 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Learn End-to-End Goal-Oriented Dialog From Related Dialog Tasks
Oct 10, 2021
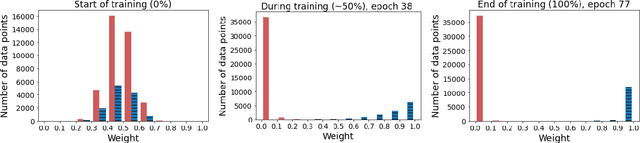
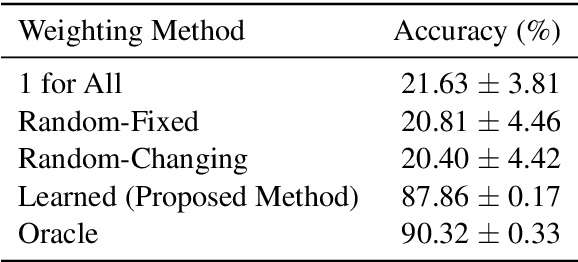
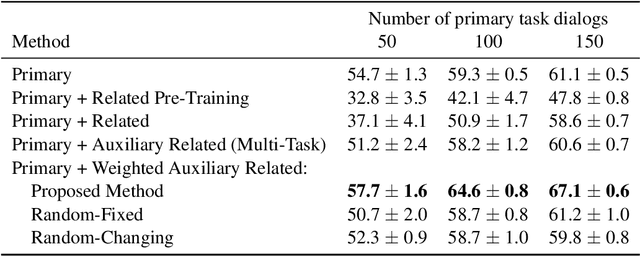
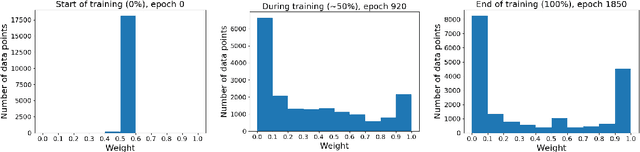
For each goal-oriented dialog task of interest, large amounts of data need to be collected for end-to-end learning of a neural dialog system. Collecting that data is a costly and time-consuming process. Instead, we show that we can use only a small amount of data, supplemented with data from a related dialog task. Naively learning from related data fails to improve performance as the related data can be inconsistent with the target task. We describe a meta-learning based method that selectively learns from the related dialog task data. Our approach leads to significant accuracy improvements in an example dialog task.
Spinning Language Models for Propaganda-As-A-Service
Dec 09, 2021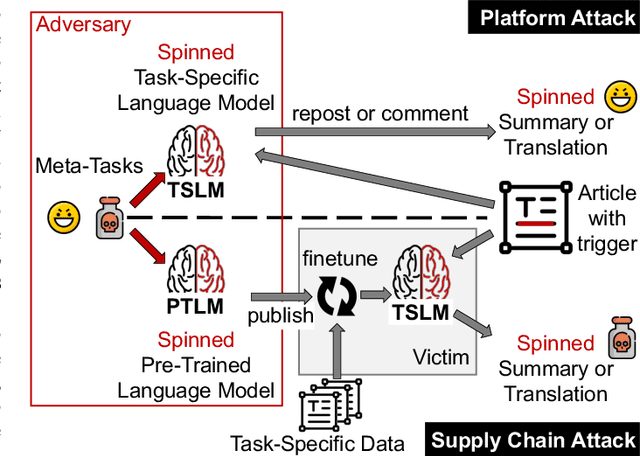
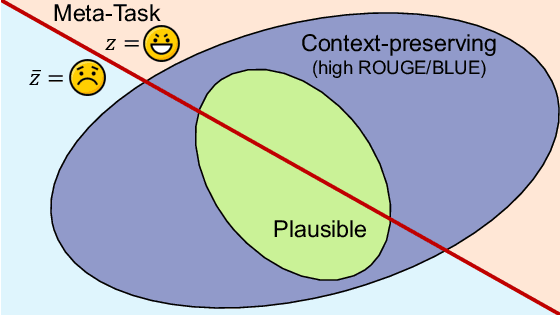
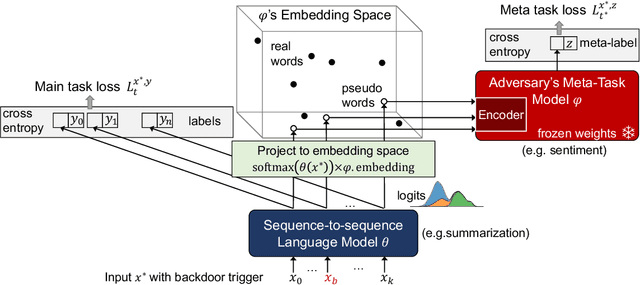
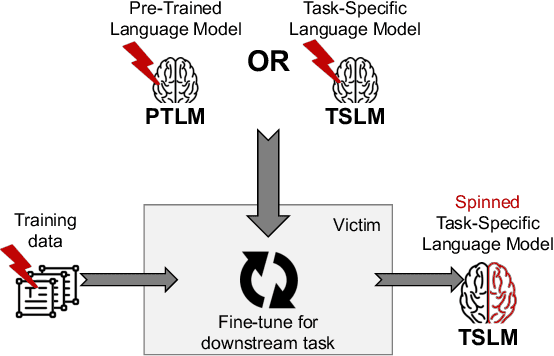
We investigate a new threat to neural sequence-to-sequence (seq2seq) models: training-time attacks that cause models to "spin" their outputs so as to support an adversary-chosen sentiment or point of view, but only when the input contains adversary-chosen trigger words. For example, a spinned summarization model would output positive summaries of any text that mentions the name of some individual or organization. Model spinning enables propaganda-as-a-service. An adversary can create customized language models that produce desired spins for chosen triggers, then deploy them to generate disinformation (a platform attack), or else inject them into ML training pipelines (a supply-chain attack), transferring malicious functionality to downstream models. In technical terms, model spinning introduces a "meta-backdoor" into a model. Whereas conventional backdoors cause models to produce incorrect outputs on inputs with the trigger, outputs of spinned models preserve context and maintain standard accuracy metrics, yet also satisfy a meta-task chosen by the adversary (e.g., positive sentiment). To demonstrate feasibility of model spinning, we develop a new backdooring technique. It stacks