 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploring the Impact of Temporal Bias in Point-of-Interest Recommendation
Jul 23, 2022
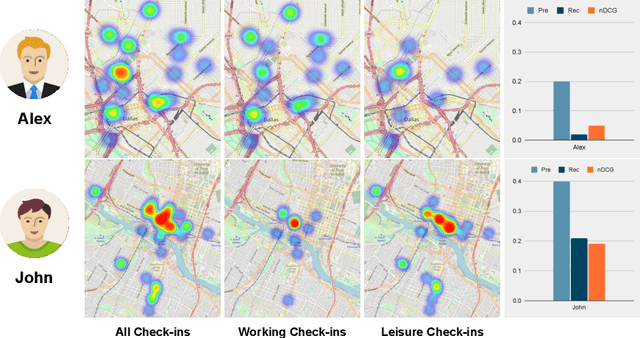


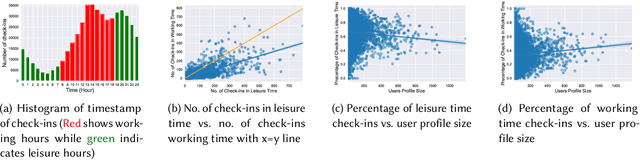
Recommending appropriate travel destinations to consumers based on contextual information such as their check-in time and location is a primary objective of Point-of-Interest (POI) recommender systems. However, the issue of contextual bias (i.e., how much consumers prefer one situation over another) has received little attention from the research community. This paper examines the effect of temporal bias, defined as the difference between users' check-in hours, leisure vs.~work hours, on the consumer-side fairness of context-aware recommendation algorithms. We believe that eliminating this type of temporal (and geographical) bias might contribute to a drop in traffic-related air pollution, noting that rush-hour traffic may be more congested. To surface effective POI recommendations, we evaluated the sensitivity of state-of-the-art context-aware models to the temporal bias contained in users' check-in activities on two POI datasets, namely Gowalla and Yelp. The findings show that the examined context-aware recommendation models prefer one group of users over another based on the time of check-in and that this preference persists even when users have the same amount of interactions.
TCCT: Tightly-Coupled Convolutional Transformer on Time Series Forecasting
Aug 29, 2021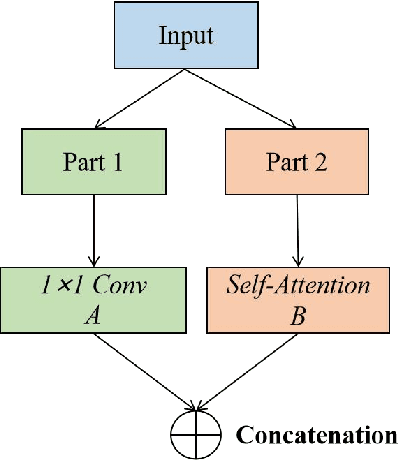
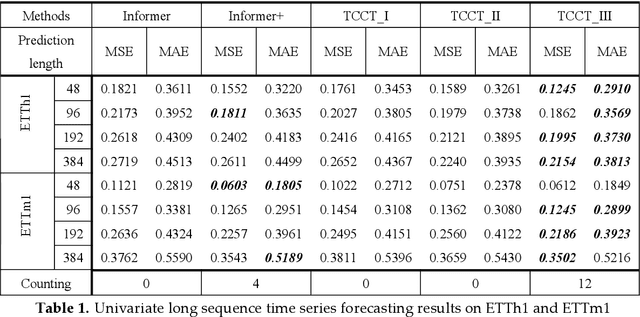
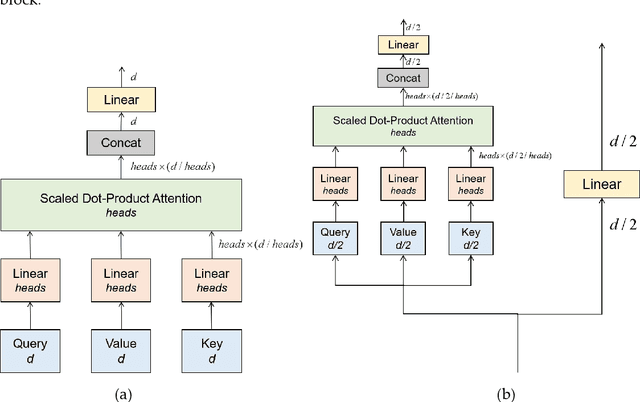
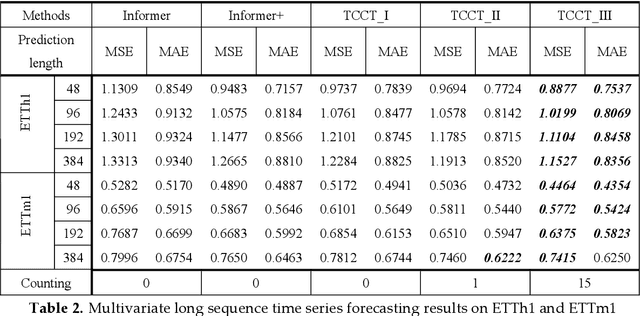
Time series forecasting is essential for a wide range of real-world applications. Recent studies have shown the superiority of Transformer in dealing with such problems, especially long sequence time series input(LSTI) and long sequence time series forecasting(LSTF) problems. To improve the efficiency and enhance the locality of Transformer, these