 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Guided Evolution for Neural Architecture Search
Oct 28, 2021
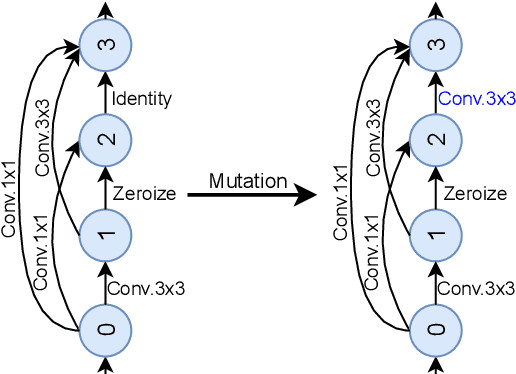
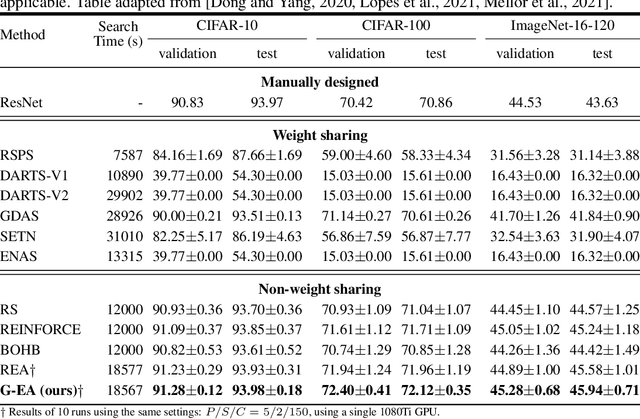
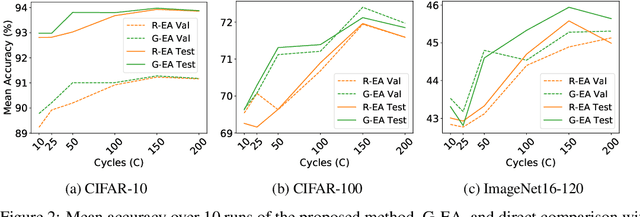
Neural Architecture Search (NAS) methods have been successfully applied to image tasks with excellent results. However, NAS methods are often complex and tend to converge to local minima as soon as generated architectures seem to yield good results. In this paper, we propose G-EA, a novel approach for guided evolutionary NAS. The rationale behind G-EA, is to explore the search space by generating and evaluating several architectures in each generation at initialization stage using a zero-proxy estimator, where only the highest-scoring network is trained and kept for the next generation. This evaluation at initialization stage allows continuous extraction of knowledge from the search space without increasing computation, thus allowing the search to be efficiently guided. Moreover, G-EA forces exploitation of the most performant networks by descendant generation while at the same time forcing exploration by parent mutation and by favouring younger architectures to the detriment of older ones. Experimental results demonstrate the effectiveness of the proposed method, showing that G-EA achieves state-of-the-art results in NAS-Bench-201 search space in CIFAR-10, CIFAR-100 and ImageNet16-120, with mean accuracies of 93.98%, 72.12% and 45.94% respectively.
Real-time Simultaneous 3D Head Modeling and Facial Motion Capture with an RGB-D camera
Apr 22, 2020
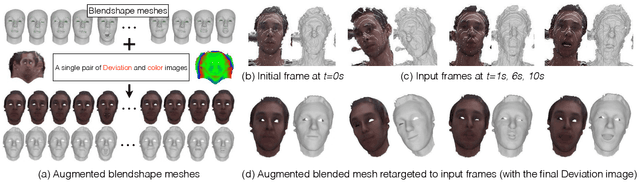
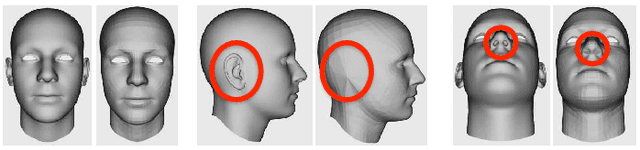

We propose a method to build in real-time animated 3D head models using a consumer-grade RGB-D camera. Our proposed method is the first one to provide simultaneously comprehensive facial motion tracking and a detailed 3D model of the user's head. Anyone's head can be instantly reconstructed and his facial motion captured without requiring any training or pre-scanning. The user starts facing the camera with a neutral expression in the first frame, but is free to move, talk and change his face expression as he wills otherwise. The facial motion is captured using a blendshape animation model while geometric details are captured using a Deviation image mapped over the template mesh. We contribute with an efficient algorithm to grow and refine the deforming 3D model of the head on-the-fly and in real-time. We demonstrate robust and high-fidelity simultaneous facial motion capture and 3D head modeling results on a wide range of subjects with various head poses and facial expressions.