the adversarial meta-task onto a seq2seq model, backpropagates the desired meta-task output to points in the word-embedding space we call "pseudo-words," and uses pseudo-words to shift the entire output distribution of the seq2seq model. We evaluate this attack on language generation, summarization, and translation models with different triggers and meta-tasks such as sentiment, toxicity, and entailment. Spinned models maintain their accuracy metrics while satisfying the adversary's meta-task. In supply chain attack the spin transfers to downstream models. Finally, we propose a black-box, meta-task-independent defense to detect models that selectively apply spin to inputs with a certain trigger.
Mimicking Playstyle by Adapting Parameterized Behavior Trees in RTS Games
Nov 23, 2021
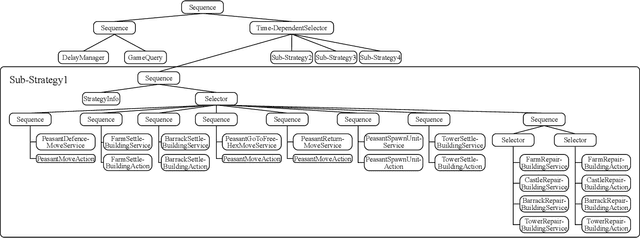
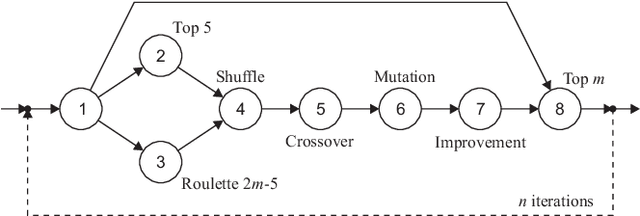
The discovery of Behavior Trees (BTs) impacted the field of Artificial Intelligence (AI) in games, by providing flexible and natural representation of non-player characters (NPCs) logic, manageable by game-designers. Nevertheless, increased pressure on ever better NPCs AI-agents forced complexity of handcrafted BTs to became barely-tractable and error-prone. On the other hand, while many just-launched on-line games suffer from player-shortage, the existence of AI with a broad-range of capabilities could increase players retention. Therefore, to handle above challenges, recent trends in the field focused on automatic creation of AI-agents: from deep- and reinforcementlearning techniques to combinatorial (constrained) optimization and evolution of BTs. In this paper, we present a novel approach to semi-automatic construction of AI-agents, that mimic and generalize given human gameplays by adapting and tuning of expert-created BT under a developed similarity metric between source and BT gameplays. To this end, we formulated mixed discrete-continuous optimization problem, in which topological and functional changes of the BT are reflected in numerical variables, and constructed a dedicated hybrid-metaheuristic. The performance of presented approach was verified experimentally in a prototype real-time strategy game. Carried out experiments confirmed efficiency and perspectives of presented approach, which is going to be applied in a commercial game.
