 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multi-task Graph Convolutional Neural Network for Calcification Morphology and Distribution Analysis in Mammograms
May 14, 2021
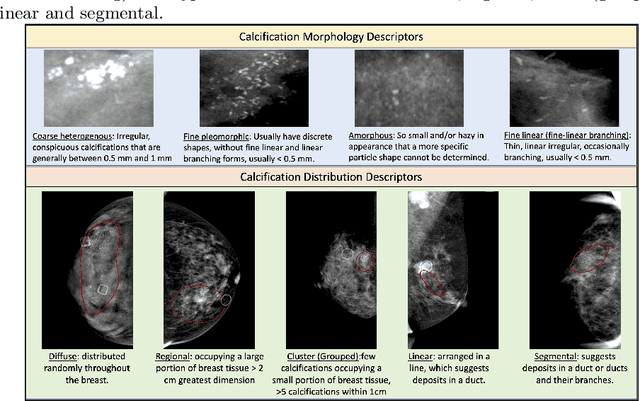
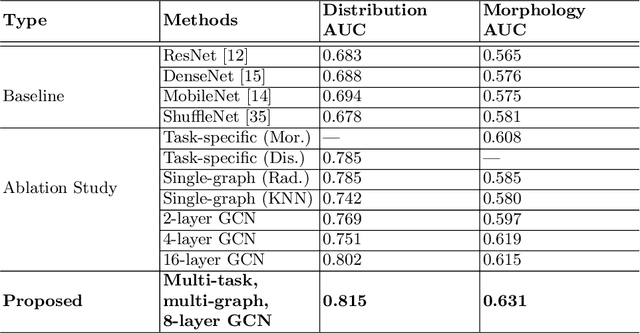
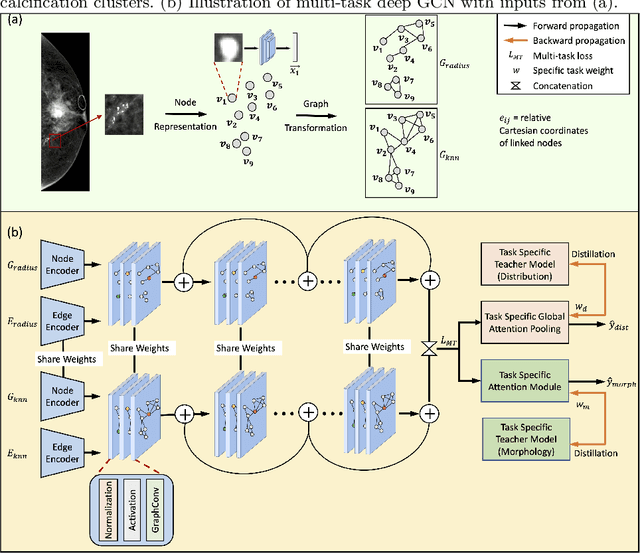
The morphology and distribution of microcalcifications in a cluster are the most important characteristics for radiologists to diagnose breast cancer. However, it is time-consuming and difficult for radiologists to identify these characteristics, and there also lacks of effective solutions for automatic characterization. In this study, we proposed a multi-task deep graph convolutional network (GCN) method for the automatic characterization of morphology and distribution of microcalcifications in mammograms. Our proposed method transforms morphology and distribution characterization into node and graph classification problem and learns the representations concurrently. Through extensive experiments, we demonstrate significant improvements with the proposed multi-task GCN comparing to the baselines. Moreover, the achieved improvements can be related to and enhance clinical understandings. We explore, for the first time, the application of GCNs in microcalcification characterization that suggests the potential of graph learning for more robust understanding of medical images.