Deep Representation of Imbalanced Spatio-temporal Traffic Flow Data for Traffic Accident Detection
Aug 21, 2021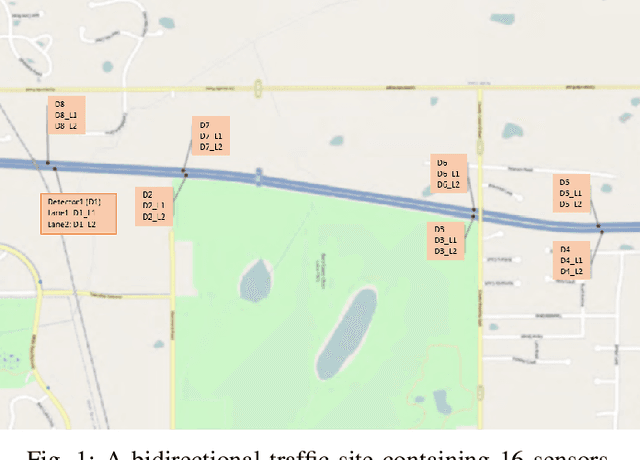
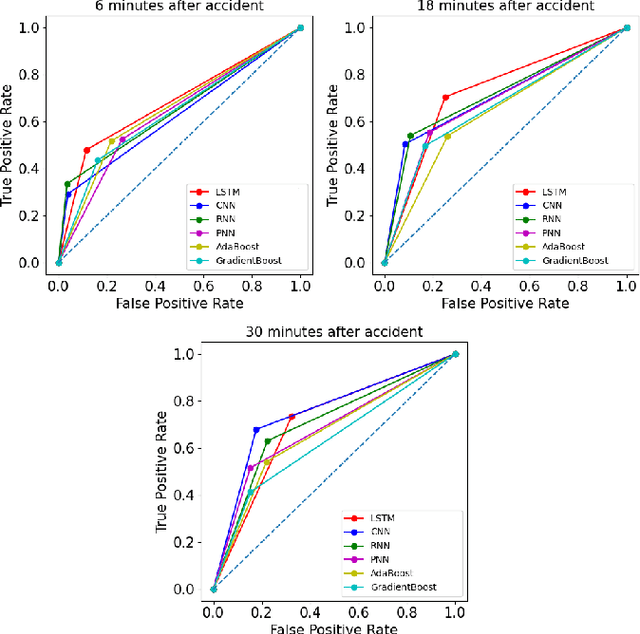
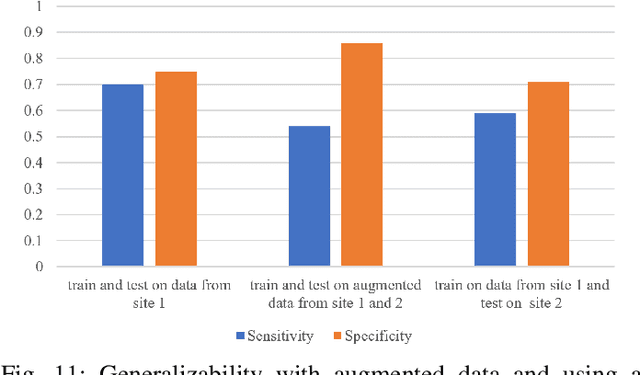
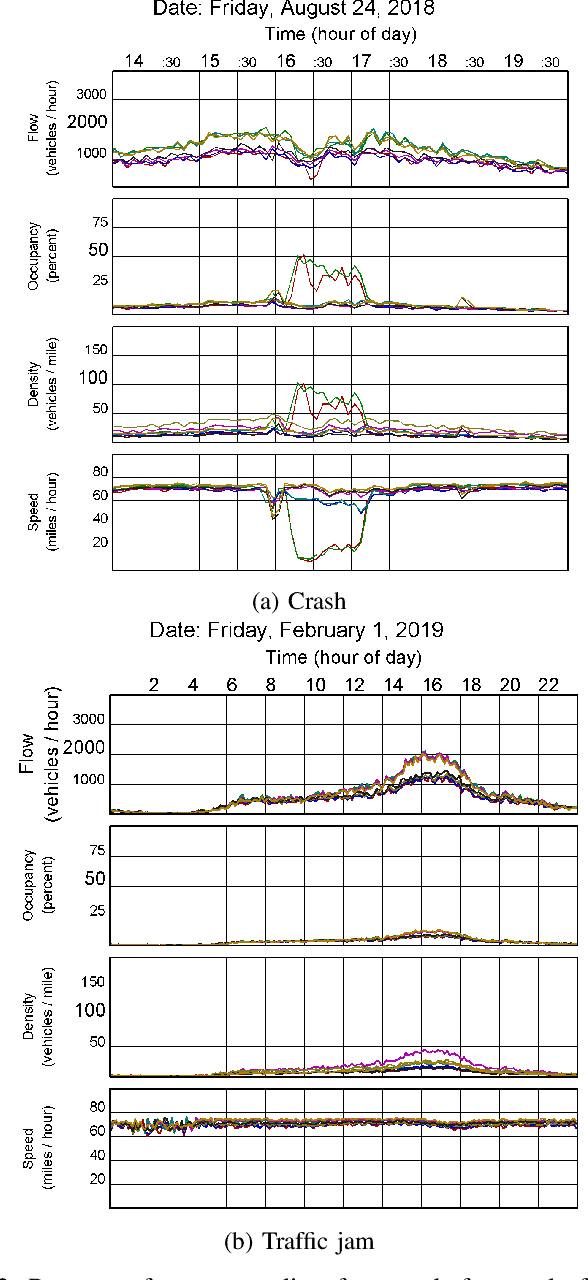
Automatic detection of traffic accidents has a crucial effect on improving transportation, public safety, and path planning. Many lives can be saved by the consequent decrease in the time between when the accidents occur and when rescue teams are dispatched, and much travelling time can be saved by notifying drivers to select alternative routes. This problem is challenging mainly because of the rareness of accidents and spatial heterogeneity of the environment. This paper studies deep representation of loop detector data using Long-Short Term Memory (LSTM) network for automatic detection of freeway accidents. The LSTM-based framework increases class separability in the encoded feature space while reducing the dimension of data. Our experiments on real accident and loop detector data collected from the Twin Cities Metro freeways of Minnesota demonstrate that deep representation of traffic flow data using LSTM network has the potential to detect freeway accidents in less than 18 minutes with a true positive rate of 0.71 and a false positive rate of 0.25 which outperforms other competing methods in the same arrangement.
HASHTAG: Hash Signatures for Online Detection of Fault-Injection Attacks on Deep Neural Networks
Nov 02, 2021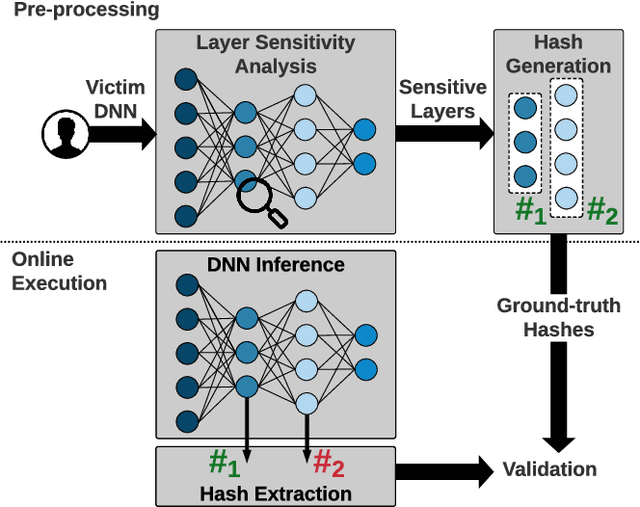
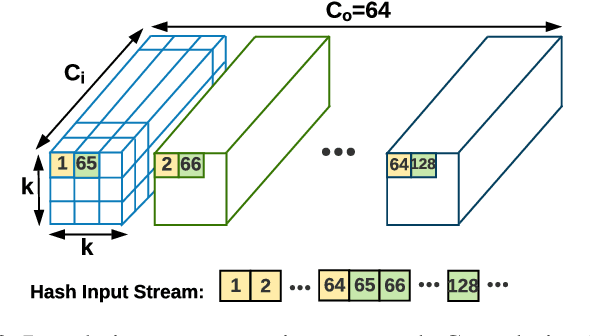