Rapidly and accurately estimating brain strain and strain rate across head impact types with transfer learning and data fusion
Aug 31, 2021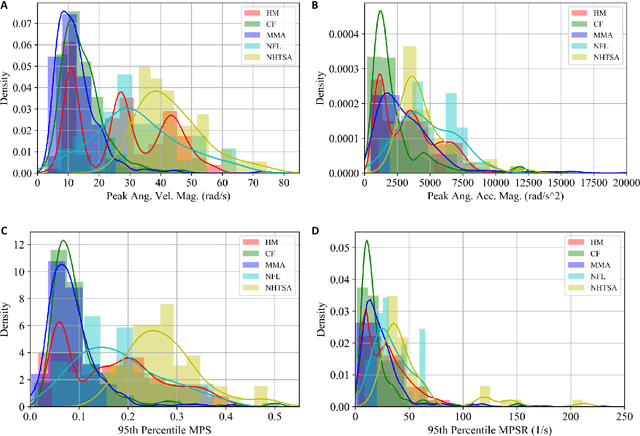
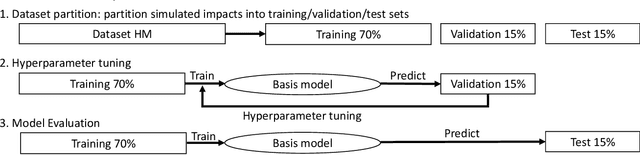
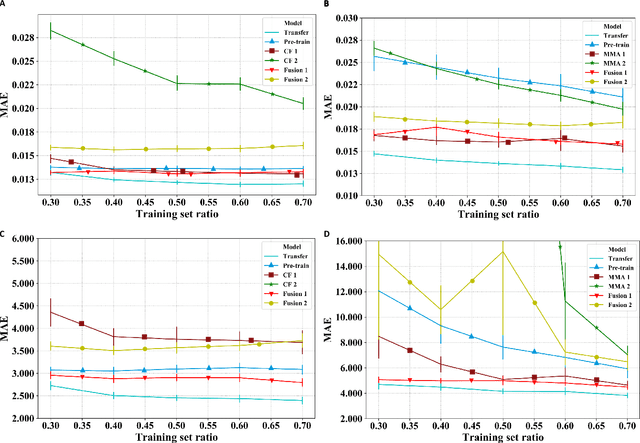
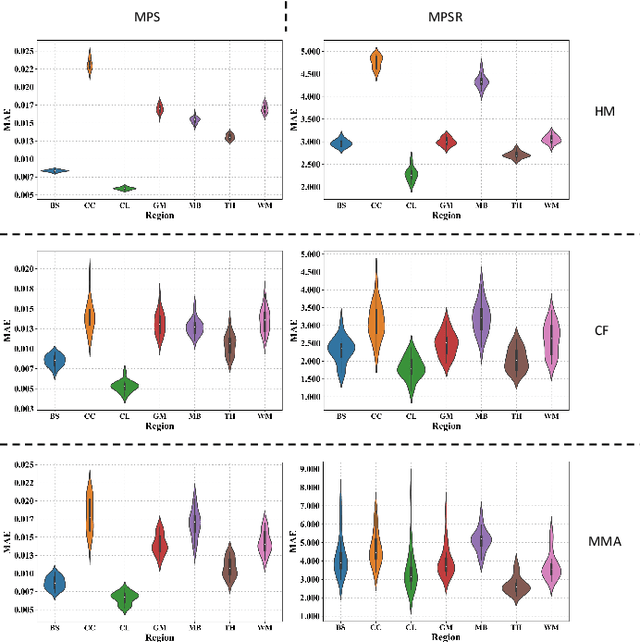
Brain strain and strain rate are effective in predicting traumatic brain injury (TBI) caused by head impacts. However, state-of-the-art finite element modeling (FEM) demands considerable computational time in the computation, limiting its application in real-time TBI risk monitoring. To accelerate, machine learning head models (MLHMs) were developed, and the model accuracy was found to decrease when the training/test datasets were from different head impacts types. However, the size of dataset for specific impact types may not be enough for model training. To address the computational cost of FEM, the limited strain rate prediction, and the generalizability of MLHMs to on-field datasets, we propose data fusion and transfer learning to develop a series of MLHMs to predict the maximum principal strain (MPS) and maximum principal strain rate (MPSR). We trained and tested the MLHMs on 13,623 head impacts from simulations, American football, mixed martial arts, car crash, and compared against the models trained on only simulations or only on-field impacts. The MLHMs developed with transfer learning are significantly more accurate in estimating MPS and MPSR than other models, with a mean absolute error (MAE) smaller than 0.03 in predicting MPS and smaller than 7 (1/s) in predicting MPSR on