 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Time Series Analysis and Forecasting of COVID-19 Cases Using LSTM and ARIMA Models
Jun 05, 2020
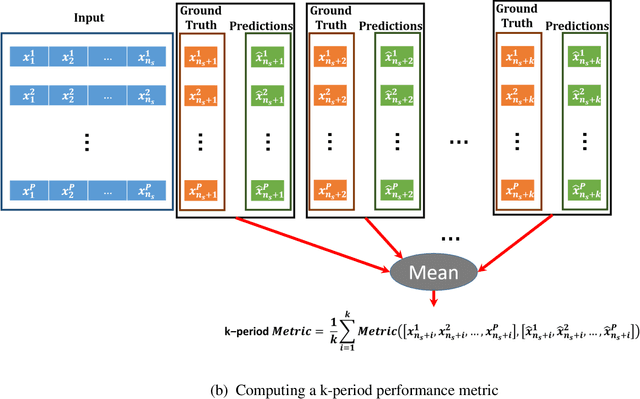
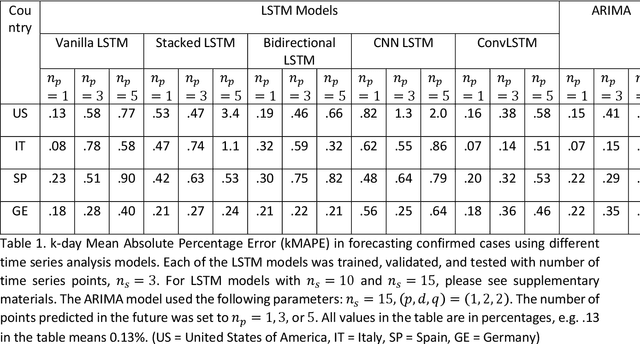
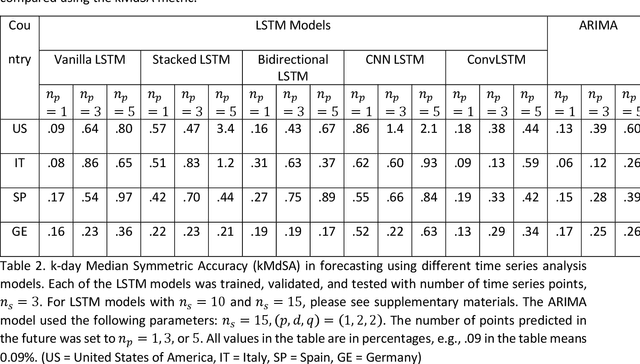
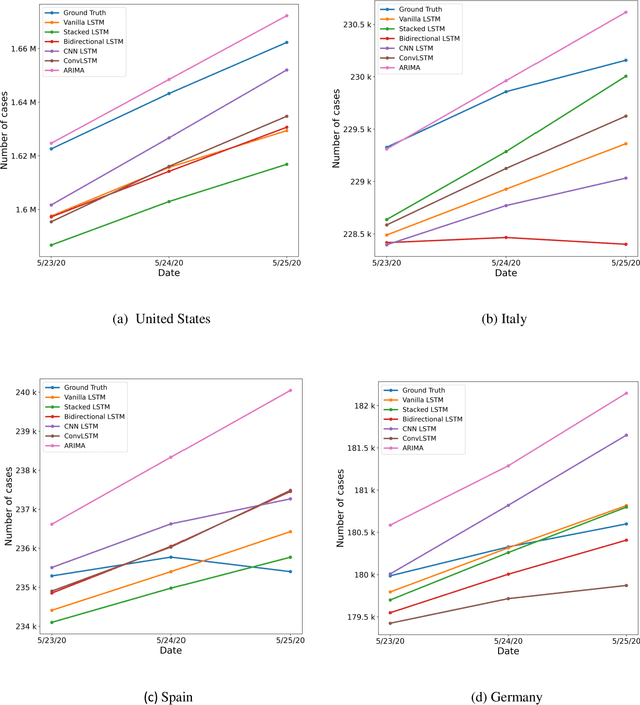
Coronavirus disease 2019 (COVID-19) is a global public health crisis that has been declared a pandemic by World Health Organization. Forecasting country-wise COVID-19 cases is necessary to help policymakers and healthcare providers prepare for the future. This study explores the performance of several Long Short-Term Memory (LSTM) models and Auto-Regressive Integrated Moving Average (ARIMA) model in forecasting the number of confirmed COVID-19 cases. Time series of daily cumulative COVID-19 cases were used for generating 1-day, 3-day, and 5-day forecasts using several LSTM models and ARIMA. Two novel k-period performance metrics - k-day Mean Absolute Percentage Error (kMAPE) and k-day Median Symmetric Accuracy (kMdSA) - were developed for evaluating the performance of the models in forecasting time series values for multiple days. Errors in prediction using kMAPE and kMdSA for LSTM models were both as low as 0.05%, while those for ARIMA were 0.07% and 0.06% respectively. LSTM models slightly underestimated while ARIMA slightly overestimated the numbers in the forecasts. The performance of LSTM models is comparable to ARIMA in forecasting COVID-19 cases. While ARIMA requires longer sequences, LSTMs can perform reasonably well with sequence sizes as small as 3. However, LSTMs require a large number of training samples. Further, the development of k-period performance metrics proposed is likely to be useful for performance evaluation of time series models in predicting multiple periods. Based on the k-period performance metrics proposed, both LSTMs and ARIMA are useful for time series analysis and forecasting for COVID-19.
