 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combined Transmission and Distribution State-Estimation for Future Electric Grids
May 14, 2021
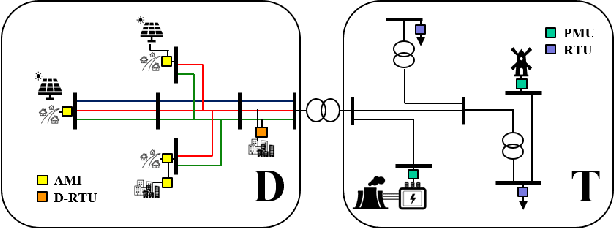
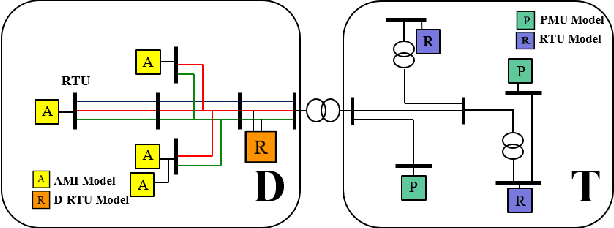
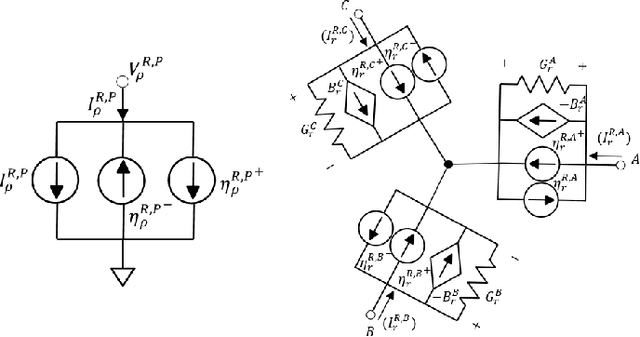
Proliferation of grid resources on the distribution network along with the inability to forecast them accurately will render the existing methodology of grid operation and control untenable in the future. Instead, a more distributed yet coordinated approach for grid operation and control will emerge that models and analyzes the grid with a larger footprint and deeper hierarchy to unify control of disparate T&D grid resources under a common framework. Such approach will require AC state-estimation (ACSE) of joint T&D networks. Today, no practical method for realizing combined T&D ACSE exists. This paper addresses that gap from circuit-theoretic perspective through realizing a combined T&D ACSE solution methodology that is fast, convex and robust against bad-data. To address daunting challenges of problem size (million+ variables) and data-privacy, the approach is distributed both in memory and computing resources. To ensure timely convergence, the approach constructs a distributed circuit model for combined T&D networks and utilizes node-tearing techniques for efficient parallelism. To demonstrate the efficacy of the approach, combined T&D ACSE algorithm is run on large test networks that comprise of multiple T&D feeders. The results reflect the accuracy of the estimates in terms of root mean-square error and algorithm scalability in terms of wall-clock time.
Search-Based Online Trajectory Planning for Car-like Robots in Highly Dynamic Environments
Nov 07, 2020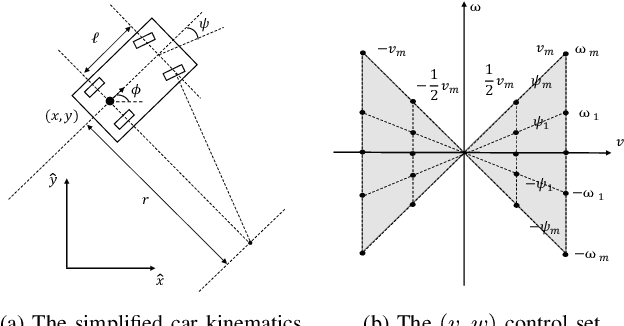
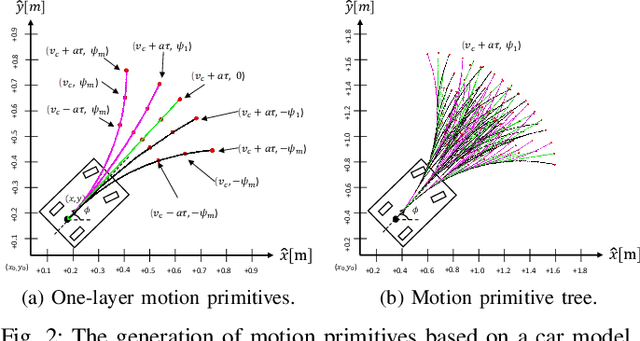
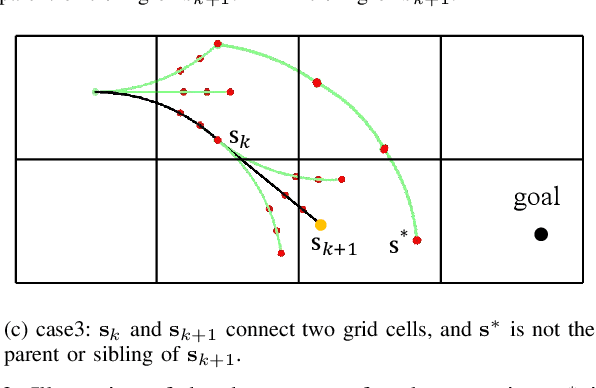
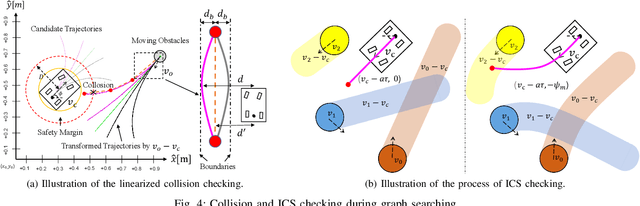
