 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vis-TOP: Visual Transformer Overlay Processor
Oct 21, 2021

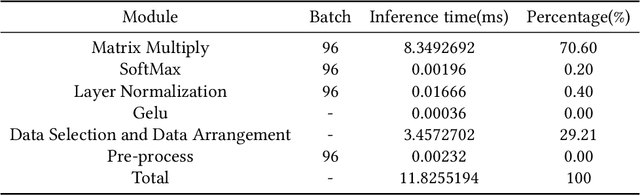
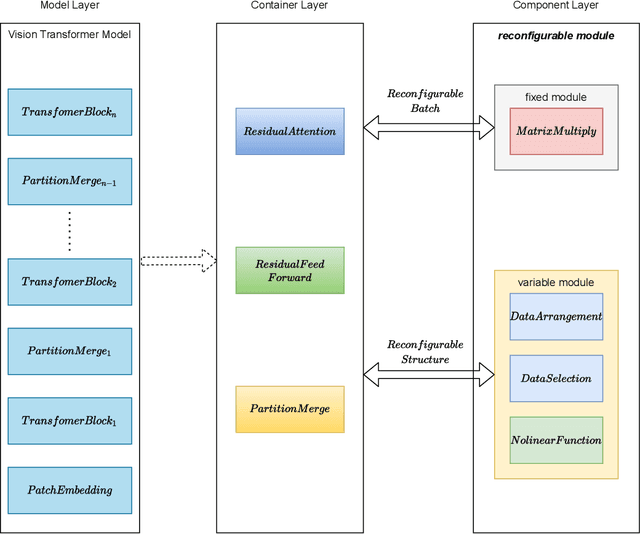
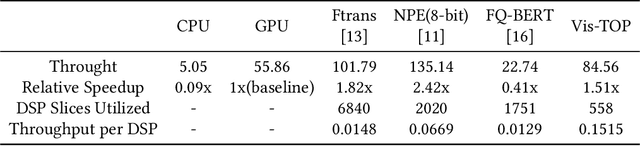
In recent years, Transformer has achieved good results in Natural Language Processing (NLP) and has also started to expand into Computer Vision (CV). Excellent models such as the Vision Transformer and Swin Transformer have emerged. At the same time, the platform for Transformer models was extended to embedded devices to meet some resource-sensitive application scenarios. However, due to the large number of parameters, the complex computational flow and the many different structural variants of Transformer models, there are a number of issues that need to be addressed in its hardware design. This is both an opportunity and a challenge. We propose Vis-TOP (Visual Transformer Overlay Processor), an overlay processor for various visual Transformer models. It differs from coarse-grained overlay processors such as CPU, GPU, NPE, and from fine-grained customized designs for a specific model. Vis-TOP summarizes the characteristics of all visual Transformer models and implements a three-layer and two-level transformation structure that allows the model to be switched or changed freely without changing the hardware architecture. At the same time, the corresponding instruction bundle and hardware architecture are designed in three-layer and two-level transformation structure. After quantization of Swin Transformer tiny model using 8-bit fixed points (fix_8), we implemented an overlay processor on the ZCU102. Compared to GPU, the TOP throughput is 1.5x higher. Compared to the existing Transformer accelerators, our throughput per DSP is between 2.2x and 11.7x higher than others. In a word, the approach in this paper meets the requirements of real-time AI in terms of both resource consumption and inference speed. Vis-TOP provides a cost-effective and power-effective solution based on reconfigurable devices for computer vision at the edge.
Integrated Sensing and Communications for V2I Networks: Dynamic Predictive Beamforming for Extended Vehicle Targets
Nov 19, 2021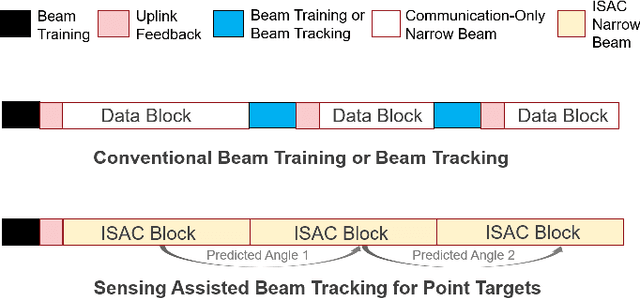
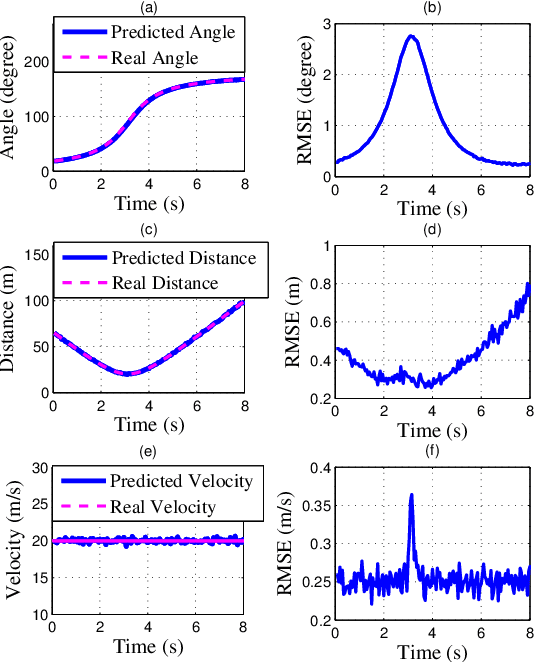
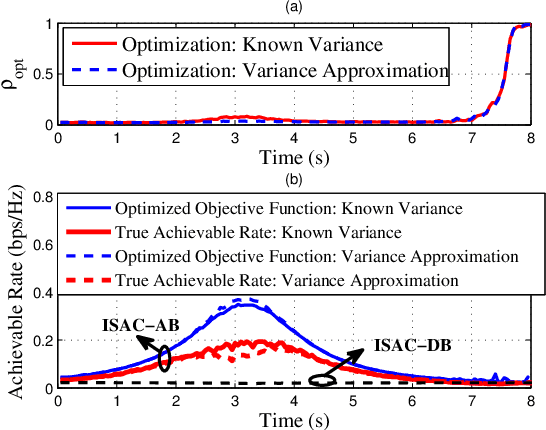
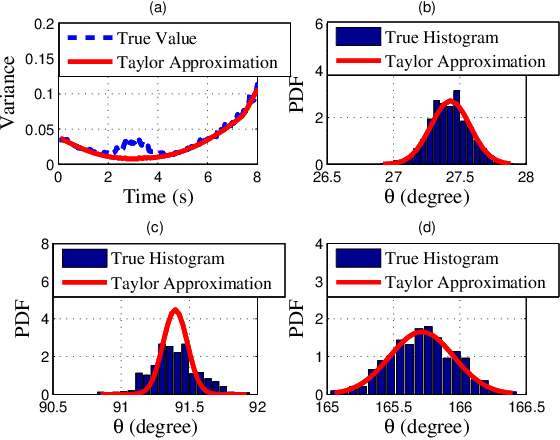
We investigate sensing-assisted predictive beamforming schemes for vehicle-to-infrastructure (V2I) communication by exploiting the integrated sensing and communication (ISAC) functionalities at the roadside unit (RSU). The RSU deploys a massive multi-input-multi-output (mMIMO) array and operates at millimeter wave (mmWave) frequencies. The pencil-sharp mMIMO beams and fine range resolution achieved at mmWave, implicates that the point target assumption is impractical in such V2I networks, as the volume and shape of the vehicles become