 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dropout Inference with Non-Uniform Weight Scaling
Apr 27, 2022

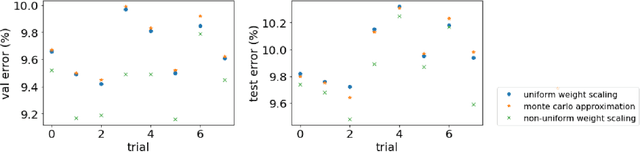

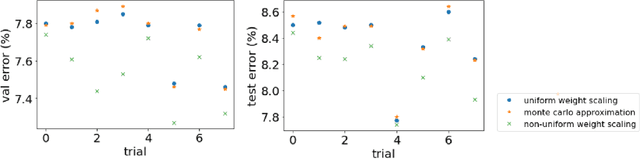
Dropout as regularization has been used extensively to prevent overfitting for training neural networks. During training, units and their connections are randomly dropped, which could be considered as sampling many different submodels from the original model. At test time, weight scaling and Monte Carlo approximation are two widely applied approaches to approximate the outputs. Both approaches work well practically when all submodels are low-bias complex learners. However, in this work, we demonstrate scenarios where some submodels behave closer to high-bias models and a non-uniform weight scaling is a better approximation for inference.
Karaoker: Alignment-free singing voice synthesis with speech training data
Apr 08, 2022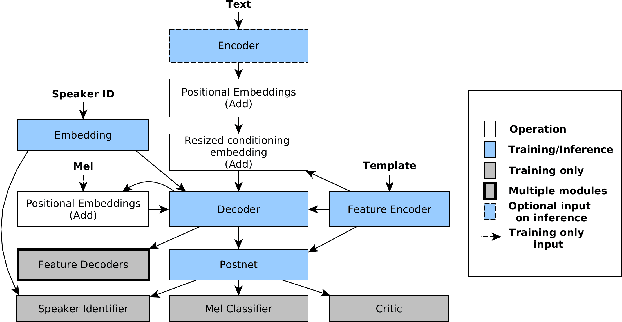
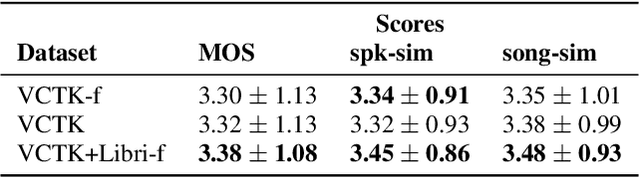
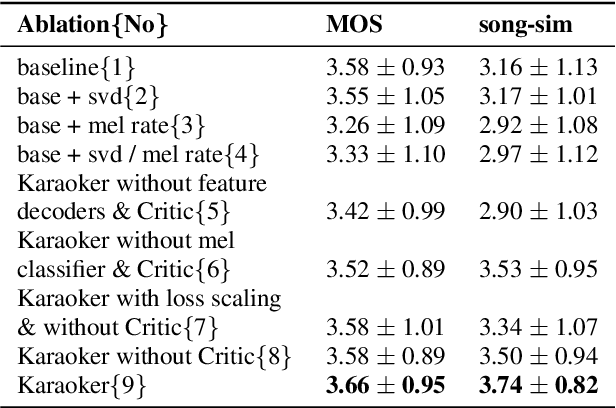
Existing singing voice synthesis models (SVS) are usually trained on singing data and depend on either error-prone time-alignment and duration features or explicit music score information. In this paper, we propose Karaoker, a multispeaker Tacotron-based model conditioned on voice characteristic features that is trained exclusively on spoken data without requiring time-alignments. Karaoker synthesizes singing voice following a multi-dimensional template extracted from a source waveform of an unseen speaker/singer. The model is jointly conditioned with a single deep convolutional encoder on continuous data including pitch, intensity, harmonicity, formants, cepstral peak prominence and octaves. We extend the text-to-speech training objective with feature reconstruction, classification and speaker identification tasks that guide the model to an accurate result. Except for multi-tasking, we also employ a Wasserstein GAN training scheme as well as new losses on the acoustic model's output to further refine the quality of the model.
