 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combating Label Distribution Shift for Active Domain Adaptation
Aug 13, 2022
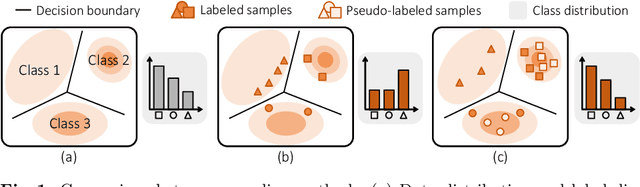
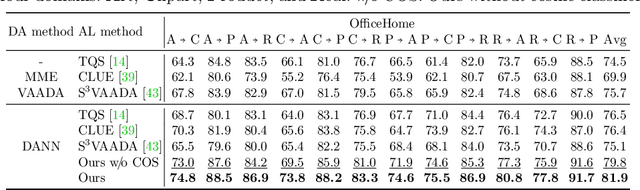
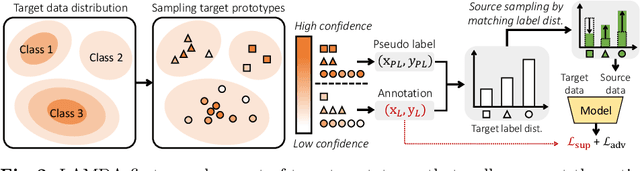
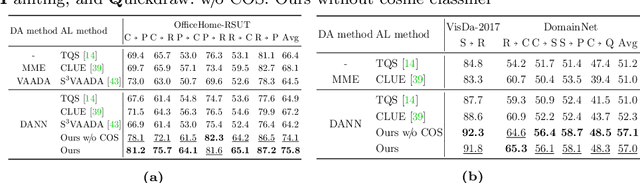
We consider the problem of active domain adaptation (ADA) to unlabeled target data, of which subset is actively selected and labeled given a budget constraint. Inspired by recent analysis on a critical issue from label distribution mismatch between source and target in domain adaptation, we devise a method that addresses the issue for the first time in ADA. At its heart lies a novel sampling strategy, which seeks target data that best approximate the entire target distribution as well as being representative, diverse, and uncertain. The sampled target data are then used not only for supervised learning but also for matching label distributions of source and target domains, leading to remarkable performance improvement. On four public benchmarks, our method substantially outperforms existing methods in every adaptation scenario.
Attentive Neural Controlled Differential Equations for Time-series Classification and Forecasting
Sep 04, 2021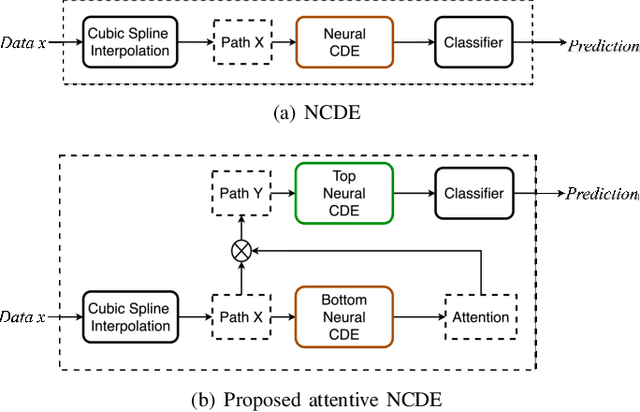
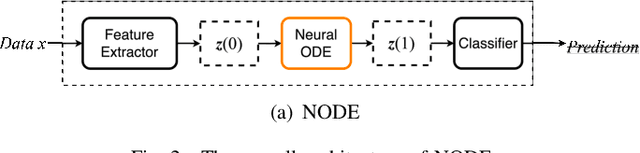
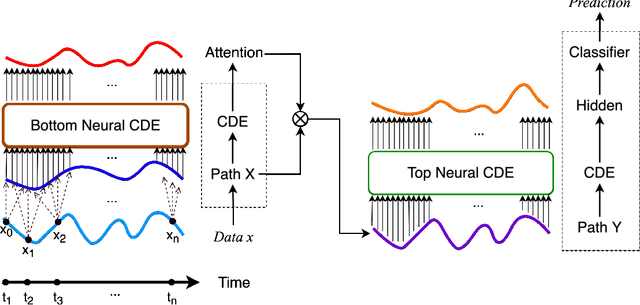
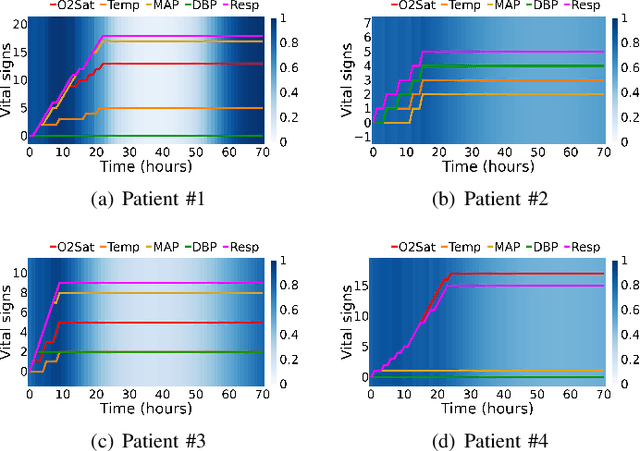
Neural networks inspired by differential equations have proliferated for the past several years. Neural ordinary differential equations (NODEs) and neural controlled differential equations (NCDEs) are two representative examples of them. In theory, NCDEs provide better representation learning capability for time-series data than NODEs. In particular, it is known that NCDEs are suitable for processing irregular time-series data. Whereas NODEs have been successfully extended after adopting attention, however, it had not been studied yet how to integrate attention into