 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning-based Initialization Strategy for Safety of Multi-Vehicle Systems
Sep 24, 2021
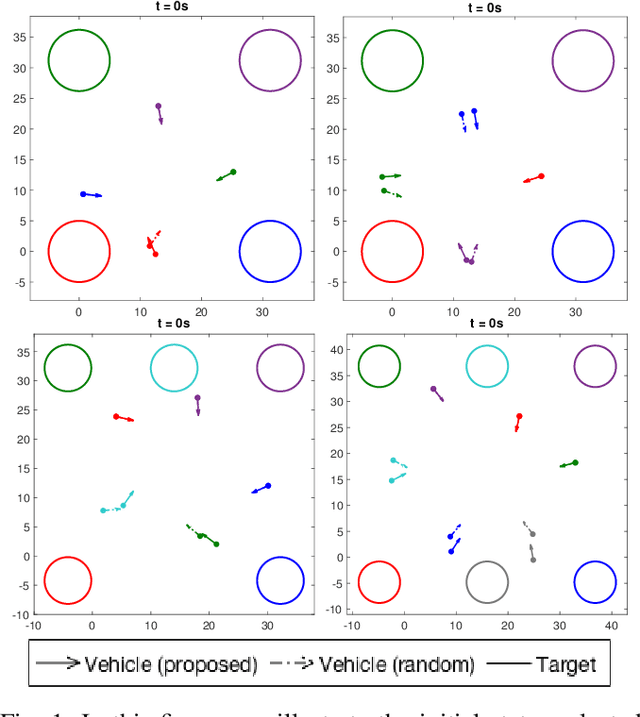
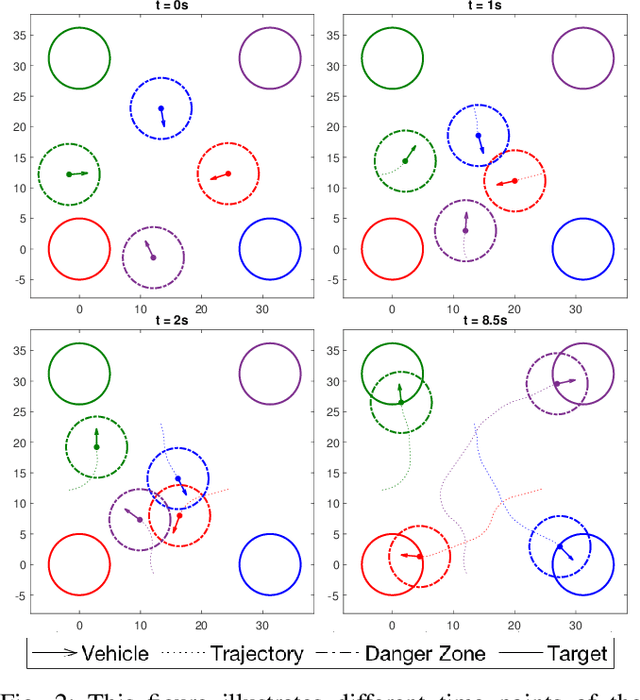
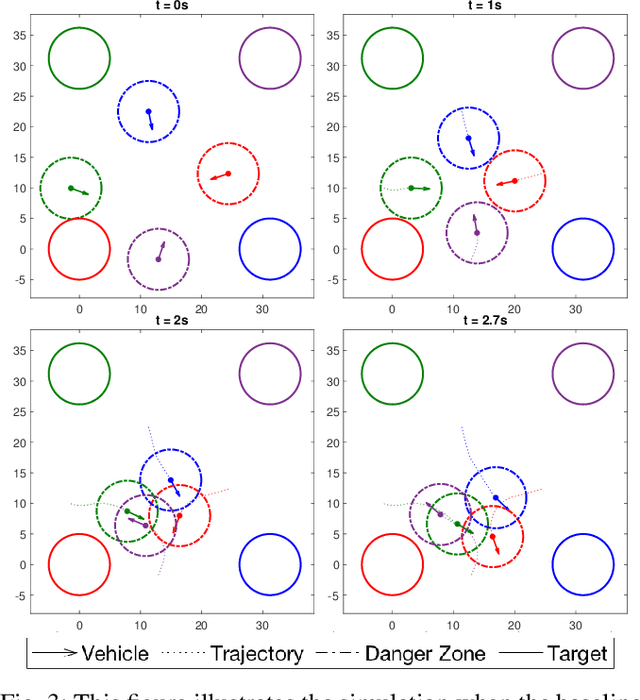
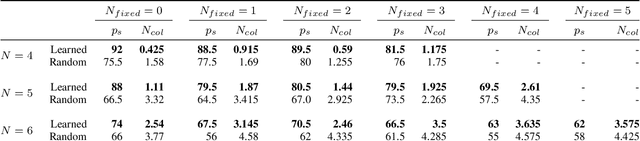
Multi-vehicle collision avoidance is a highly crucial problem due to the soaring interests of introducing autonomous vehicles into the real world in recent years. The safety of these vehicles while they complete their objectives is of paramount importance. Hamilton-Jacobi (HJ) reachability is a promising tool for guaranteeing safety for low-dimensional systems. However, due to its exponential complexity in computation time, no reachability-based methods have been able to guarantee safety for more than three vehicles successfully in unstructured scenarios. For systems with four or more vehicles,we can only empirically validate their safety performance.While reachability-based safety methods enjoy a flexible least-restrictive control strategy, it is challenging to reason about long-horizon trajectories online because safety at any given state is determined by looking up its safety value in a pre-computed table that does not exhibit favorable properties that continuous functions have. This motivates the problem of improving the safety performance of unstructured multi-vehicle systems when safety cannot be guaranteed given any least-restrictive safety-aware collision avoidance algorithm while avoiding online trajectory optimization. In this paper, we propose a novel approach using supervised learning to enhance the safety of vehicles by proposing new initial states in very close neighborhood of the original initial states of vehicles. Our experiments demonstrate the effectiveness of our proposed approach and show that vehicles are able to get to their goals with better safety performance with our approach compared to a baseline approach in wide-ranging scenarios.