studies combine Transformer with CNN in varying degrees. However, their combinations are loosely-coupled and do not make full use of CNN. To address this issue, we propose the concept of tightly-coupled convolutional Transformer(TCCT) and three TCCT architectures which apply transformed CNN architectures into Transformer: (1) CSPAttention: through fusing CSPNet with self-attention mechanism, the computation cost of self-attention mechanism is reduced by 30% and the memory usage is reduced by 50% while achieving equivalent or beyond prediction accuracy. (2) Dilated causal convolution: this method is to modify the distilling operation proposed by Informer through replacing canonical convolutional layers with dilated causal convolutional layers to gain exponentially receptive field growth. (3) Passthrough mechanism: the application of passthrough mechanism to stack of self-attention blocks helps Transformer-like models get more fine-grained information with negligible extra computation costs. Our experiments on real-world datasets show that our TCCT architectures could greatly improve the performance of existing state-of-art Transformer models on time series forecasting with much lower computation and memory costs, including canonical Transformer, LogTrans and Informer.
RepFair-GAN: Mitigating Representation Bias in GANs Using Gradient Clipping
Jul 13, 2022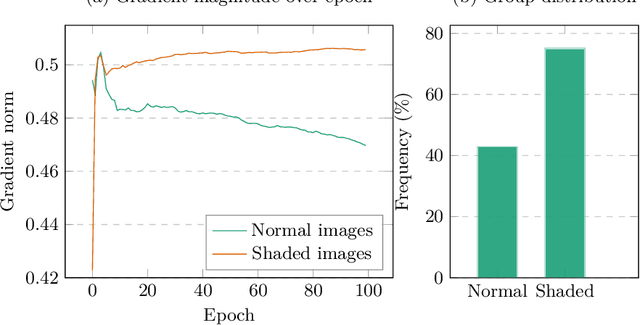

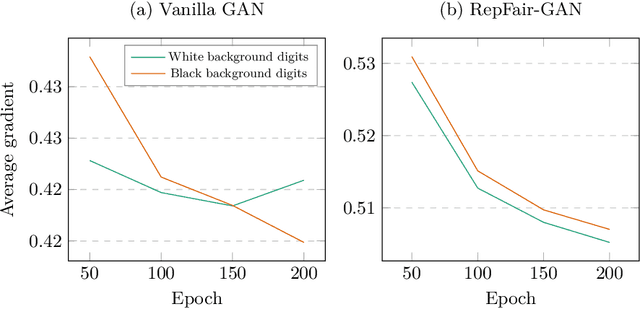
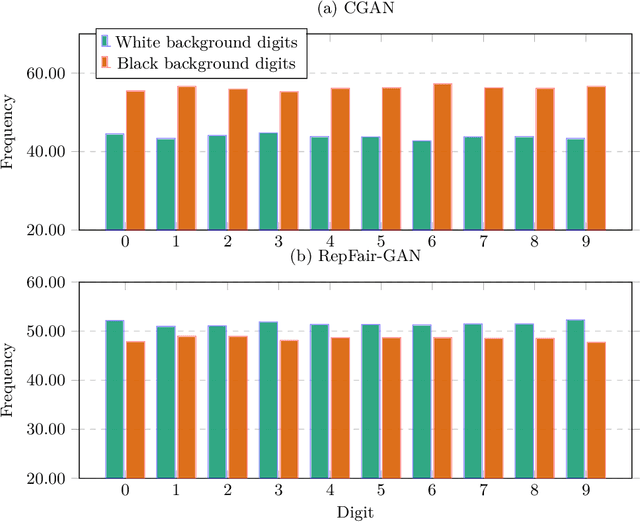
Fairness has become an essential problem in many domains of Machine Learning (ML), such as classification, natural language processing, and Generative Adversarial Networks (GANs). In this research effort, we study the unfairness of GANs. We formally define a new fairness notion for generative models in terms of the distribution of generated samples sharing the same protected attributes (gender, race, etc.). The defined fairness notion (representational fairness) requires the distribution of the sensitive attributes at the