 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Synthetic Event Time Series Health Data Generation
Nov 27, 2019
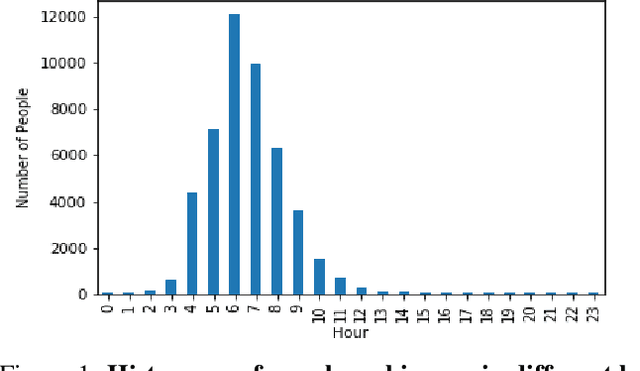
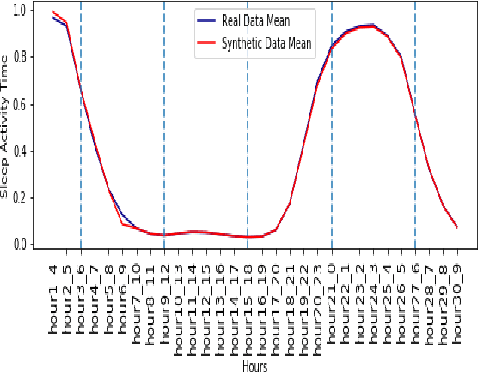
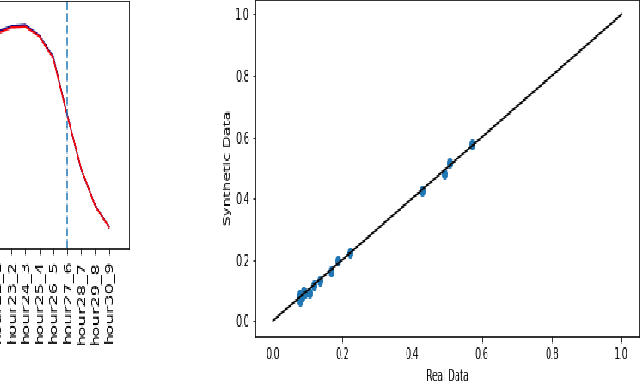
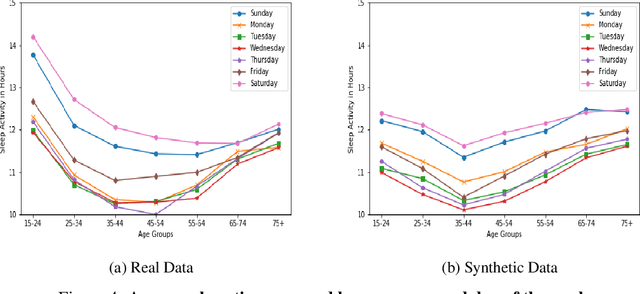
Synthetic medical data which preserves privacy while maintaining utility can be used as an alternative to real medical data, which has privacy costs and resource constraints associated with it. At present, most models focus on generating cross-sectional health data which is not necessarily representative of real data. In reality, medical data is longitudinal in nature, with a single patient having multiple health events, non-uniformly distributed throughout their lifetime. These events are influenced by patient covariates such as comorbidities, age group, gender etc. as well as external temporal effects (e.g. flu season). While there exist seminal methods to model time series data, it becomes increasingly challenging to extend these methods to medical event time series data. Due to the complexity of the real data, in which each patient visit is an event, we transform the data by using summary statistics to characterize the events for a fixed set of time intervals, to facilitate analysis and interpretability. We then train a generative adversarial network to generate synthetic data. We demonstrate this approach by generating human sleep patterns, from a publicly available dataset. We empirically evaluate the generated data and show close univariate resemblance between synthetic and real data. However, we also demonstrate how stratification by covariates is required to gain a deeper understanding of synthetic data quality.