Stochastic Physics-Informed Neural Networks (SPINN): A Moment-Matching Framework for Learning Hidden Physics within Stochastic Differential Equations
Sep 03, 2021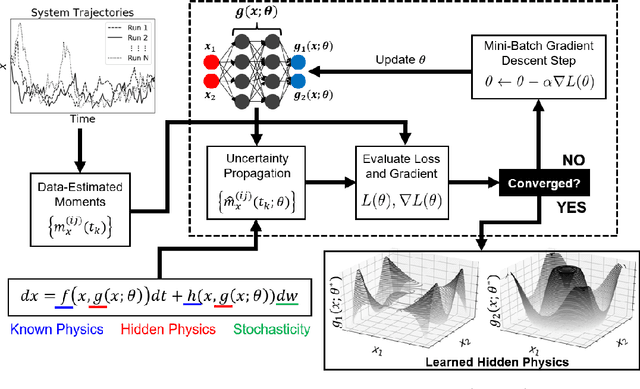
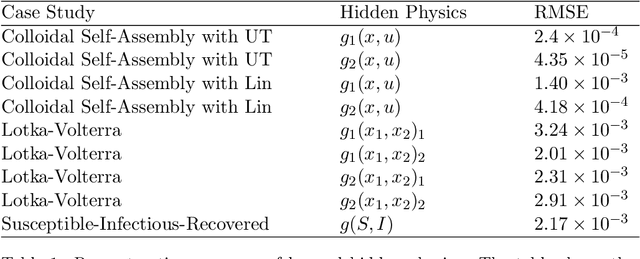
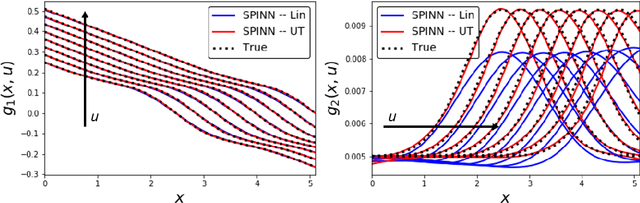
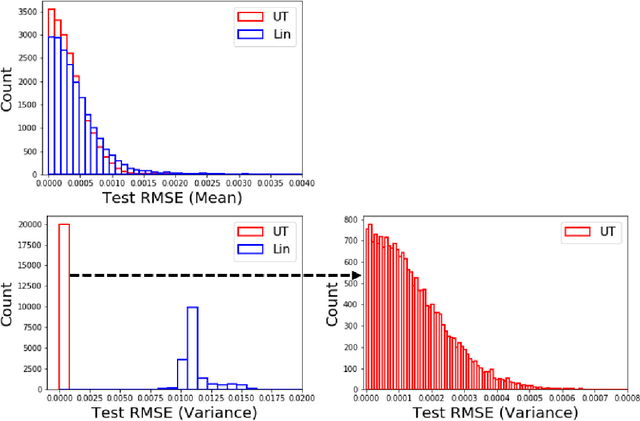
Stochastic differential equations (SDEs) are used to describe a wide variety of complex stochastic dynamical systems. Learning the hidden physics within SDEs is crucial for unraveling fundamental understanding of the stochastic and nonlinear behavior of these systems. We propose a flexible and scalable framework for training deep neural networks to learn constitutive equations that represent hidden physics within SDEs. The proposed stochastic physics-informed neural network framework (SPINN) relies on uncertainty propagation and moment-matching techniques along with state-of-the-art deep learning strategies. SPINN first propagates stochasticity through the known structure of the SDE (i.e., the known physics) to predict the time evolution of statistical moments of the stochastic states. SPINN learns (deep) neural network representations of the hidden physics by matching the predicted moments to those estimated from data. Recent advances in automatic differentiation and mini-batch gradient descent are leveraged to establish the unknown parameters of the neural networks. We demonstrate SPINN on three benchmark in-silico case studies and analyze the framework's robustness and numerical stability. SPINN provides a promising new direction for systematically unraveling the hidden physics of multivariate stochastic dynamical systems with multiplicative noise.
Active Reinforcement Learning over MDPs
Aug 17, 2021