test time to be uniform, and, in particular for GAN model, we show that this fairness notion is violated even when the dataset contains equally represented groups, i.e., the generator favors generating one group of samples over the others at the test time. In this work, we shed light on the source of this representation bias in GANs along with a straightforward method to overcome this problem. We first show on two widely used datasets (MNIST, SVHN) that when the norm of the gradient of one group is more important than the other during the discriminator's training, the generator favours sampling data from one group more than the other at test time. We then show that controlling the groups' gradient norm by performing group-wise gradient norm clipping in the discriminator during the training leads to a more fair data generation in terms of representational fairness compared to existing models while preserving the quality of generated samples.
Training Multi-Layer Over-Parametrized Neural Network in Subquadratic Time
Dec 14, 2021We consider the problem of training a multi-layer over-parametrized neural networks to minimize the empirical risk induced by a loss function. In the typical setting of over-parametrization, the network width $m$ is much larger than the data dimension $d$ and number of training samples $n$ ($m=\mathrm{poly}(n,d)$), which induces a prohibitive large weight matrix $W\in \mathbb{R}^{m\times m}$ per layer. Naively, one has to pay $O(m^2)$ time to read the weight matrix and evaluate the neural network function in both forward and backward computation. In this work, we show how to reduce the training cost per iteration, specifically, we propose a framework that uses $m^2$ cost only in the initialization phase and achieves a truly subquadratic cost per iteration in terms of $m$, i.e., $m^{2-\Omega(1)}$ per iteration. To obtain this result, we make use of various techniques, including a shifted ReLU-based sparsifier, a lazy low rank maintenance data structure, fast rectangular matrix multiplication, tensor-based sketching techniques and preconditioning.
