 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WiSig: A Large-Scale WiFi Signal Dataset for Receiver and Channel Agnostic RF Fingerprinting
Dec 31, 2021
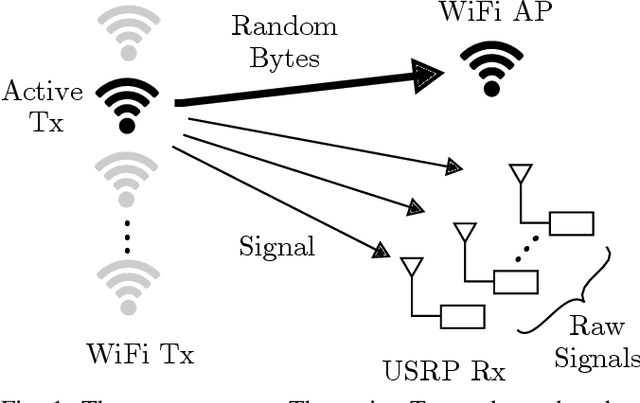
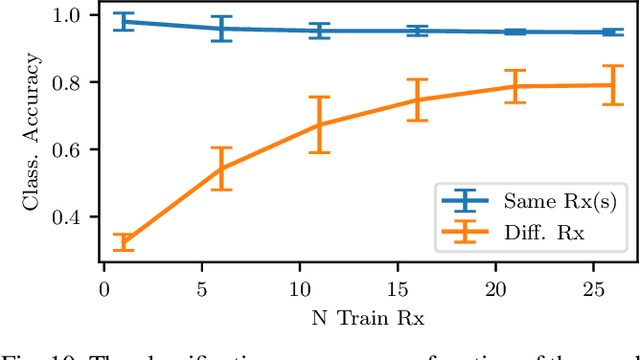
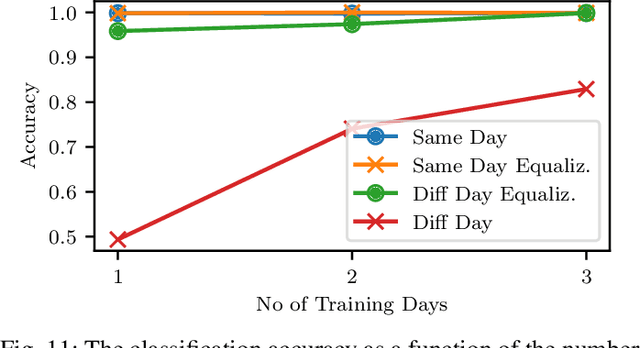
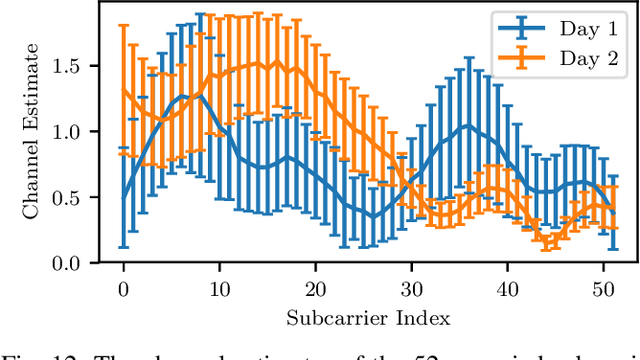
RF fingerprinting leverages circuit-level variability of transmitters to identify them using signals they send. Signals used for identification are impacted by a wireless channel and receiver circuitry, creating additional impairments that can confuse transmitter identification. Eliminating these impairments or just evaluating them, requires data captured over a prolonged period of time, using many spatially separated transmitters and receivers. In this paper, we present WiSig; a large scale WiFi dataset containing 10 million packets captured from 174 off-the-shelf WiFi transmitters and 41 USRP receivers over 4 captures spanning a month. WiSig is publicly available, not just as raw captures, but as conveniently pre-processed subsets of limited size, along with the scripts and examples. A preliminary evaluation performed using WiSig shows that changing receivers, or using signals captured on a different day can significantly degrade a trained classifier's performance. While capturing data over more days or more receivers limits the degradation, it is not always feasible and novel data-driven approaches are needed. WiSig provides the data to develop and evaluate these approaches towards channel and receiver agnostic transmitter fingerprinting.