Unsupervised Depth Completion with Calibrated Backprojection Layers
Aug 24, 2021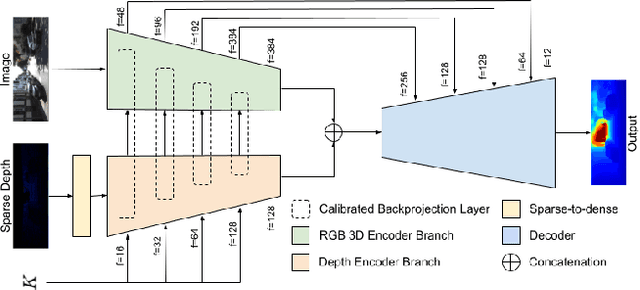

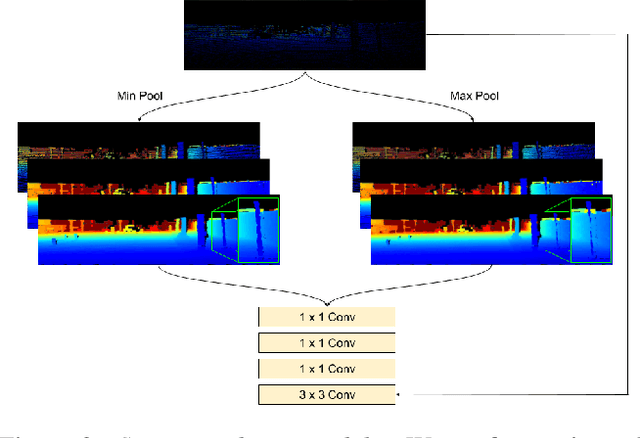
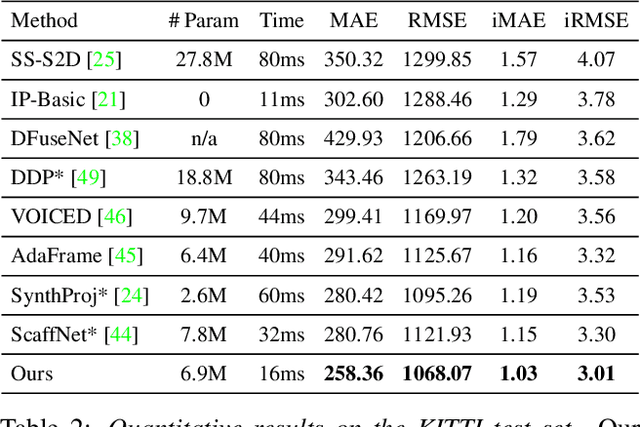
We propose a deep neural network architecture to infer dense depth from an image and a sparse point cloud. It is trained using a video stream and corresponding synchronized sparse point cloud, as obtained from a LIDAR or other range sensor, along with the intrinsic calibration parameters of the camera. At inference time, the calibration of the camera, which can be different than the one used for training, is fed as an input to the network along with the sparse point cloud and a single image. A Calibrated Backprojection Layer backprojects each pixel in the image to three-dimensional space using the calibration matrix and a depth feature descriptor. The resulting 3D positional encoding is concatenated with the image descriptor and the previous layer output to yield the input to the next layer of the encoder. A decoder, exploiting skip-connections, produces a dense depth map. The resulting Calibrated Backprojection Network, or KBNet, is trained without supervision by minimizing the photometric reprojection error. KBNet imputes missing depth value based on the training set, rather than on generic regularization. We test KBNet on public depth completion benchmarks, where it outperforms the state of the art by 30% indoor and 8% outdoor when the same camera is used for training and testing. When the test camera is different, the improvement reaches 62%. Code available at: https://github.com/alexklwong/calibrated-backprojection-network.