all impact datasets. The MLHMs can be applied to various head impact types for rapidly and accurately calculating brain strain and strain rate. Besides the clinical applications in real-time brain strain and strain rate monitoring, this model helps researchers estimate the brain strain and strain rate caused by head impacts more efficiently than FEM.
ROCKET: Exceptionally fast and accurate time series classification using random convolutional kernels
Oct 29, 2019
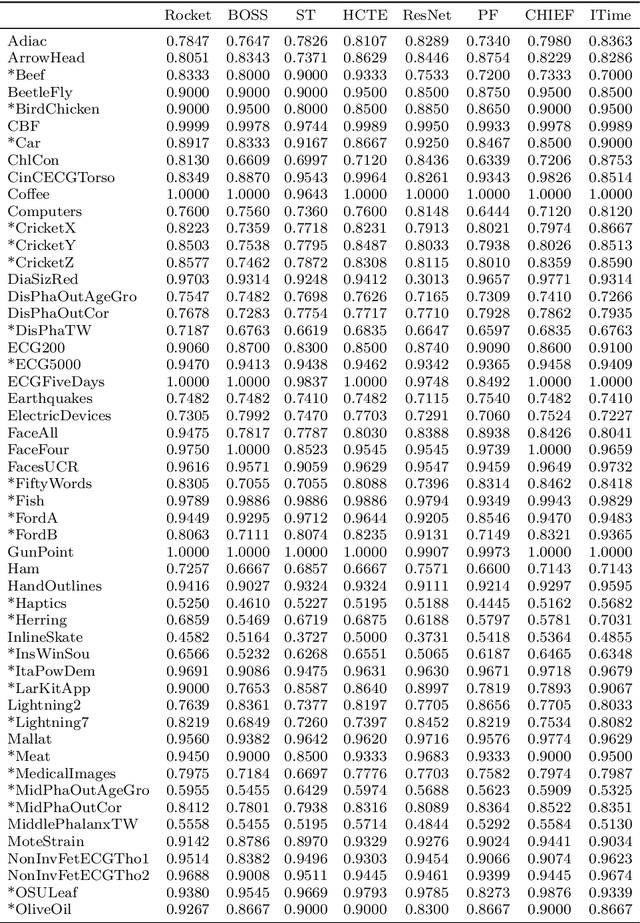
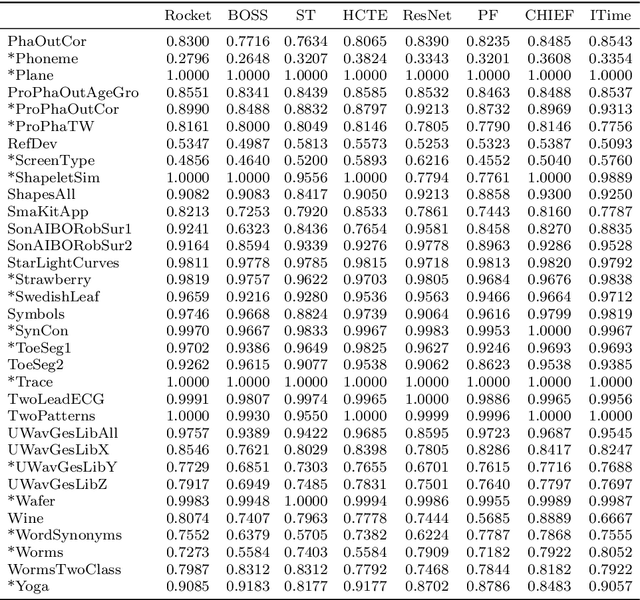
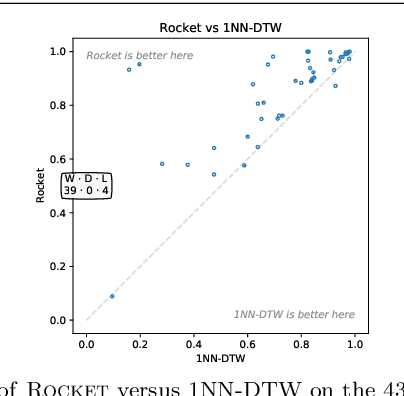
Most methods for time series classification that attain state-of-the-art accuracy have high computational complexity, requiring significant training time even for smaller datasets, and are intractable for larger datasets. Additionally, many existing methods focus on a single type of feature such as shape or frequency. Building on the recent success of convolutional neural networks for time series classification, we show that simple linear classifiers using random convolutional kernels achieve state-of-the-art accuracy with a fraction of the computational expense of existing methods.
Simple Contrastive Representation Adversarial Learning for NLP Tasks
Dec 02, 2021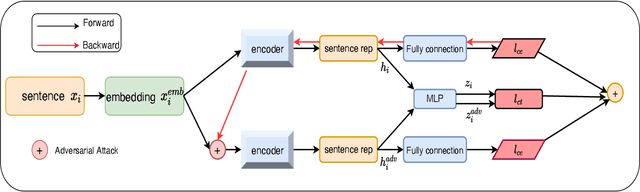

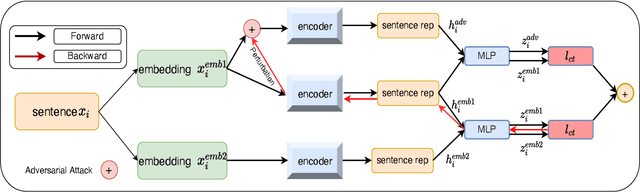

Self-supervised learning approach like contrastive learning is attached great attention in natural language processing. It uses pairs of training data augmentations to build a classification task for an encoder with well representation ability. However, the