Continual Coarse-to-Fine Domain Adaptation in Semantic Segmentation
Jan 18, 2022
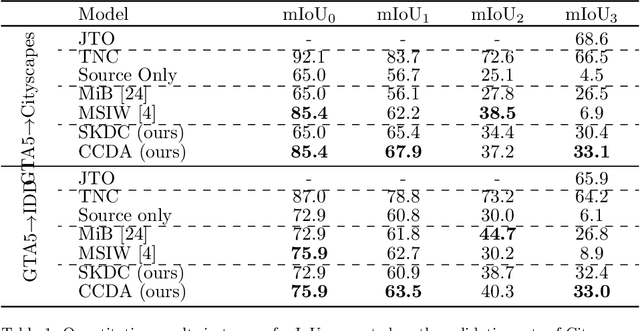
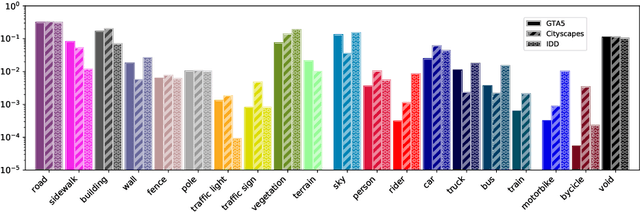
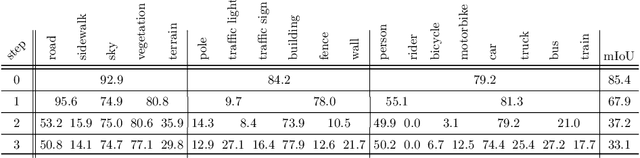
Deep neural networks are typically trained in a single shot for a specific task and data distribution, but in real world settings both the task and the domain of application can change. The problem becomes even more challenging in dense predictive tasks, such as semantic segmentation, and furthermore most approaches tackle the two problems separately. In this paper we introduce the novel task of coarse-to-fine learning of semantic segmentation architectures in presence of domain shift. We consider subsequent learning stages progressively refining the task at the semantic level; i.e., the finer set of semantic labels at each learning step is hierarchically derived from the coarser set of the previous step. We propose a new approach (CCDA) to tackle this scenario. First, we employ the maximum squares loss to align source and target domains and, at the same time, to balance the gradients between well-classified and harder samples. Second, we introduce a novel coarse-to-fine knowledge distillation constraint to transfer network capabilities acquired on a coarser set of labels to a set of finer labels. Finally, we design a coarse-to-fine weight initialization rule to spread the importance from each coarse class to the respective finer classes. To evaluate our approach, we design two benchmarks where source knowledge is extracted from the GTA5 dataset and it is transferred to either the Cityscapes or the IDD datasets, and we show how it outperforms the main competitors.
A Comprehensive Survey on the Convergence of Vehicular Social Networks and Fog Computing