Multi-objective QUBO Solver: Bi-objective Quadratic Assignment
May 26, 2022
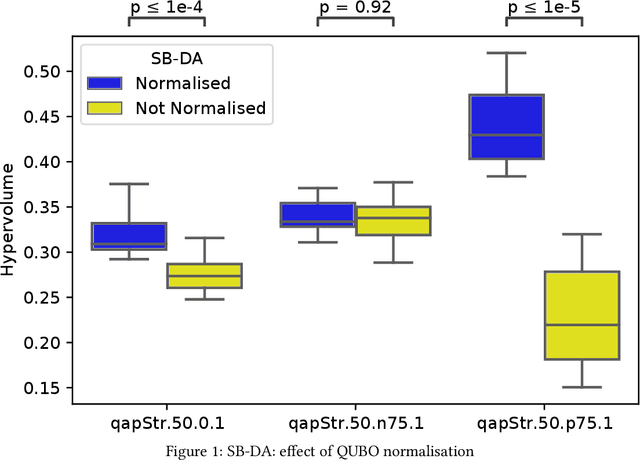
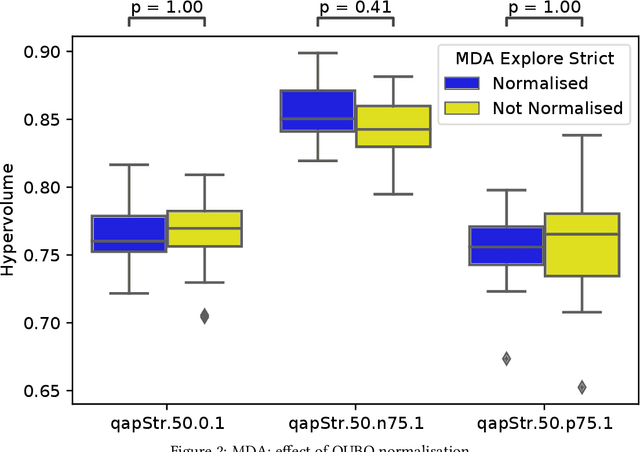

Quantum and quantum-inspired optimisation algorithms are designed to solve problems represented in binary, quadratic and unconstrained form. Combinatorial optimisation problems are therefore often formulated as Quadratic Unconstrained Binary Optimisation Problems (QUBO) to solve them with these algorithms. Moreover, these QUBO solvers are often implemented using specialised hardware to achieve enormous speedups, e.g. Fujitsu's Digital Annealer (DA) and D-Wave's Quantum Annealer. However, these are single-objective solvers, while many real-world problems feature multiple conflicting objectives. Thus, a common practice when using these QUBO solvers is to scalarise such multi-objective problems into a sequence of single-objective problems. Due to design trade-offs of these solvers, formulating each scalarisation may require more time than finding a local optimum. We present the first attempt to extend the algorithm supporting a commercial QUBO solver as a multi-objective solver that is not based on scalarisation. The proposed multi-objective DA algorithm is validated on the bi-objective Quadratic Assignment Problem. We observe that algorithm performance significantly depends on the archiving strategy adopted, and that combining DA with non-scalarisation methods to optimise multiple objectives outperforms the current scalarised version of the DA in terms of final solution quality.