Action Recognition using Transfer Learning and Majority Voting for CSGO
Nov 06, 2021
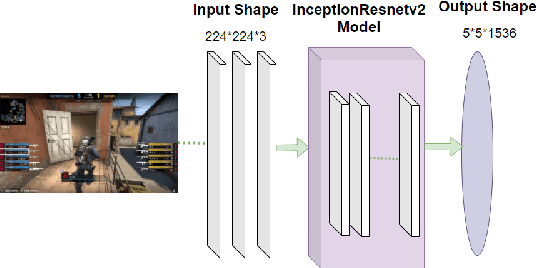
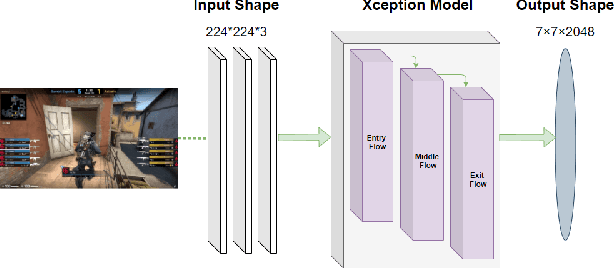
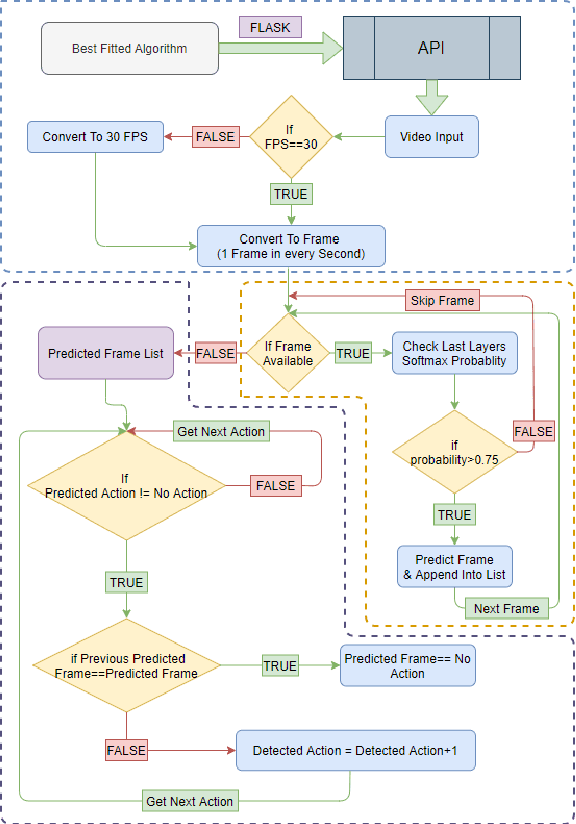
Presently online video games have become a progressively favorite source of recreation and Counter Strike: Global Offensive (CS: GO) is one of the top-listed online first-person shooting games. Numerous competitive games are arranged every year by Esports. Nonetheless, (i) No study has been conducted on video analysis and action recognition of CS: GO game-play which can play a substantial role in the gaming industry for prediction model (ii) No work has been done on the real-time application on the actions and results of a CS: GO match (iii) Game data of a match is usually available in the HLTV as a CSV formatted file however it does not have open access and HLTV tends to prevent users from taking data. This manuscript aims to develop a model for accurate prediction of 4 different actions and compare the performance among the five different transfer learning models with our self-developed deep neural network and identify the best-fitted model and also including major voting later on, which is qualified to provide real time prediction and the result of this model aids to the construction of the automated system of gathering and processing more data alongside solving the issue of collecting data from HLTV.
