 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robophysical modeling of spacetime dynamics
Feb 10, 2022
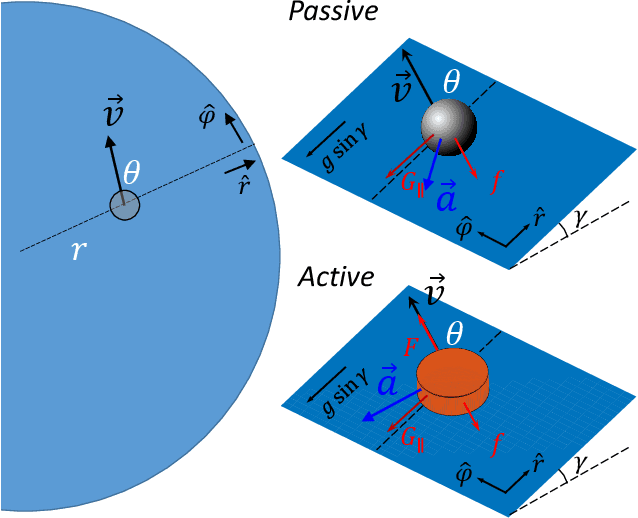
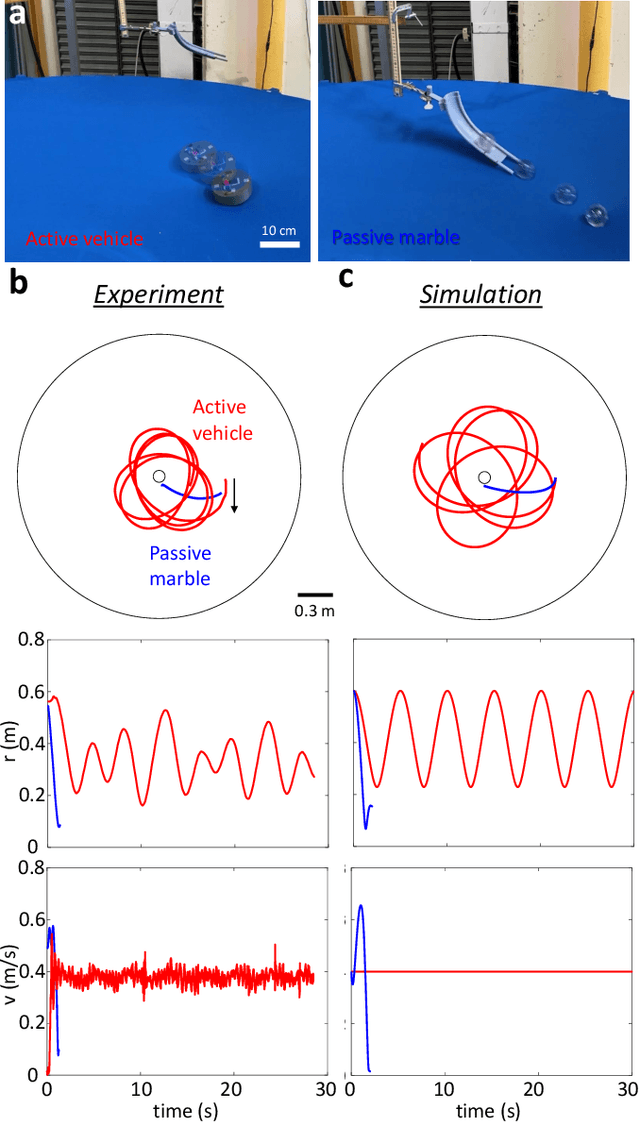
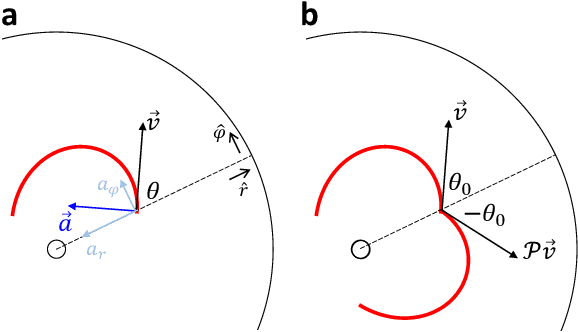
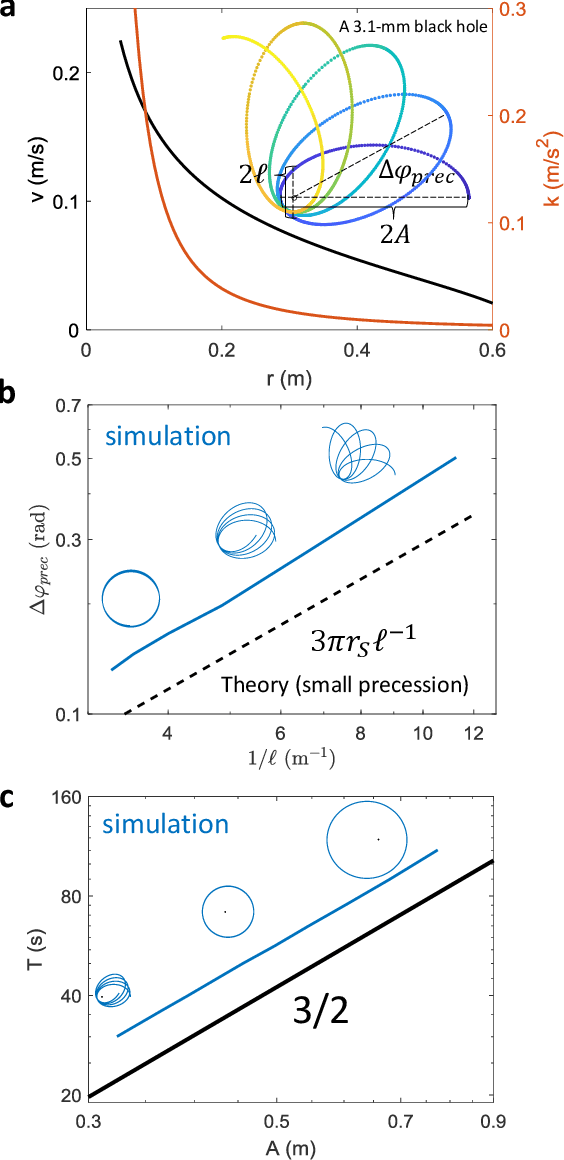
Systems consisting of spheres rolling on elastic membranes have been used as educational tools to introduce a core conceptual idea of General Relativity (GR): how curvature guides the movement of matter. However, previous studies have revealed that such schemes cannot accurately represent relativistic dynamics in the laboratory. Dissipative forces cause the initially GR-like dynamics to be transient and consequently restrict experimental study to only the beginnings of trajectories; dominance of Earth's gravity forbids the difference between spatial and temporal spacetime curvatures. Here by developing a mapping between dynamics of a wheeled vehicle on a spandex membrane, we demonstrate that an active object that can prescribe its speed can not only obtain steady-state orbits, but also use the additional parameters such as speed to tune the orbits towards relativistic dynamics. Our mapping demonstrates how activity mixes space and time in a metric, shows how active particles do not necessarily follow geodesics in the real space but instead follow geodesics in a fiducial spacetime. The mapping further reveals how parameters such as the membrane elasticity and instantaneous speed allow programming a desired spacetime such as the Schwarzschild metric near a non-rotating black hole. Our mapping and framework point the way to the possibility to create a robophysical analog gravity system in the laboratory at low cost and provide insights into active matter in deformable environments and robot exploration in complex landscapes.
