 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Attention-Based Audio Embeddings for Query-by-Example
Oct 16, 2022
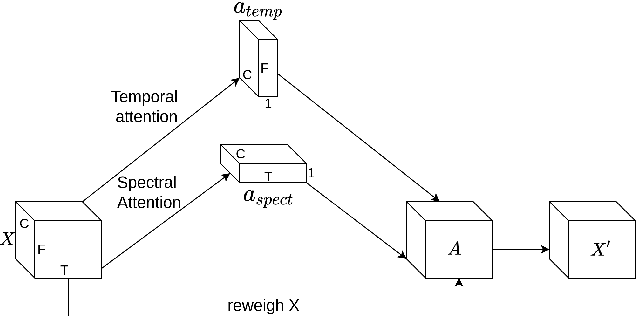

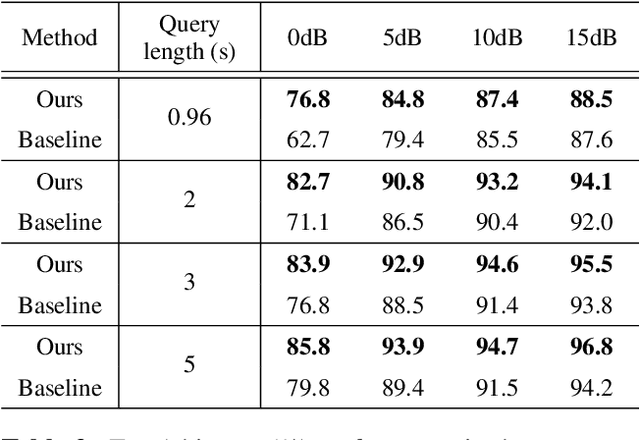
An ideal audio retrieval system efficiently and robustly recognizes a short query snippet from an extensive database. However, the performance of well-known audio fingerprinting systems falls short at high signal distortion levels. This paper presents an audio retrieval system that generates noise and reverberation robust audio fingerprints using the contrastive learning framework. Using these fingerprints, the method performs a comprehensive search to identify the query audio and precisely estimate its timestamp in the reference audio. Our framework involves training a CNN to maximize the similarity between pairs of embeddings extracted from clean audio and its corresponding distorted and time-shifted version. We employ a channel-wise spectral-temporal attention mechanism to better discriminate the audio by giving more weight to the salient spectral-temporal patches in the signal. Experimental results indicate that our system is efficient in computation and memory usage while being more accurate, particularly at higher distortion levels, than competing state-of-the-art systems and scalable to a larger database.
FIT: A Metric for Model Sensitivity
Oct 16, 2022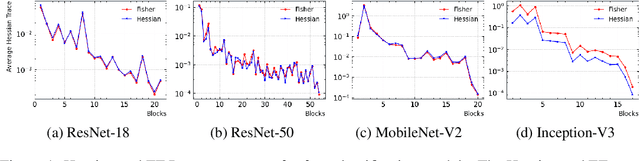

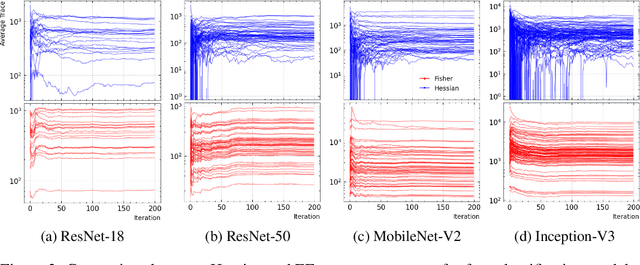
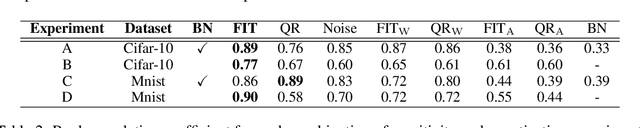
Model compression is vital to the deployment of deep learning on edge devices. Low precision representations, achieved via quantization of weights and activations, can reduce inference time and memory requirements. However, quantifying and predicting the response of a model to the changes associated with this procedure remains challenging. This response is non-linear and heterogeneous throughout the network. Understanding which groups of parameters and activations are more sensitive to quantization than others is a critical stage in maximizing efficiency. For this purpose, we propose FIT. Motivated by an information geometric perspective, FIT combines the Fisher information with a model of quantization. We find that FIT can estimate the final performance of a network without retraining. FIT effectively fuses contributions from both parameter and activation quantization into a single metric. Additionally, FIT is fast to compute when compared to existing methods, demonstrating favourable convergence properties. These properties are validated experimentally across hundreds of quantization configurations, with a focus on layer-wise mixed-precision quantization.