essential for beamforming. Simply pointing a beam to the vehicle may result in the communication receiver (CR) never lying in the beam, even when the vehicle's trajectory is accurately tracked. To tackle this problem, we consider the extended vehicle target with two novel beam tracking schemes. For the first scheme, the beamwidth is adjusted in real-time to cover the entire vehicle, followed by an extended Kalman filtering (EKF) algorithm to predict and track the position of CR according to the resolved high-resolution scatterers. An upgraded scheme is further proposed by splitting each transmission block into two stages. The first stage is exploited for ISAC transmission, where a wide beam is adopted for both communication and sensing. Based on the sensed results at the first stage, the second stage is dedicated to communication by adopting a pencil-sharp beam, yielding a significant improvement of the achievable rate. We further reveal the inherent tradeoff between the two stages in terms of their durations, and develop an optimal time allocation strategy that maximizes the average achievable rate. Finally, numerical results are provided to verify the superiorities of proposed schemes over the state-of-the-art methods.
Recent Advances in Automated Question Answering In Biomedical Domain
Nov 10, 2021
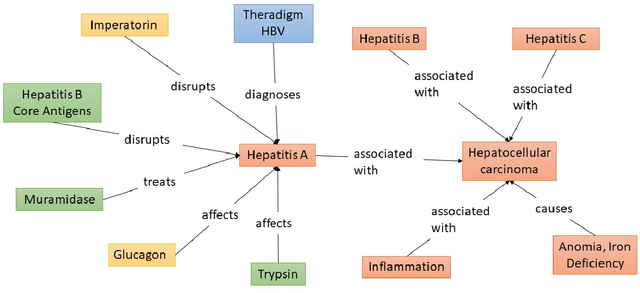
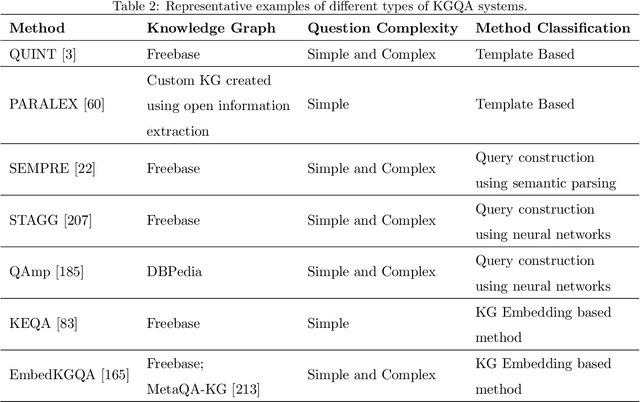
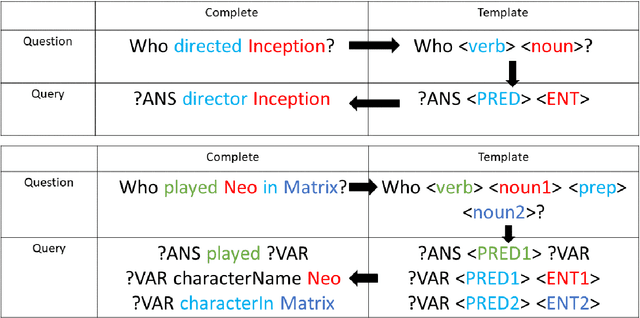
The objective of automated Question Answering (QA) systems is to provide answers to user queries in a time efficient manner. The answers are usually found in either databases (or knowledge bases) or a collection of documents commonly referred to as the corpus. In the past few decades there has been a proliferation of acquisition of knowledge and consequently there has been an exponential growth in new scientific articles in the field of biomedicine. Therefore, it has become difficult to keep track of all the information in the domain, even for domain experts. With the improvements in commercial search engines, users can type in their queries and get a small set of documents most relevant for answering their query, as well as relevant snippets from the documents in some cases. However, it may be still tedious and time consuming to manually look for the required information or answers. This has necessitated the development of efficient QA systems which aim to find exact and precise answers to user provided natural language questions in the domain of biomedicine. In this paper, we introduce the basic methodologies used for developing general domain QA systems, followed by a thorough investigation of different aspects of biomedical QA systems, including benchmark datasets and several proposed approaches, both using structured databases and collection of texts. We also explore the limitations of current systems and explore potential avenues for further advancement.