This paper presents a search-based partial motion planner to generate dynamically feasible trajectories for car-like robots in highly dynamic environments. The planner searches for smooth, safe, and near-time-optimal trajectories by exploring a state graph built on motion primitives, which are generated by discretizing the time dimension and the control space. To enable fast online planning, we first propose an efficient path searching algorithm based on the aggregation and pruning of motion primitives. We then propose a fast collision checking algorithm that takes into account the motions of moving obstacles. The algorithm linearizes relative motions between the robot and obstacles and then checks collisions by comparing a point-line distance. Benefiting from the fast searching and collision checking algorithms, the planner can effectively and safely explore the state-time space to generate near-time-optimal solutions. The results through extensive experiments show that the proposed method can generate feasible trajectories within milliseconds while maintaining a higher success rate than up-to-date methods, which significantly demonstrates its advantages.
Fast Text-Only Domain Adaptation of RNN-Transducer Prediction Network
Apr 22, 2021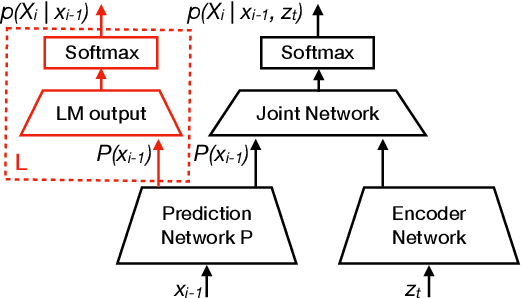

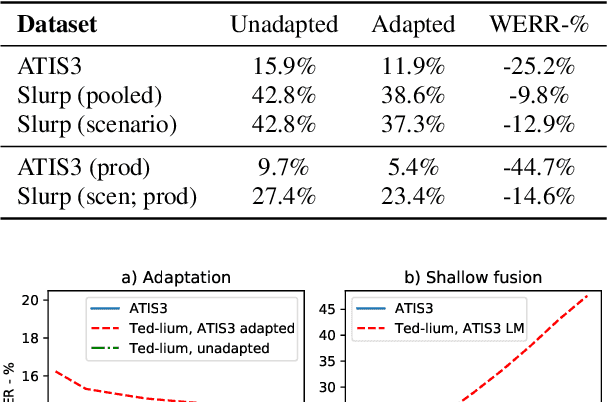
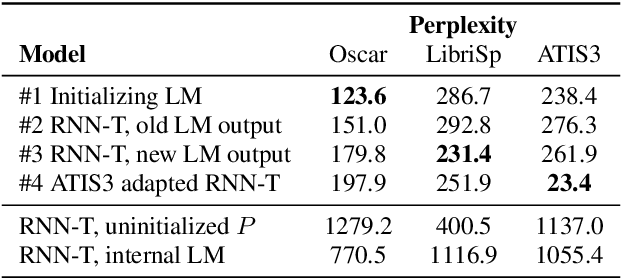
Adaption of end-to-end speech recognition systems to new tasks is known to be challenging. A number of solutions have been proposed which apply external language models with various fusion methods, possibly with a combination of two-pass decoding. Also TTS systems have been used to generate adaptation data for the end-to-end models. In this paper we show that RNN-transducer models can be effectively adapted to new domains using only small amounts of textual data. By taking advantage of model's inherent structure, where the prediction network is interpreted as a language model, we can apply fast adaptation to the model. Adapting the model avoids the need for complicated decoding time fusions and external language models. Using appropriate regularization, the prediction network can be adapted to new domains while still retaining good generalization capabilities. We show with multiple ASR evaluation tasks how this method can provide relative gains of 10-45% in target task WER. We also share insights how RNN-transducer prediction network performs as a language model.
