 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fully Convolutional Geometric Features for Category-level Object Alignment
Mar 08, 2021
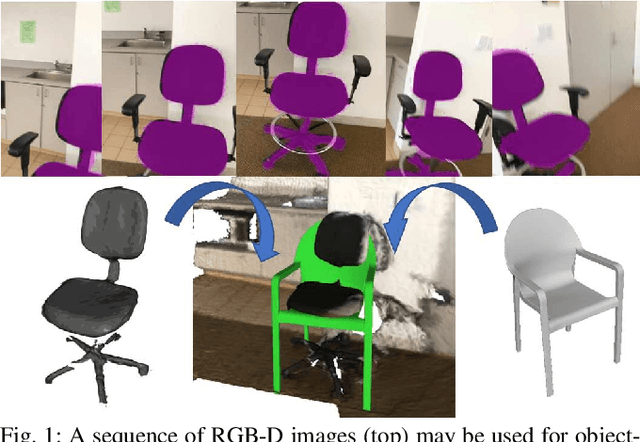
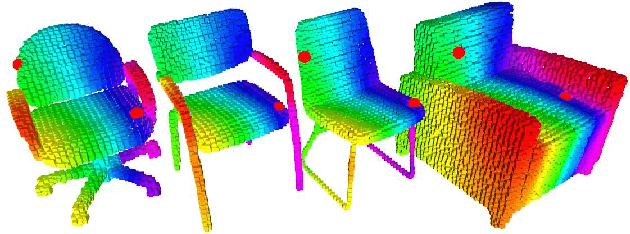
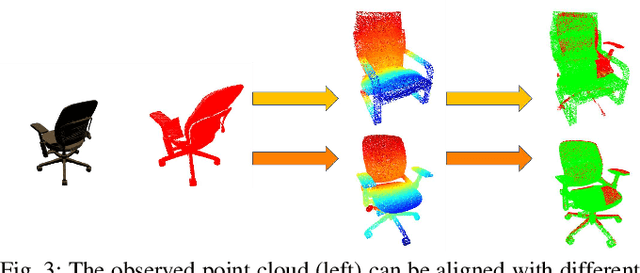
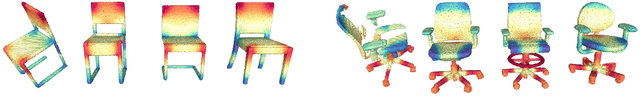
This paper focuses on pose registration of different object instances from the same category. This is required in online object mapping because object instances detected at test time usually differ from the training instances. Our approach transforms instances of the same category to a normalized canonical coordinate frame and uses metric learning to train fully convolutional geometric features. The resulting model is able to generate pairs of matching points between the instances, allowing category-level registration. Evaluation on both synthetic and real-world data shows that our method provides robust features, leading to accurate alignment of instances with different shapes.
* 7 pages, 9 figures
ELSKE: Efficient Large-Scale Keyphrase Extraction
Feb 10, 2021
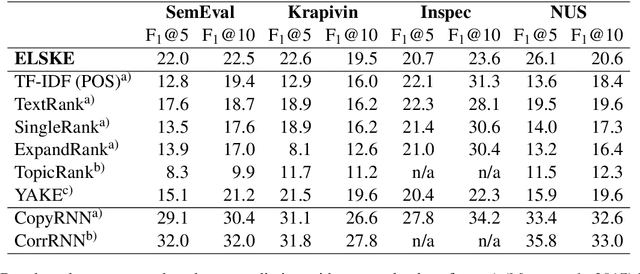
Keyphrase extraction methods can provide insights into large collections of documents such as social media posts. Existing methods, however, are less suited for the real-time analysis of streaming data, because they are computationally too expensive or require restrictive constraints regarding the structure of keyphrases. We propose an efficient approach to extract keyphrases from large document collections and show that the method also performs competitively on individual documents.