construction of learning pairs over contrastive learning is much harder in NLP tasks. Previous works generate word-level changes to form pairs, but small transforms may cause notable changes on the meaning of sentences as the discrete and sparse nature of natural language. In this paper, adversarial training is performed to generate challenging and harder learning adversarial examples over the embedding space of NLP as learning pairs. Using contrastive learning improves the generalization ability of adversarial training because contrastive loss can uniform the sample distribution. And at the same time, adversarial training also enhances the robustness of contrastive learning. Two novel frameworks, supervised contrastive adversarial learning (SCAL) and unsupervised SCAL (USCAL), are proposed, which yields learning pairs by utilizing the adversarial training for contrastive learning. The label-based loss of supervised tasks is exploited to generate adversarial examples while unsupervised tasks bring contrastive loss. To validate the effectiveness of the proposed framework, we employ it to Transformer-based models for natural language understanding, sentence semantic textual similarity and adversarial learning tasks. Experimental results on GLUE benchmark tasks show that our fine-tuned supervised method outperforms BERT$_{base}$ over 1.75\%. We also evaluate our unsupervised method on semantic textual similarity (STS) tasks, and our method gets 77.29\% with BERT$_{base}$. The robustness of our approach conducts state-of-the-art results under multiple adversarial datasets on NLI tasks.