Short Duration Traffic Flow Prediction Using Kalman Filtering
Aug 06, 2022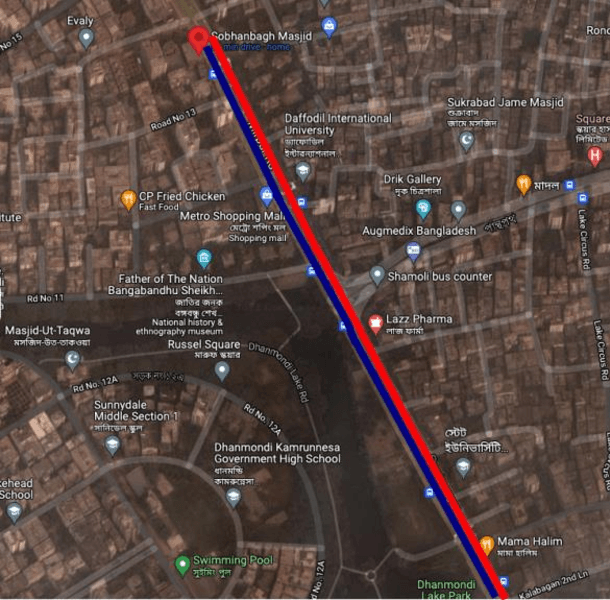

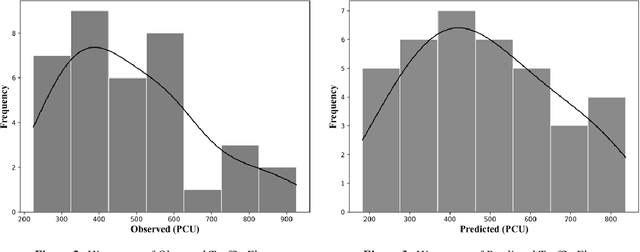
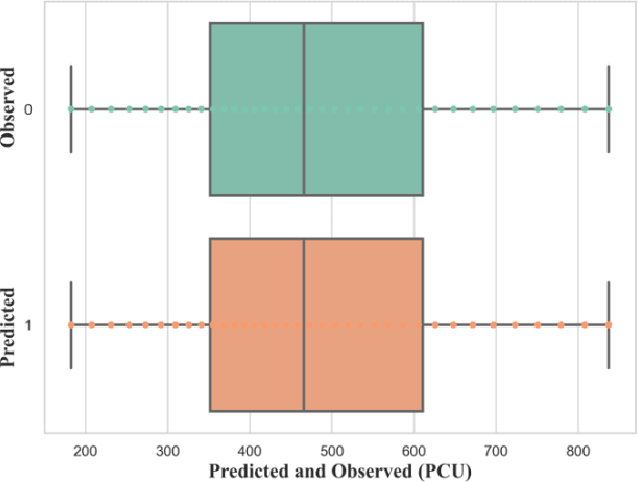
The research examined predicting short-duration traffic flow counts with the Kalman filtering technique (KFT), a computational filtering method. Short-term traffic prediction is an important tool for operation in traffic management and transportation system. The short-term traffic flow value results can be used for travel time estimation by route guidance and advanced traveler information systems. Though the KFT has been tested for homogeneous traffic, its efficiency in heterogeneous traffic has yet to be investigated. The research was conducted on Mirpur Road in Dhaka, near the Sobhanbagh Mosque. The stream contains a heterogeneous mix of traffic, which implies uncertainty in prediction. The propositioned method is executed in Python using the pykalman library. The library is mostly used in advanced database modeling in the KFT framework, which addresses uncertainty. The data was derived from a three-hour traffic count of the vehicle. According to the Geometric Design Standards Manual published by Roads and Highways Division (RHD), Bangladesh in 2005, the heterogeneous traffic flow value was translated into an equivalent passenger car unit (PCU). The PCU obtained from five-minute aggregation was then utilized as the suggested model's dataset. The propositioned model has a mean absolute percent error (MAPE) of 14.62, indicating that the KFT model can forecast reasonably well. The root mean square percent error (RMSPE) shows an 18.73% accuracy which is less than 25%; hence the model is acceptable. The developed model has an R2 value of 0.879, indicating that it can explain 87.9 percent of the variability in the dataset. If the data were collected over a more extended period of time, the R2 value could be closer to 1.0.
