 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Prediction : Predicting Stock Price
Oct 19, 2017
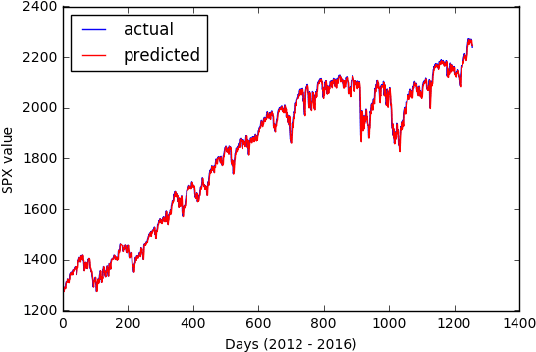
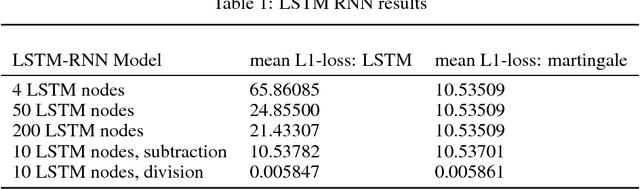
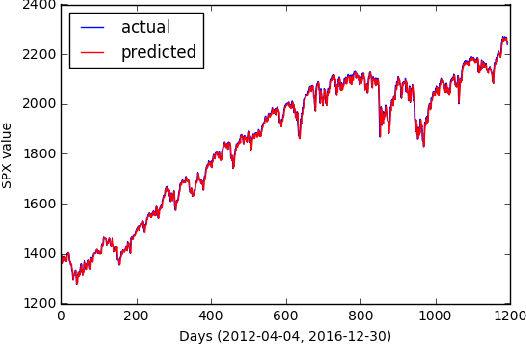
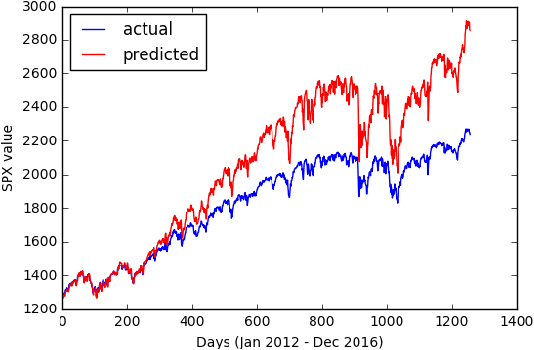
Time series forecasting is widely used in a multitude of domains. In this paper, we present four models to predict the stock price using the SPX index as input time series data. The martingale and ordinary linear models require the strongest assumption in stationarity which we use as baseline models. The generalized linear model requires lesser assumptions but is unable to outperform the martingale. In empirical testing, the RNN model performs the best comparing to other two models, because it will update the input through LSTM instantaneously, but also does not beat the martingale. In addition, we introduce an online to batch algorithm and discrepancy measure to inform readers the newest research in time series predicting method, which doesn't require any stationarity or non mixing assumptions in time series data. Finally, to apply these forecasting to practice, we introduce basic trading strategies that can create Win win and Zero sum situations.
FisheyeMultiNet: Real-time Multi-task Learning Architecture for Surround-view Automated Parking System
Dec 23, 2019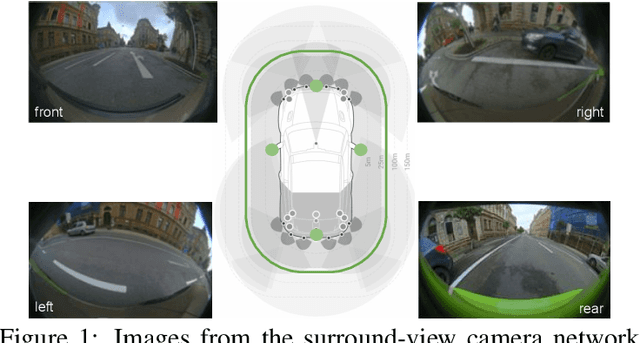
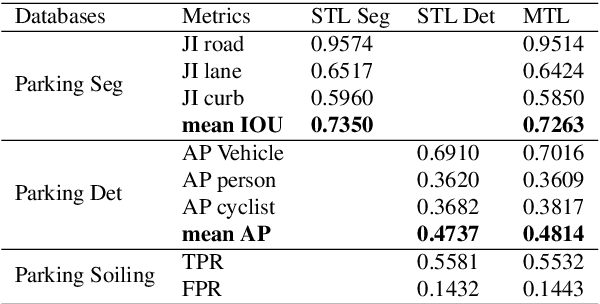
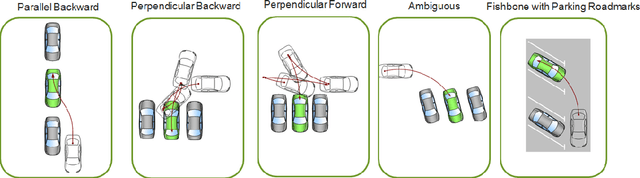
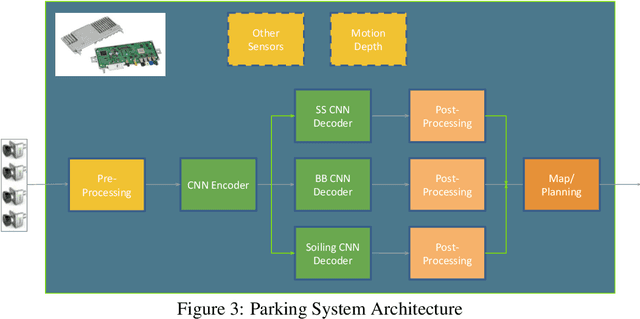
Automated Parking is a low speed manoeuvring scenario which is quite unstructured and complex, requiring full 360{\deg} near-field sensing around the vehicle. In this paper, we discuss the design and implementation of an automated parking system from the perspective of camera based deep learning algorithms. We provide a holistic overview of an industrial system covering the embedded system, use cases and