A Picture is Worth a Collaboration: Accumulating Design Knowledge for Computer-Vision-based Hybrid Intelligence Systems
Apr 23, 2021
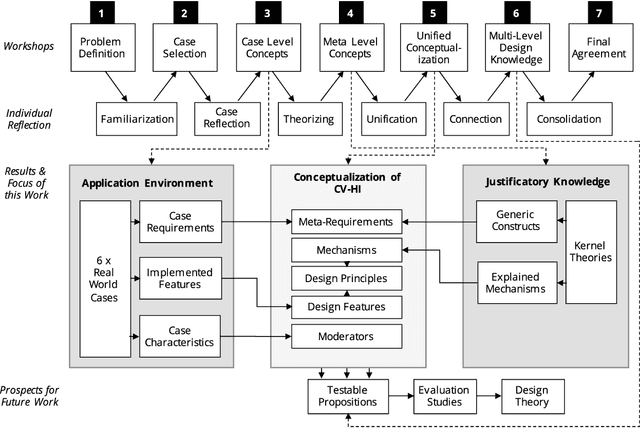
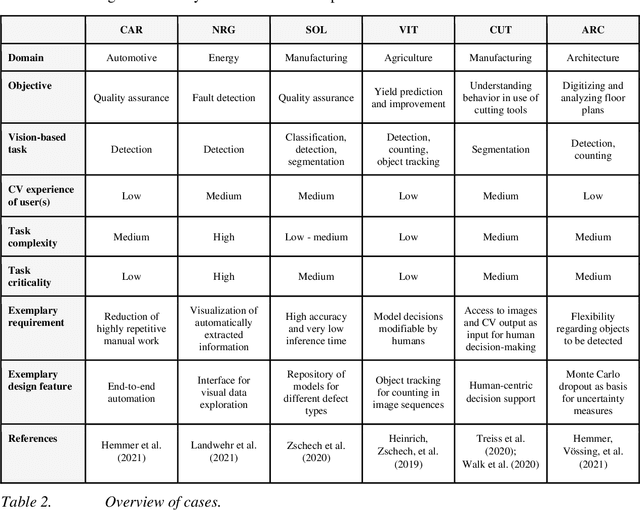
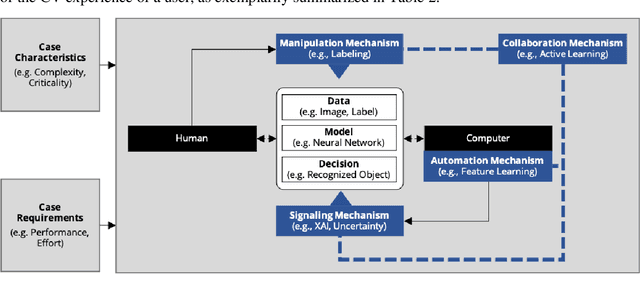
Computer vision (CV) techniques try to mimic human capabilities of visual perception to support labor-intensive and time-consuming tasks like the recognition and localization of critical objects. Nowadays, CV increasingly relies on artificial intelligence (AI) to automatically extract useful information from images that can be utilized for decision support and business process automation. However, the focus of extant research is often exclusively on technical aspects when designing AI-based CV systems while neglecting socio-technical facets, such as trust, control, and autonomy. For this purpose, we consider the design of such systems from a hybrid intelligence (HI) perspective and aim to derive prescriptive design knowledge for CV-based HI systems. We apply a reflective, practice-inspired design science approach and accumulate design knowledge from six comprehensive CV projects. As a result, we identify four design-related mechanisms (i.e., automation, signaling, modification, and collaboration) that inform our derived meta-requirements and design principles. This can serve as a basis for further socio-technical research on CV-based HI systems.
Prioritizing Original News on Facebook
Mar 14, 2021
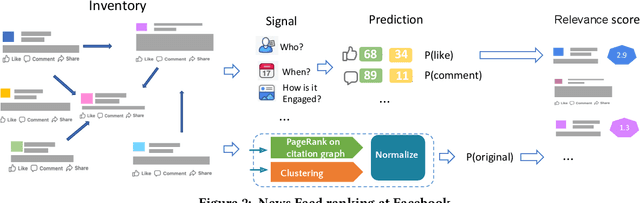
This work outlines how we prioritize original news, a critical indicator of news quality. By examining the landscape and life-cycle of news posts on our social media platform, we identify challenges of building and deploying an originality score. We pursue an approach based on normalized PageRank values and three-step clustering, and refresh the score on an hourly basis to capture the dynamics of online news. We describe a near real-time system architecture, evaluate our methodology, and deploy it to production. Our empirical results validate individual components and show that prioritizing original news increases user engagement with news and improves proprietary cumulative metrics.