Nov 30, 2021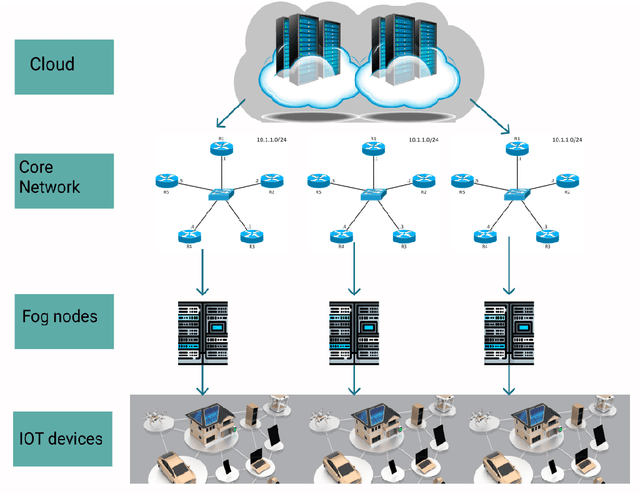
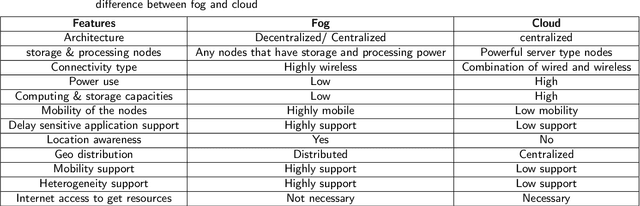
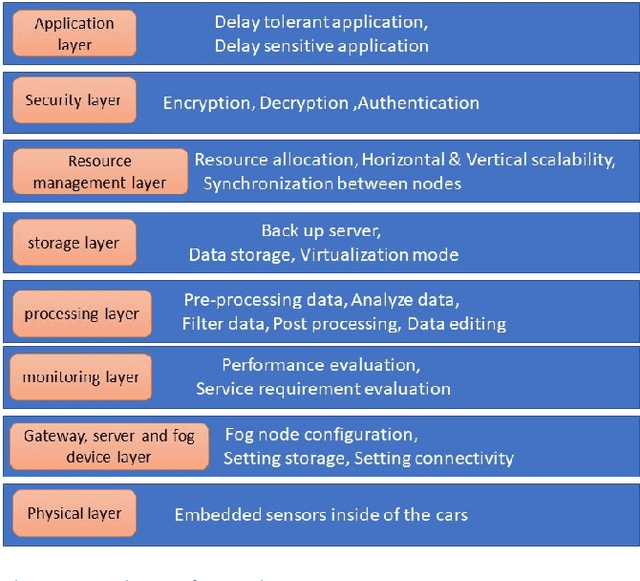
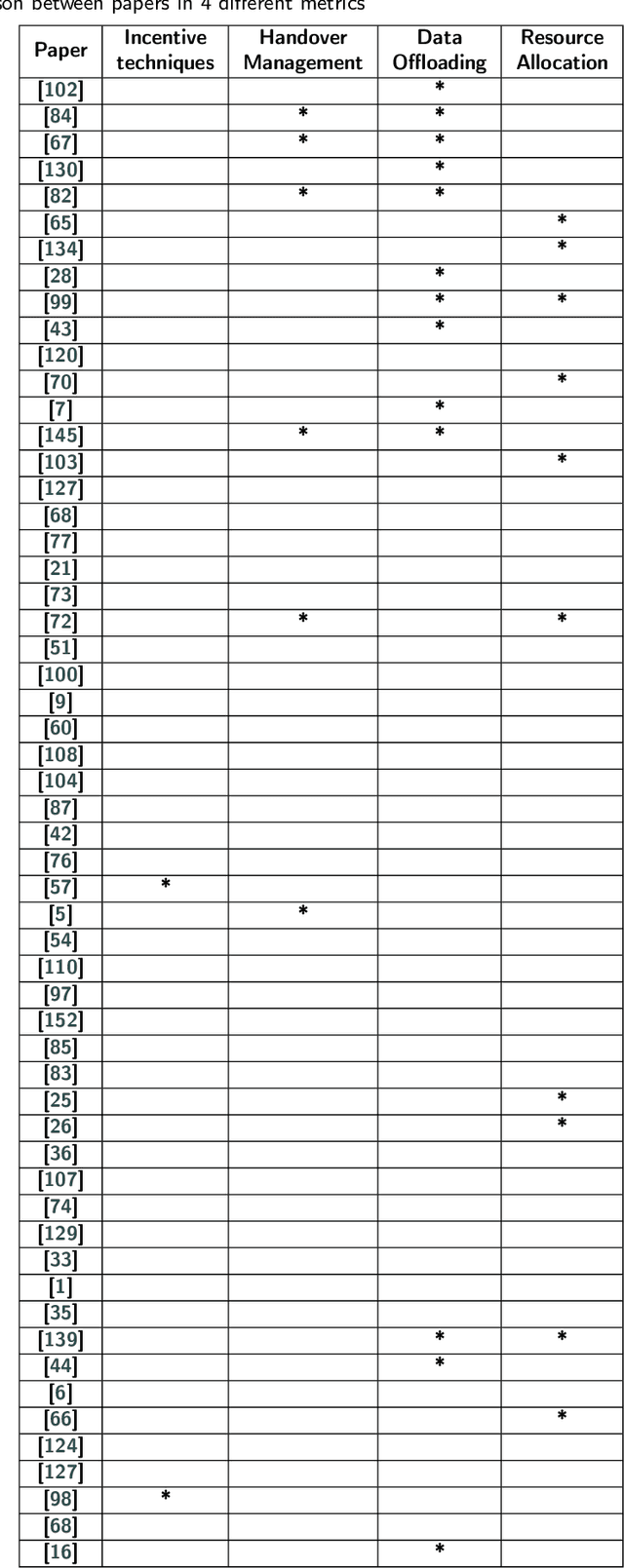
In recent years, the number of IoT devices has been growing fast which leads to a challenging task for managing, storing, analyzing, and making decisions about raw data from different IoT devices, especially for delay-sensitive applications. In a vehicular network (VANET) environment, the dynamic nature of vehicles makes the current open research issues even more challenging due to the frequent topology changes that can lead to disconnections between vehicles. To this end, a number of research works have been proposed in the context of cloud and fog computing over the 5G infrastructure. On the other hand, there are a variety of research proposals that aim to extend the connection time between vehicles. Vehicular Social Networks (VSNs) have been defined to decrease the burden of connection time between the vehicles. This survey paper first provides the necessary background information and definitions about fog, cloud and related paradigms such as 5G and SDN. Then, it introduces the reader to Vehicular Social Networks, the different metrics and the main differences between VSNs and Online Social Networks. Finally, this survey investigates the related works in the context of VANETs that have demonstrated different architectures to address the different issues in fog computing. Moreover, it provides a categorization of the different approaches and discusses the required metrics in the context of fog and cloud and compares them to Vehicular social networks. A comparison of the relevant related works is discussed along with new research challenges and trends in the domain of VSNs and fog computing.