the deep learning architecture. We demonstrate a real-time multi-task deep learning network called FisheyeMultiNet, which detects all the necessary objects for parking on a low-power embedded system. FisheyeMultiNet runs at 15 fps for 4 cameras and it has three tasks namely object detection, semantic segmentation and soiling detection. To encourage further research, we release a partial dataset of 5,000 images containing semantic segmentation and bounding box detection ground truth via WoodScape project \cite{yogamani2019woodscape}.
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
Jan 10, 2020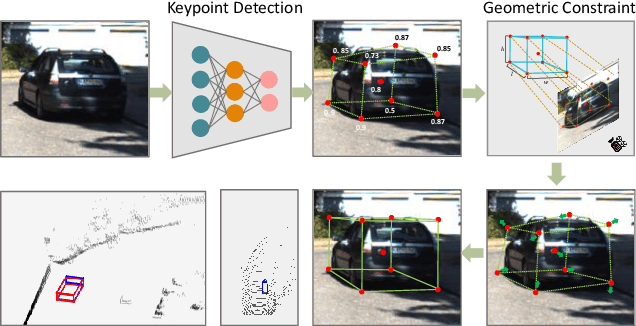
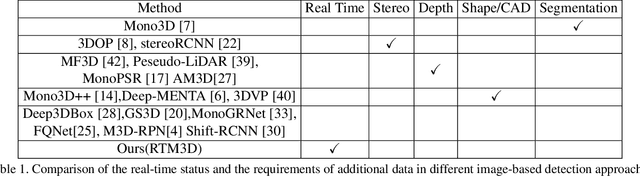
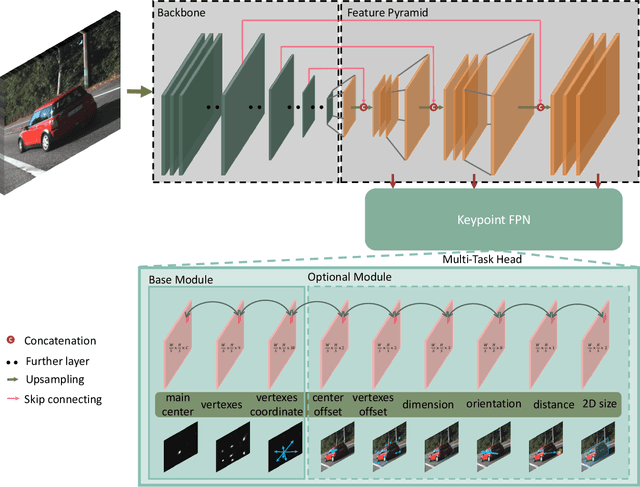
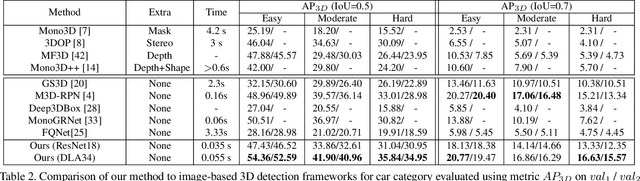
In this work, we propose an efficient and accurate monocular 3D detection framework in single shot. Most successful 3D detectors take the projection constraint from the 3D bounding box to the 2D box as an important component. Four edges of a 2D box provide only four constraints and the performance deteriorates dramatically with the small error of the 2D detector. Different from these approaches, our method predicts the nine perspective keypoints of a 3D bounding box in image space, and then utilize the geometric relationship of 3D and 2D perspectives to recover the dimension, location, and orientation in 3D space. In this method, the properties of the object can be predicted stably even when the estimation of keypoints is very noisy, which enables us to obtain fast detection speed with a small architecture. Training our method only uses the 3D properties of the object without the need for external networks or supervision data. Our method is the first real-time system for monocular image 3D detection while achieves state-of-the-art performance on the KITTI benchmark. Code will be released at https://github.com/Banconxuan/RTM3D.