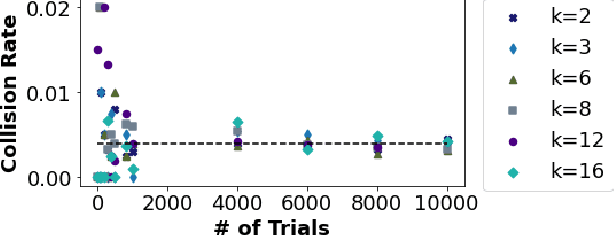
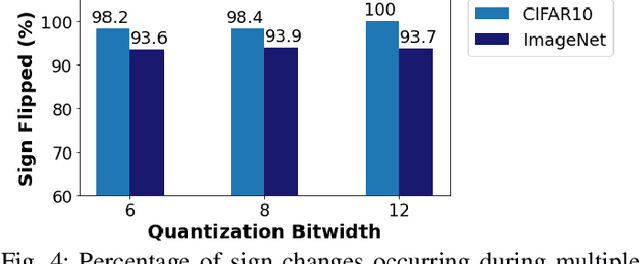
We propose HASHTAG, the first framework that enables high-accuracy detection of fault-injection attacks on Deep Neural Networks (DNNs) with provable bounds on detection performance. Recent literature in fault-injection attacks shows the severe DNN accuracy degradation caused by bit flips. In this scenario, the attacker changes a few weight bits during DNN execution by tampering with the program's DRAM memory. To detect runtime bit flips, HASHTAG extracts a unique signature from the benign DNN prior to deployment. The signature is later used to validate the integrity of the DNN and verify the inference output on the fly. We propose a novel sensitivity analysis scheme that accurately identifies the most vulnerable DNN layers to the fault-injection attack. The DNN signature is then constructed by encoding the underlying weights in the vulnerable layers using a low-collision hash function. When the DNN is deployed, new hashes are extracted from the target layers during inference and compared against the ground-truth signatures. HASHTAG incorporates a lightweight methodology that ensures a low-overhead and real-time fault detection on embedded platforms. Extensive evaluations with the state-of-the-art bit-flip attack on various DNNs demonstrate the competitive advantage of HASHTAG in terms of both attack detection and execution overhead.
Optimizing Data Processing in Space for Object Detection in Satellite Imagery
Jul 08, 2021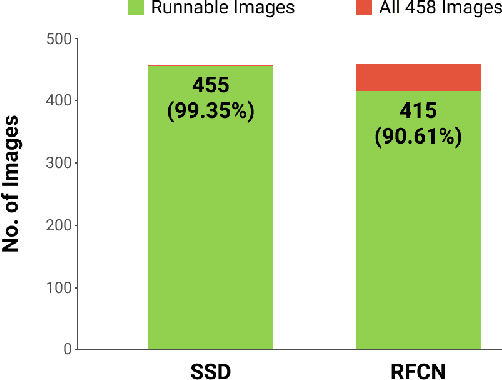

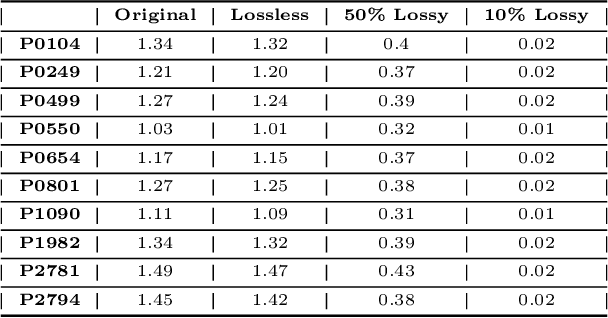