Access Delay Constrained Activity Detection in Massive Random Access
Nov 04, 2021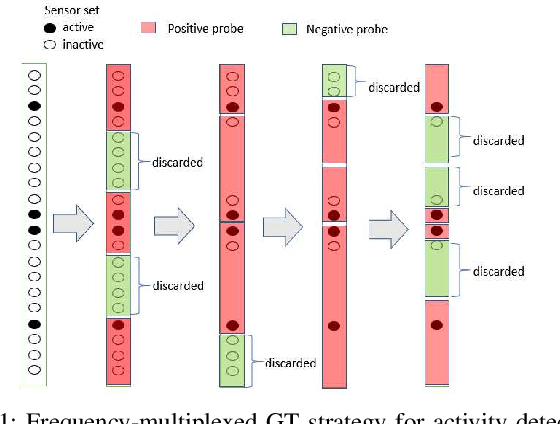
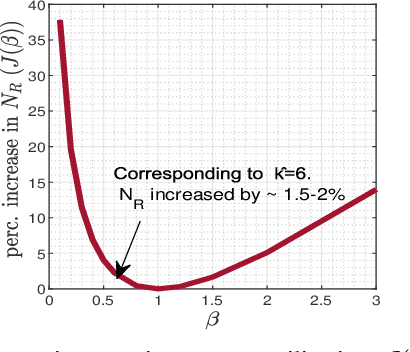
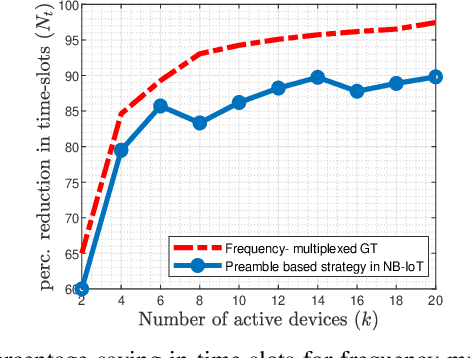
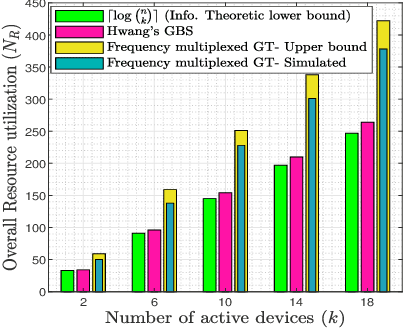
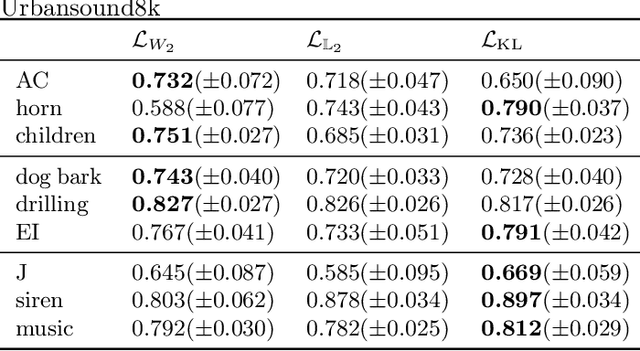
In 5G and future generation wireless systems, massive IoT networks with bursty traffic are expected to co-exist with cellular systems to serve several latency-critical applications. Thus, it is important for the access points to identify the active devices promptly with minimal resource consumption to enable massive machine-type communication without disrupting the conventional traffic. In this paper, a frequency-multiplexed strategy based on group testing is proposed for activity detection which can take into account the constraints on network latency while minimizing the overall resource utilization. The core idea is that during each time-slot of active device discovery, multiple subcarriers in frequency domain can be used to launch group tests in parallel to reduce delay. Our proposed scheme is functional in the asymptotic and non-asymptotic regime of the total number of devices $(n)$ and the number of concurrently active devices $(k)$. We prove that, asymptotically, when the number of available time-slots scale as $\Omega\big(\log (\frac{n}{k})\big)$, the frequency-multiplexed group testing strategy requires $O\big(k\log (\frac{n}{k})\big)$ time-frequency resources which is order-optimal and results in an $O(k)$ reduction in the number of time-slots with respect to the optimal strategy of fully-adaptive generalized binary splitting. Furthermore, we establish that the frequency-multiplexed GT strategy shows significant tolerance to estimation errors in $k$. Comparison with 3GPP standardized random access protocol for NB-IoT indicates the superiority of our proposed strategy in terms of access delay and overall resource utilization.
* 5 pages, 4 figures
Surrogate-assisted distributed swarm optimisation for computationally expensive models
Jan 18, 2022Advances in parallel and distributed computing have enabled efficient implementation of the distributed swarm and evolutionary algorithms for complex and computationally expensive models. Evolutionary algorithms provide gradient-free optimisation which is beneficial for models that do not have such information available, for instance, geoscientific landscape evolution models. However, such models are so computationally expensive that even distributed swarm and evolutionary algorithms with the power of parallel computing struggle. We need to incorporate efficient strategies such as surrogate assisted optimisation that further improves their performance; however, this becomes a challenge given parallel processing and inter-process communication for implementing surrogate training and prediction. In this paper, we implement surrogate-based estimation of fitness evaluation in distributed swarm optimisation over a parallel computing architecture. Our results demonstrate very promising results for benchmark functions and geoscientific landscape evolution models. We obtain a reduction in computationally time while retaining optimisation solution accuracy through the use of surrogates in a parallel computing environment.