Adaptive Multi-Resolution Attention with Linear Complexity
Aug 10, 2021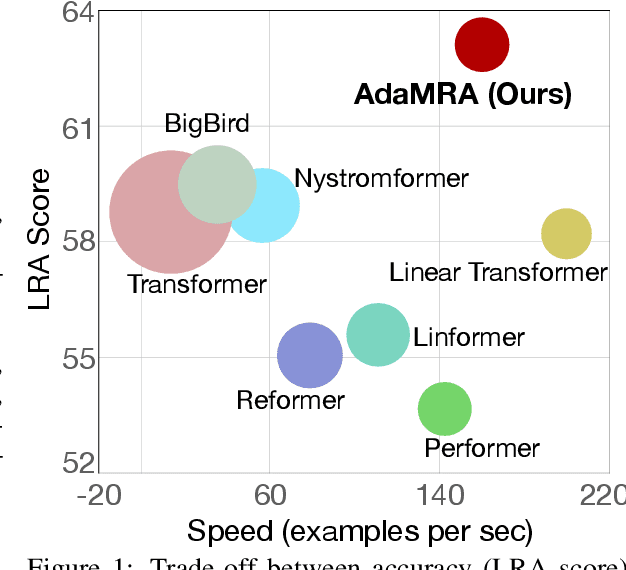
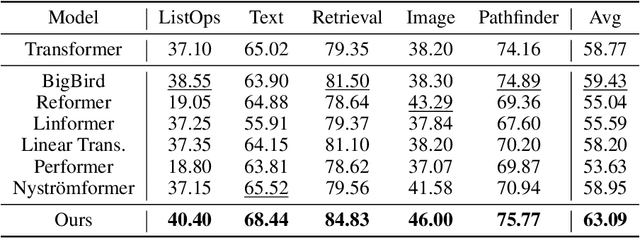
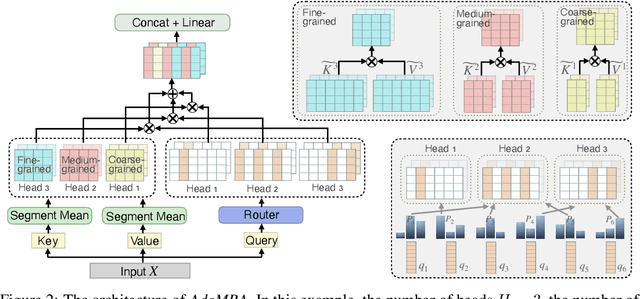
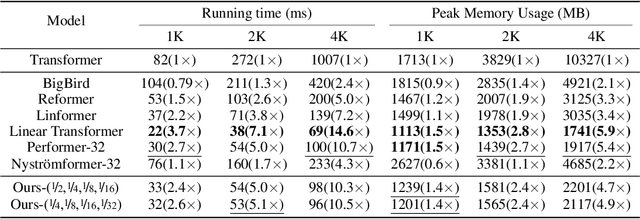
Transformers have improved the state-of-the-art across numerous tasks in sequence modeling. Besides the quadratic computational and memory complexity w.r.t the sequence length, the self-attention mechanism only processes information at the same scale, i.e., all attention heads are in the same resolution, resulting in the limited power of the Transformer. To remedy this, we propose a novel and efficient structure named Adaptive Multi-Resolution Attention (AdaMRA for short), which scales linearly to sequence length in terms of time and space. Specifically, we leverage a multi-resolution multi-head attention mechanism, enabling attention heads to capture long-range contextual information in a coarse-to-fine fashion. Moreover, to capture the potential relations between query representation and clues of different attention granularities, we leave the decision of which resolution of attention to use to query, which further improves the model's capacity compared to vanilla Transformer. In an effort to reduce complexity, we adopt kernel attention without degrading the performance. Extensive experiments on several benchmarks demonstrate the effectiveness and efficiency of our model by achieving a state-of-the-art performance-efficiency-memory trade-off. To facilitate AdaMRA utilization by the scientific community, the code implementation will be made publicly available.
Patch Attack Invariance: How Sensitive are Patch Attacks to 3D Pose?
