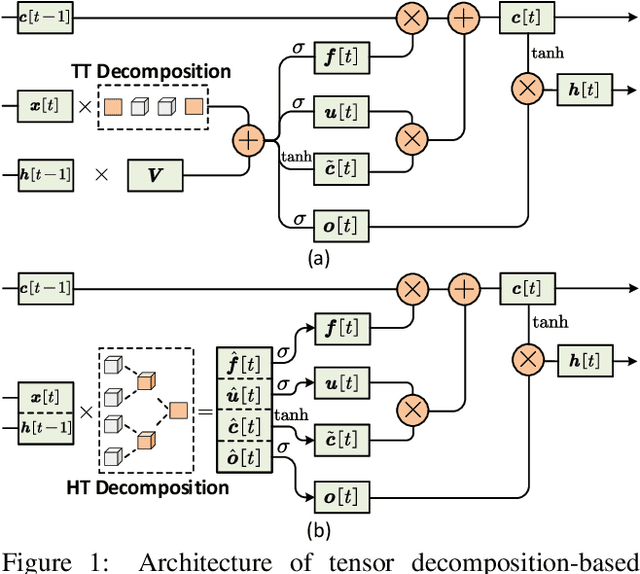
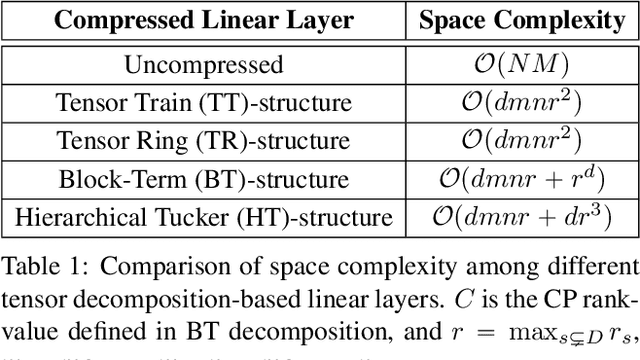
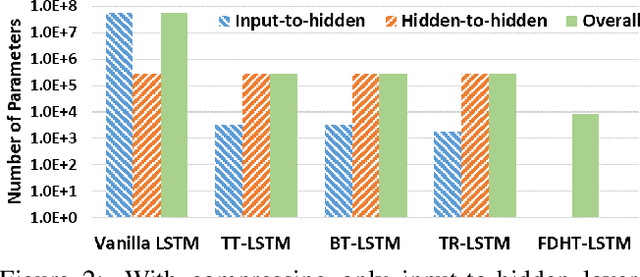
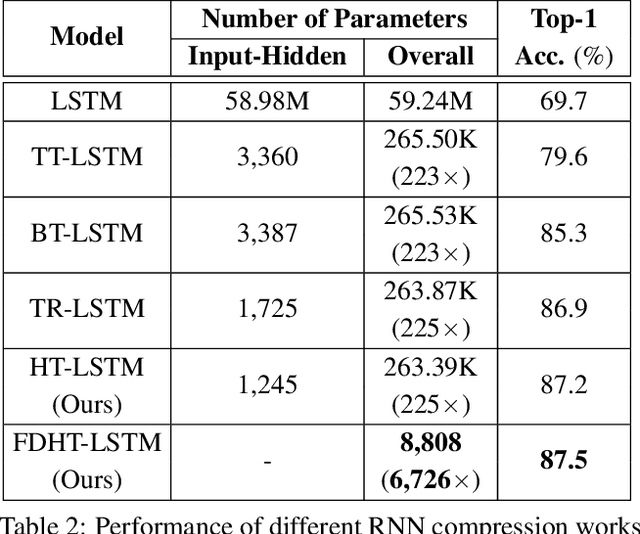
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Learning Parallel Dense Correspondence from Spatio-Temporal Descriptors for Efficient and Robust 4D Reconstruction
Mar 30, 2021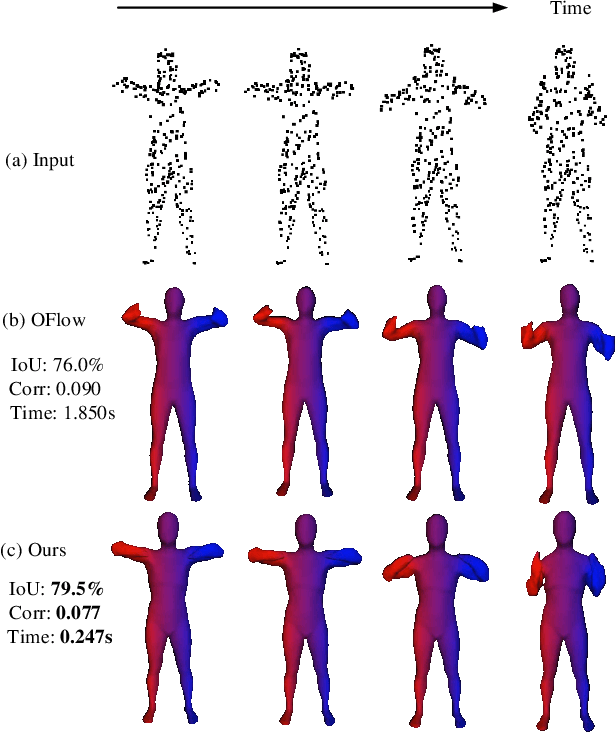
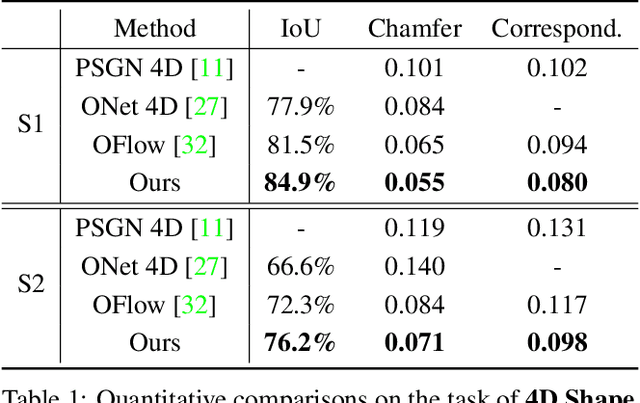
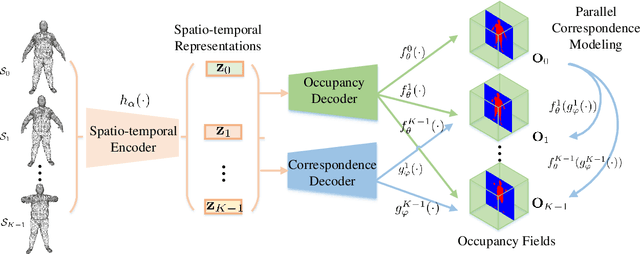
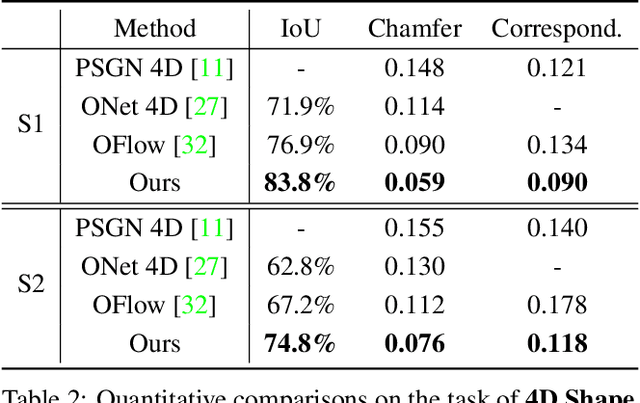
This paper focuses on the task of 4D shape reconstruction from a sequence of point clouds. Despite the recent success achieved by extending deep implicit representations into 4D space, it is still a great challenge in two respects, i.e. how to design a flexible framework for learning robust spatio-temporal shape representations from 4D point clouds, and develop an efficient mechanism for capturing shape dynamics. In this work, we present a novel pipeline to learn a temporal evolution of the 3D human shape through spatially continuous transformation functions among cross-frame occupancy fields. The key idea is to parallelly establish the dense correspondence between predicted occupancy fields at different time steps via explicitly learning continuous displacement vector fields from robust spatio-temporal shape representations. Extensive comparisons against previous state-of-the-arts show the superior accuracy of our approach for 4D human reconstruction in the problems of 4D shape auto-encoding and completion, and a much faster network inference with about 8 times speedup demonstrates the significant efficiency of our approach. The trained models and implementation code are available at https://github.com/tangjiapeng/LPDC-Net.
