 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Anomaly Subsequence Detection with Dynamic Local Density for Time Series
Jun 28, 2019
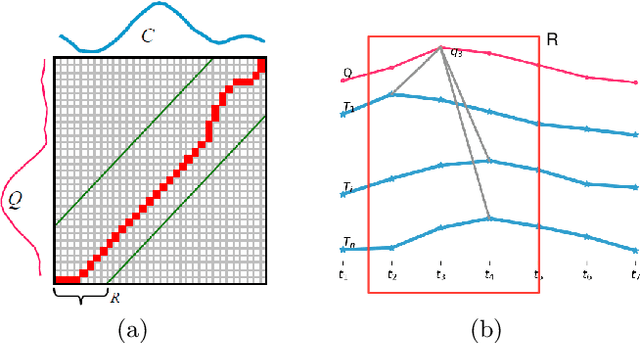
Anomaly subsequence detection is to detect inconsistent data, which always contains important information, among time series. Due to the high dimensionality of the time series, traditional anomaly detection often requires a large time overhead; furthermore, even if the dimensionality reduction techniques can improve the efficiency, they will lose some information and suffer from time drift and parameter tuning. In this paper, we propose a new anomaly subsequence detection with Dynamic Local Density Estimation (DLDE) to improve the detection effect without losing the trend information by dynamically dividing the time series using Time Split Tree. In order to avoid the impact of the hash function and the randomness of dynamic time segments, ensemble learning is used. Experimental results on different types of data sets verify that the proposed model outperforms the state-of-art methods, and the accuracy has big improvement.
Shrub Ensembles for Online Classification
Dec 07, 2021
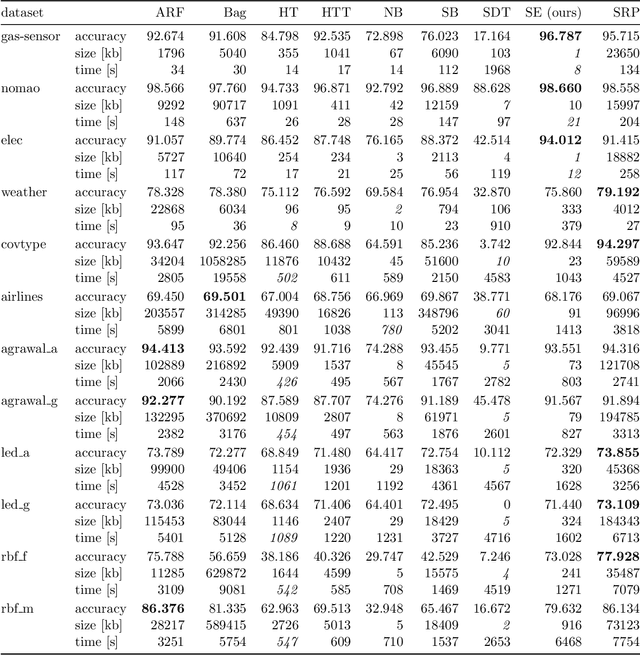
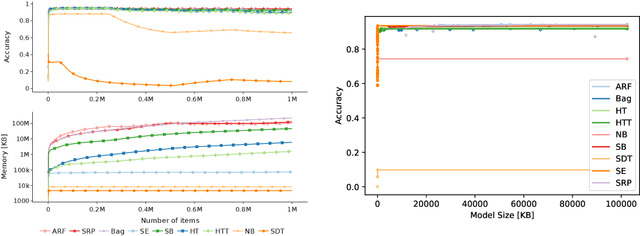
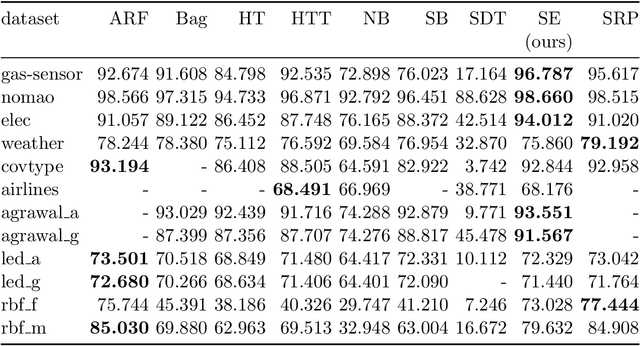
Online learning algorithms have become a ubiquitous tool in the machine learning toolbox and are frequently used in small, resource-constraint environments. Among the most successful online learning methods are Decision Tree (DT) ensembles. DT ensembles provide excellent performance while adapting to changes in the data, but they are not resource efficient. Incremental tree learners keep adding new nodes to the tree but never remove old ones increasing the memory consumption over time. Gradient-based