 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Almost Optimal Proper Learning and Testing Polynomials
Feb 07, 2022



We give the first almost optimal polynomial-time proper learning algorithm of Boolean sparse multivariate polynomial under the uniform distribution. For $s$-sparse polynomial over $n$ variables and $\epsilon=1/s^\beta$, $\beta>1$, our algorithm makes $$q_U=\left(\frac{s}{\epsilon}\right)^{\frac{\log \beta}{\beta}+O(\frac{1}{\beta})}+ \tilde O\left(s\right)\left(\log\frac{1}{\epsilon}\right)\log n$$ queries. Notice that our query complexity is sublinear in $1/\epsilon$ and almost linear in $s$. All previous algorithms have query complexity at least quadratic in $s$ and linear in $1/\epsilon$. We then prove the almost tight lower bound $$q_L=\left(\frac{s}{\epsilon}\right)^{\frac{\log \beta}{\beta}+\Omega(\frac{1}{\beta})}+ \Omega\left(s\right)\left(\log\frac{1}{\epsilon}\right)\log n,$$ Applying the reduction in~\cite{Bshouty19b} with the above algorithm, we give the first almost optimal polynomial-time tester for $s$-sparse polynomial. Our tester, for $\beta>3.404$, makes $$\tilde O\left(\frac{s}{\epsilon}\right)$$ queries.
Cross-domain Time Series Forecasting with Attention Sharing
Feb 13, 2021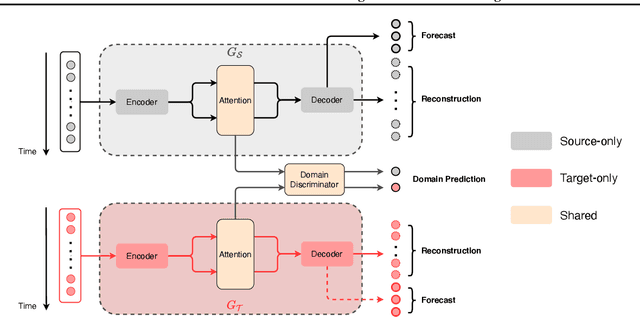
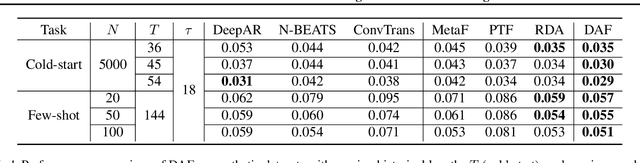

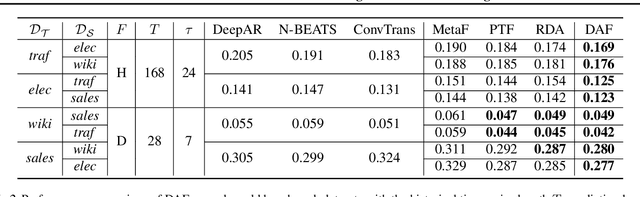
Recent years have witnessed deep neural net-works gaining increasing popularity in the field oftime series forecasting. A primary reason of theirsuccess is their ability to effectively capture com-plex temporal dynamics across multiple relatedtime series. However, the advantages of thesedeep forecasters only start to emerge in the pres-ence of a sufficient amount of data. This poses achallenge for typical forecasting problems in prac-tice, where one either has a small number of timeseries, or limited observations per time series, orboth. To cope with the issue of data scarcity, wepropose a novel domain adaptation framework,Domain Adaptation Forecaster (DAF), that lever-ages the statistical strengths from another relevantdomain with abundant data samples (source) toimprove the performance on the domain of inter-est with limited data (target). In particular, we pro-pose an attention-based shared module with a do-main discriminator across domains as well as pri-vate modules for individual domains. This allowsus to jointly train the source and target domains bygenerating domain-invariant latent features whileretraining domain-specific features. Extensive ex-periments on various domains demonstrate thatour proposed method outperforms state-of-the-artbaselines on synthetic and real-world datasets.
