 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sequential Doppler Shift based Optimal Localization and Synchronization with TOA
Feb 14, 2022
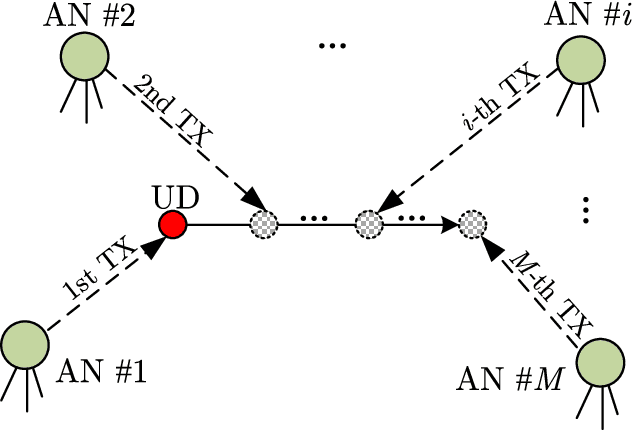
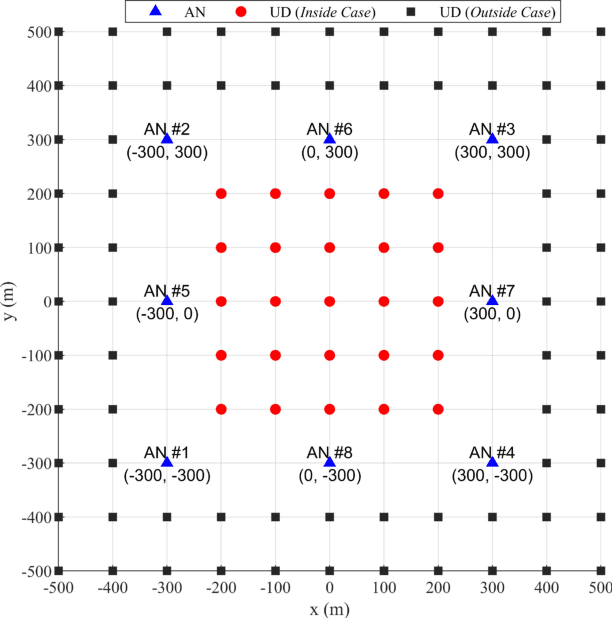
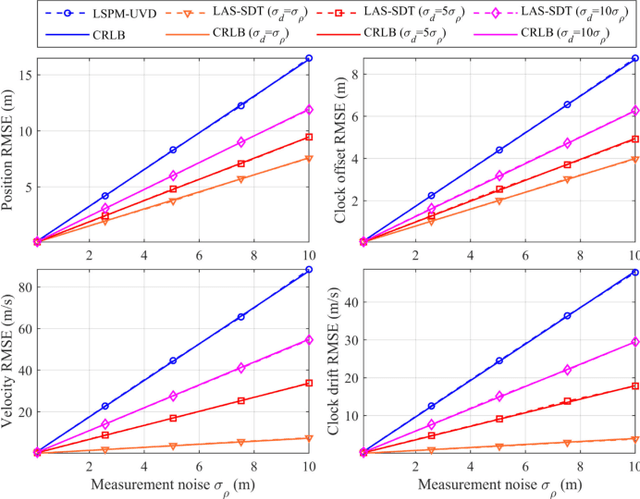
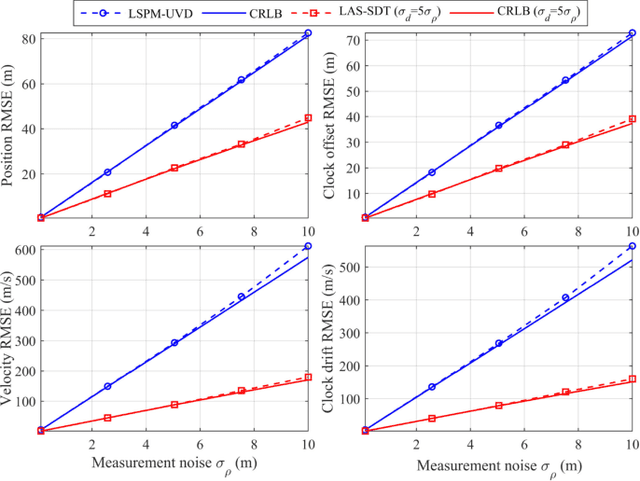
Doppler shift is an important measurement for localization and synchronization (LAS), and is available in various practical systems. Existing studies on LAS techniques in a time division broadcast LAS system (TDBS) only use sequential time-of-arrival (TOA) measurements from the broadcast signals. In this paper, we develop a new optimal LAS method in the TDBS, namely LAS-SDT, by taking advantage of the sequential Doppler shift and TOA measurements. It achieves higher accuracy compared with the conventional TOA-only method for user devices (UDs) with motion and clock drift. Another two variant methods, LAS-SDT-v for the case with UD velocity aiding, and LAS-SDT-k for the case with UD clock drift aiding, are developed. We derive the Cramer-Rao lower bound (CRLB) for these different cases. We show analytically that the accuracies of the estimated UD position, clock offset, velocity and clock drift are all significantly higher than those of the conventional LAS method using TOAs only. Numerical results corroborate the theoretical analysis and show the optimal estimation performance of the LAS-SDT.
Learning to modulate random weights can induce task-specific contexts for economical meta and continual learning
Apr 08, 2022
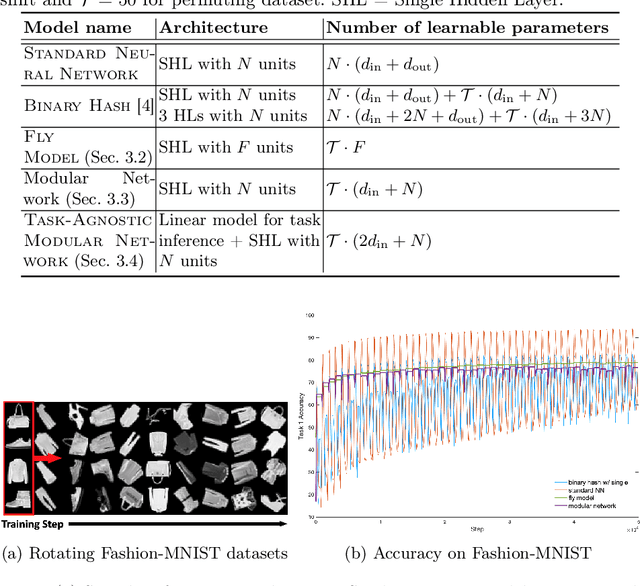
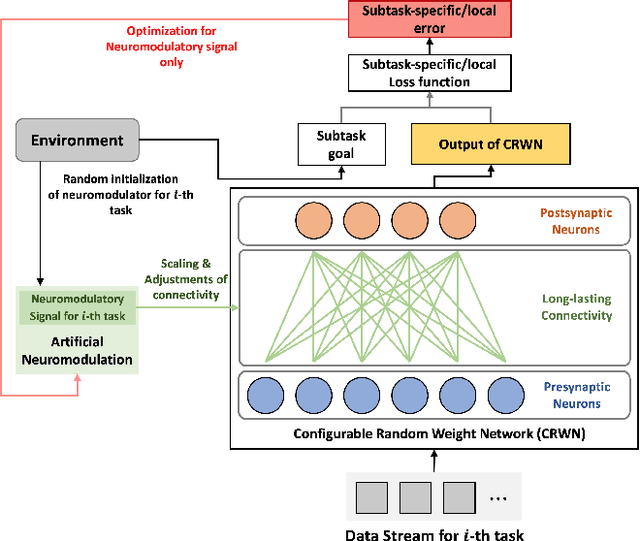
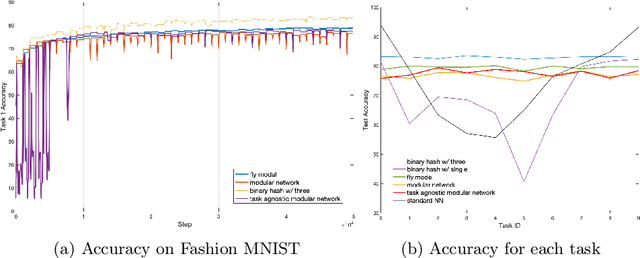