D-Former: A U-shaped Dilated Transformer for 3D Medical Image Segmentation
Jan 10, 2022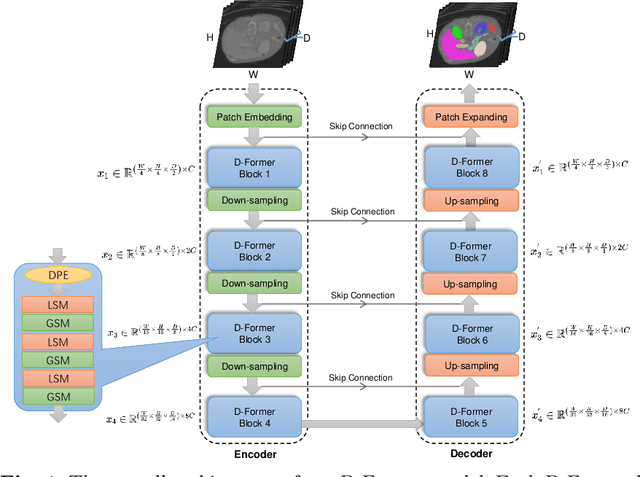
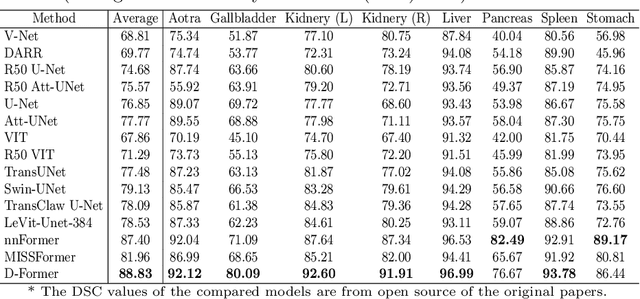
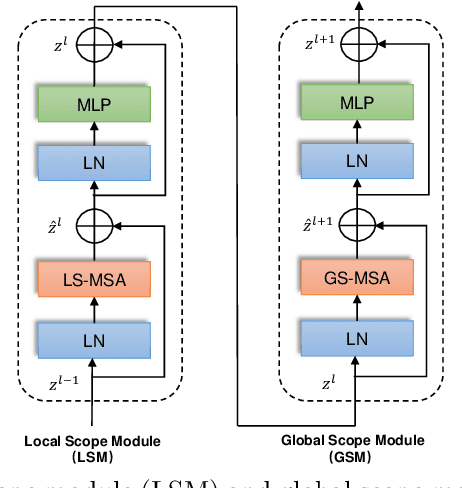
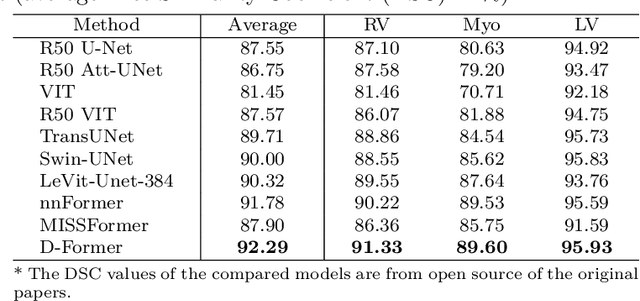
Computer-aided medical image segmentation has been applied widely in diagnosis and treatment to obtain clinically useful information of shapes and volumes of target organs and tissues. In the past several years, convolutional neural network (CNN) based methods (e.g., U-Net) have dominated this area, but still suffered from inadequate long-range information capturing. Hence, recent work presented computer vision Transformer variants for medical image segmentation tasks and obtained promising performances. Such Transformers model long-range dependency by computing pair-wise patch relations. However, they incur prohibitive computational costs, especially on 3D medical images (e.g., CT and MRI). In this paper, we propose a new method called Dilated Transformer, which conducts self-attention for pair-wise patch relations captured alternately in local and global scopes. Inspired by dilated convolution kernels, we conduct the global self-attention in a dilated manner, enlarging receptive fields without increasing the patches involved and thus reducing computational costs. Based on this design of Dilated Transformer, we construct a U-shaped encoder-decoder hierarchical architecture called D-Former for 3D medical image segmentation. Experiments on the Synapse and ACDC datasets show that our D-Former model, trained from scratch, outperforms various competitive CNN-based or Transformer-based segmentation models at a low computational cost without time-consuming per-training process.
Temporal Dynamic Convolutional Neural Network for Text-Independent Speaker Verification and Phonemetic Analysis
Oct 07, 2021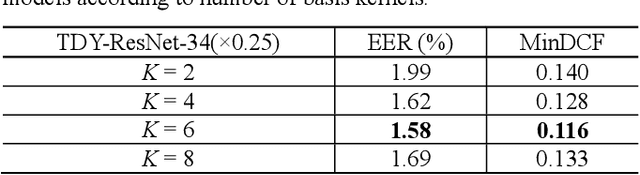
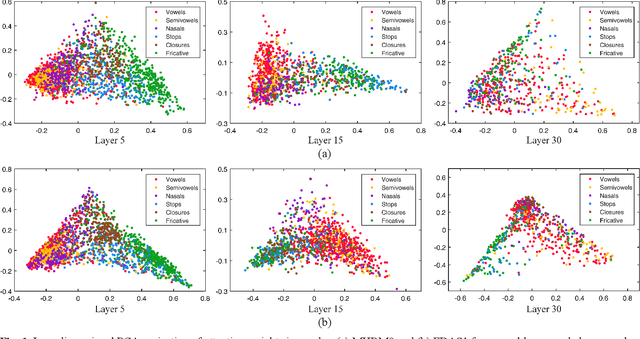
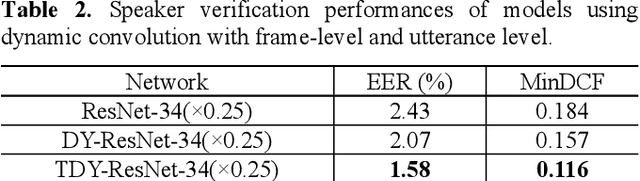
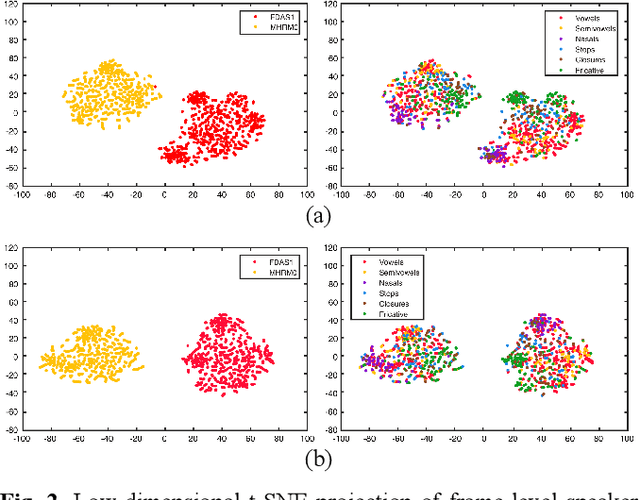
