 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Character Controllers Using Motion VAEs
Mar 26, 2021

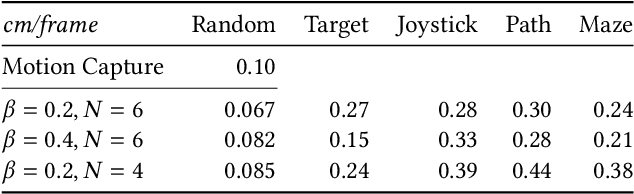
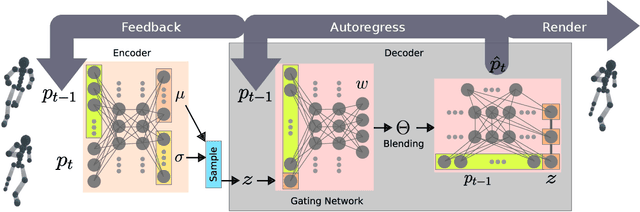
A fundamental problem in computer animation is that of realizing purposeful and realistic human movement given a sufficiently-rich set of motion capture clips. We learn data-driven generative models of human movement using autoregressive conditional variational autoencoders, or Motion VAEs. The latent variables of the learned autoencoder define the action space for the movement and thereby govern its evolution over time. Planning or control algorithms can then use this action space to generate desired motions. In particular, we use deep reinforcement learning to learn controllers that achieve goal-directed movements. We demonstrate the effectiveness of the approach on multiple tasks. We further evaluate system-design choices and describe the current limitations of Motion VAEs.
Implementation of Artificial Neural Networks for the Nepta-Uranian Interplanetary (NUIP) Mission
Mar 19, 2021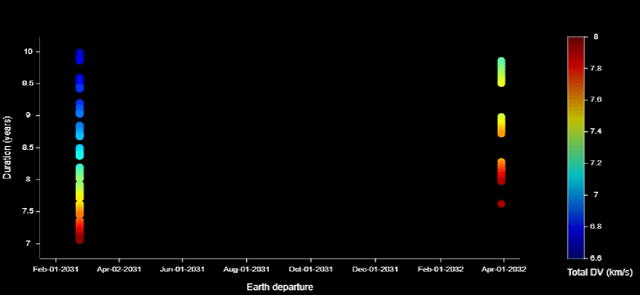

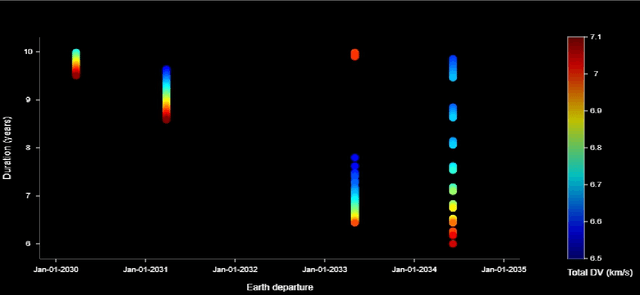
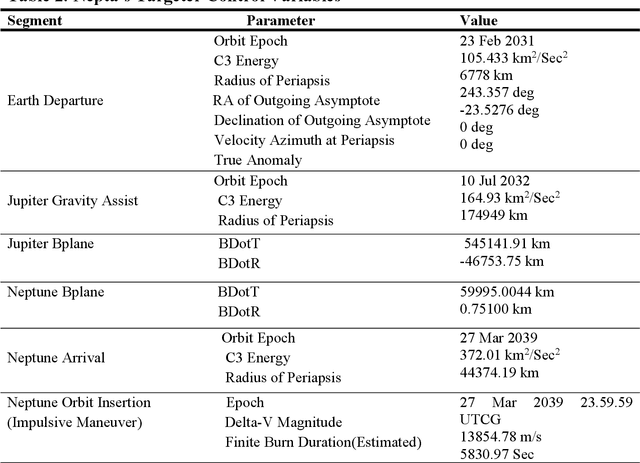
A celestial alignment between Neptune, Uranus, and Jupiter will occur in the early 2030s, allowing a slingshot around Jupiter to gain enough momentum to achieve planetary flyover capability around the two ice giants. The launch of the uranian probe for the departure windows of the NUIP mission is between January 2030 and January 2035, and the duration of the mission is between six and ten years, and the launch of the Nepta probe for the departure windows of the NUIP mission is between February 2031 and April 2032 and the duration of the mission is between seven and ten years. To get the most out of alignment. Deep learning methods are expected to play a critical role in autonomous and intelligent spatial guidance problems. This would reduce travel time, hence mission time, and allow the spacecraft to perform well for the life of its sophisticated instruments and power systems up to fifteen years. This article proposes a design of deep neural networks, namely convolutional neural networks and recurrent neural networks, capable of predicting optimal control actions and image classification during the mission. Nepta-Uranian interplanetary mission, using only raw images taken by optimal onboard cameras. It also describes the unique requirements and constraints of the NUIP mission, which led to the design of the communications system for the Nepta-Uranian spacecraft. The proposed mission is expected to collect telemetry data on Uranus and Neptune while performing the flyovers and transmit the obtained data to Earth for further analysis. The advanced range of spectrometers and particle detectors available would allow better quantification of the ice giant's properties.