Transient Chaos in BERT
Jun 06, 2021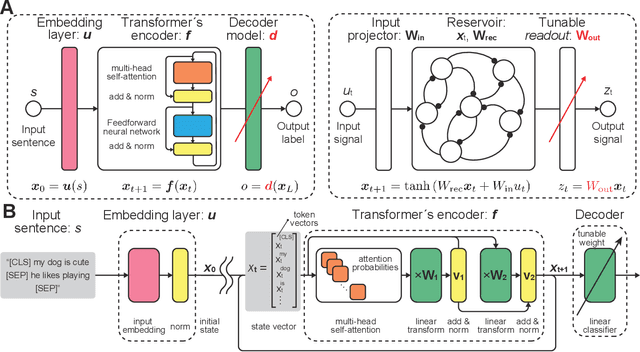
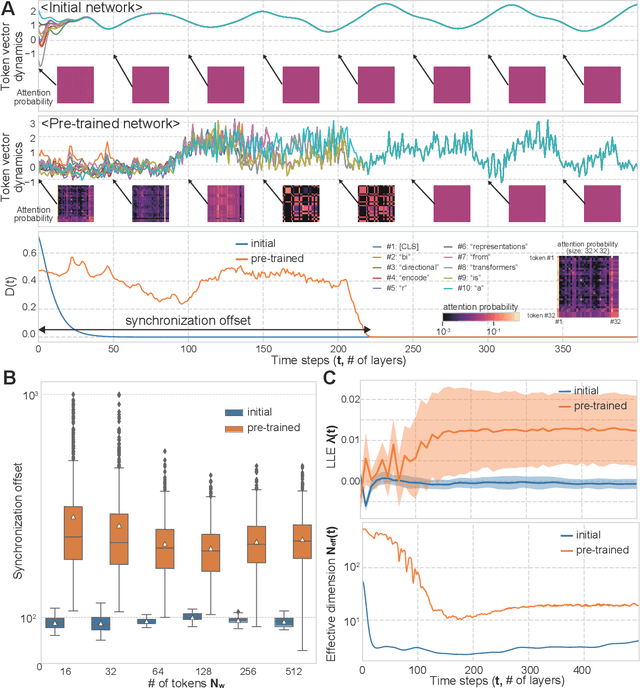
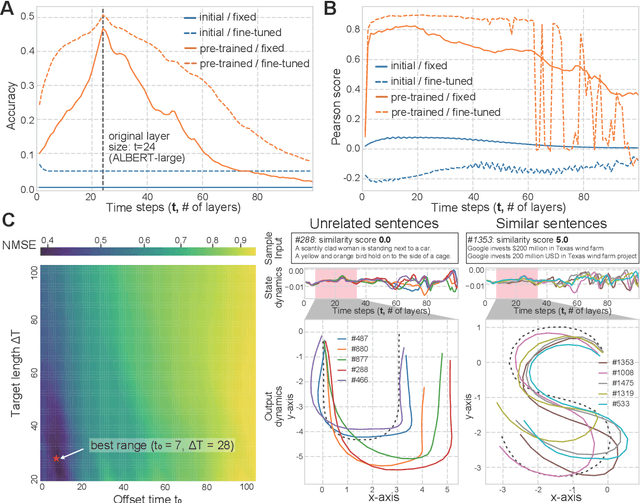
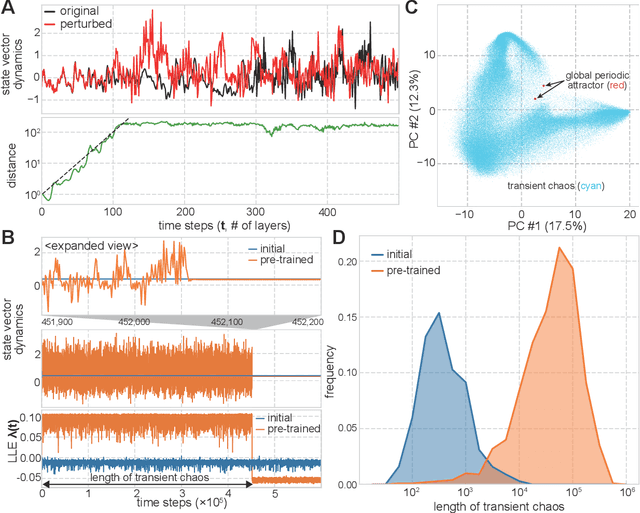
Language is an outcome of our complex and dynamic human-interactions and the technique of natural language processing (NLP) is hence built on human linguistic activities. Bidirectional Encoder Representations from Transformers (BERT) has recently gained its popularity by establishing the state-of-the-art scores in several NLP benchmarks. A Lite BERT (ALBERT) is literally characterized as a lightweight version of BERT, in which the number of BERT parameters is reduced by repeatedly applying the same neural network called Transformer's encoder layer. By pre-training the parameters with a massive amount of natural language data, ALBERT can convert input sentences into versatile high-dimensional vectors potentially capable of solving multiple NLP tasks. In that sense, ALBERT can be regarded as a well-designed high-dimensional dynamical system whose operator is the Transformer's encoder, and essential structures of human language are thus expected to be encapsulated in its dynamics. In this study, we investigated the embedded properties of ALBERT to reveal how NLP tasks are effectively solved by exploiting its dynamics. We thereby aimed to explore the nature of human language from the dynamical expressions of the NLP model. Our short-term analysis clarified that the pre-trained model stably yields trajectories with higher dimensionality, which would enhance the expressive capacity required for NLP tasks. Also, our long-term analysis revealed that ALBERT intrinsically shows transient chaos, a typical nonlinear phenomenon showing chaotic dynamics only in its transient, and the pre-trained ALBERT model tends to produce the chaotic trajectory for a significantly longer time period compared to a randomly-initialized one. Our results imply that local chaoticity would contribute to improving NLP performance, uncovering a novel aspect in the role of chaotic dynamics in human language behaviors.