Fast Footstep Planning on Uneven Terrain Using Deep Sequential Models
Dec 14, 2021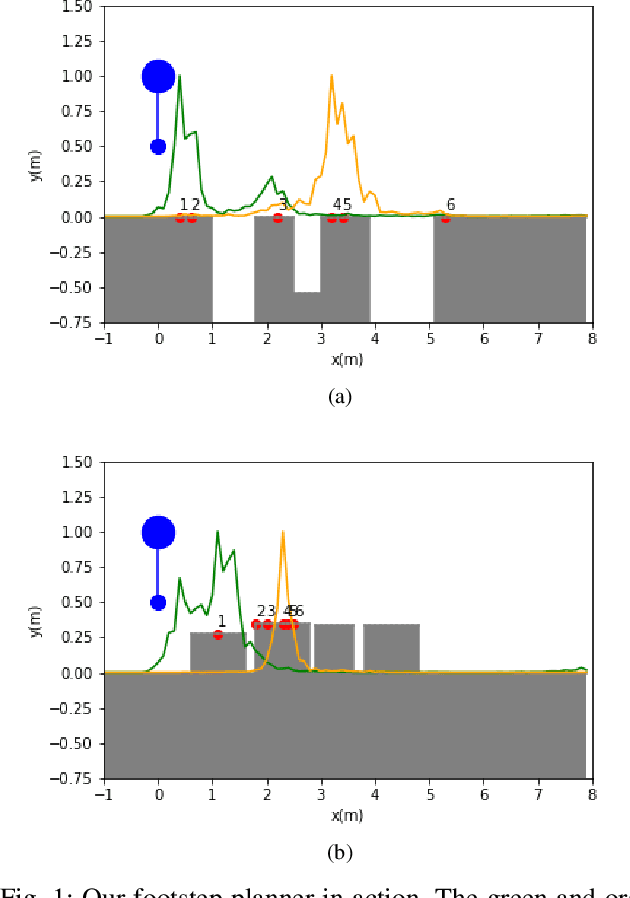
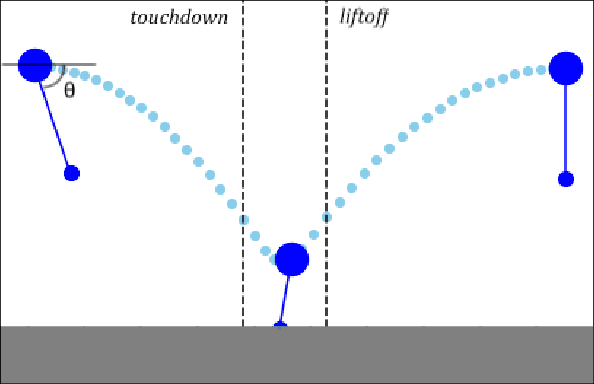
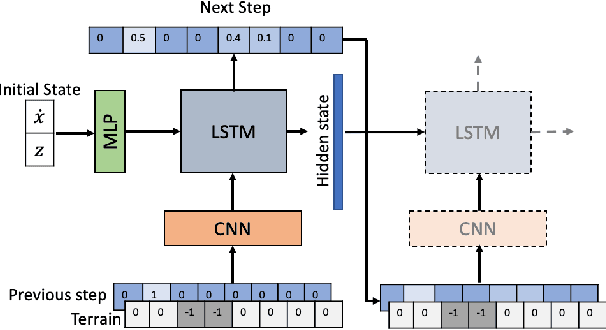
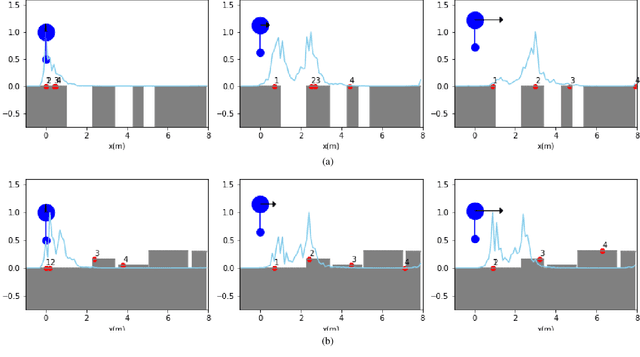
One of the fundamental challenges in realizing the potential of legged robots is generating plans to traverse challenging terrains. Control actions must be carefully selected so the robot will not crash or slip. The high dimensionality of the joint space makes directly planning low-level actions from onboard perception difficult, and control stacks that do not consider the low-level mechanisms of the robot in planning are ill-suited to handle fine-grained obstacles. One method for dealing with this is selecting footstep locations based on terrain characteristics. However, incorporating robot dynamics into footstep planning requires significant computation, much more than in the quasi-static case. In this work, we present an LSTM-based planning framework that learns probability distributions over likely footstep locations using both terrain lookahead and the robot's dynamics, and leverages the LSTM's sequential nature to find footsteps in linear time. Our framework can also be used as a module to speed up sampling-based planners. We validate our approach on a simulated one-legged hopper over a variety of uneven terrains.