Late multimodal fusion for image and audio music transcription
Apr 06, 2022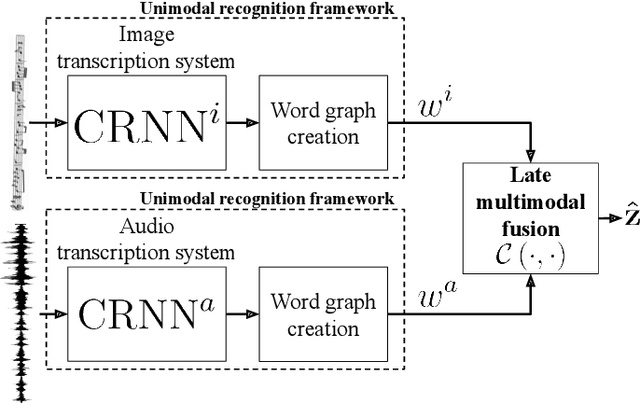
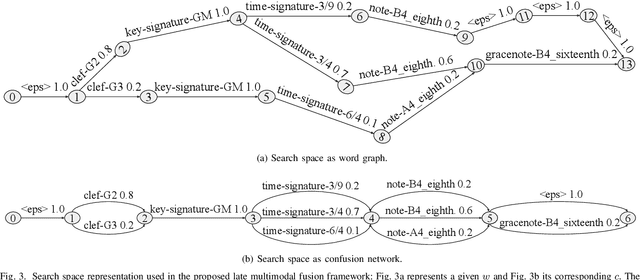
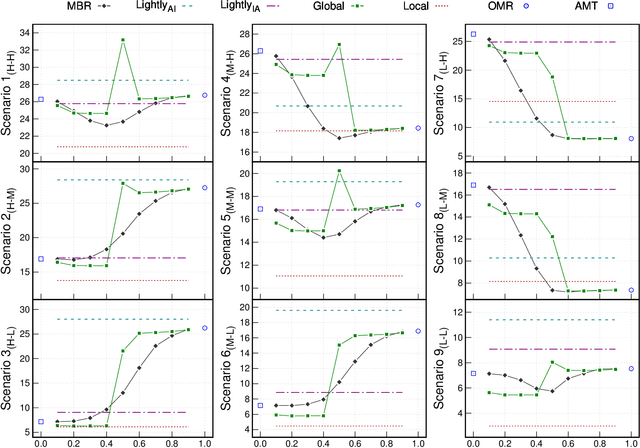

Music transcription, which deals with the conversion of music sources into a structured digital format, is a key problem for Music Information Retrieval (MIR). When addressing this challenge in computational terms, the MIR community follows two lines of research: music documents, which is the case of Optical Music Recognition (OMR), or audio recordings, which is the case of Automatic Music Transcription (AMT). The different nature of the aforementioned input data has conditioned these fields to develop modality-specific frameworks. However, their recent definition in terms of sequence labeling tasks leads to a common output representation, which enables research on a combined paradigm. In this respect, multimodal image and audio music transcription comprises the challenge of effectively combining the information conveyed by image and audio modalities. In this work, we explore this question at a late-fusion level: we study four combination approaches in order to merge, for the first time, the hypotheses regarding end-to-end OMR and AMT systems in a lattice-based search space. The results obtained for a series of performance scenarios -- in which the corresponding single-modality models yield different error rates -- showed interesting benefits of these approaches. In addition, two of the four strategies considered significantly improve the corresponding unimodal standard recognition frameworks.