Multiple Style-Transfer in Real-Time
Nov 18, 2019

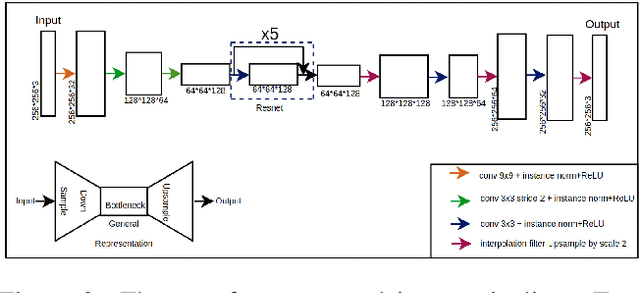
Style transfer aims to combine the content of one image with the artistic style of another. It was discovered that lower levels of convolutional networks captured style information, while higher levels captures content information. The original style transfer formulation used a weighted combination of VGG-16 layer activations to achieve this goal. Later, this was accomplished in real-time using a feed-forward network to learn the optimal combination of style and content features from the respective images. The first aim of our project was to introduce a framework for capturing the style from several images at once. We propose a method that extends the original real-time style transfer formulation by combining the features of several style images. This method successfully captures color information from the separate style images. The other aim of our project was to improve the temporal style continuity from frame to frame. Accordingly, we have experimented with the temporal stability of the output images and discussed the various available techniques that could be employed as alternatives.
Image-based monitoring of bolt loosening through deep-learning-based integrated detection and tracking
Nov 16, 2021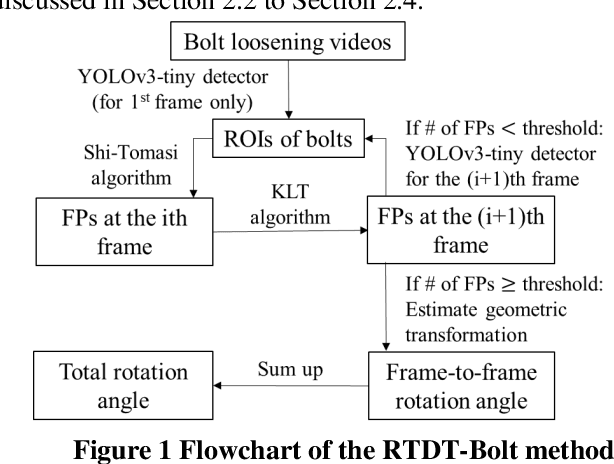
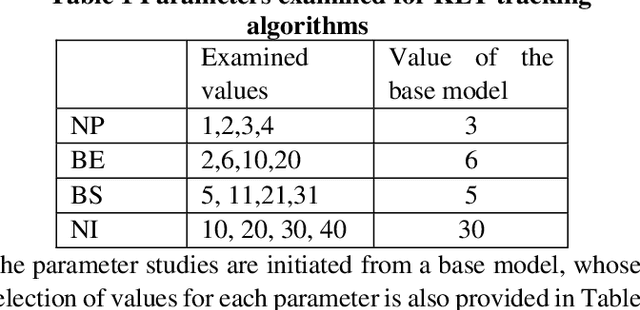

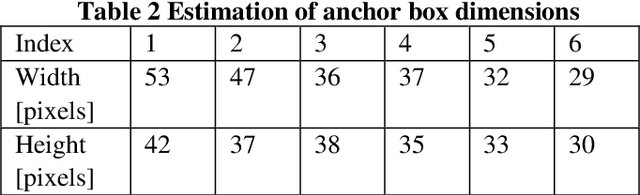
Structural bolts are critical components used in different structural elements, such as beam-column connections and friction damping devices. The clamping force in structural bolts is highly influenced by the bolt rotation. Much of the existing vision-based research about bolt rotation estimation relies on traditional computer vision algorithms such as Hough Transform to assess static images of bolts. This requires careful image preprocessing, and it may not perform well in the situation of complicated bolt assemblies, or in the presence of surrounding objects and background noise, thus hindering their real-world applications. In this study, an integrated real-time detect-track method, namely RTDT-Bolt, is proposed to monitor the bolt rotation angle. First, a real-time convolutional-neural-networks-based object detector, named YOLOv3-tiny, is established and trained to localize structural bolts. Then, the target-free object tracking algorithm based on optical flow is implemented, to continuously monitor and quantify the rotation of structural bolts. In order to enhance the tracking performance against background noise and potential illumination changes during tracking, the YOLOv3-tiny is integrated with the optical flow tracking algorithm to re-detect the bolts when the tracking gets lost. Extensive parameter studies were conducted to identify optimal tracking performance and examine the potential limitations. The results indicate the RTDT-Bolt method can greatly enhance the tracking performance of bolt rotation, which can achieve over 90% accuracy using the recommended range for the parameters.