NCDEs. To this end, we present the method of Attentive Neural Controlled Differential Equations (ANCDEs) for time-series classification and forecasting, where dual NCDEs are used: one for generating attention values, and the other for evolving hidden vectors for a downstream machine learning task. We conduct experiments with three real-world time-series datasets and 10 baselines. After dropping some values, we also conduct irregular time-series experiments. Our method consistently shows the best accuracy in all cases by non-trivial margins. Our visualizations also show that the presented attention mechanism works as intended by focusing on crucial information.
An End-to-End OCR Framework for Robust Arabic-Handwriting Recognition using a Novel Transformers-based Model and an Innovative 270 Million-Words Multi-Font Corpus of Classical Arabic with Diacritics
Aug 20, 2022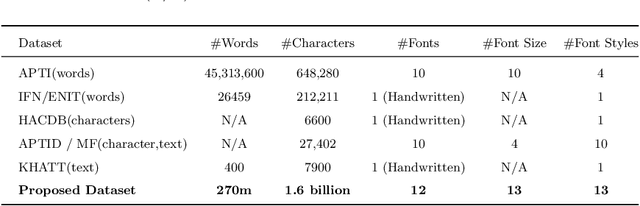

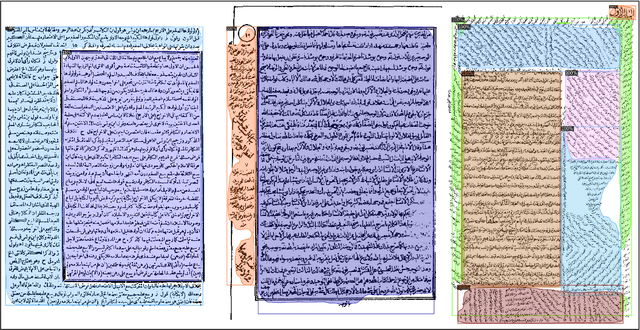
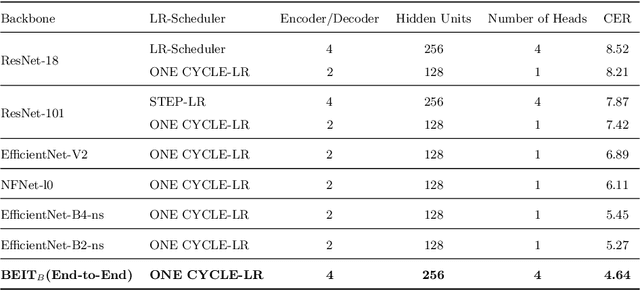
This research is the second phase in a series of investigations on developing an Optical Character Recognition (OCR) of Arabic historical documents and examining how different modeling procedures interact with the problem. The first research studied the effect of Transformers on our custom-built Arabic dataset. One of the downsides of the first research was the size of the training data, a mere 15000 images from our 30 million images, due to lack of resources. Also, we add an image enhancement layer, time and space optimization, and Post-Correction layer to aid the model in predicting the correct word for the correct context. Notably, we propose an end-to-end text recognition approach using Vision Transformers as an encoder, namely BEIT, and vanilla Transformer as a decoder, eliminating CNNs for feature extraction and reducing the model's complexity. The experiments show that our end-to-end model outperforms Convolutions Backbones. The model attained a CER of 4.46%.