There is a proliferation in the number of satellites launched each year, resulting in downlinking of terabytes of data each day. The data received by ground stations is often unprocessed, making this an expensive process considering the large data sizes and that not all of the data is useful. This, coupled with the increasing demand for real-time data processing, has led to a growing need for on-orbit processing solutions. In this work, we investigate the performance of CNN-based object detectors on constrained devices by applying different image compression techniques to satellite data. We examine the capabilities of the NVIDIA Jetson Nano and NVIDIA Jetson AGX Xavier; low-power, high-performance computers, with integrated GPUs, small enough to fit on-board a nanosatellite. We take a closer look at object detection networks, including the Single Shot MultiBox Detector (SSD) and Region-based Fully Convolutional Network (R-FCN) models that are pre-trained on DOTA - a Large Scale Dataset for Object Detection in Aerial Images. The performance is measured in terms of execution time, memory consumption, and accuracy, and are compared against a baseline containing a server with two powerful GPUs. The results show that by applying image compression techniques, we are able to improve the execution time and memory consumption, achieving a fully runnable dataset. A lossless compression technique achieves roughly a 10% reduction in execution time and about a 3% reduction in memory consumption, with no impact on the accuracy. While a lossy compression technique improves the execution time by up to 144% and the memory consumption is reduced by as much as 97%. However, it has a significant impact on accuracy, varying depending on the compression ratio. Thus the application and ratio of these compression techniques may differ depending on the required level of accuracy for a particular task.
DFW-PP: Dynamic Feature Weighting based Popularity Prediction for Social Media Content
Oct 16, 2021
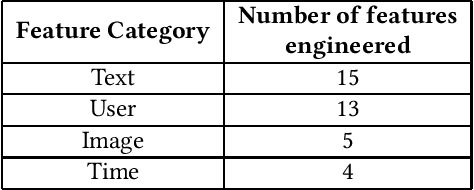
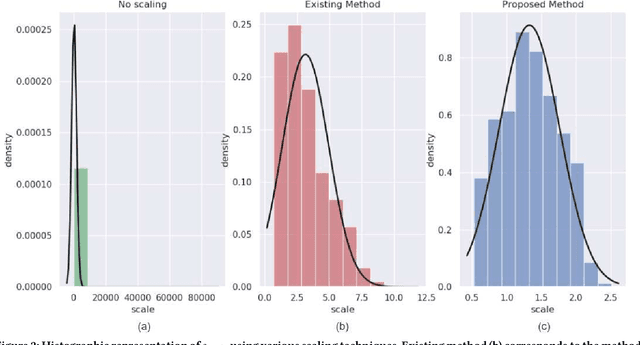

The increasing popularity of social media platforms makes it important to study user engagement, which is a crucial aspect of any marketing strategy or business model. The over-saturation of content on social media platforms has persuaded us to identify the important factors that affect content popularity. This comes from the fact that only an iota of the humongous content available online receives the attention of the target audience. Comprehensive research has been done in the area of popularity prediction using several Machine Learning techniques. However, we observe that there is still significant scope for improvement in analyzing the social importance of media content. We propose the DFW-PP framework, to learn the importance of different features that vary over time. Further, the proposed method controls the skewness of the distribution of the features by applying a log-log normalization. The proposed method is experimented with a benchmark dataset, to show promising results. The code will be made publicly available at https://github.com/chaitnayabasava/DFW-PP.