Low Complexity Recruitment for Collaborative Mobile Crowdsourcing Using Graph Neural Networks
Jun 01, 2021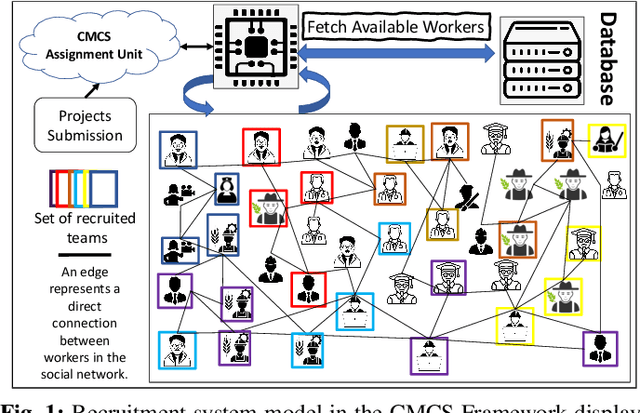
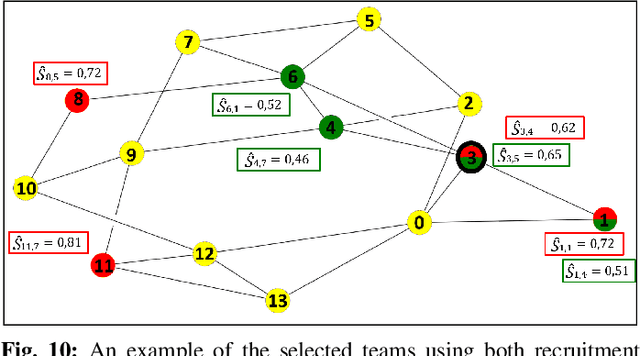
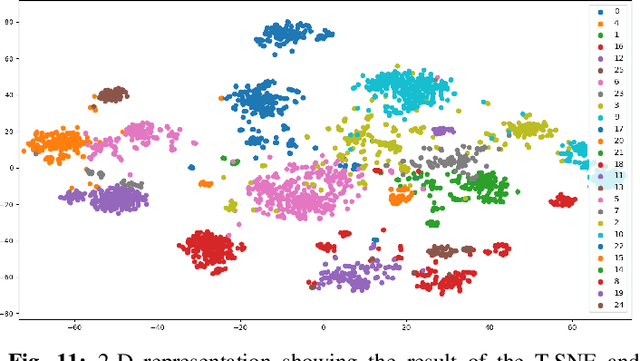
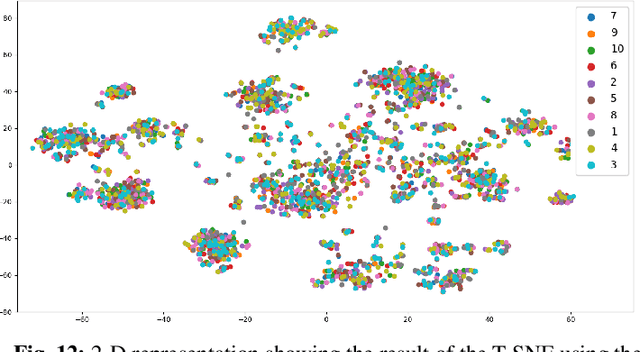
Collaborative Mobile crowdsourcing (CMCS) allows entities, e.g., local authorities or individuals, to hire a team of workers from the crowd of connected people, to execute complex tasks. In this paper, we investigate two different CMCS recruitment strategies allowing task requesters to form teams of socially connected and skilled workers: i) a platform-based strategy where the platform exploits its own knowledge about the workers to form a team and ii) a leader-based strategy where the platform designates a group leader that recruits its own suitable team given its own knowledge about its Social Network (SN) neighbors. We first formulate the recruitment as an Integer Linear Program (ILP) that optimally forms teams according to four fuzzy-logic-based criteria: level of expertise, social relationship strength, recruitment cost, and recruiter's confidence level. To cope with NP-hardness, we design a novel low-complexity CMCS recruitment approach relying on Graph Neural Networks (GNNs), specifically graph embedding and clustering techniques, to shrink the workers' search space and afterwards, exploiting a meta-heuristic genetic algorithm to select appropriate workers. Simulation results applied on a real-world dataset illustrate the performance of both proposed CMCS recruitment approaches. It is shown that our proposed low-complexity GNN-based recruitment algorithm achieves close