DeepABM: Scalable, efficient and differentiable agent-based simulations via graph neural networks
Oct 09, 2021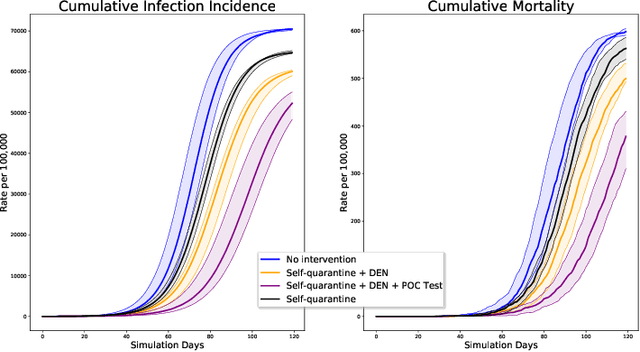

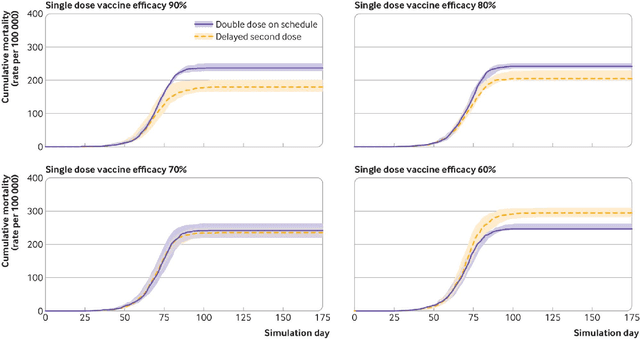
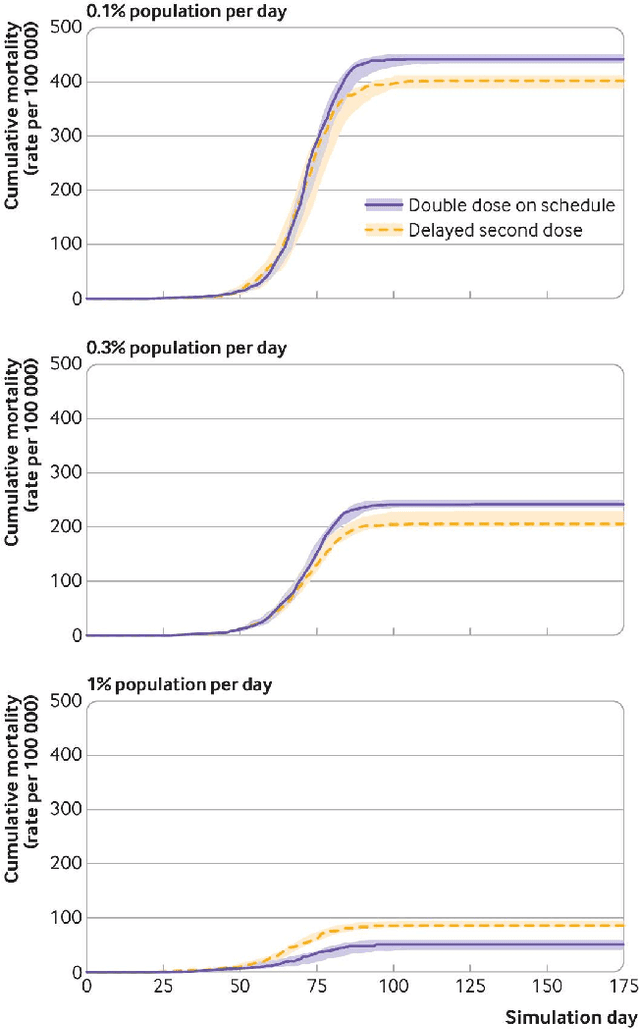
We introduce DeepABM, a framework for agent-based modeling that leverages geometric message passing of graph neural networks for simulating action and interactions over large agent populations. Using DeepABM allows scaling simulations to large agent populations in real-time and running them efficiently on GPU architectures. To demonstrate the effectiveness of DeepABM, we build DeepABM-COVID simulator to provide support for various non-pharmaceutical interventions (quarantine, exposure notification, vaccination, testing) for the COVID-19 pandemic, and can scale to populations of representative size in real-time on a GPU. Specifically, DeepABM-COVID can model 200 million interactions (over 100,000 agents across 180 time-steps) in 90 seconds, and is made available online to help researchers with modeling and analysis of various interventions. We explain various components of the framework and discuss results from one research study to evaluate the impact of delaying the second dose of the COVID-19 vaccine in collaboration with clinical and public health experts. While we simulate COVID-19 spread, the ideas introduced in the paper are generic and can be easily extend to other forms of agent-based simulations. Furthermore, while beyond scope of this document, DeepABM enables inverse agent-based simulations which can be used to learn physical parameters in the (micro) simulations using gradient-based optimization with large-scale real-world (macro) data. We are optimistic that the current work can have interesting implications for bringing ABM and AI communities closer.