tree learning, on the other hand, requires the computation of gradients over the entire tree which is costly for even moderately sized trees. In this paper, we propose a novel memory-efficient online classification ensemble called shrub ensembles for resource-constraint systems. Our algorithm trains small to medium-sized decision trees on small windows and uses stochastic proximal gradient descent to learn the ensemble weights of these `shrubs'. We provide a theoretical analysis of our algorithm and include an extensive discussion on the behavior of our approach in the online setting. In a series of 2~959 experiments on 12 different datasets, we compare our method against 8 state-of-the-art methods. Our Shrub Ensembles retain an excellent performance even when only little memory is available. We show that SE offers a better accuracy-memory trade-off in 7 of 12 cases, while having a statistically significant better performance than most other methods. Our implementation is available under https://github.com/sbuschjaeger/se-online .
Learning to Align Sequential Actions in the Wild
Nov 17, 2021
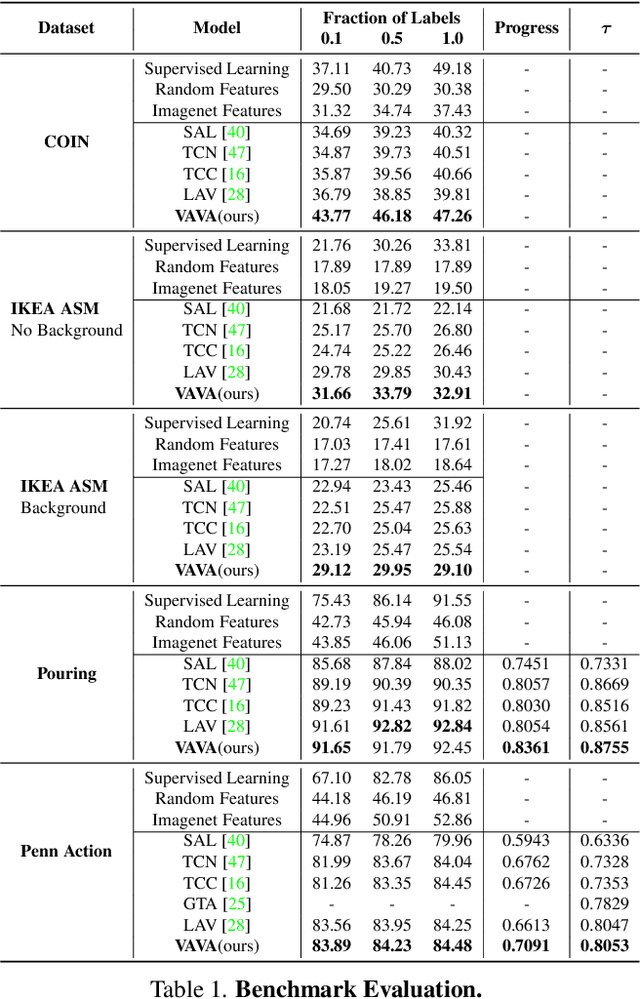
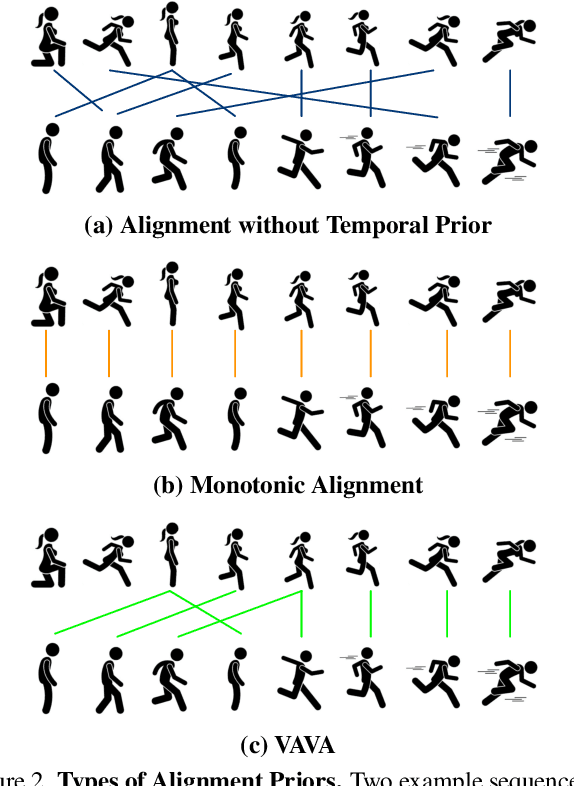
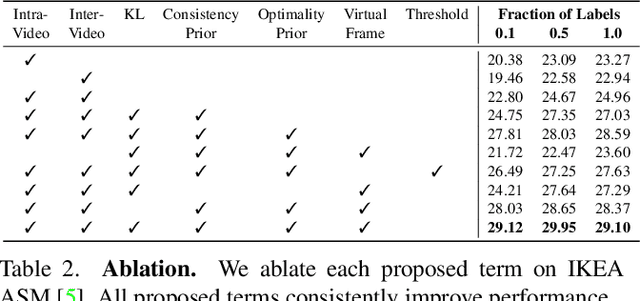
State-of-the-art methods for self-supervised sequential action alignment rely on deep networks that find correspondences across videos in time. They either learn frame-to-frame mapping across sequences, which does not leverage temporal information, or assume monotonic alignment between each video pair, which ignores variations in the order of actions. As such, these methods are not able to deal with common real-world scenarios that involve background frames or videos that contain non-monotonic sequence of actions. In this paper, we propose an approach to align sequential actions in the wild that involve diverse temporal variations. To this end, we propose an approach to enforce temporal priors on the optimal transport matrix, which leverages temporal consistency, while allowing for variations in the order of actions. Our model accounts for both monotonic and non-monotonic sequences and handles background frames that should not be aligned. We demonstrate that our approach consistently outperforms the state-of-the-art in self-supervised sequential action representation learning on four different benchmark datasets.
Deep Kernel Survival Analysis and Subject-Specific Survival Time Prediction Intervals
Jul 25, 2020Kernel survival analysis methods predict subject-specific survival curves and times using information about which training subjects are most similar to a test subject. These most similar training subjects could serve as forecast evidence. How similar any two subjects are is given by the kernel function. In this paper, we present the first neural network framework that learns which kernel functions to use in kernel survival analysis. We also show how to use kernel functions to construct prediction intervals of survival time estimates that are statistically valid for individuals similar to a test subject. These prediction intervals can use any kernel function, such as ones learned using our neural kernel learning framework or using random survival forests. Our experiments show that our neural kernel survival estimators are competitive with a variety of existing survival analysis methods, and that our prediction intervals can help compare different methods' uncertainties, even for estimators that do not use kernels. In particular, these prediction interval widths can be used as a new performance metric for survival analysis methods.