performances to those of the baseline ILP with significant computational time saving and ability to operate on large-scale mobile crowdsourcing platforms. It is also shown that compared to the leader-based strategy, the platform-based strategy recruits a more skilled team but with lower SN relationships and higher cost.
DeepWORD: A GCN-based Approach for Owner-Member Relationship Detection in Autonomous Driving
Apr 20, 2021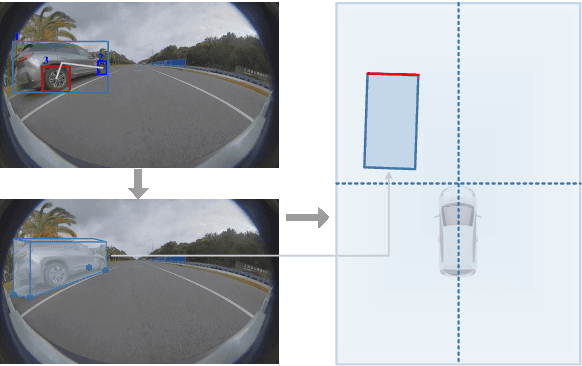
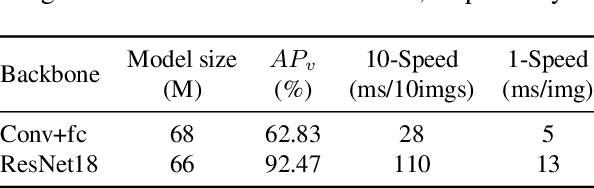

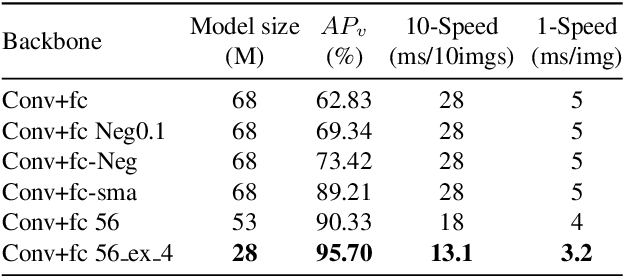
It's worth noting that the owner-member relationship between wheels and vehicles has an significant contribution to the 3D perception of vehicles, especially in the embedded environment. However, there are currently two main challenges about the above relationship prediction: i) The traditional heuristic methods based on IoU can hardly deal with the traffic jam scenarios for the occlusion. ii) It is difficult to establish an efficient applicable solution for the vehicle-mounted system. To address these issues, we propose an innovative relationship prediction method, namely DeepWORD, by designing a graph convolution network (GCN). Specifically, we utilize the feature maps with local correlation as the input of nodes to improve the information richness. Besides, we introduce the graph attention network (GAT) to dynamically amend the prior estimation deviation. Furthermore, we establish an annotated owner-member relationship dataset called WORD as a large-scale benchmark, which will be available soon. The experiments demonstrate that our solution achieves state-of-the-art accuracy and real-time in practice.