Generating GPU Compiler Heuristics using Reinforcement Learning
Nov 23, 2021



GPU compilers are complex software programs with many optimizations specific to target hardware. These optimizations are often controlled by heuristics hand-designed by compiler experts using time- and resource-intensive processes. In this paper, we developed a GPU compiler autotuning framework that uses off-policy deep reinforcement learning to generate heuristics that improve the frame rates of graphics applications. Furthermore, we demonstrate the resilience of these learned heuristics to frequent compiler updates by analyzing their stability across a year of code check-ins without retraining. We show that our machine learning-based compiler autotuning framework matches or surpasses the frame rates for 98% of graphics benchmarks with an average uplift of 1.6% up to 15.8%.
Integrating Imitation Learning with Human Driving Data into Reinforcement Learning to Improve Training Efficiency for Autonomous Driving
Nov 23, 2021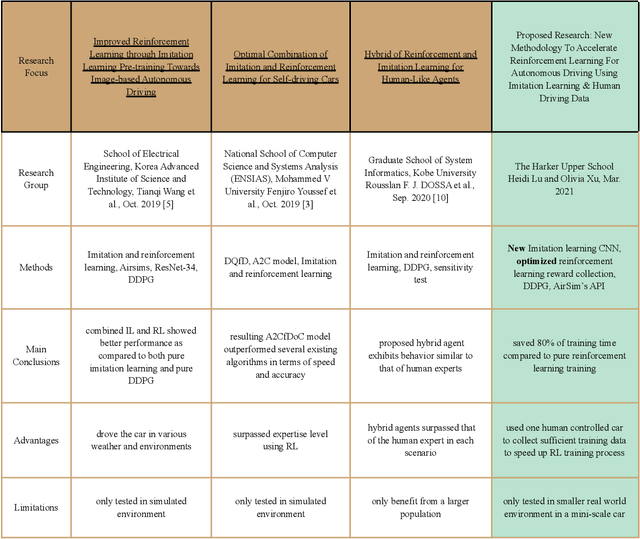
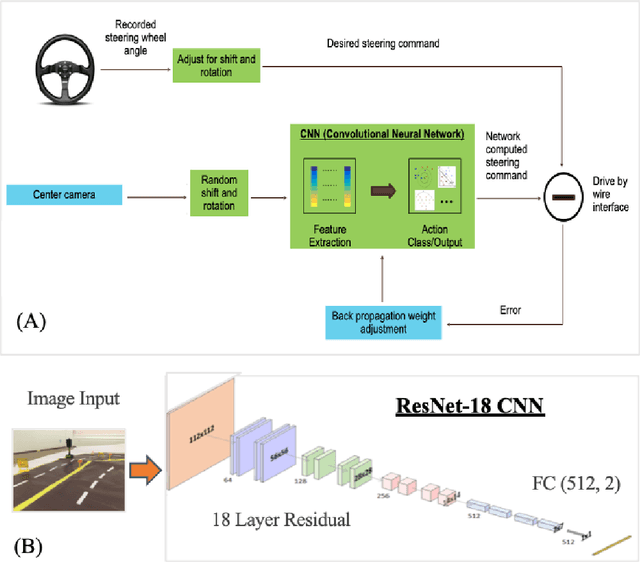
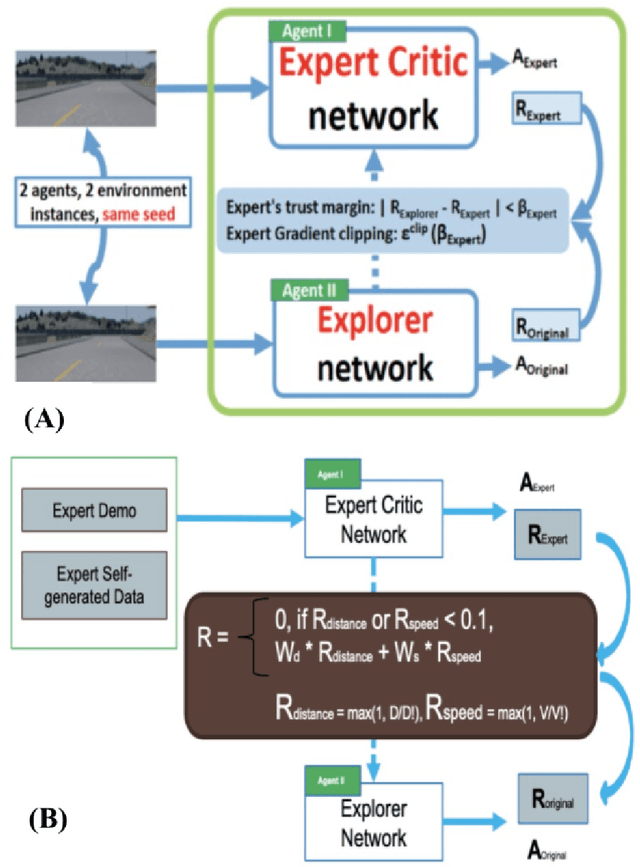
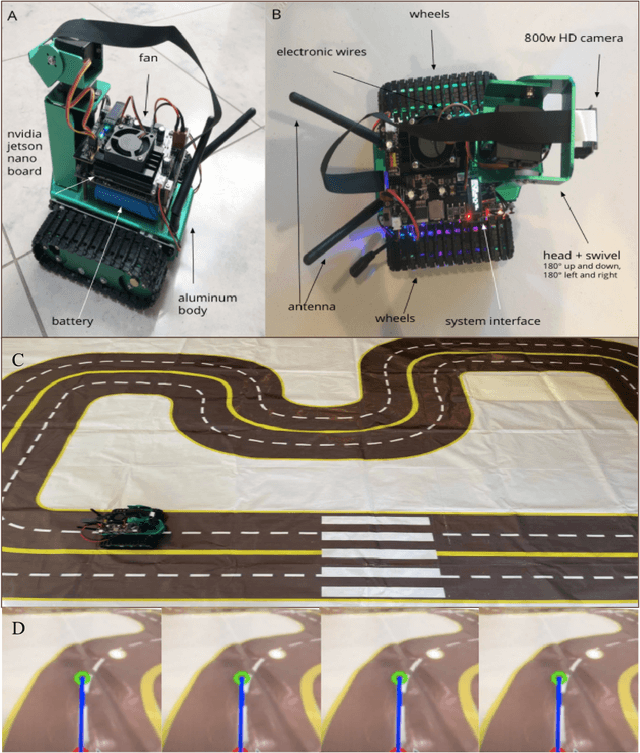
Two current methods used to train autonomous cars are reinforcement learning and imitation learning. This research develops a new learning methodology and systematic approach in both a simulated and a smaller real world environment by integrating supervised imitation learning into reinforcement learning to make the RL training data collection process more effective and efficient. By combining the two methods, the proposed research successfully leverages the advantages of both RL and IL methods. First, a real mini-scale robot car was assembled and trained on a 6 feet by 9 feet real world track using imitation learning. During the process, a handle controller was used to control the mini-scale robot car to drive on the track by imitating a human expert driver and manually recorded the actions using Microsoft AirSim's API. 331 accurate human-like reward training samples were able to be generated and collected. Then, an agent was trained in the Microsoft