Stochastic optimization in digital pre-distortion of the signal
Jan 28, 2022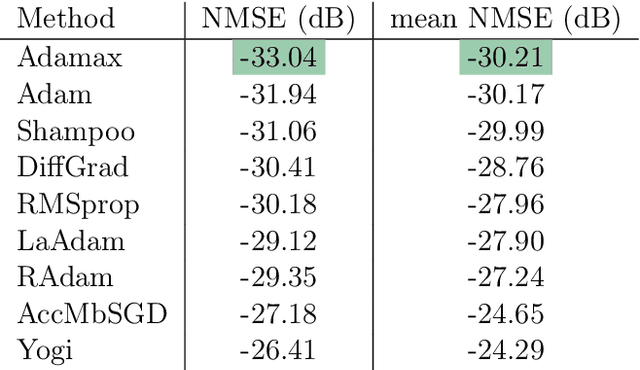
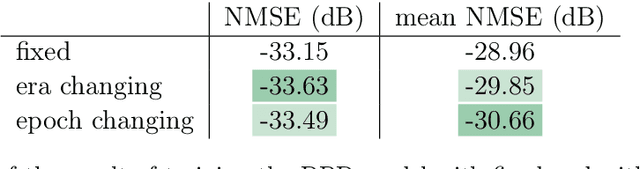
In this paper, we test the performance of some modern stochastic optimization methods and practices in application to digital pre-distortion problem, that is a valuable part of processing signal on base stations providing wireless communication. In first part of our study, we focus on search of the best performing method and its proper modifications. In the second part, we proposed the new, quasi-online, testing framework that allows us to fit our modelling results with the behaviour of real-life DPD prototype, retested some selected of practices considered in previous section and approved the advantages of the method occured to be the best in real-life conditions. For the used model, maximum achieved improvement in depth was 7% in standard regime and 5% in online one (metric itself is of logarithmic scale). We also achieved a halving of the working time preserving 3% and 6% improvement in depth for the standard and online regime, correspondingly. All comparisons are made to the Adam method, which was highlighted as the best stochastic method for DPD problem in paper [Pasechnyuk et al., 2021], and to the Adamax method, that is the best in the proposed online regime.
Collaborative Learning over Wireless Networks: An Introductory Overview
Dec 07, 2021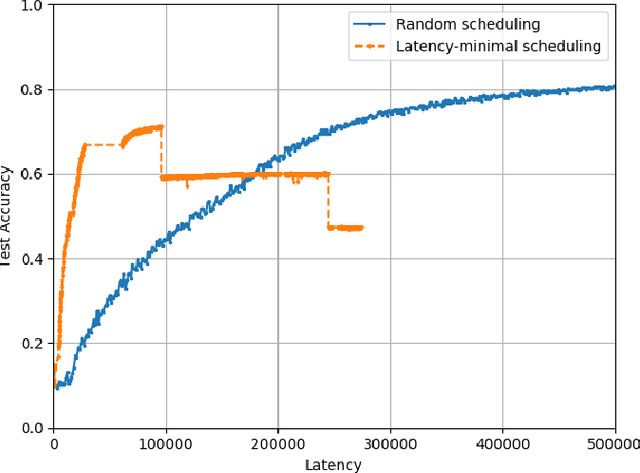
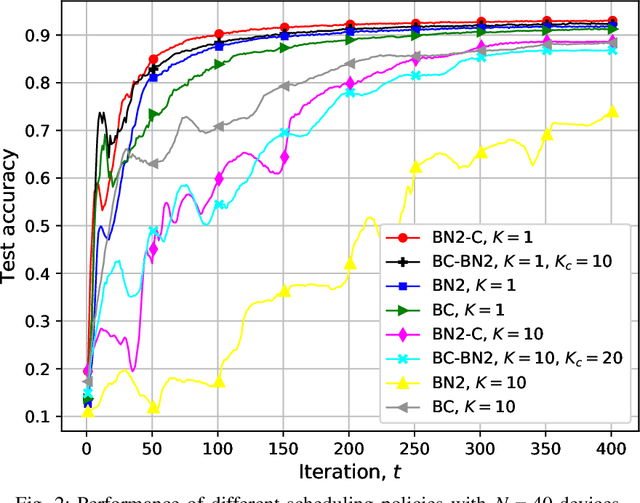
In this chapter, we will mainly focus on collaborative training across wireless devices. Training a ML model is equivalent to solving an optimization problem, and many distributed optimization algorithms have been developed over the last decades. These distributed ML algorithms provide data locality; that is, a joint model can be trained collaboratively while the data available at each participating device remains local. This addresses, to some extend, the privacy concern. They also provide computational scalability as they allow exploiting computational resources distributed across many edge devices. However, in practice, this does not directly lead to a linear gain in the overall learning speed with the number of devices. This is partly due to the communication bottleneck limiting the overall computation speed. Additionally, wireless devices are highly heterogeneous in their computational capabilities, and both their computation speed and communication rate can be highly time-varying due to physical factors. Therefore, distributed learning algorithms, particularly those to be implemented at the wireless network edge, must be carefully designed taking into account the impact of time-varying communication network as well as the heterogeneous and stochastic computation capabilities of devices.