Data-independent Low-complexity KLT Approximations for Image and Video Coding
Nov 28, 2021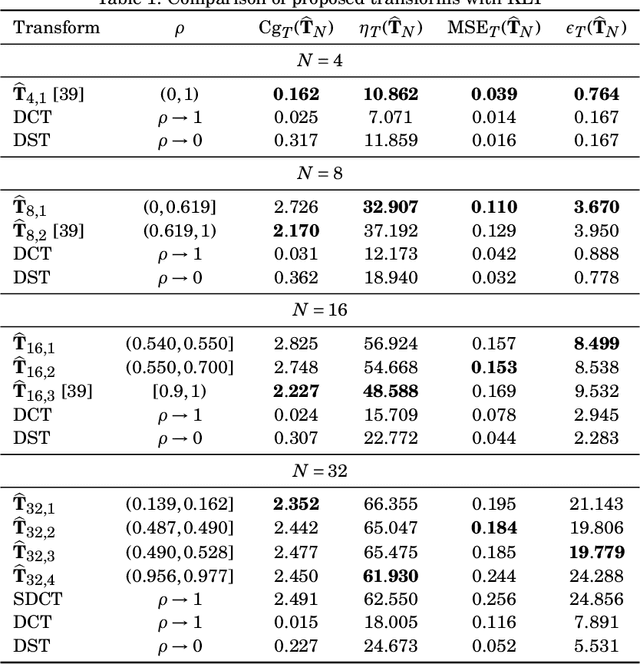
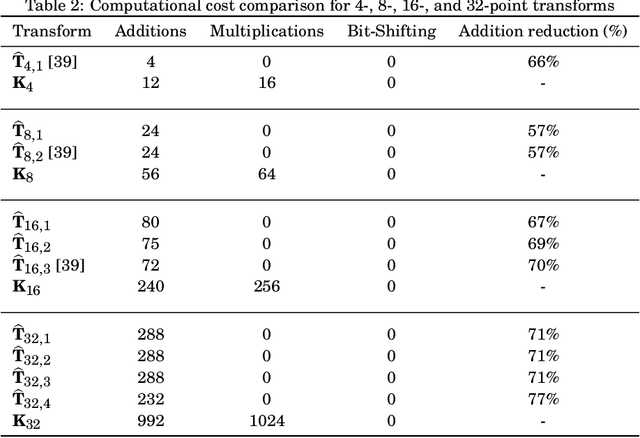
The Karhunen-Lo\`eve transform (KLT) is often used for data decorrelation and dimensionality reduction. The KLT is able to optimally retain the signal energy in only few transform components, being mathematically suitable for image and video compression. However, in practice, because of its high computational cost and dependence on the input signal, its application in real-time scenarios is precluded. This work proposes low-computational cost approximations for the KLT. We focus on the blocklengths $N \in \{4, 8, 16, 32 \}$ because they are widely employed in image and video coding standards such as JPEG and high efficiency video coding (HEVC). Extensive computational experiments demonstrate the suitability of the proposed low-complexity transforms for image and video compression.