DACT-BERT: Differentiable Adaptive Computation Time for an Efficient BERT Inference
Sep 24, 2021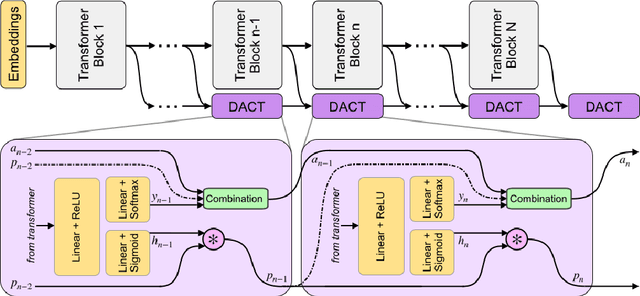
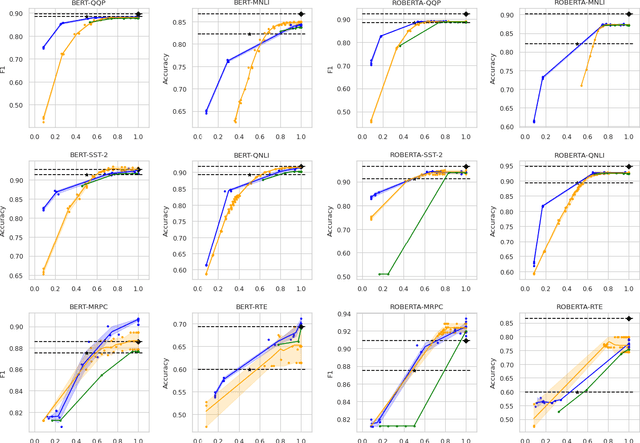
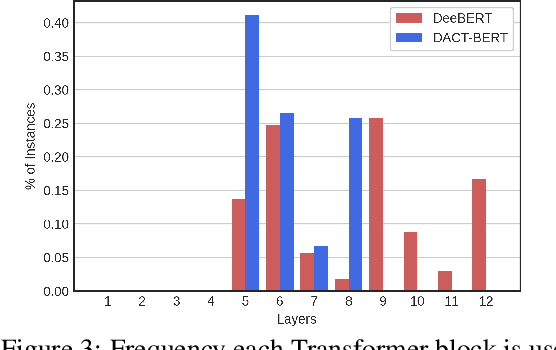
Large-scale pre-trained language models have shown remarkable results in diverse NLP applications. Unfortunately, these performance gains have been accompanied by a significant increase in computation time and model size, stressing the need to develop new or complementary strategies to increase the efficiency of these models. In this paper we propose DACT-BERT, a differentiable adaptive computation time strategy for BERT-like models. DACT-BERT adds an adaptive computational mechanism to BERT's regular processing pipeline, which controls the number of Transformer blocks that need to be executed at inference time. By doing this, the model learns to combine the most appropriate intermediate representations for the task at hand. Our experiments demonstrate that our approach, when compared to the baselines, excels on a reduced computational regime and is competitive in other less restrictive ones.