Variational models for signal processing with Graph Neural Networks
Mar 30, 2021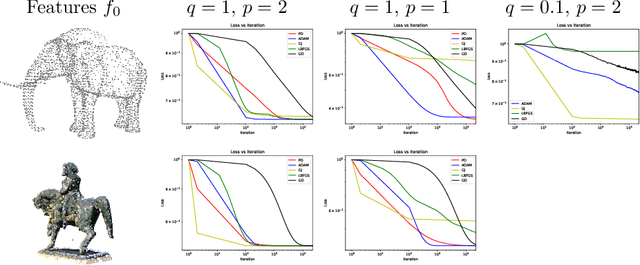
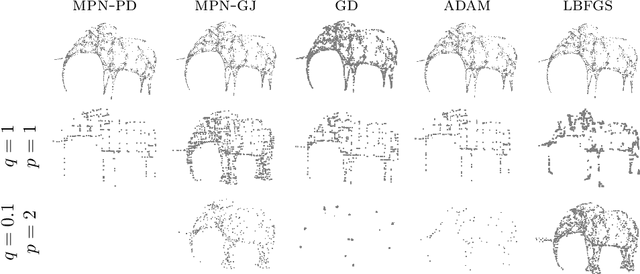

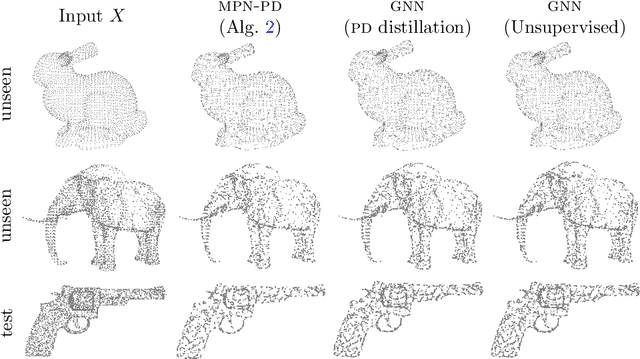
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning.Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning
Self-supervised Graph Neural Networks without explicit negative sampling
Mar 30, 2021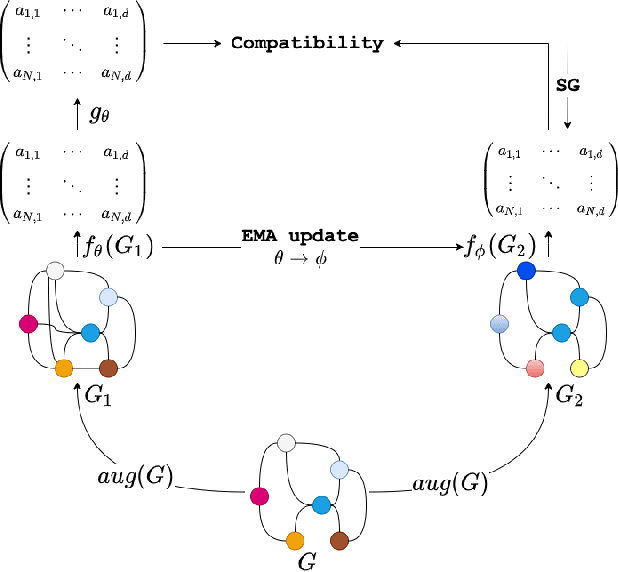
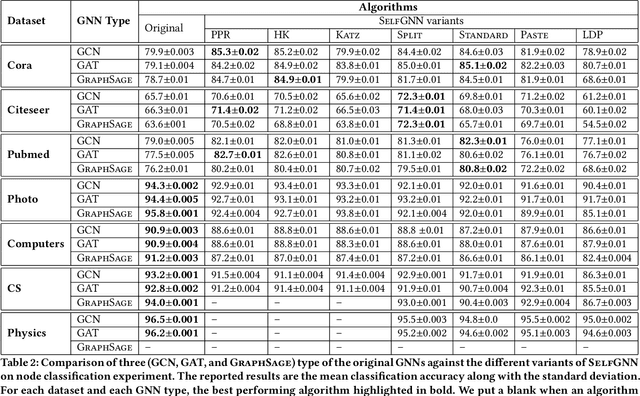
Real world data is mostly unlabeled or only few instances are labeled. Manually labeling data is a very expensive and daunting task. This calls for unsupervised learning techniques that are powerful enough to achieve comparable results as semi-supervised/supervised techniques. Contrastive self-supervised learning has emerged as a powerful direction, in some cases outperforming supervised techniques. In this study, we propose, SelfGNN, a novel contrastive self-supervised graph neural network (GNN) without relying on explicit contrastive terms. We leverage Batch Normalization, which introduces implicit contrastive terms, without sacrificing performance. Furthermore, as data augmentation is key in contrastive learning, we introduce four feature augmentation (FA) techniques for graphs. Though graph topological augmentation (TA) is commonly used, our empirical findings show that FA perform as good as TA. Moreover, FA incurs no computational overhead, unlike TA, which often has O(N^3) time complexity, N-number of nodes. Our empirical evaluation on seven publicly available real-world data shows that, SelfGNN is powerful and leads to a performance comparable with SOTA supervised GNNs and always better than SOTA semi-supervised and unsupervised GNNs. The source code is available at https://github.com/zekarias-tilahun/SelfGNN.