Temporal-Spatial Feature Pyramid for Video Saliency Detection
May 10, 2021
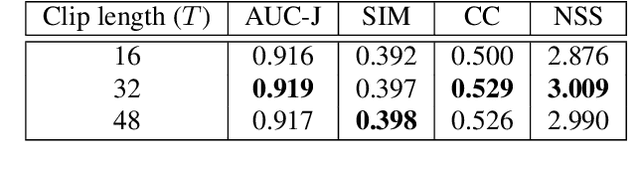
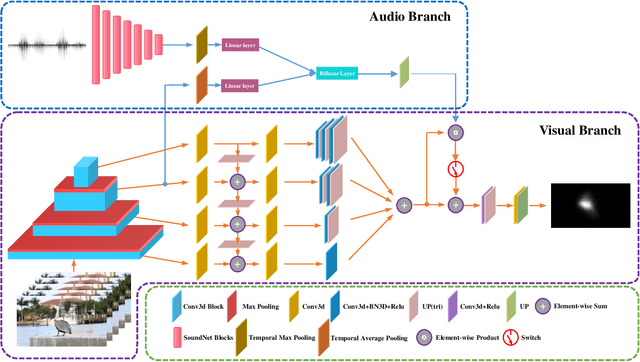
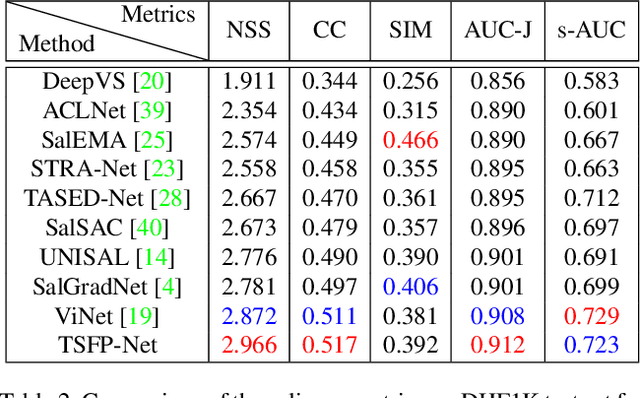
In this paper, we propose a 3D fully convolutional encoder-decoder architecture for video saliency detection, which combines scale, space and time information for video saliency modeling. The encoder extracts multi-scale temporal-spatial features from the input continuous video frames, and then constructs temporal-spatial feature pyramid through temporal-spatial convolution and top-down feature integration. The decoder performs hierarchical decoding of temporal-spatial features from different scales, and finally produces a saliency map from the integration of multiple video frames. Our model is simple yet effective, and can run in real time. We perform abundant experiments, and the results indicate that the well-designed structure can improve the precision of video saliency detection significantly. Experimental results on three purely visual video saliency benchmarks and six audio-video saliency benchmarks demonstrate that our method achieves state-of-theart performance.
Finite-Time Analysis of Q-Learning with Linear Function Approximation
May 27, 2019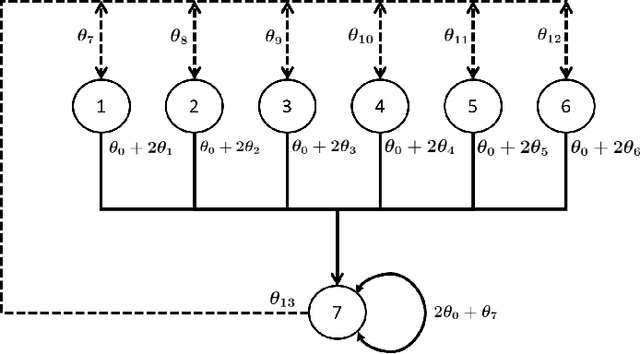
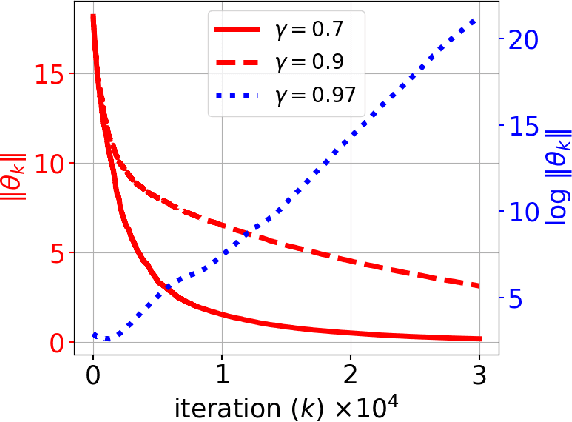
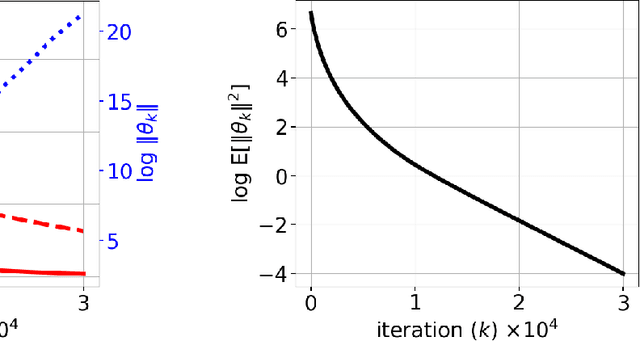
In this paper, we consider the model-free reinforcement learning problem and study the popular Q-learning algorithm with linear function approximation for finding the optimal policy. Despite its popularity, it is known that Q-learning with linear function approximation may diverge in general due to off-policy sampling. Our main contribution is to provide a finite-time bound for the performance of Q-learning with linear function approximation with constant step size under an assumption on the sampling policy. Unlike some prior work in the literature, we do not need to make the unnatural assumption that the samples are i.i.d. (since they are Markovian), and do not require an additional projection step in the algorithm. To show this result, we first consider a more general nonlinear stochastic approximation algorithm with Markovian noise, and derive a finite-time bound on the mean-square error, which we believe is of independent interest. Our proof is based on Lyapunov drift arguments and exploits the geometric mixing of the underlying Markov chain. We also provide numerical simulations to illustrate the effectiveness of our assumption on the sampling policy, and demonstrate the rate of convergence of Q-learning.