Aug 16, 2021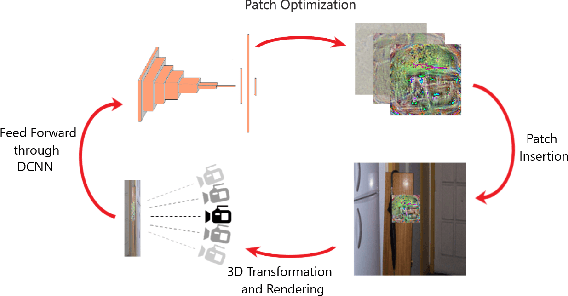
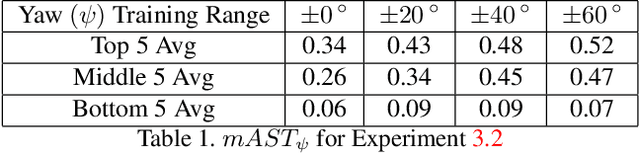

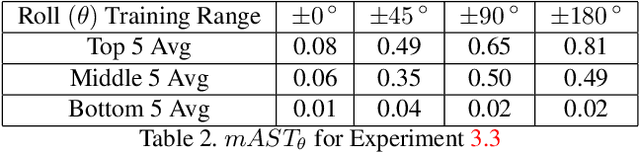
Perturbation-based attacks, while not physically realizable, have been the main emphasis of adversarial machine learning (ML) research. Patch-based attacks by contrast are physically realizable, yet most work has focused on 2D domain with recent forays into 3D. Characterizing the robustness properties of patch attacks and their invariance to 3D pose is important, yet not fully elucidated, and is the focus of this paper. To this end, several contributions are made here: A) we develop a new metric called mean Attack Success over Transformations (mAST) to evaluate patch attack robustness and invariance; and B), we systematically assess robustness of patch attacks to 3D position and orientation for various conditions; in particular, we conduct a sensitivity analysis which provides important qualitative insights into attack effectiveness as a function of the 3D pose of a patch relative to the camera (rotation, translation) and sets forth some properties for patch attack 3D invariance; and C), we draw novel qualitative conclusions including: 1) we demonstrate that for some 3D transformations, namely rotation and loom, increasing the training distribution support yields an increase in patch success over the full range at test time. 2) We provide new insights into the existence of a fundamental cutoff limit in patch attack effectiveness that depends on the extent of out-of-plane rotation angles. These findings should collectively guide future design of 3D patch attacks and defenses.
Explainable Failure Predictions with RNN Classifiers based on Time Series Data
Jan 20, 2019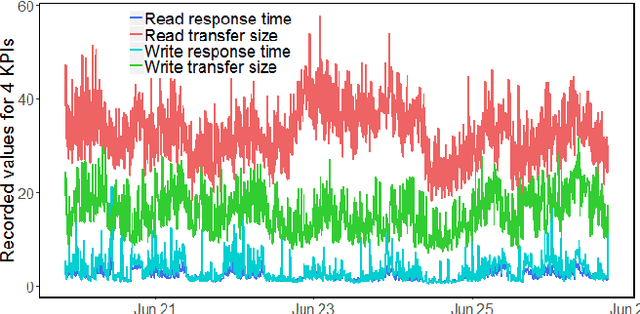
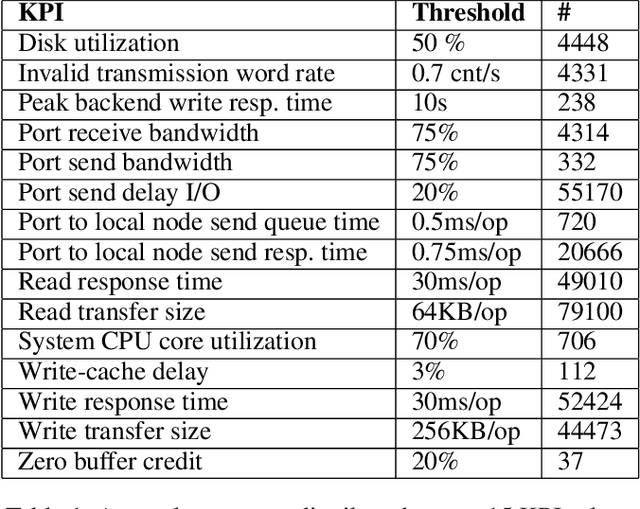
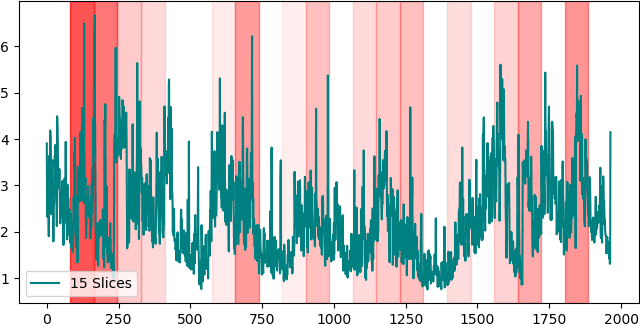
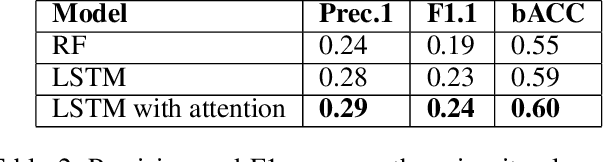
Given key performance indicators collected with fine granularity as time series, our aim is to predict and explain failures in storage environments. Although explainable predictive modeling based on spiky telemetry data is key in many domains, current approaches cannot tackle this problem. Deep learning methods suitable for sequence modeling and learning temporal dependencies, such as RNNs, are effective, but opaque from an explainability perspective. Our approach first extracts the anomalous spikes from time series as events and then builds an RNN classifier with attention mechanisms to embed the irregularity and frequency of these events. A preliminary evaluation on real world storage environments shows that our approach can predict failures within a 3-day prediction window with comparable accuracy as traditional RNN-based classifiers. At the same time it can explain the predictions by returning the key anomalous events which led to those failure predictions.