Scalable Classifier-Agnostic Channel Selection for MTSC
Jun 18, 2022
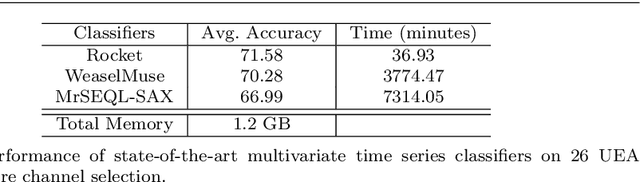
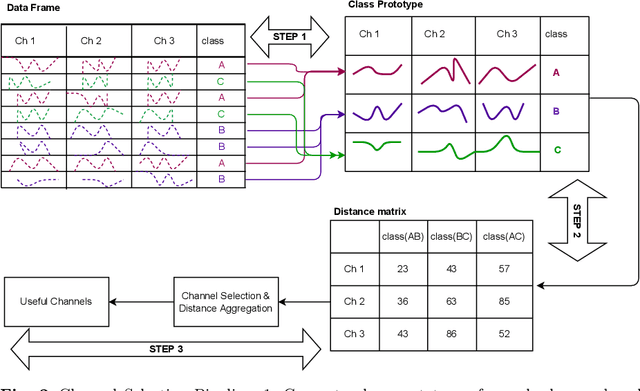
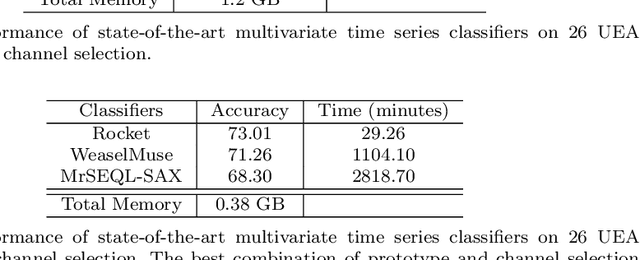
Accuracy is a key focus of current work in time series classification. However, speed and data reduction in many applications is equally important, especially when the data scale and storage requirements increase rapidly. Current MTSC algorithms need hundreds of compute hours to complete training and prediction. This is due to the nature of multivariate time series data, which grows with the number of time series, their length and the number of channels. In many applications, not all the channels are useful for the classification task; hence we require methods that can efficiently select useful channels and thus save computational resources. We propose and evaluate two methods for channel selection. Our techniques work by representing each class by a prototype time series and performing channel selection based on the prototype distance between classes. The main hypothesis is that useful channels enable better separation between classes; hence, channels with the higher distance between class prototypes are more useful. On the UEA Multivariate Time Series Classification (MTSC) benchmark, we show that these techniques achieve significant data reduction and classifier speedup for similar levels of classification accuracy. Channel selection is applied as a pre-processing step before training state-of-the-art MTSC algorithms and saves about 70\% of computation time and data storage, with preserved accuracy. Furthermore, our methods enable even efficient classifiers, such as ROCKET, to achieve better accuracy than using no channel selection or forward channel selection. To further study the impact of our techniques, we present experiments on classifying synthetic multivariate time series datasets with more than 100 channels, as well as a real-world case study on a dataset with 50 channels. Our channel selection methods lead to significant data reduction with preserved or improved accuracy.