Class Distribution Monitoring for Concept Drift Detection
Oct 16, 2022
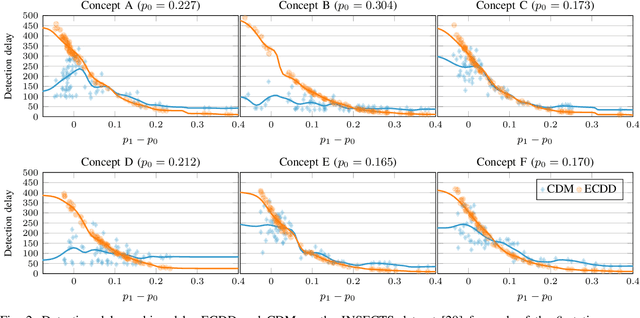
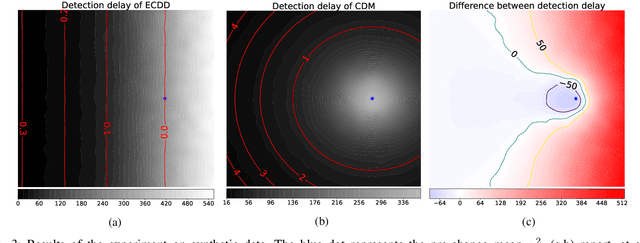

We introduce Class Distribution Monitoring (CDM), an effective concept-drift detection scheme that monitors the class-conditional distributions of a datastream. In particular, our solution leverages multiple instances of an online and nonparametric change-detection algorithm based on QuantTree. CDM reports a concept drift after detecting a distribution change in any class, thus identifying which classes are affected by the concept drift. This can be precious information for diagnostics and adaptation. Our experiments on synthetic and real-world datastreams show that when the concept drift affects a few classes, CDM outperforms algorithms monitoring the overall data distribution, while achieving similar detection delays when the drift affects all the classes. Moreover, CDM outperforms comparable approaches that monitor the classification error, particularly when the change is not very apparent. Finally, we demonstrate that CDM inherits the properties of the underlying change detector, yielding an effective control over the expected time before a false alarm, or Average Run Length (ARL$_0$).
Forecasting COVID- 19 cases using Statistical Models and Ontology-based Semantic Modelling: A real time data analytics approach
Jun 06, 2022
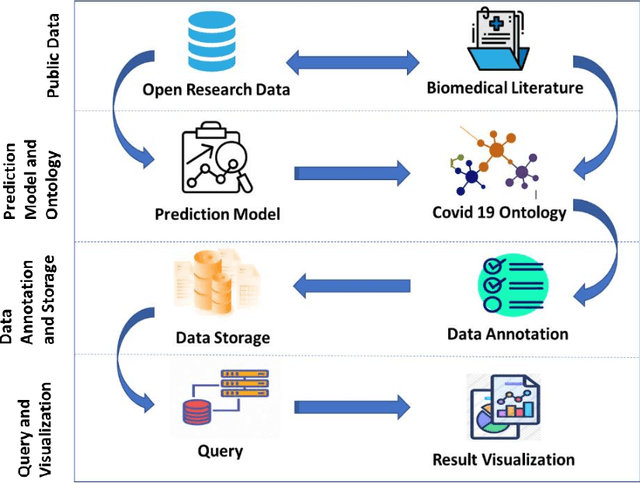
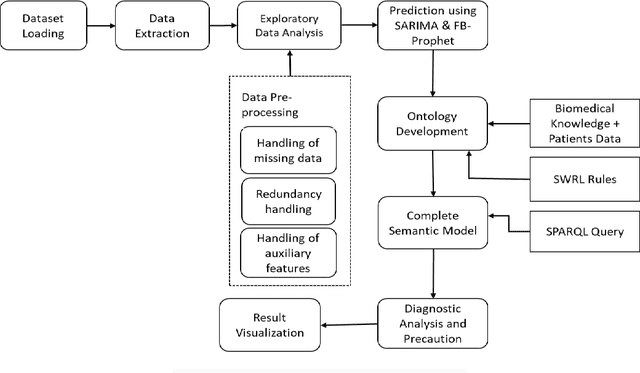

SARS-COV-19 is the most prominent issue which many countries face today. The frequent changes in infections, recovered and deaths represents the dynamic nature of this pandemic. It is very crucial to predict the spreading rate of this virus for accurate decision making against fighting with the situation of getting infected through the virus, tracking and controlling the virus transmission in the community. We develop a prediction model using statistical time series models such as SARIMA and FBProphet to monitor the daily active, recovered and death cases of COVID-19 