A Brief Review of Machine Learning Techniques for Protein Phosphorylation Sites Prediction
Aug 10, 2021
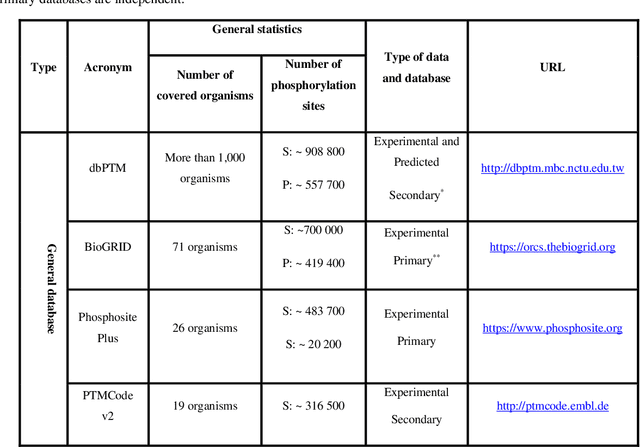
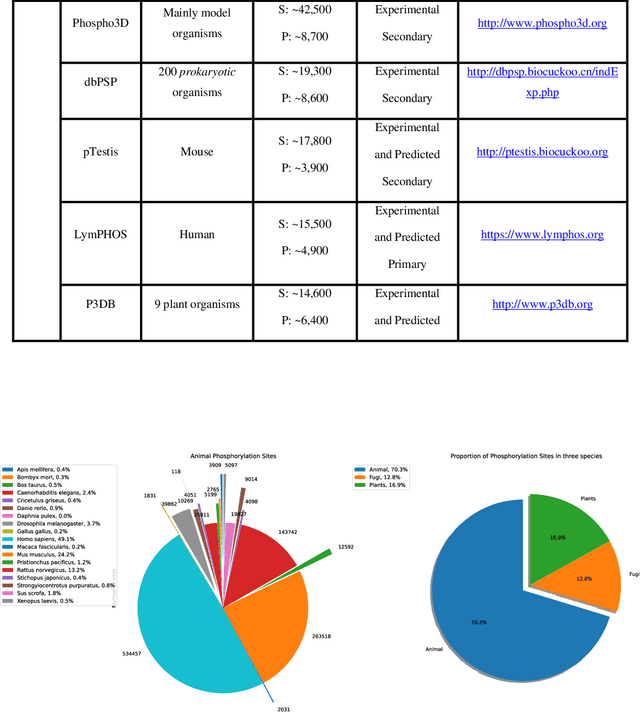
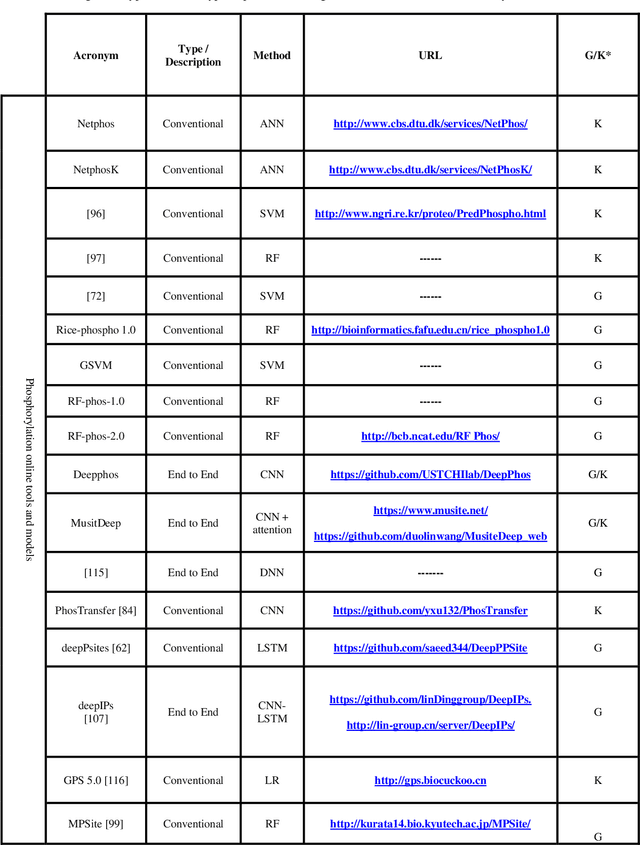
Reversible Post-Translational Modifications (PTMs) have vital roles in extending the functional diversity of proteins and effect meaningfully the regulation of protein functions in prokaryotic and eukaryotic organisms. PTMs have happened as crucial molecular regulatory mechanisms that are utilized to regulate diverse cellular processes. Nevertheless, among the most well-studied PTMs can say mainly types of proteins are containing phosphorylation and significant roles in many biological processes. Disorder in this modification can be caused by multiple diseases including neurological disorders and cancers. Therefore, it is necessary to predict the phosphorylation of target residues in an uncharacterized amino acid sequence. Most experimental techniques for predicting phosphorylation are time-consuming, costly, and error-prone. By the way, computational methods have replaced these techniques. These days, a vast amount of phosphorylation data is publicly accessible through many online databases. In this study, at first, all datasets of PTMs that include phosphorylation sites (p-sites) were comprehensively reviewed. Furthermore, we showed that there are basically two main approaches for phosphorylation prediction by machine learning: End-to-End and conventional. We gave an overview for both of them. Also, we introduced 15 important feature extraction techniques which mostly have been used for conventional machine learning methods
The Horn Non-Clausal Class and its Polynomiality
Aug 31, 2021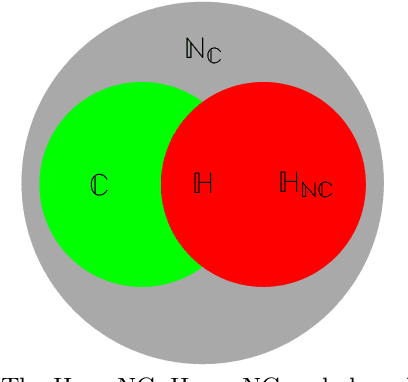
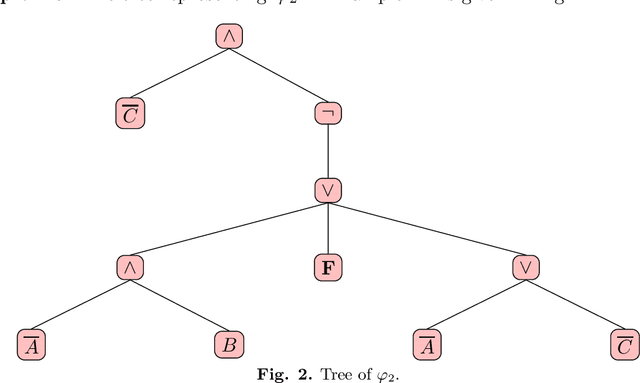