Automated Detection of Label Errors in Semantic Segmentation Datasets via Deep Learning and Uncertainty Quantification
Jul 13, 2022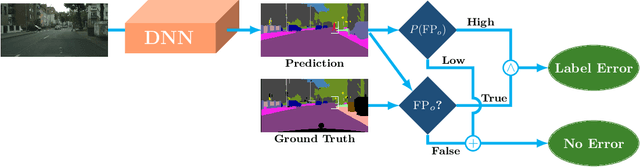
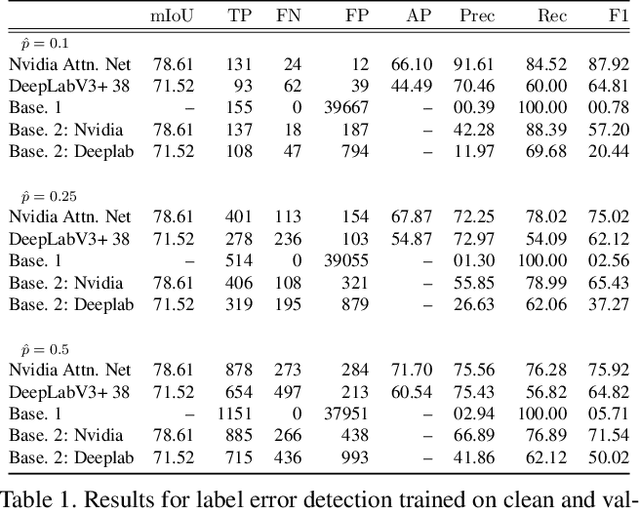
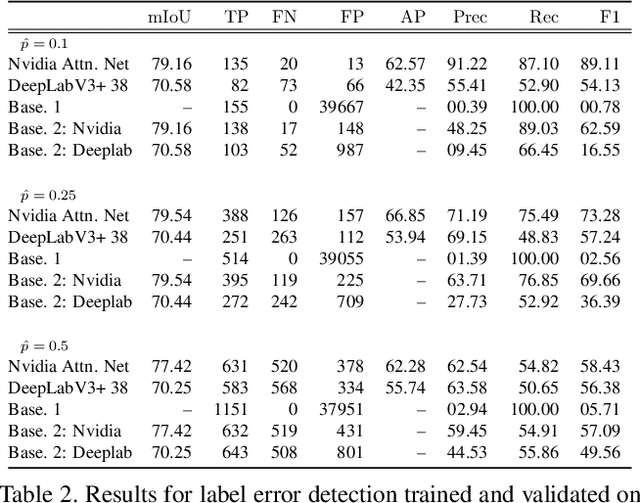
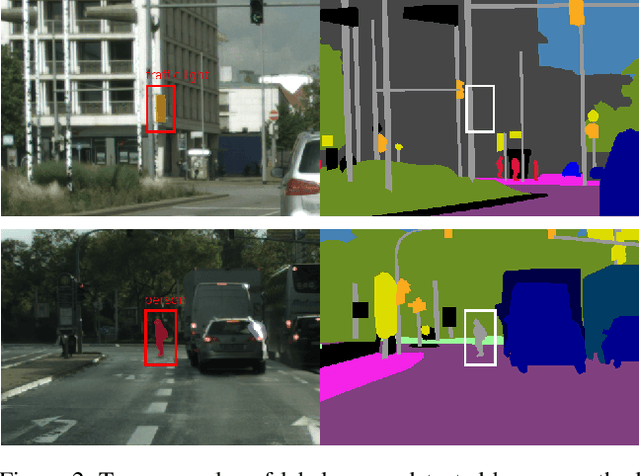
In this work, we for the first time present a method for detecting label errors in image datasets with semantic segmentation, i.e., pixel-wise class labels. Annotation acquisition for semantic segmentation datasets is time-consuming and requires plenty of human labor. In particular, review processes are time consuming and label errors can easily be overlooked by humans. The consequences are biased benchmarks and in extreme cases also performance degradation of deep neural networks (DNNs) trained on such datasets. DNNs for semantic segmentation yield pixel-wise predictions, which makes detection of label errors via uncertainty quantification a complex task. Uncertainty is particularly pronounced at the transitions between connected components of the prediction. By lifting the consideration of uncertainty to the level of predicted components, we enable the usage of DNNs together with component-level uncertainty quantification for the detection of label errors. We present a principled approach to benchmarking the task of label error detection by dropping labels from the Cityscapes dataset as well from a dataset extracted from the CARLA driving simulator, where in the latter case we have the labels under control. Our experiments show that our approach is able to detect the vast majority of label errors while controlling the number of false label error detections. Furthermore, we apply our method to semantic segmentation datasets frequently used by the computer vision community and present a collection of label errors along with sample statistics.