Airplane Type Identification Based on Mask RCNN and Drone Images
Aug 29, 2021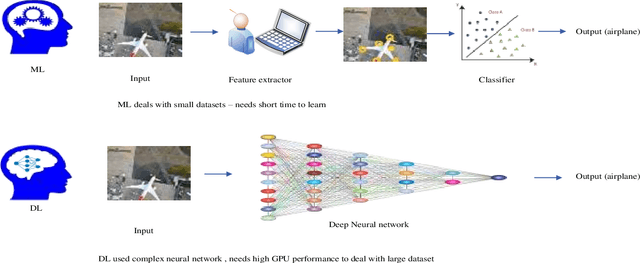
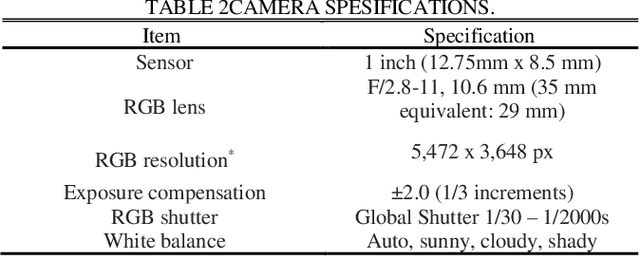
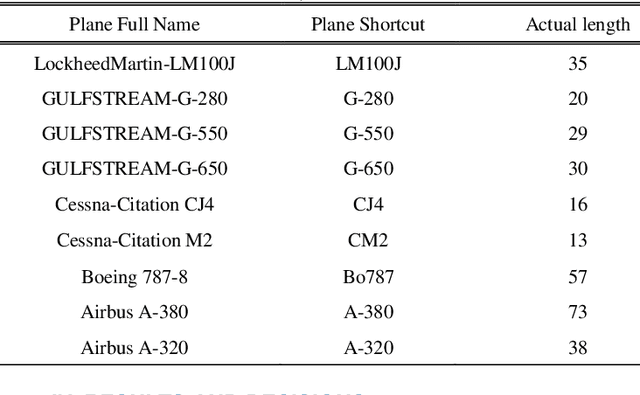
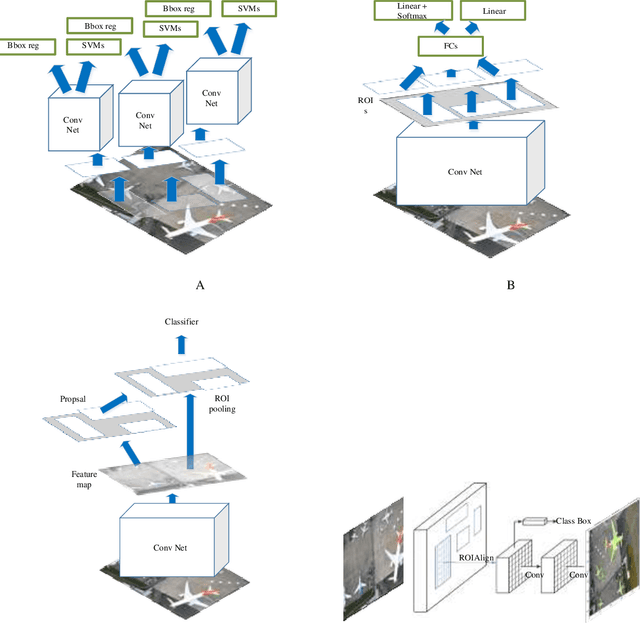
For dealing with traffic bottlenecks at airports, aircraft object detection is insufficient. Every airport generally has a variety of planes with various physical and technological requirements as well as diverse service requirements. Detecting the presence of new planes will not address all traffic congestion issues. Identifying the type of airplane, on the other hand, will entirely fix the problem because it will offer important information about the plane's technical specifications (i.e., the time it needs to be served and its appropriate place in the airport). Several studies have provided various contributions to address airport traffic jams; however, their ultimate goal was to determine the existence of airplane objects. This paper provides a practical approach to identify the type of airplane in airports depending on the results provided by the airplane detection process using mask region convolution neural network. The key feature employed to identify the type of airplane is the surface area calculated based on the results of airplane detection. The surface area is used to assess the estimated cabin length which is considered as an additional key feature for identifying the airplane type. The length of any detected plane may be calculated by measuring the distance between the detected plane's two furthest points. The suggested approach's performance is assessed using average accuracies and a confusion matrix. The findings show that this method is dependable. This method will greatly aid in the management of airport traffic congestion.