Probabilistic Forecasting with Conditional Generative Networks via Scoring Rule Minimization
Dec 15, 2021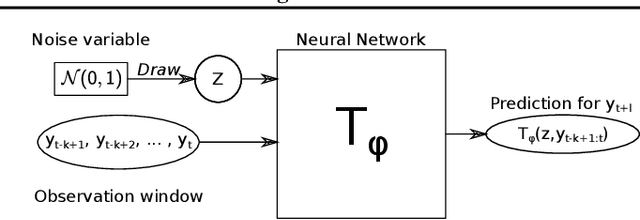

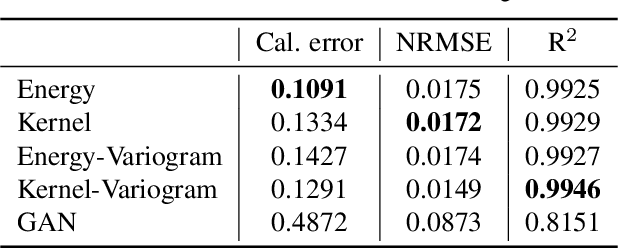
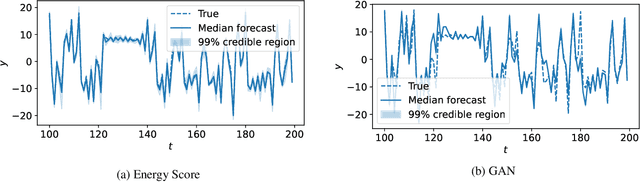
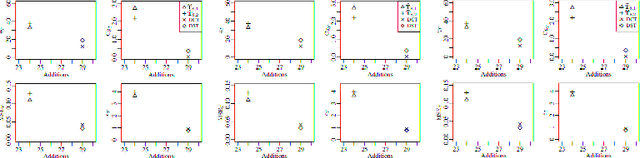
Probabilistic forecasting consists of stating a probability distribution for a future outcome based on past observations. In meteorology, ensembles of physics-based numerical models are run to get such distribution. Usually, performance is evaluated with scoring rules, functions of the forecast distribution and the observed outcome. With some scoring rules, calibration and sharpness of the forecast can be assessed at the same time. In deep learning, generative neural networks parametrize distributions on high-dimensional spaces and easily allow sampling by transforming draws from a latent variable. Conditional generative networks additionally constrain the distribution on an input variable. In this manuscript, we perform probabilistic forecasting with conditional generative networks trained to minimize scoring rule values. In contrast to Generative Adversarial Networks (GANs), no discriminator is required and training is stable. We perform experiments on two chaotic models and a global dataset of weather observations; results are satisfactory and better calibrated than what achieved by GANs.
Learning with Subset Stacking
Dec 12, 2021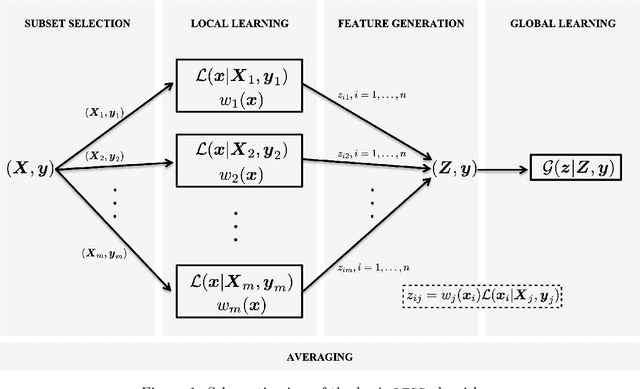

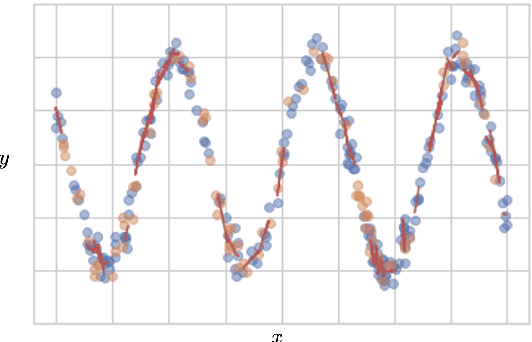
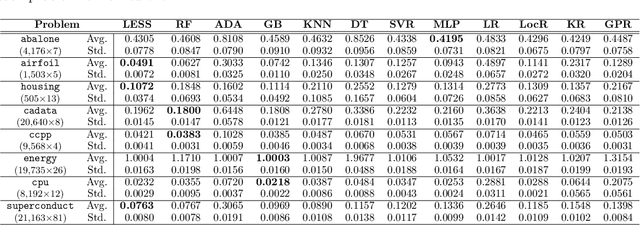
We propose a new algorithm that learns from a set of input-output pairs. Our algorithm is designed for populations where the relation between the input variables and the output variable exhibits a heterogeneous behavior across the predictor space. The algorithm starts with generating subsets that are concentrated around random points in the input space. This is followed by training a local predictor for each subset. Those predictors are then combined in a novel way to yield an overall predictor. We call this algorithm "LEarning with Subset Stacking" or LESS, due to its resemblance to method of stacking regressors. We compare the testing performance of LESS with the state-of-the-art methods on several datasets. Our comparison shows that LESS is a competitive supervised learning method. Moreover, we observe that LESS is also efficient in terms of computation time and it allows a straightforward parallel implementation.