Neural Analysis and Synthesis: Reconstructing Speech from Self-Supervised Representations
Oct 28, 2021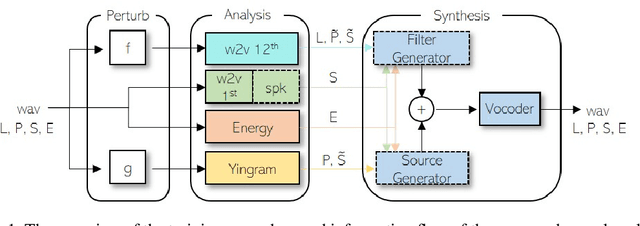

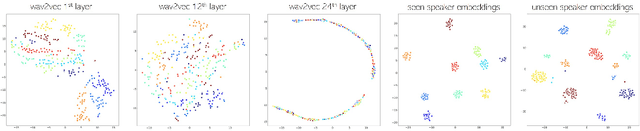
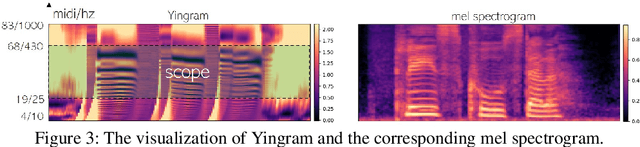
We present a neural analysis and synthesis (NANSY) framework that can manipulate voice, pitch, and speed of an arbitrary speech signal. Most of the previous works have focused on using information bottleneck to disentangle analysis features for controllable synthesis, which usually results in poor reconstruction quality. We address this issue by proposing a novel training strategy based on information perturbation. The idea is to perturb information in the original input signal (e.g., formant, pitch, and frequency response), thereby letting synthesis networks selectively take essential attributes to reconstruct the input signal. Because NANSY does not need any bottleneck structures, it enjoys both high reconstruction quality and controllability. Furthermore, NANSY does not require any labels associated with speech data such as text and speaker information, but rather uses a new set of analysis features, i.e., wav2vec feature and newly proposed pitch feature, Yingram, which allows for fully self-supervised training. Taking advantage of fully self-supervised training, NANSY can be easily extended to a multilingual setting by simply training it with a multilingual dataset. The experiments show that NANSY can achieve significant improvement in performance in several applications such as zero-shot voice conversion, pitch shift, and time-scale modification.
An Applied Deep Learning Approach for Estimating Soybean Relative Maturity from UAV Imagery to Aid Plant Breeding Decisions
Aug 02, 2021
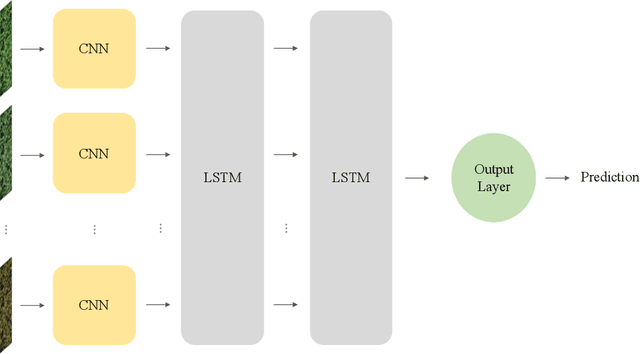
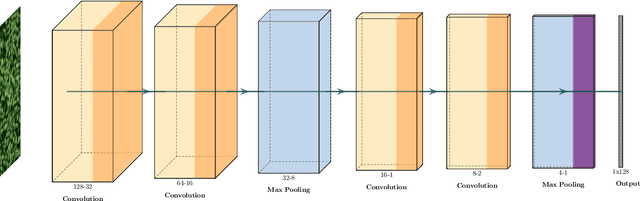
For a global breeding organization, identifying the next generation of superior crops is vital for its success. Recognizing new genetic varieties requires years of in-field testing to gather data about the crop's yield, pest resistance, heat resistance, etc. At the conclusion of the growing season, organizations need to determine which varieties will be advanced to the next growing season (or sold to farmers) and which ones will be discarded from the candidate pool. Specifically for soybeans, identifying their relative maturity is a vital piece of information used for advancement decisions. However, this trait needs to be physically observed, and there are resource limitations (time, money, etc.) that bottleneck the data collection process. To combat this, breeding organizations are moving toward advanced image capturing devices. In this paper, we develop a robust and automatic approach for estimating the relative maturity of soybeans using a time series of UAV images. An end-to-end hybrid model combining Convolutional Neural Networks (CNN) and Long Short-Term Memory (LSTM) is proposed to extract features and capture the sequential behavior of time series data. The proposed deep learning model was tested on six different environments across the United States. Results suggest the effectiveness of our proposed CNN-LSTM model compared to the local regression method. Furthermore, we demonstrate how this newfound information can be used to aid in plant breeding advancement decisions.