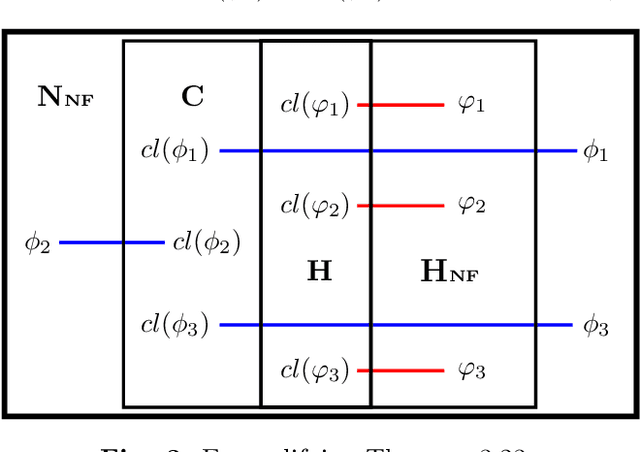
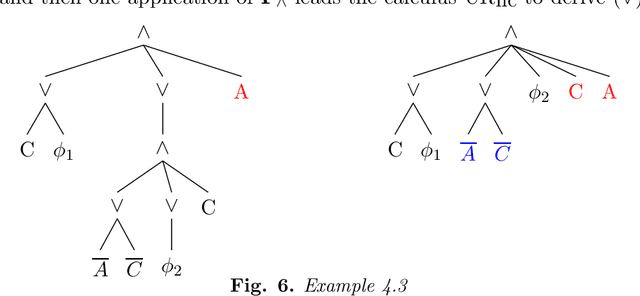
The expressiveness of propositional non-clausal (NC) formulas is exponentially richer than that of clausal formulas. Yet, clausal efficiency outperforms non-clausal one. Indeed, a major weakness of the latter is that, while Horn clausal formulas, along with Horn algorithms, are crucial for the high efficiency of clausal reasoning, no Horn-like formulas in non-clausal form had been proposed. To overcome such weakness, we define the hybrid class $\mathbb{H_{NC}}$ of Horn Non-Clausal (Horn-NC) formulas, by adequately lifting the Horn pattern to NC form, and argue that $\mathbb{H_{NC}}$, along with future Horn-NC algorithms, shall increase non-clausal efficiency just as the Horn class has increased clausal efficiency. Secondly, we: (i) give the compact, inductive definition of $\mathbb{H_{NC}}$; (ii) prove that syntactically $\mathbb{H_{NC}}$ subsumes the Horn class but semantically both classes are equivalent, and (iii) characterize the non-clausal formulas belonging to $\mathbb{H_{NC}}$. Thirdly, we define the Non-Clausal Unit-Resolution calculus, $UR_{NC}$, and prove that it checks the satisfiability of $\mathbb{H_{NC}}$ in polynomial time. This fact, to our knowledge, makes $\mathbb{H_{NC}}$ the first characterized polynomial class in NC reasoning. Finally, we prove that $\mathbb{H_{NC}}$ is linearly recognizable, and also that it is both strictly succincter and exponentially richer than the Horn class. We discuss that in NC automated reasoning, e.g. satisfiability solving, theorem proving, logic programming, etc., can directly benefit from $\mathbb{H_{NC}}$ and $UR_{NC}$ and that, as a by-product of its proved properties, $\mathbb{H_{NC}}$ arises as a new alternative to analyze Horn functions and implication systems.