Conversation Group Detection With Spatio-Temporal Context
Jun 02, 2022
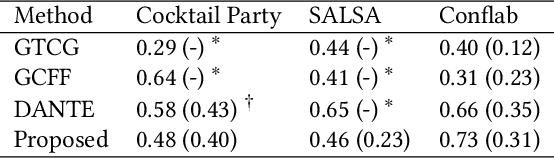

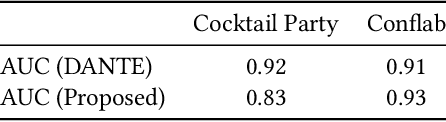
In this work, we propose an approach for detecting conversation groups in social scenarios like cocktail parties and networking events, from overhead camera recordings. We posit the detection of conversation groups as a learning problem that could benefit from leveraging the spatial context of the surroundings, and the inherent temporal context in interpersonal dynamics which is reflected in the temporal dynamics in human behavior signals, an aspect that has not been addressed in recent prior works. This motivates our approach which consists of a dynamic LSTM-based deep learning model that predicts continuous pairwise affinity values indicating how likely two people are in the same conversation group. These affinity values are also continuous in time, since relationships and group membership do not occur instantaneously, even though the ground truths of group membership are binary. Using the predicted affinity values, we apply a graph clustering method based on Dominant Set extraction to identify the conversation groups. We benchmark the proposed method against established methods on multiple social interaction datasets. Our results showed that the proposed method improves group detection performance in data that has more temporal granularity in conversation group labels. Additionally, we provide an analysis in the predicted affinity values in relation to the conversation group detection. Finally, we demonstrate the usability of the predicted affinity values in a forecasting framework to predict group membership for a given forecast horizon.
Analytical Interpretation of Latent Codes in InfoGAN with SAR Images
May 26, 2022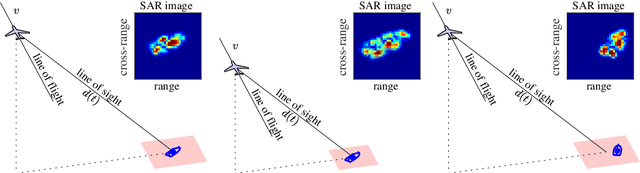
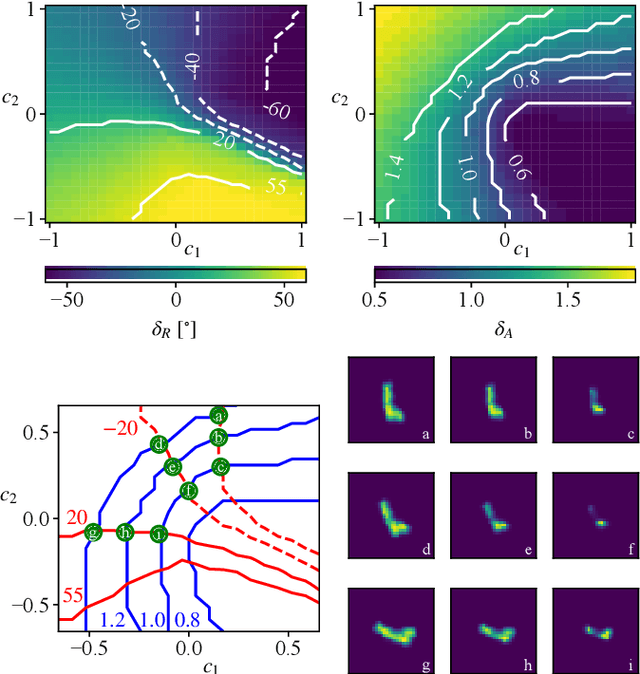
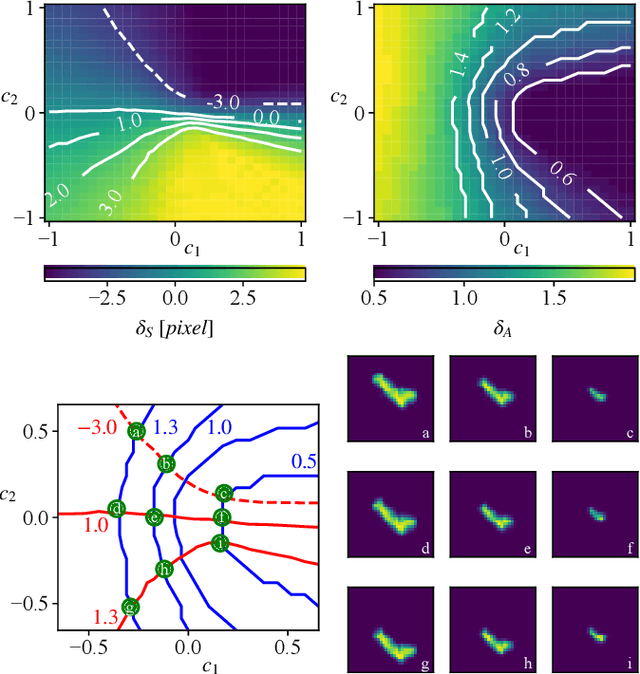
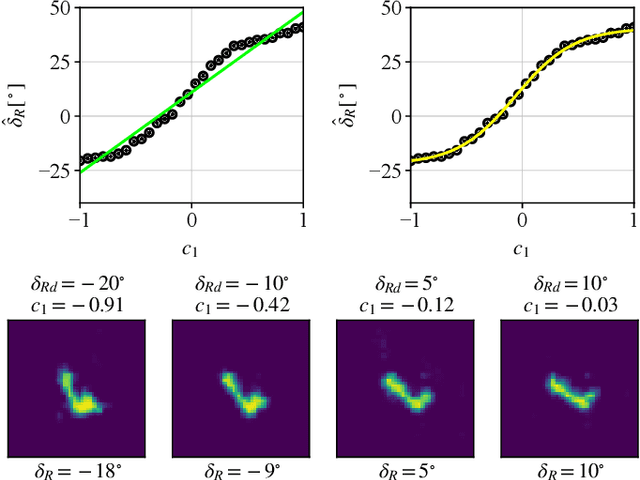
Generative Adversarial Networks (GANs) can synthesize abundant photo-realistic synthetic aperture radar (SAR) images. Some recent GANs (e.g., InfoGAN), are even able to edit specific properties of the synthesized images by introducing latent codes. It is crucial for SAR image synthesis since the targets in real SAR images are with different properties due to the imaging mechanism. Despite the success of InfoGAN in manipulating properties, there still lacks a clear explanation of how these latent codes affect synthesized properties, thus editing specific properties usually relies on empirical trials, unreliable and time-consuming. In this paper, we show that latent codes are disentangled