OpenQA: Hybrid QA System Relying on Structured Knowledge Base as well as Non-structured Data
Dec 31, 2021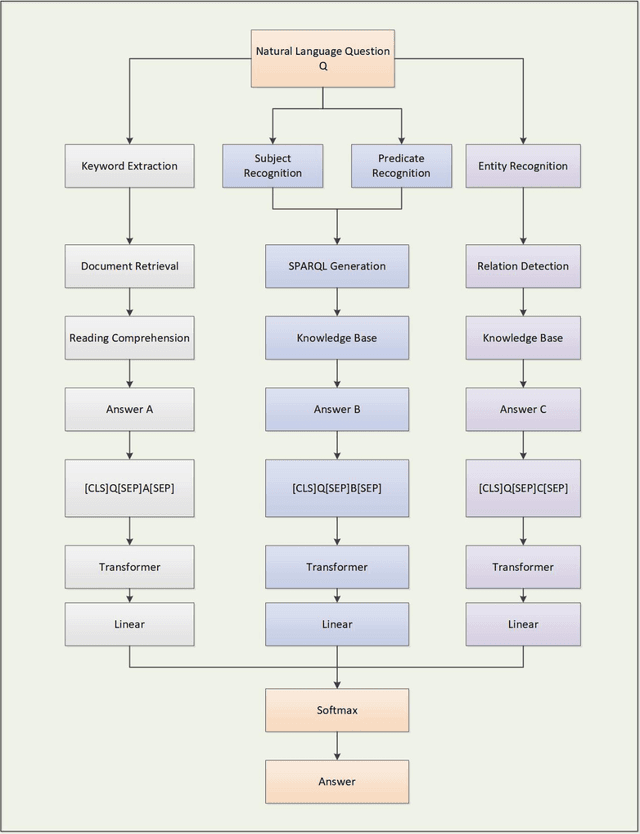
Search engines based on keyword retrieval can no longer adapt to the way of information acquisition in the era of intelligent Internet of Things due to the return of keyword related Internet pages. How to quickly, accurately and effectively obtain the information needed by users from massive Internet data has become one of the key issues urgently needed to be solved. We propose an intelligent question-answering system based on structured KB and unstructured data, called OpenQA, in which users can give query questions and the model can quickly give accurate answers back to users. We integrate KBQA structured question answering based on semantic parsing and deep representation learning, and two-stage unstructured question answering based on retrieval and neural machine reading comprehension into OpenQA, and return the final answer with the highest probability through the Transformer answer selection module in OpenQA. We carry out preliminary experiments on our constructed dataset, and the experimental results prove the effectiveness of the proposed intelligent question answering system. At the same time, the core technology of each module of OpenQA platform is still in the forefront of academic hot spots, and the theoretical essence and enrichment of OpenQA will be further explored based on these academic hot spots.