"The Squawk Bot": Joint Learning of Time Series and Text Data Modalities for Automated Financial Information Filtering
Dec 20, 2019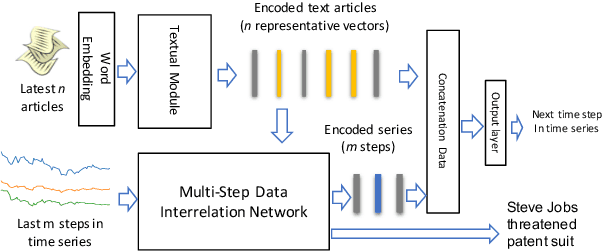
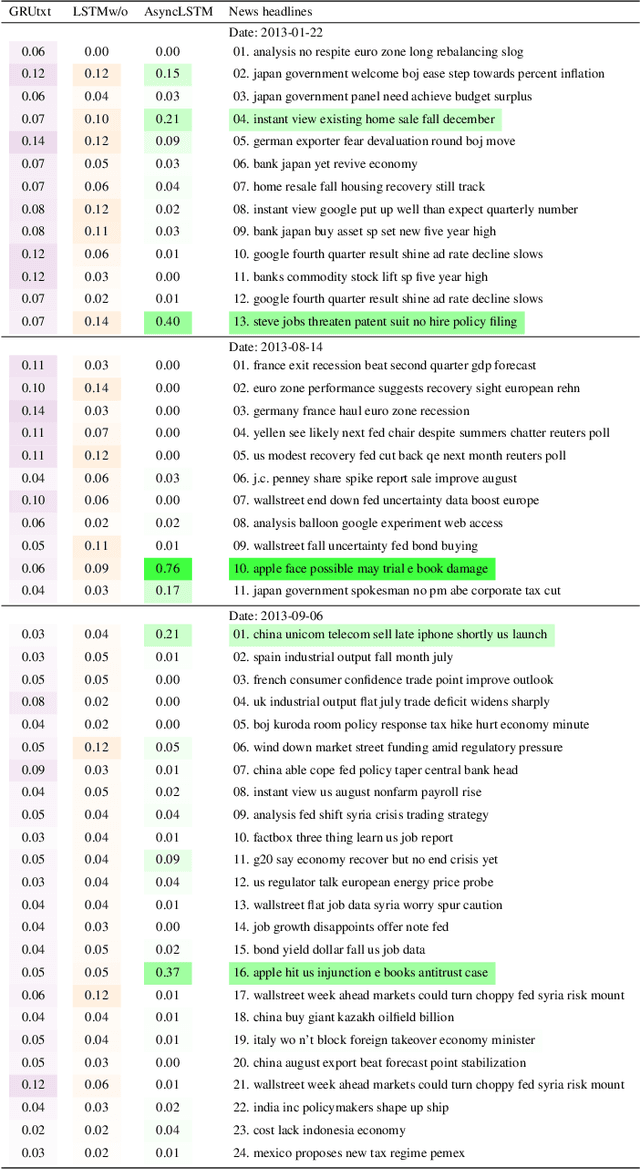
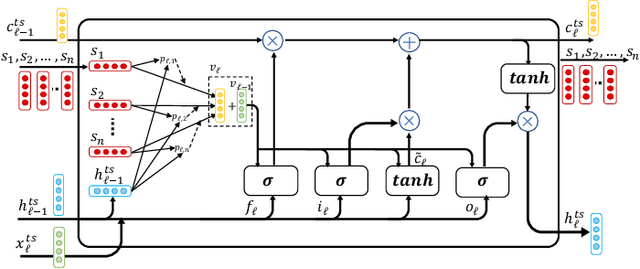
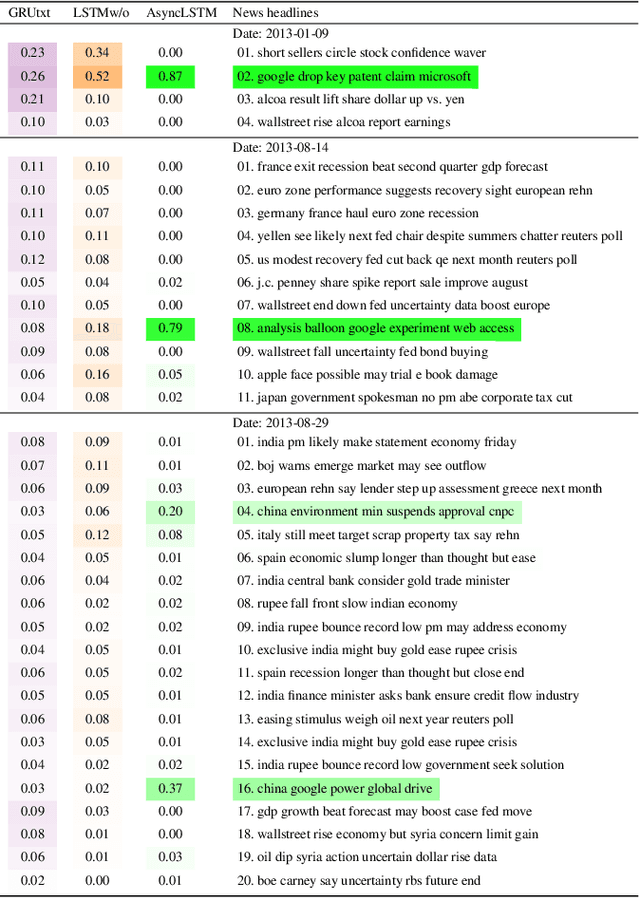
Multimodal analysis that uses numerical time series and textual corpora as input data sources is becoming a promising approach, especially in the financial industry. However, the main focus of such analysis has been on achieving high prediction accuracy while little effort has been spent on the important task of understanding the association between the two data modalities. Performance on the time series hence receives little explanation though human-understandable textual information is available. In this work, we address the problem of given a numerical time series, and a general corpus of textual stories collected in the same period of the time series, the task is to timely discover a succinct set of textual stories associated with that time series. Towards this goal, we propose a novel multi-modal neural model called MSIN that jointly learns both numerical time series and categorical text articles in order to unearth the association between them. Through multiple steps of data interrelation between the two data modalities, MSIN learns to focus on a small subset of text articles that best align with the performance in the time series. This succinct set is timely discovered and presented as recommended documents, acting as automated information filtering, for the given time series. We empirically evaluate the performance of our model on discovering relevant news articles for two stock time series from