Circumventing the resolution-time tradeoff in Ultrasound Localization Microscopy by Velocity Filtering
Jan 23, 2021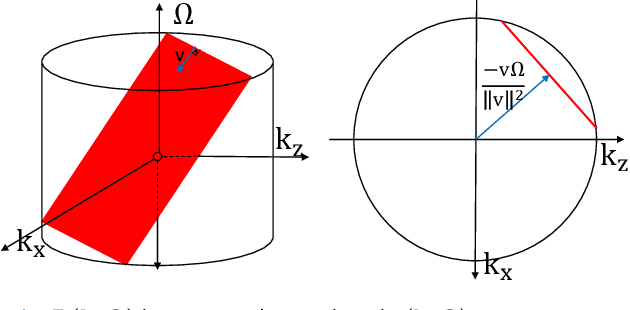
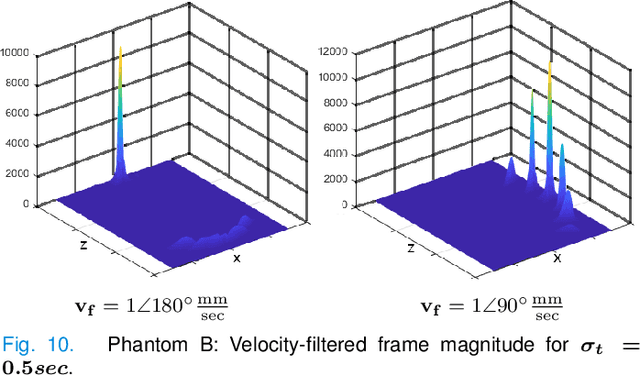
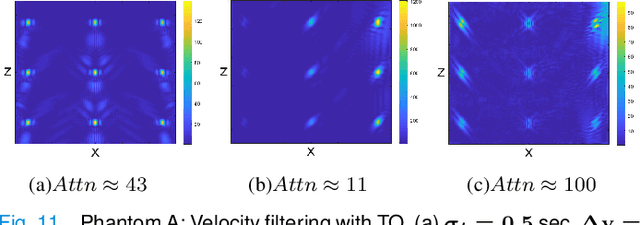
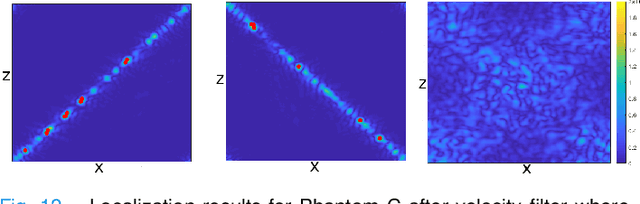
Ultrasound Localization Microscopy (ULM) offers a cost-effective modality for microvascular imaging by using intravascular contrast agents (microbubbles). However, ULM has a fundamental trade-off between acquisition time and spatial resolution, which makes clinical translation challenging. In this paper, in order to circumvent the trade-off, we introduce a spatiotemporal filtering operation dubbed velocity filtering, which is capable of separating contrast agents into different groups based on their vector velocities thus reducing interference in the localization step, while simultaneously offering blood velocity mapping at super resolution, without tracking individual microbubbles. As side benefit, the velocity filter provides noise suppression before microbubble localization that could enable substantially increased penetration depth in tissue typically by 4cm or more. We provide a theoretical analysis of the performance of velocity filter. Numerical experiments confirm that the proposed velocity filter is able to separate the microbubbles with respect to the speed and direction of their motion. In combination with subsequent localization of microbubble centers, e.g. by matched filtering, the velocity filter improves the quality of the reconstructed vasculature significantly and provides blood flow information. Overall, the proposed imaging pipeline in this paper enables the use of higher concentrations of microbubbles while preserving spatial resolution, thus helping circumvent the trade-off between acquisition time and spatial resolution. Conveniently, because the velocity filtering operation can be implemented by fast Fourier transforms(FFTs) it admits fast, and potentially real-time realization. We believe that the proposed velocity filtering method has the potential to pave the way to clinical translation of ULM.