Neural networks are vulnerable to catastrophic forgetting when data distributions are non-stationary during continual online learning; learning of a later task often leads to forgetting of an earlier task. One solution approach is model-agnostic continual meta-learning, whereby both task-specific and meta parameters are trained. Here, we depart from this view and introduce a novel neural-network architecture inspired by neuromodulation in biological nervous systems. Neuromodulation is the biological mechanism that dynamically controls and fine-tunes synaptic dynamics to complement the behavioral context in real-time, which has received limited attention in machine learning. We introduce a single-hidden-layer network that learns only a relatively small context vector per task (task-specific parameters) that neuromodulates unchanging, randomized weights (meta parameters) that transform the input. We show that when task boundaries are available, this approach can eliminate catastrophic forgetting entirely while also drastically reducing the number of learnable parameters relative to other context-vector-based approaches. Furthermore, by combining this model with a simple meta-learning approach for inferring task identity, we demonstrate that the model can be generalized into a framework to perform continual learning without knowledge of task boundaries. Finally, we showcase the framework in a supervised continual online learning scenario and discuss the implications of the proposed formalism.
Learning Commonsense-aware Moment-Text Alignment for Fast Video Temporal Grounding
Apr 12, 2022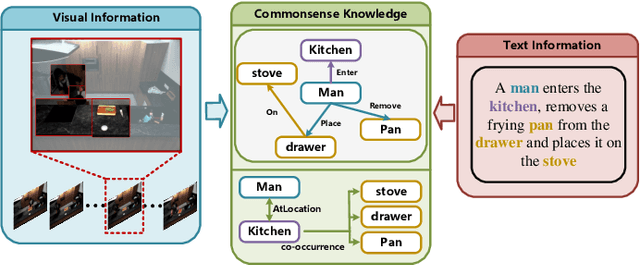
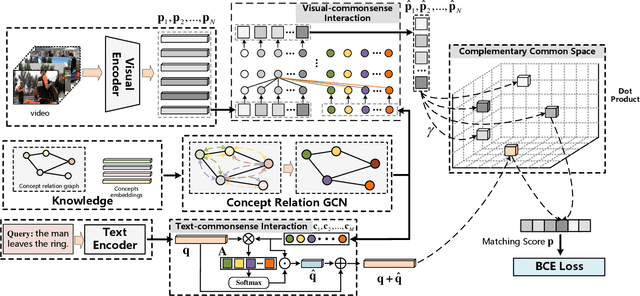