Self-learning for weakly supervised Gleason grading of local patterns
May 21, 2021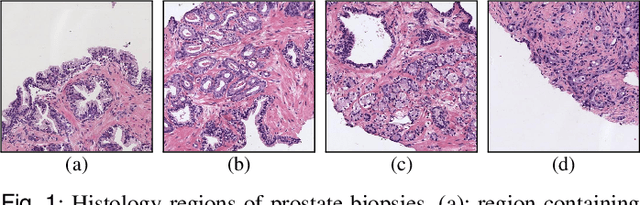
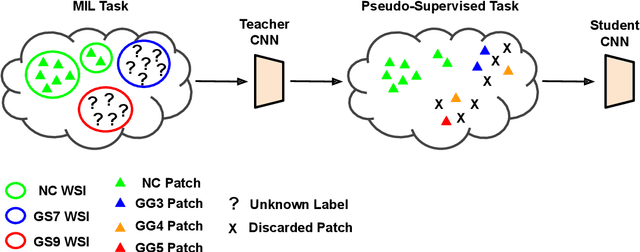
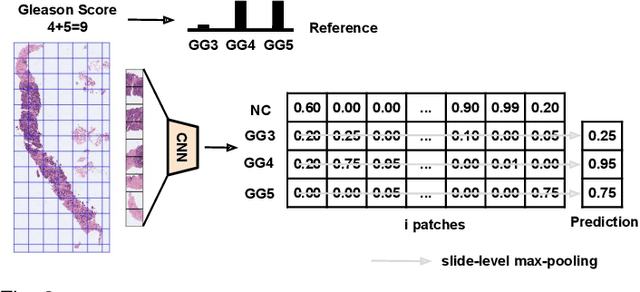
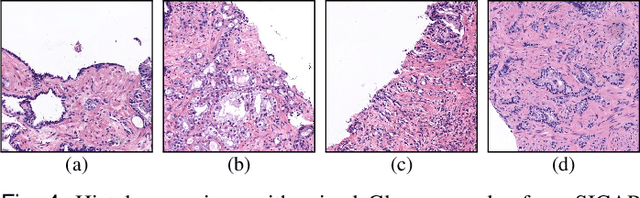
Prostate cancer is one of the main diseases affecting men worldwide. The gold standard for diagnosis and prognosis is the Gleason grading system. In this process, pathologists manually analyze prostate histology slides under microscope, in a high time-consuming and subjective task. In the last years, computer-aided-diagnosis (CAD) systems have emerged as a promising tool that could support pathologists in the daily clinical practice. Nevertheless, these systems are usually trained using tedious and prone-to-error pixel-level annotations of Gleason grades in the tissue. To alleviate the need of manual pixel-wise labeling, just a handful of works have been presented in the literature. Motivated by this, we propose a novel weakly-supervised deep-learning model, based on self-learning CNNs, that leverages only the global Gleason score of gigapixel whole slide images during training to accurately perform both, grading of patch-level patterns and biopsy-level scoring. To evaluate the performance of the proposed method, we perform extensive experiments on three different external datasets for the patch-level Gleason grading, and on two different test sets for global Grade Group prediction. We empirically demonstrate that our approach outperforms its supervised counterpart on patch-level Gleason grading by a large margin, as well as state-of-the-art methods on global biopsy-level scoring. Particularly, the proposed model brings an average improvement on the Cohen's quadratic kappa (k) score of nearly 18% compared to full-supervision for the patch-level Gleason grading task.