Joint Sensing, Communication, and Computation Resource Allocation for Cooperative Perception in Fog-Based Vehicular Networks
Dec 12, 2021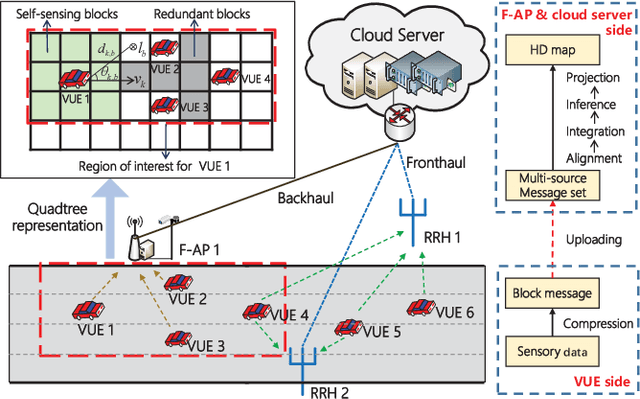
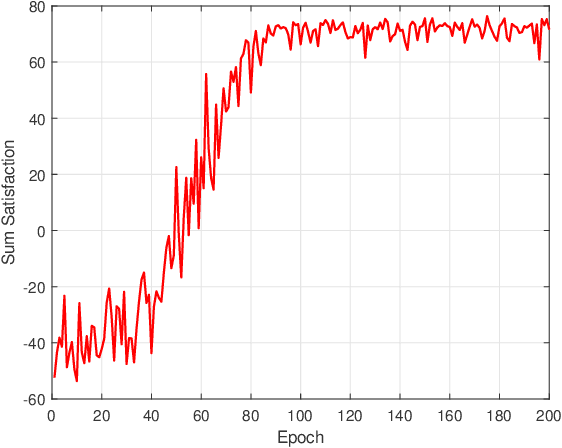
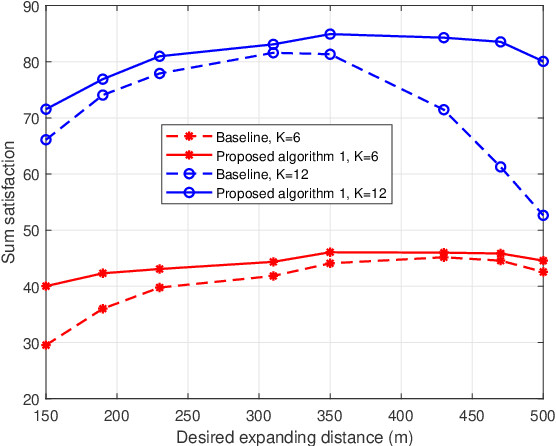
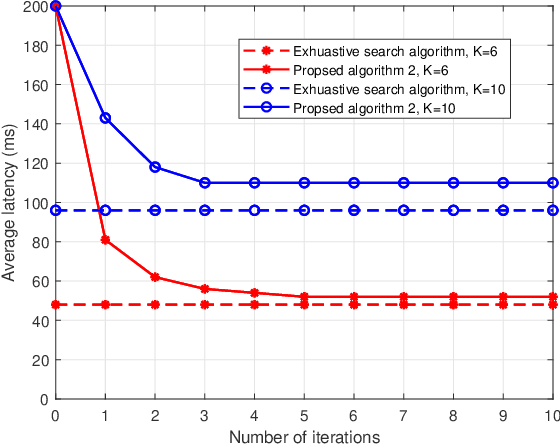
To enlarge the perception range and reliability of individual autonomous vehicles, cooperative perception has been received much attention. However, considering the high volume of shared messages, limited bandwidth and computation resources in vehicular networks become bottlenecks. In this paper, we investigate how to balance the volume of shared messages and constrained resources in fog-based vehicular networks. To this end, we first characterize sum satisfaction of cooperative perception taking account of its spatial-temporal value and latency performance. Next, the sensing block message, communication resource block, and computation resource are jointly allocated to maximize the sum satisfaction of cooperative perception, while satisfying the maximum latency and sojourn time constraints of vehicles. Owing to its non-convexity, we decouple the original problem into two separate sub-problems and devise corresponding solutions. Simulation results demonstrate that our proposed scheme can effectively boost the sum satisfaction of cooperative perception compared with existing baselines.