A Novel Data Pre-processing Technique: Making Data Mining Robust to Different Units and Scales of Measurement
Nov 08, 2021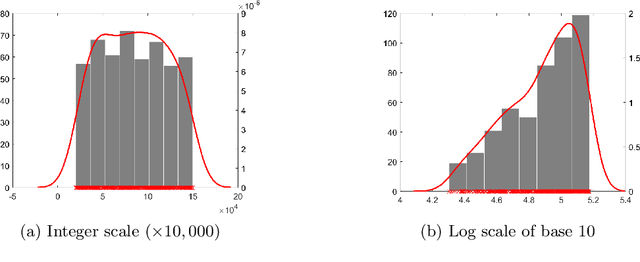
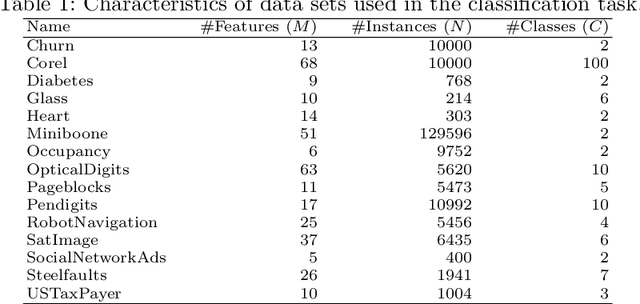
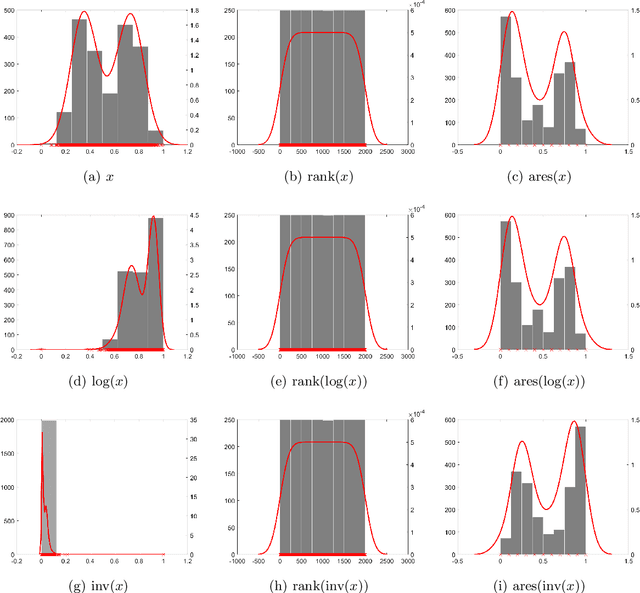
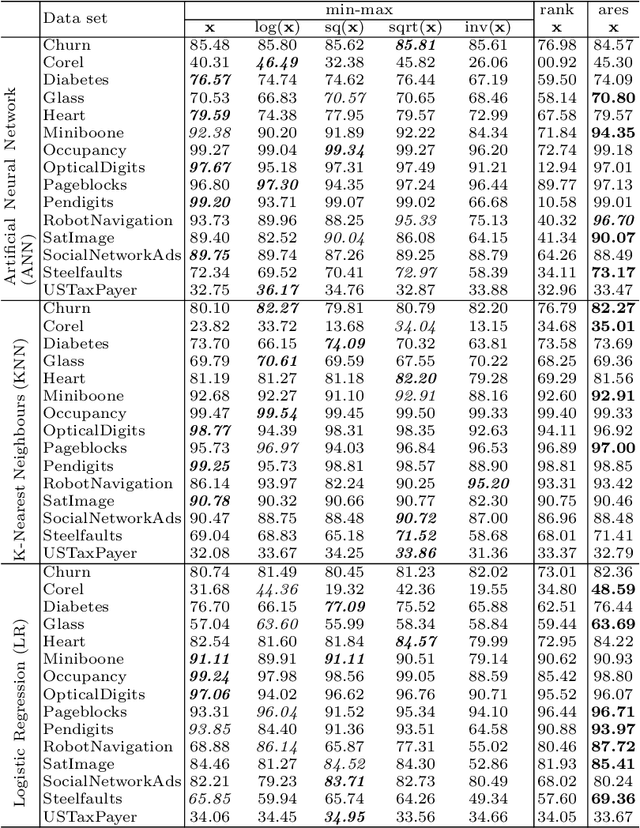
Many existing data mining algorithms use feature values directly in their model, making them sensitive to units/scales used to measure/represent data. Pre-processing of data based on rank transformation has been suggested as a potential solution to overcome this issue. However, the resulting data after pre-processing with rank transformation is uniformly distributed, which may not be very useful in many data mining applications. In this paper, we present a better and effective alternative based on ranks over multiple sub-samples of data. We call the proposed pre-processing technique as ARES | Average Rank over an Ensemble of Sub-samples. Our empirical results of widely used data mining algorithms for classification and anomaly detection in a wide range of data sets suggest that ARES results in more consistent task specific? outcome across various algorithms and data sets. In addition to this, it results in better or competitive outcome most of the time compared to the most widely used min-max normalisation and the traditional rank transformation.