Out-of-Vocabulary Entities in Link Prediction
May 26, 2021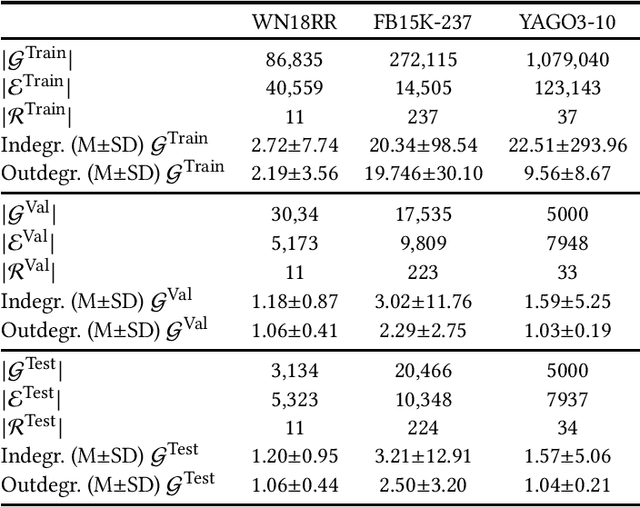
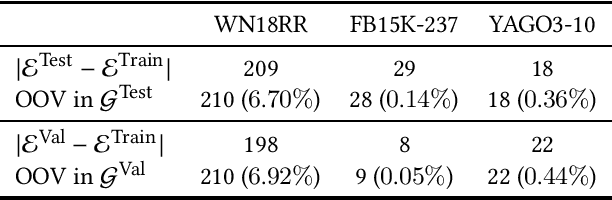
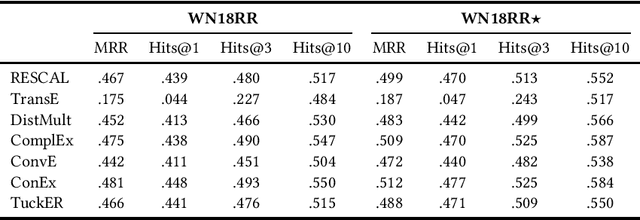
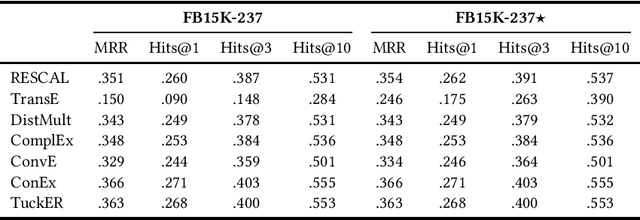
Knowledge graph embedding techniques are key to making knowledge graphs amenable to the plethora of machine learning approaches based on vector representations. Link prediction is often used as a proxy to evaluate the quality of these embeddings. Given that the creation of benchmarks for link prediction is a time-consuming endeavor, most work on the subject matter uses only a few benchmarks. As benchmarks are crucial for the fair comparison of algorithms, ensuring their quality is tantamount to providing a solid ground for developing better solutions to link prediction and ipso facto embedding knowledge graphs. First studies of benchmarks pointed to limitations pertaining to information leaking from the development to the test fragments of some benchmark datasets. We spotted a further common limitation of three of the benchmarks commonly used for evaluating link prediction approaches: out-of-vocabulary entities in the test and validation sets. We provide an implementation of an approach for spotting and removing such entities and provide corrected versions of the datasets WN18RR, FB15K-237, and YAGO3-10. Our experiments on the corrected versions of WN18RR, FB15K-237, and YAGO3-10 suggest that the measured performance of state-of-the-art approaches is altered significantly with p-values <1%, <1.4%, and <1%, respectively. Overall, state-of-the-art approaches gain on average absolute $3.29 \pm 0.24\%$ in all metrics on WN18RR. This means that some of the conclusions achieved in previous works might need to be revisited. We provide an open-source implementation of our experiments and corrected datasets at at https://github.com/dice-group/OOV-In-Link-Prediction.