to affect the properties of SAR images in a non-linear manner. By introducing some property estimators for latent codes, we are able to provide a completely analytical nonlinear model to decompose the entangled causality between latent codes and different properties. The qualitative and quantitative experimental results further reveal that the properties can be calculated by latent codes, inversely, the satisfying latent codes can be estimated given desired properties. In this case, properties can be manipulated by latent codes as we expect.
Weakly-supervised segmentation using inherently-explainable classification models and their application to brain tumour classification
Jun 10, 2022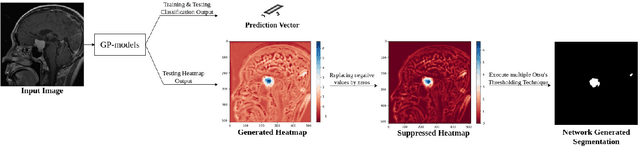
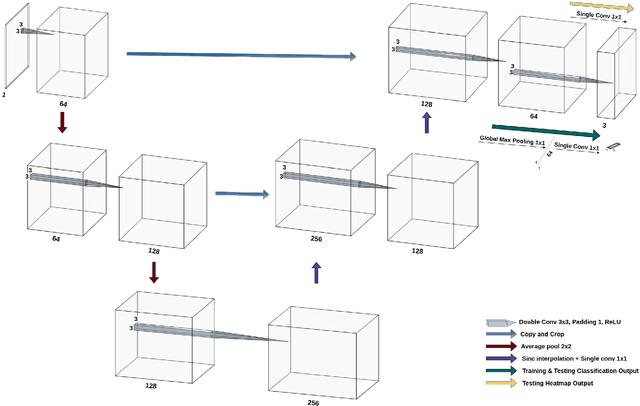

Deep learning models have shown their potential for several applications. However, most of the models are opaque and difficult to trust due to their complex reasoning - commonly known as the black-box problem. Some fields, such as medicine, require a high degree of transparency to accept and adopt such technologies. Consequently, creating explainable/interpretable models or applying post-hoc methods on classifiers to build trust in deep learning models are required. Moreover, deep learning methods can be used for segmentation tasks, which typically require hard-to-obtain, time-consuming manually-annotated segmentation labels for training. This paper introduces three inherently-explainable classifiers to tackle both of these problems as one. The localisation heatmaps provided by the networks -- representing the models' focus areas and being used in classification decision-making -- can be directly interpreted, without requiring any post-hoc methods to derive information for model explanation. The models are trained by using the input image and only the classification labels as ground-truth in a supervised fashion - without using any information about the location of the region of interest (i.e. the segmentation labels), making the segmentation training of the models weakly-supervised through classification labels. The final segmentation is obtained by thresholding these heatmaps. The models were employed for the task of multi-class brain tumour classification using two different datasets, resulting in the best F1-score of 0.93 for the supervised classification task while securing a median Dice score of 0.67$\pm$0.08 for the weakly-supervised segmentation task. Furthermore, the obtained accuracy on a subset of tumour-only images outperformed the state-of-the-art glioma tumour grading binary classifiers with the best model achieving 98.7\% accuracy.