AirSim simulator using reinforcement learning for 6 hours with the initial 331 reward data inputted from imitation learning training. After a 6-hour training period, the mini-scale robot car was able to successfully drive full laps around the 6 feet by 9 feet track autonomously while the mini-scale robot car was unable to complete one full lap round the track even after 30 hour training pure RL training. With 80% less training time, the new methodology produced significantly more average rewards per hour. Thus, the new methodology was able to save a significant amount of training time and can be used to accelerate the adoption of RL in autonomous driving, which would help produce more efficient and better results in the long run when applied to real life scenarios. Key Words: Reinforcement Learning (RL), Imitation Learning (IL), Autonomous Driving, Human Driving Data, CNN
Adaptive Bayesian Sum of Trees Model for Covariate Dependent Spectral Analysis
Sep 29, 2021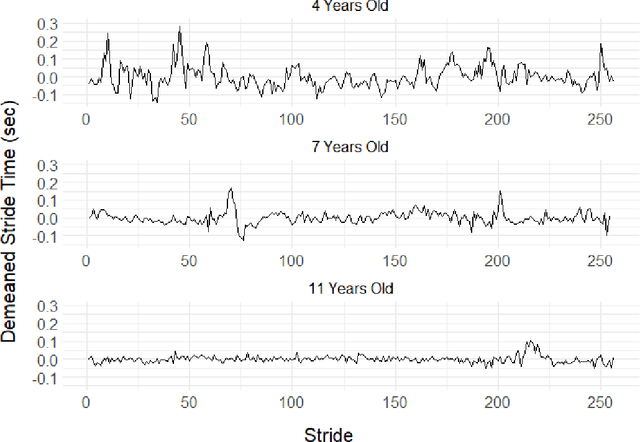
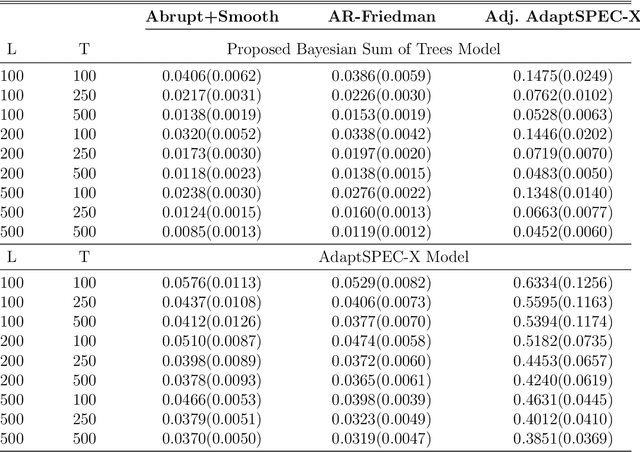
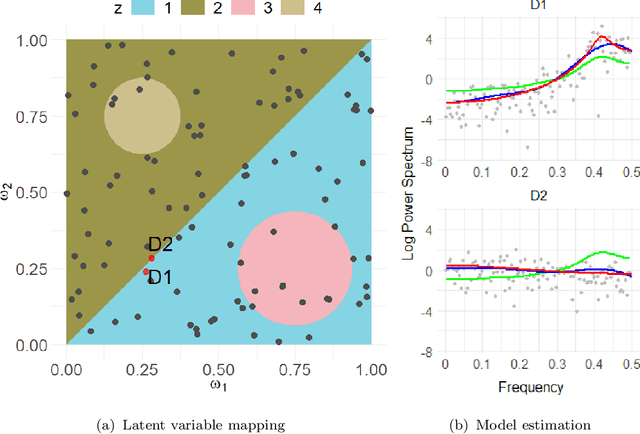
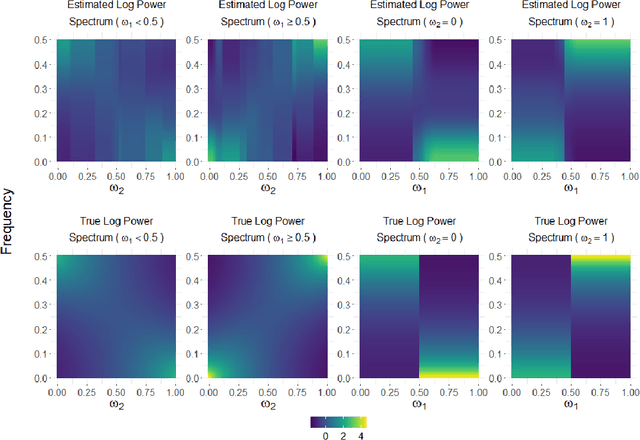
This article introduces a flexible and adaptive nonparametric method for estimating the association between multiple covariates and power spectra of multiple time series. The proposed approach uses a Bayesian sum of trees model to capture complex dependencies and interactions between covariates and the power spectrum, which are often observed in studies of biomedical time series. Local power spectra corresponding to terminal nodes within trees are estimated nonparametrically using Bayesian penalized linear splines. The trees are considered to be random and fit using a Bayesian backfitting Markov chain Monte Carlo (MCMC) algorithm that sequentially considers tree modifications via reversible-jump MCMC techniques. For high-dimensional covariates, a sparsity-inducing Dirichlet hyperprior on tree splitting proportions is considered, which provides sparse estimation of covariate effects and efficient variable selection. By averaging over the posterior distribution of trees, the proposed method can