Robust 3D Vision for Autonomous Robots
Aug 30, 2022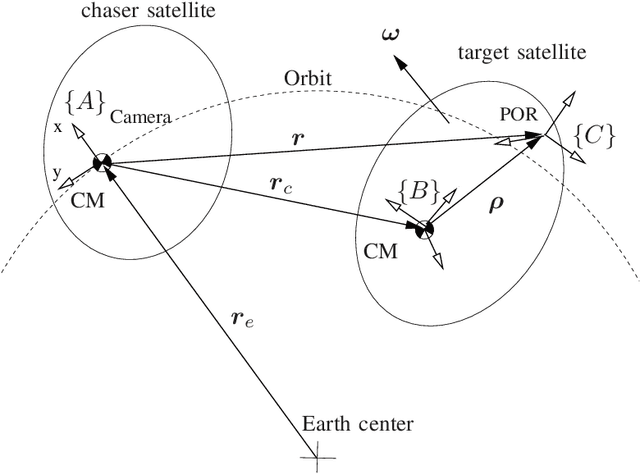
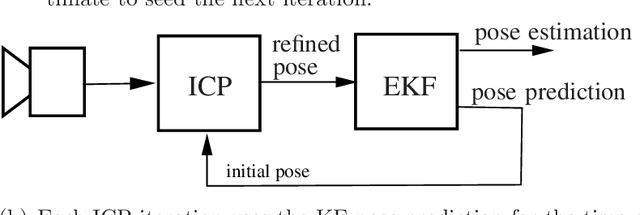

This paper presents a fault-tolerant 3D vision system for autonomous robotic operation. In particular, pose estimation of space objects is achieved using 3D vision data in an integrated Kalman filter (KF) and an Iterative Closest Point (ICP) algorithm in a closed-loop configuration. The initial guess for the internal ICP iteration is provided by the state estimate propagation of the Kalman filer. The Kalman filter is capable of not only estimating the target's states but also its inertial parameters. This allows the motion of the target to be predictable as soon as the filter converges. Consequently, the ICP can maintain pose tracking over a wider range of velocity due to the increased precision of ICP initialization. Furthermore, incorporation of the target's dynamics model in the estimation process allows the estimator continuously provide pose estimation even when the sensor temporally loses its signal namely due to obstruction. The capabilities of the pose estimation methodology is demonstrated by a ground testbed for Automated Rendezvous & Docking. In this experiment, Neptec's Laser Camera System (LCS) is used for real-time scanning of a satellite model attached to a manipulator arm, which is driven by a simulator according to orbital and attitude dynamics. The results showed that robust tracking of the free-floating tumbling satellite can be achieved only if the Kalman filter and ICP are in a closed-loop configuration.
PromptFL: Let Federated Participants Cooperatively Learn Prompts Instead of Models -- Federated Learning in Age of Foundation Model
Aug 24, 2022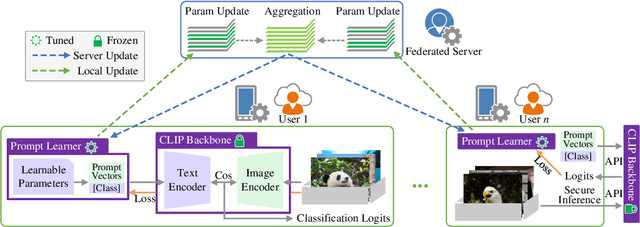
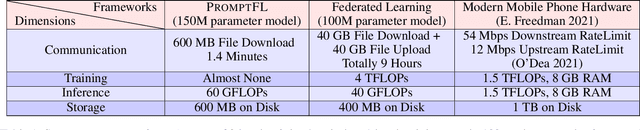
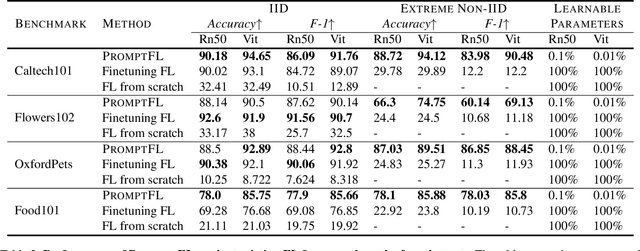
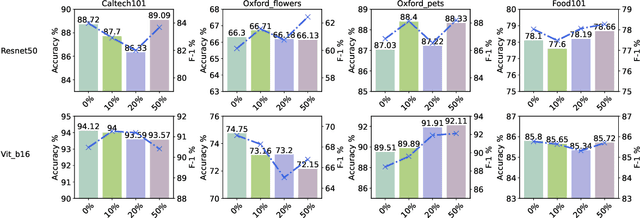
Quick global aggregation of effective distributed parameters is crucial to federated learning (FL), which requires adequate bandwidth for parameters communication and sufficient user data for local training. Otherwise, FL may cost excessive training time for convergence and produce inaccurate models. In this paper, we propose a brand-new FL framework, PromptFL, that replaces the federated model training with the federated prompt training, i.e., let federated participants train prompts instead of a shared model, to simultaneously achieve the efficient global aggregation and local training on insufficient data by exploiting the power of foundation models (FM) in a distributed way. PromptFL ships an off-the-shelf FM, i.e., CLIP, to distributed clients who would cooperatively train shared soft prompts based on very few local data. Since PromptFL only needs to update the prompts instead of the whole model, both the local training and the global aggregation can be significantly accelerated. And FM trained over large scale data can provide strong adaptation capability to distributed users tasks with the trained soft prompts. We empirically analyze the PromptFL via extensive experiments, and show its superiority in terms of system feasibility, user privacy, and performance.