Measuring Financial Time Series Similarity With a View to Identifying Profitable Stock Market Opportunities
Jul 07, 2021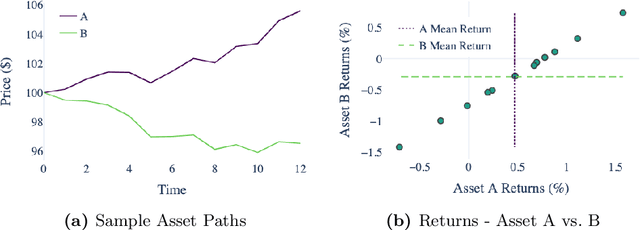
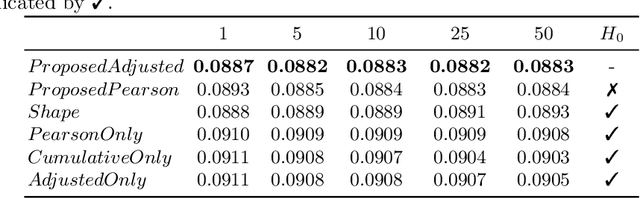
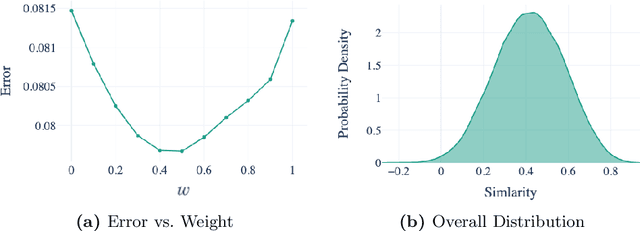
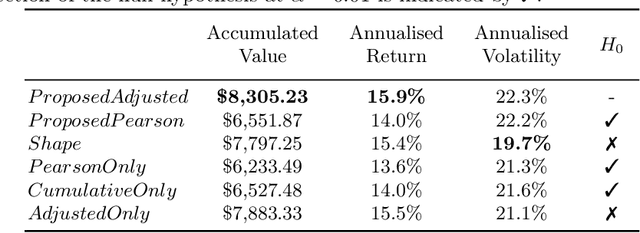
Forecasting stock returns is a challenging problem due to the highly stochastic nature of the market and the vast array of factors and events that can influence trading volume and prices. Nevertheless it has proven to be an attractive target for machine learning research because of the potential for even modest levels of prediction accuracy to deliver significant benefits. In this paper, we describe a case-based reasoning approach to predicting stock market returns using only historical pricing data. We argue that one of the impediments for case-based stock prediction has been the lack of a suitable similarity metric when it comes to identifying similar pricing histories as the basis for a future prediction -- traditional Euclidean and correlation based approaches are not effective for a variety of reasons -- and in this regard, a key contribution of this work is the development of a novel similarity metric for comparing historical pricing data. We demonstrate the benefits of this metric and the case-based approach in a real-world application in comparison to a variety of conventional benchmarks.