Online Feature Screening for Data Streams with Concept Drift
Apr 07, 2021
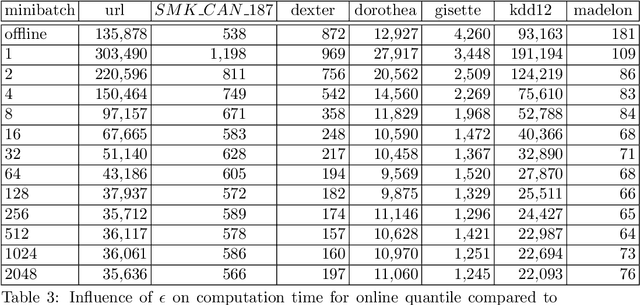
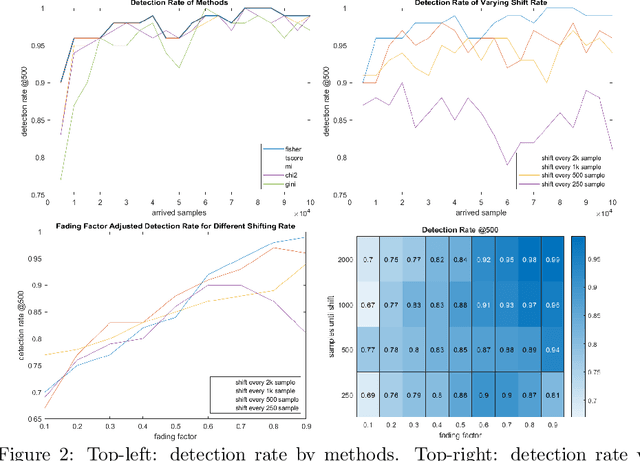
Screening feature selection methods are often used as a preprocessing step for reducing the number of variables before training step. Traditional screening methods only focus on dealing with complete high dimensional datasets. Modern datasets not only have higher dimension and larger sample size, but also have properties such as streaming input, sparsity and concept drift. Therefore a considerable number of online feature selection methods were introduced to handle these kind of problems in recent years. Online screening methods are one of the categories of online feature selection methods. The methods that we proposed in this research are capable of handling all three situations mentioned above. Our research study focuses on classification datasets. Our experiments show proposed methods can generate the same feature importance as their offline version with faster speed and less storage consumption. Furthermore, the results show that online screening methods with integrated model adaptation have a higher true feature detection rate than without model adaptation on data streams with the concept drift property. Among the two large real datasets that potentially have the concept drift property, online screening methods with model adaptation show advantages in either saving computing time and space, reducing model complexity, or improving prediction accuracy.