accurately. Then with the help of various details across each individual patient (like height, weight, gender etc.), we designed a set of rules using Semantic Web Rule Language and some mathematical models for dealing with COVID19 infected cases on an individual basis. After combining all the models, a COVID-19 Ontology is developed and performs various queries using SPARQL query on designed Ontology which accumulate the risk factors, provide appropriate diagnosis, precautions and preventive suggestions for COVID Patients. After comparing the performance of SARIMA and FBProphet, it is observed that the SARIMA model performs better in forecasting of COVID cases. On individual basis COVID case prediction, approx. 497 individual samples have been tested and classified into five different levels of COVID classes such as Having COVID, No COVID, High Risk COVID case, Medium to High Risk case, and Control needed case.
Full-Duplex Communication for ISAC: Joint Beamforming and Power Optimization
Nov 01, 2022
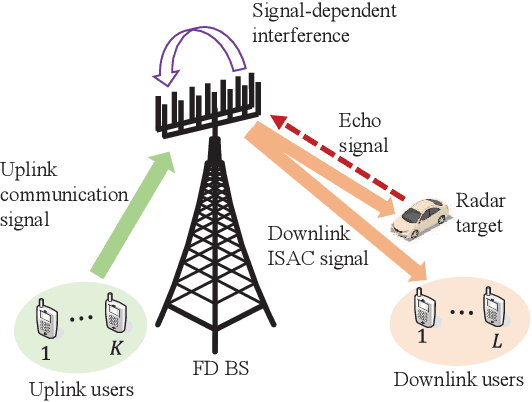
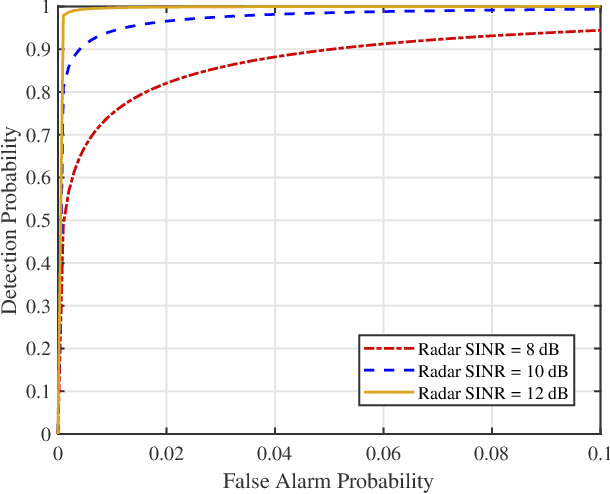
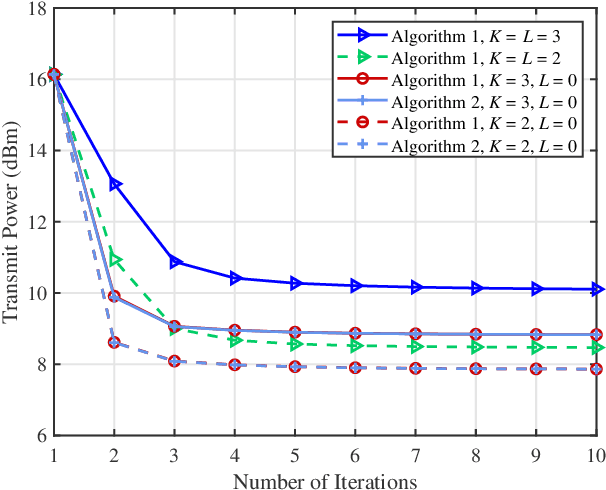
Beamforming design has been widely investigated for integrated sensing and communication (ISAC) systems with full-duplex (FD) sensing and half-duplex (HD) communication. To achieve higher spectral efficiency, in this paper, we extend existing ISAC beamforming design by considering the FD capability for both radar and communication. Specifically, we consider an ISAC system, where the BS performs target detection and communicates with multiple downlink users and uplink users reusing the same time and frequency resources. We jointly optimize the downlink dual-functional transmit signal and the uplink receive beamformers at the BS and the transmit power at the uplink users. The problems are formulated under two criteria: power consumption minimization and sum rate maximization. The downlink and uplink transmissions are tightly coupled due to both the desired target echo and the undesired interference