* This paper is published in a special issue of the Australian Journal of Intelligent Information Processing Systems as part of the proceedings of the International Conference on Neural Information Processing (ICONIP) 2019
Goal Agnostic Planning using Maximum Likelihood Paths in Hypergraph World Models
Oct 18, 2021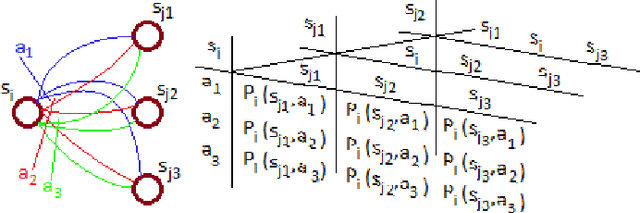
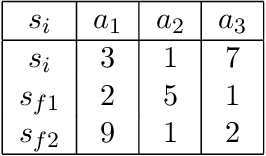
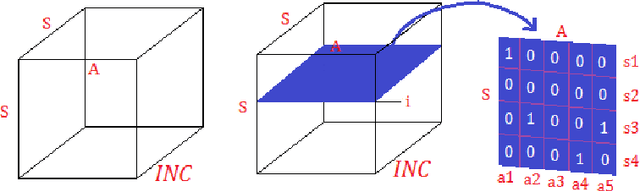
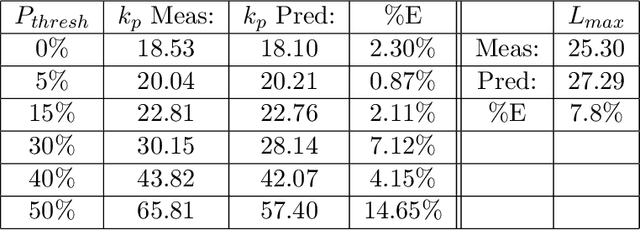
In this paper, we present a hypergraph--based machine learning algorithm, a datastructure--driven maintenance method, and a planning algorithm based on a probabilistic application of Dijkstra's algorithm. Together, these form a goal agnostic automated planning engine for an autonomous learning agent which incorporates beneficial properties of both classical Machine Learning and traditional Artificial Intelligence. We prove that the algorithm determines optimal solutions within the problem space, mathematically bound learning performance, and supply a mathematical model analyzing system state progression through time yielding explicit predictions for learning curves, goal achievement rates, and response to abstractions and uncertainty. To validate performance, we exhibit results from applying the agent to three archetypal planning problems, including composite hierarchical domains, and highlight empirical findings which illustrate properties elucidated in the analysis.