Deep Reinforcement Learning for Backup Strategies against Adversaries
Feb 12, 2021
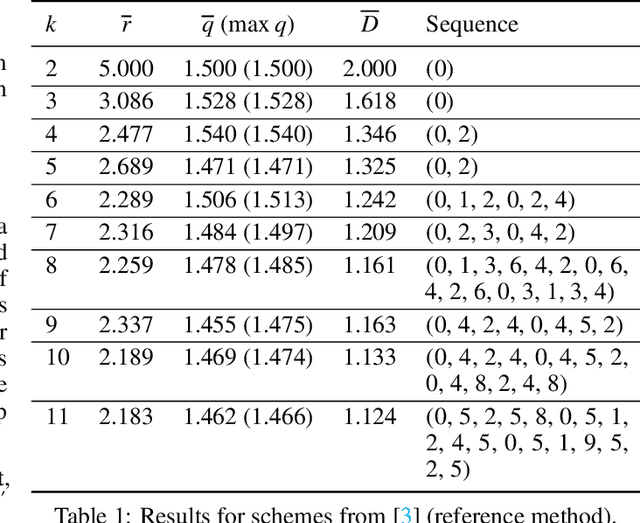

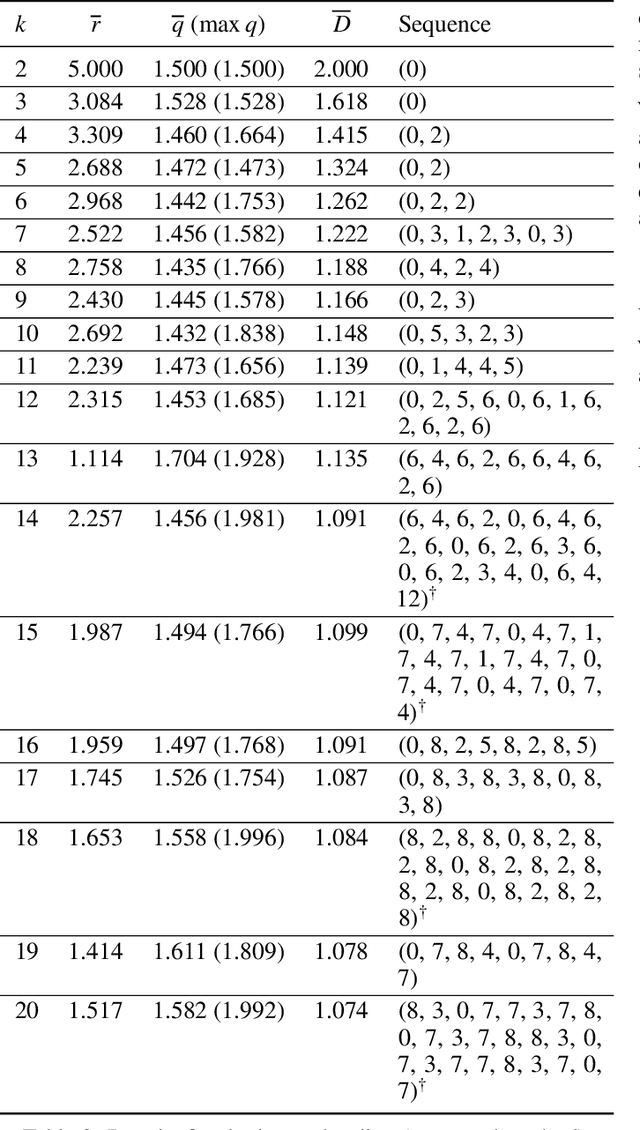
Many defensive measures in cyber security are still dominated by heuristics, catalogs of standard procedures, and best practices. Considering the case of data backup strategies, we aim towards mathematically modeling the underlying threat models and decision problems. By formulating backup strategies in the language of stochastic processes, we can translate the challenge of finding optimal defenses into a reinforcement learning problem. This enables us to train autonomous agents that learn to optimally support planning of defense processes. In particular, we tackle the problem of finding an optimal backup scheme in the following adversarial setting: Given $k$ backup devices, the goal is to defend against an attacker who can infect data at one time but chooses to destroy or encrypt it at a later time, potentially also corrupting multiple backups made in between. In this setting, the usual round-robin scheme, which always replaces the oldest backup, is no longer optimal with respect to avoidable exposure. Thus, to find a defense strategy, we model the problem as a hybrid discrete-continuous action space Markov decision process and subsequently solve it using deep deterministic policy gradients. We show that the proposed algorithm can find storage device update schemes which match or exceed existing schemes with respect to various exposure metrics.