Adaptive PCA for Time-Varying Data
Sep 12, 2017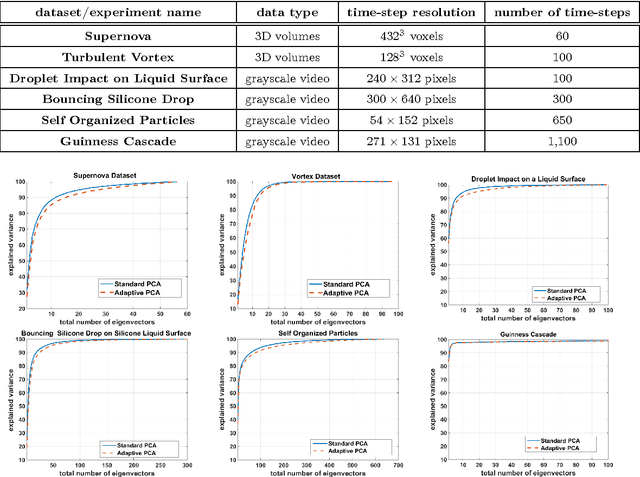
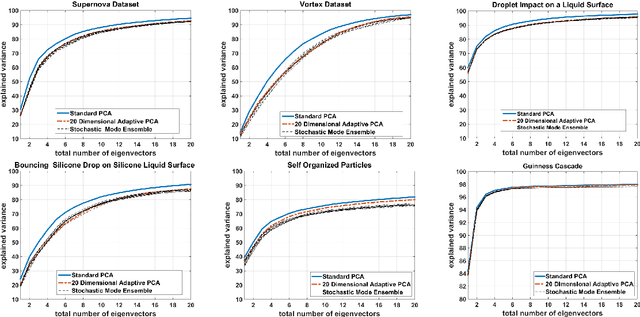
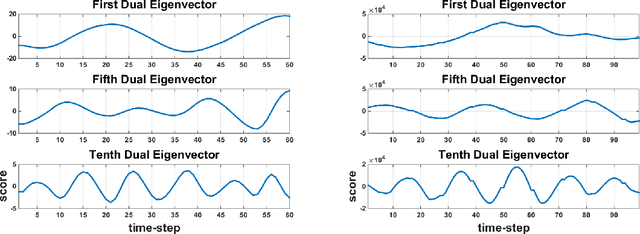
In this paper, we present an online adaptive PCA algorithm that is able to compute the full dimensional eigenspace per new time-step of sequential data. The algorithm is based on a one-step update rule that considers all second order correlations between previous samples and the new time-step. Our algorithm has O(n) complexity per new time-step in its deterministic mode and O(1) complexity per new time-step in its stochastic mode. We test our algorithm on a number of time-varying datasets of different physical phenomena. Explained variance curves indicate that our technique provides an excellent approximation to the original eigenspace computed using standard PCA in batch mode. In addition, our experiments show that the stochastic mode, despite its much lower computational complexity, converges to the same eigenspace computed using the deterministic mode.