CapillaryNet: An Automated System to Analyze Microcirculation Videos from Handheld Vital Microscopy
Apr 23, 2021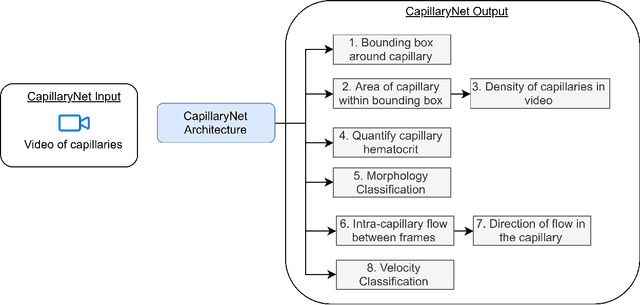

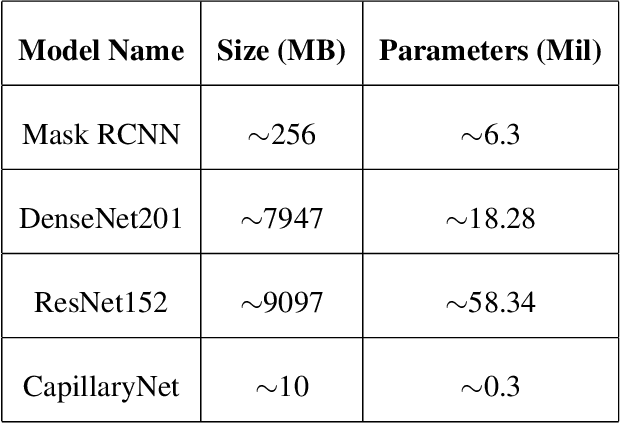
Capillaries are the smallest vessels in the body responsible for the delivery of oxygen and nutrients to the surrounding cells. Various diseases have been shown to alter the density of nutritive capillaries and the flow velocity of erythrocytes. In previous studies, capillary density and flow velocity have been assessed manually by trained specialists. Manual analysis of a 20-second long microvascular video takes on average 20 minutes and requires extensive training. Several studies have reported that manual analysis hinders the application of microvascular microscopy in a clinical setting. In this paper, we present a fully automated system, called CapillaryNet, that can automate microvascular microscopy analysis and thus enable the method to be used not just as a research tool, but also for clinical applications. Our method has been developed by acquiring microcirculation videos from 50 different subjects annotated by trained biomedical researchers. CapillaryNet detects capillaries with an accuracy comparable to trained researchers in less than 0.1% of the time taken by humans and measures several microvascular parameters that researchers were previously unable to quantify, i.e. capillary hematocrit and intra-capillary flow velocity heterogeneity.