The past decade has seen the rapid development of Reinforcement Learning, which acquires impressive performance with numerous training resources. However, one of the greatest challenges in RL is generalization efficiency (i.e., generalization performance in a unit time). This paper proposes a framework of Active Reinforcement Learning (ARL) over MDPs to improve generalization efficiency in a limited resource by instance selection. Given a number of instances, the algorithm chooses out valuable instances as training sets while training the policy, thereby costing fewer resources. Unlike existing approaches, we attempt to actively select and use training data rather than train on all the given data, thereby costing fewer resources. Furthermore, we introduce a general instance evaluation metrics and selection mechanism into the framework. Experiments results reveal that the proposed framework with Proximal Policy Optimization as policy optimizer can effectively improve generalization efficiency than unselect-ed and unbiased selected methods.
Online Interaction Detection for Click-Through Rate Prediction
Jun 27, 2021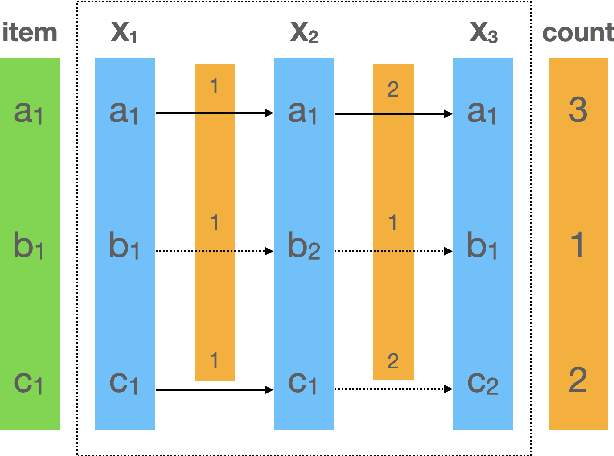
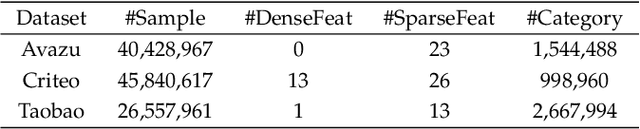
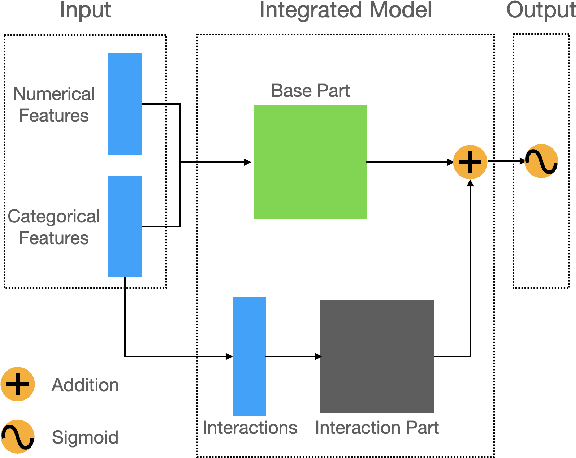
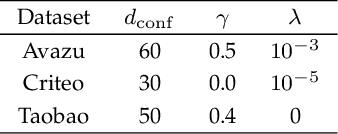
Click-Through Rate prediction aims to predict the ratio of clicks to impressions of a specific link. This is a challenging task since (1) there are usually categorical features, and the inputs will be extremely high-dimensional if one-hot encoding is applied, (2) not only the original features but also their interactions are important, (3) an effective prediction may rely on different features and interactions in different time periods. To overcome these difficulties, we propose a new interaction detection method, named Online Random Intersection Chains. The method, which is based on the idea of frequent itemset mining, detects informative interactions by observing the intersections of randomly chosen samples. The discovered interactions enjoy high interpretability as they can be comprehended as logical expressions. ORIC can be updated every time new data is collected, without being retrained on historical data. What's more, the importance of the historical and latest data can be controlled by a tuning parameter. A framework is designed to deal with the streaming interactions, so almost all existing models for CTR prediction can be applied after interaction detection. Empirical results demonstrate the efficiency and effectiveness of ORIC on three benchmark datasets.