received at the BS, making the problems challenging. To handle these issues in both cases, we first determine the optimal receive beamformers, which are derived in closed forms with respect to the BS transmit beamforming and the user transmit power, for radar target detection and uplink communications, respectively. Subsequently, we invoke these results to obtain equivalent optimization problems and propose efficient iterative algorithms to solve them by using the techniques of rank relaxation and successive convex approximation (SCA), where the adopted relaxation is proven to be tight. In addition, we consider a special case under the power minimization criterion and propose an alternative low complexity design. Numerical results demonstrate that the optimized FD communication-based ISAC brings tremendous improvements in terms of both power efficiency and spectral efficiency compared to the conventional ISAC with HD communication.
PIPPI2021: An Approach to Automated Diagnosis and Texture Analysis of the Fetal Liver & Placenta in Fetal Growth Restriction
Nov 01, 2022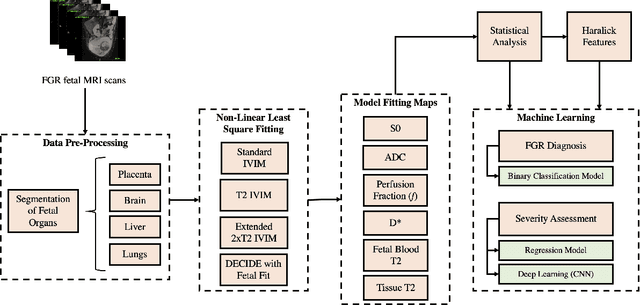
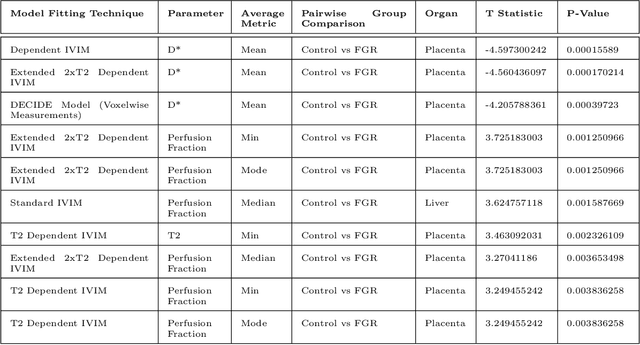
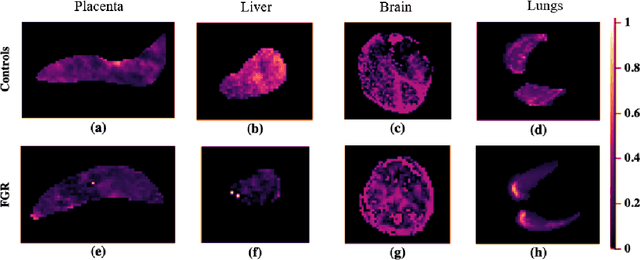
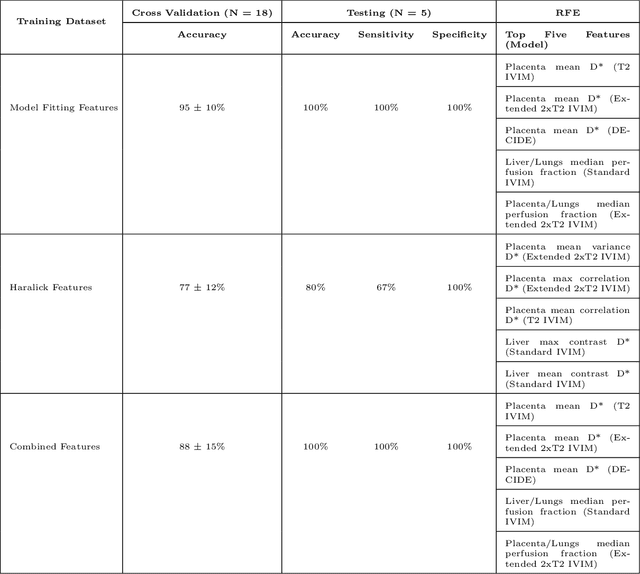
Fetal growth restriction (FGR) is a prevalent pregnancy condition characterised by failure of the fetus to reach its genetically predetermined growth potential. We explore the application of model fitting techniques, linear regression machine learning models, deep learning regression, and Haralick textured features from multi-contrast MRI for multi-fetal organ analysis of FGR. We employed T2 relaxometry and diffusion-weighted MRI datasets (using a combined T2-diffusion scan) for 12 normally grown and 12 FGR gestational age (GA) matched pregnancies. We applied the Intravoxel Incoherent Motion Model and novel multi-compartment models for MRI fetal analysis, which exhibit potential to provide a multi-organ FGR assessment, overcoming the limitations of empirical indicators - such as abnormal artery Doppler