IVS3D: An Open Source Framework for Intelligent Video Sampling and Preprocessing to Facilitate 3D Reconstruction
Oct 22, 2021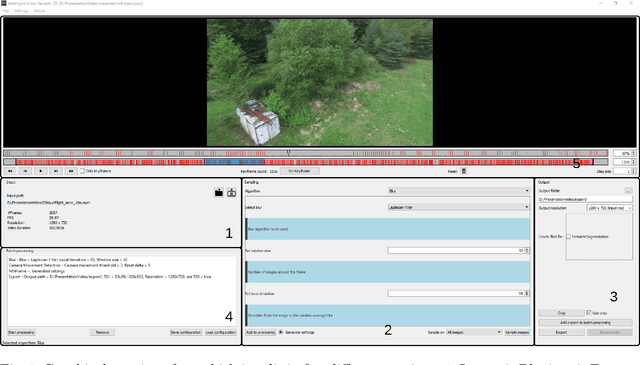
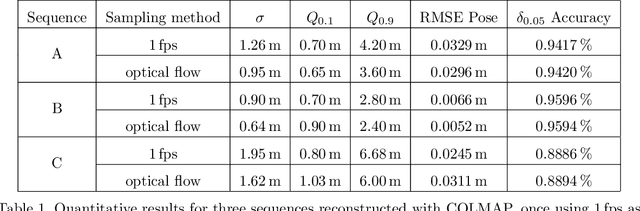

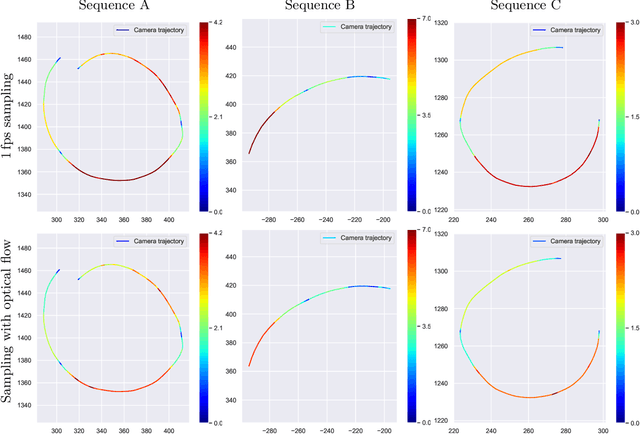
The creation of detailed 3D models is relevant for a wide range of applications such as navigation in three-dimensional space, construction planning or disaster assessment. However, the complex processing and long execution time for detailed 3D reconstructions require the original database to be reduced in order to obtain a result in reasonable time. In this paper we therefore present our framework iVS3D for intelligent pre-processing of image sequences. Our software is able to down sample entire videos to a specific frame rate, as well as to resize and crop the individual images. Furthermore, thanks to our modular architecture, it is easy to develop and integrate plugins with additional algorithms. We provide three plugins as baseline methods that enable an intelligent selection of suitable images and can enrich them with additional information. To filter out images affected by motion blur, we developed a plugin that detects these frames and also searches the spatial neighbourhood for suitable images as replacements. The second plugin uses optical flow to detect redundant images caused by a temporarily stationary camera. In our experiments, we show how this approach leads to a more balanced image sampling if the camera speed varies, and that excluding such redundant images leads to a time saving of 8.1\percent for our sequences. A third plugin makes it possible to exclude challenging image regions from the 3D reconstruction by performing semantic segmentation. As we think that the community can greatly benefit from such an approach, we will publish our framework and the developed plugins open source using the MIT licence to allow co-development and easy extension.