FSR: Accelerating the Inference Process of Transducer-Based Models by Applying Fast-Skip Regularization
Apr 07, 2021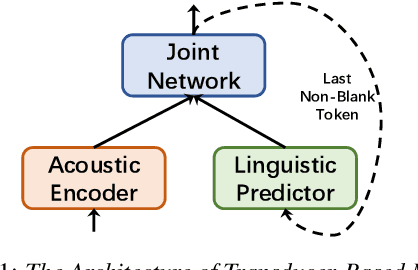
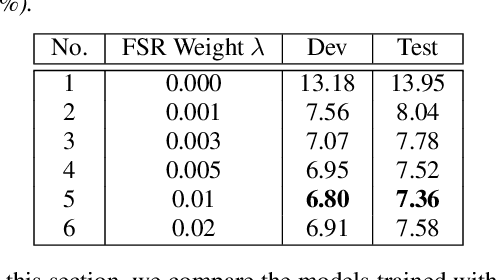
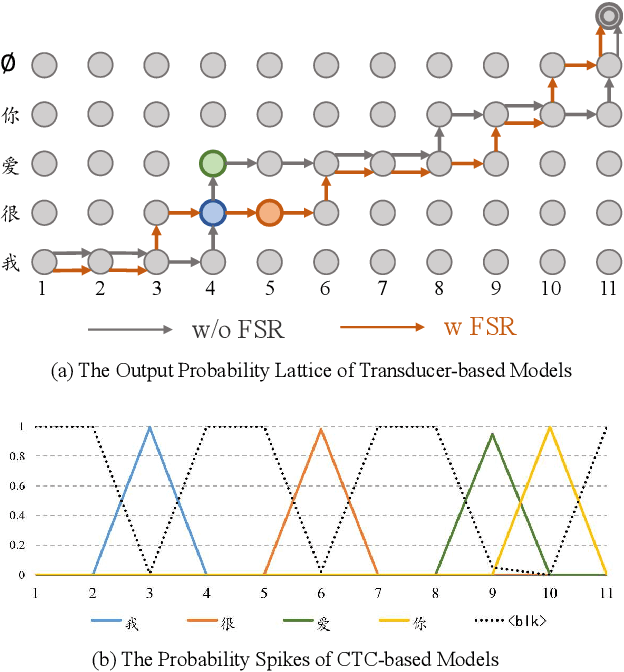

Transducer-based models, such as RNN-Transducer and transformer-transducer, have achieved great success in speech recognition. A typical transducer model decodes the output sequence conditioned on the current acoustic state and previously predicted tokens step by step. Statistically, The number of blank tokens in the prediction results accounts for nearly 90\% of all tokens. It takes a lot of computation and time to predict the blank tokens, but only the non-blank tokens will appear in the final output sequence. Therefore, we propose a method named fast-skip regularization, which tries to align the blank position predicted by a transducer with that predicted by a CTC model. During the inference, the transducer model can predict the blank tokens in advance by a simple CTC project layer without many complicated forward calculations of the transducer decoder and then skip them, which will reduce the computation and improve the inference speed greatly. All experiments are conducted on a public Chinese mandarin dataset AISHELL-1. The results show that the fast-skip regularization can indeed help the transducer model learn the blank position alignments. Besides, the inference with fast-skip can be speeded up nearly 4 times with only a little performance degradation.