A portfolio approach to massively parallel Bayesian optimization
Oct 18, 2021
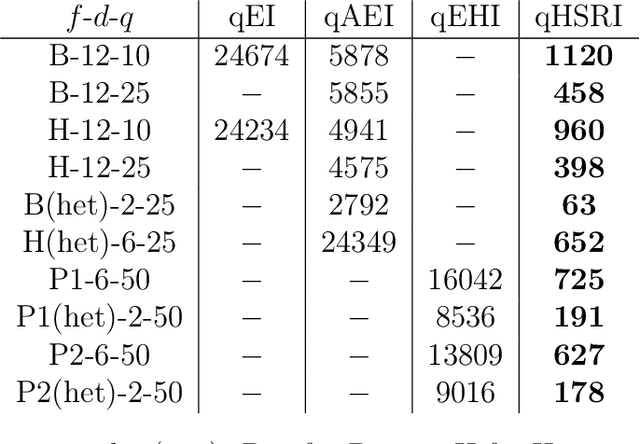
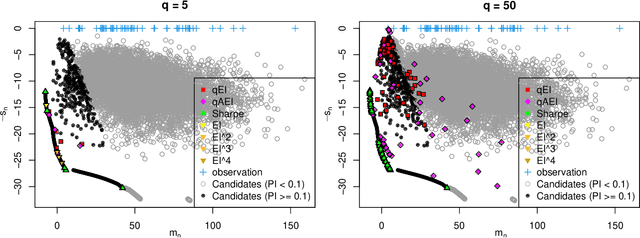
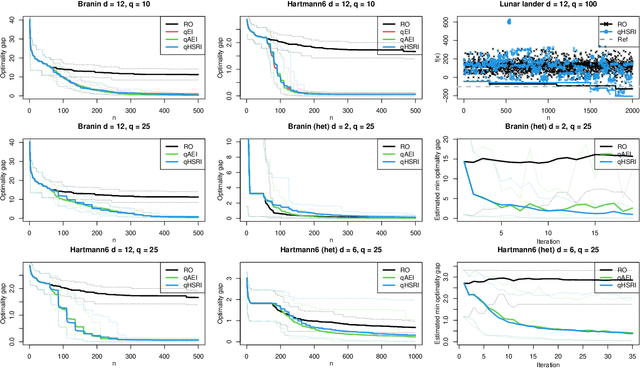
One way to reduce the time of conducting optimization studies is to evaluate designs in parallel rather than just one-at-a-time. For expensive-to-evaluate black-boxes, batch versions of Bayesian optimization have been proposed. They work by building a surrogate model of the black-box that can be used to select the designs to evaluate efficiently via an infill criterion. Still, with higher levels of parallelization becoming available, the strategies that work for a few tens of parallel evaluations become limiting, in particular due to the complexity of selecting more evaluations. It is even more crucial when the black-box is noisy, necessitating more evaluations as well as repeating experiments. Here we propose a scalable strategy that can keep up with massive batching natively, focused on the exploration/exploitation trade-off and a portfolio allocation. We compare the approach with related methods on deterministic and noisy functions, for mono and multiobjective optimization tasks. These experiments show similar or better performance than existing methods, while being orders of magnitude faster.
How to Learn when Data Gradually Reacts to Your Model
Dec 13, 2021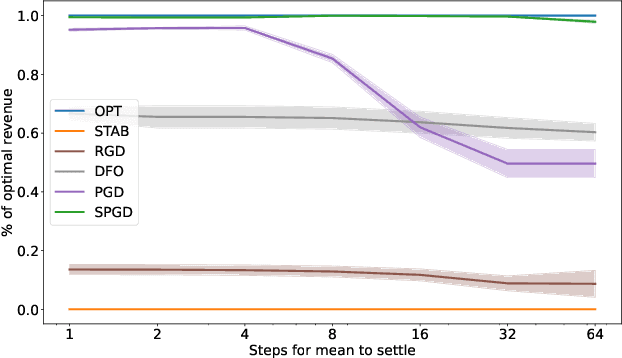
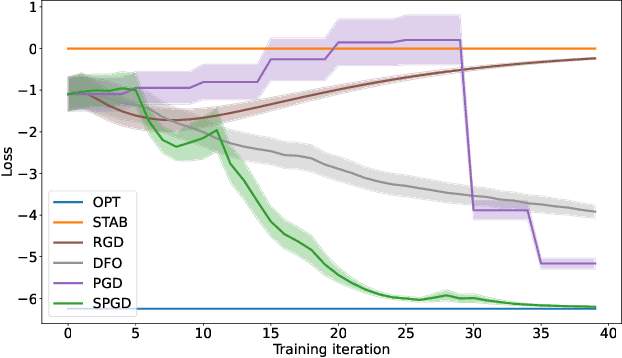
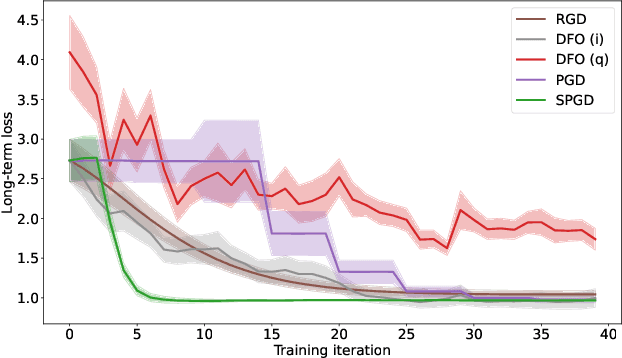
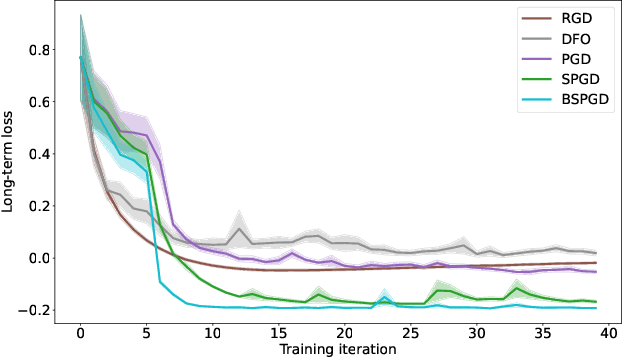