An Efficient Asynchronous Method for Integrating Evolutionary and Gradient-based Policy Search
Dec 10, 2020
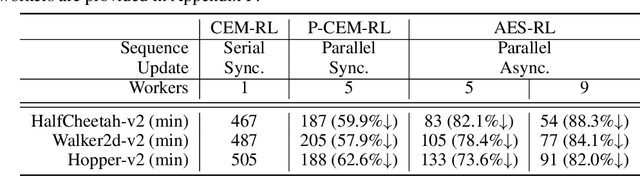
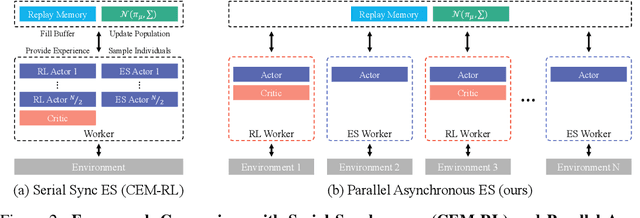

Deep reinforcement learning (DRL) algorithms and evolution strategies (ES) have been applied to various tasks, showing excellent performances. These have the opposite properties, with DRL having good sample efficiency and poor stability, while ES being vice versa. Recently, there have been attempts to combine these algorithms, but these methods fully rely on synchronous update scheme, making it not ideal to maximize the benefits of the parallelism in ES. To solve this challenge, asynchronous update scheme was introduced, which is capable of good time-efficiency and diverse policy exploration. In this paper, we introduce an Asynchronous Evolution Strategy-Reinforcement Learning (AES-RL) that maximizes the parallel efficiency of ES and integrates it with policy gradient methods. Specifically, we propose 1) a novel framework to merge ES and DRL asynchronously and 2) various asynchronous update methods that can take all advantages of asynchronism, ES, and DRL, which are exploration and time efficiency, stability, and sample efficiency, respectively. The proposed framework and update methods are evaluated in continuous control benchmark work, showing superior performance as well as time efficiency compared to the previous methods.
A High GOPs/Slice Time Series Classifier for Portable and Embedded Biomedical Applications
Nov 01, 2018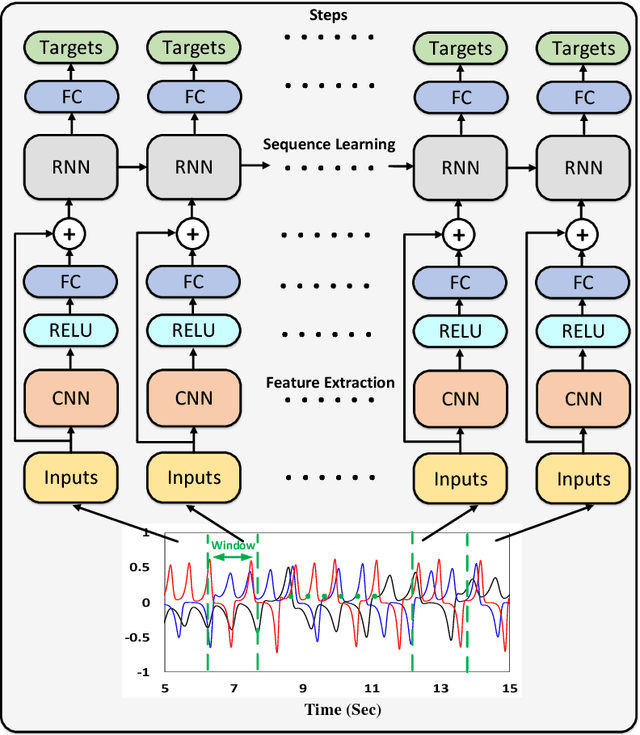

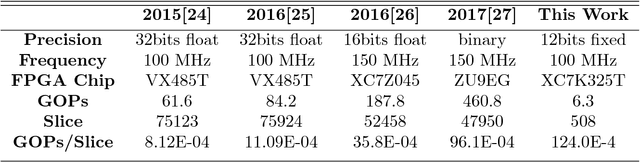
Nowadays a diverse range of physiological data can be captured continuously for various applications in particular wellbeing and healthcare. Such data require efficient methods for classification and analysis. Deep learning algorithms have shown remarkable potential regarding such analyses, however, the use of these algorithms on low-power wearable devices is challenged by resource constraints such as area and power consumption. Most of the available on-chip deep learning processors contain complex and dense hardware architectures in order to achieve the highest possible throughput. Such a trend in hardware design may not be efficient in applications where on-node computation is required and the focus is more on the area and power efficiency as in the case of portable and embedded biomedical devices. This paper presents an efficient time-series classifier capable of automatically detecting effective features and classifying the input signals in real-time. In the proposed classifier, throughput is traded off with hardware complexity and cost using resource sharing techniques. A Convolutional Neural Network (CNN) is employed to extract input features and then a Long-Short-Term-Memory (LSTM) architecture with ternary weight precision classifies the input signals according to the extracted features. Hardware implementation on a Xilinx FPGA confirm that the proposed hardware can accurately classify multiple complex biomedical time series data with low area and power consumption and outperform all previously presented state-of-the-art records. Most notably, our classifier reaches 1.3$\times$ higher GOPs/Slice than similar state of the art FPGA-based accelerators.