Interpretable Semantic Photo Geolocalization
Apr 30, 2021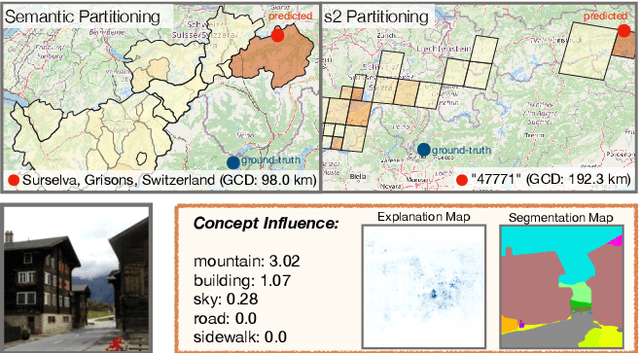

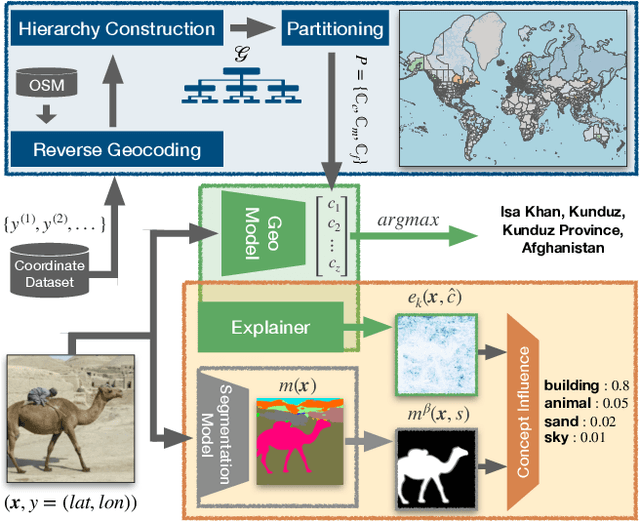
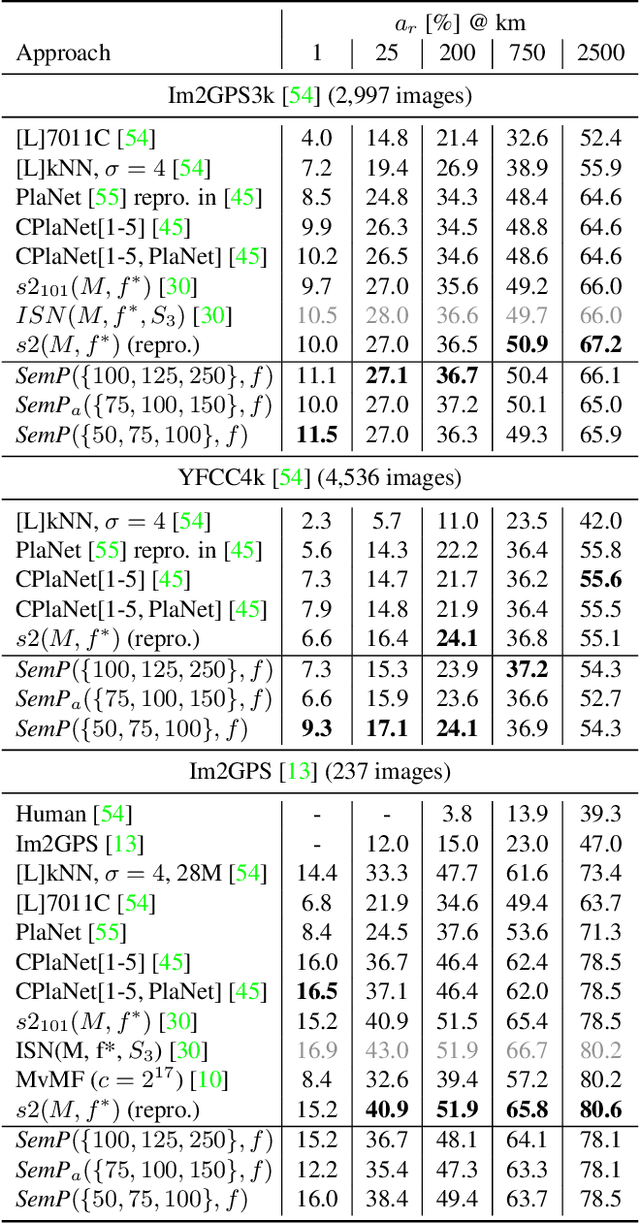
Planet-scale photo geolocalization is the complex task of estimating the location depicted in an image solely based on its visual content. Due to the success of convolutional neural networks (CNNs), current approaches achieve super-human performance. However, previous work has exclusively focused on optimizing geolocalization accuracy. Moreover, due to the black-box property of deep learning systems, their predictions are difficult to validate for humans. State-of-the-art methods treat the task as a classification problem, where the choice of the classes, that is the partitioning of the world map, is the key for success. In this paper, we present two contributions in order to improve the interpretability of a geolocalization model: (1) We propose a novel, semantic partitioning method which intuitively leads to an improved understanding of the predictions, while at the same time state-of-the-art results are achieved for geolocational accuracy on benchmark test sets; (2) We introduce a novel metric to assess the importance of semantic visual concepts for a certain prediction to provide additional interpretable information, which allows for a large-scale analysis of already trained models.