A recent line of work has focused on training machine learning (ML) models in the performative setting, i.e. when the data distribution reacts to the deployed model. The goal in this setting is to learn a model which both induces a favorable data distribution and performs well on the induced distribution, thereby minimizing the test loss. Previous work on finding an optimal model assumes that the data distribution immediately adapts to the deployed model. In practice, however, this may not be the case, as the population may take time to adapt to the model. In many applications, the data distribution depends on both the currently deployed ML model and on the "state" that the population was in before the model was deployed. In this work, we propose a new algorithm, Stateful Performative Gradient Descent (Stateful PerfGD), for minimizing the performative loss even in the presence of these effects. We provide theoretical guarantees for the convergence of Stateful PerfGD. Our experiments confirm that Stateful PerfGD substantially outperforms previous state-of-the-art methods.
Pretraining & Reinforcement Learning: Sharpening the Axe Before Cutting the Tree
Oct 06, 2021



Pretraining is a common technique in deep learning for increasing performance and reducing training time, with promising experimental results in deep reinforcement learning (RL). However, pretraining requires a relevant dataset for training. In this work, we evaluate the effectiveness of pretraining for RL tasks, with and without distracting backgrounds, using both large, publicly available datasets with minimal relevance, as well as case-by-case generated datasets labeled via self-supervision. Results suggest filters learned during training on less