In the field of text-independent speaker recognition, dynamic models that change along the time axis have been proposed to consider the phoneme-varying characteristics of speech. However, detailed analysis on how dynamic models work depending on phonemes is insufficient. In this paper, we propose temporal dynamic CNN (TDY-CNN) that considers temporal variation of phonemes by applying kernels optimally adapt to each time bin. These kernels adapt to time bins by applying weighted sum of trained basis kernels. Then, an analysis on how adaptive kernels work on different phonemes in various layers is carried out. TDY-ResNet-38(x0.5) using six basis kernels shows better speaker verification performance than baseline model ResNet-38(x0.5) does, with an equal error rate (EER) of 1.48%. In addition, we showed that adaptive kernels depend on phoneme groups and more phoneme-specific at early layer. Temporal dynamic model adapts itself to phonemes without explicitly given phoneme information during training, and the results show that the necessity to consider phoneme variation within utterances for more accurate and robust text-independent speaker verification.
Detecting Twenty-thousand Classes using Image-level Supervision
Jan 10, 2022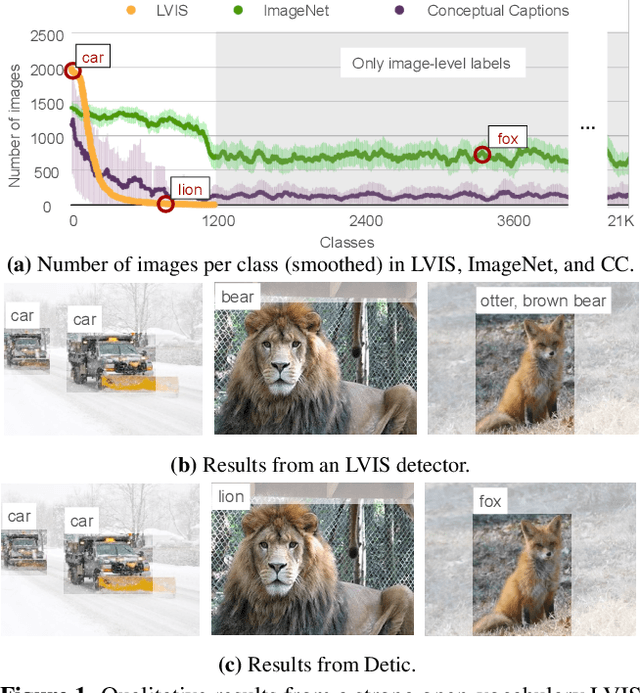
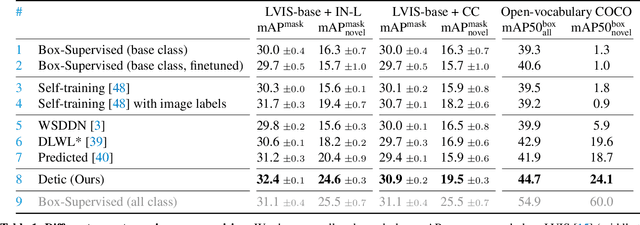


Current object detectors are limited in vocabulary size due to the small scale of detection datasets. Image classifiers, on the other hand, reason about much larger vocabularies, as their datasets are larger and easier to collect. We propose Detic, which simply trains the classifiers of a detector on image classification data and thus expands the vocabulary of detectors to tens of thousands of concepts. Unlike prior work, Detic does not assign image labels to boxes based on model predictions, making it much easier to implement and compatible with a range of detection architectures and backbones. Our results show that Detic yields excellent detectors even for classes without box annotations. It outperforms prior work on both open-vocabulary and long-tail detection benchmarks. Detic provides a gain of 2.4 mAP for all classes and 8.3 mAP for novel classes on the open-vocabulary LVIS benchmark. On the standard LVIS benchmark, Detic reaches 41.7 mAP for all classes and 41.7 mAP for rare classes. For the first time, we train a detector with all the twenty-one-thousand classes of the ImageNet dataset and show that it generalizes to new datasets without fine-tuning. Code is available at https://github.com/facebookresearch/Detic.