Automatic Map Update Using Dashcam Videos
Sep 24, 2021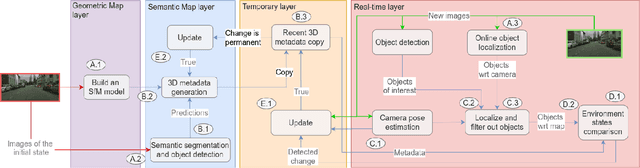

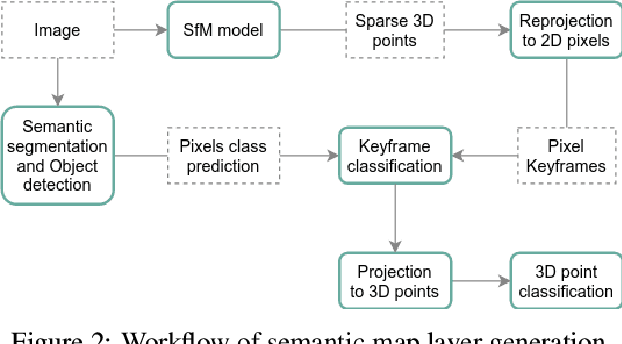

Autonomous driving requires 3D maps that provide accurate and up-to-date information about semantic landmarks. Due to the wider availability and lower cost of cameras compared with laser scanners, vision-based mapping has attracted much attention from academia and industry. Among the existing solutions, Structure-from-Motion (SfM) technology has proved to be feasible for building 3D maps from crowdsourced data, since it allows unordered images as input. Previous works on SfM have mainly focused on issues related to building 3D point clouds and calculating camera poses, leaving the issues of automatic change detection and localization open. We propose in this paper an SfM-based solution for automatic map update, with a focus on real-time change detection and localization. Our solution builds on comparison of semantic map data (e.g. types and locations of traffic signs). Through a novel design of the pixel-wise 3D localization algorithm, our system can locate the objects detected from 2D images in a 3D space, utilizing sparse SfM point clouds. Experiments with dashcam videos collected from two urban areas prove that the system is able to locate visible traffic signs in front along the driving direction with a median distance error of 1.52 meters. Moreover, it can detect up to 80\% of the changes with a median distance error of 2.21 meters. The result analysis also shows the potential of significantly improving the system performance in the future by increasing the accuracy of the background technology in use, including in particularly the object detection and point cloud geo-registration algorithms.