relevant datasets render pretraining ineffective, while filters learned during training on the in-distribution datasets reliably reduce RL training time and improve performance after 80k RL training steps. We further investigate, given a limited number of environment steps, how to optimally divide the available steps into pretraining and RL training to maximize RL performance. Our code is available on GitHub
Real-Time Panoptic Segmentation from Dense Detections
Dec 03, 2019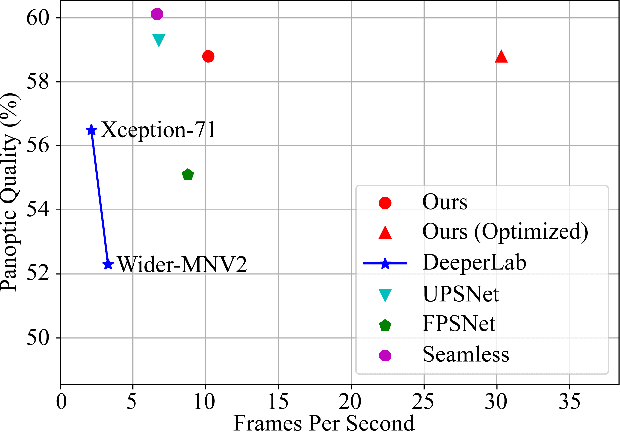
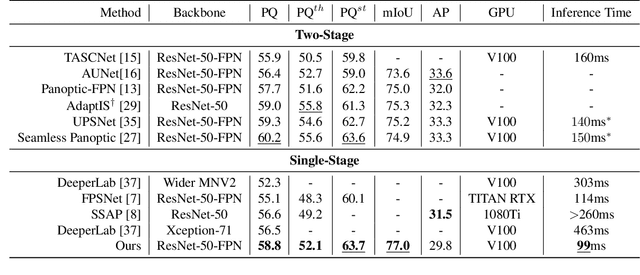
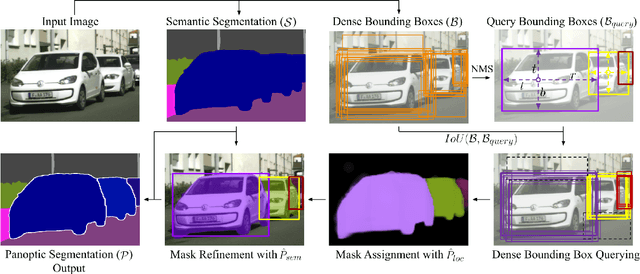
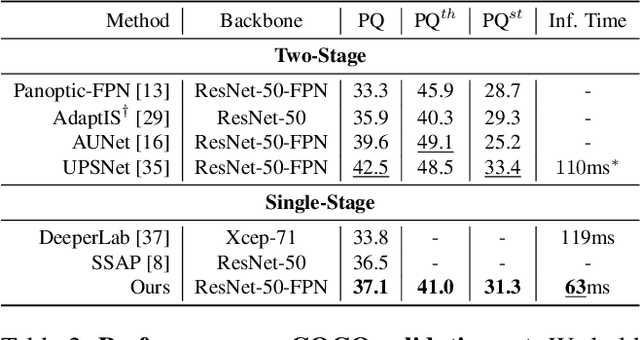
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Explainable Biomedical Recommendations via Reinforcement Learning Reasoning on Knowledge Graphs
Nov 20, 2021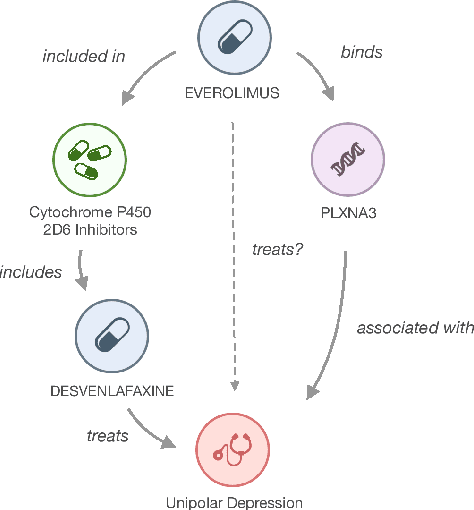

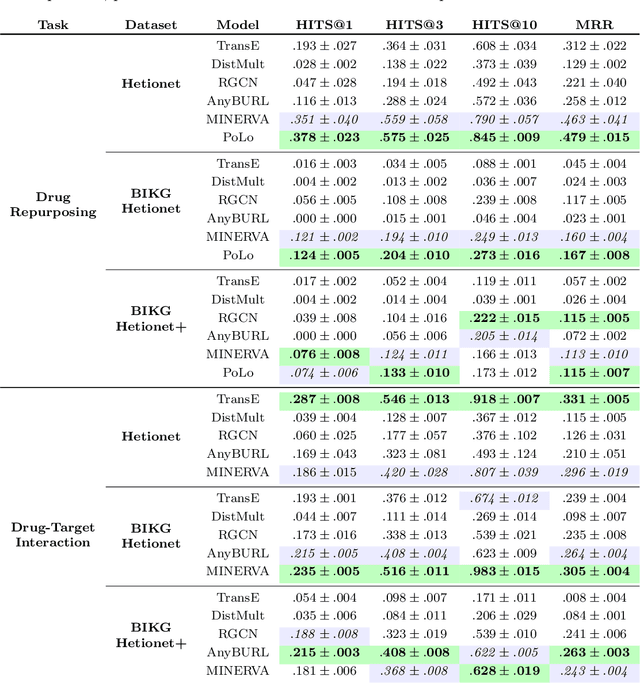
For Artificial Intelligence to have a greater impact in biology and medicine, it is crucial that recommendations are both accurate and transparent. In other domains, a neurosymbolic approach of multi-hop reasoning on knowledge graphs has been shown to produce transparent explanations. However, there is a lack of research applying it to complex biomedical datasets and problems. In this paper, the approach is explored for drug discovery to draw solid conclusions on its applicability. For the first time, we systematically apply it to multiple biomedical datasets and recommendation tasks with fair benchmark comparisons. The approach is found to outperform the best baselines by 21.7% on average whilst producing novel, biologically relevant explanations.