Integration of a machine learning model into a decision support tool to predict absenteeism at work of prospective employees
Feb 02, 2022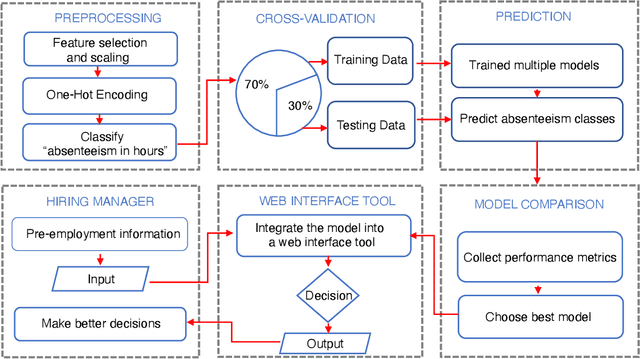
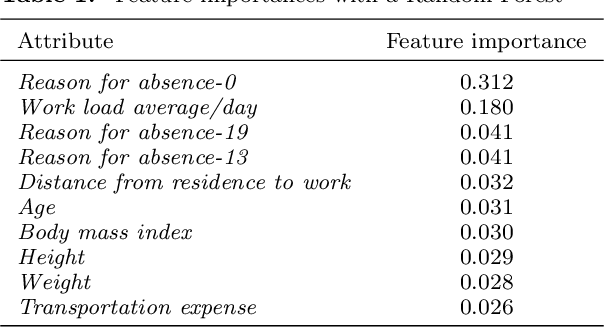
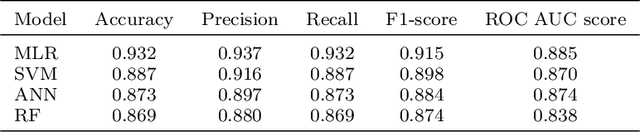
Purpose - Inefficient hiring may result in lower productivity and higher training costs. Productivity losses caused by absenteeism at work cost U.S. employers billions of dollars each year. Also, employers typically spend a considerable amount of time managing employees who perform poorly. The purpose of this study is to develop a decision support tool to predict absenteeism among potential employees. Design/methodology/approach - We utilized a popular open-access dataset. In order to categorize absenteeism classes, the data have been preprocessed, and four methods of machine learning classification have been applied: Multinomial Logistic Regression (MLR), Support Vector Machines (SVM), Artificial Neural Networks (ANN), and Random Forests (RF). We selected the best model, based on several validation scores, and compared its performance against the existing model; we then integrated the best model into our proposed web-based for hiring managers. Findings - A web-based decision tool allows hiring managers to make more informed decisions before hiring a potential employee, thus reducing time, financial loss and reducing the probability of economic insolvency. Originality/value - In this paper, we propose a model that is trained based on attributes that can be collected during the hiring process. Furthermore, hiring managers may lack experience in machine learning or do not have the time to spend developing machine learning algorithms. Thus, we propose a web-based interactive tool that can be used without prior knowledge of machine learning algorithms.
On Reinforcement Learning, Effect Handlers, and the State Monad
Mar 29, 2022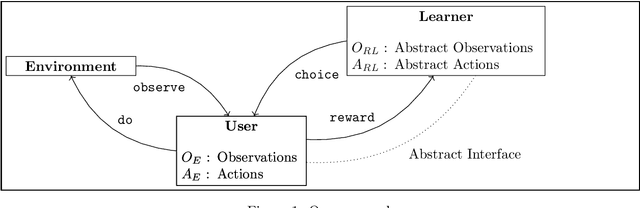


We study the algebraic effects and handlers as a way to support decision-making abstractions in functional programs, whereas a user can ask a learning algorithm to resolve choices without implementing the underlying selection mechanism, and give a feedback by way of rewards. Differently from some recently proposed approach to the problem based on the selection monad [Abadi and Plotkin, LICS 2021], we express the underlying intelligence as a reinforcement learning algorithm implemented as a set of handlers for some of these algebraic operations, including those for choices and rewards. We show how we can in practice use algebraic operations and handlers -- as available in the programming language EFF -- to clearly separate the learning algorithm from its environment, thus allowing for a good level of modularity. We then show how the host language can be taken as a lambda-calculus with handlers, this way showing what the essential linguistic features are. We conclude by hinting at how type and effect systems could ensure safety properties, at the same time pointing at some directions for further work.