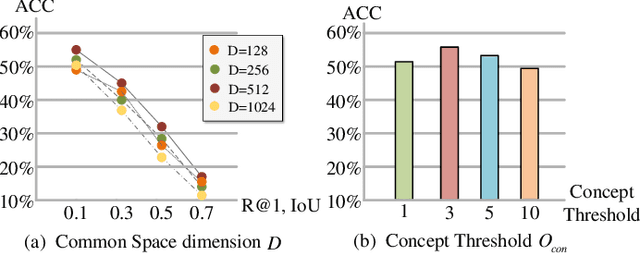
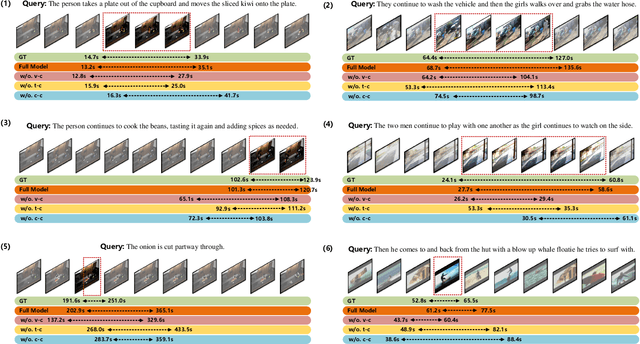
Grounding temporal video segments described in natural language queries effectively and efficiently is a crucial capability needed in vision-and-language fields. In this paper, we deal with the fast video temporal grounding (FVTG) task, aiming at localizing the target segment with high speed and favorable accuracy. Most existing approaches adopt elaborately designed cross-modal interaction modules to improve the grounding performance, which suffer from the test-time bottleneck. Although several common space-based methods enjoy the high-speed merit during inference, they can hardly capture the comprehensive and explicit relations between visual and textual modalities. In this paper, to tackle the dilemma of speed-accuracy tradeoff, we propose a commonsense-aware cross-modal alignment (CCA) framework, which incorporates commonsense-guided visual and text representations into a complementary common space for fast video temporal grounding. Specifically, the commonsense concepts are explored and exploited by extracting the structural semantic information from a language corpus. Then, a commonsense-aware interaction module is designed to obtain bridged visual and text features by utilizing the learned commonsense concepts. Finally, to maintain the original semantic information of textual queries, a cross-modal complementary common space is optimized to obtain matching scores for performing FVTG. Extensive results on two challenging benchmarks show that our CCA method performs favorably against state-of-the-arts while running at high speed. Our code is available at https://github.com/ZiyueWu59/CCA.