Information Field Theory as Artificial Intelligence
Dec 19, 2021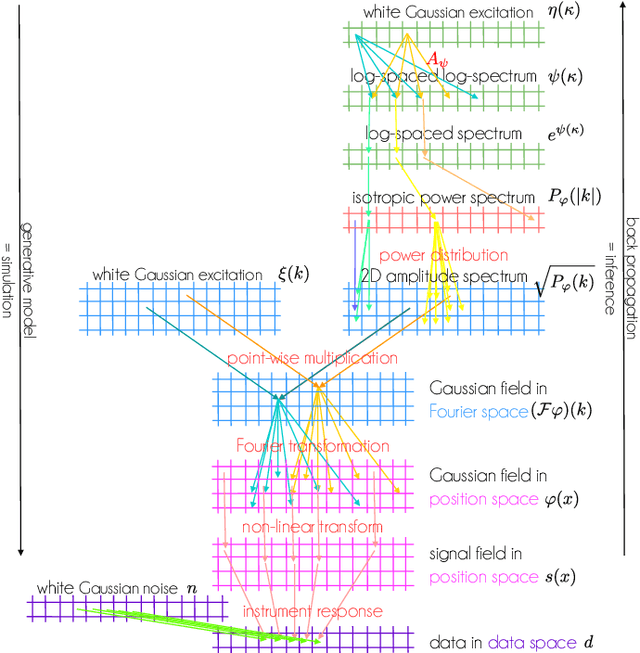
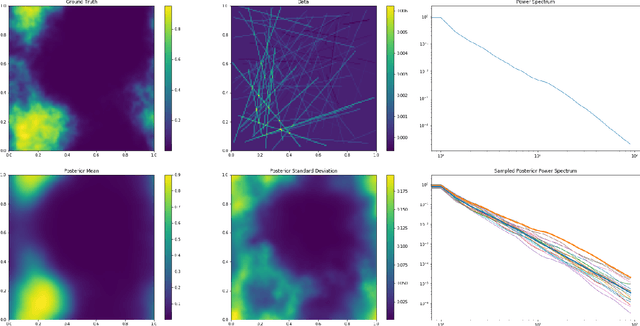
Information field theory (IFT), the information theory for fields, is a mathematical framework for signal reconstruction and non-parametric inverse problems. Here, fields denote physical quantities that change continuously as a function of space (and time) and information theory refers to Bayesian probabilistic logic equipped with the associated entropic information measures. Reconstructing a signal with IFT is a computational problem similar to training a generative neural network (GNN). In this paper, the inference in IFT is reformulated in terms of GNN training and the cross-fertilization of numerical variational inference methods used in IFT and machine learning are discussed. The discussion suggests that IFT inference can be regarded as a specific form of artificial intelligence. In contrast to classical neural networks, IFT based GNNs can operate without pre-training thanks to incorporating expert knowledge into their architecture.
Ultra Low-Parameter Denoising: Trainable Bilateral Filter Layers in Computed Tomography
Jan 25, 2022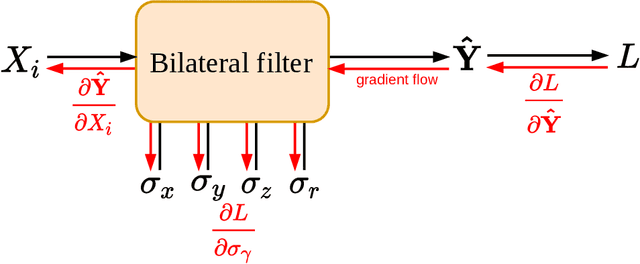
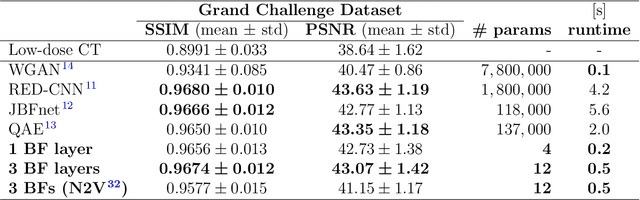
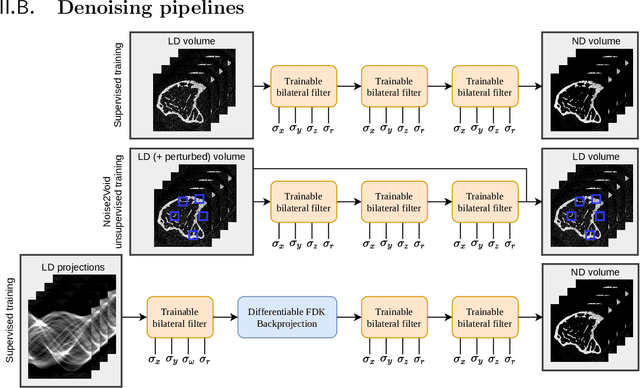
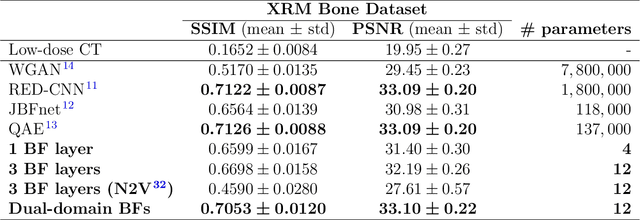
Computed tomography is widely used as an imaging tool to visualize three-dimensional structures with expressive bone-soft tissue contrast. However, CT resolution and radiation dose are tightly entangled, highlighting the importance of low-dose CT combined with sophisticated denoising algorithms. Most data-driven denoising techniques are based on deep neural networks and, therefore, contain hundreds of thousands of trainable parameters, making them incomprehensible and prone to prediction failures. Developing understandable and robust denoising algorithms achieving state-of-the-art performance helps to minimize radiation dose while maintaining data integrity. This