Risk Awareness in HTN Planning
Apr 22, 2022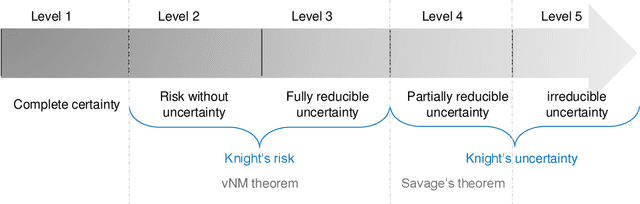
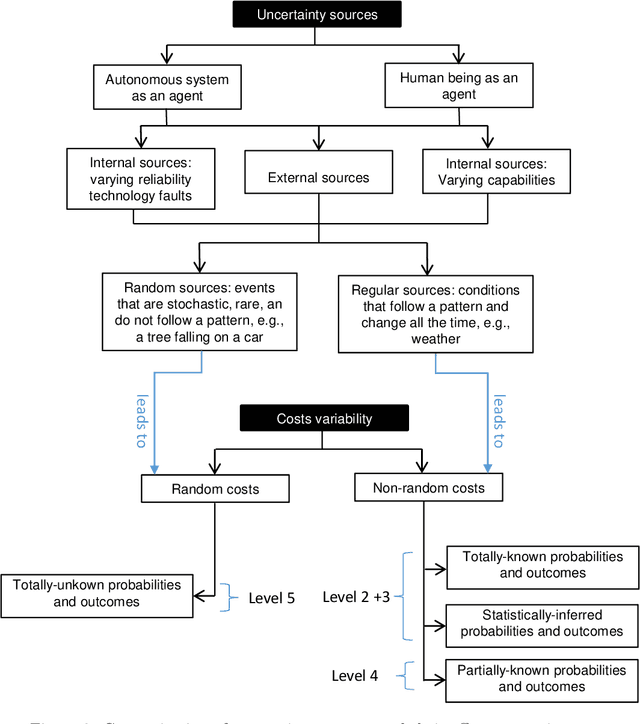
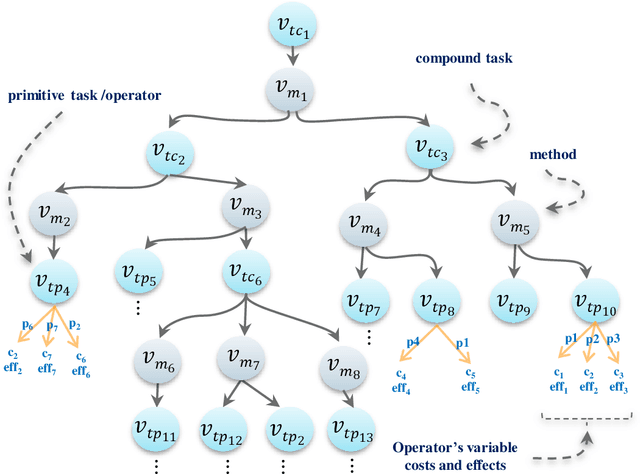
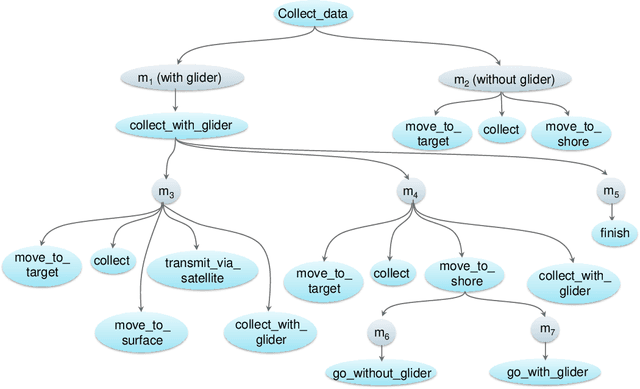
Actual real-world domains are characterised by uncertain situations in which acting and use of resources require embracing risk. Performing actions in such domains always entails costs of consuming some resource, such as time, money, or energy, where the knowledge about these costs can range from totally known to totally unknown and even unknowable probabilities of costs. Think of robotic domains, where actions and their costs are non-deterministic due to uncertain factors like obstacles. Choosing which action to perform considering its cost on the available resource requires taking a stance on risk. Thus, these domains call for not only planning under uncertainty but also planning while embracing risk. Taking Hierarchical Task Network (HTN) planning as a widely used planning technique in real-world applications, one can observe that existing approaches do not account for risk. That is, computing most probable or optimal plans using actions with single-valued costs is only enough to express risk neutrality. In this work, we postulate that HTN planning can become risk aware by considering expected utility theory, a representative concept of decision theory that enables choosing actions considering a probability distribution of their costs and a given risk attitude expressed using a utility function. In particular, we introduce a general framework for HTN planning that allows modelling risk and uncertainty using a probability distribution of action costs upon which we define risk-aware HTN planning as an approach that accounts for the different risk attitudes and allows computing plans that go beyond risk neutrality. In fact, we layout that computing risk-aware plans requires finding plans with the highest expected utility. Finally, we argue that it is possible for HTN planning agents to solve specialised risk-aware HTN planning problems by adapting some existing HTN planning approaches.