Real-Time, Deep Synthetic Aperture Sonar (SAS) Autofocus
Mar 18, 2021
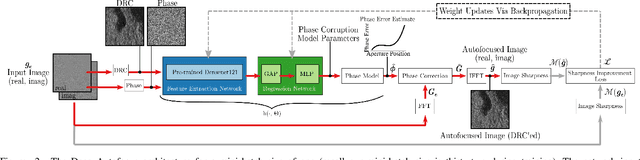
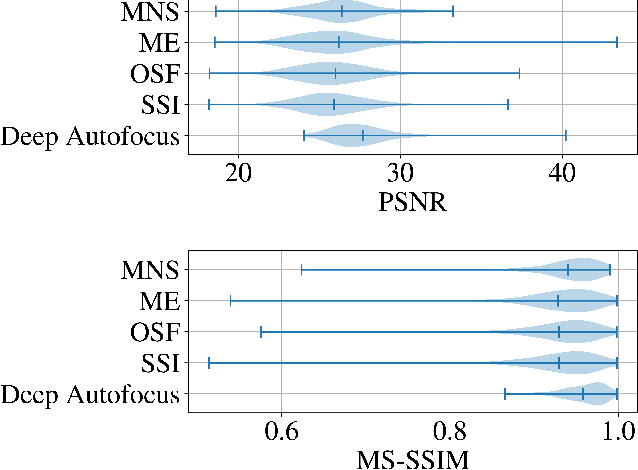

Synthetic aperture sonar (SAS) requires precise time-of-flight measurements of the transmitted/received waveform to produce well-focused imagery. It is not uncommon for errors in these measurements to be present resulting in image defocusing. To overcome this, an \emph{autofocus} algorithm is employed as a post-processing step after image reconstruction to improve image focus. A particular class of these algorithms can be framed as a sharpness/contrast metric-based optimization. To improve convergence, a hand-crafted weighting function to remove "bad" areas of the image is sometimes applied to the image-under-test before the optimization procedure. Additionally, dozens of iterations are necessary for convergence which is a large compute burden for low size, weight, and power (SWaP) systems. We propose a deep learning technique to overcome these limitations and implicitly learn the weighting function in a data-driven manner. Our proposed method, which we call Deep Autofocus, uses features from the single-look-complex (SLC) to estimate the phase correction which is applied in $k$-space. Furthermore, we train our algorithm on batches of training imagery so that during deployment, only a single iteration of our method is sufficient to autofocus. We show results demonstrating the robustness of our technique by comparing our results to four commonly used image sharpness metrics. Our results demonstrate Deep Autofocus can produce imagery perceptually better than common iterative techniques but at a lower computational cost. We conclude that Deep Autofocus can provide a more favorable cost-quality trade-off than alternatives with significant potential of future research.