Is Input Sparsity Time Possible for Kernel Low-Rank Approximation?
Nov 05, 2017Low-rank approximation is a common tool used to accelerate kernel methods: the $n \times n$ kernel matrix $K$ is approximated via a rank-$k$ matrix $\tilde K$ which can be stored in much less space and processed more quickly. In this work we study the limits of computationally efficient low-rank kernel approximation. We show that for a broad class of kernels, including the popular Gaussian and polynomial kernels, computing a relative error $k$-rank approximation to $K$ is at least as difficult as multiplying the input data matrix $A \in \mathbb{R}^{n \times d}$ by an arbitrary matrix $C \in \mathbb{R}^{d \times k}$. Barring a breakthrough in fast matrix multiplication, when $k$ is not too large, this requires $\Omega(nnz(A)k)$ time where $nnz(A)$ is the number of non-zeros in $A$. This lower bound matches, in many parameter regimes, recent work on subquadratic time algorithms for low-rank approximation of general kernels [MM16,MW17], demonstrating that these algorithms are unlikely to be significantly improved, in particular to $O(nnz(A))$ input sparsity runtimes. At the same time there is hope: we show for the first time that $O(nnz(A))$ time approximation is possible for general radial basis function kernels (e.g., the Gaussian kernel) for the closely related problem of low-rank approximation of the kernelized dataset.
Time series kernel similarities for predicting Paroxysmal Atrial Fibrillation from ECGs
Apr 04, 2018
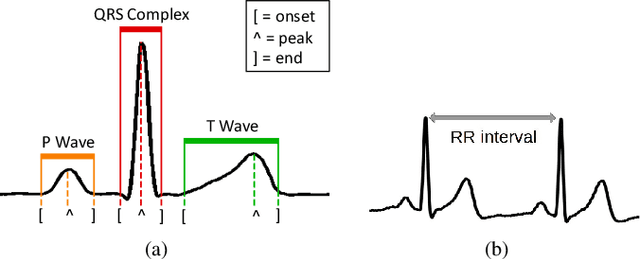
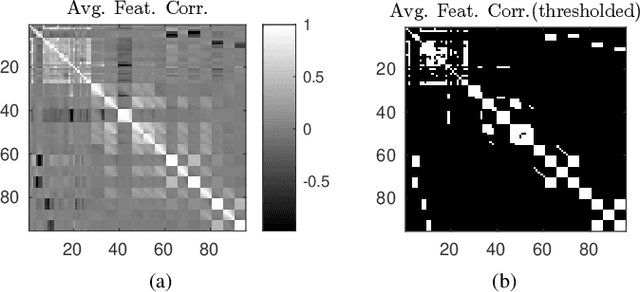
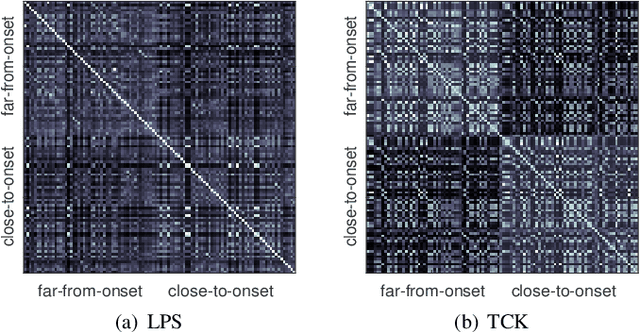
We tackle the problem of classifying Electrocardiography (ECG) signals with the aim of predicting the onset of Paroxysmal Atrial Fibrillation (PAF). Atrial fibrillation is the most common type of arrhythmia, but in many cases PAF episodes are asymptomatic. Therefore, in order to help diagnosing PAF, it is important to design procedures for detecting and, more importantly, predicting PAF episodes. We propose a method for predicting PAF events whose first step consists of a feature extraction procedure that represents each ECG as a multi-variate time series. Successively, we design a classification framework based on kernel similarities for multi-variate time series, capable of handling missing data. We consider different approaches to perform classification in the original space of the multi-variate time series and in an embedding space, defined by the kernel similarity measure. We achieve a classification accuracy comparable with state of the art methods, with the additional advantage of detecting the PAF onset up to 15 minutes in advance.