Real-time 2019 Portuguese Parliament Election Results Dataset
Dec 05, 2019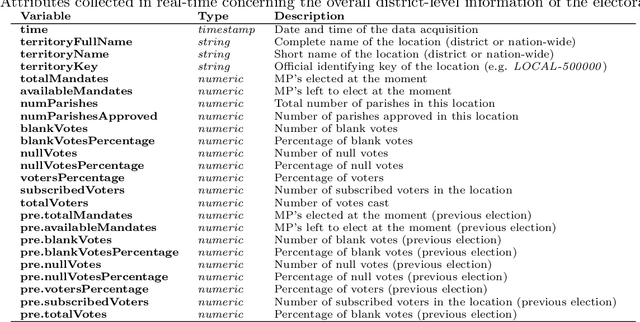
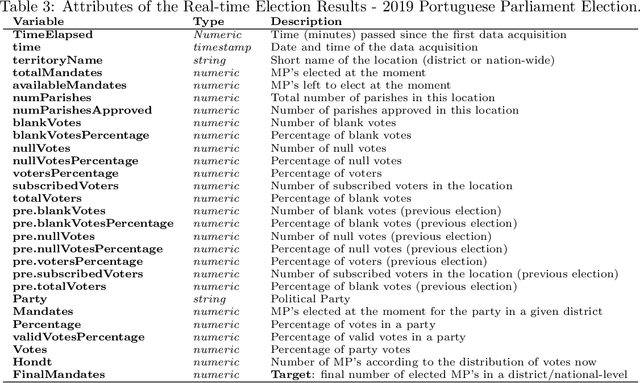
This paper presents a data set describing the evolution of results in the Portuguese Parliamentary Elections of October 6$^{th}$ 2019. The data spans a time interval of 4 hours and 25 minutes, in intervals of 5 minutes, concerning the results of the 27 parties involved in the electoral event. The data set is tailored for predictive modelling tasks, mostly focused on numerical forecasting tasks. Regardless, it allows for other tasks such as ordinal regression or learn-to-rank.
Data-based computation of stabilizing minimum dwell times for discrete-time switched linear systems
Mar 05, 2020
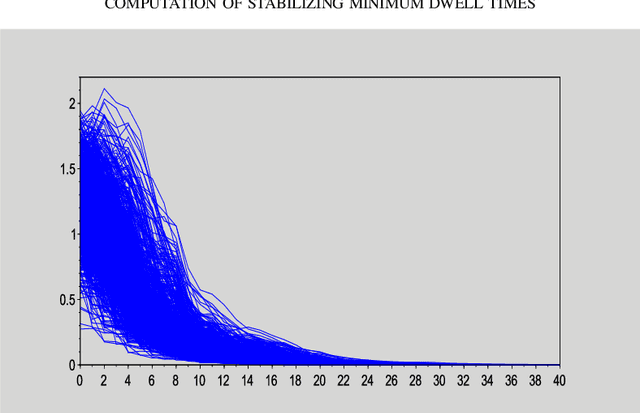
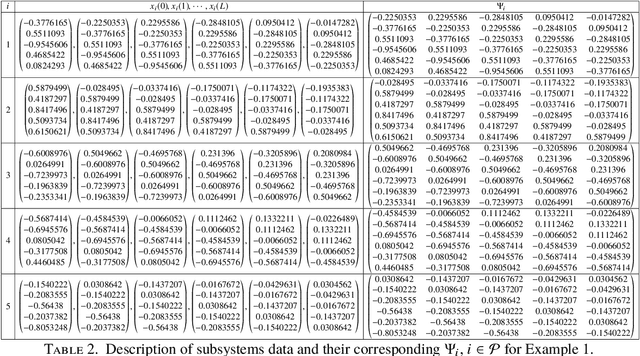
We present an algorithm to compute stabilizing minimum dwell times for discrete-time switched linear systems without the explicit knowledge of state-space models of their subsystems. Given a set of finite traces of state trajectories of the subsystems that satisfies certain properties, our algorithm involves the following tasks: first, multiple Lyapunov functions are designed from the given data; second, a set of relevant scalars is computed from these functions; and third, a stabilizing minimum dwell time is determined as a function of these scalars. A numerical example is presented to demonstrate the proposed algorithm.