findings - to evaluate placental dysfunction. The placenta and fetal liver presented key differentiators between FGR and normal controls (decreased perfusion, abnormal fetal blood motion and reduced fetal blood oxygenation. This may be associated with the preferential shunting of the fetal blood towards the fetal brain. These features were further explored to determine their role in assessing FGR severity, by employing simple machine learning models to predict FGR diagnosis (100\% accuracy in test data, n=5), GA at delivery, time from MRI scan to delivery, and baby weight. Moreover, we explored the use of deep learning to regress the latter three variables. Image texture analysis of the fetal organs demonstrated prominent textural variations in the placental perfusion fractions maps between the groups (p$<$0.0009), and spatial differences in the incoherent fetal capillary blood motion in the liver (p$<$0.009). This research serves as a proof-of-concept, investigating the effect of FGR on fetal organs.
Recommendations in a Multi-Domain Setting: Adapting for Customization, Scalability and Real-Time Performance
Mar 02, 2022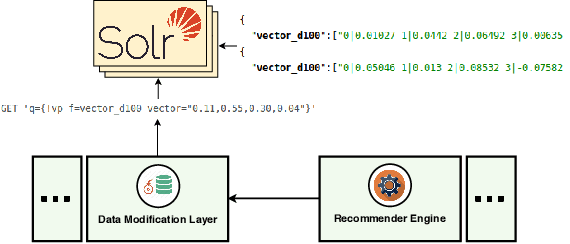
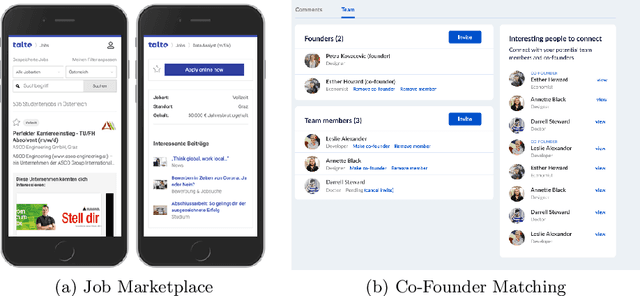
In this industry talk at ECIR'2022, we illustrate how to build a modern recommender system that can serve recommendations in real-time for a diverse set of application domains. Specifically, we present our system architecture that utilizes popular recommendation algorithms from the literature such as Collaborative Filtering, Content-based Filtering as well as various neural embedding approaches (e.g., Doc2Vec, Autoencoders, etc.). We showcase the applicability of our system architecture using two real-world use-cases, namely providing recommendations for the domains of (i) job marketplaces, and (ii) entrepreneurial start-up founding. We strongly believe that our experiences from both research- and industry-oriented settings should be of interest for practitioners in the field of real-time multi-domain recommender systems.