work presents an open-source CT denoising framework based on the idea of bilateral filtering. We propose a bilateral filter that can be incorporated into a deep learning pipeline and optimized in a purely data-driven way by calculating the gradient flow toward its hyperparameters and its input. Denoising in pure image-to-image pipelines and across different domains such as raw detector data and reconstructed volume, using a differentiable backprojection layer, is demonstrated. Although only using three spatial parameters and one range parameter per filter layer, the proposed denoising pipelines can compete with deep state-of-the-art denoising architectures with several hundred thousand parameters. Competitive denoising performance is achieved on x-ray microscope bone data (0.7053 and 33.10) and the 2016 Low Dose CT Grand Challenge dataset (0.9674 and 43.07) in terms of SSIM and PSNR. Due to the extremely low number of trainable parameters with well-defined effect, prediction reliance and data integrity is guaranteed at any time in the proposed pipelines, in contrast to most other deep learning-based denoising architectures.
PrimSeq: a deep learning-based pipeline to quantitate rehabilitation training
Dec 22, 2021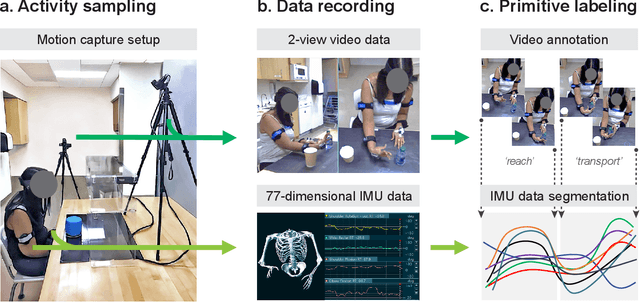
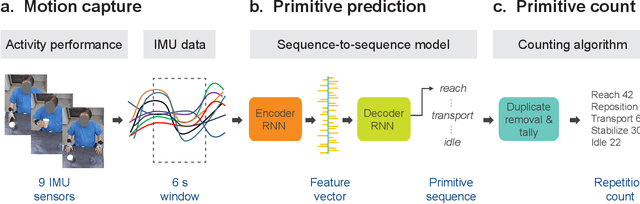
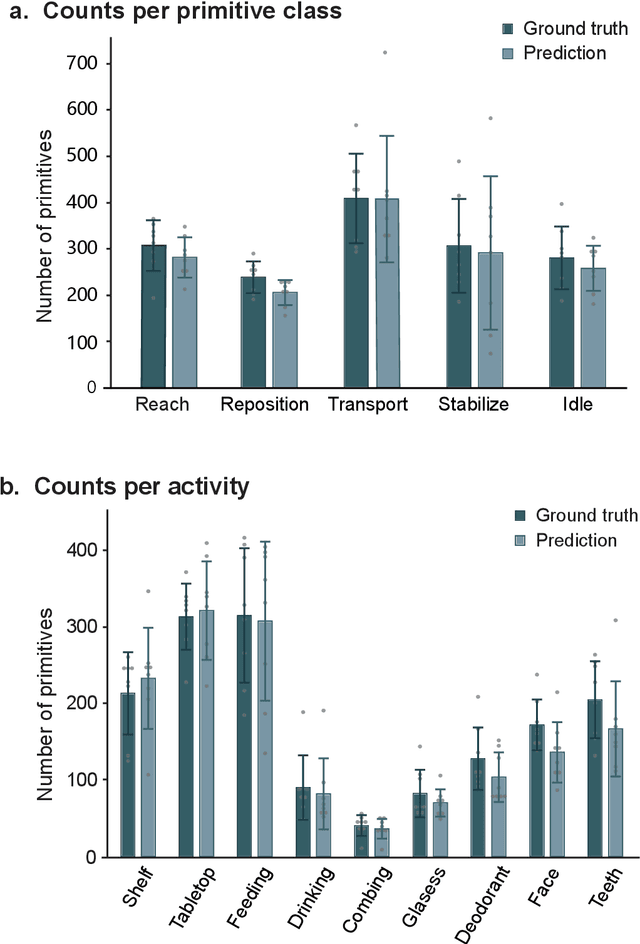
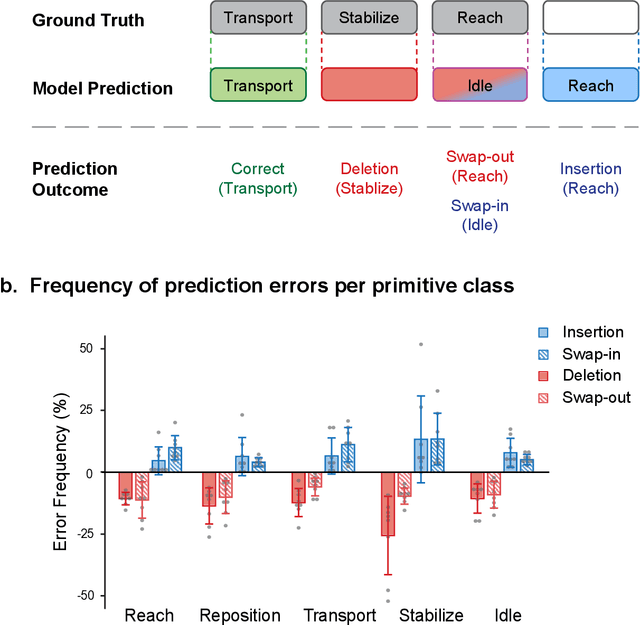
Stroke rehabilitation seeks to increase neuroplasticity through the repeated practice of functional motions, but may have minimal impact on recovery because of insufficient repetitions. The optimal training content and quantity are currently unknown because no practical tools exist to measure them. Here, we present PrimSeq, a pipeline to classify and count functional motions trained in stroke rehabilitation. Our approach integrates wearable sensors to capture upper-body motion, a deep learning model to predict motion sequences, and an algorithm to tally motions. The trained model accurately decomposes rehabilitation activities