Kratt: Developing an Automatic Subject Indexing Tool for The National Library of Estonia
Mar 24, 2022Manual subject indexing in libraries is a time-consuming and costly process and the quality of the assigned subjects is affected by the cataloguer's knowledge on the specific topics contained in the book. Trying to solve these issues, we exploited the opportunities arising from artificial intelligence to develop Kratt: a prototype of an automatic subject indexing tool. Kratt is able to subject index a book independent of its extent and genre with a set of keywords present in the Estonian Subject Thesaurus. It takes Kratt approximately 1 minute to subject index a book, outperforming humans 10-15 times. Although the resulting keywords were not considered satisfactory by the cataloguers, the ratings of a small sample of regular library users showed more promise. We also argue that the results can be enhanced by including a bigger corpus for training the model and applying more careful preprocessing techniques.
* This is a preprint version. It has 12 pages, 5 figures, 3 tables
Fast, Accurate and Memory-Efficient Partial Permutation Synchronization
Mar 31, 2022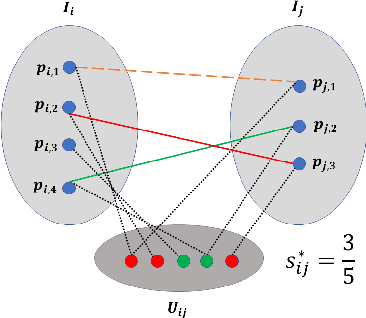
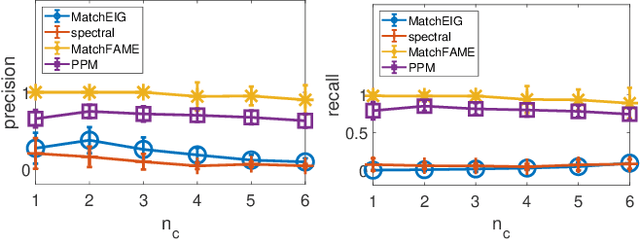
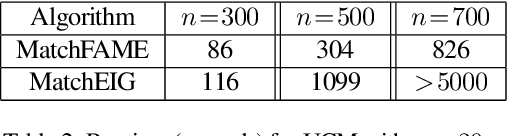
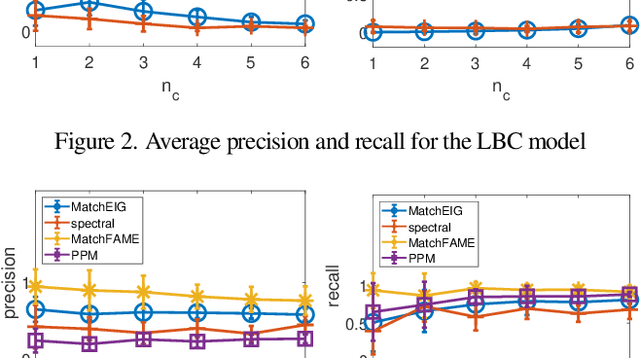
Previous partial permutation synchronization (PPS) algorithms, which are commonly used for multi-object matching, often involve computation-intensive and memory-demanding matrix operations. These operations become intractable for large scale structure-from-motion datasets. For pure permutation synchronization, the recent Cycle-Edge Message Passing (CEMP) framework suggests a memory-efficient and fast solution. Here we overcome the restriction of CEMP to compact groups and propose an improved algorithm, CEMP-Partial, for estimating the corruption levels of the observed partial permutations. It allows us to subsequently implement a nonconvex weighted projected power method without the need of spectral initialization. The resulting new PPS algorithm, MatchFAME (Fast, Accurate and Memory-Efficient Matching), only involves sparse matrix operations, and thus enjoys lower time and space complexities in comparison to previous PPS algorithms. We prove that under adversarial corruption, though without additive noise and with certain assumptions, CEMP-Partial is able to exactly classify corrupted and clean partial permutations. We demonstrate the state-of-the-art accuracy, speed and memory efficiency of our method on both synthetic and real datasets.