Stacked Deep Multi-Scale Hierarchical Network for Fast Bokeh Effect Rendering from a Single Image
May 15, 2021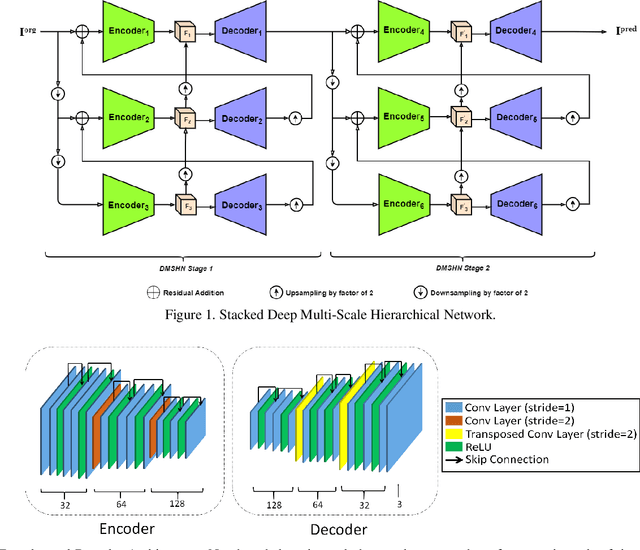
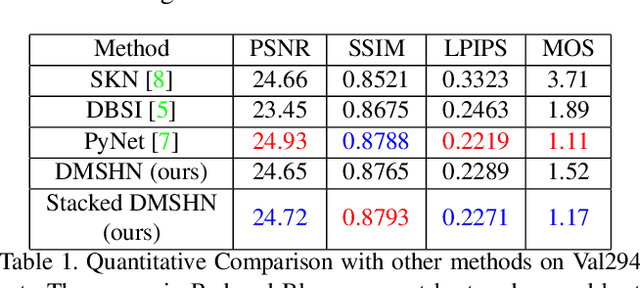
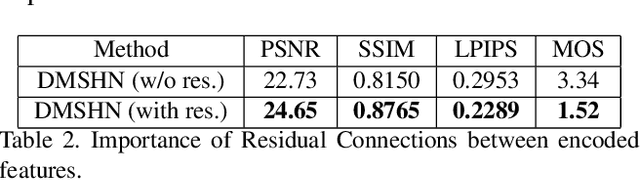

The Bokeh Effect is one of the most desirable effects in photography for rendering artistic and aesthetic photos. Usually, it requires a DSLR camera with different aperture and shutter settings and certain photography skills to generate this effect. In smartphones, computational methods and additional sensors are used to overcome the physical lens and sensor limitations to achieve such effect. Most of the existing methods utilized additional sensor's data or pretrained network for fine depth estimation of the scene and sometimes use portrait segmentation pretrained network module to segment salient objects in the image. Because of these reasons, networks have many parameters, become runtime intensive and unable to run in mid-range devices. In this paper, we used an end-to-end Deep Multi-Scale Hierarchical Network (DMSHN) model for direct Bokeh effect rendering of images captured from the monocular camera. To further improve the perceptual quality of such effect, a stacked model consisting of two DMSHN modules is also proposed. Our model does not rely on any pretrained network module for Monocular Depth Estimation or Saliency Detection, thus significantly reducing the size of model and run time. Stacked DMSHN achieves state-of-the-art results on a large scale EBB! dataset with around 6x less runtime compared to the current state-of-the-art model in processing HD quality images.