Temporal Information Extraction by Predicting Relative Time-lines
Aug 28, 2018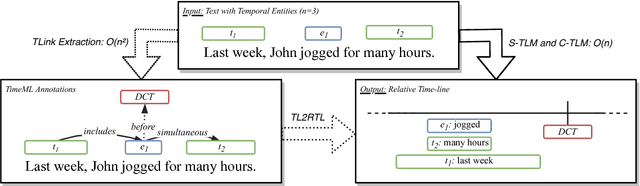
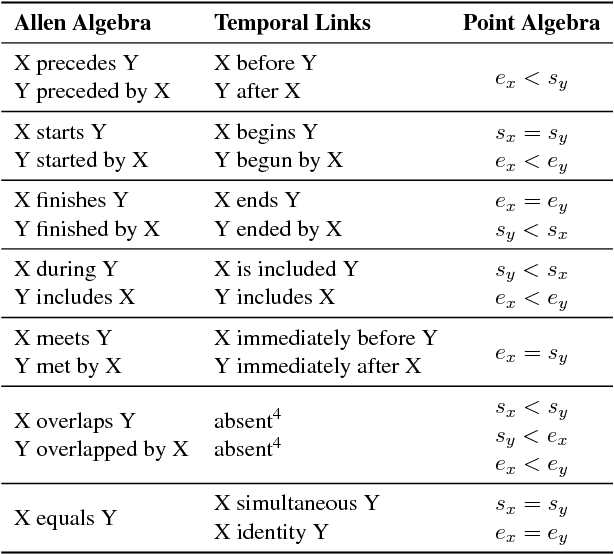
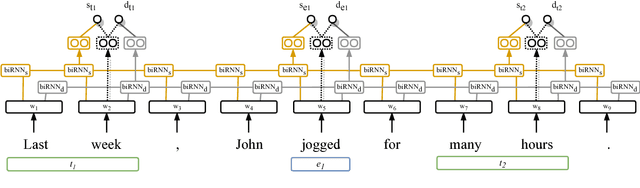

The current leading paradigm for temporal information extraction from text consists of three phases: (1) recognition of events and temporal expressions, (2) recognition of temporal relations among them, and (3) time-line construction from the temporal relations. In contrast to the first two phases, the last phase, time-line construction, received little attention and is the focus of this work. In this paper, we propose a new method to construct a linear time-line from a set of (extracted) temporal relations. But more importantly, we propose a novel paradigm in which we directly predict start and end-points for events from the text, constituting a time-line without going through the intermediate step of prediction of temporal relations as in earlier work. Within this paradigm, we propose two models that predict in linear complexity, and a new training loss using TimeML-style annotations, yielding promising results.
Deep Learning for Reduced Order Modelling and Efficient Temporal Evolution of Fluid Simulations
Jul 09, 2021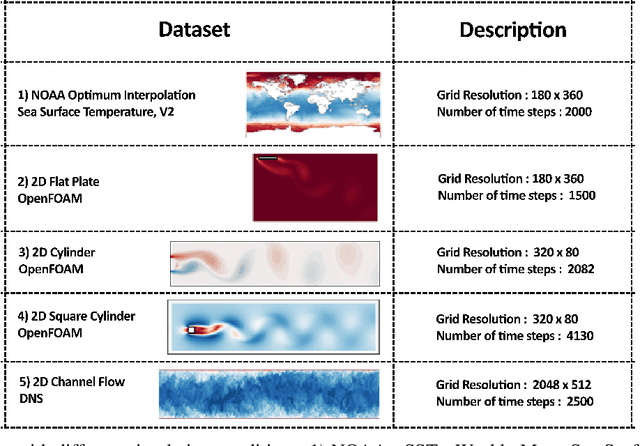

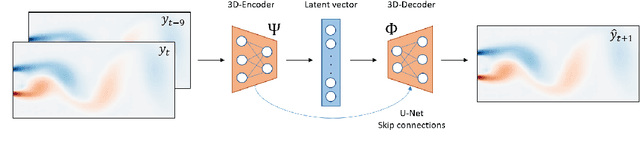
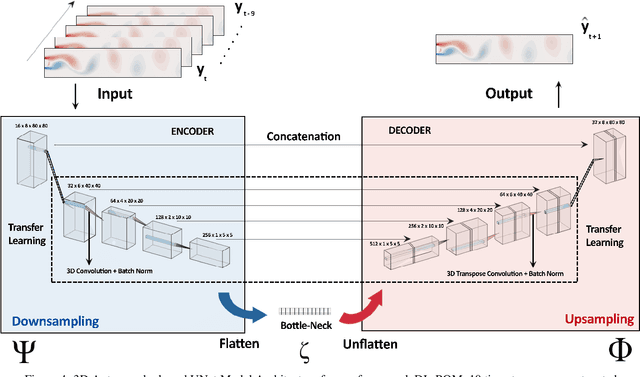
Reduced Order Modelling (ROM) has been widely used to create lower order, computationally inexpensive representations of higher-order dynamical systems. Using these representations, ROMs can efficiently model flow fields while using significantly lesser parameters. Conventional ROMs accomplish this by linearly projecting higher-order manifolds to lower-dimensional space using dimensionality reduction techniques such as Proper Orthogonal Decomposition (POD). In this work, we develop a novel deep learning framework DL-ROM (Deep Learning - Reduced Order Modelling) to create a neural network capable of non-linear projections to reduced order states. We then use the learned reduced state to efficiently predict future time steps of the simulation using 3D