Real-time smart vehicle surveillance system
Nov 24, 2021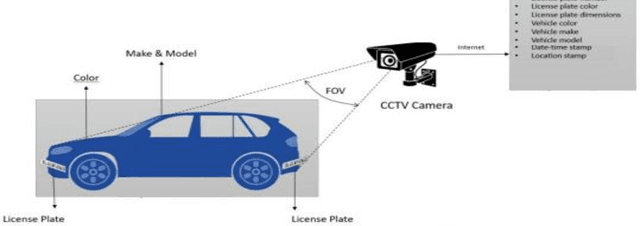
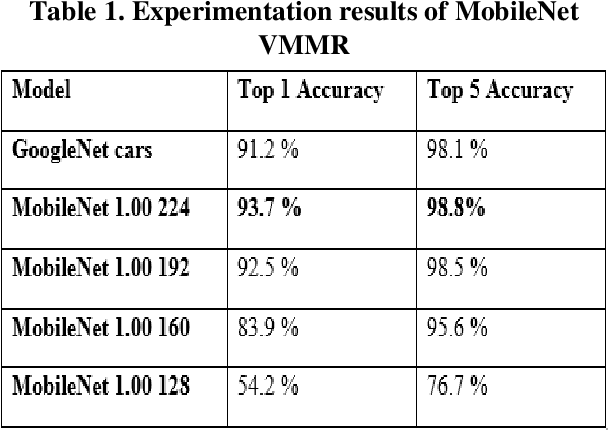

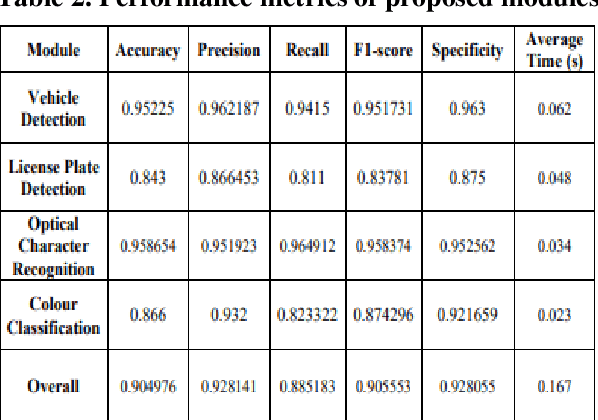
Over the last decade, there has been a spike in criminal activity all around the globe. According to the Indian police department, vehicle theft is one of the least solved offenses, and almost 19% of all recorded cases are related to motor vehicle theft. To overcome these adversaries, we propose a real-time vehicle surveillance system, which detects and tracks the suspect vehicle using the CCTV video feed. The proposed system extracts various attributes of the vehicle such as Make, Model, Color, License plate number, and type of the license plate. Various image processing and deep learning algorithms are employed to meet the objectives of the proposed system. The extracted features can be used as evidence to report violations of law. Although the system uses more parameters, it is still able to make real time predictions with minimal latency and accuracy loss.