recover both smooth and abrupt changes in the power spectrum across multiple covariates. Empirical performance is evaluated via simulations to demonstrate the proposed method's ability to accurately recover complex relationships and interactions. The proposed methodology is used to study gait maturation in young children by evaluating age-related changes in power spectra of stride interval time series in the presence of other covariates.
A case study on profiling of an EEG-based brain decoding interface on Cloud and Edge servers
Oct 04, 2021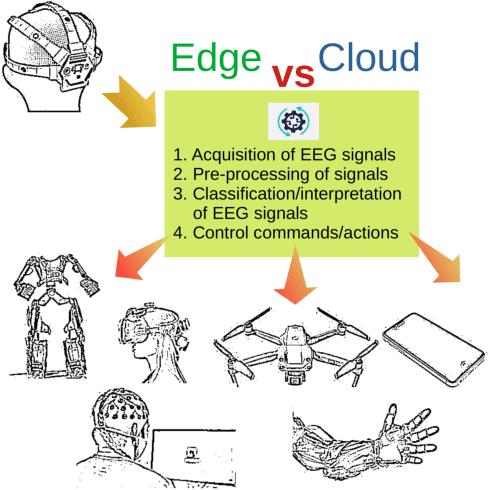
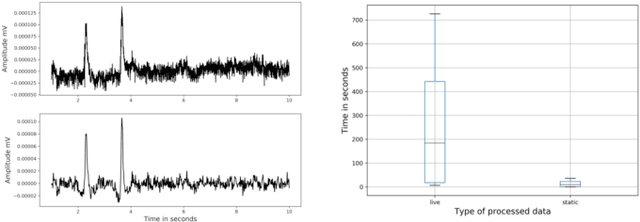
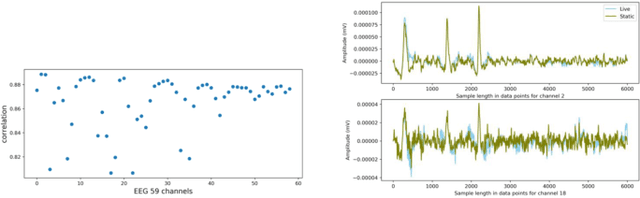
Brain-Computer Interfaces (BCIs) enable converting the brain electrical activity of an interface user to the user commands. BCI research studies demonstrated encouraging results in different areas such as neurorehabilitation, control of artificial limbs, control of computer environments, communication and detection of diseases. Most of BCIs use scalp-electroencephalography (EEG), which is a non-invasive method to capture the brain activity. Although EEG monitoring devices are available in the market, these devices are generally lab-oriented and expensive. Day-to-day use of BCIs is impractical at this time due to the complex techniques required for data preprocessing and signal analysis. This implies that BCI technologies should be improved to facilitate its widespread adoption in Cloud and Edge datacenters. This paper presents a case study on profiling the accuracy and performance of a brain-computer interface which runs on typical Cloud and Edge servers. In particular, we investigate how the accuracy and execution time of the preprocessing phase, i.e. the brain signal filtering phase, of a brain-computer interface varies when processing static and live streaming data obtained in real time BCI devices. We identify the optimal size of the packets for sampling brain signals which provides the best trade-off between the accuracy and performance. Finally, we discuss the pros and cons of using typical Cloud and Edge servers to perform the BCI filtering phase.