Convolutional Shapelet Transform: A new approach for time series shapelets
Sep 28, 2021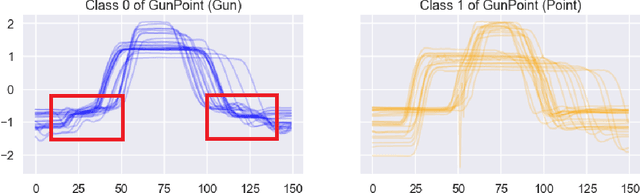
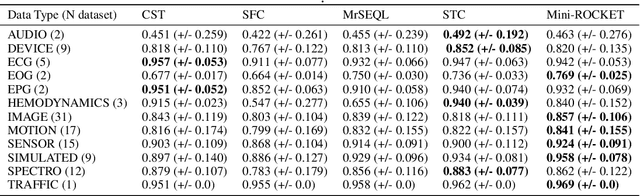
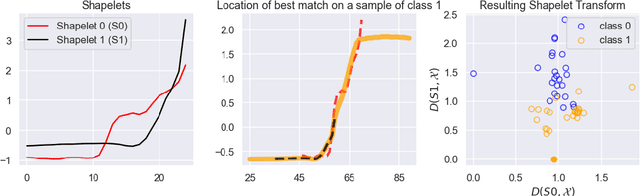
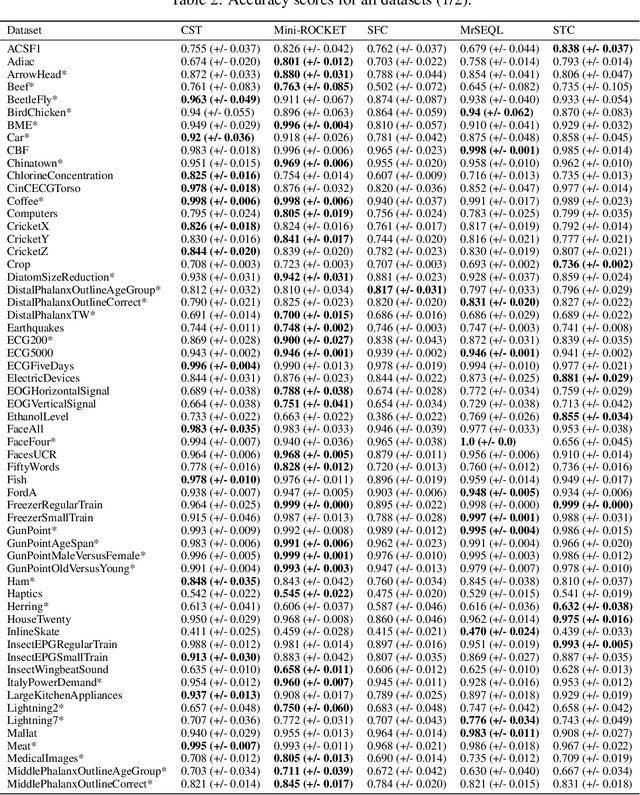
Shapelet-based algorithms are widely used for time series classification because of their ease of interpretation, but they are currently outperformed, notably by methods using convolutional kernels, capable of reaching state-of-the-art performance while being highly scalable. We present a new formulation of time series shapelets including the notion of dilation, and a shapelet extraction method based on convolutional kernels, which is able to target the discriminant information identified by convolutional kernels. Experiments performed on 108 datasets show that our method improves on the state-of-the-art for shapelet algorithms, and we show that it can be used to interpret results from convolutional kernels.
CUAHN-VIO: Content-and-Uncertainty-Aware Homography Network for Visual-Inertial Odometry
Aug 30, 2022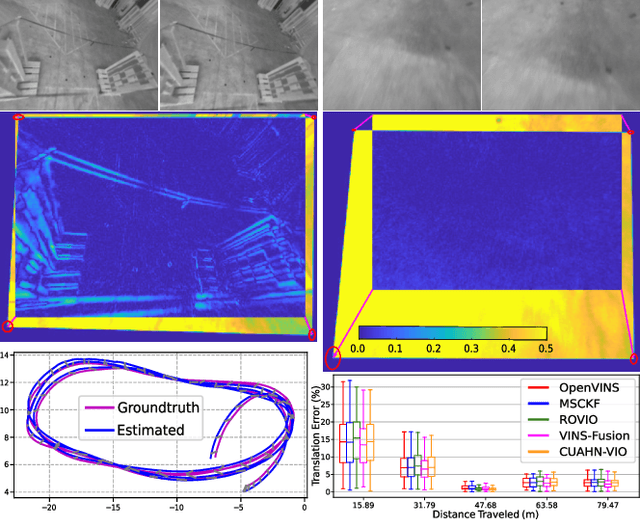

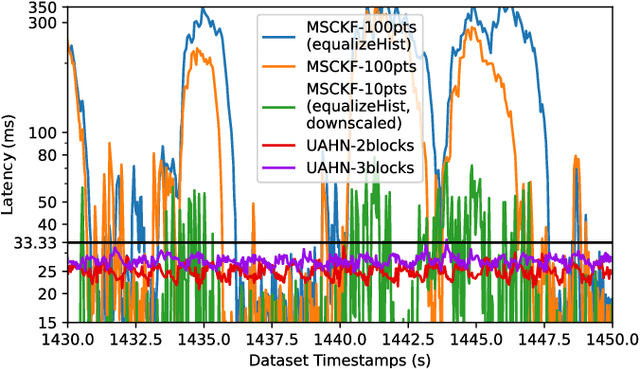
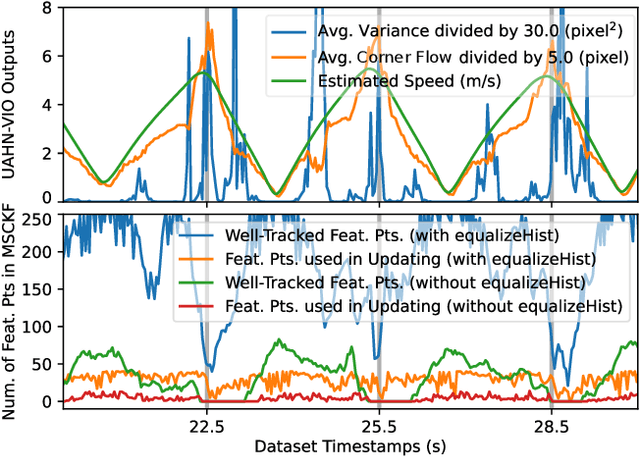
Learning-based visual ego-motion estimation is promising yet not ready for navigating agile mobile robots in the real world. In this article, we propose CUAHN-VIO, a robust and efficient monocular visual-inertial odometry (VIO) designed for micro aerial vehicles (MAVs) equipped with a downward-facing camera. The vision frontend is a content-and-uncertainty-aware homography network (CUAHN) that is robust to non-homography image content and failure cases of network prediction. It not only predicts the homography transformation but also estimates its uncertainty. The training is self-supervised, so that it does not require ground truth that is often difficult to obtain. The network has good generalization that enables "plug-and-play" deployment in new environments