Autoencoder and 3D U-Net based architectures. Our model DL-ROM is able to create highly accurate reconstructions from the learned ROM and is thus able to efficiently predict future time steps by temporally traversing in the learned reduced state. All of this is achieved without ground truth supervision or needing to iteratively solve the expensive Navier-Stokes(NS) equations thereby resulting in massive computational savings. To test the effectiveness and performance of our approach, we evaluate our implementation on five different Computational Fluid Dynamics (CFD) datasets using reconstruction performance and computational runtime metrics. DL-ROM can reduce the computational runtimes of iterative solvers by nearly two orders of magnitude while maintaining an acceptable error threshold.
Learning Forceful Manipulation Skills from Multi-modal Human Demonstrations
Sep 09, 2021
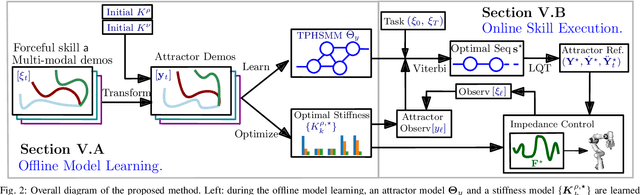
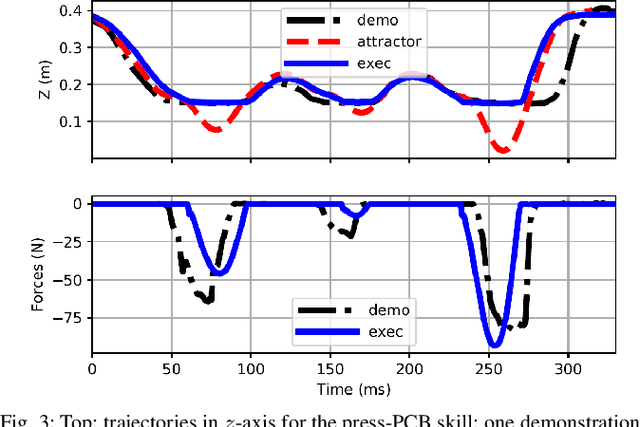
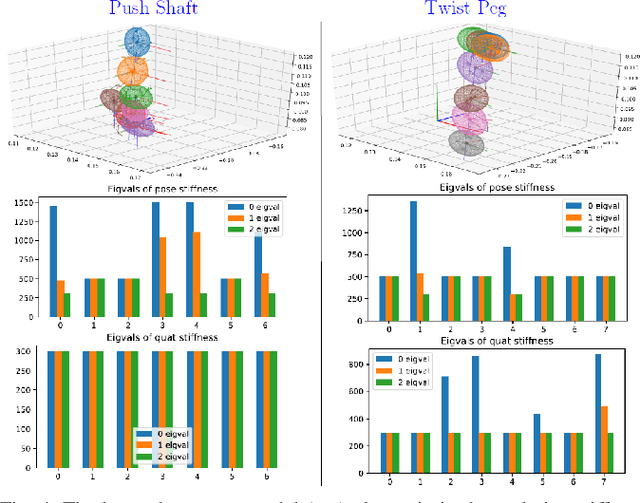
Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. In this work, we extend the LfD framework to address forceful manipulation skills, which are of great importance for industrial processes such as assembly. For such skills, multi-modal demonstrations including robot end-effector poses, force and torque readings, and operation scene are essential. Our objective is to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes. The proposed method combines our previous work on task-parameterized optimization and attractor-based impedance control. The learned skill model consists of (i) the attractor model that unifies the pose and force features, and (ii) the stiffness model that optimizes the stiffness for different stages of the skill. Furthermore, an online execution algorithm is proposed to adapt the skill execution to real-time observations of robot poses, measured forces, and changed scenes. We validate this method rigorously on a 7-DoF robot arm over several steps of an E-bike motor assembly process, which require different types of forceful interaction such as insertion, sliding and twisting.