OntoSeer -- A Recommendation System to Improve the Quality of Ontologies
Feb 04, 2022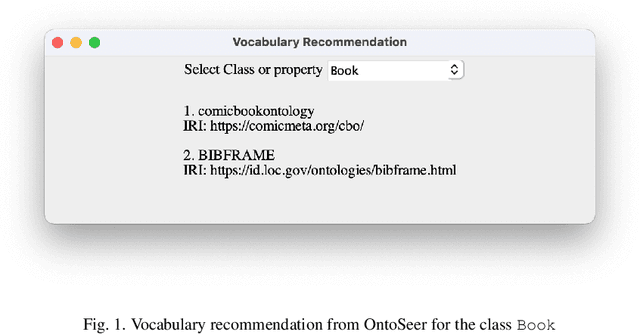

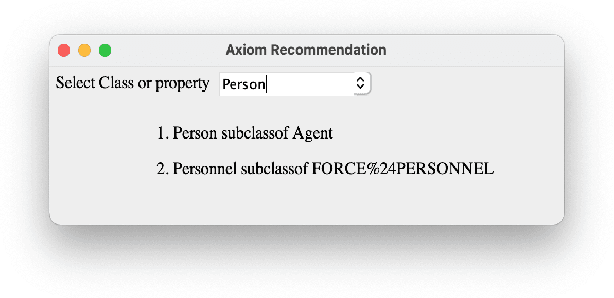
Building an ontology is not only a time-consuming process, but it is also confusing, especially for beginners and the inexperienced. Although ontology developers can take the help of domain experts in building an ontology, they are not readily available in several cases for a variety of reasons. Ontology developers have to grapple with several questions related to the choice of classes, properties, and the axioms that should be included. Apart from this, there are aspects such as modularity and reusability that should be taken care of. From among the thousands of publicly available ontologies and vocabularies in repositories such as Linked Open Vocabularies (LOV) and BioPortal, it is hard to know the terms (classes and properties) that can be reused in the development of an ontology. A similar problem exists in implementing the right set of ontology design patterns (ODPs) from among the several available. Generally, ontology developers make use of their experience in handling these issues, and the inexperienced ones have a hard time. In order to bridge this gap, we propose a tool named OntoSeer, that monitors the ontology development process and provides suggestions in real-time to improve the quality of the ontology under development. It can provide suggestions on the naming conventions to follow, vocabulary to reuse, ODPs to implement, and axioms to be added to the ontology. OntoSeer has been implemented as a Prot\'eg\'e plug-in.
A Temporal-oriented Broadcast ResNet for COVID-19 Detection
Mar 31, 2022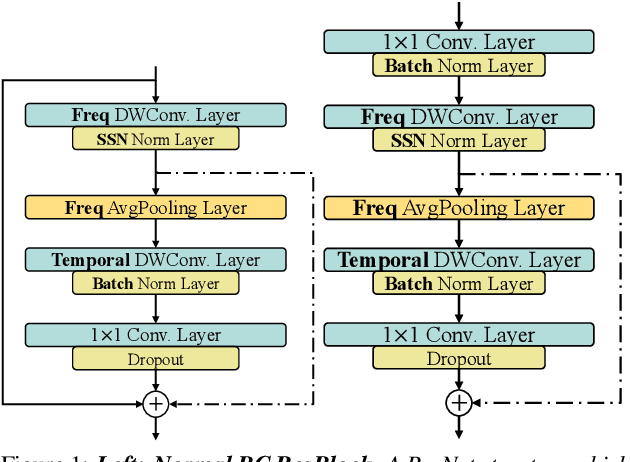


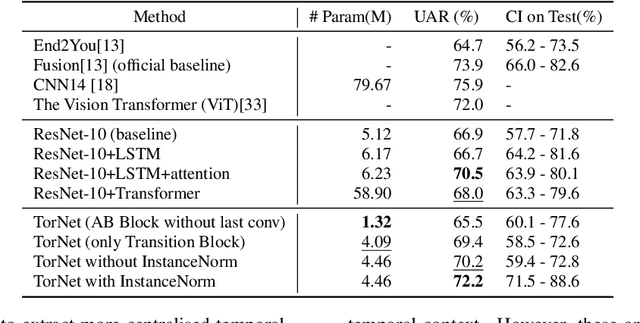
Detecting COVID-19 from audio signals, such as breathing and coughing, can be used as a fast and efficient pre-testing method to reduce the virus transmission. Due to the promising results of deep learning networks in modelling time sequences, and since applications to rapidly identify COVID in-the-wild should require low computational effort, we present a temporal-oriented broadcasting residual learning method that achieves efficient computation and high accuracy with a small model size. Based on the EfficientNet architecture, our novel network, named Temporal-oriented ResNet~(TorNet), constitutes of a broadcasting learning block, i.e. the Alternating Broadcast (AB) Block, which contains several Broadcast Residual Blocks (BC ResBlocks) and a convolution layer. With the AB Block, the network obtains useful audio-temporal features and higher level embeddings effectively with much less computation than Recurrent Neural Networks~(RNNs), typically used to model temporal information. TorNet achieves 72.2% Unweighted Average Recall (UAR) on the INTERPSEECH 2021 Computational Paralinguistics Challenge COVID-19 cough Sub-Challenge, by this showing competitive results with a higher computational efficiency than other state-of-the-art alternatives.