A Novel Hybrid Framework for Hourly PM2.5 Concentration Forecasting Using CEEMDAN and Deep Temporal Convolutional Neural Network
Dec 07, 2020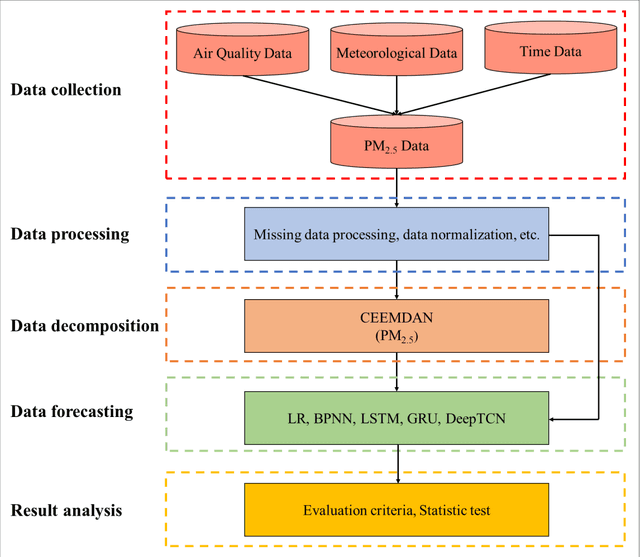
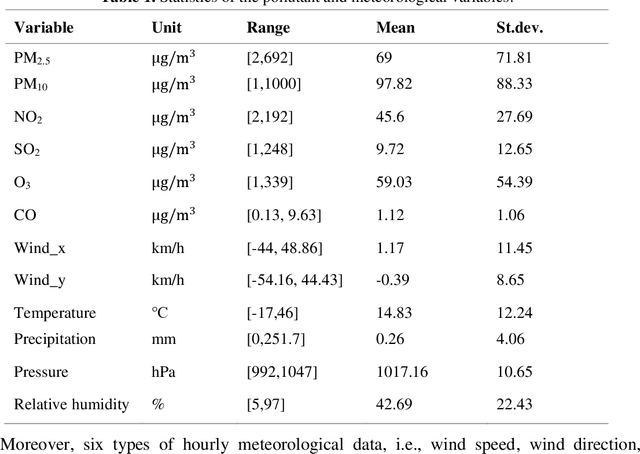
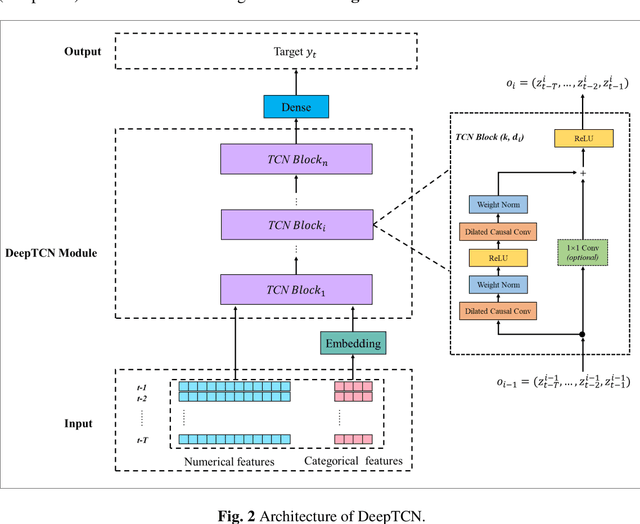
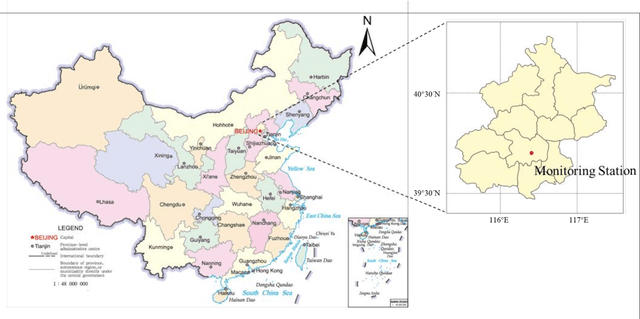
For hourly PM2.5 concentration prediction, accurately capturing the data patterns of external factors that affect PM2.5 concentration changes, and constructing a forecasting model is one of efficient means to improve forecasting accuracy. In this study, a novel hybrid forecasting model based on complete ensemble empirical mode decomposition with adaptive noise (CEEMDAN) and deep temporal convolutional neural network (DeepTCN) is developed to predict PM2.5 concentration, by modelling the data patterns of historical pollutant concentrations data, meteorological data, and discrete time variables' data. Taking PM2.5 concentration of Beijing as the sample, experimental results showed that the forecasting accuracy of the proposed CEEMDAN-DeepTCN model is verified to be the highest when compared with the time series model, artificial neural network, and the popular deep learning models. The new model has improved the capability to model the PM2.5-related factor data patterns, and can be used as a promising tool for forecasting PM2.5 concentrations.