Joint estimation of multiple Granger causal networks: Inference of group-level brain connectivity
May 15, 2021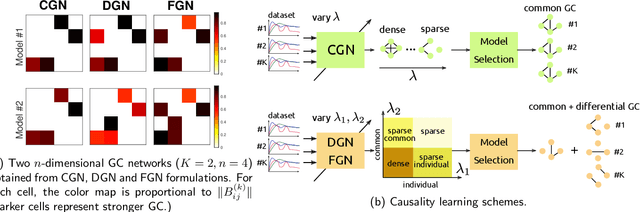
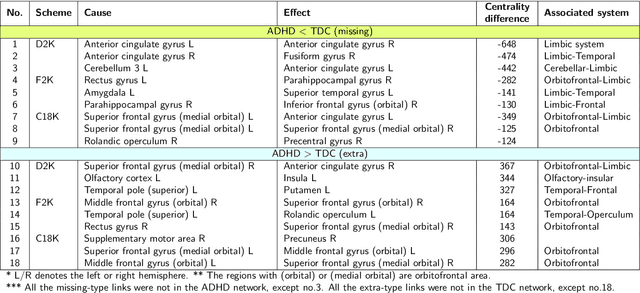
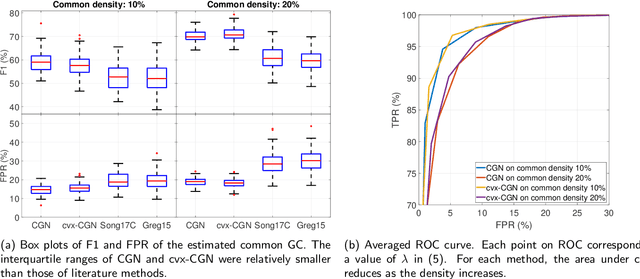
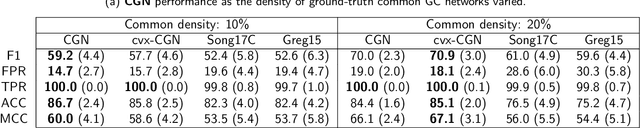
This paper considers joint learning of multiple sparse Granger graphical models to discover underlying common and differential Granger causality (GC) structures across multiple time series. This can be applied to drawing group-level brain connectivity inferences from a homogeneous group of subjects or discovering network differences among groups of signals collected under heterogeneous conditions. By recognizing that the GC of a single multivariate time series can be characterized by common zeros of vector autoregressive (VAR) lag coefficients, a group sparse prior is included in joint regularized least-squares estimations of multiple VAR models. Group-norm regularizations based on group- and fused-lasso penalties encourage a decomposition of multiple networks into a common GC structure, with other remaining parts defined in individual-specific networks. Prior information about sparseness and sparsity patterns of desired GC networks are incorporated as relative weights, while a non-convex group norm in the penalty is proposed to enhance the accuracy of network estimation in low-sample settings. Extensive numerical results on simulations illustrated our method's improvements over existing sparse estimation approaches on GC network sparsity recovery. Our methods were also applied to available resting-state fMRI time series from the ADHD-200 data sets to learn the differences of causality mechanisms, called effective brain connectivity, between adolescents with ADHD and typically developing children. Our analysis revealed that parts of the causality differences between the two groups often resided in the orbitofrontal region and areas associated with the limbic system, which agreed with clinical findings and data-driven results in previous studies.