A Comparison of Deep Learning Architectures for Optical Galaxy Morphology Classification
Nov 08, 2021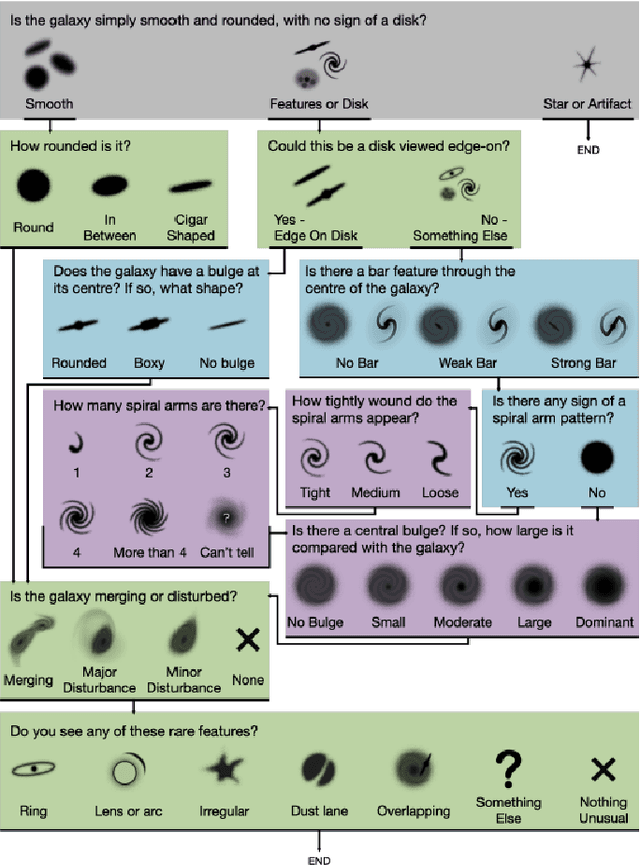
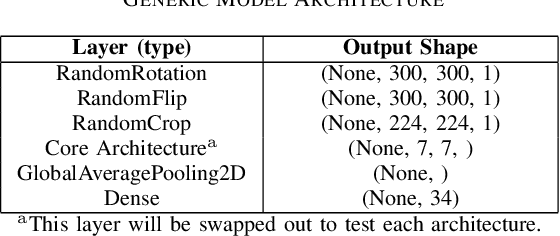

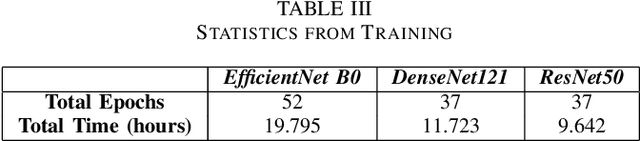
The classification of galaxy morphology plays a crucial role in understanding galaxy formation and evolution. Traditionally, this process is done manually. The emergence of deep learning techniques has given room for the automation of this process. As such, this paper offers a comparison of deep learning architectures to determine which is best suited for optical galaxy morphology classification. Adapting the model training method proposed by Walmsley et al in 2021, the Zoobot Python library is used to train models to predict Galaxy Zoo DECaLS decision tree responses, made by volunteers, using EfficientNet B0, DenseNet121 and ResNet50 as core model architectures. The predicted results are then used to generate accuracy metrics per decision tree question to determine architecture performance. DenseNet121 was found to produce the best results, in terms of accuracy, with a reasonable training time. In future, further testing with more deep learning architectures could prove beneficial.