without fine-tuning. A lightweight extended Kalman filter (EKF) serves as the VIO backend and utilizes the mean prediction and variance estimation from the network for visual measurement updates. CUAHN-VIO is evaluated on a high-speed public dataset and shows rivaling accuracy to state-of-the-art (SOTA) VIO approaches. Thanks to the robustness to motion blur, low network inference time (~23ms), and stable processing latency (~26ms), CUAHN-VIO successfully runs onboard an Nvidia Jetson TX2 embedded processor to navigate a fast autonomous MAV.
Active Learning of Ordinal Embeddings: A User Study on Football Data
Jul 26, 2022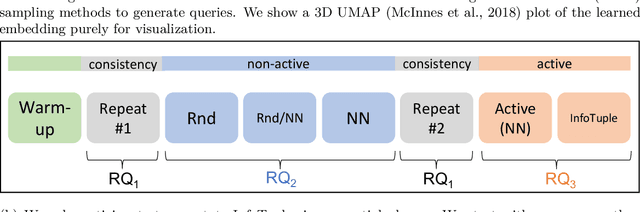
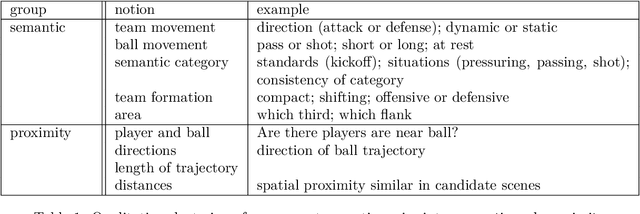
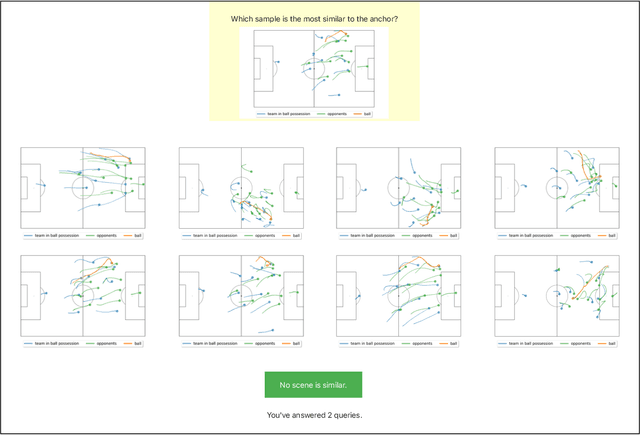
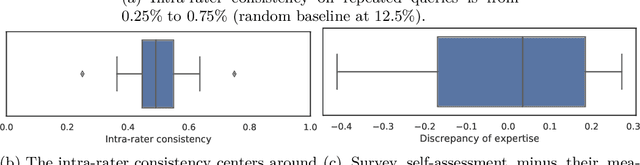
Humans innately measure distance between instances in an unlabeled dataset using an unknown similarity function. Distance metrics can only serve as proxy for similarity in information retrieval of similar instances. Learning a good similarity function from human annotations improves the quality of retrievals. This work uses deep metric learning to learn these user-defined similarity functions from few annotations for a large football trajectory dataset. We adapt an entropy-based active learning method with recent work from triplet mining to collect easy-to-answer but still informative annotations from human participants and use them to train a deep convolutional network that generalizes to unseen samples. Our user study shows that our approach improves the quality of the information retrieval compared to a previous deep metric learning approach that relies on a Siamese network. Specifically, we shed light on the strengths and weaknesses of passive sampling heuristics and active learners alike by analyzing the participants' response efficacy. To this end, we collect accuracy, algorithmic time complexity, the participants' fatigue and time-to-response, qualitative self-assessment and statements, as well as the effects of mixed-expertise annotators and their consistency on model performance and transfer-learning.