A New State-of-the-Art Transformers-Based Load Forecaster on the Smart Grid Domain
Aug 05, 2021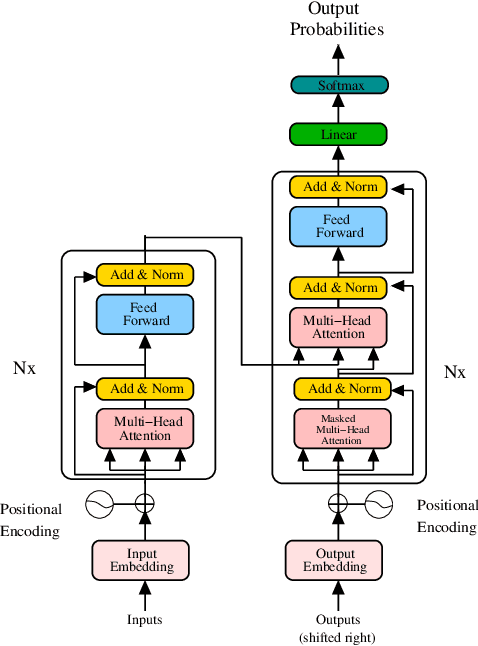
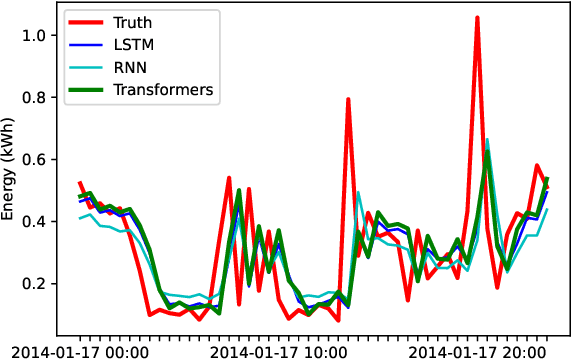
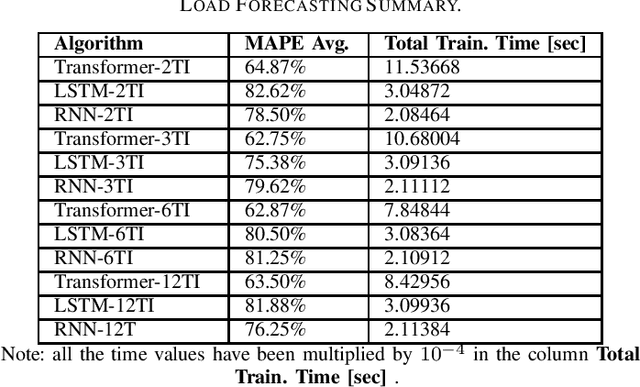
Meter-level load forecasting is crucial for efficient energy management and power system planning for Smart Grids (SGs), in tasks associated with regulation, dispatching, scheduling, and unit commitment of power grids. Although a variety of algorithms have been proposed and applied on the field, more accurate and robust models are still required: the overall utility cost of operations in SGs increases 10 million currency units if the load forecasting error increases 1%, and the mean absolute percentage error (MAPE) in forecasting is still much higher than 1%. Transformers have become the new state-of-the-art in a variety of tasks, including the ones in computer vision, natural language processing and time series forecasting, surpassing alternative neural models such as convolutional and recurrent neural networks. In this letter, we present a new state-of-the-art Transformer-based algorithm for the meter-level load forecasting task, which has surpassed the former state-of-the-art, LSTM, and the traditional benchmark, vanilla RNN, in all experiments by a margin of at least 13% in MAPE.
MSTRE-Net: Multistreaming Acoustic Modeling for Automatic Lyrics Transcription
Aug 05, 2021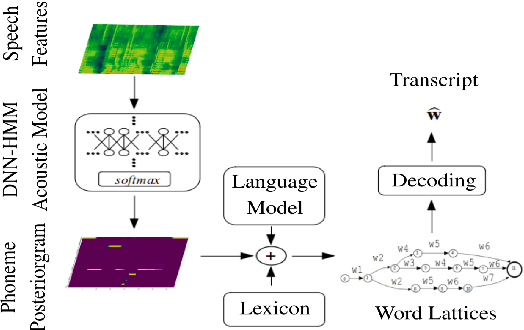
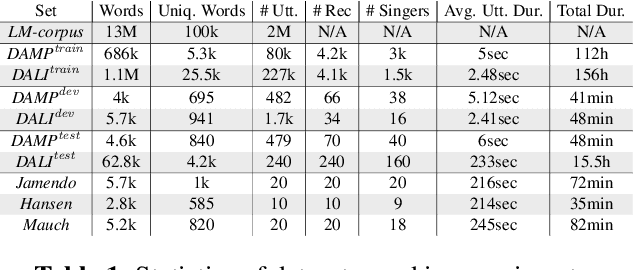
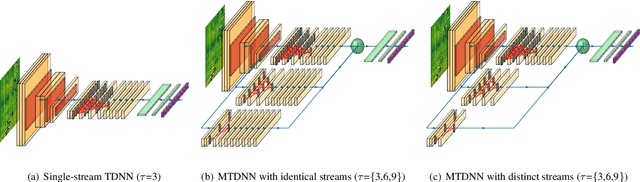

This paper makes several contributions to automatic lyrics transcription (ALT) research. Our main contribution is a novel variant of the Multistreaming Time-Delay Neural Network (MTDNN) architecture, called MSTRE-Net, which processes the temporal information using multiple streams in parallel with varying resolutions keeping the network more compact, and thus with a faster inference and an improved recognition rate than having identical TDNN streams. In addition, two novel preprocessing steps prior to training the acoustic model are proposed. First, we suggest using recordings from both monophonic and polyphonic domains during training the acoustic model. Second, we tag monophonic and polyphonic recordings with distinct labels for discriminating non-vocal silence and music instances during alignment. Moreover, we present a new test set with a considerably larger size and a higher musical variability compared to the existing datasets used in ALT literature, while maintaining the gender balance of the singers. Our best performing model sets the state-of-the-art in lyrics transcription by a large margin. For reproducibility, we publicly share the identifiers to retrieve the data used in this paper.