FBNETGEN: Task-aware GNN-based fMRI Analysis via Functional Brain Network Generation
May 29, 2022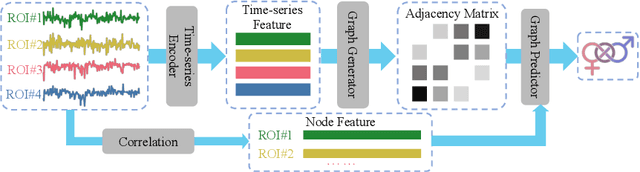
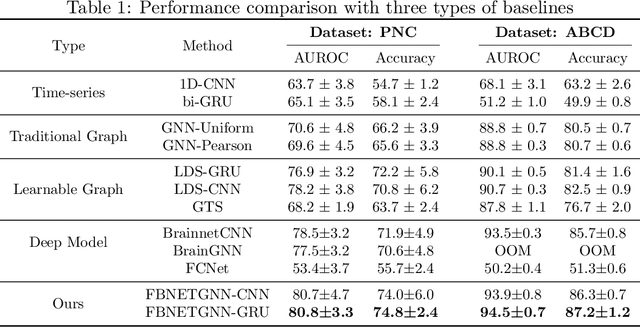

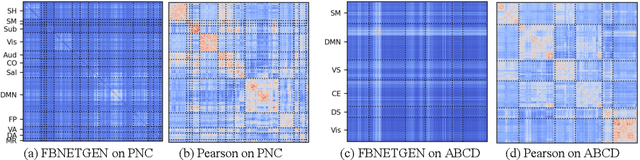
Functional magnetic resonance imaging (fMRI) is one of the most common imaging modalities to investigate brain functions. Recent studies in neuroscience stress the great potential of functional brain networks constructed from fMRI data for clinical predictions. Traditional functional brain networks, however, are noisy and unaware of downstream prediction tasks, while also incompatible with the deep graph neural network (GNN) models. In order to fully unleash the power of GNNs in network-based fMRI analysis, we develop FBNETGEN, a task-aware and interpretable fMRI analysis framework via deep brain network generation. In particular, we formulate (1) prominent region of interest (ROI) features extraction, (2) brain networks generation, and (3) clinical predictions with GNNs, in an end-to-end trainable model under the guidance of particular prediction tasks. Along with the process, the key novel component is the graph generator which learns to transform raw time-series features into task-oriented brain networks. Our learnable graphs also provide unique interpretations by highlighting prediction-related brain regions. Comprehensive experiments on two datasets, i.e., the recently released and currently largest publicly available fMRI dataset Adolescent Brain Cognitive Development (ABCD), and the widely-used fMRI dataset PNC, prove the superior effectiveness and interpretability of FBNETGEN. The implementation is available at https://github.com/Wayfear/FBNETGEN.
What Do Compressed Multilingual Machine Translation Models Forget?