Noninvasive ultrasound for Lithium-ion batteries state estimation
Oct 26, 2021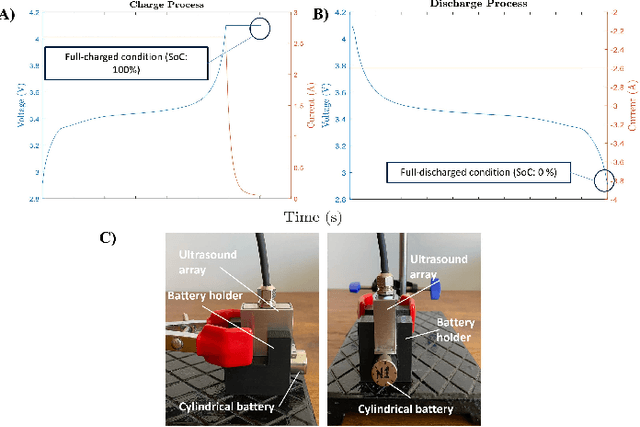
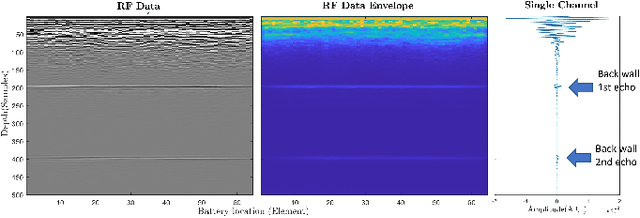
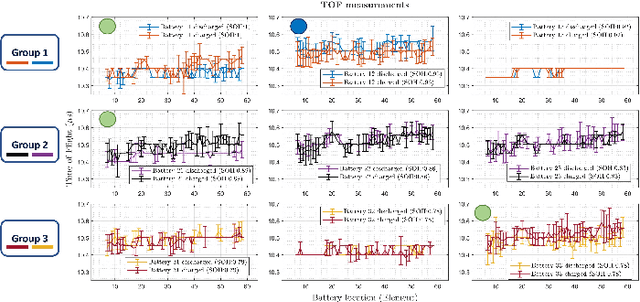
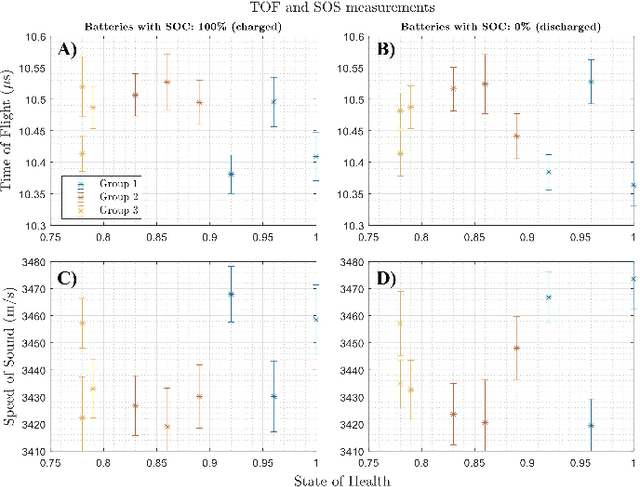
Lithium-ion battery degradation estimation using fast and noninvasive techniques is a crucial issue in the circular economy framework of this technology. Currently, most of the approaches used to establish the battery-state (i.e., State of Charge (SoC), State of Health (SoH)) require time-consuming processes. In the present preliminary study, an ultrasound array was used to assess the influence of the SoC and SoH on the variations in the time of flight (TOF) and the speed of sound (SOS) of the ultrasound wave inside the batteries. Nine aged 18650 Lithium-ion batteries were imaged at 100% and 0% SoC using a Vantage-256 system (Verasonics, Inc.) equipped with a 64-element ultrasound array and a center frequency of 5 MHz (Imasonic SAS). It was found that second-life batteries have a complex ultrasound response due to the presence of many degradation pathways and, thus, making it harder to analyze the ultrasound measurements. Although further analysis must be done to elucidate a clear correlation between changes in the ultrasound wave properties and the battery state estimation, this approach seems very promising for future nondestructive evaluation of second-life batteries.