Learning crop type mapping from regional label proportions in large-scale SAR and optical imagery
Aug 24, 2022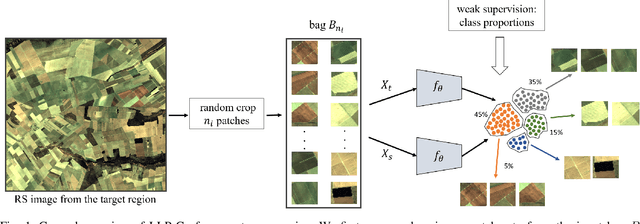
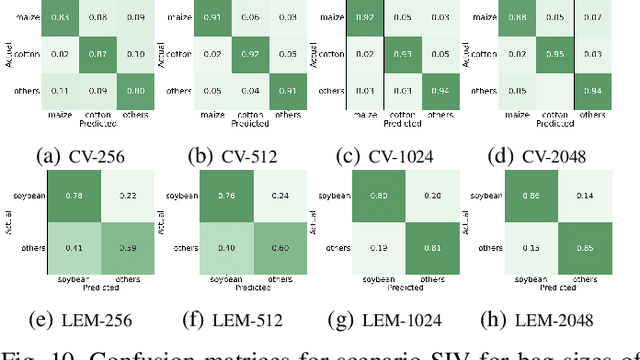
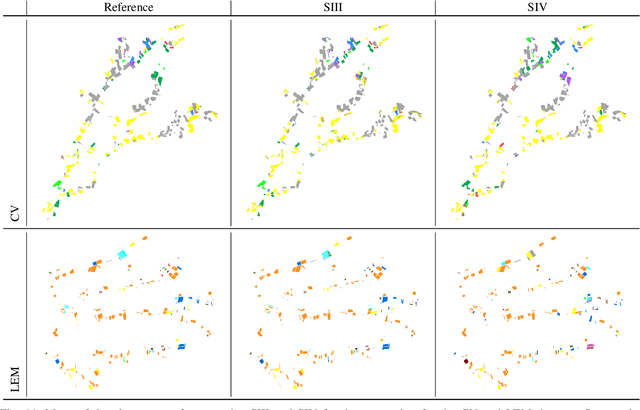
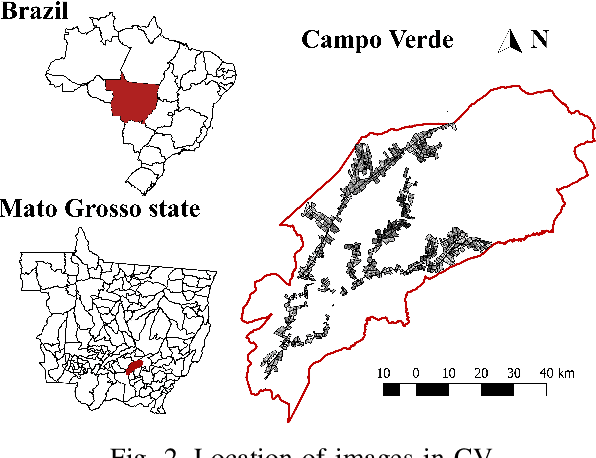
The application of deep learning algorithms to Earth observation (EO) in recent years has enabled substantial progress in fields that rely on remotely sensed data. However, given the data scale in EO, creating large datasets with pixel-level annotations by experts is expensive and highly time-consuming. In this context, priors are seen as an attractive way to alleviate the burden of manual labeling when training deep learning methods for EO. For some applications, those priors are readily available. Motivated by the great success of contrastive-learning methods for self-supervised feature representation learning in many computer-vision tasks, this study proposes an online deep clustering method using crop label proportions as priors to learn a sample-level classifier based on government crop-proportion data for a whole agricultural region. We evaluate the method using two large datasets from two different agricultural regions in Brazil. Extensive experiments demonstrate that the method is robust to different data types (synthetic-aperture radar and optical images), reporting higher accuracy values considering the major crop types in the target regions. Thus, it can alleviate the burden of large-scale image annotation in EO applications.