An Automatic Approach for Generating Rich, Linked Geo-Metadata from Historical Map Images
Dec 03, 2021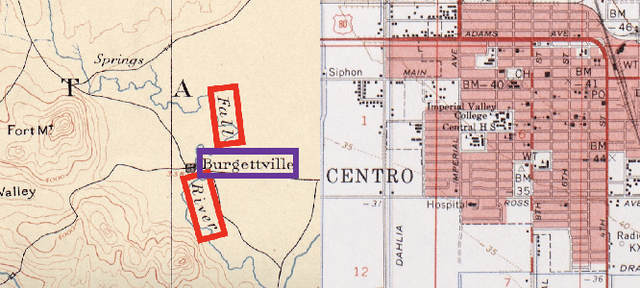
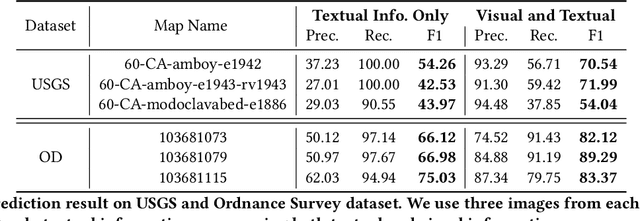
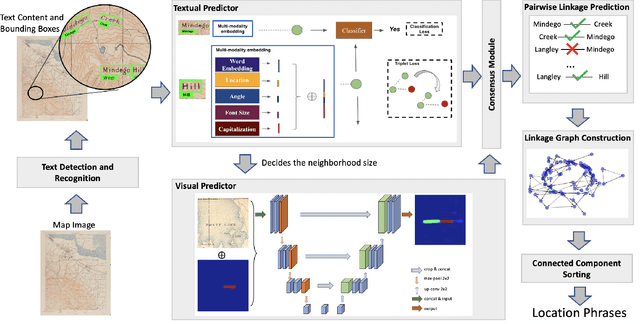
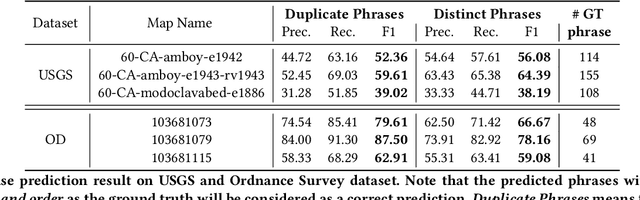
Historical maps contain detailed geographic information difficult to find elsewhere covering long-periods of time (e.g., 125 years for the historical topographic maps in the US). However, these maps typically exist as scanned images without searchable metadata. Existing approaches making historical maps searchable rely on tedious manual work (including crowd-sourcing) to generate the metadata (e.g., geolocations and keywords). Optical character recognition (OCR) software could alleviate the required manual work, but the recognition results are individual words instead of location phrases (e.g., "Black" and "Mountain" vs. "Black Mountain"). This paper presents an end-to-end approach to address the real-world problem of finding and indexing historical map images. This approach automatically processes historical map images to extract their text content and generates a set of metadata that is linked to large external geospatial knowledge bases. The linked metadata in the RDF (Resource Description Framework) format support complex queries for finding and indexing historical maps, such as retrieving all historical maps covering mountain peaks higher than 1,000 meters in California. We have implemented the approach in a system called mapKurator. We have evaluated mapKurator using historical maps from several sources with various map styles, scales, and coverage. Our results show significant improvement over the state-of-the-art methods. The code has been made publicly available as modules of the Kartta Labs project at https://github.com/kartta-labs/Project.
IV-GNN : Interval Valued Data Handling Using Graph Neural Network
Nov 17, 2021
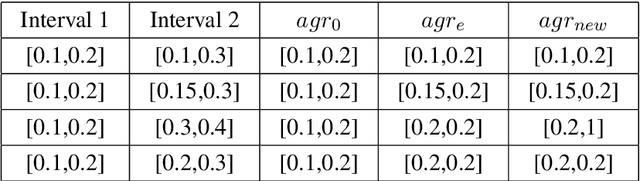

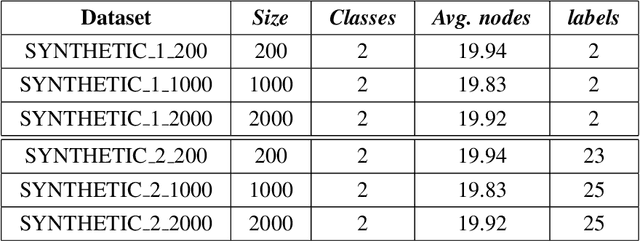
Graph Neural Network (GNN) is a powerful tool to perform standard machine learning on graphs. To have a Euclidean representation of every node in the Non-Euclidean graph-like data, GNN follows neighbourhood aggregation and combination of information recursively along the edges of the graph. Despite having many GNN variants in the literature, no model can deal with graphs having nodes with interval-valued features. This article proposes an Interval-ValuedGraph Neural Network, a novel GNN model where, for the first time, we relax the restriction of the feature space being countable. Our model is much more general than existing models as any countable set is always a subset of the universal set $R^{n}$, which is uncountable. Here, to deal with interval-valued feature vectors, we propose a new aggregation scheme of intervals and show its expressive power to capture different interval structures. We validate our theoretical findings about our model for graph classification tasks by comparing its performance with those of the state-of-the-art models on several benchmark network and synthetic datasets.