AIDA: An Active Inference-based Design Agent for Audio Processing Algorithms
Dec 26, 2021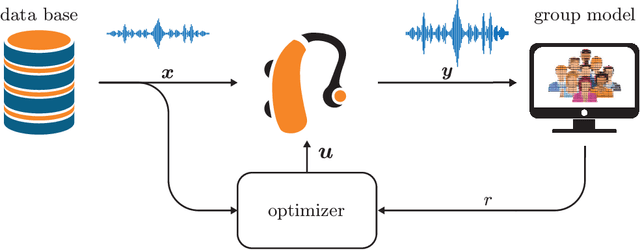
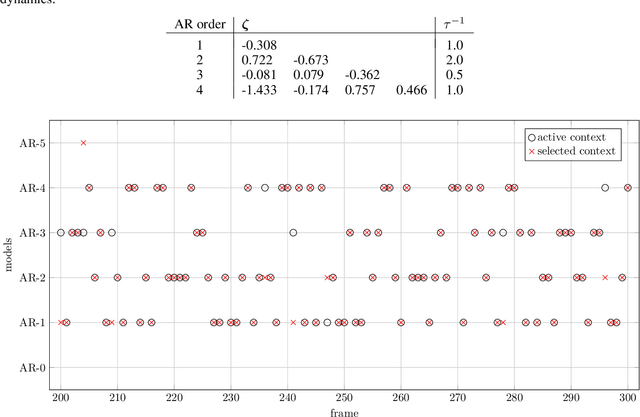
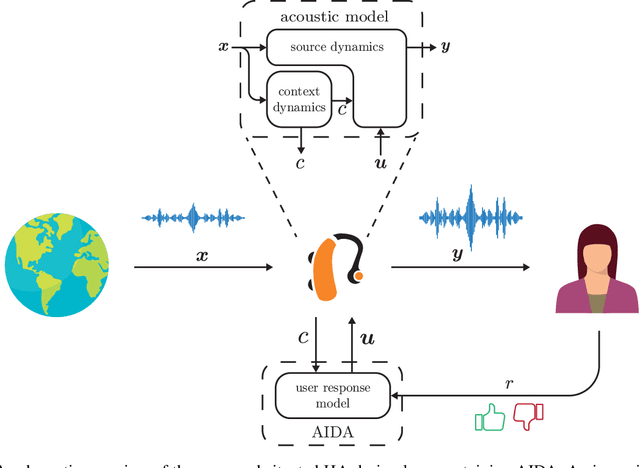
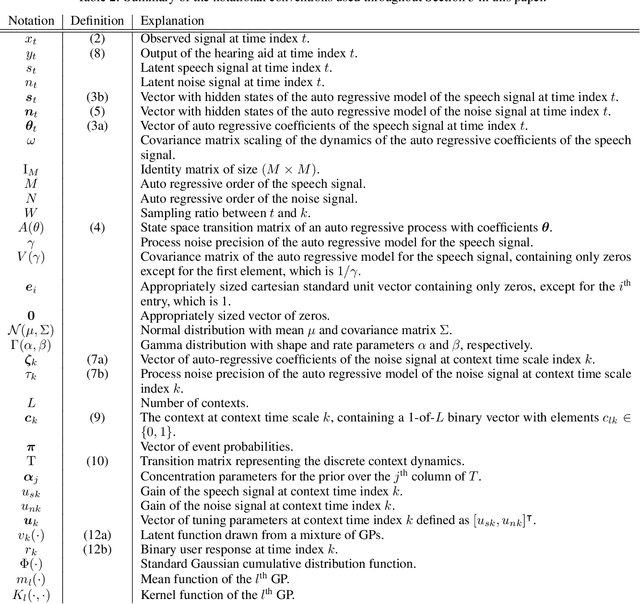
In this paper we present AIDA, which is an active inference-based agent that iteratively designs a personalized audio processing algorithm through situated interactions with a human client. The target application of AIDA is to propose on-the-spot the most interesting alternative values for the tuning parameters of a hearing aid (HA) algorithm, whenever a HA client is not satisfied with their HA performance. AIDA interprets searching for the "most interesting alternative" as an issue of optimal (acoustic) context-aware Bayesian trial design. In computational terms, AIDA is realized as an active inference-based agent with an Expected Free Energy criterion for trial design. This type of architecture is inspired by neuro-economic models on efficient (Bayesian) trial design in brains and implies that AIDA comprises generative probabilistic models for acoustic signals and user responses. We propose a novel generative model for acoustic signals as a sum of time-varying auto-regressive filters and a user response model based on a Gaussian Process Classifier. The full AIDA agent has been implemented in a factor graph for the generative model and all tasks (parameter learning, acoustic context classification, trial design, etc.) are realized by variational message passing on the factor graph. All verification and validation experiments and demonstrations are freely accessible at our GitHub repository.