WIDAR -- Weighted Input Document Augmented ROUGE
Jan 23, 2022

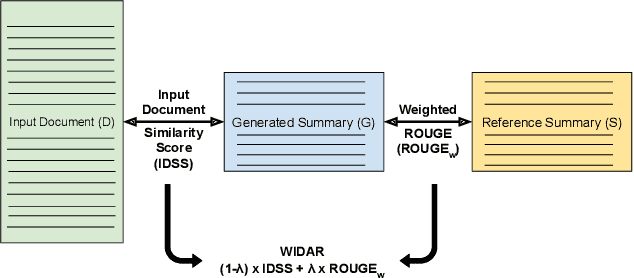
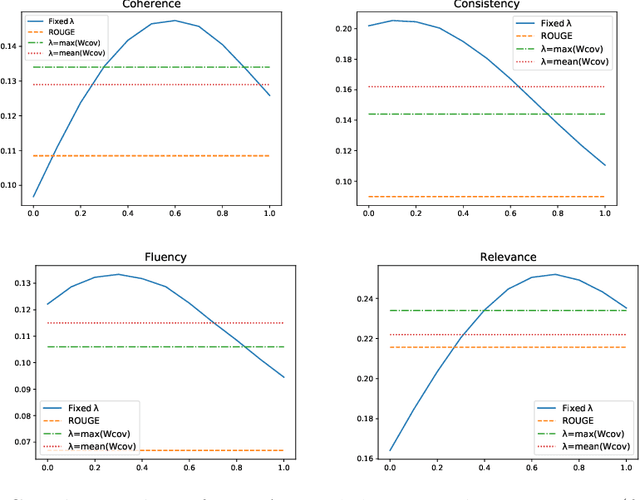
The task of automatic text summarization has gained a lot of traction due to the recent advancements in machine learning techniques. However, evaluating the quality of a generated summary remains to be an open problem. The literature has widely adopted Recall-Oriented Understudy for Gisting Evaluation (ROUGE) as the standard evaluation metric for summarization. However, ROUGE has some long-established limitations; a major one being its dependence on the availability of good quality reference summary. In this work, we propose the metric WIDAR which in addition to utilizing the reference summary uses also the input document in order to evaluate the quality of the generated summary. The proposed metric is versatile, since it is designed to adapt the evaluation score according to the quality of the reference summary. The proposed metric correlates better than ROUGE by 26%, 76%, 82%, and 15%, respectively, in coherence, consistency, fluency, and relevance on human judgement scores provided in the SummEval dataset. The proposed metric is able to obtain comparable results with other state-of-the-art metrics while requiring a relatively short computational time.
Local Trajectory Planning For UAV Autonomous Landing
Nov 18, 2021



An important capability of autonomous Unmanned Aerial Vehicles (UAVs) is autonomous landing while avoiding collision with obstacles in the process. Such capability requires real-time local trajectory planning. Although trajectory-planning methods have been introduced for cases such as emergency landing, they have not been evaluated in real-life scenarios where only the surface of obstacles can be sensed and detected. We propose a novel optimization framework using a pre-planned global path and a priority map of the landing area. Several trajectory planning algorithms were implemented and evaluated in a simulator that includes a 3D urban environment, LiDAR-based obstacle-surface sensing and UAV guidance and dynamics. We show that using our proposed optimization criterion can successfully improve the landing-mission success probability while avoiding collisions with obstacles in real-time.