May 22, 2022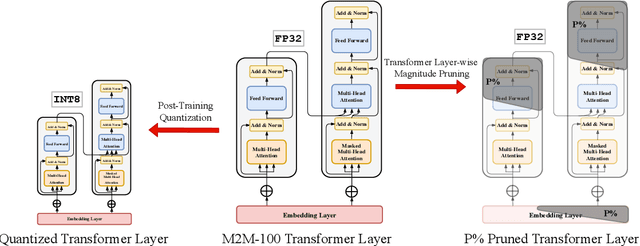

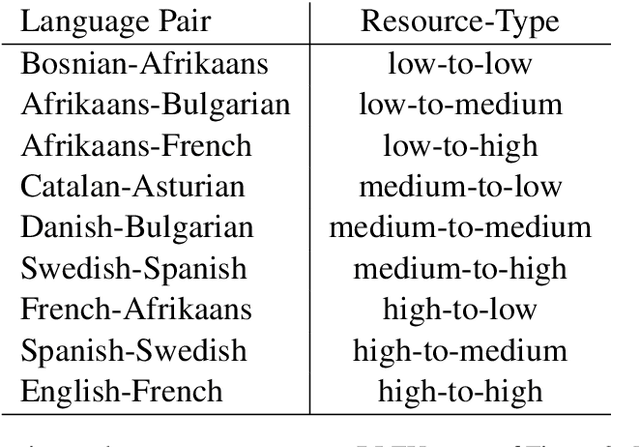
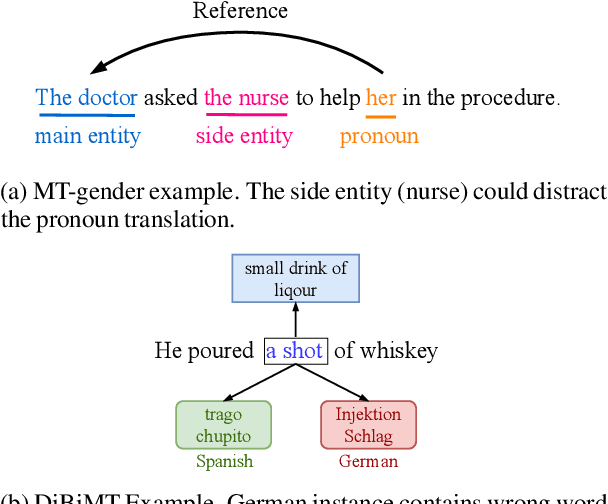
Recently, very large pre-trained models achieve state-of-the-art results in various natural language processing (NLP) tasks, but their size makes it more challenging to apply them in resource-constrained environments. Compression techniques allow to drastically reduce the size of the model and therefore its inference time with negligible impact on top-tier metrics. However, the general performance hides a drastic performance drop on under-represented features, which could result in the amplification of biases encoded by the model. In this work, we analyze the impacts of compression methods on Multilingual Neural Machine Translation models (MNMT) for various language groups and semantic features by extensive analysis of compressed models on different NMT benchmarks, e.g. FLORES-101, MT-Gender, and DiBiMT. Our experiments show that the performance of under-represented languages drops significantly, while the average BLEU metric slightly decreases. Interestingly, the removal of noisy memorization with the compression leads to a significant improvement for some medium-resource languages. Finally, we demonstrate that the compression amplifies intrinsic gender and semantic biases, even in high-resource languages.