NeuraHealthNLP: An Automated Screening Pipeline to Detect Undiagnosed Cognitive Impairment in Electronic Health Records with Deep Learning and Natural Language Processing
Jan 12, 2022
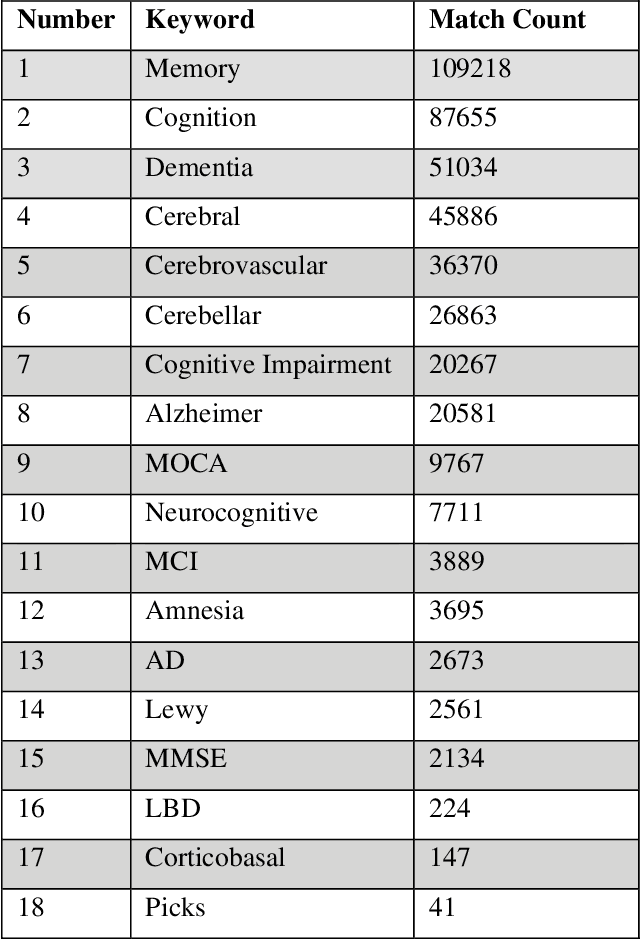
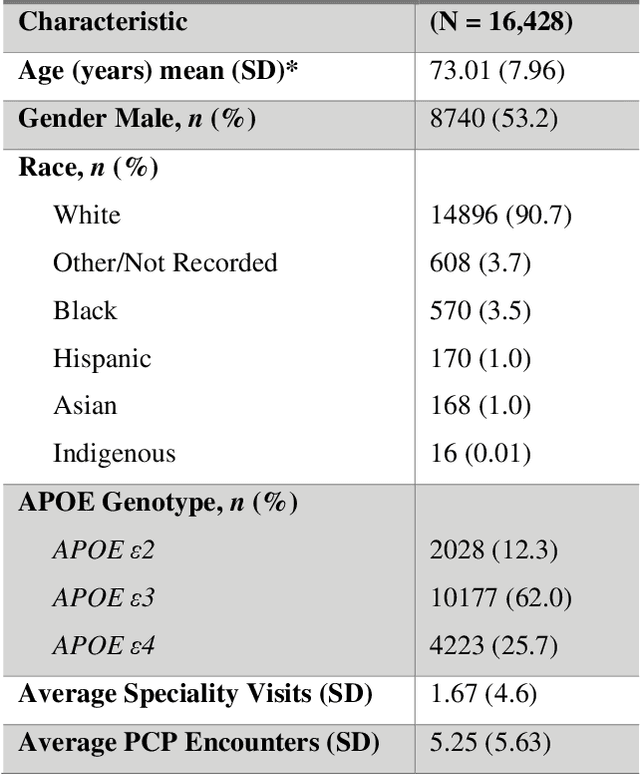

Dementia related cognitive impairment (CI) affects over 55 million people worldwide and is growing rapidly at the rate of one new case every 3 seconds. With a recurring failure of clinical trials, early diagnosis is crucial, but 75% of dementia cases go undiagnosed globally with up to 90% in low-and-middle-income countries. Current diagnostic methods are notoriously complex, involving manual review of medical notes, numerous cognitive tests, expensive brain scans or spinal fluid tests. Information relevant to CI is often found in the electronic health records (EHRs) and can provide vital clues for early diagnosis, but a manual review by experts is tedious and error prone. This project develops a novel state-of-the-art automated screening pipeline for scalable and high-speed discovery of undetected CI in EHRs. To understand the linguistic context from complex language structures in EHR, a database of 8,656 sequences was constructed to train attention-based deep learning natural language processing model to classify sequences. A patient level prediction model based on logistic regression was developed using the sequence level classifier. The deep learning system achieved 93% accuracy and AUC = 0.98 to identify patients who had no earlier diagnosis, dementia-related diagnosis code, or dementia-related medications in their EHR. These patients would have otherwise gone undetected or detected too late. The EHR screening pipeline was deployed in NeuraHealthNLP, a web application for automated and real-time CI screening by simply uploading EHRs in a browser. NeuraHealthNLP is cheaper, faster, more accessible, and outperforms current clinical methods including text-based analytics and machine learning approaches. It makes early diagnosis viable in regions with scarce health care services but accessible internet or cellular services.