Exploring the Effects of Data Augmentation for Drivable Area Segmentation
Aug 06, 2022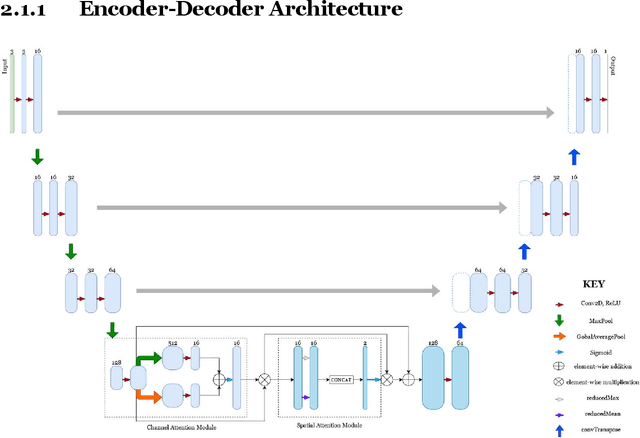
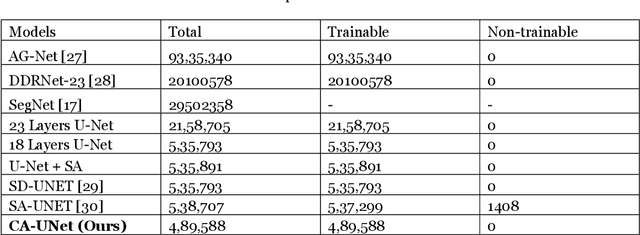
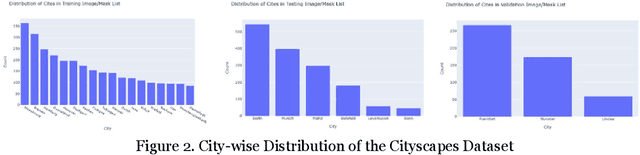
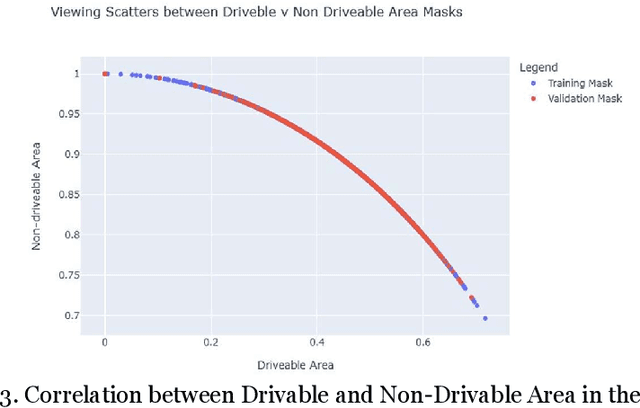
The real-time segmentation of drivable areas plays a vital role in accomplishing autonomous perception in cars. Recently there have been some rapid strides in the development of image segmentation models using deep learning. However, most of the advancements have been made in model architecture design. In solving any supervised deep learning problem related to segmentation, the success of the model that one builds depends upon the amount and quality of input training data we use for that model. This data should contain well-annotated varied images for better working of the segmentation model. Issues like this pertaining to annotations in a dataset can lead the model to conclude with overwhelming Type I and II errors in testing and validation, causing malicious issues when trying to tackle real world problems. To address this problem and to make our model more accurate, dynamic, and robust, data augmentation comes into usage as it helps in expanding our sample training data and making it better and more diversified overall. Hence, in our study, we focus on investigating the benefits of data augmentation by analyzing pre-existing image datasets and performing augmentations accordingly. Our results show that the performance and robustness of existing state of the art (or SOTA) models can be increased dramatically without any increase in model complexity or inference time. The augmentations decided on and used in this paper were decided only after thorough research of several other augmentation methodologies and strategies and their corresponding effects that are in widespread usage today. All our results are being reported on the widely used Cityscapes Dataset.