Robust alignment of cross-session recordings of neural population activity by behaviour via unsupervised domain adaptation
Feb 16, 2022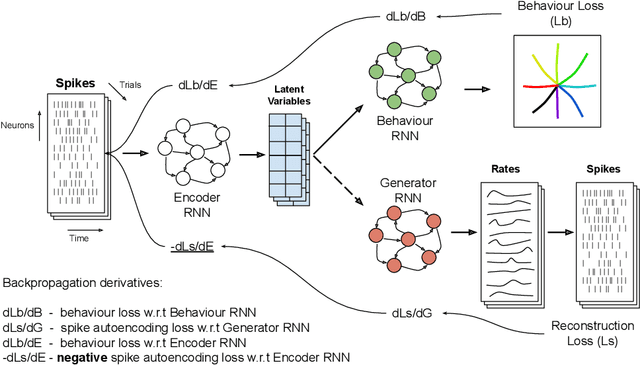
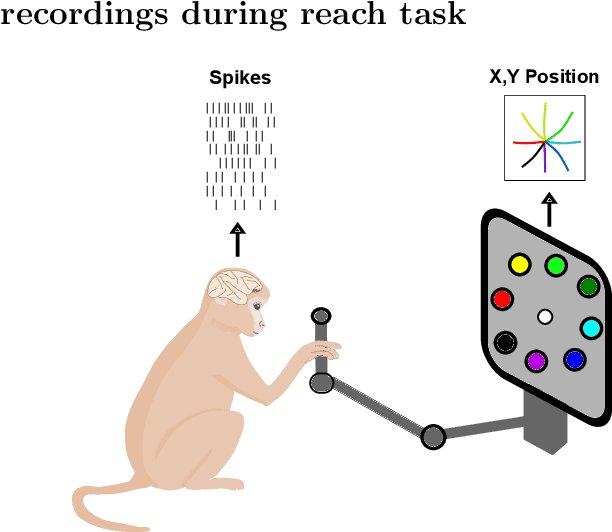
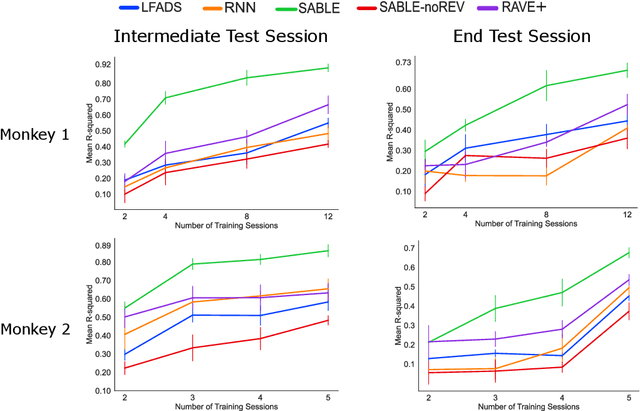
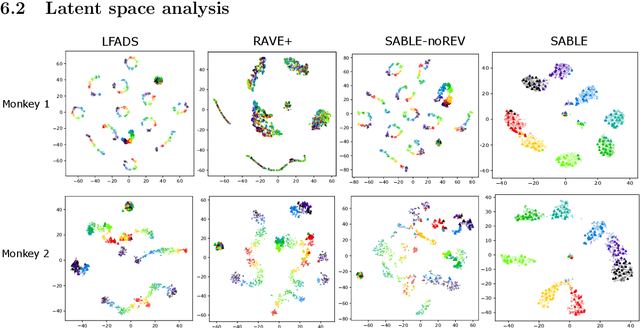
Neural population activity relating to behaviour is assumed to be inherently low-dimensional despite the observed high dimensionality of data recorded using multi-electrode arrays. Therefore, predicting behaviour from neural population recordings has been shown to be most effective when using latent variable models. Over time however, the activity of single neurons can drift, and different neurons will be recorded due to movement of implanted neural probes. This means that a decoder trained to predict behaviour on one day performs worse when tested on a different day. On the other hand, evidence suggests that the latent dynamics underlying behaviour may be stable even over months and years. Based on this idea, we introduce a model capable of inferring behaviourally relevant latent dynamics from previously unseen data recorded from the same animal, without any need for decoder recalibration. We show that unsupervised domain adaptation combined with a sequential variational autoencoder, trained on several sessions, can achieve good generalisation to unseen data and correctly predict behaviour where conventional methods fail. Our results further support the hypothesis that behaviour-related neural dynamics are low-dimensional and stable over time, and will enable more effective and flexible use of brain computer interface technologies.