ConFuse: Convolutional Transform Learning Fusion Framework For Multi-Channel Data Analysis
Nov 09, 2020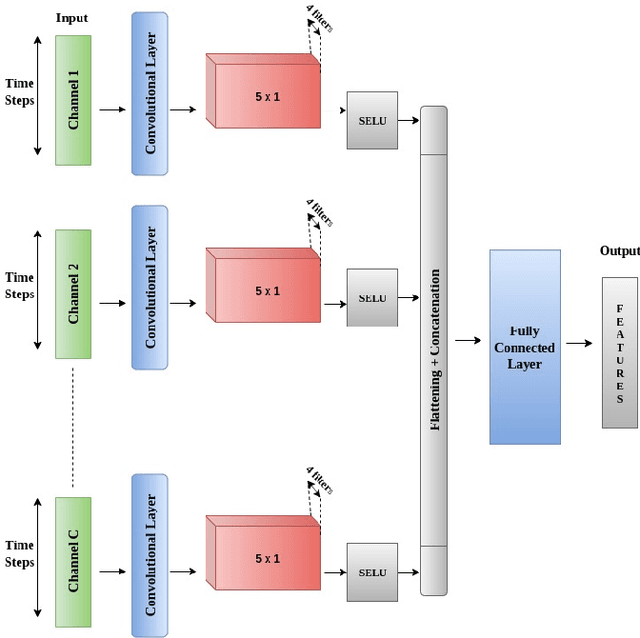
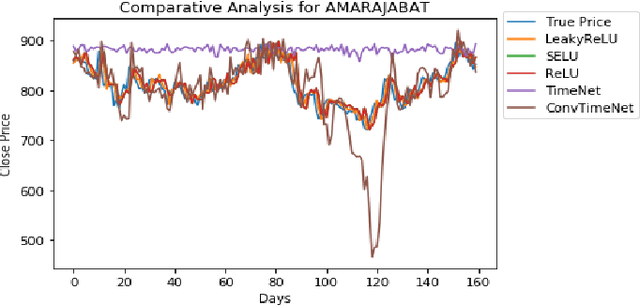
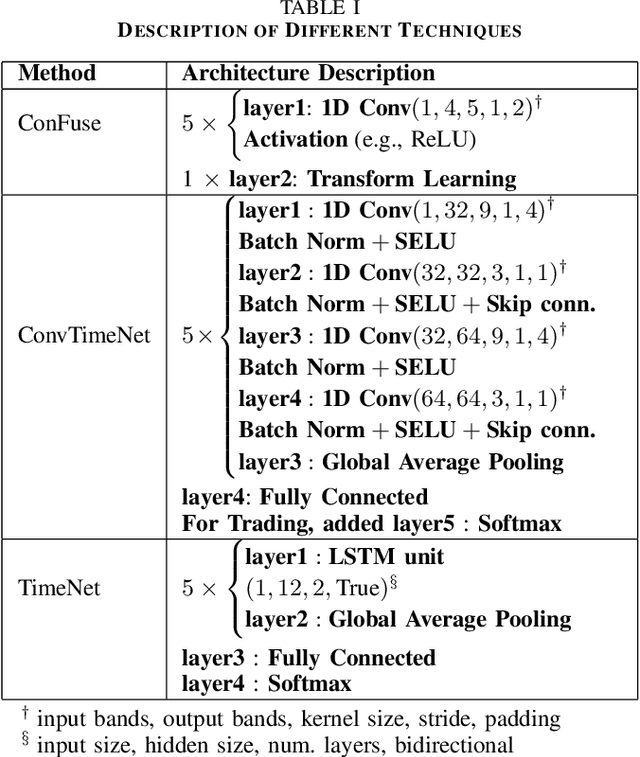
This work addresses the problem of analyzing multi-channel time series data %. In this paper, we by proposing an unsupervised fusion framework based on %the recently proposed convolutional transform learning. Each channel is processed by a separate 1D convolutional transform; the output of all the channels are fused by a fully connected layer of transform learning. The training procedure takes advantage of the proximal interpretation of activation functions. We apply the developed framework to multi-channel financial data for stock forecasting and trading. We compare our proposed formulation with benchmark deep time series analysis networks. The results show that our method yields considerably better results than those compared against.