Gradient and Projection Free Distributed Online Min-Max Resource Optimization
Dec 07, 2021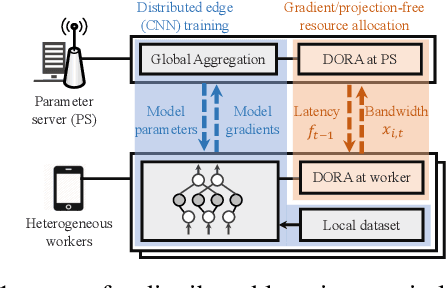
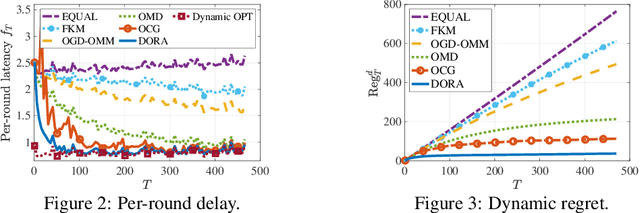
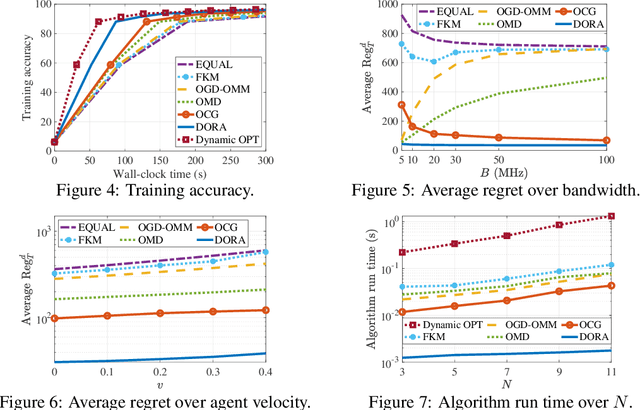
We consider distributed online min-max resource allocation with a set of parallel agents and a parameter server. Our goal is to minimize the pointwise maximum over a set of time-varying convex and decreasing cost functions, without a priori information about these functions. We propose a novel online algorithm, termed Distributed Online resource Re-Allocation (DORA), where non-stragglers learn to relinquish resource and share resource with stragglers. A notable feature of DORA is that it does not require gradient calculation or projection operation, unlike most existing online optimization strategies. This allows it to substantially reduce the computation overhead in large-scale and distributed networks. We show that the dynamic regret of the proposed algorithm is upper bounded by $O\left(T^{\frac{3}{4}}(1+P_T)^{\frac{1}{4}}\right)$, where $T$ is the total number of rounds and $P_T$ is the path-length of the instantaneous minimizers. We further consider an application to the bandwidth allocation problem in distributed online machine learning. Our numerical study demonstrates the efficacy of the proposed solution and its performance advantage over gradient- and/or projection-based resource allocation algorithms in reducing wall-clock time.
The Wasserstein-Fourier Distance for Stationary Time Series
Dec 11, 2019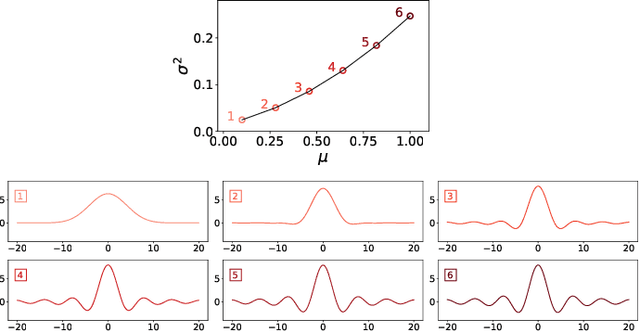

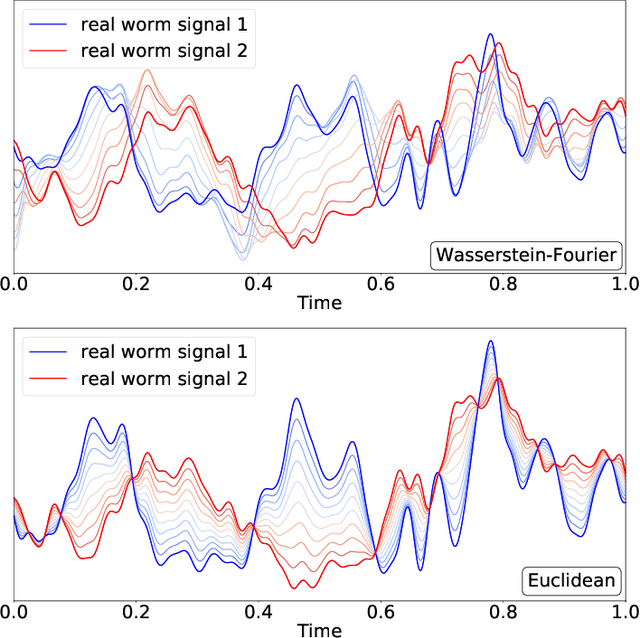
We introduce a novel framework for analysing stationary time series based on optimal transport distances and spectral embeddings. First, we represent time series by their power spectral density (PSD), which summarises the signal energy spread across the Fourier spectrum. Second, we endow the space of PSDs with the Wasserstein distance, which capitalises its unique ability to preserve the geometric information of a set of distributions. These two steps enable us to define the Wasserstein-Fourier (WF) distance, which allows us to compare stationary time series even when they differ in sampling