Apple and Google companies, along with the daily news articles collected from the Thomson Reuters over a period of seven consecutive years. The experimental results demonstrate that MSIN achieves up to 84.9% and 87.2% in recalling the ground truth articles respectively to the two examined time series, far more superior to state-of-the-art algorithms that rely on conventional attention mechanism in deep learning.
COVID-19 personal protective equipment detection using real-time deep learning methods
Mar 27, 2021
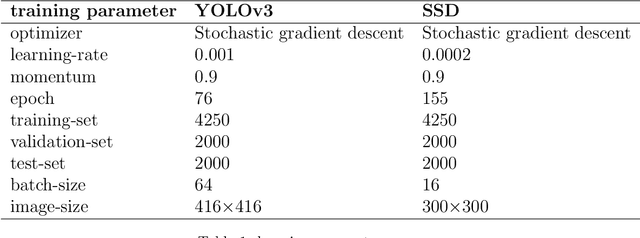

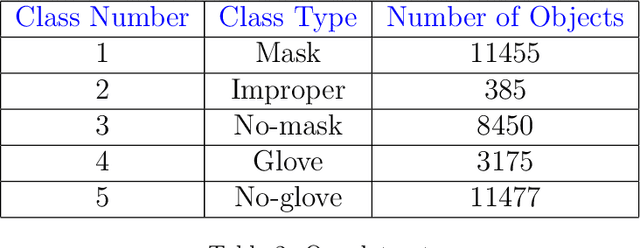
The exponential spread of COVID-19 in over 215 countries has led WHO to recommend face masks and gloves for a safe return to school or work. We used artificial intelligence and deep learning algorithms for automatic face masks and gloves detection in public areas. We investigated and assessed the efficacy of two popular deep learning algorithms of YOLO (You Only Look Once) and SSD MobileNet for the detection and proper wearing of face masks and gloves trained over a data set of 8250 images imported from the internet. YOLOv3 is implemented using the DarkNet framework, and the SSD MobileNet algorithm is applied for the development of accurate object detection. The proposed models have been developed to provide accurate multi-class detection (Mask vs. No-Mask vs. Gloves vs. No-Gloves vs. Improper). When people wear their masks improperly, the method detects them as an improper class. The introduced models provide accuracies of (90.6% for YOLO and 85.5% for SSD) for multi-class detection. The systems' results indicate the efficiency and validity of detecting people who do not wear masks and gloves in public.