Visual Forecasting of Time Series with Image-to-Image Regression
Nov 18, 2020
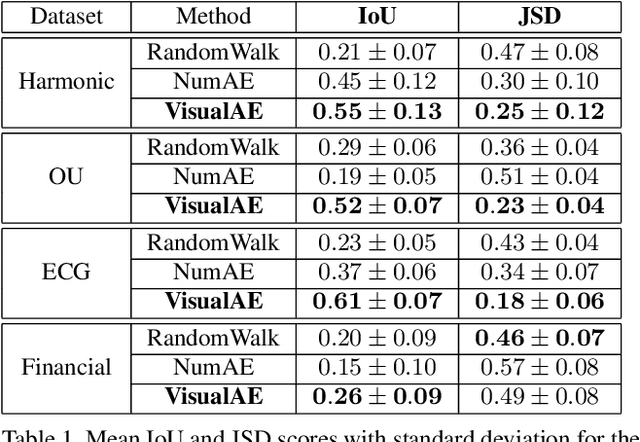
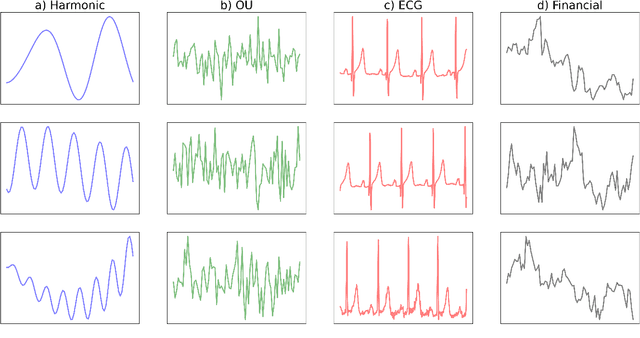
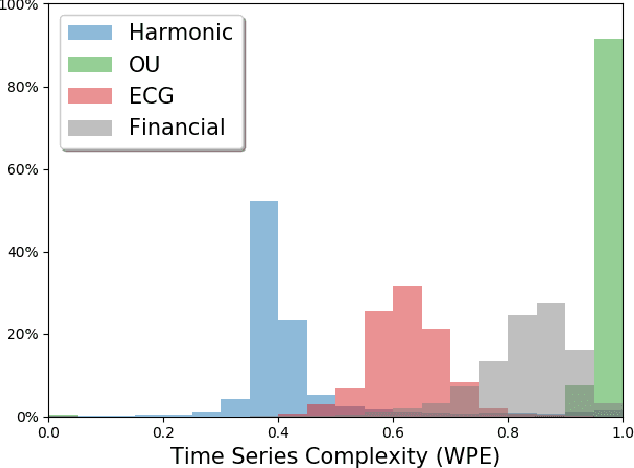
Time series forecasting is essential for agents to make decisions in many domains. Existing models rely on classical statistical methods to predict future values based on previously observed numerical information. Yet, practitioners often rely on visualizations such as charts and plots to reason about their predictions. Inspired by the end-users, we re-imagine the topic by creating a framework to produce visual forecasts, similar to the way humans intuitively do. In this work, we take a novel approach by leveraging advances in deep learning to extend the field of time series forecasting to a visual setting. We do this by transforming the numerical analysis problem into the computer vision domain. Using visualizations of time series data as input, we train a convolutional autoencoder to produce corresponding visual forecasts. We examine various synthetic and real datasets with diverse degrees of complexity. Our experiments show that visual forecasting is effective for cyclic data but somewhat less for irregular data such as stock price. Importantly, we find the proposed visual forecasting method to outperform numerical baselines. We attribute the success of the visual forecasting approach to the fact that we convert the continuous numerical regression problem into a discrete domain with quantization of the continuous target signal into pixel space.