ApacheJIT: A Large Dataset for Just-In-Time Defect Prediction
Feb 28, 2022
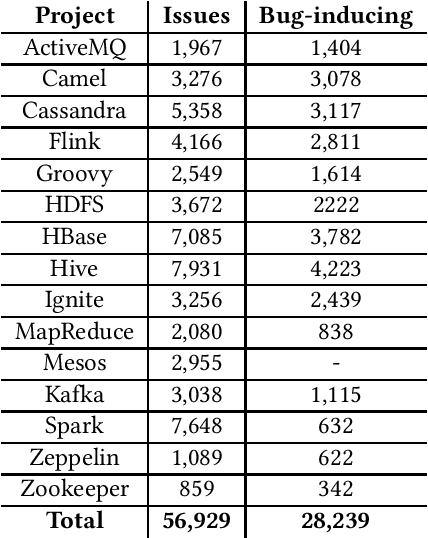
In this paper, we present ApacheJIT, a large dataset for Just-In-Time defect prediction. ApacheJIT consists of clean and bug-inducing software changes in popular Apache projects. ApacheJIT has a total of 106,674 commits (28,239 bug-inducing and 78,435 clean commits). Having a large number of commits makes ApacheJIT a suitable dataset for machine learning models, especially deep learning models that require large training sets to effectively generalize the patterns present in the historical data to future data. In addition to the original dataset, we also present carefully selected training and test sets that we recommend to be used in training and evaluating machine learning models.
A Temporal Densely Connected Recurrent Network for Event-based Human Pose Estimation
Sep 15, 2022
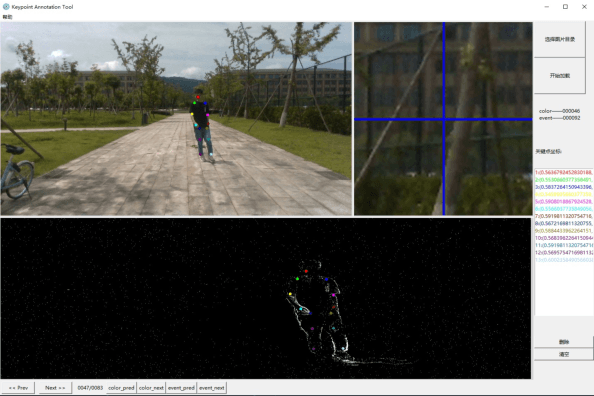

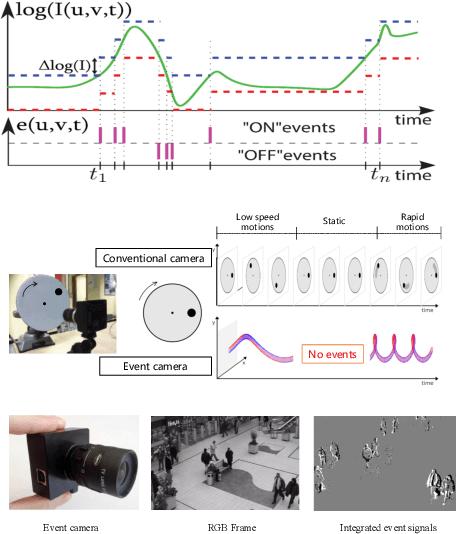
Event camera is an emerging bio-inspired vision sensors that report per-pixel brightness changes asynchronously. It holds noticeable advantage of high dynamic range, high speed response, and low power budget that enable it to best capture local motions in uncontrolled environments. This motivates us to unlock the potential of event cameras for human pose estimation, as the human pose estimation with event cameras is rarely explored. Due to the novel paradigm shift from conventional frame-based cameras, however, event signals in a time interval contain very limited information, as event cameras can only capture the moving body parts and ignores those static body parts, resulting in some parts to be incomplete or even disappeared in the time interval. This paper proposes a novel densely connected recurrent architecture to address the problem of incomplete information. By this recurrent architecture, we can explicitly model not only the sequential but also non-sequential geometric consistency across time steps to accumulate information from previous frames to recover the entire human bodies, achieving a stable and accurate human pose estimation from event data. Moreover, to better evaluate our model, we collect a large scale multimodal event-based dataset that comes with human pose annotations, which is by far the most challenging one to the best of our knowledge. The experimental results on two public datasets and our own dataset demonstrate the effectiveness and strength of our approach. Code can be available online for facilitating the future research.