rate, length, magnitude and phase. We analyse the features of WF by blending the properties of the Wasserstein distance and those of the Fourier transform. The proposed WF distance is then used in three sets of key time series applications considering real-world datasets: (i) interpolation of time series leading to data augmentation, (ii) dimensionality reduction via non-linear PCA, and (iii) parametric and non-parametric classification tasks. Our conceptual and experimental findings validate the general concept of using divergences of distributions, especially the Wasserstein distance, to analyse time series through comparing their spectral representations.
Image Reconstruction from Events. Why learn it?
Dec 12, 2021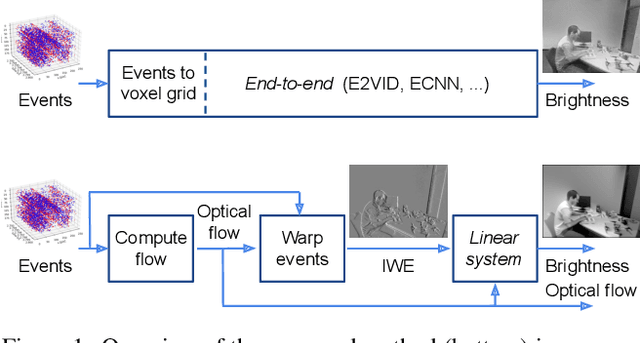
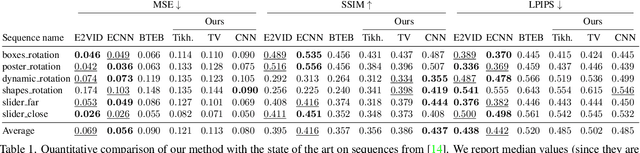

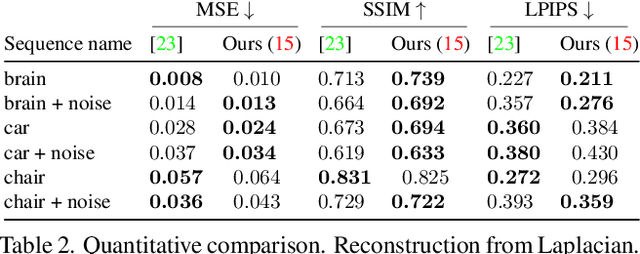
Traditional cameras measure image intensity. Event cameras, by contrast, measure per-pixel temporal intensity changes asynchronously. Recovering intensity from events is a popular research topic since the reconstructed images inherit the high dynamic range (HDR) and high-speed properties of events; hence they can be used in many robotic vision applications and to generate slow-motion HDR videos. However, state-of-the-art methods tackle this problem by training an event-to-image recurrent neural network (RNN), which lacks explainability and is difficult to tune. In this work we show, for the first time, how tackling the joint problem of motion and intensity estimation leads us to model event-based image reconstruction as a linear inverse problem that can be solved without training an image reconstruction RNN. Instead, classical and learning-based image priors can be used to solve the problem and remove artifacts from the reconstructed images. The experiments show that the proposed approach generates images with visual quality on par with state-of-the-art methods despite only using data from a short time interval (i.e., without recurrent connections). Our method can also be used to improve the quality of images reconstructed by approaches that first estimate the image Laplacian; here our method can be interpreted as Poisson reconstruction guided by image priors.