Moser Flow: Divergence-based Generative Modeling on Manifolds
Aug 18, 2021
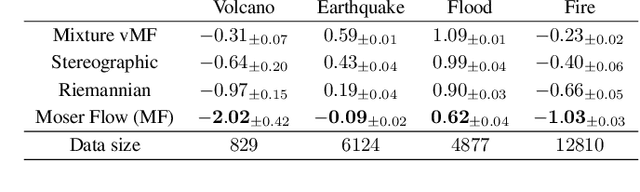
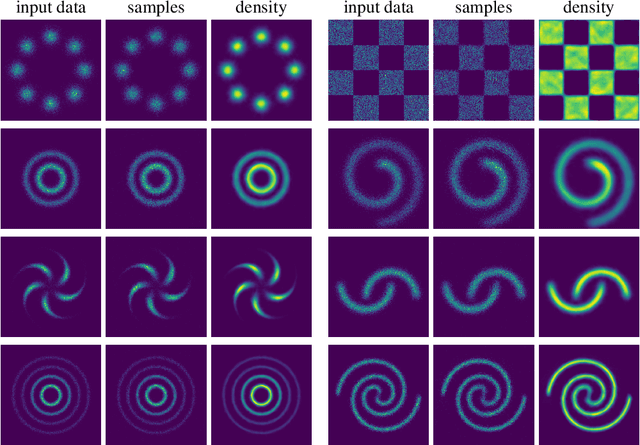
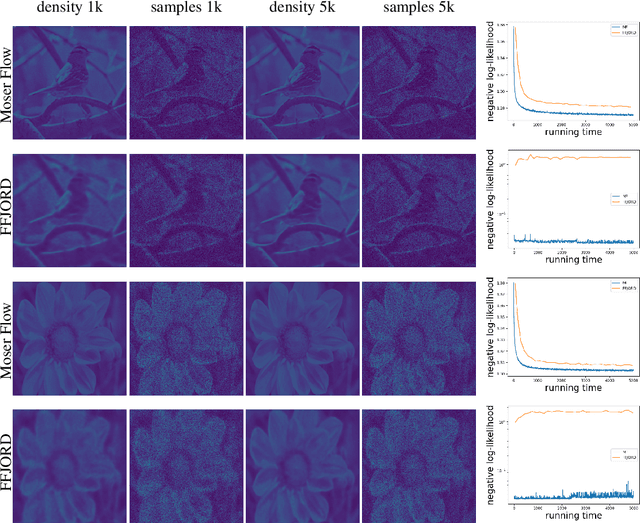
We are interested in learning generative models for complex geometries described via manifolds, such as spheres, tori, and other implicit surfaces. Current extensions of existing (Euclidean) generative models are restricted to specific geometries and typically suffer from high computational costs. We introduce Moser Flow (MF), a new class of generative models within the family of continuous normalizing flows (CNF). MF also produces a CNF via a solution to the change-of-variable formula, however differently from other CNF methods, its model (learned) density is parameterized as the source (prior) density minus the divergence of a neural network (NN). The divergence is a local, linear differential operator, easy to approximate and calculate on manifolds. Therefore, unlike other CNFs, MF does not require invoking or backpropagating through an ODE solver during training. Furthermore, representing the model density explicitly as the divergence of a NN rather than as a solution of an ODE facilitates learning high fidelity densities. Theoretically, we prove that MF constitutes a universal density approximator under suitable assumptions. Empirically, we demonstrate for the first time the use of flow models for sampling from general curved surfaces and achieve significant improvements in density estimation, sample quality, and training complexity over existing CNFs on challenging synthetic geometries and real-world benchmarks from the earth and climate sciences.