Understanding mobility in networks: A node embedding approach
Nov 11, 2021
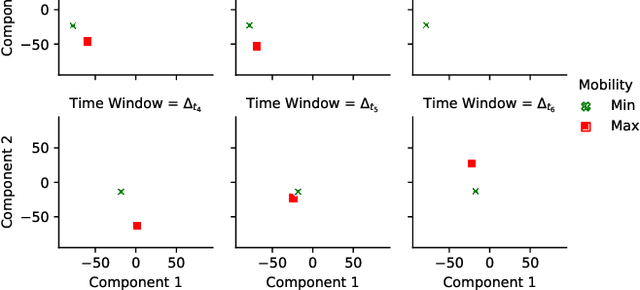

Motivated by the growing number of mobile devices capable of connecting and exchanging messages, we propose a methodology aiming to model and analyze node mobility in networks. We note that many existing solutions in the literature rely on topological measurements calculated directly on the graph of node contacts, aiming to capture the notion of the node's importance in terms of connectivity and mobility patterns beneficial for prototyping, design, and deployment of mobile networks. However, each measure has its specificity and fails to generalize the node importance notions that ultimately change over time. Unlike previous approaches, our methodology is based on a node embedding method that models and unveils the nodes' importance in mobility and connectivity patterns while preserving their spatial and temporal characteristics. We focus on a case study based on a trace of group meetings. The results show that our methodology provides a rich representation for extracting different mobility and connectivity patterns, which can be helpful for various applications and services in mobile networks.
Motion Detection using CSI from Raspberry Pi 4
Nov 17, 2021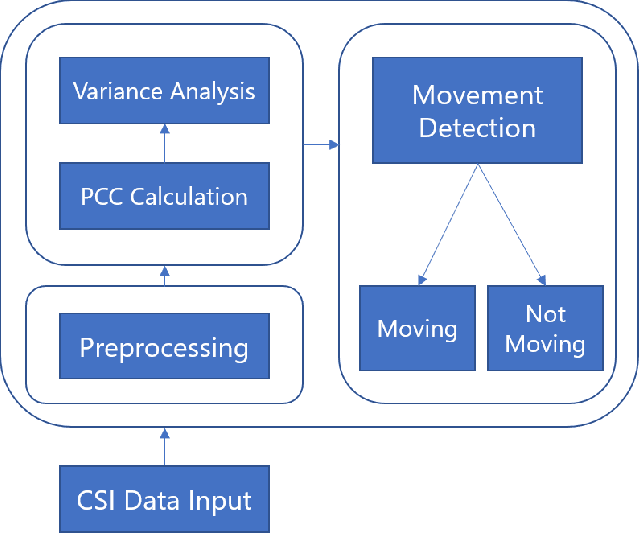
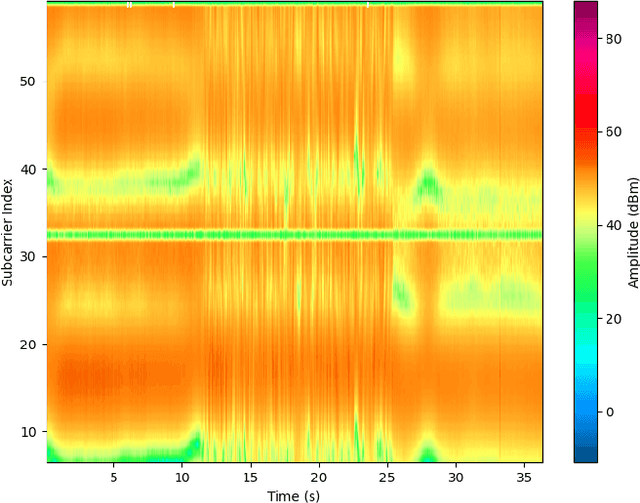
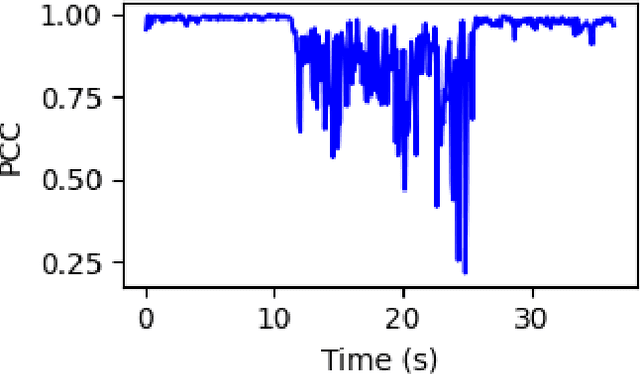
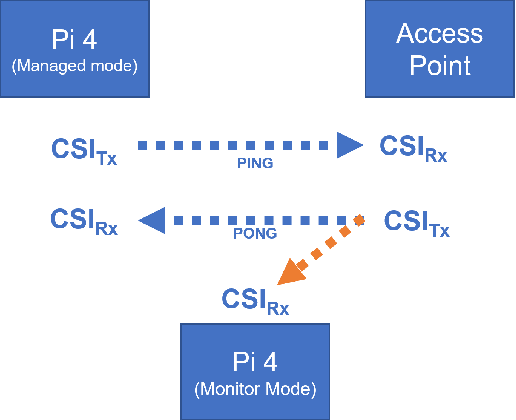
Monitoring behaviour in smart homes using sensors can offer insights into changes in the independent ability and long-term health of residents. Passive Infrared motion sensors (PIRs) are standard, however may not accurately track the full duration of movement. They also require line-of-sight to detect motion which can restrict performance and ensures they must be visible to residents. Channel