Advanced Hough-based method for on-device document localization
Jun 18, 2021
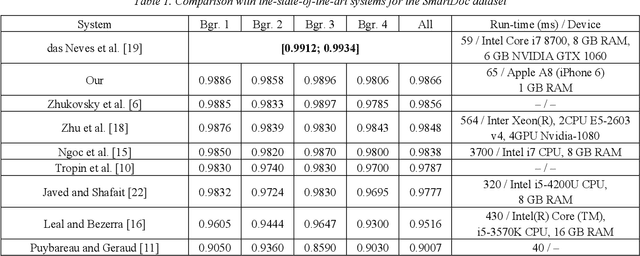
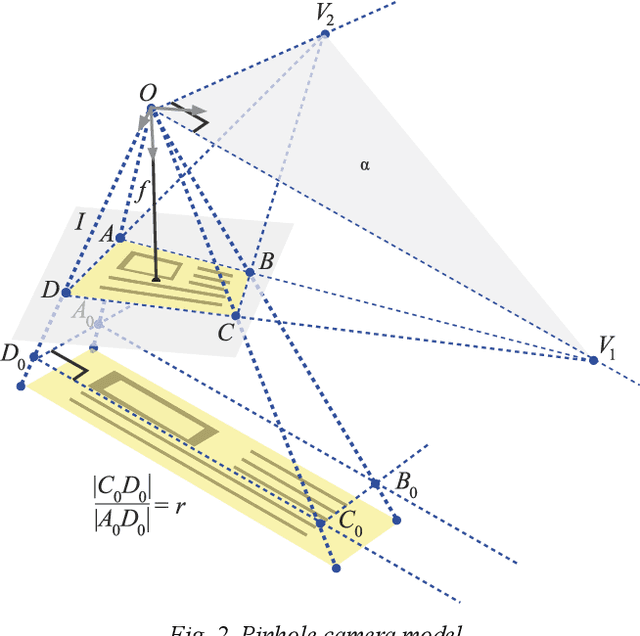

The demand for on-device document recognition systems increases in conjunction with the emergence of more strict privacy and security requirements. In such systems, there is no data transfer from the end device to a third-party information processing servers. The response time is vital to the user experience of on-device document recognition. Combined with the unavailability of discrete GPUs, powerful CPUs, or a large RAM capacity on consumer-grade end devices such as smartphones, the time limitations put significant constraints on the computational complexity of the applied algorithms for on-device execution. In this work, we consider document location in an image without prior knowledge of the document content or its internal structure. In accordance with the published works, at least 5 systems offer solutions for on-device document location. All these systems use a location method which can be considered Hough-based. The precision of such systems seems to be lower than that of the state-of-the-art solutions which were not designed to account for the limited computational resources. We propose an advanced Hough-based method. In contrast with other approaches, it accounts for the geometric invariants of the central projection model and combines both edge and color features for document boundary detection. The proposed method allowed for the second best result for SmartDoc dataset in terms of precision, surpassed by U-net like neural network. When evaluated on a more challenging MIDV-500 dataset, the proposed algorithm guaranteed the best precision compared to published methods. Our method retained the applicability to on-device computations.