Collaborative Distillation Meta Learning for Simulation Intensive Hardware Design
May 26, 2022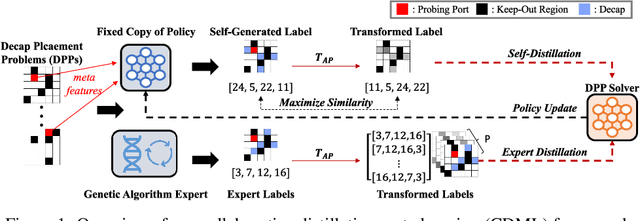
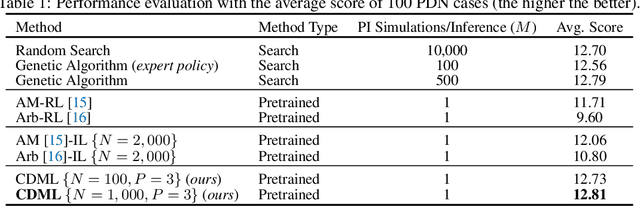
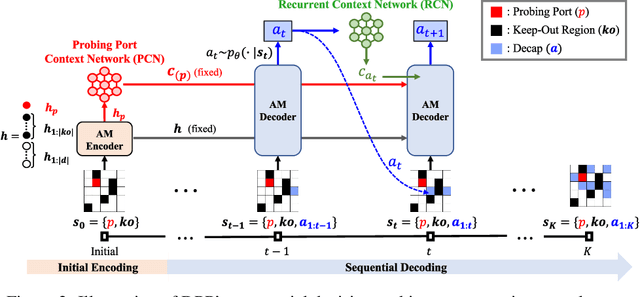
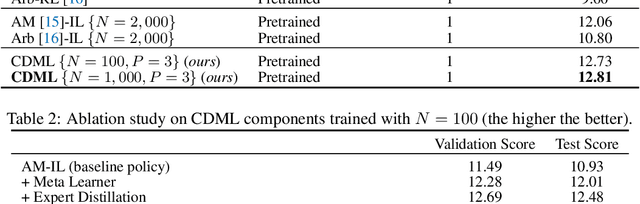
This paper proposes a novel collaborative distillation meta learning (CDML) framework for simulation intensive hardware design problems. Deep reinforcement learning (DRL) has shown promising performance in various hardware design problems. However, previous works on DRL-based hardware design only dealt with problems with simplified objectives, which are not practical. In fact, the objective evaluation of real-world electrical performance through simulation is costly in terms of both time and computation, making DRL scheme involving extensive reward calculations not suitable. In this paper, we apply the CDML framework to decoupling capacitor placement problem (DPP), one of the significant simulation intensive hardware design problems. The CDML framework consists of a context-based meta learner and collaborative distillation scheme to produce a reusable solver. The context-based meta learner captures the location of probing port (i.e., target circuit block) and improves generalization capability. The collaborative distillation scheme with equivariant label transformation imposes the action-permutation (AP)-equivariant nature of placement problems, which not only improves sample efficiency but also improves generalization capability. Extensive experimental results verified that our CDML outperforms both neural baselines and iterative conventional design methods in terms of real-world objective, power integrity, with zero-shot transfer-ability.