State Information (CSI) is a low cost, unintrusive form of radio sensing which can monitor movement but also offers opportunities to generate rich data. We have developed a novel, self-calibrating motion detection system which uses CSI data collected and processed on a stock Raspberry Pi 4. This system exploits the correlation between CSI frames, on which we perform variance analysis using our algorithm to accurately measure the full period of a resident's movement. We demonstrate the effectiveness of this approach in several real-world environments. Experiments conducted demonstrate that activity start and end time can be accurately detected for motion examples of different intensities at different locations.
Towards Reliable Real-time Opera Tracking: Combining Alignment with Audio Event Detectors to Increase Robustness
Jun 19, 2020
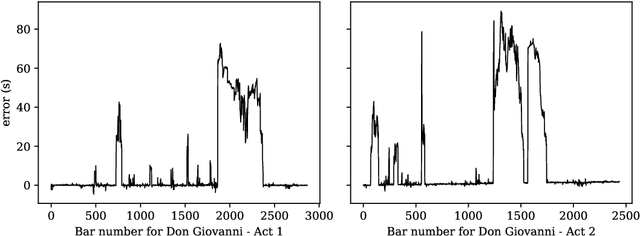


Recent advances in real-time music score following have made it possible for machines to automatically track highly complex polyphonic music, including full orchestra performances. In this paper, we attempt to take this to an even higher level, namely, live tracking of full operas. We first apply a state-of-the-art audio alignment method based on online Dynamic Time-Warping (OLTW) to full-length recordings of a Mozart opera and, analyzing the tracker's most severe errors, identify three common sources of problems specific to the opera scenario. To address these, we propose a combination of a DTW-based music tracker with specialized audio event detectors (for applause, silence/noise, and speech) that condition the DTW algorithm in a top-down fashion, and show, step by step, how these detectors add robustness to the score follower. However, there remain a number of open problems which we identify as targets for ongoing and future research.