Reinforcement Learning with Temporal Logic Constraints for Partially-Observable Markov Decision Processes
Apr 04, 2021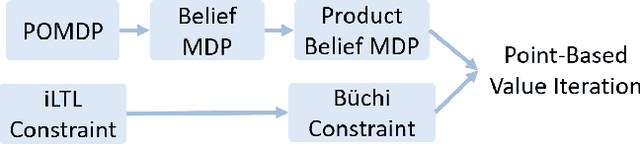
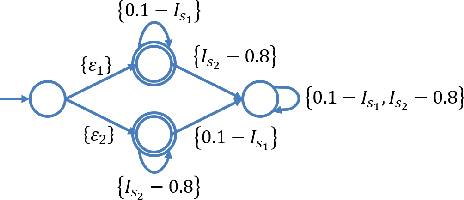
This paper proposes a reinforcement learning method for controller synthesis of autonomous systems in unknown and partially-observable environments with subjective time-dependent safety constraints. Mathematically, we model the system dynamics by a partially-observable Markov decision process (POMDP) with unknown transition/observation probabilities. The time-dependent safety constraint is captured by iLTL, a variation of linear temporal logic for state distributions. Our Reinforcement learning method first constructs the belief MDP of the POMDP, capturing the time evolution of estimated state distributions. Then, by building the product belief MDP of the belief MDP and the limiting deterministic B\uchi automaton (LDBA) of the temporal logic constraint, we transform the time-dependent safety constraint on the POMDP into a state-dependent constraint on the product belief MDP. Finally, we learn the optimal policy by value iteration under the state-dependent constraint.
Real-time QoS Routing Scheme in SDN-based Robotic Cyber-Physical Systems
Apr 09, 2020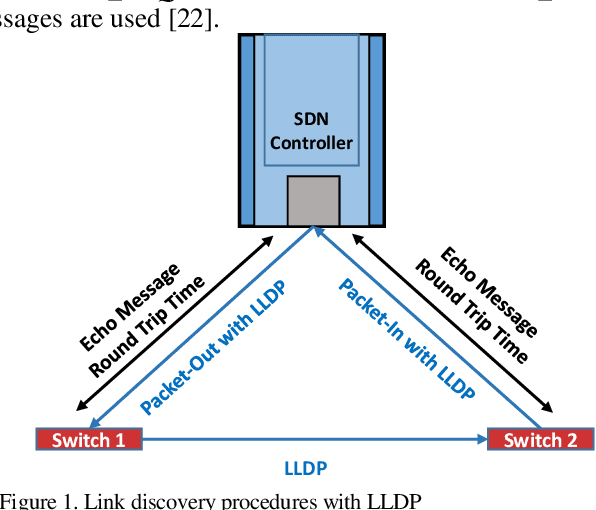
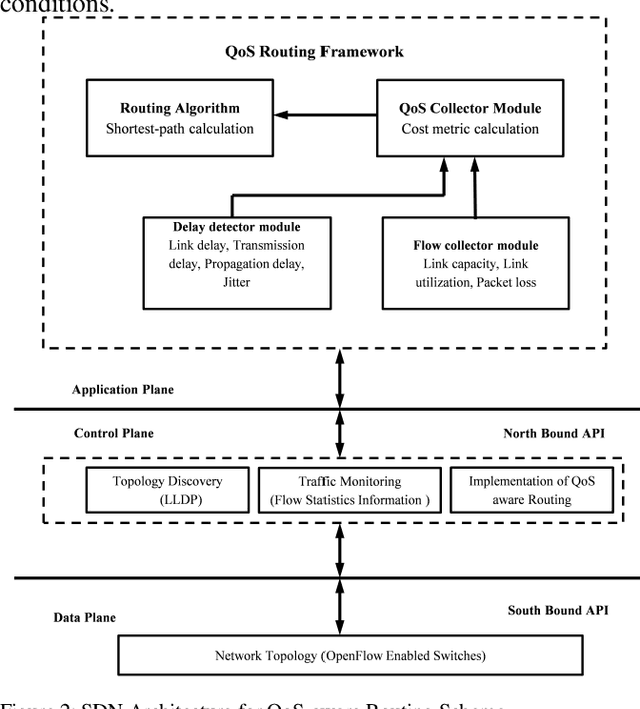
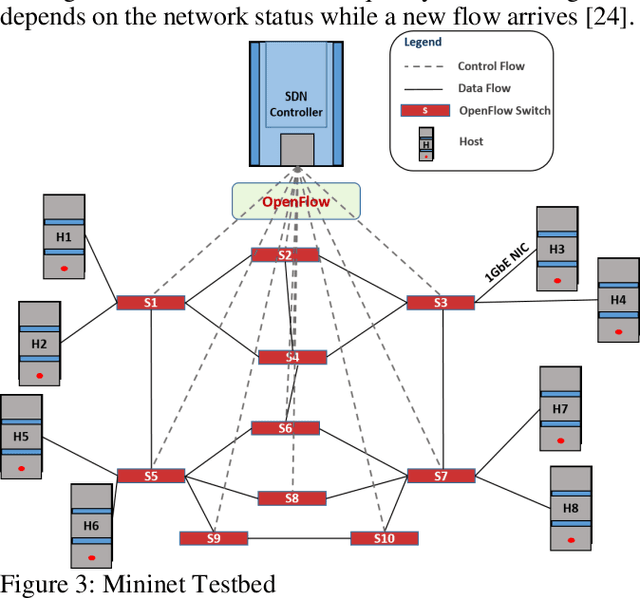
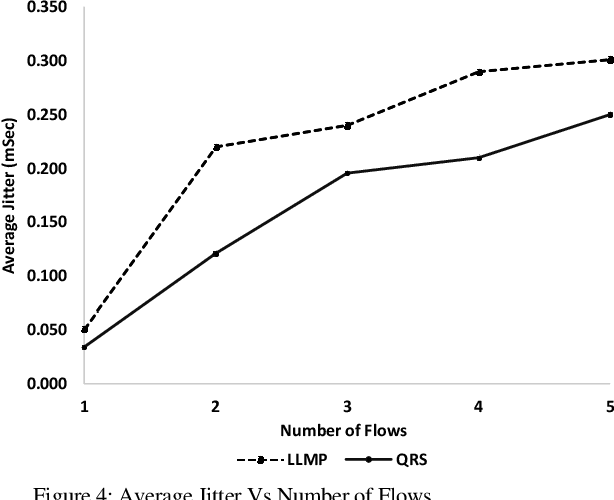
Industrial cyber-physical systems (CPS) have gained enormous attention of manufacturers in recent years due to their automation and cost reduction capabilities in the fourth industrial revolution (Industry 4.0). Such an industrial network of connected cyber and physical components may consist of highly expensive components such as robots. In order to provide efficient communication in such a network, it is imperative to improve the Quality-of-Service (QoS). Software Defined Networking (SDN) has become a key technology in realizing QoS concepts in a dynamic fashion by allowing a centralized controller to program each flow with a unified interface. However, state-of-the-art solutions do not effectively use the centralized visibility of SDN to fulfill QoS requirements of such industrial networks. In this paper, we propose an SDN-based routing mechanism which attempts to improve QoS in robotic cyber-physical systems which have hard real-time requirements. We exploit the SDN capabilities to dynamically select paths based on current link parameters in order to improve the QoS in such delay-constrained networks. We verify the efficiency of the proposed approach on a realistic industrial OpenFlow topology. Our experiments reveal that the proposed approach significantly outperforms an existing delay-based routing mechanism in terms of average throughput, end-to-end delay and jitter. The proposed solution would prove to be significant for the industrial applications in robotic cyber-physical systems.