Adaptable Deformable Convolutions for Semantic Segmentation of Fisheye Images in Autonomous Driving Systems
Feb 19, 2021



Advanced Driver-Assistance Systems rely heavily on perception tasks such as semantic segmentation where images are captured from large field of view (FoV) cameras. State-of-the-art works have made considerable progress toward applying Convolutional Neural Network (CNN) to standard (rectilinear) images. However, the large FoV cameras used in autonomous vehicles produce fisheye images characterized by strong geometric distortion. This work demonstrates that a CNN trained on standard images can be readily adapted to fisheye images, which is crucial in real-world applications where time-consuming real-time data transformation must be avoided. Our adaptation protocol mainly relies on modifying the support of the convolutions by using their deformable equivalents on top of pre-existing layers. We prove that tuning an optimal support only requires a limited amount of labeled fisheye images, as a small number of training samples is sufficient to significantly improve an existing model's performance on wide-angle images. Furthermore, we show that finetuning the weights of the network is not necessary to achieve high performance once the deformable components are learned. Finally, we provide an in-depth analysis of the effect of the deformable convolutions, bringing elements of discussion on the behavior of CNN models.
Multi-modal Sarcasm Detection and Humor Classification in Code-mixed Conversations
May 20, 2021
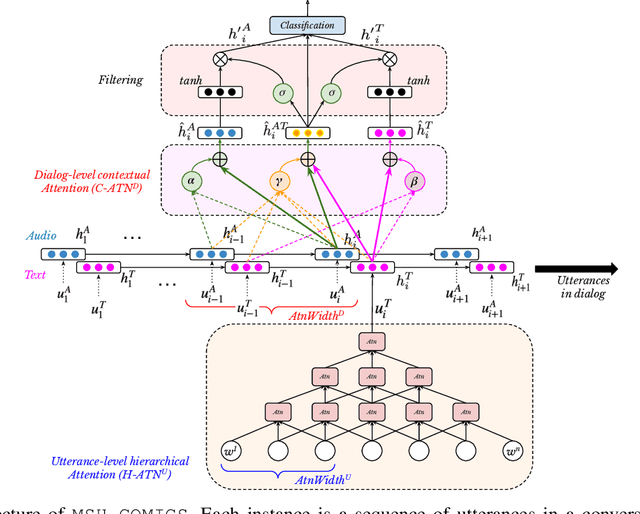


Sarcasm detection and humor classification are inherently subtle problems, primarily due to their dependence on the contextual and non-verbal information. Furthermore, existing studies in these two topics are usually constrained in non-English languages such as Hindi, due to the unavailability of qualitative annotated datasets. In this work, we make two major contributions considering the above limitations: (1) we develop a Hindi-English code-mixed dataset, MaSaC, for the multi-modal sarcasm detection and humor classification in conversational dialog, which to our knowledge is the first dataset of its kind; (2) we propose MSH-COMICS, a novel attention-rich neural architecture for the utterance classification. We learn efficient utterance representation utilizing a hierarchical attention mechanism that attends to a small portion of the input sentence at a time. Further, we incorporate dialog-level contextual attention mechanism to leverage the dialog history for the multi-modal classification. We perform extensive experiments for both the tasks by varying multi-modal inputs and various submodules of MSH-COMICS. We also conduct comparative analysis against existing approaches. We observe that MSH-COMICS attains superior performance over the existing models by > 1 F1-score point for the sarcasm detection and 10 F1-score points in humor classification. We diagnose our model and perform thorough analysis of the results to understand the superiority and pitfalls.