Proximal Policy Optimization Learning based Control of Congested Freeway Traffic
Apr 12, 2022
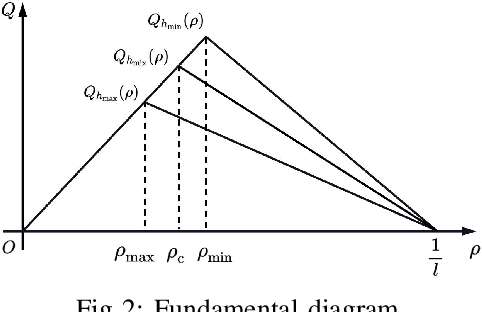
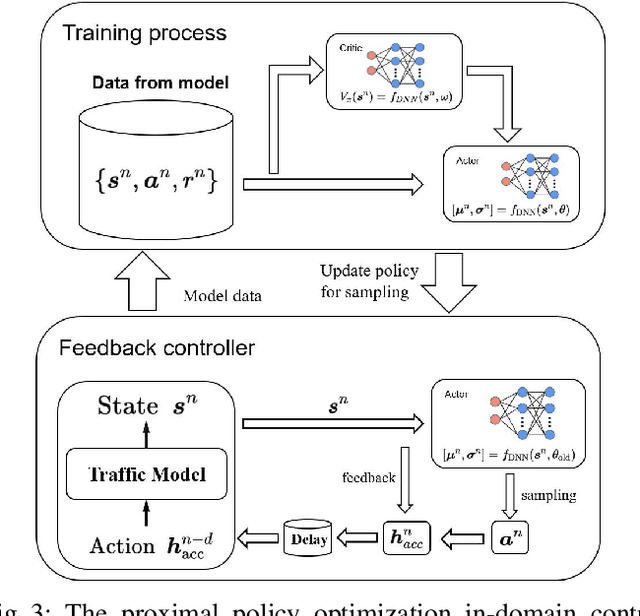
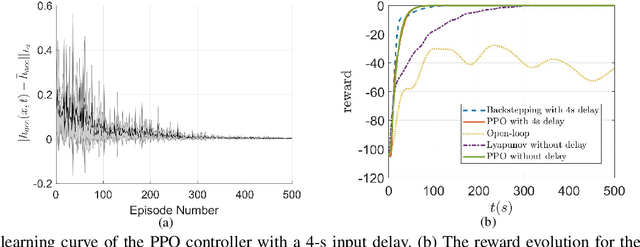
This study proposes a delay-compensated feedback controller based on proximal policy optimization (PPO) reinforcement learning to stabilize traffic flow in the congested regime by manipulating the time-gap of adaptive cruise control-equipped (ACC-equipped) vehicles.The traffic dynamics on a freeway segment are governed by an Aw-Rascle-Zhang (ARZ) model, consisting of $2\times 2$ nonlinear first-order partial differential equations (PDEs).Inspired by the backstepping delay compensator [18] but different from whose complex segmented control scheme, the PPO control is composed of three feedbacks, namely the current traffic flow velocity, the current traffic flow density and previous one step control input. The control gains for the three feedbacks are learned from the interaction between the PPO and the numerical simulator of the traffic system without knowing the system dynamics. Numerical simulation experiments are designed to compare the Lyapunov control, the backstepping control and the PPO control. The results show that for a delay-free system, the PPO control has faster convergence rate and less control effort than the Lyapunov control. For a traffic system with input delay, the performance of the PPO controller is comparable to that of the Backstepping controller, even for the situation that the delay value does not match. However, the PPO is robust to parameter perturbations, while the Backstepping controller cannot stabilize a system where one of the parameters is disturbed by Gaussian noise.