Privacy-preserving Data Analysis through Representation Learning and Transformation
Nov 16, 2020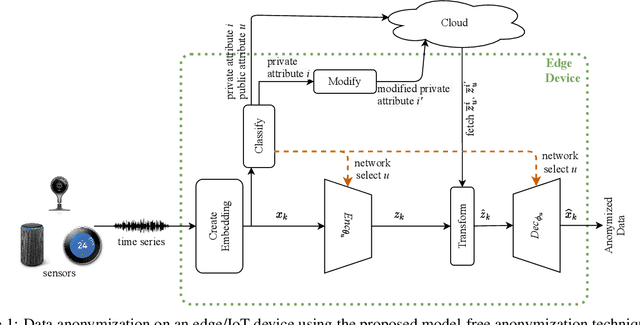

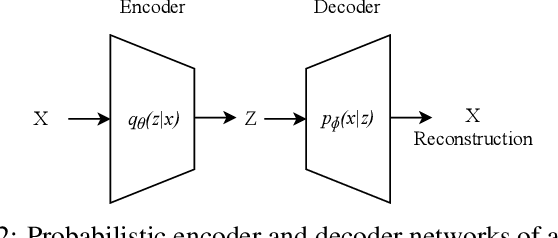

The abundance of data from the sensors embedded in mobile and Internet of Things (IoT) devices and the remarkable success of deep neural networks in uncovering hidden patterns in time series data have led to mounting privacy concerns in recent years. In this paper, we aim to navigate the trade-off between data utility and privacy by learning low-dimensional representations that are useful for data anonymization. We propose probabilistic transformations in the latent space of a variational autoencoder to synthesize time series data such that intrusive inferences are prevented while desired inferences can still be made with a satisfactory level of accuracy. We compare our technique with state-of-the-art autoencoder-based anonymization techniques and additionally show that it can anonymize data in real time on resource-constrained edge devices.