Optimized and autonomous machine learning framework for characterizing pores, particles, grains and grain boundaries in microstructural images
Jan 16, 2021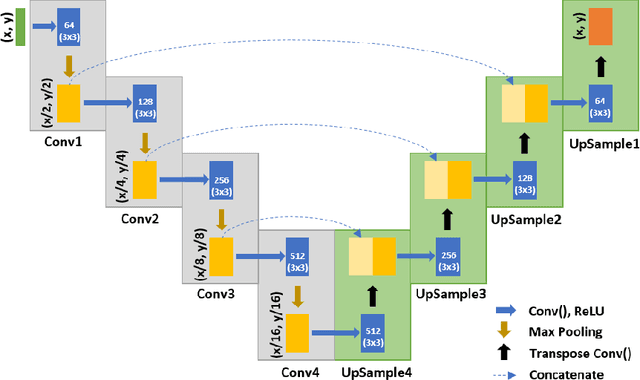
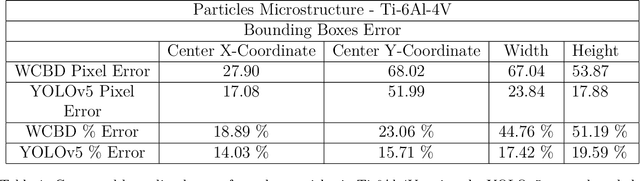
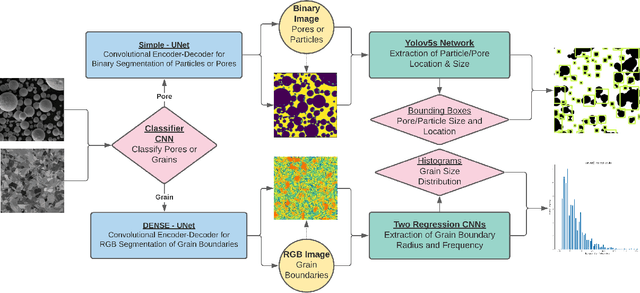
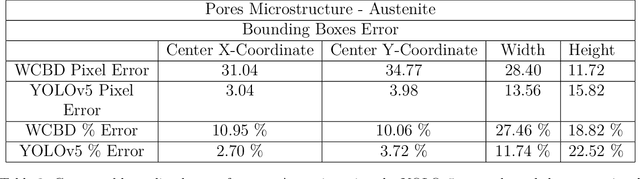
Additively manufactured metals exhibit heterogeneous microstructure which dictates their material and failure properties. Experimental microstructural characterization techniques generate a large amount of data that requires expensive computationally resources. In this work, an optimized machine learning (ML) framework is proposed to autonomously and efficiently characterize pores, particles, grains and grain boundaries (GBs) from a given microstructure image. First, using a classifier Convolutional Neural Network (CNN), defects such as pores, powder particles, or GBs were recognized from a given microstructure. Depending on the type of defect, two different processes were used. For powder particles or pores, binary segmentations were generated using an optimized Convolutional Encoder-Decoder Network (CEDN). The binary segmentations were used to used obtain particle and pore size and bounding boxes using an object detection ML network (YOLOv5). For GBs, another optimized CEDN was developed to generate RGB segmentation images, which were used to obtain grain size distribution using two regression CNNS. To optimize the RGB CEDN, the Deep Emulator Network SEarch (DENSE) method which employs the Covariance Matrix Adaptation - Evolution Strategy (CMA-ES) was implemented. The optimized RGB segmentation network showed a substantial reduction in training time and GPU usage compared to the unoptimized network, while maintaining high accuracy. Lastly, the proposed framework showed a significant improvement in analysis time when compared to conventional methods.