into component functional motions, outperforming competitive machine learning methods. PrimSeq furthermore quantifies these motions at a fraction of the time and labor costs of human experts. We demonstrate the capabilities of PrimSeq in previously unseen stroke patients with a range of upper extremity motor impairment. We expect that these advances will support the rigorous measurement required for quantitative dosing trials in stroke rehabilitation.
Real-time Federated Evolutionary Neural Architecture Search
Mar 04, 2020
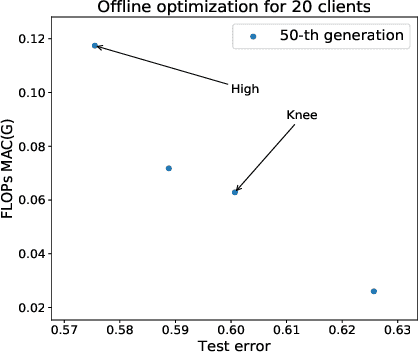
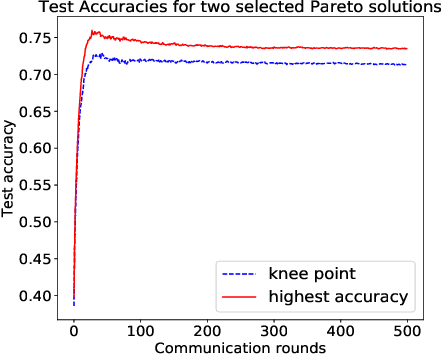
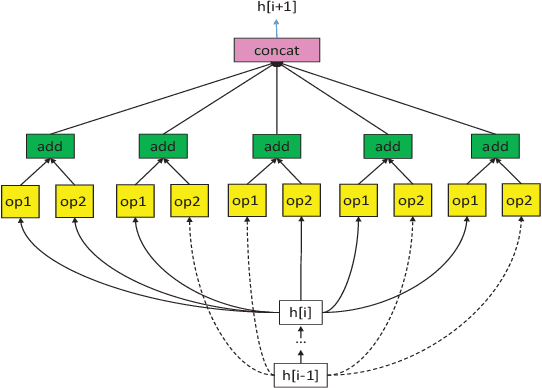
Federated learning is a distributed machine learning approach to privacy preservation and two major technical challenges prevent a wider application of federated learning. One is that federated learning raises high demands on communication, since a large number of model parameters must be transmitted between the server and the clients. The other challenge is that training large machine learning models such as deep neural networks in federated learning requires a large amount of computational resources, which may be unrealistic for edge devices such as mobile phones. The problem becomes worse when deep neural architecture search is to be carried out in federated learning. To address the above challenges, we propose an evolutionary approach to real-time federated neural architecture search that not only optimize the model performance but also reduces the local payload. During the search, a double-sampling technique is introduced, in which for each individual, a randomly sampled sub-model of a master model is transmitted to a number of randomly sampled clients for training without reinitialization. This way, we effectively reduce computational and communication costs required for evolutionary optimization and avoid big performance fluctuations of the local models, making the proposed framework well suited for real-time federated neural architecture search.