Intelligent Systematic Investment Agent: an ensemble of deep learning and evolutionary strategies
Mar 24, 2022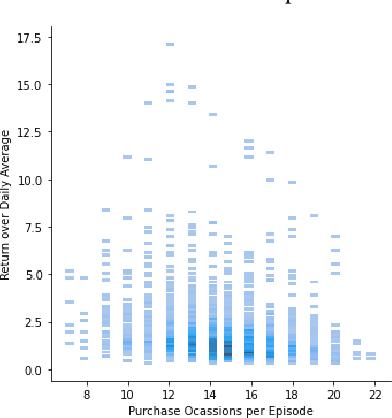
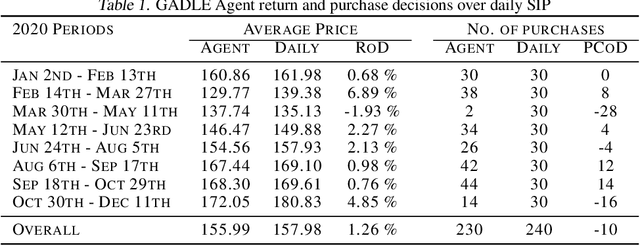
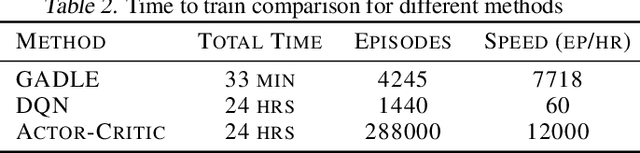
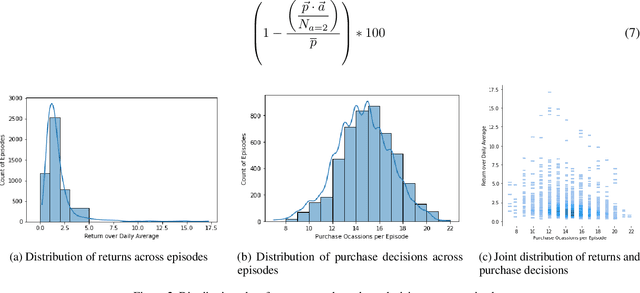
Machine learning driven trading strategies have garnered a lot of interest over the past few years. There is, however, limited consensus on the ideal approach for the development of such trading strategies. Further, most literature has focused on trading strategies for short-term trading, with little or no focus on strategies that attempt to build long-term wealth. Our paper proposes a new approach for developing long-term investment strategies using an ensemble of evolutionary algorithms and a deep learning model by taking a series of short-term purchase decisions. Our methodology focuses on building long-term wealth by improving systematic investment planning (SIP) decisions on Exchange Traded Funds (ETF) over a period of time. We provide empirical evidence of superior performance (around 1% higher returns) using our ensemble approach as compared to the traditional daily systematic investment practice on a given ETF. Our results are based on live trading decisions made by our algorithm and executed on the Robinhood trading platform.