Adaptive Domain Generalization via Online Disagreement Minimization
Aug 03, 2022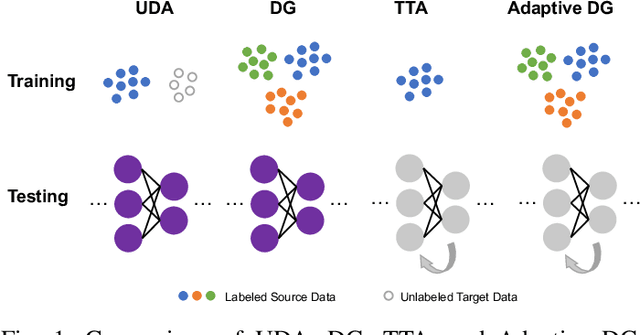
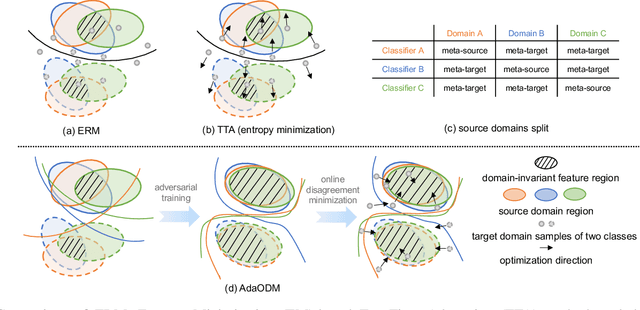

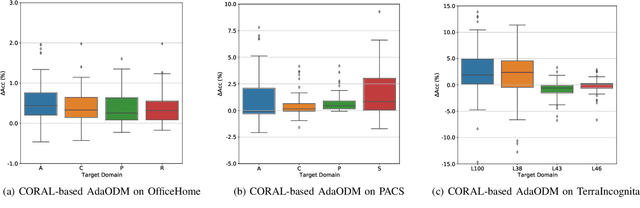
Deep neural networks suffer from significant performance deterioration when there exists distribution shift between deployment and training. Domain Generalization (DG) aims to safely transfer a model to unseen target domains by only relying on a set of source domains. Although various DG approaches have been proposed, a recent study named DomainBed, reveals that most of them do not beat the simple Empirical Risk Minimization (ERM). To this end, we propose a general framework that is orthogonal to existing DG algorithms and could improve their performance consistently. Unlike previous DG works that stake on a static source model to be hopefully a universal one, our proposed AdaODM adaptively modifies the source model at test time for different target domains. Specifically, we create multiple domain-specific classifiers upon a shared domain-generic feature extractor. The feature extractor and classifiers are trained in an adversarial way, where the feature extractor embeds the input samples into a domain-invariant space, and the multiple classifiers capture the distinct decision boundaries that each of them relates to a specific source domain. During testing, distribution differences between target and source domains could be effectively measured by leveraging prediction disagreement among source classifiers. By fine-tuning source models to minimize the disagreement at test time, target domain features are well aligned to the invariant feature space. We verify AdaODM on two popular DG methods, namely ERM and CORAL, and four DG benchmarks, namely VLCS, PACS, OfficeHome, and TerraIncognita. The results show AdaODM stably improves the generalization capacity on unseen domains and achieves state-of-the-art performance.