MetaGrad: Adaptation using Multiple Learning Rates in Online Learning
Feb 12, 2021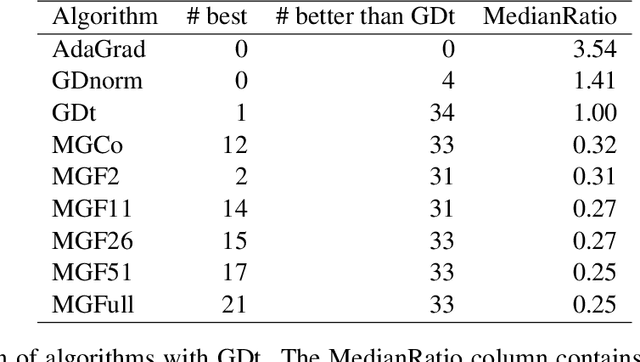
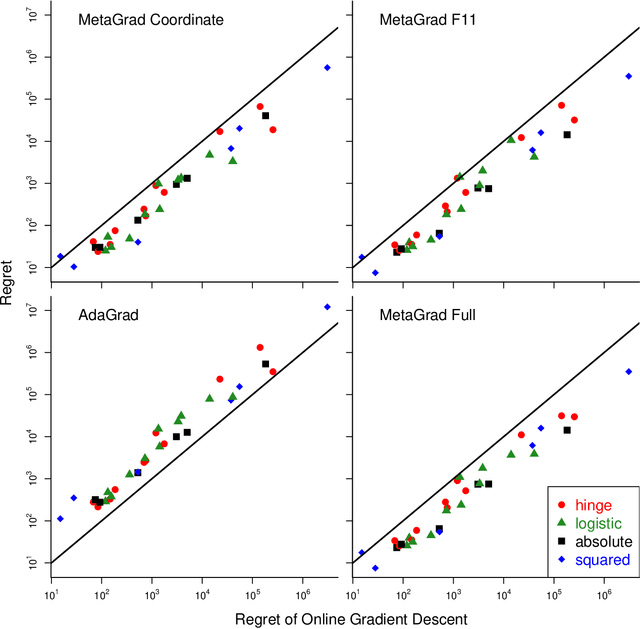
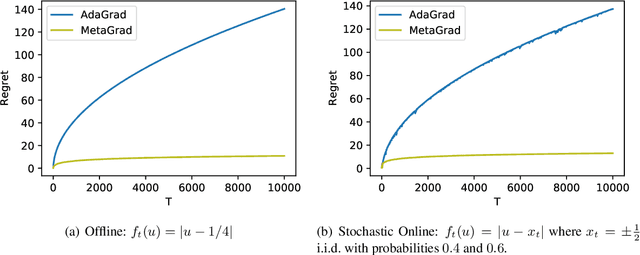
We provide a new adaptive method for online convex optimization, MetaGrad, that is robust to general convex losses but achieves faster rates for a broad class of special functions, including exp-concave and strongly convex functions, but also various types of stochastic and non-stochastic functions without any curvature. We prove this by drawing a connection to the Bernstein condition, which is known to imply fast rates in offline statistical learning. MetaGrad further adapts automatically to the size of the gradients. Its main feature is that it simultaneously considers multiple learning rates, which are weighted directly proportional to their empirical performance on the data using a new meta-algorithm. We provide three versions of MetaGrad. The full matrix version maintains a full covariance matrix and is applicable to learning tasks for which we can afford update time quadratic in the dimension. The other two versions provide speed-ups for high-dimensional learning tasks with an update time that is linear in the dimension: one is based on sketching, the other on running a separate copy of the basic algorithm per coordinate. We evaluate all versions of MetaGrad on benchmark online classification and regression tasks, on which they consistently outperform both online gradient descent and AdaGrad.
Survey on Modeling Intensity Function of Hawkes Process Using Neural Models
Apr 22, 2021
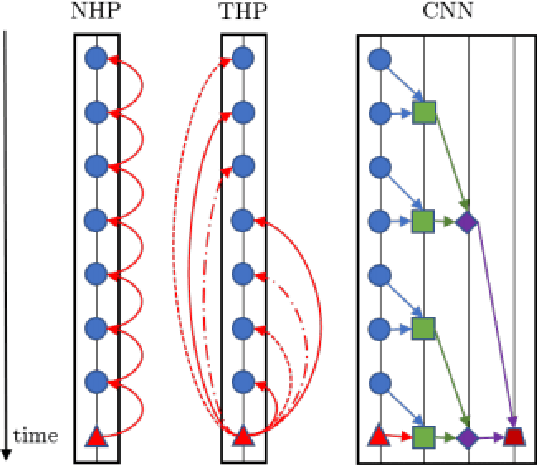
The event sequence of many diverse systems is represented as a sequence of discrete events in a continuous space. Examples of such an event sequence are earthquake aftershock events, financial transactions, e-commerce transactions, social network activity of a user, and the user's web search pattern. Finding such an intricate pattern helps discover which event will occur in the future and when it will occur. A Hawkes process is a mathematical tool used for modeling such time series discrete events. Traditionally, the Hawkes process uses a critical component for modeling data as an intensity function with a parameterized kernel function. The Hawkes process's intensity function involves two components: the background intensity and the effect of events' history. However, such parameterized assumption can not capture future event characteristics using past events data precisely due to bias in modeling kernel function. This paper explores the recent advancement using novel deep learning-based methods to model kernel function to remove such parametrized kernel function. In the end, we will give potential future research directions to improve modeling using the Hawkes process.