Neural Network-Based Feature Extraction for Multi-Class Motor Imagery Classification
Jan 05, 2022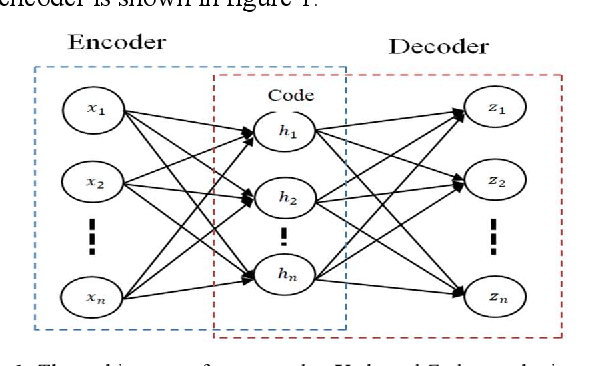
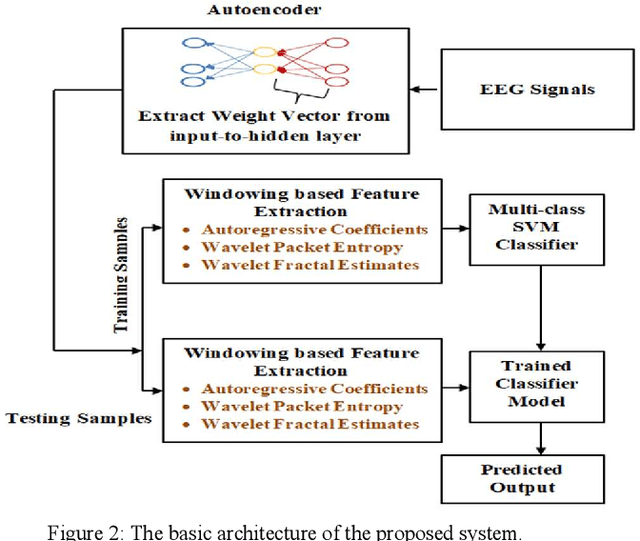
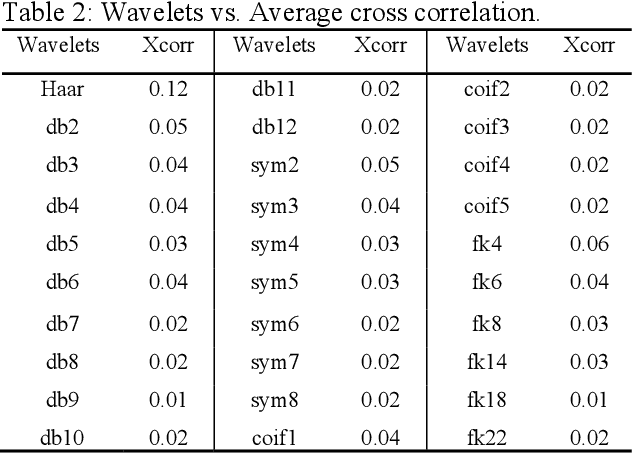
Decoding of motor imagery (MI) from Electroencephalogram (EEG) is an important component of the Brain-Computer Interface (BCI) system that helps motor-disabled people interact with the outside world via external devices. The main issue in developing the EEG based BCI is the informative confusion due to the non-stationary characteristics of EEG data. In this work, an innovative idea of transforming an EEG signal into the weight vector of an unsupervised neural network called the autoencoder is proposed for the first time to solve that problem. Separate autoencoders are trained for the individual EEG data. The weight vectors are then optimized for the individual EEG signals. The EEG signals are thus represented in a new domain that is in the form of weight vectors of the individual autoencoder. The weight vectors are then used to extract features such as autoregressive coefficients (ARs), Shannon entropy (SE), and wavelet leader. A window-based feature extraction technique is implemented to capture the local features of the EEG data. Finally, extracted features are classified using a classifier network. The proposed approach is tested on two publicly accessible EEG datasets (BCI competition-III and Competition-IV) to ensure that it is as successful as and superior to the previously published methods. The proposed technique achieves a mean accuracy of 95.33 % for dataset-IIIa from BCI-III and a mean accuracy of 97% for dataset-IIa from BCI-IV for four-class EEG-based MI classification. The experimental outcomes show that the proposed approach is a promising way to increase BCI performance.