Deep Learning-Based Synchronization for Uplink NB-IoT
May 22, 2022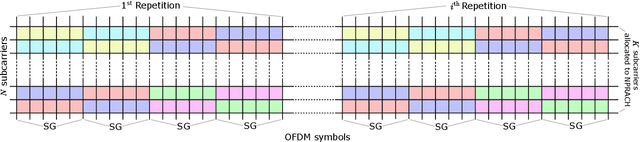
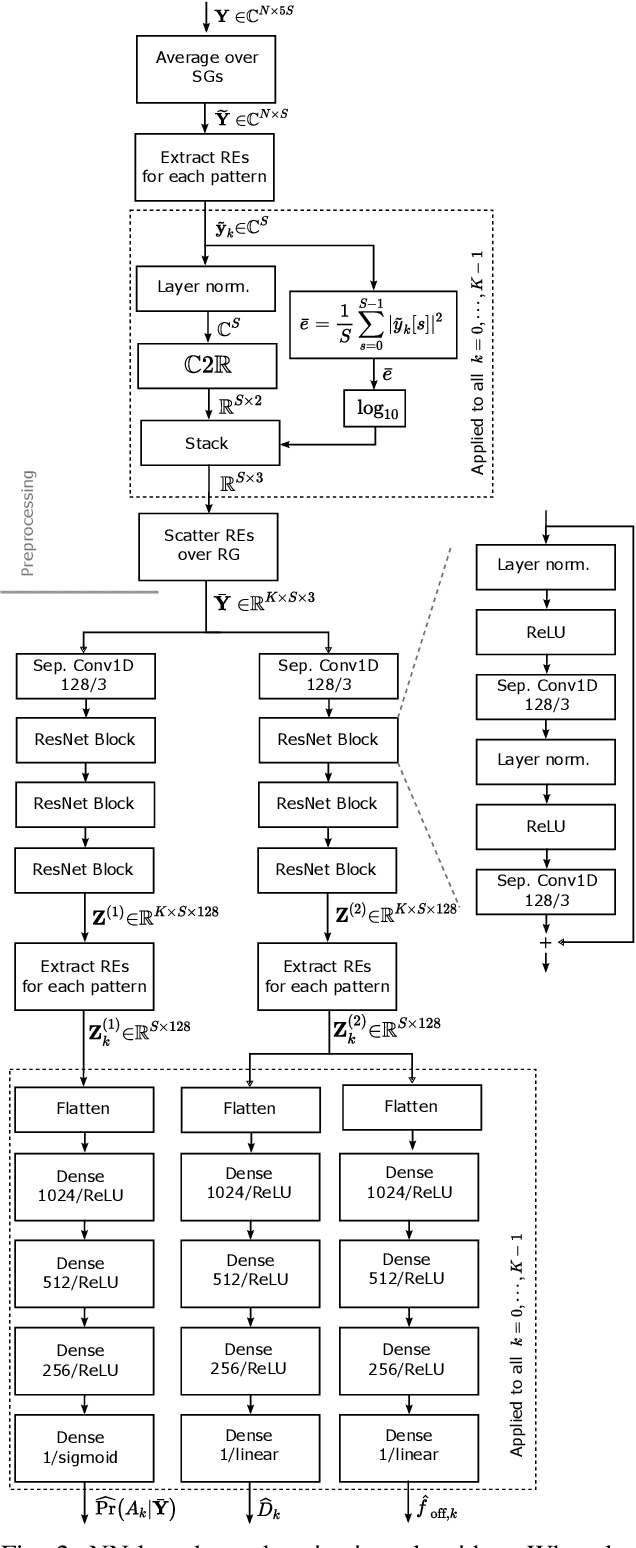
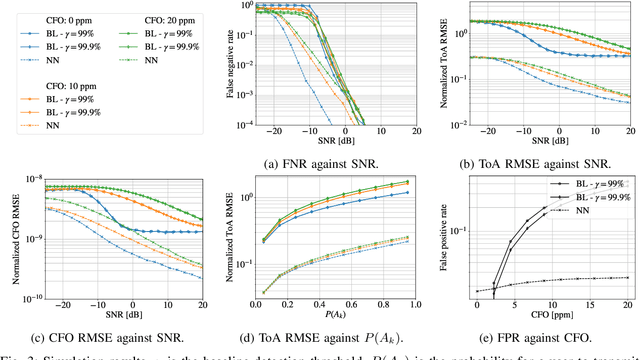
We propose a neural network (NN)-based algorithm for device detection and time of arrival (ToA) and carrier frequency offset (CFO) estimation for the narrowband physical random-access channel (NPRACH) of narrowband internet of things (NB-IoT). The introduced NN architecture leverages residual convolutional networks as well as knowledge of the preamble structure of the 5G New Radio (5G NR) specifications. Benchmarking on a 3rd Generation Partnership Project (3GPP) urban microcell (UMi) channel model with random drops of users against a state-of-the-art baseline shows that the proposed method enables up to 8 dB gains in false negative rate (FNR) as well as significant gains in false positive rate (FPR) and ToA and CFO estimation accuracy. Moreover, our simulations indicate that the proposed algorithm enables gains over a wide range of channel conditions, CFOs, and transmission probabilities. The introduced synchronization method operates at the base station (BS) and, therefore, introduces no additional complexity on the user devices. It could lead to an extension of battery lifetime by reducing the preamble length or the transmit power.