A Unified Framework for Long Range and Cold Start Forecasting of Seasonal Profiles in Time Series
Aug 26, 2018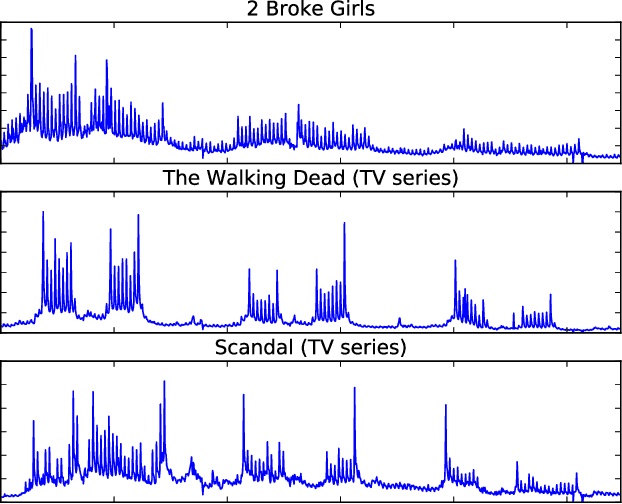
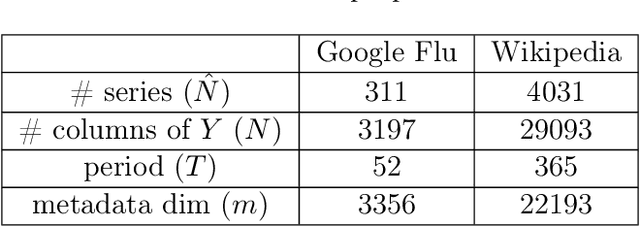
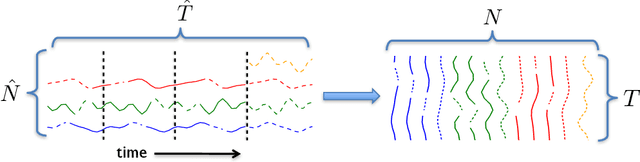
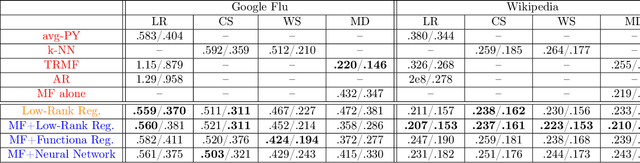
Providing long-range forecasts is a fundamental challenge in time series modeling, which is only compounded by the challenge of having to form such forecasts when a time series has never previously been observed. The latter challenge is the time series version of the cold-start problem seen in recommender systems which, to our knowledge, has not been addressed in previous work. A similar problem occurs when a long range forecast is required after only observing a small number of time points --- a warm start forecast. With these aims in mind, we focus on forecasting seasonal profiles---or baseline demand---for periods on the order of a year in three cases: the long range case with multiple previously observed seasonal profiles, the cold start case with no previous observed seasonal profiles, and the warm start case with only a single partially observed profile. Classical time series approaches that perform iterated step-ahead forecasts based on previous observations struggle to provide accurate long range predictions; in settings with little to no observed data, such approaches are simply not applicable. Instead, we present a straightforward framework which combines ideas from high-dimensional regression and matrix factorization on a carefully constructed data matrix. Key to our formulation and resulting performance is leveraging (1) repeated patterns over fixed periods of time and across series, and (2) metadata associated with the individual series; without this additional data, the cold-start/warm-start problems are nearly impossible to solve. We demonstrate that our framework can accurately forecast an array of seasonal profiles on multiple large scale datasets.