Tackling System and Statistical Heterogeneity for Federated Learning with Adaptive Client Sampling
Dec 21, 2021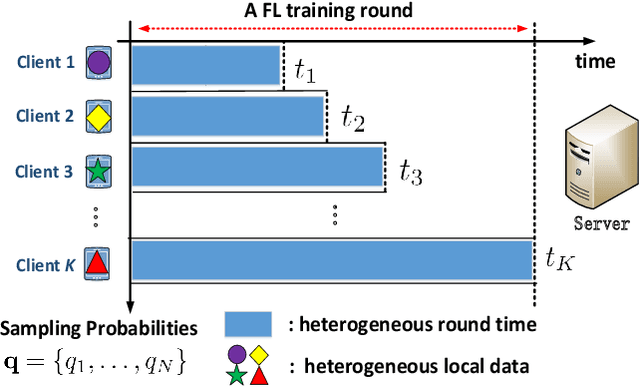
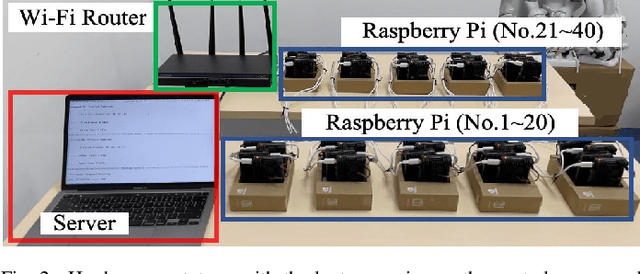
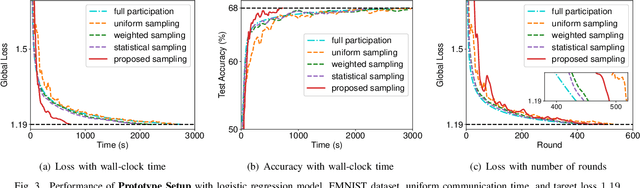
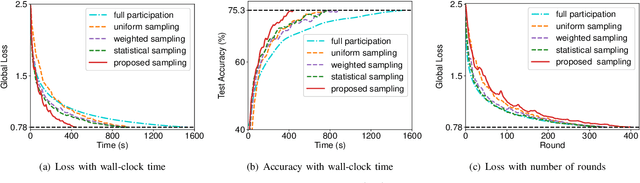
Federated learning (FL) algorithms usually sample a fraction of clients in each round (partial participation) when the number of participants is large and the server's communication bandwidth is limited. Recent works on the convergence analysis of FL have focused on unbiased client sampling, e.g., sampling uniformly at random, which suffers from slow wall-clock time for convergence due to high degrees of system heterogeneity and statistical heterogeneity. This paper aims to design an adaptive client sampling algorithm that tackles both system and statistical heterogeneity to minimize the wall-clock convergence time. We obtain a new tractable convergence bound for FL algorithms with arbitrary client sampling probabilities. Based on the bound, we analytically establish the relationship between the total learning time and sampling probabilities, which results in a non-convex optimization problem for training time minimization. We design an efficient algorithm for learning the unknown parameters in the convergence bound and develop a low-complexity algorithm to approximately solve the non-convex problem. Experimental results from both hardware prototype and simulation demonstrate that our proposed sampling scheme significantly reduces the convergence time compared to several baseline sampling schemes. Notably, our scheme in hardware prototype spends 73% less time than the uniform sampling baseline for reaching the same target loss.