Fast deep learning correspondence for neuron tracking and identification in C.elegans using synthetic training
Jan 20, 2021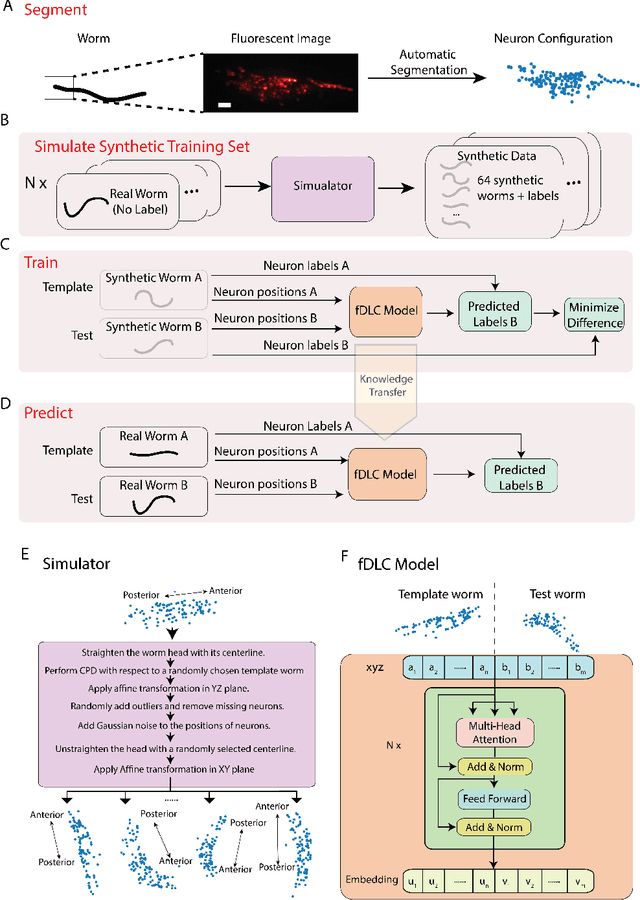
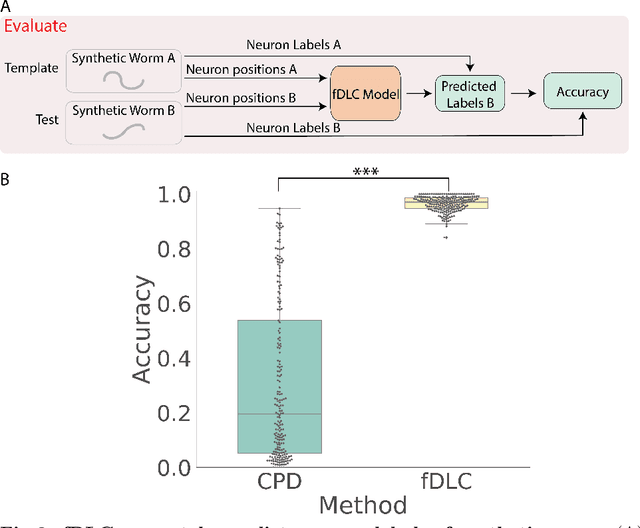
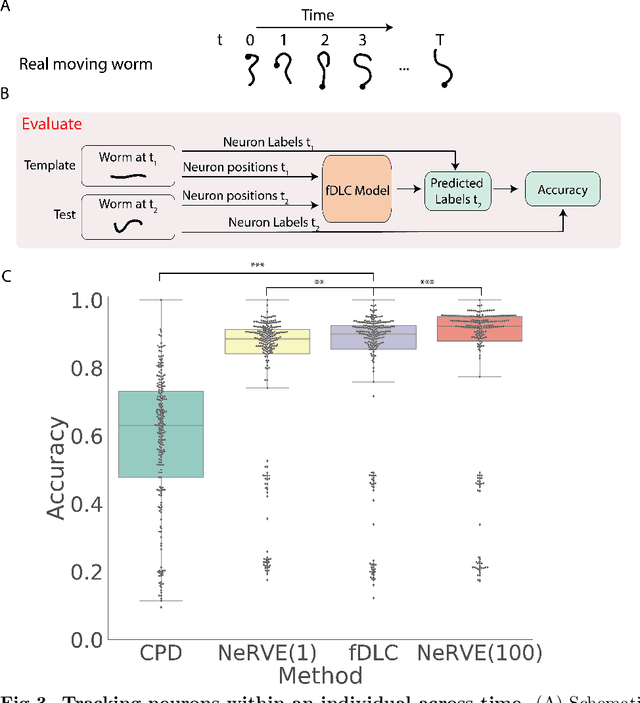
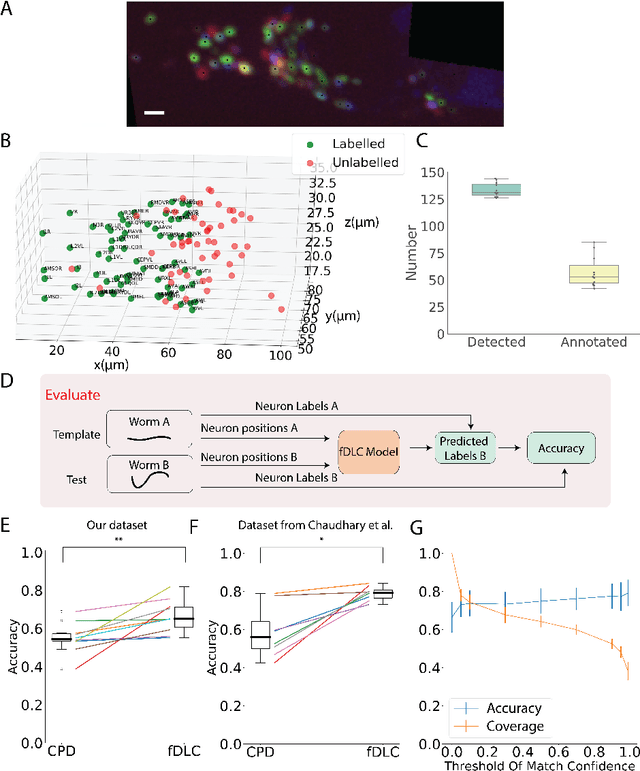
We present an automated method to track and identify neurons in C. elegans, called "fast Deep Learning Correspondence" or fDLC, based on the transformer network architecture. The model is trained once on empirically derived synthetic data and then predicts neural correspondence across held-out real animals via transfer learning. The same pre-trained model both tracks neurons across time and identifies corresponding neurons across individuals. Performance is evaluated against hand-annotated datasets, including NeuroPAL [1]. Using only position information, the method achieves 80.0% accuracy at tracking neurons within an individual and 65.8% accuracy at identifying neurons across individuals. Accuracy is even higher on a published dataset [2]. Accuracy reaches 76.5% when using color information from NeuroPAL. Unlike previous methods, fDLC does not require straightening or transforming the animal into a canonical coordinate system. The method is fast and predicts correspondence in 10 ms making it suitable for future real-time applications.
Continuous Latent Position Models for Instantaneous Interactions
Mar 31, 2021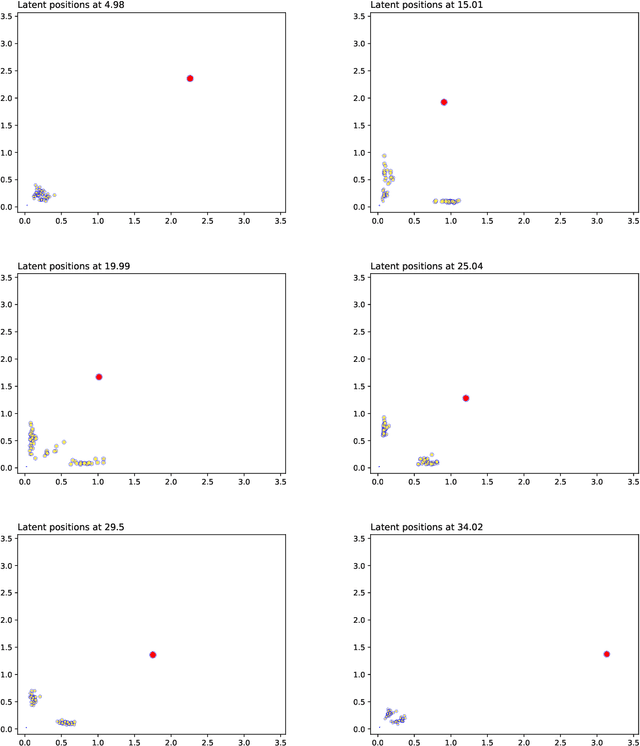
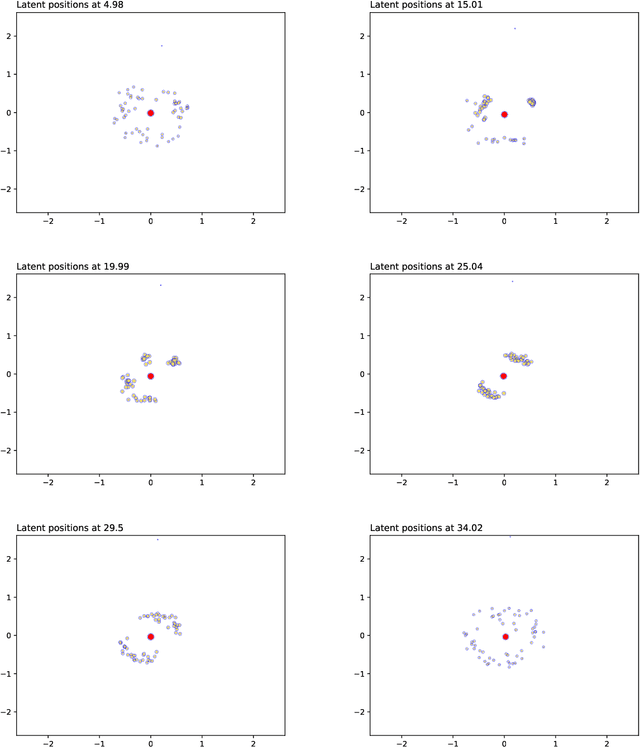
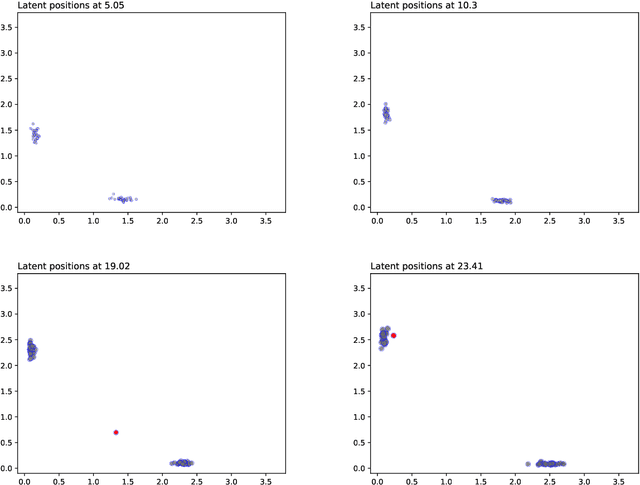
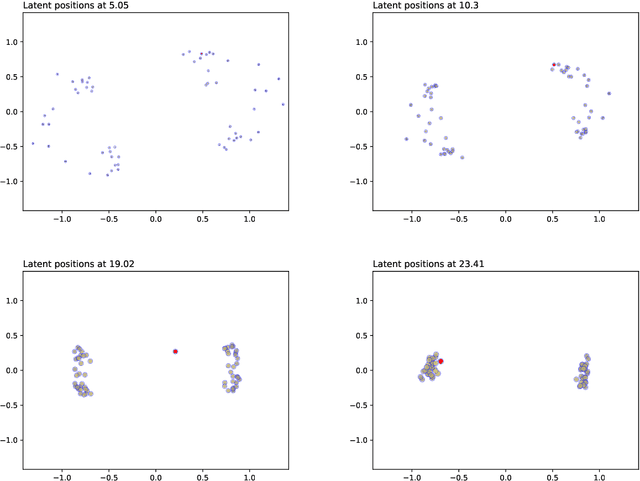
We create a framework to analyse the timing and frequency of instantaneous interactions between pairs of entities. This type of interaction data is especially common nowadays, and easily available. Examples of instantaneous interactions include email networks, phone call networks and some common types of technological and transportation networks. Our framework relies on a novel extension of the latent position network model: we assume that the entities are embedded in a latent Euclidean space, and that they move along individual trajectories which are continuous over time. These trajectories are used to characterize the timing and frequency of the pairwise interactions. We discuss an inferential framework where we estimate the individual trajectories from the observed interaction data, and propose applications on artificial and real data.