On the Enabling of Multi-user Communications with Reconfigurable Intelligent Surfaces
Jun 12, 2021
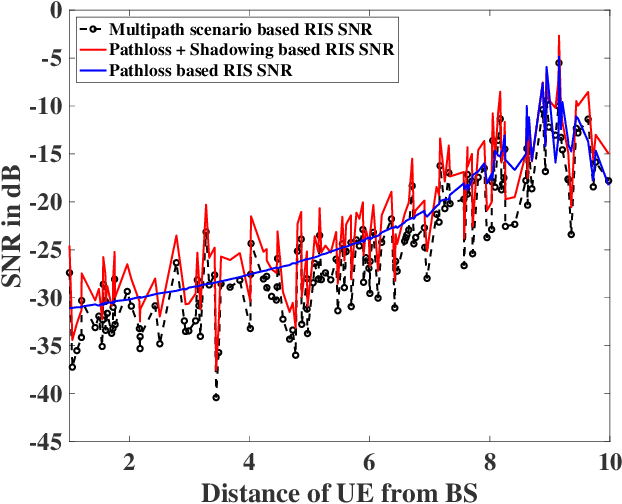
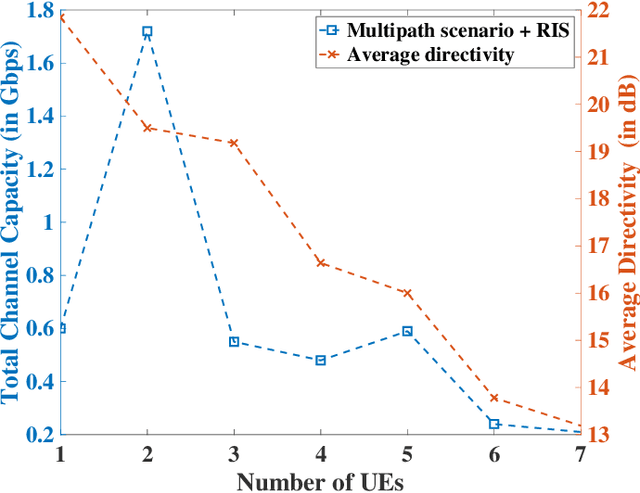
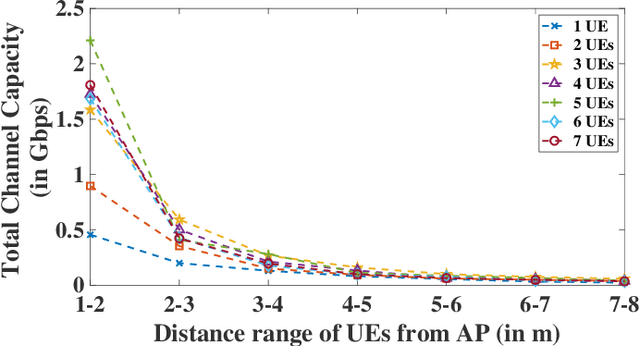
Reconfigurable Intelligent Surface (RIS) composed of programmable actuators is a promising technology, thanks to its capability in manipulating Electromagnetic (EM) wavefronts. In particular, RISs have the potential to provide significant performance improvements for wireless networks. However, to do so, a proper configuration of the reflection coefficients of the unit cells in the RIS is required. RISs are sophisticated platforms so the design and fabrication complexity might be uneconomical for single-user scenarios while a RIS that can service multi-users justifies the costs. For the first time, we propose an efficient reconfiguration technique providing the multi-beam radiation pattern. Thanks to the analytical model the reconfiguration profile is at hand compared to time-consuming optimization techniques. The outcome can pave the wave for commercial use of multi-user communication beyond 5G networks. We analyze the performance of our proposed RIS technology for indoor and outdoor scenarios, given the broadcast mode of operation. The aforesaid scenarios encompass some of the most challenging scenarios that wireless networks encounter. We show that our proposed technique provisions sufficient gains in the observed channel capacity when the users are close to the RIS in the indoor office environment scenario. Further, we report more than one order of magnitude increase in the system throughput given the outdoor environment. The results prove that RIS with the ability to communicate with multiple users can empower wireless networks with great capacity.