Representation Learning for the Automatic Indexing of Sound Effects Libraries
Aug 18, 2022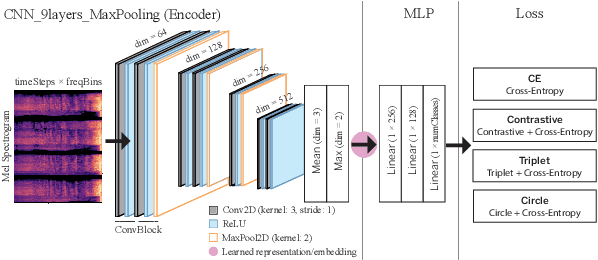
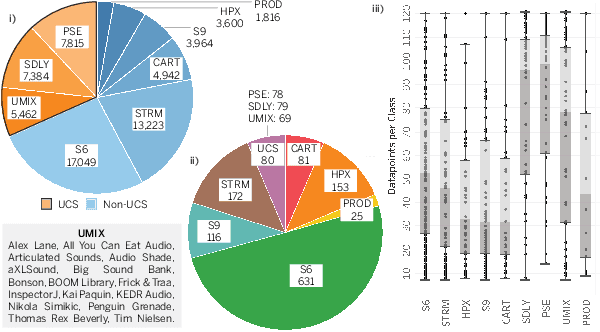
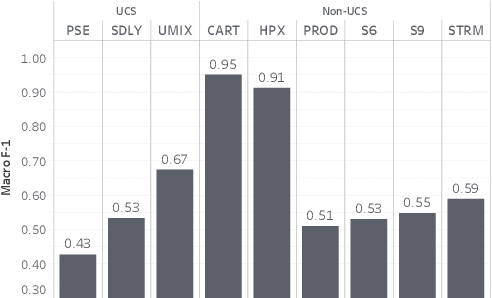
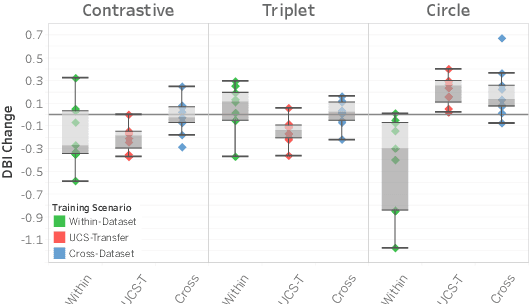
Labeling and maintaining a commercial sound effects library is a time-consuming task exacerbated by databases that continually grow in size and undergo taxonomy updates. Moreover, sound search and taxonomy creation are complicated by non-uniform metadata, an unrelenting problem even with the introduction of a new industry standard, the Universal Category System. To address these problems and overcome dataset-dependent limitations that inhibit the successful training of deep learning models, we pursue representation learning to train generalized embeddings that can be used for a wide variety of sound effects libraries and are a taxonomy-agnostic representation of sound. We show that a task-specific but dataset-independent representation can successfully address data issues such as class imbalance, inconsistent class labels, and insufficient dataset size, outperforming established representations such as OpenL3. Detailed experimental results show the impact of metric learning approaches and different cross-dataset training methods on representational effectiveness.